华中科大联手小米推出ReCogDrive:自动驾驶迎来“认知革命”!
1.【前言】
在开放道路中实现安全、平稳、泛化的自动驾驶,是智能交通领域的“圣杯”。尽管近年来 端到端自动驾驶(End-to-End Autonomous Driving, E2E-AD) 框架(如 UniAD、VAD)在 NuScenes 等基准中展现出优异表现,但它们在真实世界的 长尾场景(复杂路口、罕见交通模式、极端天气)中仍然表现不佳:要么轨迹预测失真,要么决策鲁棒性不足。
与此同时,研究者们开始尝试将 视觉-语言模型(Vision-Language Models, VLMs) 引入自动驾驶,希望借助其强大的知识库和泛化能力来增强驾驶决策。但现实问题在于:
-
VLMs 训练于互联网数据,缺乏驾驶领域知识;
-
离散的文本输出无法直接映射到车辆需要的连续控制空间;
-
大多数方法依赖模仿学习,难以摆脱“次优解”的困境。
为解决这些瓶颈,来自 华中科技大学 & 小米汽车 的研究团队提出了 ReCogDrive ——首个融合视觉-语言推理与强化学习优化的开源认知型自动驾驶框架。它结合了 VLM 的认知泛化能力、扩散模型的轨迹生成能力 与 模拟器辅助的强化学习优化,在 NAVSIM 基准测试 上实现 PDMS 90.5,比现有纯视觉方案提升 6.5 分,树立了新的 SOTA 标杆。
点击阅读原文,获取更多前沿咨询
论文基本信息

论文题目: ReCogDrive: A Reinforced Cognitive Framework for End-to-End Autonomous Driving
论文链接:https://arxiv.org/abs/2506.08052
代码链接: https://github.com/xiaomi-research/recogdrive
