【datawhale组队学习】RAG技术 -TASK05 向量数据库实践(第三章3、4节)
教程地址:https://github.com/datawhalechina/all-in-rag
TASK05 向量数据库实践(第三章3、4节)
文章目录
- 向量数据库
- 工作原理
- 主流向量数据库
- 本地向量存储:以 FAISS 为例
- 基础示例(FAISS)
- milvus
- 部署安装
- 核心组件
- Collection (集合)
- Schema
- Partition (分区)
- Alias (别名)
- 索引 (Index)
- 主要向量索引类型
- 如何选择
- 检索
- 基础向量检索 (ANN Search)
- 增强检索
- milvus多模态实践
- 初始化与工具定义
- 创建 Collection
- 准备并插入数据
- 创建索引
- 执行多模态检索
- 可视化与清理
向量数据库
向量数据库的核心价值在于其高效处理海量高维向量的能力。其主要功能可以概括为以下几点:
- 高效的相似性搜索:这是向量数据库最重要的功能。它利用专门的索引技术(如 HNSW, IVF),能够在数十亿级别的向量中实现毫秒级的近似最近邻(ANN)查询,快速找到与给定查询最相似的数据。
- 高维数据存储与管理:专门为存储高维向量(通常维度成百上千)而优化,支持对向量数据进行增、删、改、查等基本操作。
- 丰富的查询能力:除了基本的相似性搜索,还支持按标量字段过滤查询(例如,在搜索相似图片的同时,指定年份 > 2023)、范围查询和聚类分析等,满足复杂业务需求。
4。 可扩展与高可用:现代向量数据库通常采用分布式架构,具备良好的水平扩展能力和容错性,能够通过增加节点来应对数据量的增长,并确保服务的稳定可靠。 - 数据与模型生态集成:与主流的 AI 框架(如 LangChain, LlamaIndex)和机器学习工作流无缝集成,简化了从模型训练到向量检索的应用开发流程。
向量数据库 vs 传统数据库
传统的数据库(如 MySQL)擅长处理结构化数据的精确匹配查询(例如,WHERE age = 25),但它们并非为处理高维向量的相似性搜索而设计的。
在庞大的向量集合中进行暴力、线性的相似度计算,其计算成本和时间延迟无法接受。向量数据库 (Vector Database) 很好的解决了这一问题,它是一种专门设计用于高效存储、管理和查询高维向量的数据库系统。在 RAG 流程中,它扮演着“知识库”的角色,是连接数据与大语言模型的关键桥梁。
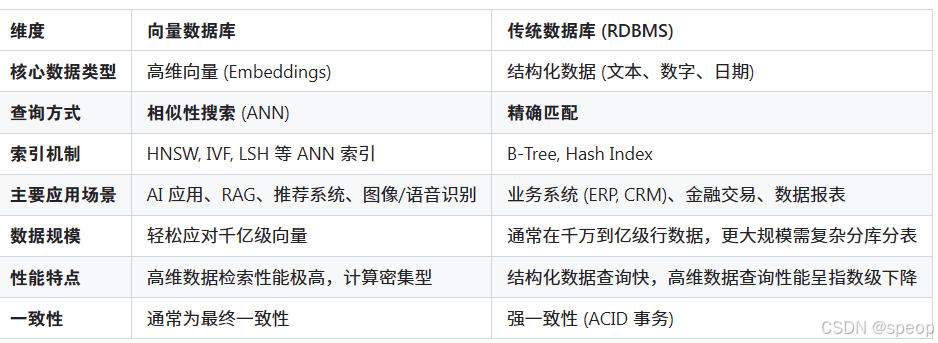
向量数据库和传统数据库并非相互替代的关系,而是互补关系。在构建现代 AI 应用时,通常会将两者结合使用:利用传统数据库存储业务元数据和结构化信息,而向量数据库则专门负责处理和检索由 AI 模型产生的海量向量数据。
工作原理
向量数据库的核心是高效处理高维向量的相似性搜索。向量是一组有序的数值,可以表示文本、图像、音频等复杂数据的特征或属性。在 RAG 系统中,向量一般通过嵌入模型将原始数据转换为高维向量表示,比如上一节的图文示例。
向量数据库通常采用四层架构,通过以下技术手段实现高效相似性搜索:
- 存储层:存储向量数据和元数据,优化存储效率,支持分布式存储
- 索引层:维护索引算法(HNSW、LSH、PQ等),创建和优化索引,支持索引调整
- 查询层:处理查询请求,支持混合查询,实现查询优化
- 服务层:管理客户端连接,提供监控和日志,实现安全管理
主要技术手段包括:
基于树的方法:如 Annoy 使用的随机投影树,通过树形结构实现对数复杂度的搜索
基于哈希的方法:如 LSH(局部敏感哈希),通过哈希函数将相似向量映射到同一“桶”
基于图的方法:如 HNSW(分层可导航小世界图),通过多层邻近图结构实现快速搜索
基于量化的方法:如 Faiss 的 IVF 和 PQ,通过聚类和量化压缩向量
主流向量数据库
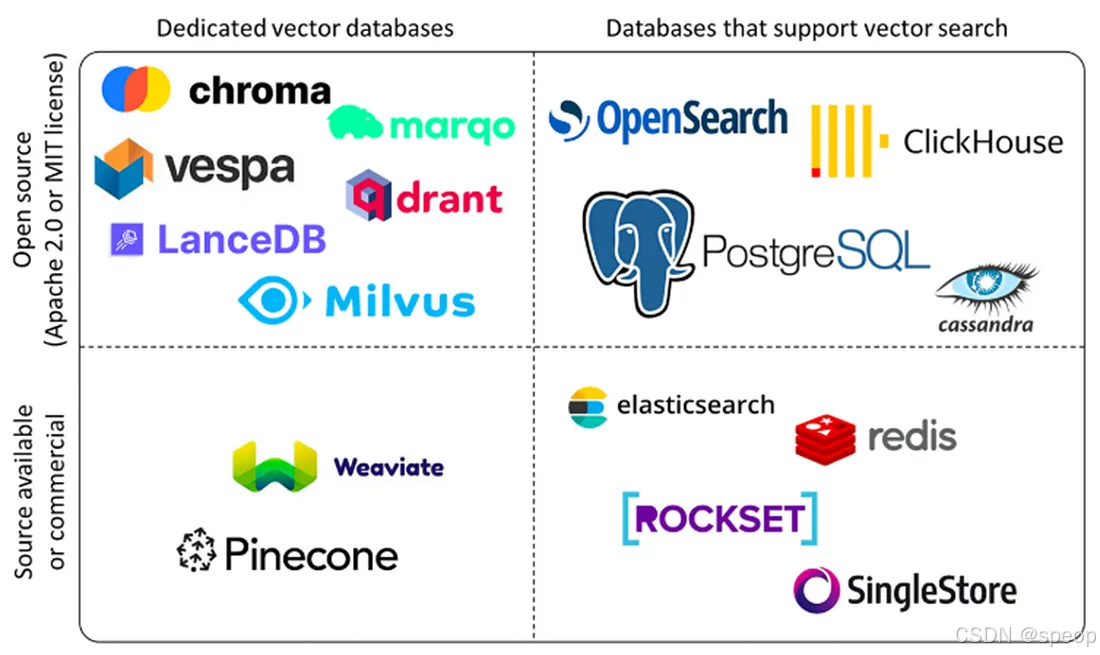
Pinecone 是一款完全托管的向量数据库服务,采用Serverless架构设计。它提供存储计算分离、自动扩展和负载均衡等企业级特性,并保证99.95%的SLA。Pinecone支持多种语言SDK,提供极高可用性和低延迟搜索(<100ms),特别适合企业级生产环境、高并发场景和大规模部署。
Milvus 是一款开源的分布式向量数据库,采用分布式架构设计,支持GPU加速和多种索引算法。它能够处理亿级向量检索,提供高性能GPU加速和完善的生态系统。Milvus特别适合大规模部署、高性能要求的场景,以及需要自定义开发的开源项目。
Qdrant 是一款高性能的开源向量数据库,采用Rust开发,支持二进制量化技术。它提供多种索引策略和向量混合搜索功能,能够实现极高的性能(RPS>4000)和低延迟搜索。Qdrant特别适合性能敏感应用、高并发场景以及中小规模部署。
Weaviate 是一款支持GraphQL的AI集成向量数据库,提供20+AI模块和多模态支持。它采用GraphQL API设计,支持RAG优化,特别适合AI开发、多模态处理和快速开发场景。Weaviate具有活跃的社区支持和易于集成的特点。
Chroma 是一款轻量级的开源向量数据库,采用本地优先设计,无依赖。它提供零配置安装、本地运行和低资源消耗等特性,特别适合原型开发、教育培训和小规模应用。Chroma的部署简单,适合快速原型开发。
选择建议:
- 新手入门/小型项目:从 ChromaDB 或 FAISS 开始是最佳选择。它们与 LangChain/LlamaIndex 紧密集成,几行代码就能运行,且能满足基本的存储和检索需求。
- 生产环境/大规模应用:当数据量超过百万级,或需要高并发、实时更新、复杂元数据过滤时,应考虑更专业的解决方案,如 Milvus、Weaviate 或云服务 Pinecone。
本地向量存储:以 FAISS 为例
FAISS (Facebook AI Similarity Search) 是一个由 Facebook AI Research 开发的高性能库,专门用于高效的相似性搜索和密集向量聚类。当与 LangChain 结合使用时,它可以作为一个强大的本地向量存储方案,非常适合快速原型设计和中小型应用。
与 ChromaDB 等数据库不同,FAISS 本质上是一个算法库,它将索引直接保存为本地文件(一个 .faiss 索引文件和一个 .pkl 映射文件),而非运行一个数据库服务。这种方式轻量且高效。
基础示例(FAISS)
02_langchain_faiss.py
FAISS:Facebook 开发的高效向量搜索库,用于对密集向量进行相似性检索和聚类。
HuggingFaceEmbeddings:加载 HuggingFace 生态的预训练模型,将文本转换为向量(嵌入)。
Document:LangChain 中的文档对象,用于标准化文本数据的格式。
原始文本 → 嵌入模型转为向量 → FAISS构建索引并保存 → 加载索引 → 输入查询→ 找到最相似文本
# 导入FAISS向量存储库,用于存储和检索向量
from langchain_community.vectorstores import FAISS
# 导入HuggingFace嵌入模型,用于将文本转换为向量
from langchain_community.embeddings import HuggingFaceEmbeddings
# 导入Document类,用于标准化文本数据格式
from langchain_core.documents import Document
