模型解释性:使用 SHAPASH 在贷款被拒原因的解释性(三)
github地址:
https://github.com/MAIF/shapash
中文文档:
https://weak.notion.site/README-8cc8e0bb36b44c7ca3251c3a27d83605
英文文档:
https://shapash.readthedocs.io/en/latest/
本文:From Confusion to Clarity: Explaining Loan Rejections Using SHAPASH
文章目录
- 1 业务场景:贷款
- 2 SHAPASH应用在贷款被拒原因解释
- 2.1 数据预处理
- 2.2 创建部分并拟合模型
- 2.3 SHAPASH 概览
- 2.4 解释
- 3 业务解决方案
- 3.1 负面贡献者
- 3.2 正面贡献者(允许因素)
- 4 结论

今天,我探索了 SHAPASH——一个能让黑盒模型变得可解释的 Python 库。我没有一味追求准确性,而是构建了一个简单的分类模型,以突出 SHAPASH 的最大优势:将复杂的决策转化为清晰、易于理解的洞察。在这篇文章中,我将逐步向你展示我是如何使用 SHAPASH 来剖析模型逻辑的。
1 业务场景:贷款
世界许多地区(如印度、非洲和东南亚)的小额贷款公司和数字贷款机构正在使用机器学习来决定谁能获得贷款。但问题在于:
人们被拒绝后完全不知道原因。
即使公司员工也无法清楚地解释,因为机器学习模型过于复杂。这导致:
- 客户不信任
- 监管机构的投诉和法律压力
- 公司声誉受损
2 SHAPASH应用在贷款被拒原因解释
在思考这个问题时,一个简单而有力的想法突然浮现在我脑海中:如果我们能准确地向客户展示他们的贷款为何被拒绝,会怎样? 这种透明度不仅可以减少不信任,还可以通过提供清晰、有数据支持的解释来缓解法律压力。
就在那时,我在 Twitter 上偶然发现了 SHAPASH——它立刻让我眼前一亮。我开始思考如何从商业角度应用它,以创造真正的价值。
为了探索这一点,我下载了一个信用风险贷款审批数据集,因为这个用例非常契合。然后我启动 pandas 来深入研究数据并理解特征。
import pandas as pd df = pd.read_csv("C:/Users/USER/.cache/kagglehub/datasets/laotse/credit-risk-dataset/versions/1/credit_risk_dataset.csv")df.head(2)
以下是数据概览:

图 01:前两条记录的概览
2.1 数据预处理
拿到数据集后,我做的第一件事是检查它的形状,以了解我将处理的记录量。这是一个快速的健全性检查,有助于在深入研究之前设定预期。
df.shape
数据集有 32,581 行和 12 列——对于使用 SHAPASH 进行实验来说,这是一个不错的规模。足以模拟真实世界的场景。
接下来,我通过删除两个与解释管道无关的列来清理数据。
df.drop(columns= ["cb_person_default_on_file", "cb_person_cred_hist_length"], inplace= True)
在检查数据类型时,我发现了一些异常——person_emp_length(就业时长)被存储为浮点数,这对于一个应该是整数的特征来说,并没有什么意义。
因此,我处理了缺失值并将其转换为整数,使数据更干净、更可靠,以便后续解释。
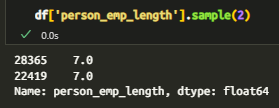
图 02:浮点数据类型
接下来,我检查了整个数据集的缺失值,以了解数据可能不完整的地方。以下是我发现的空值分布的快速概览——这是在为建模或可解释性准备特征之前必不可少的一步。
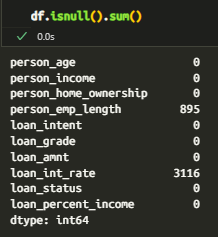
图 03:空值状态
