【SQL优化案例】SQL执行频率问题与优化效果预期
案例一:SQL执行频率太高 - 业务逻辑
1. 问题 SQL
有三个sql执行次数太高,8M的表一天能有 110TB 的逻辑读,猜测应该在一个业务逻辑
涉及表:JUDGE_TASK (8M)、JUDGE_TASK_HIS (归档表,52M)
status 字段:0-未处理,1-处理成功,2-处理中,9-处理失败
SQL 及执行情况:
1)85m3gxkjzaqkt
SELECT INST_ID,DTYPE,STATUS,NODEID,ERROR_MSG,CREATEDATE,EXECUTEDATE FROM JUDGE_TASK WHERE STATUS = '0' AND ROWNUM <= 500 ORDER BY CREATEDATE;- 业务逻辑:查询 JUDGE_TASK 任务表 中还 未处理 的任务,返回500行按创建时间排序
- 执行频率:每30分钟执行 126,508 次,≈ 每秒 70 次,早晚都是 TOP SQL
- 平均逻辑读:1000 块次,一天产生逻辑读:≈ 58.7 亿块次 ≈ 43.73 TB
2)dnbf276hzw04k
INSERT INTO JUDGE_TASK_HIS(INST_ID,DTYPE,STATUS,NODEID,ERRMSG,CREATEDATE,EXECUTEDATE) SELECT INST_ID,DTYPE,STATUS,NODEID,ERROR_MSG,CREATEDATE,EXECUTEDATE FROM JUDGE_TASK WHERE STATUS='1' OR STATUS='9';- 业务逻辑: 将
JUDGE_TASK任务 处理成功 和 处理失败 的记录插入到JUDGE_TASK_HIS表(归档) - 执行频率:每30分钟执行 126,599 次,≈ 每秒 70 次,早晚都是 TOP SQL
- 平均逻辑读:1000 块次,一天产生逻辑读:≈ 58.7 亿块次 ≈ 43.73 TB
3)cyypmad5n2b1m
DELETE FROM JUDGE_TASK WHERE STATUS='1' OR STATUS='9';- 业务逻辑:删除已处理任务(成功+失败,已归档)
- 执行频率:每30分钟执行 125,046 次,≈ 每秒 70 次
- 平均逻辑读:1000 块次,一天产生逻辑读:≈ 37.18 亿块次 ≈ 27.7 TB
每个月只处理几千条任务,但是三条 SQL 加起来,单表每天逻辑读 110TB+,远超正常业务规模。并且JUDGE_TASK 15天仅有 60条 insert,每天需要执行六百万次,查询/归档/删除过于频繁,属于 业务逻辑设计不合理。
SQL> select status,count(*) from PANDA.JUDGE_TASK group by status order by count(*) desc;no rows selectedSQL> select * from PANDA.JUDGE_TASK;no rows selectedSQL> @seg PANDA.JUDGE_TASKSEG_MB OWNER SEGMENT_NAME SEG_PART_NAME SEGMENT_TYPE SEG_TABLESPACE_NAME BLOCKS HDRFIL HDRBLK
---------- -------------------- ------------------------------ ------------------------------ -------------------- ------------------------------ ---------- ---------- ----------8 PANDA JUDGE_TASK TABLE DATA999 1024 544 138560952 PANDA JUDGE_TASK_HIS TABLE DATA999 6656 544 18745692 rows selected.-- 历史记录
SQL> select count(*) from PANDA.JUDGE_TASK_HIS;COUNT(*)
----------667816
-- 估算每月任务量
SELECT TO_CHAR(TRUNC(EXECUTEDATE, 'MM'), 'YYYY-MM') AS month,COUNT(*) AS cntFROM PANDA.JUDGE_TASKGROUP BY TRUNC(EXECUTEDATE, 'MM')ORDER BY month;MONTH CNT
1 2018-09 541
2 2018-10 1417
3 2018-11 7414
4 2018-12 5875
5 2019-01 4118
......