# 1. 示例文本和嵌入模型
texts = ["张三是法外狂徒","FAISS是一个用于高效相似性搜索和密集向量聚类的库。","LangChain是一个用于开发由语言模型驱动的应用程序的框架。"
]
docs = [Document(page_content=t) for t in texts]
#通过列表推导式,将每条文本t转换为Document对象(仅包含文本内容page_content),统一格式以便 LangChain 处理。
#########1. 嵌入模型转为向量
embeddings = HuggingFaceEmbeddings(model_name="BAAI/bge-small-zh-v1.5")
#初始化嵌入模型:加载预训练模型BAAI/bge-small-zh-v1.5(这是一个轻量级中文语义嵌入模型),用于后续将文本转换为向量
######### 2. 创建向量存储并保存到本地
vectorstore = FAISS.from_documents(docs, embeddings)
#构建向量存储:FAISS.from_documents方法会自动调用embeddings模型将docs中的所有文本转换为向量,然后创建 FAISS 向量索引,存储向量与对应文本的映射关系。
local_faiss_path = "./faiss_index_store"
#定义本地保存路径local_faiss_path,指定向量索引文件的存储位置(当前目录下的faiss_index_store文件夹)
vectorstore.save_local(local_faiss_path)
#将构建好的 FAISS 向量索引(包含向量数据和文本映射)保存到本地路径,避免重复计算向量,方便后续直接加载使用。
print(f"FAISS index has been saved to {local_faiss_path}")
#打印提示信息,告知用户向量索引已成功保存到指定路径。
######### 3. 加载索引并执行查询
# 加载时需指定相同的嵌入模型,并允许反序列化
loaded_vectorstore = FAISS.load_local(local_faiss_path,embeddings,allow_dangerous_deserialization=True
)
#从本地加载向量索引:FAISS.load_local方法读取之前保存的向量数据,
#需传入相同的embeddings模型(确保向量格式一致)
#allow_dangerous_deserialization=True允许反序列化本地文件(注意:生产环境需评估安全性)。
# 相似性搜索
query = "FAISS是做什么的?"
#定义查询文本query,即用户想了解的问题:“FAISS 是做什么的?
results = loaded_vectorstore.similarity_search(query, k=1)
#执行相似性搜索:similarity_search方法会先将query转换为向量,然后在加载的向量库中查找与该向量最相似的文本,k=1表示返回相似度最高的 1 条结果。
print(f"\n查询: '{query}'")
#打印查询文本,展示用户的问题。
print("相似度最高的文档:")
for doc in results:print(f"- {doc.page_content}")
#打印提示信息,告知后续内容是匹配到的最相似文档。
#遍历搜索结果results(这里只有 1 条),打印每条结果的文本内容(doc.page_content),最终会输出与查询最相关的文本:“FAISS 是一个用于高效相似性搜索和密集向量聚类的库。”
输出

索引创建实现细节:
通过深入 LangChain 源码,可以发现索引创建是一个分层、解耦的过程,主要涉及以下几个方法的嵌套调用:
-
from_documents(封装层):- 这是我们直接调用的方法。它的职责很简单:从输入的
Document对象列表中提取出纯文本内容 (page_content) 和元数据 (metadata)。 - 然后,它将这些提取出的信息传递给核心的
from_texts方法。
- 这是我们直接调用的方法。它的职责很简单:从输入的
-
from_texts(向量化入口):- 这个方法是面向用户的核心入口。它接收文本列表,并执行关键的第一步:调用
embedding.embed_documents(texts),将所有文本批量转换为向量。 - 完成向量化后,它并不直接处理索引构建,而是将生成的向量和其他所有信息(文本、元数据等)传递给一个内部的辅助方法
__from。
- 这个方法是面向用户的核心入口。它接收文本列表,并执行关键的第一步:调用
-
__from(构建索引框架):- 这是一个内部方法,负责搭建 FAISS 向量存储的“空框架”。
- 它会根据指定的距离策略(默认为 L2 欧氏距离)初始化一个空的 FAISS 索引结构(如
faiss.IndexFlatL2)。 - 同时,它也准备好了用于存储文档原文的
docstore和用于连接 FAISS 索引与文档的index_to_docstore_id映射。 - 最后,它调用另一个内部方法
__add来完成数据的填充。
-
__add(填充数据):- 这是真正执行数据添加操作的核心。它接收到向量、文本和元数据后,执行以下关键操作:
- 添加向量: 将向量列表转换为 FAISS 需要的
numpy数组,并调用self.index.add(vector)将其批量添加到 FAISS 索引中。 - 存储文档: 将文本和元数据打包成
Document对象,存入docstore。 - 建立映射: 更新
index_to_docstore_id字典,建立起 FAISS 内部的整数 ID(如 0, 1, 2…)到我们文档唯一 ID 的映射关系。
03_llamaindex_vector.py
- 添加向量: 将向量列表转换为 FAISS 需要的
- 这是真正执行数据添加操作的核心。它接收到向量、文本和元数据后,执行以下关键操作:
from llama_index.core import VectorStoreIndex, Document, Settings
from llama_index.embeddings.huggingface import HuggingFaceEmbedding# 1. 配置全局嵌入模型
Settings.embed_model = HuggingFaceEmbedding("BAAI/bge-small-zh-v1.5")# 2. 创建示例文档
texts = ["张三是法外狂徒","LlamaIndex是一个用于构建和查询私有或领域特定数据的框架。","它提供了数据连接、索引和查询接口等工具。"
]
docs = [Document(text=t) for t in texts]# 3. 创建索引并持久化到本地
index = VectorStoreIndex.from_documents(docs)
persist_path = "./llamaindex_index_store"
index.storage_context.persist(persist_dir=persist_path)
print(f"LlamaIndex 索引已保存至: {persist_path}")
from llama_index.core import VectorStoreIndex, StorageContext, load_index_from_storage
from llama_index.core import Settings