高质量驾驶QA数据集链接: https://huggingface.co/datasets/owl10/ReCogDrive_Pretraining
模型链接:https://huggingface.co/owl10/ReCogDrive
2.【创新点概述】
-
可扩展的认知预训练
ReCogDrive 构建了一个 310 万条高质量驾驶问答对 的训练语料,这是目前规模最大的驾驶认知数据集。通过融合 12 个开源驾驶数据集与自动标注流水线生成的数据,模型学会了对驾驶场景的语义理解与解释能力。 -
语言到动作的扩散式桥梁
不同于直接让 VLM 输出轨迹,ReCogDrive 在 VLM 的高层次特征与车辆的连续控制空间之间,引入了一个 扩散式轨迹规划器。它逐步从噪声中“去噪”出平滑轨迹,解决了语言空间与动作空间的不匹配问题。研究团队采用 LightningDiT 架构,结合 RMSNorm、RoPE 和 SwiGLU-FFN 等前沿技术,使轨迹生成更稳定、更高效。 -
模拟器辅助的强化学习
为避免模仿学习的“平均轨迹陷阱”,ReCogDrive 创新性地利用 NAVSIM 仿真器 作为奖励反馈,基于碰撞率、舒适度等指标进行强化微调。这样,模型能在探索中逐步优化策略,生成更安全、更类人的驾驶行为。
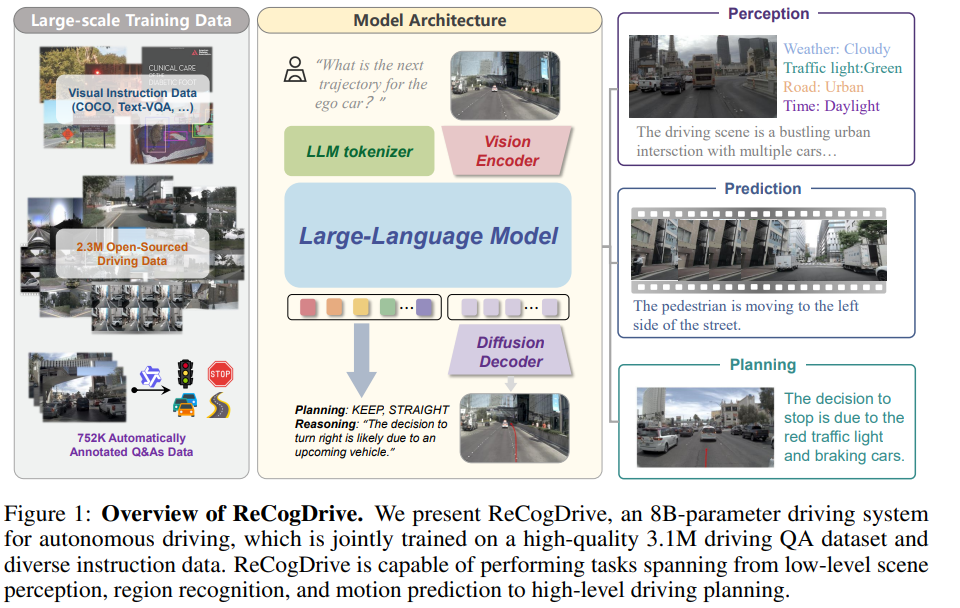
3.【整体架构流程】
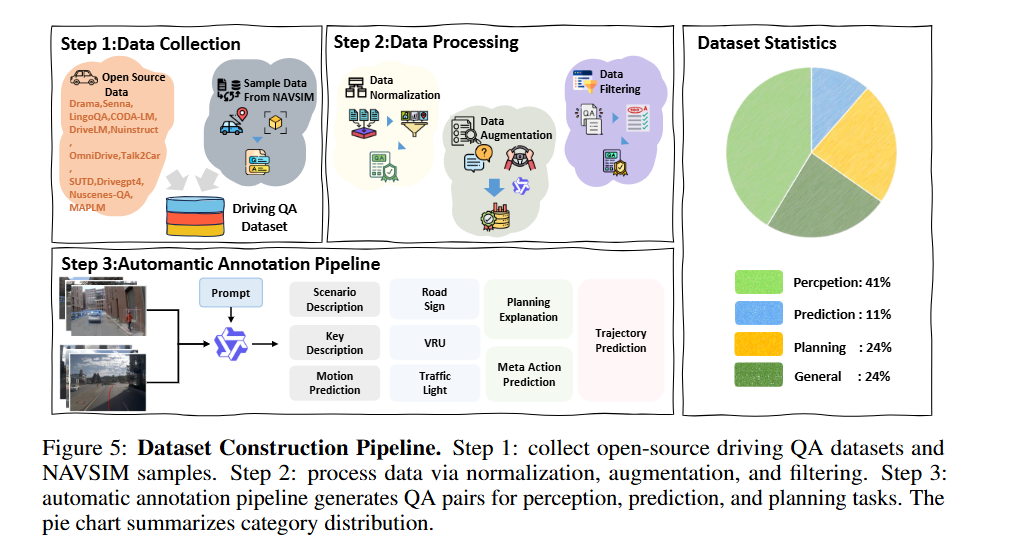
由于通用多模态大模型大多在互联网的图文数据上完成预训练,缺乏与驾驶相关的知识与经验,直接应用于驾驶轨迹预测往往存在困难。为此,ReCogDrive 首先构建了一个规模高达 310 万条的驾驶问答数据集,让模型能够在真实的交通语境中习得认知能力。其中,研究团队从 12 个开源驾驶数据集收集数据,经过归一化、统一格式、重新标注和质量筛选,最终保留下 230 万条高质量问答对。同时,团队还搭建了一个自动标注流水线,结合 Qwen2.5-VL 与数据集标签,自动生成了涵盖场景描述、关键物体识别和规划解释等任务的问答数据,并引入 LLaVA 指令调优数据,以确保模型在具备驾驶认知的同时,依然保持良好的指令遵循能力。