74 2024-10 5059
75 2024-11 6235
76 2024-12 8751
77 2025-01 10422
78 2025-02 10459
79 2025-03 1096
80 2025-04 2199
81 2025-05 3490
82 2025-06 4910
83 2025-07 2480-- 根据 sql_id 估算一天产生的逻辑读
SELECT AVG(BUFFER_GETS) * 24 / 10 ,ROUND((AVG(BUFFER_GETS) * 24 / 10 * 8192)/ POWER(1024, 4), 2 ) AS LOGICAL_READ_TB_24H
FROM DBMT.GETS_STAT_HIST WHERESNAP_TIME <= TO_DATE('20250723', 'yyyymmdd')--AND INSTANCE_NUMBER = 1AND sql_id = '85m3gxkjzaqkt';PLAN_TABLE_OUTPUT
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
SQL_ID dnbf276hzw04k, child number 0
-------------------------------------
INSERT INTO JUDGE_TASK_HIS(INST_ID,DTYPE,STATUS,NODEID,E
RRMSG,CREATEDATE,EXECUTEDATE) SELECT
INST_ID,DTYPE,STATUS,NODEID,ERROR_MSG,CREATEDATE,EXECUTEDATE FROM
JUDGE_TASK WHERE STATUS='1' OR STATUS='9'Plan hash value: 3244728187-----------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------------------------------
| 0 | INSERT STATEMENT | | | | 223 (100)| |
| 1 | LOAD TABLE CONVENTIONAL | JUDGE_TASK_HIS | | | | |
|* 2 | TABLE ACCESS FULL | JUDGE_TASK | 822 | 183K| 223 (1)| 00:00:01 |
-----------------------------------------------------------------------------------------------------Predicate Information (identified by operation id):
---------------------------------------------------2 - filter(("STATUS"='1' OR "STATUS"='9'))22 rows selected.-- 索引信息
TABLE TABLE Index COLUMN Col
OWNER NAME Name UCPTDVS NAME Pos DESC
--------------- ------------- -------------------------- ------- ------------------------- ---- ----
PANDA JUDGE_TASK IDX_INST_ID_STATUS NNNNNVY INST_ID 1 ASCNNNNNVY STATUS 2 ASCJUDGE_TASK_HIS IDX_INST_ID_STATUS_HIS NNNNNVY INST_ID 1 ASCNNNNNVY STATUS 2 ASCPLAN GET DISK WRITE ROWS ROWS USER_IO(MS) ELA(MS) CPU(MS) CLUSTER(MS) PLSQL
END_TI I NAME HASH VALUE EXEC PRE EXEC PRE EXEC PER EXEC ROW_P PRE EXEC PRE FETCH PER EXEC PRE EXEC PRE EXEC PER EXEC PER EXEC
------ - --------------- ------------- ---------- ------------ -------- -------- ----- ----------- --------- ----------- --------------- --------------- ----------- --------
26 11 1 PANDA 3244728187 11.W 1,009 0 0 0 0 0 0 2,230 1,410 0 0
26 11 1 PANDA 3244728187 11.W 1,009 0 0 0 0 0 0 2,237 1,413 0 0