from llama_index.embeddings.huggingface import HuggingFaceEmbeddingdef load_llamaindex_and_search(query: str, persist_path: str = "./llamaindex_index_store", top_k: int = 1):"""加载LlamaIndex索引并执行相似性搜索参数:query: 搜索查询文本persist_path: 索引存储路径top_k: 返回的相似文档数量返回:搜索结果列表"""# 1. 配置与创建索引时相同的嵌入模型(必须保持一致)Settings.embed_model = HuggingFaceEmbedding("/home/jingyi/all-in-rag/code/C1/bge-small-zh-v1.5")Settings.llm = None# 2. 从本地加载存储的索引storage_context = StorageContext.from_defaults(persist_dir=persist_path)index = load_index_from_storage(storage_context)# 3. 创建查询引擎并执行相似性搜索query_engine = index.as_query_engine(similarity_top_k=top_k,llm=None)response = query_engine.query(query)return responseif __name__ == "__main__":# 示例查询search_query = "LlamaIndex能做什么?"result = load_llamaindex_and_search(search_query, top_k=2)# 输出结果print(f"查询: {search_query}")print("相似性搜索结果:")print(f"- 最相关内容: {result.response}")# 打印原始文档信息(可选)print("\n匹配的原始文档:")for doc in result.source_nodes:print(f"文档内容: {doc.text}")print(f"相似度分数: {doc.score:.4f}\n")
milvus
Milvus 是一个开源的、专为大规模向量相似性搜索和分析而设计的向量数据库。它诞生于 Zilliz 公司,并已成为 LF AI & Data 基金会的顶级项目,在AI领域拥有广泛的应用。
与 FAISS、ChromaDB 等轻量级本地存储方案不同,Milvus 从设计之初就瞄准了生产环境。其采用云原生架构,具备高可用、高性能、易扩展的特性,能够处理十亿、百亿甚至更大规模的向量数据。
官网地址: https://milvus.io/
GitHub: https://github.com/milvus-io/milvus
部署安装
-
安装docker
-
下载配置文件
wget https://github.com/milvus-io/milvus/releases/download/v2.5.14/milvus-standalone-docker-compose.yml -O docker-compose.yml
#MinIO 用于对象存储
docker compose up -d
#在 docker-compose.yml 文件所在的目录中,运行以下命令以后台模式启动 Milvus
验证安装
可以通过以下方式验证 Milvus 是否成功启动:
查看 Docker 容器: 打开 Docker Desktop 的仪表盘 (Windows/macOS) 或在终端运行 docker ps 命令 (Linux),确认三个 Milvus 相关容器(milvus-standalone, milvus-minio, milvus-etcd)都处于 running 或 up 状态。
检查服务端口: Milvus Standalone 默认通过 19530 端口提供服务,这是后续代码连接时需要用到的地址。
常用管理命令
docker compose down #此命令会停止并移除容器,但保留存储的数据卷。
docker compose down -v#彻底清理 (停止并删除数据): 如果想彻底删除所有数据(包括向量、元数据等)
核心组件
Collection (集合)
- Collection (集合): 相当于一个图书馆,是所有数据的顶层容器。一个 Collection 可以包含多个 Partition,每个 Partition 可以包含多个 Entity。
- Partition (分区): 相当于图书馆里的不同区域(如“小说区”、“科技区”),将数据物理隔离,让检索更高效。
- Schema (模式): 相当于图书馆的图书卡片规则,定义了每本书(数据)必须登记哪些信息(字段)。
- Entity (实体): 相当于一本具体的书,是数据本身。
- Alias (别名): 相当于一个动态的推荐书单(如“本周精选”),它可以指向某个具体的 Collection,方便应用层调用,实现数据更新时的无缝切换。

Collection 是 Milvus 中最基本的数据组织单位,类似于关系型数据库中的一张表 (Table)。是我们存储、管理和查询向量及相关元数据的容器。所有的数据操作,如插入、删除、查询等,都是围绕 Collection 展开的。
一个 Collection 由其 Schema 定义,并包含以下重要的子概念和特性:
Schema
在创建 Collection 之前,必须先定义它的 Schema。 Schema 规定了 Collection 的数据结构,定义了其中包含的所有字段 (Field) 及其属性。一个设计良好的 Schema 对于保证数据一致性和提升查询性能至关重要。
Schema 通常包含以下几类字段:
- 主键字段 (Primary Key Field): 每个 Collection 必须有且仅有一个主键字段,用于唯一标识每一条数据(实体)。它的值必须是唯一的,通常是整数或字符串类型。
- 向量字段 (Vector Field): 用于存储核心的向量数据。一个 Collection 可以有一个或多个向量字段,以满足多模态等复杂场景的需求。Image Embedding/Summary Embedding/Summary Sparse Embedding(Sparse Vector)
- 标量字段 (Scalar Field): 用于存储除向量之外的元数据,如字符串、数字、布尔值、JSON 等。这些字段可以用于过滤查询,实现更精确的检索。
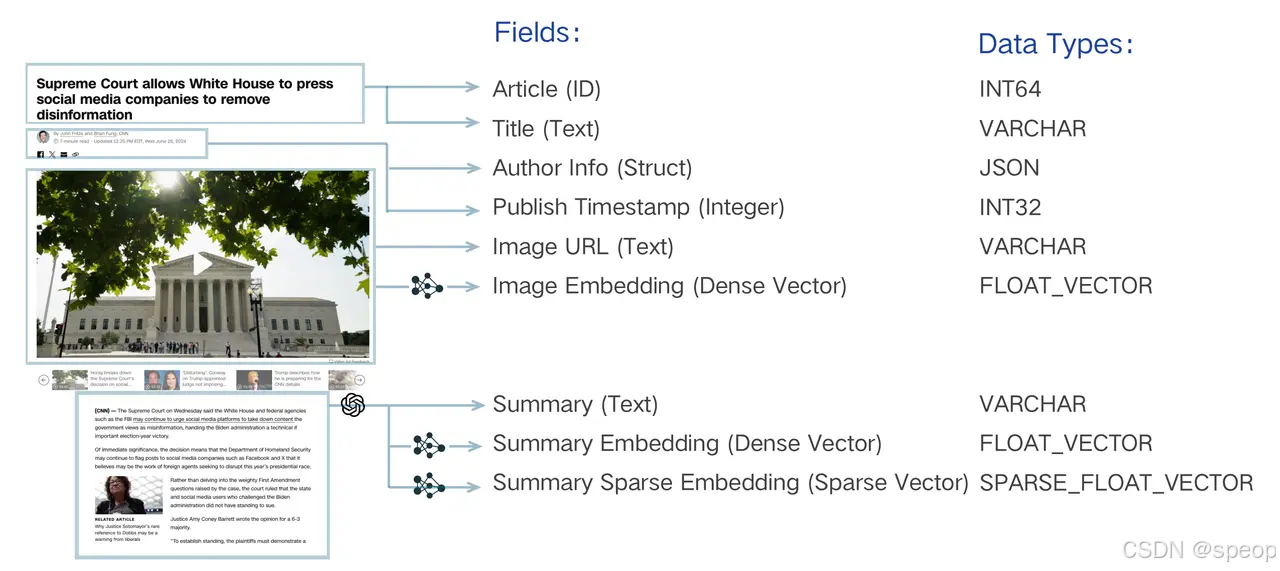
上图以一篇新闻文章为例,生动地展示了一个典型的多模态、混合向量 Schema 设计。它将一篇文章拆解为:唯一的 Article (ID)、文本元数据(如 Title、Author Info)、图像信息(Image URL),并为图像和摘要内容分别生成了密集向量(Image Embedding, Summary Embedding)和稀疏向量(Summary Sparse Embedding)。
Partition (分区)
Partition 是 Collection 内部的一个逻辑划分。每个 Collection 在创建时都会有一个名为 _default 的默认分区。我们可以根据业务需求创建更多的分区,将数据按特定规则(如类别、日期等)存入不同分区。
为什么使用分区?