在模型架构上,ReCogDrive 采用了 InternVL3-8B 作为基础模型。该模型以“原生多模态预训练”范式为核心,在多个基准测试中表现出色。每张图像会被划分为多个图块并配合缩略图输入 InternViT 编码器,经 pixel shuffle 压缩后形成紧凑的视觉 Token,再与文本 Token 融合输入大语言模型。经过在这 310 万条混合数据上的微调,ReCogDrive 的多模态大模型不仅能够生成未来的驾驶轨迹,还能同时给出场景描述和规划解释,从而在轨迹预测之外,提供更加全面和可解释的驾驶认知能力。
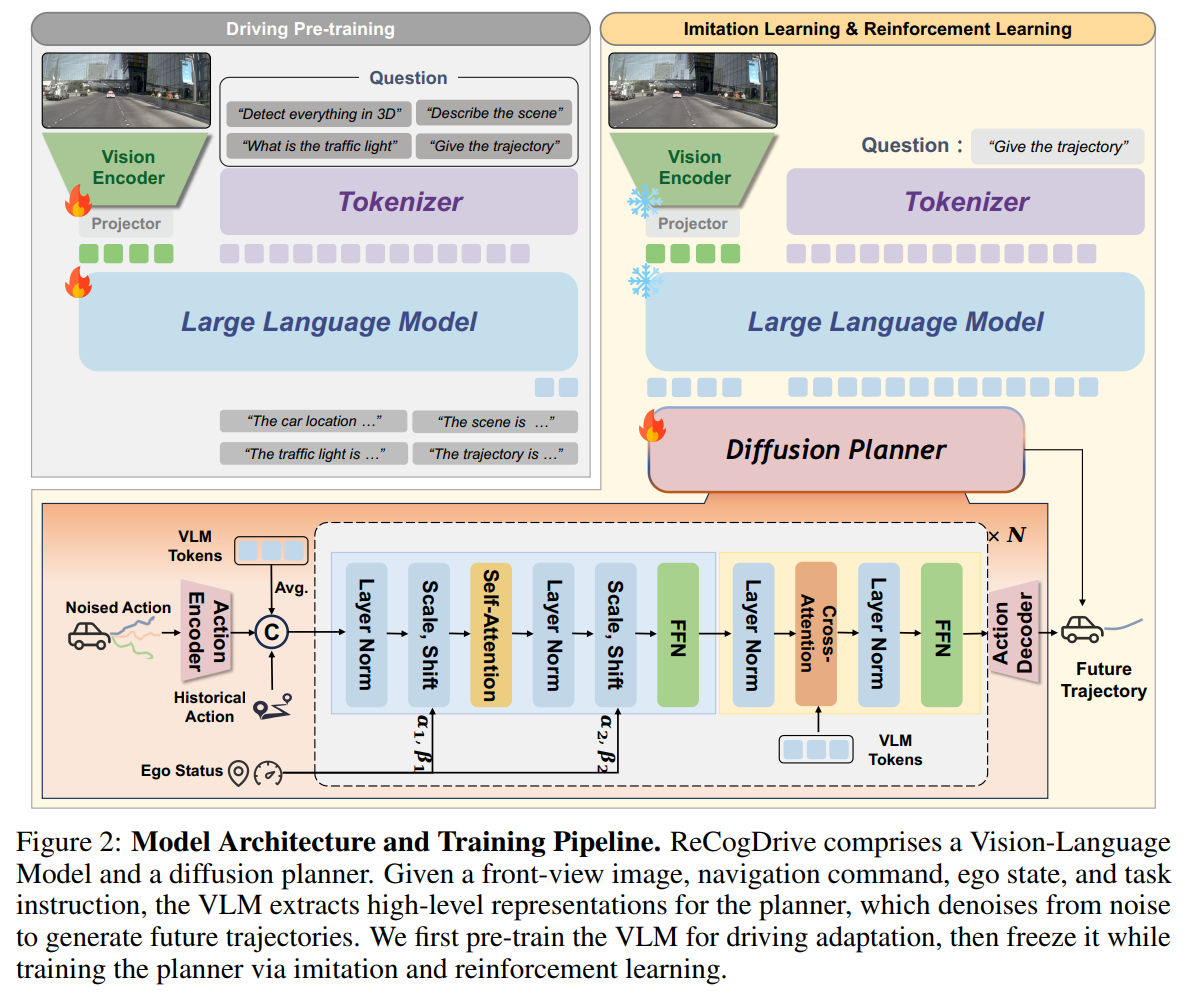
虽然视觉语言大模型可以直接以自回归的方式生成轨迹,但由于动作空间与语言空间之间存在巨大的差异,这种方法在自动驾驶中有天然的限制。一方面,多模态大模型并不擅长数值级别的精确预测;另一方面,它们偶尔还会出现“幻觉”,生成与现实不符的结果,这在安全要求极高的驾驶场景中是难以接受的。
为了解决这一问题,ReCogDrive 借鉴了具身智能领域 π0 和 GR00T-N1 等工作的思路,引入了 基于扩散模型的轨迹规划器,作为语言与动作之间的桥梁。该规划器从高维语义特征空间出发,将噪声轨迹逐步解码为平滑、稳定的驾驶轨迹。在这一过程中,它会同时考虑三类关键信息:自车的历史轨迹、视觉语言模型生成的高层语义特征,以及驾驶环境中的全局上下文。通过对这些信息的整合,轨迹规划器能够更好地理解复杂交通场景,并输出符合实际驾驶规律的连续轨迹。
