面向 6G 网络的 LLM 赋能物联网:架构、挑战与解决方案
英文:LLM-Empowered IoT for 6G Networks: Architecture, Challenges, and Solutions
中文:面向 6G 网络的 LLM 赋能物联网:架构、挑战与解决方案
作者
Xiaopei Chen(华南理工大学未来技术学院 / 鹏城实验室前沿研究中心)
Wen Wu(鹏城实验室前沿研究中心)
Liang Li(鹏城实验室前沿研究中心)
Fei Ji(华南理工大学电子与信息学院)
论文出处
IEEE Internet of Things Magazine,已录用,作者稿(未最终编辑)。DOI: 10.1109/MIOT.2025.3582641
主要内容梳理
引言
作者指出 6G 将带来超低时延、超大带宽、全域智能与自治等革命性能力,使物联网(IoT)在设备规模、数据处理与决策自动化三方面发生深刻变革。与此同时,GPT、LLaMA 等大型语言模型(LLM)在 NLP、CV 等多领域表现出强大泛化能力,其“预训练–微调”范式天然契合 6G 时代 IoT 场景。然而,现有 LLM 重度依赖云端,带来高时延、高带宽及隐私风险,且资源受限的 IoT 设备无法直接承载完整模型。因此,文章提出“LLM-Empowered IoT”双层愿景:一方面用 LLM 提升 IoT 应用与网络管理(LLM for 6G IoT);另一方面在 6G IoT 边缘基础设施上部署并运行 LLM(LLM on 6G IoT),并给出内存友好的分裂联邦学习(SFL)框架以解决微调阶段的资源瓶颈。
第二节 6G 时代的 IoT 场景与 LLM 基础
该节首先勾勒 6G 物联网的典型应用:智能交通(V2X 与全自动驾驶)、工业 IoT(超低时延机器人控制)、智慧城市(城市级感知与主动管理)、eHealth(远程手术、可穿戴监测、脑机接口)、空天地海一体化 IoT(卫星、船舶、无人机协同)。随后回顾 LLM 发展历程:2017 年 Transformer 架构奠定注意力机制基础;2018-2019 年 BERT/GPT-1 确立预训练-微调范式;2020 年后 GPT-3、PaLM、LLaMA 等模型展示规模定律(scaling law),但高质量公开数据预计在 2026 年左右枯竭。
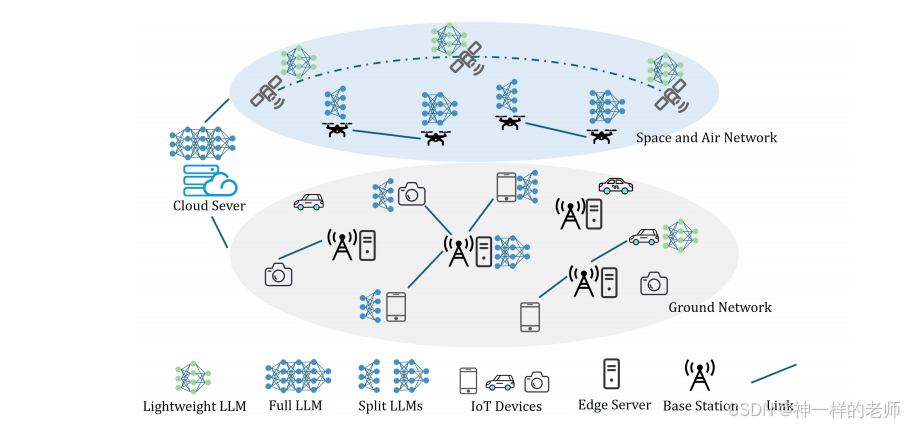
第三节 LLM for 6G IoT:用 LLM 提升 IoT 智能
该节聚焦“LLM 为 IoT 做什么”。
LLM 赋能 IoT 应用:
– 智慧医疗——LLM 解析病历、文献及可穿戴设备实时数据,辅助诊断、预测风险并给出个性化健康建议。
– 智慧家庭——LLM 通过语音/文本理解实现情境感知控制;学习用户习惯自动调节灯光温度;融合视觉与传感器数据识别异常行为。
– 智慧城市——LLM 分析交通流量、摄像头、GPS 大数据,实时优化信号灯、缓解拥堵。LLM 增强网络管理:
IoT 设备持续产生日志、信号、传感等多模态数据,边缘服务器先进行预处理并提取关键信息;云侧 LLM 依据全局信息和优化目标生成资源调度策略,再下发给边缘与终端执行。相比传统基于数学模型的优化,LLM 可直接从数据学习策略,适配动态场景。
第四节 LLM on 6G IoT:如何在 IoT 上部署 LLM
该节讨论“LLM 如何在 IoT 上跑起来”。
边缘微调