提升查询性能: 在查询时,可以指定只在一个或几个分区内进行搜索,从而大幅减少需要扫描的数据量,显著提升检索速度。
数据管理: 便于对部分数据进行批量操作,如加载/卸载特定分区到内存,或者删除整个分区的数据。
一个 Collection 最多可以有 1024 个分区。合理利用分区是 Milvus 性能优化的重要手段之一。
Alias (别名)
Alias (别名) 是为 Collection 提供的一个“昵称”。通过为一个 Collection 设置别名,我们可以在应用程序中使用这个别名来执行所有操作,而不是直接使用真实的 Collection 名称。
为什么使用别名?
- 安全地更新数据:想象一下,你需要对一个在线服务的 Collection 进行大规模的数据更新或重建索引。直接在原 Collection 上操作风险很高。正确的做法是:
- 创建一个新的 Collection (
collection_v2) 并导入、索引好所有新数据。 - 将指向旧 Collection (
collection_v1) 的别名(例如my_app_collection)原子性地切换到新 Collection (collection_v2) 上。
- 创建一个新的 Collection (
- 代码解耦:整个切换过程对上层应用完全透明,无需修改任何代码或重启服务,实现了数据的平滑无缝升级。
索引 (Index)
如果说 Collection 是 Milvus 的骨架,那么索引 (Index) 就是其加速检索的神经系统。从宏观上看,索引本身就是一种为了加速查询而设计的复杂数据结构。对向量数据创建索引后,Milvus 可以极大地提升向量相似性搜索的速度,代价是会占用额外的存储和内存资源。
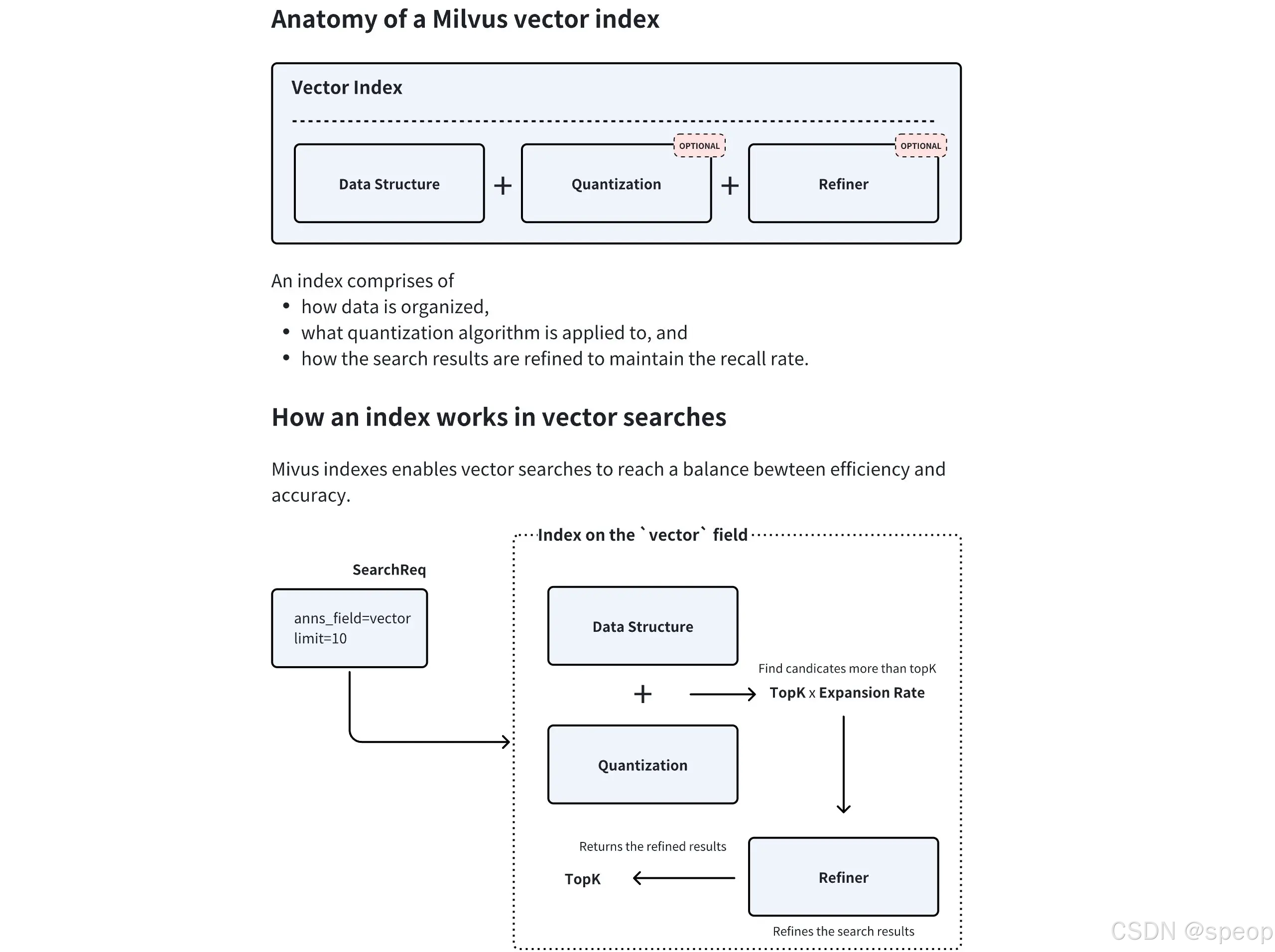
上图清晰地展示了 Milvus 向量索引的内部组件及其工作流程:
上图清晰地展示了 Milvus 向量索引的内部组件及其工作流程:
- 数据结构:这是索引的骨架,定义了向量的组织方式(如 HNSW 中的图结构)。
- 量化(可选):数据压缩技术,通过降低向量精度来减少内存占用和加速计算。
- 结果精炼(可选):在找到初步候选集后,进行更精确的计算以优化最终结果。
Milvus 支持对标量字段和向量字段分别创建索引。 - 标量字段索引:主要用于加速元数据过滤,常用的有
INVERTED、BITMAP等。通常使用推荐的索引类型即可。 - 向量字段索引:这是 Milvus 的核心。选择合适的向量索引是在查询性能、召回率和内存占用之间做出权衡的艺术。
主要向量索引类型
-
FLAT (精确查找)
- 原理:暴力搜索(Brute-force Search)。它会计算查询向量与集合中所有向量之间的实际距离,返回最精确的结果。
- 优点:100% 的召回率,结果最准确。
- 缺点:速度慢,内存占用大,不适合海量数据。
- 适用场景:对精度要求极高,且数据规模较小(百万级以内)的场景。
-
IVF 系列 (倒排文件索引)
- 原理:类似于书籍的目录。它首先通过聚类将所有向量分成多个“桶”(
nlist),查询时,先找到最相似的几个“桶”,然后只在这几个桶内进行精确搜索。IVF_FLAT、IVF_SQ8、IVF_PQ是其不同变体,主要区别在于是否对桶内向量进行了压缩(量化)。 - 优点:通过缩小搜索范围,极大地提升了检索速度,是性能和效果之间很好的平衡。
- 缺点:召回率不是100%,因为相关向量可能被分到了未被搜索的桶中。
- 适用场景:通用场景,尤其适合需要高吞吐量的大规模数据集。
- 原理:类似于书籍的目录。它首先通过聚类将所有向量分成多个“桶”(
-
HNSW (基于图的索引)
- 原理:构建一个多层的邻近图。查询时从最上层的稀疏图开始,[快速定位]到目标区域,然后在下层的密集图中进行[精确搜索]。
- 优点:检索速度极快,召回率高,尤其擅长处理高维数据和低延迟查询。
- 缺点:内存占用非常大,构建索引的时间也较长。
- 适用场景:对查询延迟有严格要求(如实时推荐、在线搜索)的场景。
-
DiskANN (基于磁盘的索引)
- 原理:一种为在 SSD 等高速磁盘上运行而优化的图索引。
- 优点:支持远超内存容量的海量数据集(十亿级甚至更多),同时保持较低的查询延迟。
- 缺点:相比纯内存索引,延迟稍高。
- 适用场景:数据规模巨大,无法全部加载到内存的场景。
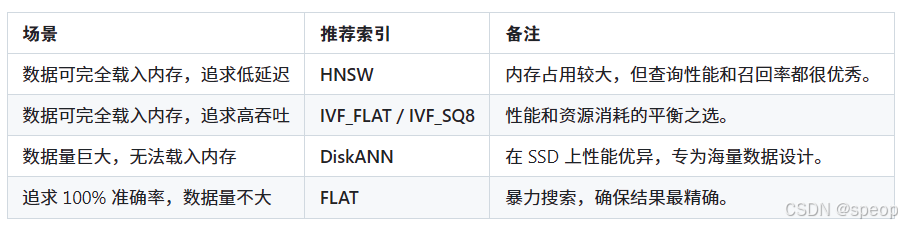
如何选择
检索
拥有了数据容器 (Collection) 和检索引擎 (Index) 后,最后一步就是从海量数据中高效地检索信息。
基础向量检索 (ANN Search)
这是 Milvus 的核心功能之一,近似最近邻 (Approximate Nearest Neighbor, ANN) 检索。与需要计算全部数据的暴力检索(Brute-force Search)不同,ANN 检索利用预先构建好的索引,能够极速地从海量数据中找到与查询向量最相似的 Top-K 个结果。这是一种在速度和精度之间取得极致平衡的策略。
- 主要参数:
anns_field: 指定要在哪个向量字段上进行检索。data: 传入一个或多个查询向量。limit(或top_k): 指定需要返回的最相似结果的数量。search_params: 指定检索时使用的参数,例如距离计算方式 (metric_type) 和索引相关的查询参数。
增强检索
在基础的 ANN 检索之上,Milvus 提供了多种增强检索功能,以满足更复杂的业务需求。
过滤检索 (Filtered Search)
在实际应用中,我们很少只进行单纯的向量检索。更常见的需求是“在满足特定条件的向量中,查找最相似的结果”,这就是过滤检索。它将向量相似性检索与标量字段过滤结合在一起。
- 工作原理:先根据提供的过滤表达式 (
filter) 筛选出符合条件的实体,然后仅在这个子集内执行 ANN 检索。这极大地提高了查询的精准度。 - 应用示例:
- 电商:“检索与这件红色连衣裙最相似的商品,但只看价格低于500元且有库存的。”
- 知识库:“查找与‘人工智能’相关的文档,但只从‘技术’分类下、且发布于2023年之后的文章中寻找。”
范围检索 (Range Search)
有时我们关心的不是最相似的 Top-K 个结果,而是“所有与查询向量的相似度在特定范围内的结果”。
- 工作原理:范围检索允许定义一个距离(或相似度)的阈值范围。Milvus 会返回所有与查询向量的距离落在这个范围内的实体。
- 应用示例:
- 人脸识别:“查找所有与目标人脸相似度超过 0.9 的人脸”,用于身份验证。