在网络结构上,ReCogDrive 使用了改进版的 LightningDiT 模块,它通过 AdaLayerNorm 显式引入自车状态和时间因素,再结合交叉注意力机制吸收视觉语言模型的输出特征。最终,轨迹解码器将高维表示转化为连续的轨迹点,使得生成的驾驶轨迹不仅平滑自然,而且兼具语义一致性和物理合理性。训练过程中,团队采用了扩散式的去噪优化策略,使模型能够逐步提升轨迹的质量和稳定性。
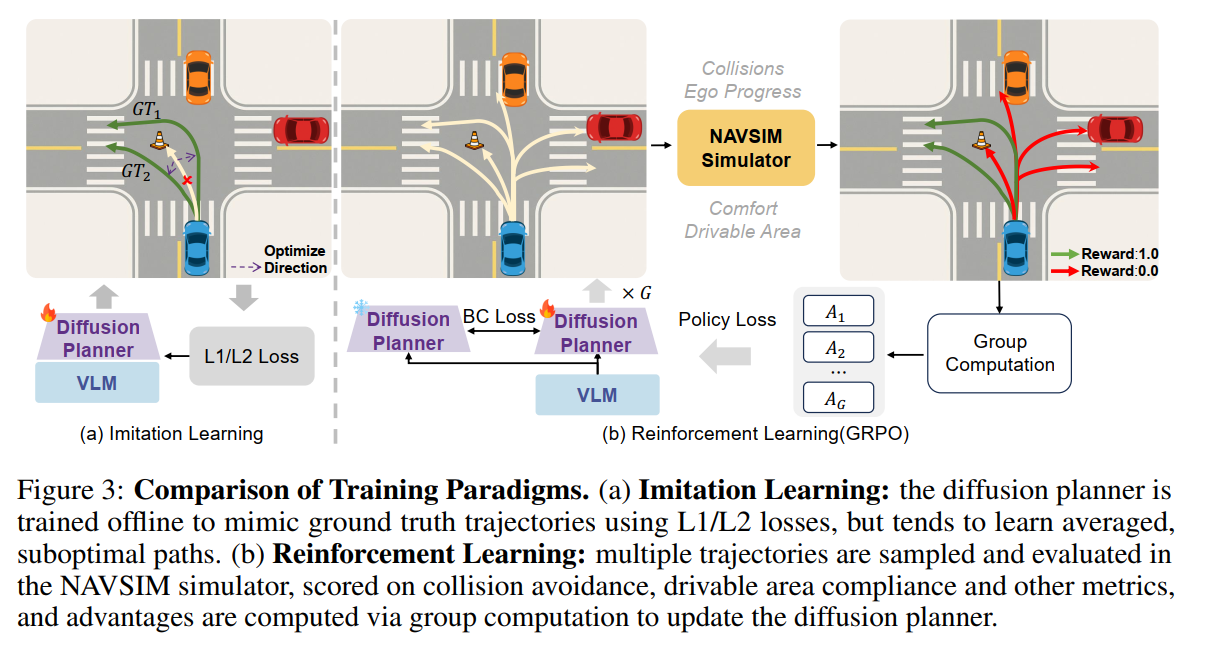
仅依赖模仿学习进行训练存在局限性,因为同一个场景可能存在很多条不相同的专家轨迹,导致优化到次优的轨迹,如图(a)所示,在一个交叉路口转弯场景中,存在多条专家轨迹,模型倾向于学习平均轨迹以实现全局最优,最终可能导致错误或不安全的行驶。
更符合人类学习驾驶的方式是让模型在一个驾驶环境中自主驾驶,模拟真实世界的学习过程,但构建具有交互式的真实场景闭环仿真器非常困难,因此ReCogDrive使用 NAVSIM 非交互式的仿真器评估碰撞、舒适度等指标,来进行强化学习训练。 强化学习训练过程如下:
扩散策略 πθ\pi_\thetaπθ 可视为从高斯噪声逐步去噪生成动作序列的马尔可夫决策过程,具体地,ReCogDrive首先采样 GGG 条轨迹,获取其扩散去噪链:
x=(xT,xT−1,…,x0),\mathbf{x} = \bigl(x_T,\,x_{T-1},\,\dots,\,x_0\bigr), x=(xT,xT−1,…,x0),
其中 TTT 是去噪步骤总数,对于该链:
xT∼N(0,I),xt−1∼πθ(xt−1∣xt),t=T,T−1,…,1.x_T \sim \mathcal{N}(0, \mathbf{I}), \qquad x_{t-1} \sim \pi_\theta\bigl(x_{t-1}\mid x_t\bigr), \quad t = T, T-1, \dots, 1. xT∼N(0,I),xt−1∼πθ(xt−1∣xt),t=T,T−1,…,1.