我没有盲目地删除带有缺失值的列,而是有意识地进行处理——特别是 person_emp_length,它有大量的空值。如果删除它,就会失去有价值的上下文。
因此,我导入了 Seaborn 并绘制了直方图以可视化其分布。我选择使用最小值和最大值来填充空值,而不是默认使用均值或中位数,这使得插补与反映极端就业历史的业务目标保持一致。
import seaborn as sns
import matplotlib.pyplot as pltsns.histplot(data= df, x= "person_emp_length", kde= True)
plt.show()
输出结果:
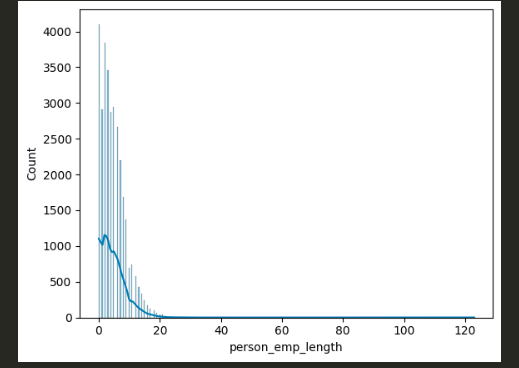
图 04:左偏分布
从直方图可以清楚地看出——person_emp_length 呈左偏分布,大多数值介于 0 到 20 之间。异常值推高了尾部,因此使用均值会使插补产生偏差。
相反,我选择了中位数,这是一个更安全、更稳健的选择,可以在最大限度地减少异常值造成的失真的同时,保留数据完整性。
df['person_emp_length'].fillna(df['person_emp_length'].median(), inplace= True)
第二个有缺失数据的主要列是 loan_int_rate,它在数据集中空值数量最多。和之前一样,我使用 Seaborn 直方图可视化了它的分布,以便更好地理解如何在不引入偏差的情况下进行插补。
sns.histplot(data= df, x= 'loan_int_rate')
plt.show()
输出结果:
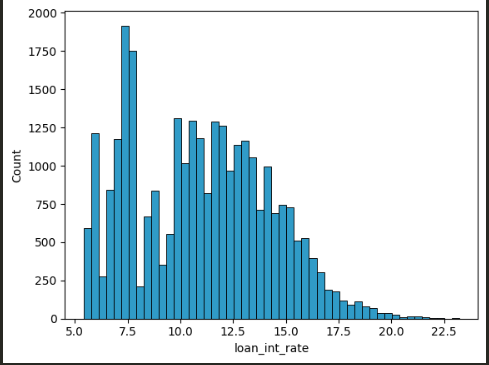
图 05:双峰分布
直方图显示了两个主要簇:一个在 5.0-10.0 之间,另一个更大的簇在 10.0-20.0 之间。由于大多数值右偏,我选择用常数 11.5 填充缺失值,恰好位于主要范围的中间——保持插补简单且具有代表性。
df['loan_int_rate'] = df['loan_int_rate'].fillna(11.5)
处理完空值后,我注意到有三列明显是分类变量。为了为建模做准备,我首先将它们转换为 category 数据类型——这使得以后将它们编码为数值变得更容易,同时保留了它们的语义意义。
df['person_home_ownership'] = df['person_home_ownership'].astype("category")df['loan_intent'] = df['loan_intent'].astype("category")df['loan_grade'] = df['loan_grade'].astype("category")
将列设置为分类变量后,我应用了一个简单的编码步骤,将它们转换为数值格式——为模型训练做好准备,而不会丢失其原始意图。
df['person_home_ownership'] = df['person_home_ownership'].cat.codesdf['loan_intent'] = df['loan_intent'].cat.codesdf['loan_grade'] = df['loan_grade'].cat.codes
2.2 创建部分并拟合模型
有了干净且经过预处理的数据集,我定义了 X(特征)和 y(目标),然后将数据拆分为训练集和测试集——为构建和评估分类模型奠定了基础。
X = df.drop(columns= ['loan_status'])
y = df['loan_status']
由于这是一个分类问题,我引入了 **RandomForestClassifier**——一个可靠、可解释的基线模型。然后我使用之前拆分的训练-测试数据对其进行训练,为使用 SHAPASH 进行评估和解释做好了准备。