- 异常检测:“查找所有与正常样本向量距离过大的数据点”,用于发现异常。
多向量混合检索 (Hybrid Search)
这是 Milvus 提供的一种极其强大的高级检索模式,它允许在一个请求中同时检索多个向量字段,并将结果智能地融合在一起。
- 工作原理:
- 并行检索:应用针对不同的向量字段(如一个用于文本语义的密集向量,一个用于关键词匹配的稀疏向量,一个用于图像内容的多模态向量)分别发起 ANN 检索请求。
- 结果融合 (Rerank):Milvus 使用一个重排策略(Reranker)将来自不同检索流的结果合并成一个统一的、更高质量的排序列表。常用的策略有
RRFRanker(平衡各方结果)和WeightedRanker(可为特定字段结果加权)。
- 应用示例:
- 多模态商品检索:用户输入文本“安静舒适的白色耳机”,系统可以同时检索商品的文本描述向量和图片内容向量,返回最匹配的商品。
- 增强型 RAG: 结合密集向量(捕捉语义)和稀疏向量(精确匹配关键词),实现比单一向量更精准的文档检索效果。
分组检索 (Grouping Search)
分组检索解决了一个常见的痛点:检索结果多样性不足。想象一下,你检索“机器学习”,返回的前10篇文章都来自同一本教科书不同章节。这显然不是理想的结果。
- 工作原理:分组检索允许指定一个字段(如
document_id)对结果进行分组。Milvus 会在检索后,确保返回的结果中每个组(每个document_id)只出现一次(或指定的次数),且返回的是该组内与查询最相似的那个实体。 - 应用示例:
- 视频检索:检索“可爱的猫咪”,确保返回的视频来自不同的博主。
- 文档检索:检索“数据库索引”,确保返回的结果来自不同的书籍或来源。
| 检索类型 | 核心目标 | 关键逻辑 | 典型场景 |
|---|---|---|---|
| 过滤检索 | 精准匹配(向量+标量) | 先过滤标量子集,再查向量相似 | 电商相似商品(限价格/库存) |
| 范围检索 | 全量匹配(阈值内) | 按相似度/距离阈值返回所有符合项 | 人脸识别(相似度≥0.9) |
| 多向量混合检索 | 多维度精准匹配 | 多向量并行检索,结果重排融合 | 多模态商品(文本+图片向量) |
| 分组检索 | 结果多样性 | 按指定字段分组,每组仅返回少量结果 | 文档检索(限不同来源) |
milvus多模态实践
初始化与工具定义
首先导入所有必需的库,定义好模型路径、数据目录等常量。为了代码的整洁和复用,将 Visualized-BGE 模型的加载和编码逻辑封装在一个 Encoder 类中,并定义了一个 visualize_results 函数用于后续的结果可视化。
# 导入所需的系统操作、进度显示、文件查找、深度学习及向量数据库相关库
import os # 用于文件路径、目录操作等系统级功能
from tqdm import tqdm # 用于显示循环、任务执行的进度条
from glob import glob # 用于按通配符模式查找文件路径
import torch # PyTorch深度学习框架,用于模型加载和张量计算
from visual_bge.visual_bge.modeling import Visualized_BGE # 导入Visualized_BGE多模态模型(支持图文编码)
from pymilvus import MilvusClient, FieldSchema, CollectionSchema, DataType # Milvus向量数据库相关工具(客户端、字段/集合 schema 定义、数据类型)
import numpy as np # 用于数值计算和图像数组处理
import cv2 # OpenCV库,用于图像读取、缩放、边框添加等图像处理操作
from PIL import Image # PIL/Pillow库,用于图像打开和格式转换# 1. 初始化设置:定义模型、数据、向量数据库相关的核心参数
MODEL_NAME = "BAAI/bge-base-en-v1.5" # BGE基础英文模型名称(用于指定模型结构)
MODEL_PATH = "../../models/bge/Visualized_base_en_v1.5.pth" # 预训练模型权重文件的本地路径
DATA_DIR = "../../data/C3" # 待处理/检索的图像数据所在目录
COLLECTION_NAME = "multimodal_demo" # Milvus中用于存储多模态数据的集合(Collection)名称
MILVUS_URI = "http://localhost:19530" # Milvus服务的连接地址(本地默认端口19530)# 2. 定义工具 (编码器和可视化函数):封装图文编码和检索结果可视化功能
class Encoder:"""编码器类,用于将图像和文本编码为向量(统一多模态数据的表示形式)。"""def __init__(self, model_name: str, model_path: str):# 初始化时加载Visualized_BGE多模态模型(传入模型结构名称和权重路径)self.model = Visualized_BGE(model_name_bge=model_name, model_weight=model_path)# 设置模型为评估模式(禁用训练时的 dropout、batch norm 等随机操作)self.model.eval()def encode_query(self, image_path: str, text: str) -> list[float]:"""将图像和文本组合的查询(多模态查询)编码为向量。Args:image_path: 查询图像的本地路径text: 查询文本内容Returns:编码后的向量(转换为Python列表格式,取第一个元素是因为模型输出为批量格式)"""# 禁用梯度计算(推理阶段无需反向传播,节省内存并加速)with torch.no_grad():# 调用模型的encode方法,传入图像路径和文本,得到多模态查询向量query_emb = self.model.encode(image=image_path, text=text)# 将PyTorch张量转换为Python列表,取第一个元素(因模型默认输出批量维度,单样本时索引0为有效数据)return query_emb.tolist()[0]def encode_image(self, image_path: str) -> list[float]:"""将单张图像编码为向量(用于图像数据入库前的预处理)。