这些轨迹在 NAVSIM 仿真器中执行,仿真器根据碰撞情况、行驶区域合规性及驾驶舒适度给出驾驶评分(PDMS),作为奖励 rir_iri。随后计算组内标准化优势:
A^i=ri−mean(r1..G)var(r1..G),i=1,…,G.\hat A_{i} \;=\; \frac{r_i - \mathrm{mean}\bigl(r_{1..G}\bigr)}{\sqrt{\mathrm{var}\bigl(r_{1..G}\bigr)}}, \quad i=1,\dots,G. A^i=var(r1..G)ri−mean(r1..G),i=1,…,G.
扩散链中每一步的条件策略符合高斯分布:
πθ(xt−1∣xt)=N(xt−1;μθ(xt,t),σt2I),\pi_\theta\bigl(x_{t-1}\mid x_t\bigr) = \mathcal{N}\!\Bigl(x_{t-1};\,\mu_\theta(x_t,t),\,\sigma_t^2 I\Bigr), πθ(xt−1∣xt)=N(xt−1;μθ(xt,t),σt2I),
其中 μθ(xt,t)\mu_\theta(x_t,t)μθ(xt,t) 是模型预测的均值,σt2I\sigma_t^2 Iσt2I 是固定协方差。
因此,完整链条 x0:T\mathbf{x}_{0:T}x0:T 在策略 πθ\pi_\thetaπθ 下的对数策略概率为:
logπθ(x0:T)=∑t=1Tlogπθ(xt−1∣xt).\log \pi_\theta\bigl(\mathbf{x}_{0:T}\bigr) = \sum_{t=1}^T \log \pi_\theta\bigl(x_{t-1}\mid x_t\bigr). logπθ(x0:T)=t=1∑Tlogπθ(xt−1∣xt).