26 12 1 PANDA 3244728187 12.W 1,009 0 0 0 0 0 0 2,164 1,328 0 0
26 12 1 PANDA 3244728187 12.W 1,009 0 0 0 0 0 0 2,155 1,335 0 0
26 13 1 PANDA 3244728187 12.W 1,009 0 0 0 0 0 0 1,961 1,118 0 0
26 13 1 PANDA 3244728187 12.W 1,009 0 0 0 0 0 0 2,136 1,317 0 0
26 14 1 PANDA 3244728187 12.W 1,009 0 0 0 0 0 0 2,055 1,226 0 0
26 14 1 PANDA 3244728187 12.W 1,009 0 0 0 0 0 0 2,095 1,252 0 0
26 15 1 PANDA 3244728187 12.W 1,009 0 0 0 0 0 0 2,072 1,228 0 0
26 15 1 PANDA 3244728187 11.W 1,009 0 0 0 0 0 0 2,220 1,397 0 0
......2. 优化实施
(1)业务逻辑优化(首选方案)
- 降低执行频率:建议 30s~1min 执行一次任务处理或者重构一下将相关SQL模块封装出去,而不是毫秒级频繁执行。
- 合理批量处理:判断任务优先级,如果不要求实时,可以批量归档/删除,而非频繁小批量。
猜测业务逻辑如下:
检查status='0'是否有任务未处理-> 处理任务 -> 处理成功和失败的(STATUS='1' OR STATUS='9')任务归档在JUDGE_TASK_HIS->删除JUDGE_TASK任务记录(STATUS='1' OR STATUS='9')
(2)数据库层面优化(预备方案)
- 在
STATUS字段建立索引(或组合索引):
CREATE INDEX PANDA.JUDGE_TASK_status ON PANDA.JUDGE_TASK(status);访问路径优化,将目前执行计划 TABLE ACCESS FULL,建索引后预期转为 INDEX RANGE SCAN,逻辑读可由 ~658 降至几十。
3. 优化效果(预期)
很简单的一个业务每天能有110TB的逻辑读,全库每天才产生1500TB左右。但生产上还未优化,该业务不属于核心,在一个没见过的用户下,业务还在定位,预期效果逻辑读是从 110TB+/天 → <1TB/天。
案例二:SQL执行频率太高 - 4M 表进AWR TOP SQL
1. 问题 SQL
表 PANDA.ZONE_LIST 仅 13 行数据,核心表,频繁访问。每分钟执行9122次,每次执行0.17ms,逻辑读70块次,一天概产生读13.18TB数据。
SELECT T.ZONE FROM ZONE_LIST T WHERE T.PARTITION = :1;-- 测试
SQL> SELECT T.ZONE FROM ZONE_LIST T WHERE T.PARTITION = 'G';Elapsed: 00:00:00.00Execution Plan
----------------------------------------------------------
Plan hash value: 3167746917---------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 6 | 28 (0)| 00:00:01 |
|* 1 | TABLE ACCESS FULL| ZONE_LIST | 1 | 6 | 28 (0)| 00:00:01 |
---------------------------------------------------------------------------------------Predicate Information (identified by operation id):
---------------------------------------------------1 - filter("T"."PARTITION"='G')Statistics
----------------------------------------------------------0 recursive calls0 db block gets70 consistent gets0 physical reads0 redo size549 bytes sent via SQL*Net to client421 bytes received via SQL*Net from client2 SQL*Net roundtrips to/from client0 sorts (memory)0 sorts (disk)1 rows processed 2. 优化实施
(1)索引优化--(数据库层优化建议)