Args:image_path: 待编码图像的本地路径Returns:编码后的图像向量(Python列表格式)"""# 禁用梯度计算(推理阶段优化)with torch.no_grad():# 调用模型的encode方法,仅传入图像路径,得到图像向量query_emb = self.model.encode(image=image_path)# 张量转列表,取第一个元素(处理批量维度)return query_emb.tolist()[0]def visualize_results(query_image_path: str, retrieved_images: list, img_height: int = 300, img_width: int = 300, row_count: int = 3) -> np.ndarray:"""从检索到的图像列表创建一个全景图用于可视化(左侧显示查询图,右侧显示检索结果)。Args:query_image_path: 查询图像的本地路径retrieved_images: 检索到的图像路径列表img_height: 单个图像的显示高度(默认300像素)img_width: 单个图像的显示宽度(默认300像素)row_count: 检索结果的每行显示数量(默认3张)Returns:拼接后的全景图像(numpy数组格式,可直接用cv2显示或保存)"""# 计算全景图的总宽度和高度:右侧结果区为 row_count×row_count 网格,左侧为单列panoramic_width = img_width * row_count # 右侧检索结果区总宽度panoramic_height = img_height * row_count # 整体总高度(左右侧高度一致)# 创建右侧检索结果区的背景画布(白色,RGB三通道,uint8类型)panoramic_image = np.full((panoramic_height, panoramic_width, 3), 255, dtype=np.uint8)# 创建左侧查询图像显示区的背景画布(白色,单列宽度)query_display_area = np.full((panoramic_height, img_width, 3), 255, dtype=np.uint8)# 处理查询图像:读取、格式转换、缩放、添加蓝色边框和文字标注query_pil = Image.open(query_image_path).convert("RGB") # 用PIL打开图像并转为RGB格式(避免Alpha通道干扰)query_cv = np.array(query_pil)[:, :, ::-1] # PIL图像是RGB顺序,转为OpenCV的BGR顺序resized_query = cv2.resize(query_cv, (img_width, img_height)) # 将查询图缩放到指定尺寸# 给查询图添加蓝色边框(10像素宽,BGR格式中(255,0,0)为蓝色)bordered_query = cv2.copyMakeBorder(resized_query, 10, 10, 10, 10, cv2.BORDER_CONSTANT, value=(255, 0, 0))# 将带边框的查询图放到左侧显示区的底部(row_count-1行开始,即最后一行)query_display_area[img_height * (row_count - 1):, :] = cv2.resize(bordered_query, (img_width, img_height))# 在左侧显示区添加“Query”文字标注(蓝色,字体大小1,线宽2)cv2.putText(query_display_area, "Query", (10, panoramic_height - 20), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 0, 0), 2)# 处理检索到的图像:循环读取、缩放、添加黑色边框和索引标注for i, img_path in enumerate(retrieved_images):# 计算当前图像在右侧结果区的行列位置(按row_count行/列网格排列)row, col = i // row_count, i % row_count# 计算当前图像在全景图中的左上角坐标start_row, start_col = row * img_height, col * img_width# 读取检索到的图像并处理格式retrieved_pil = Image.open(img_path).convert("RGB") # PIL打开并转RGBretrieved_cv = np.array(retrieved_pil)[:, :, ::-1] # RGB转BGR(适配OpenCV)# 缩放图像(预留4像素边框空间,所以尺寸比指定小4像素)resized_retrieved = cv2.resize(retrieved_cv, (img_width - 4, img_height - 4))# 给检索结果图添加黑色边框(2像素宽,BGR(0,0,0)为黑色)bordered_retrieved = cv2.copyMakeBorder(resized_retrieved, 2, 2, 2, 2, cv2.BORDER_CONSTANT, value=(0, 0, 0))# 将带边框的检索图放到右侧结果区的对应位置panoramic_image[start_row:start_row + img_height, start_col:start_col + img_width] = bordered_retrieved# 在检索结果图上添加索引号标注(红色,字体大小1,线宽2)cv2.putText(panoramic_image, str(i), (start_col + 10, start_row + 30), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), 2)# 将左侧查询区和右侧结果区横向拼接,返回全景图return np.hstack([query_display_area, panoramic_image])
创建 Collection
# 3. 初始化客户端:创建多模态编码器实例和Milvus向量数据库客户端,为后续数据处理和检索做准备
# 打印初始化提示信息,方便跟踪程序执行进度
print("--> 正在初始化编码器和Milvus客户端...")