最后,ReCogDrive参考 REINFORCE、RLOO、GRPO 等算法计算策略损失,同时引入行为克隆损失以防止探索过程中模型崩溃。
L=−1G∑i=1G1T∑t=1Tγt−1logπθ(xt−1(i)∣xt(i))A^i⏟LRL−λ1G∑i=1G1T∑t=1Tlogπθ(x~t−1(i)∣x~t(i))⏟LBC,L \;=\; \underbrace{-\frac{1}{G}\sum_{i=1}^G\frac{1}{T}\sum_{t=1}^T \gamma^{\,t-1}\,\log \pi_\theta\bigl(x_{t-1}^{(i)}\mid x_t^{(i)}\bigr)\,\hat A_{i}}_{L_{\mathrm{RL}}} \;-\; \underbrace{\lambda\;\frac{1}{G}\sum_{i=1}^G\frac{1}{T}\sum_{t=1}^T \log \pi_\theta\bigl(\tilde x_{t-1}^{(i)}\mid \tilde x_t^{(i)}\bigr)}_{ L_{\mathrm{BC}}}, L=LRL−G1i=1∑GT1t=1∑Tγt−1logπθ(xt−1(i)∣xt(i))A^i−LBCλG1i=1∑GT1t=1∑Tlogπθ(x~t−1(i)∣x~t(i)),
其中,γ\gammaγ 是用于缓解去噪初期不稳定性的折扣因子,λ\lambdaλ 是行为克隆损失的权重,x~t−1,x~t\tilde x_{t-1}, \tilde x_tx~t−1,x~t 是从参考策略 πref\pi_{\mathrm{ref}}πref 中采样的值,折扣因子和行为克隆损失权重对于模型训练效果都非常重要。
4.【实验结果】
实验在 NAVSIM 基准 上展开,评价指标包括:PDMS 分数、碰撞率、驾驶舒适度、效率等。
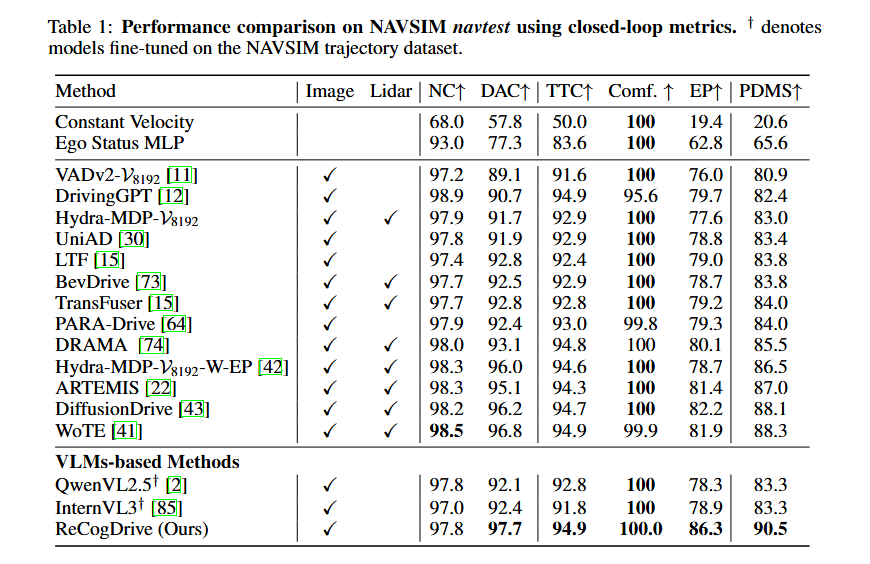
表1 展示了ReCogDrive的方法与现有方法在 NAVSIM 数据集上的比较结果。ReCogDrive 实现了 90.5 的 PDMS,超过了 DiffusionDrive 等 SOTA 模型。而且,ReCogDrive仅使用前视相机数据,ReCogDrive 依然比同时使用相机和激光雷达输入的 DiffusionDrive 和 WoTE 分别高出 2.4 和 2.2 的 PDMS。此外,相比ReCogDrive复现的 InternVL3†^{\dagger}† 和 QwenVL2.5†^{\dagger}† 这两个直接在 NAVSIM 轨迹上训练的基线方法,ReCogDrive 的 PDMS 提高了 7.2,展示了ReCogDrive方法的有效性。同时,它还比纯视觉方案的 SOTA 模型 PARA-Drive 高出 6.5 的 PDMS。
