31.Encoder-Decoder(Seq2Seq)
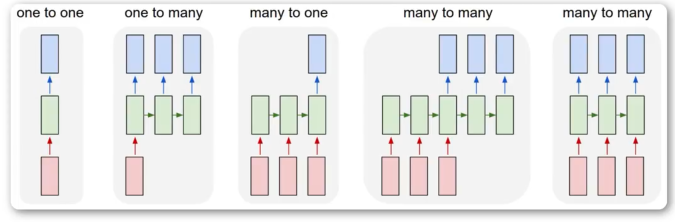
常见网络结构
-
One2One
固定大小的输入,固定大小的输出。如:图像分类任务,输入固定大小图片,输出一个类别。
-
One2Many
固定大小的输入,不固定大小的输出。如:看图说话、用词造句。
-
Many2One
不固定的输入,固定的输出。如:语句情感分析、文章分类、视频分类
-
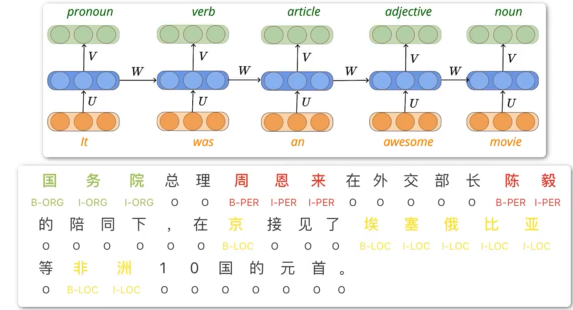
Many2Many同步
固定长度的序列,输出等长的序列。如:词性标注、字符级预测、视频帧级分类
-
Many2Many异步——Seq2Seq
不固定输入,不固定输出。如:机器翻译、命题作文、语音识别。
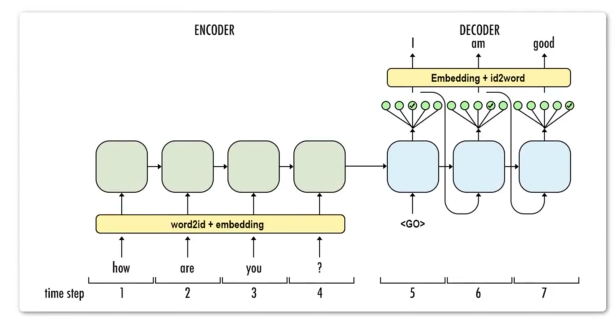
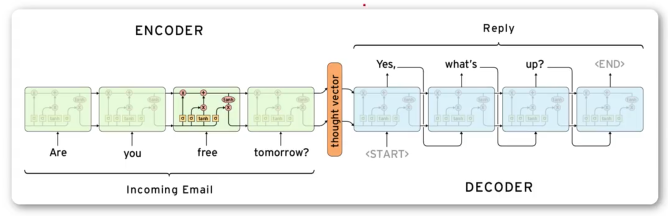
Encoder-Decoder
编码器-解码器架构:不固定输入,不固定输出。分为编码和解码两个部分:编码器处理输入序列,经过一个隐藏层输出向量。解码器把向量作为输入,输出新序列。
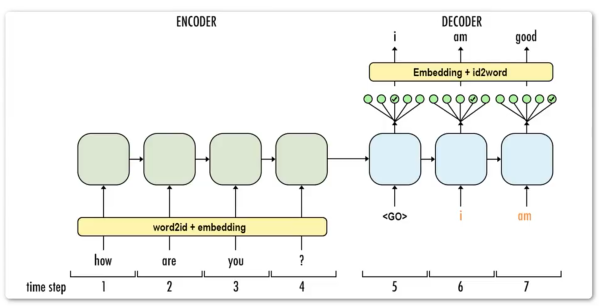
训练时
Decoder并不是把当前时刻的输出,作为下一时刻的输入。训练阶段的Decoder,输入时刻为目标序列(橙色)。
意为:如果在输出am的位置,输出的不是am,而是is。那么,下一时刻的输入(橙色am位置),依然为am。
其实好理解,这是训练阶段,他做错了,你需要纠正他。这个过程叫做Teacher Forcing。
预测时
decoder的当前输入,作为下一时刻输出。