# 实例化Encoder类(传入模型名称和权重路径),用于后续图像/图文组合的向量编码
encoder = Encoder(MODEL_NAME, MODEL_PATH)
# 实例化Milvus客户端(传入Milvus服务地址),用于与Milvus数据库交互(创建集合、插入数据、查询等)
milvus_client = MilvusClient(uri=MILVUS_URI)# 4. 创建 Milvus Collection:定义集合结构(字段、数据类型),并在Milvus中创建集合(类似数据库的表)
# 打印创建集合的提示信息
print(f"\n--> 正在创建 Collection '{COLLECTION_NAME}'")
# 检查指定名称的Collection是否已存在(避免重复创建导致冲突)
if milvus_client.has_collection(COLLECTION_NAME):# 若已存在,先删除该Collection(确保创建的是全新集合,避免旧数据干扰)milvus_client.drop_collection(COLLECTION_NAME)# 打印删除提示,告知用户旧集合已清理print(f"已删除已存在的 Collection: '{COLLECTION_NAME}'")# 查找指定数据目录下(dragon子目录)所有.png格式的图像文件,获取图像路径列表(后续用于计算向量维度和插入数据)
# os.path.join拼接目录路径,glob按通配符"*.png"匹配文件
image_list = glob(os.path.join(DATA_DIR, "dragon", "*.png"))
# 检查是否找到图像文件:若列表为空,抛出文件未找到异常(避免后续编码操作报错)
if not image_list:raise FileNotFoundError(f"在 {DATA_DIR}/dragon/ 中未找到任何 .png 图像。")
# 计算向量维度:通过编码第一张图像获取向量长度(Milvus的FLOAT_VECTOR字段需指定固定维度)
# encoder.encode_image对第一张图像编码,返回向量列表,len()获取维度值
dim = len(encoder.encode_image(image_list[0]))# 定义Collection的字段结构:指定每个字段的名称、数据类型、是否为主键等属性
fields = [# 主键字段:名称"id",数据类型INT64(64位整数),设为primary=True(主键唯一标识每条数据),auto_id=True(自动生成主键值,无需手动指定)FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, auto_id=True),# 向量字段:名称"vector",数据类型FLOAT_VECTOR(浮点型向量),dim=dim(向量维度,与编码结果一致)FieldSchema(name="vector", dtype=DataType.FLOAT_VECTOR, dim=dim),# 图像路径字段:名称"image_path",数据类型VARCHAR(字符串),max_length=512(最大长度限制,适配长路径)FieldSchema(name="image_path", dtype=DataType.VARCHAR, max_length=512),
]# 创建集合 Schema:将定义的fields列表和描述信息封装为CollectionSchema(类似数据库表的结构定义)
schema = CollectionSchema(fields, description="多模态图文检索")
# 打印Schema结构,方便用户确认字段定义是否正确
print("Schema 结构:")
print(schema)# 调用Milvus客户端的create_collection方法,在Milvus中创建集合
# 传入集合名称和Schema,完成集合创建(此时集合仅含结构,无数据)
milvus_client.create_collection(collection_name=COLLECTION_NAME, schema=schema)
# 打印创建成功提示
print(f"成功创建 Collection: '{COLLECTION_NAME}'")
# 打印Collection的详细描述信息(包括字段、索引、统计信息等),确认集合创建结果
print("Collection 结构:")
print(milvus_client.describe_collection(collection_name=COLLECTION_NAME))
输出结果
--> 正在创建 Collection 'multimodal_demo'Schema 结构:
{'auto_id': True, 'description': '多模态图文检索', 'fields': [{'name': 'id', 'description': '', 'type': <DataType.INT64: 5>, 'is_primary': True, 'auto_id': True}, {'name': 'vector', 'description': '', 'type': <DataType.FLOAT_VECTOR: 101>, 'params': {'dim': 768}}, {'name': 'image_path', 'description': '', 'type': <DataType.VARCHAR: 21>, 'params': {'max_length': 512}}], 'enable_dynamic_field': False
}成功创建 Collection: 'multimodal_demo'Collection 结构:
{'collection_name': 'multimodal_demo', 'auto_id': True, 'num_shards': 1, 'description': '多模态图文检索', 'fields': [{'field_id': 100, 'name': 'id', 'description': '', 'type': <DataType.INT64: 5>, 'params': {}, 'auto_id': True, 'is_primary': True}, {'field_id': 101, 'name': 'vector', 'description': '', 'type': <DataType.FLOAT_VECTOR: 101>, 'params': {'dim': 768}}, {'field_id': 102, 'name': 'image_path', 'description': '', 'type': <DataType.VARCHAR: 21>, 'params': {'max_length': 512}}], 'functions': [], 'aliases': [], 'collection_id': 459243798405253751, 'consistency_level': 2, 'properties': {}, 'num_partitions': 1, 'enable_dynamic_field': False, 'created_timestamp': 459249546649403396, 'update_timestamp': 459249546649403396
}
上面的输出详细展示了刚刚创建的 multimodal_demo Collection 的完整结构。其 Schema 包含了三个核心字段(Field):一个自增的 id 作为主键,一个 768 维的 vector 向量字段用于存储图像嵌入,以及一个 image_path 标量字段来记录原始图片路径
准备并插入数据
创建好 Collection 后,需要将数据填充进去。通过遍历指定目录下的所有图片,将它们逐一编码成向量,然后与图片路径一起组织成符合 Schema 结构的格式,最后批量插入到 Collection 中。
# 5. 准备并插入数据:将图像编码为向量后,批量插入到Milvus集合中
# 打印数据插入的提示信息,明确当前操作目标
print(f"\n--> 正在向 '{COLLECTION_NAME}' 插入数据")
# 初始化空列表,用于存储待插入Milvus的数据(每条数据含向量和对应的图像路径)
data_to_insert = []
# 遍历之前获取的图像路径列表,用tqdm显示编码进度(desc参数设置进度条描述文本)
for image_path in tqdm(image_list, desc="生成图像嵌入"):# 调用编码器的encode_image方法,将当前图像路径对应的图像编码为向量vector = encoder.encode_image(image_path)# 构造单条待插入数据(字典格式,键与Milvus集合的字段名对应),添加到数据列表中data_to_insert.append({"vector": vector, "image_path": image_path})# 检查待插入数据列表是否非空(避免空数据插入操作)
if data_to_insert:# 调用Milvus客户端的insert方法,将数据插入指定集合# 传入集合名称和待插入数据列表,返回插入结果(含插入成功数量等信息)result = milvus_client.insert(collection_name=COLLECTION_NAME, data=data_to_insert)# 打印插入结果,显示成功插入的数据条数(从result字典中提取insert_count字段值)print(f"成功插入 {result['insert_count']} 条数据。")
创建索引
为了实现快速检索,需要为向量字段创建索引。这里选择 HNSW 索引,它在召回率和查询性能之间有着很好的平衡。创建索引后,必须调用 load_collection 将集合加载到内存中才能进行搜索。
# 6. 创建索引:为Milvus集合的向量字段创建索引,加速后续相似性检索(无索引时检索效率极低)
# 打印创建索引的提示信息,明确当前操作对象
print(f"\n--> 正在为 '{COLLECTION_NAME}' 创建索引")
# 调用Milvus客户端的prepare_index_params方法,初始化索引参数配置对象(用于统一管理索引相关设置)
index_params = milvus_client.prepare_index_params()
