如何用JAVA实现布隆过滤器?
目录
引言
布隆过滤器的原理
1. 核心思想
2. 优缺点
布隆过滤器的使用场景
Java 实现布隆过滤器
1. 实现步骤
2. 代码实现
3. 代码说明
4. 测试结果
布隆过滤器的优化
总结
引言
布隆过滤器(Bloom Filter)是一种高效的概率数据结构,用于判断一个元素是否属于某个集合。它的特点是空间效率高、查询速度快,但有一定的误判率(False Positive)。布隆过滤器常用于缓存系统、垃圾邮件过滤、数据库查询优化等场景。
1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列的随机映射函数(哈希函数)两部分组成的数据结构。
背景:为预防大量黑客故意发起非法的时间查询请求,造成缓存击穿,建议采用布隆过滤器的方法解决。布隆过滤器通过一个很长的二进制向量和一系列随机映射函数(哈希函数)来记录与识别某个数据是否在一个集合中。如果数据不在集合中,能被识别出来,不需要到数据库中进行查询,所以能将数据库查询返回值为空的查询过滤掉。
缓存穿透: 缓存穿透是查询一个根本不存在的数据,由于缓存是不命中时需要从数据库查询,这将导致这个不存在的数据每次请求都要到数据库去查询,进而给数据库带来压力。
布隆过滤器的原理
1. 核心思想
布隆过滤器的核心思想是使用多个哈希函数将元素映射到一个位数组中。具体步骤如下:
-
初始化位数组:创建一个长度为
m的位数组,所有位初始化为 0。 -
添加元素:
-
对元素使用
k个哈希函数计算哈希值。 -
将位数组中对应哈希值的位置置为 1。
-
-
查询元素:
-
对元素使用相同的
k个哈希函数计算哈希值。 -
检查位数组中对应哈希值的位置是否都为 1。
-
-
如果都为 1,则元素可能存在(可能有误判)。
-
如果有任何一个位置为 0,则元素一定不存在。
2. 优缺点
-
优点:
-
空间效率高:使用位数组存储数据。
-
查询速度快:时间复杂度为 O(k),其中 k 是哈希函数的数量。
-
-
缺点:
-
有误判率:可能将不存在的元素误判为存在。
-
不支持删除操作:删除元素会影响其他元素的判断。
-
简单来说
当一个元素加入布隆过滤器中的时候,会进行如下操作:
使用布隆过滤器中的哈希函数对元素进行计算,得到哈希值(有几个哈希函数得到几个哈希值)。
根据得到的哈希值,在位数组中把对应下标的值置为1。
当我们需要判断一个元素是否位于布隆过滤器的时候,会进行如下操作:
对给定元素再次进行相同的哈希计算;
得到值之后判断位数组中的每个元素是否都为1,如果值都为1,那么说明这个值在布隆过滤器中,如果存在一个值不为1,说明该元素不在布隆过滤器中。
例子:
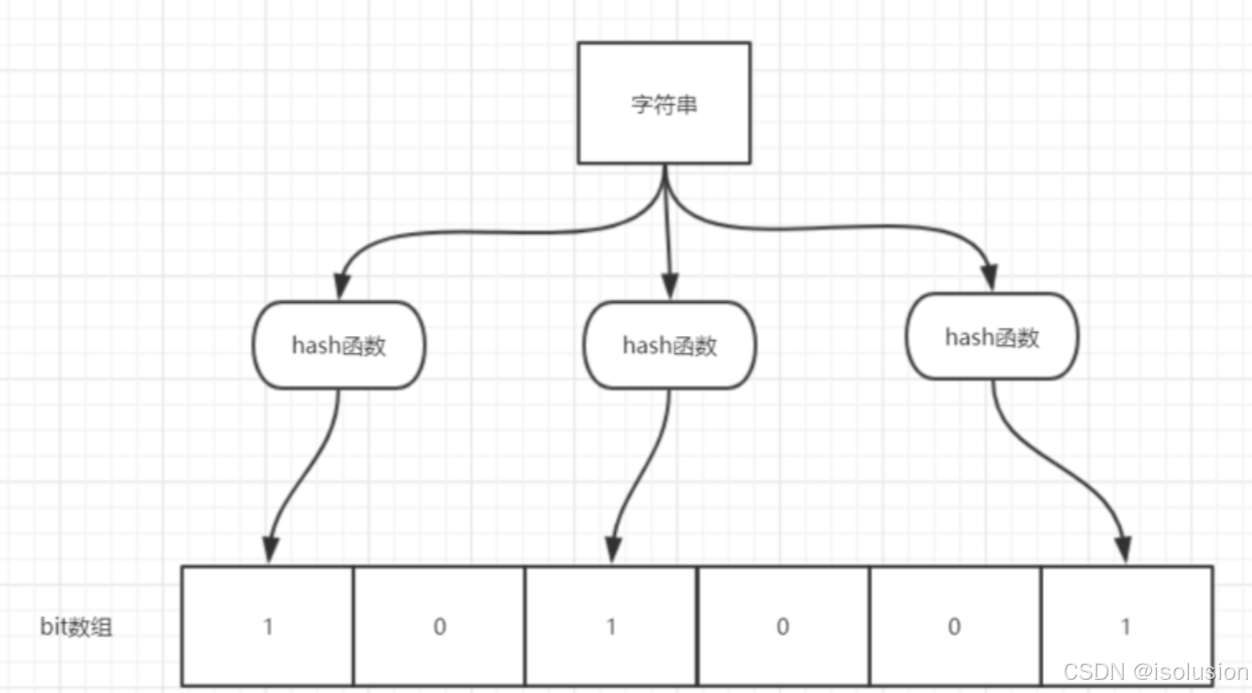
如图所示,当字符串存储要加入到布隆过滤器中时,该字符串首先由多个哈希函数生成不同的哈希值,然后将对应的位数组的下标设置为 1 (当位数组初始化时,所有位置均为 0)。当第二次存储相同字符串时,因为先前的对应位置已设置为 1,所以很容易知道此值已经存在(去重非常方便);
如果我们需要判断某个字符串是否在布隆过滤器中时,只需要对给定字符串再次进行相同的哈希计算,得到值之后判断位数组中的某个元素是否都为1,如果值都为1,那么说明这个值在布隆过滤器中,如果存在一个值不为1,说明该元素不在布隆过滤器中。
不同的字符串可能哈希出来的位置相同,这种情况我们可以适当增加位数组大小或者调整我们的哈希函数。
综上,我们可以得出:布隆过滤器说某个元素存在,小概率会误判。布隆过滤器说某个元素不存在,那么这个元素一定不在。
布隆过滤器的使用场景
判断给定数据是否存在:比如判断一个数字是否在于包含大量数字的数字集中(数字集很大,5亿以上)、防止缓存穿透(判断请求的数据是否有效避免直接绕过缓存请求数据库)、邮箱的垃圾邮件过滤、黑名单功能等。去重:爬给定网址的时候对已经爬取过的URL去重。
Java 实现布隆过滤器
1. 实现步骤
-
定义位数组和哈希函数。
-
实现添加元素的方法。
-
实现查询元素的方法。
2. 代码实现
import java.util.BitSet;
import java.util.Random;
public class BloomFilter {
private BitSet bitSet; // 位数组
private int size; // 位数组大小
private int[] seeds; // 哈希函数的种子
private SimpleHash[] hashFunctions; // 哈希函数数组
/**
* 构造函数
*
* @param size 位数组大小
* @param hashCount 哈希函数数量
*/
public BloomFilter(int size, int hashCount) {
this.size = size;