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_splitx_train , x_test , y_train , y_test = train_test_split(X, y, test_size = 0.2, random_state = 42)
我初始化了 RandomForestClassifier 并在训练数据上拟合了它。模型训练完成后,现在可以进行预测——更重要的是,可以使用 SHAPASH 进行解释。
clf = RandomForestClassifier()clf.fit(x_train, y_train)
2.3 SHAPASH 概览
为了开始使用 SHAPASH,我导入了 SmartExplainer——它是其交互式可解释性的核心类。我初始化了它,并将训练好的 RandomForestClassifier 作为要解释的模型传入。这为生成一个基于网络的界面奠定了基础,使模型决策完全透明。
from shapash.explainer.smart_explainer import SmartExplainerxpl = SmartExplainer(model= clf)
接下来,我使用 X_test 集编译了 SmartExplainer。此步骤将解释器连接到模型及其将解释的数据,允许 SHAPASH 为真实的测试用例并行生成预测和解释。
xpl.compile(x= x_test)
最后,我运行了 SHAPASH 网络应用——就这样,一个完全交互式的解释仪表板在 **localhost:8080** 上线了。你现在可以探索预测、特征影响,并实时了解模型做出每个决策的原因。
app = xpl.run_app(port= "8080", host= "0.0.0.0", title_story= "credits_risk")
探索完成后,你可以简单地从终端停止应用程序以关闭本地服务器。快速而干净——就像 SHAPASH 提供的洞察一样。
app.kill()
2.4 解释
一旦应用程序上线,SHAPASH 会为你提供一个干净、交互式的仪表板,你可以在其中探索:
- 每个单独案例的预测
- 每个决策的特征重要性
- 模型行为和逻辑的全局视图
以下是你在 localhost:8080 上运行的界面概览:
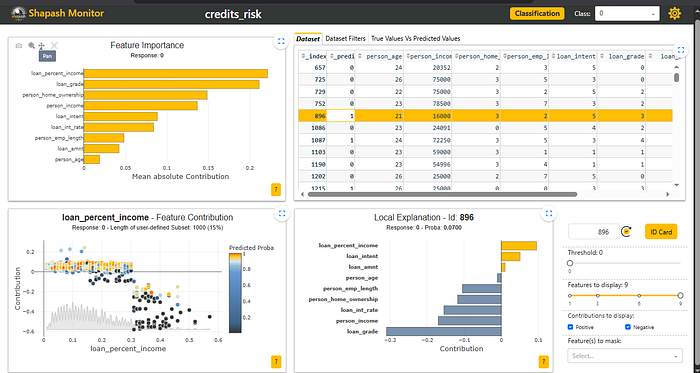
图 06:用于监控的 Shapash 监控器
它直观、无需代码,旨在使黑盒模型可解释——即使对于非技术用户也是如此。
现在,你可能想知道你看到的是什么。让我来解释一下:
- 右上角: 预测输出——
0(未批准)或1(已批准)。你可以使用下拉菜单在它们之间切换。 - 左上角: 一个条形图,显示特征重要性——哪些因素对预测的影响更大。
- 左下角: 一个散点图,x 轴是贷款等级,y 轴是它们的贡献——黄色点倾向于批准 (
1),蓝色点倾向于拒绝 (0)。例如,模型在批准 0 到 0.3 之间的 0 级贷款时很谨慎,并且大多预测其他等级会被拒绝。 - 右下角: 一个局部可解释性图,显示特定案例的正(黄色)和负(蓝色)特征贡献。
3 业务解决方案
对于被拒绝的贷款,以下是驱动决策的因素:
3.1 负面贡献者
- 低收入(中等特征重要性)
- 低贷款收入比(散点图上大多在 0.1-0.2 范围内)
- 低贷款等级(不是最差的,但有很强的负面影响)
- 利率、年龄和贷款意图影响最小
3.2 正面贡献者(允许因素)
- 较高的贷款金额(相当重要)
- 房屋所有权(财务稳定性的有力标志)
- 就业时长几乎不影响决策
把它想象成一辆车在岔路口。有些因素将其推向批准,另一些则推向拒绝。由于权重更倾向于拒绝,最终的决定是“拒绝”。
这种清晰度让客户准确理解他们的贷款为何被拒绝,通过提供透明的、数据驱动的原因,减少了不信任并缓解了法律压力。
4 结论
使用 SHAPASH,我们可以打开机器学习模型的黑箱,清晰地解释决策——比如为什么贷款被批准或拒绝。这种透明度与客户建立了信任,并帮助企业减少困惑和法律风险。这是一种将复杂数据转化为可理解、可操作洞察的强大方法。