# 为向量字段添加具体的索引配置(指定索引类型、距离度量方式及索引参数)
index_params.add_index(field_name="vector", # 要创建索引的字段名(必须是集合中定义的FLOAT_VECTOR类型字段)index_type="HNSW", # 索引类型:HNSW(Hierarchical Navigable Small Worlds),适用于高维向量快速相似性检索metric_type="COSINE", # 距离/相似度度量方式:COSINE(余弦相似度),常用于文本、图像等向量的相似性计算params={"M": 16, "efConstruction": 256} # HNSW索引的核心参数:# - M:每个节点的邻居数量(16为常用值,值越大索引精度越高但构建/存储成本越高)# - efConstruction:索引构建时的探索深度(256为常用值,值越大构建越慢但索引质量越高)
)
# 调用Milvus客户端的create_index方法,根据配置为指定集合创建索引
milvus_client.create_index(collection_name=COLLECTION_NAME, index_params=index_params)
# 打印索引创建成功的提示,明确索引类型和目标字段
print("成功为向量字段创建 HNSW 索引。")
# 打印索引的详细信息(如索引类型、参数、创建时间等),方便验证索引配置是否正确
print("索引详情:")
print(milvus_client.describe_index(collection_name=COLLECTION_NAME, index_name="vector"))
# 将集合加载到Milvus内存中(Milvus检索时需先加载集合到内存,否则无法执行查询)
milvus_client.load_collection(collection_name=COLLECTION_NAME)
# 打印集合加载成功的提示,告知后续可执行检索操作
print("已加载 Collection 到内存中。")
输出结果
--> 正在为 'multimodal_demo' 创建索引
成功为向量字段创建 HNSW 索引。
索引详情:
{'M': '16', 'efConstruction': '256', 'metric_type': 'COSINE', 'index_type': 'HNSW', 'field_name': 'vector', 'index_name': 'vector', 'total_rows': 0, 'indexed_rows': 0, 'pending_index_rows': 0, 'state': 'Finished'}
已加载 Collection 到内存中。
可以看出,索引创建成功,在 vector 字段上成功创建了 HNSW 索引,并使用 COSINE 作为距离度量。M: ‘16’ 和 efConstruction: ‘256’ 是 HNSW 索引的两个关键参数,分别控制着图中每个节点的最大连接数和索引构建时的搜索范围,这些参数直接影响检索的性能和准确性。state: ‘Finished’ 状态表明索引已成功构建。
执行多模态检索
这里通过定义一个包含图片和文本的组合查询,将其编码为查询向量,然后调用 search 方法在 Milvus 中执行近似最近邻搜索。
# 7. 执行多模态检索:结合查询图像和查询文本生成多模态向量,在Milvus集合中搜索相似结果
# 打印检索操作提示,明确当前操作的目标集合
print(f"\n--> 正在 '{COLLECTION_NAME}' 中执行检索")# 定义多模态查询的输入:查询图像路径和查询文本(图文结合提升检索精准度)
# os.path.join拼接数据目录、子目录和图像文件名,获取查询图像的完整本地路径
query_image_path = os.path.join(DATA_DIR, "dragon", "dragon01.png")
# 定义查询文本(与图像内容关联,此处为"一条龙",用于补充图像的语义信息)
query_text = "一条龙"# 生成多模态查询向量:调用编码器的encode_query方法,同时传入图像路径和文本
# 该方法会融合图像特征和文本特征,输出一个统一的多模态向量(用于后续相似性匹配)
query_vector = encoder.encode_query(image_path=query_image_path, text=query_text)# 调用Milvus客户端的search方法执行相似性检索,返回匹配结果
# 注意:search方法返回的是嵌套列表(外层对应批量查询的每个query,此处仅1个query,故取[0])
search_results = milvus_client.search(collection_name=COLLECTION_NAME, # 检索的目标集合名称(必须已加载到内存)data=[query_vector], # 待检索的向量列表(批量检索可传多个向量,此处仅1个多模态向量)output_fields=["image_path"], # 检索结果中需要返回的非向量字段(此处需获取匹配图像的路径,用于后续可视化)limit=5, # 检索结果返回的Top-K数量(此处取前5个最相似的结果)search_params={"metric_type": "COSINE", "params": {"ef": 128}} # 检索参数配置:# - metric_type:与索引创建时一致,用COSINE(余弦相似度)计算匹配度# - ef:检索阶段的探索深度(128为常用值,值越大检索精度越高但速度越慢)
)[0] # 取索引0是因为data参数传入的是单向量列表,返回结果外层列表仅1个元素# 初始化空列表,用于存储检索结果中的图像路径(后续用于可视化展示)
retrieved_images = []# 打印检索结果的标题,提示后续为匹配详情
print("检索结果:")
# 遍历检索结果(search_results为Top-K匹配列表,每个元素是一个匹配项)
for i, hit in enumerate(search_results):# 打印每个匹配项的详细信息:排名、匹配实体ID、余弦距离(距离越小相似度越高)、图像路径# hit['id']:匹配实体的主键ID;hit['distance']:与查询向量的余弦距离;hit['entity']['image_path']:返回的图像路径字段值print(f" Top {i+1}: ID={hit['id']}, 距离={hit['distance']:.4f}, 路径='{hit['entity']['image_path']}'")# 将当前匹配项的图像路径添加到retrieved_images列表,供后续可视化使用retrieved_images.append(hit['entity']['image_path'])
输出结果
--> 正在 'multimodal_demo' 中执行检索
检索结果:Top 1: ID=459243798403756667, 距离=0.9411, 路径='../../data/C3\dragon\dragon01.png'Top 2: ID=459243798403756668, 距离=0.5818, 路径='../../data/C3\dragon\dragon02.png'Top 3: ID=459243798403756671, 距离=0.5731, 路径='../../data/C3\dragon\dragon05.png'Top 4: ID=459243798403756670, 距离=0.4894, 路径='../../data/C3\dragon\dragon04.png'Top 5: ID=459243798403756669, 距离=0.4100, 路径='../../data/C3\dragon\dragon03.png'
这段输出展示了与图文组合查询最相似的5个实体 (Entity)。distance 字段代表了余弦相似度,值越接近 1 表示越相似。可以看到,Top 1 结果正是查询图片本身,其相似度得分最高(0.9411),这说明了检索的有效性。其余结果也都是龙的图片,并按相似度从高到低精确排列。
可视化与清理
最后,将检索到的图片路径用于可视化,生成一张直观的结果对比图。在完成所有操作后,应该释放 Milvus 中的资源,包括从内存中卸载 Collection 和删除整个 Collection。
# 8. 可视化与清理:将检索结果生成为可视化图像并保存,同时释放Milvus资源避免内存占用
# 打印操作提示,明确当前阶段为结果可视化和资源清理
print(f"\n--> 正在可视化结果并清理资源")# 检查检索结果列表是否为空(避免无结果时执行无效可视化操作)
if not retrieved_images:# 若检索结果为空,打印提示信息print("没有检索到任何图像。")
else:# 若有检索结果,调用之前定义的visualize_results函数生成全景可视化图像# 传入查询图像路径和检索到的图像路径列表,返回拼接好的全景图(numpy数组格式)panoramic_image = visualize_results(query_image_path, retrieved_images)# 定义可视化结果图像的保存路径:拼接数据目录和文件名"search_result.png"combined_image_path = os.path.join(DATA_DIR, "search_result.png")# 使用OpenCV的imwrite方法将全景图保存到指定路径cv2.imwrite(combined_image_path, panoramic_image)# 打印保存成功的提示,告知用户结果图像的具体路径print(f"结果图像已保存到: {combined_image_path}")# 使用PIL的Image.open打开保存的图像,并调用show()方法弹出窗口显示图像(需系统支持图像预览)Image.open(combined_image_path).show()# 释放Milvus集合占用的内存:调用release_collection方法,将集合从内存卸载(避免长期占用内存资源)
milvus_client.release_collection(collection_name=COLLECTION_NAME)
# 打印释放成功的提示,告知用户集合已从内存中移除
print(f"已从内存中释放 Collection: '{COLLECTION_NAME}'")# 删除Milvus中的集合:调用drop_collection方法,彻底删除集合(包括数据和索引,适用于测试或临时场景)
milvus_client.drop_collection(COLLECTION_NAME)
# 打印删除成功的提示,告知用户集合已被彻底清理
print(f"已删除 Collection: '{COLLECTION_NAME}'")