this.bitSet = new BitSet(size);
this.seeds = new int[hashCount];
this.hashFunctions = new SimpleHash[hashCount];
// 初始化哈希函数
Random random = new Random();
for (int i = 0; i < hashCount; i++) {
seeds[i] = random.nextInt();
hashFunctions[i] = new SimpleHash(size, seeds[i]);
}
}
/**
* 添加元素
*
* @param value 要添加的元素
*/
public void add(String value) {
for (SimpleHash hashFunction : hashFunctions) {
int hash = hashFunction.hash(value);
bitSet.set(hash, true);
}
}
/**
* 查询元素是否存在
*
* @param value 要查询的元素
* @return 如果可能存在返回 true,否则返回 false
*/
public boolean contains(String value) {
for (SimpleHash hashFunction : hashFunctions) {
int hash = hashFunction.hash(value);
if (!bitSet.get(hash)) {
return false;
}
}
return true;
}
/**
* 内部类:简单哈希函数
*/
private static class SimpleHash {
private int capacity;
private int seed;
public SimpleHash(int capacity, int seed) {
this.capacity = capacity;
this.seed = seed;
}
/**
* 计算哈希值
*
* @param value 输入值
* @return 哈希值
*/
public int hash(String value) {
int result = 0;
int len = value.length();
for (int i = 0; i < len; i++) {
result = seed * result + value.charAt(i);
}
return (capacity - 1) & result; // 取模运算
}
}
public static void main(String[] args) {
// 创建布隆过滤器
BloomFilter bloomFilter = new BloomFilter(1000, 3);
// 添加元素
bloomFilter.add("Alice");
bloomFilter.add("Bob");
bloomFilter.add("Charlie");
// 查询元素
System.out.println("Contains Alice: " + bloomFilter.contains("Alice")); // true
System.out.println("Contains Dave: " + bloomFilter.contains("Dave")); // false
}
}3. 代码说明
-
BitSet:
-
使用
BitSet作为位数组,节省空间。
-
-
哈希函数:
-
使用多个简单的哈希函数(
SimpleHash)来计算哈希值。 -
哈希函数通过种子生成不同的哈希值。
-
-
添加元素:
-
对元素使用所有哈希函数计算哈希值,并将位数组中对应位置置为 1。
-
-
查询元素:
-
对元素使用所有哈希函数计算哈希值,检查位数组中对应位置是否都为 1。
-
4. 测试结果
运行上述代码,输出如下:
Contains Alice: true
Contains Dave: false
布隆过滤器的优化
-
选择合适的位数组大小和哈希函数数量:
-
位数组越大,误判率越低,但占用空间越多。
-
哈希函数越多,误判率越低,但计算开销越大。
-
可以通过公式计算最优的位数组大小和哈希函数数量。
-
-
使用更复杂的哈希函数:
-
例如 MurmurHash、MD5 等,减少哈希冲突。
-
-
支持删除操作:
-
使用计数布隆过滤器(Counting Bloom Filter),通过计数器记录每个位的使用次数。
-
总结
布隆过滤器是一种高效的概率数据结构,适用于需要快速判断元素是否存在的场景。本文通过 Java 实现了一个简单的布隆过滤器,并介绍了其原理和优化方法。希望这篇文章能帮助你理解布隆过滤器,并在实际项目中应用它!