为查询条件建立唯一索引 (PARTITION, ZONE),优化前执行计划走TABLE ACCESS FULL,Consistent gets = 70,优化后执行计划走INDEX RANGE SCAN UN_ZONE_LIST_PARTGConsistent gets = 1 逻辑读从 70 → 1,降幅 98.5%。
--- 创建索引
create UNIQUE index PANDA.UN_ZONE_LIST_PARTG on PANDA.ZONE_LIST(PARTITION,ZONE);SQL> SELECT T.ZONE FROM ZONE_LIST T WHERE T.PARTITION = 'G';Elapsed: 00:00:00.01Execution Plan
----------------------------------------------------------
Plan hash value: 586154005-----------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 6 | 1 (0)| 00:00:01 |
|* 1 | INDEX RANGE SCAN| UN_ZONE_LIST_PARTG | 1 | 6 | 1 (0)| 00:00:01 |
-----------------------------------------------------------------------------------------Predicate Information (identified by operation id):
---------------------------------------------------1 - access("T"."PARTITION"='G')Statistics
----------------------------------------------------------0 recursive calls0 db block gets1 consistent gets0 physical reads0 redo size549 bytes sent via SQL*Net to client421 bytes received via SQL*Net from client2 SQL*Net roundtrips to/from client0 sorts (memory)0 sorts (disk)1 rows processed
(2)应用层面优化建议
现在主要矛盾是应用层频繁请求数据库,应用层-数据库层面有一个东西可以解决这一问题-中间件缓存,对于热点数据,可以放入缓存中间件 比如 Redis,避免频繁访问 DB。案例二是一个只有select的表,比较好修改,案例一也可以引用这种方法,但会涉及到缓存一致性问题,一致性越强代码越不好改动。
但其实除了应用层,Oracle也提供了两种方法,一个是KEEP Buffer Pool, 专为“热点小表”准备的一块独立内存区,启用后这些表的数据块不再被 LRU 算法换出,从而避免反复磁盘 I/O,提高访问速度。上面方式可以降低物理读,对于热点表逻辑读可以通过Oracle11g的一种新特性Result Cache,可以用来缓存SQL Query Result Cache:存储 SQL 查询的结果集和PL/SQL Function Result Cache:用于存储 PL/SQL 函数的结果集。
配合result_cache_max_resultresult_cache_mode参数/*+ result_cache */hint可直接访问结果集不需要再查询这个sql,比如案例二可将逻辑读降为0。
3. 优化效果(预期)
单靠建索引即可将 每天 I/O 量由 13.18TB → <1TB;若再结合缓存/队列,能进一步大幅降低数据库压力。
| 指标 | 优化前 | 优化后 | 降幅 |
| 平均逻辑读 | 70 blocks | 1 block | -98.5% |
| 每天逻辑读量 | ≈ 13.18 TB | ≈ 0.986 TB | -92.5% |
| 平均响应耗时 | 0.17 ms | 0.01 ms | 提升17倍 |
| 执行频率影响 | 高频仍然存在 | 可通过缓存/队列进一步优化 | - |
SQL优化效果预期
上面说一个4M的表的SQL进AWR TOP SQL,一天概产生读13.18TB数据,一个8M的表和一个简单任务的处理逻辑3个SQL一天产生110TB 的逻辑读,还有前面几篇讲到的
【SQL优化案例】Oracle统计信息缺失 - 墨天轮
【SQL优化案例】索引问题 - 墨天轮
【SQL优化案例】SQL改写 - 用 UNION ALL 替代 OR - 墨天轮
【SQL优化案例】表结构与数据分布问题 - 墨天轮
这些案例都是很常见的优化案例,相较于慢SQL,TOP SQL优化起来并不困难,但是在实施之后怎么观察预期效果呢?