-
整体性能:ReCogDrive 在 PDMS 上达到 90.5,显著超越现有视觉 E2E 方法(提升 6.5 分)。
-
复杂场景下的稳健性:ReCogDrive 的碰撞率显著下降,轨迹更接近人类驾驶风格。
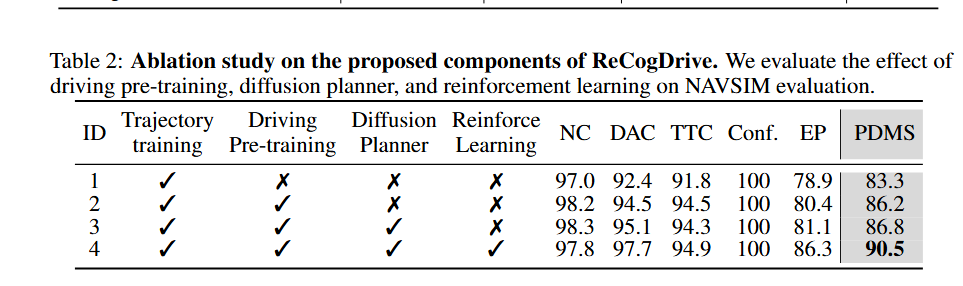
表2 展示了ReCogDrive方法中各个关键组件的消融实验结果,当仅在NAVSIM轨迹数据上训练时,模型的PDMS为83.3,在此基础上,结合ReCogDrive的大规模驾驶问答数据对视觉语言大模型进行驾驶场景适应后,PDMS提高了2.9,引入扩散模型规划器以实现连续轨迹预测,进一步提升了0.6的PDMS,最后,通过引入模拟器辅助的强化学习,PDMS提升至90.5,增加了3.7,验证了ReCogDrive强化学习在提升驾驶安全性方面的有效性。
如图所示,可视化展示了ReCogDrive在 NAVSIM 上的感知与规划的能力。除了生成平滑的轨迹预测外,ReCogDrive 还能输出描述性的场景总结和高层次的驾驶指令。它能够准确识别关键物体,如出租车和红绿灯等。
5.【总结与展望】
ReCogDrive 提出了一个全新的范式:将 视觉-语言推理、扩散式轨迹生成 和 强化学习优化 有机结合,让自动驾驶模型具备认知能力和类人决策模式。它不仅在指标上刷新了记录,更为未来 认知增强型自动驾驶 提供了可行方案。
展望未来,研究团队计划在以下几个方向继续拓展:
-
更大规模的多模态驾驶环境:验证 ReCogDrive 在视觉-雷达融合模态的表现。
-
更细粒度的奖励信号:通过更精确的推理与反馈,让模型具备更强的自适应与纠错能力。
-
与世界模型结合:通过显式建模世界动态,进一步提升长时序规划与泛化推理能力。
ReCogDrive 在视觉-雷达融合模态的表现。
-
更细粒度的奖励信号:通过更精确的推理与反馈,让模型具备更强的自适应与纠错能力。
-
与世界模型结合:通过显式建模世界动态,进一步提升长时序规划与泛化推理能力。
这一成果表明:未来的自动驾驶系统,不仅仅是“模仿司机”,而是真正具备 认知推理、探索优化与自主学习 的智能体。