– 参数高效微调(PEFT):冻结大部分预训练权重,仅更新少量附加参数(Additive)、选定的原参数(Selective)或重参数化矩阵(Reparameterization,如 LoRA),显著降低计算与通信开销,但仍需较大激活内存。
– 分布式学习框架:
· 协同设备分裂学习(Collaborative devices split learning)
· 服务器-设备分裂学习(Server-device split learning)
· 分裂联邦学习(Split Federated Learning, SFL):结合联邦学习与分裂学习优点,客户端只训练局部子模型,剩余计算卸载到服务器,降低终端内存占用并保留隐私。
· 知识蒸馏式迁移学习:终端运行轻量化模型,边缘服务器运行大模型,通过蒸馏实现知识迁移。边缘推理
– 终端推理:对模型进行量化、剪枝、蒸馏后直接在设备端运行,响应快但精度可能不足。
– 协同推理(Co-Inference):按层切分模型,终端执行前几层后将中间特征发送至边缘/云端继续推理,既减轻终端负担,又减少原始数据传输量,兼顾隐私与时延。
第五节 内存高效的分裂联邦学习(SFL)框架
作者提出一个面向异构 IoT 设备的内存友好 SFL 框架:
系统由边缘服务器与若干 IoT 客户端构成,服务器保存完整 LLM 与多套 LoRA 适配器;客户端仅保存嵌入层加少量浅层 Transformer 及对应 LoRA 模块。
训练分“客户端并行”与“服务器串行”两阶段:客户端本地前反向计算后上传激活与梯度;服务器按调度顺序依次加载各客户端对应的 LoRA 模块完成剩余计算,并通过 FedAVG 聚合全局 LoRA 适配器后再下发。
调度策略:服务器优先处理客户端反向传播时间长的任务,以隐藏通信与计算延迟。
实验结果表明,该方法相比传统 SL 在只增加 10% 内存的情况下缩短 40% 训练时间;相比标准 SFL 节省 79% 内存、缩短 6% 训练时间。
第六节 案例研究
作者在 RTX 4080S 服务器与六款异构终端(Jetson Nano、TX2、Snapdragon 8/8s Gen3、A17 Pro、M3)上,用 BERT-base 与 CARER 情感数据集验证框架效果,指标设定为 LoRA rank=16、batch=16、学习率 1e-5、序列长度 128、目标精度 0.89。结果再次验证了 SFL 框架在内存占用与收敛时间上的优势。
第七节 开放问题
资源感知的 LLM 部署:如何结合模型压缩、分裂计算、自适应负载分配,解决 IoT 设备内存、算力、能耗差异巨大的问题。
按需部署:面对任务多样且动态变化,如何借助边缘缓存与压缩技术实现“用多少、放哪里”的弹性部署,同时在性能与资源间取得平衡。
数据隐私与安全:IoT 数据敏感且设备安全能力参差不齐,需引入差分隐私、U 形分裂学习等机制,防范数据泄露、模型逆向、投毒攻击等风险。
结论
文章总结提出的 LLM-Empowered IoT 架构:
LLM for 6G IoT 旨在用 LLM 提升 IoT 应用智能与网络管理效率;
LLM on 6G IoT 通过边缘计算、分布式学习与协同推理,解决在资源受限设备上运行 LLM 的挑战;
内存高效的 SFL 框架显著降低微调阶段的内存与时间开销。
作者指出,6G、IoT 与 LLM 的深度融合有望构建未来智能网络的基石,但仍需在资源、部署、安全等方面持续创新。