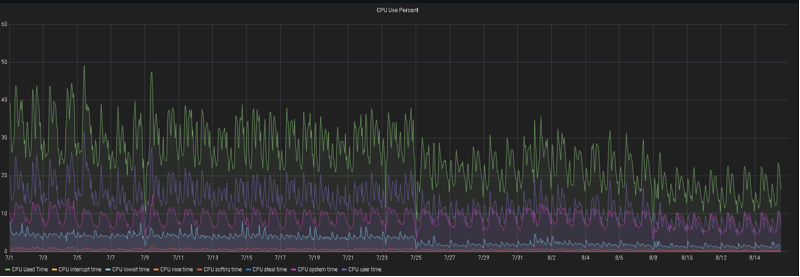
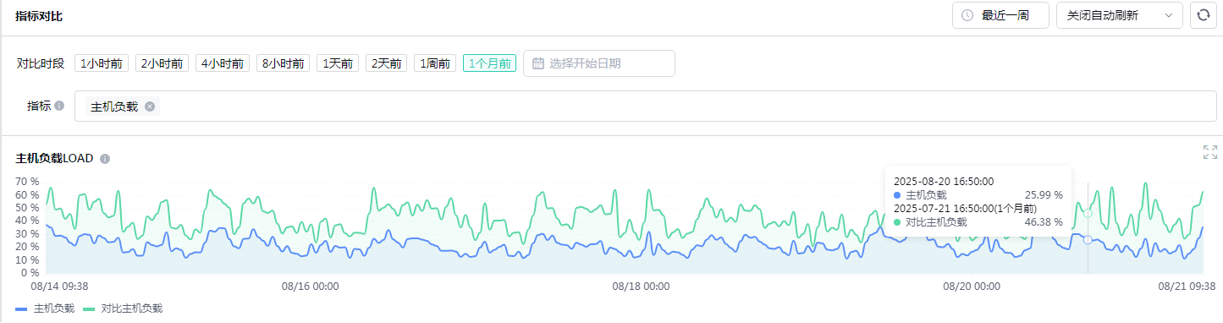
除了单个SQL实施之后的执行时间、逻辑读大小,常见的指标有CPU使用率、操作系统负载,AAS,DB CPU、DB TIME等。
在实施40+SQL左右,可以观察到实例每天产生的逻辑读降了30%-50%。
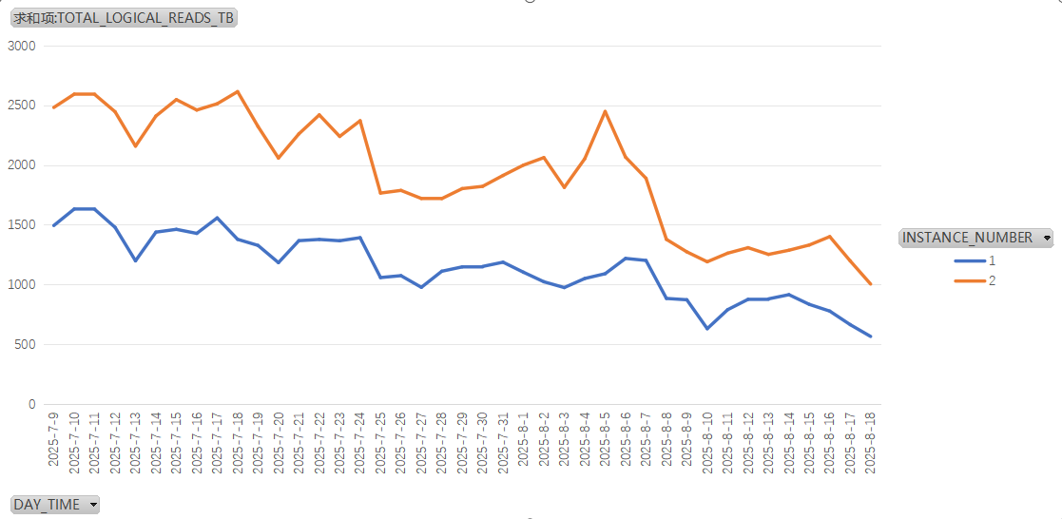
CPU和操作系统负载下降幅度也很明显
实例一
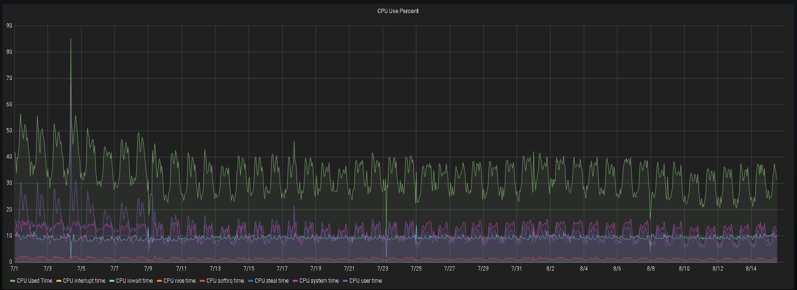
实例二