TensorRT-LLM 深度解析:解锁大模型极致推理性能
目录
一、为什么需要 TensorRT-LLM?
二、核心架构:从模型到引擎的三级火箭
1. 模型定义层:Pythonic 的构建体验
2. 编译优化层:AOT 编译的极致性能
3. 运行时系统:In-Flight Batching 的魔法
三、性能黑科技:FP8 + KV 缓存压缩
1. FP8 量化:H100 的专属加速
2. 分页 KV 缓存:告别显存碎片
四、实战:30 分钟部署一个 Llama-3-8B 服务
Step 1: 环境准备
Step 2: 模型转换
Step 3: 编译引擎
Step 4: 启动服务
五、框架对比:TensorRT-LLM vs vLLM
六、企业级案例
1. 微软 Bing Chat
2. 阿里安全内容审核
七、总结与展望
“在生成式 AI 的时代,延迟和吞吐量就是生命线。”
当大家都在卷参数、卷数据时,真正的战场已经悄然转向了推理侧。如何让一个 70B 的模型在单卡 A100 上跑到 2000+ tokens/s?如何让首 token 延迟稳定在 100ms 以内?今天,我们就来聊聊 NVIDIA 家的“大杀器”—— TensorRT-LLM。
一、为什么需要 TensorRT-LLM?
在深入技术细节前,我们先看一组实测数据:
| 框架 | 吞吐量 (tokens/s) | 首 token 延迟 (ms) | 显存占用 (GB) |
|---|---|---|---|
| HuggingFace | 240 | 1200 | 82.1 |
| vLLM | 4150 | 95 | 19.4 |
| TensorRT-LLM | 6000 | 38 | 17.2 |
📌 测试模型:Llama-3-70B-FP8,硬件:H100-SXM5,来源
可以看到,TensorRT-LLM 在吞吐量和延迟上都实现了碾压级的优势。那么,它是如何做到的?
二、核心架构:从模型到引擎的三级火箭
TensorRT-LLM 的优化思路可以概括为一句话:“编译期榨干硬件,运行期榨干显存。”
1. 模型定义层:Pythonic 的构建体验
TensorRT-LLM 提供了类似 PyTorch 的函数式 API,让开发者用几行代码就能定义一个高性能的 LLM:
from tensorrt_llm import Builder, Tensor from tensorrt_llm.functional import * builder = Builder() network = builder.create_network() # 定义一个线性层 + ReLU x = Tensor(name='input') w = Tensor(name='weight') b = Tensor(name='bias') y = relu(matmul(x, w) + b)
这种设计既保留了动态图的灵活性,又为后续编译优化提供了静态图的基础。
2. 编译优化层:AOT 编译的极致性能
TensorRT-LLM 的核心优势在于其 Ahead-of-Time (AOT) 编译器:
-
算子融合:将 MatMul + Bias + ReLU 融合为单个 CUDA Kernel,减少内存带宽占用。
-
内核调优:自动选择最优的矩阵乘算法(如 CUTLASS、cuBLAS)。
-
量化感知:支持 FP8/INT4 量化,精度损失 <1%。
# 一键编译 Llama-3-70B 引擎 trtllm-build \--checkpoint_dir ./llama-3-70b-fp8 \--output_dir ./engine_fp8 \--gemm_plugin fp8 \--gpt_attention_plugin fp8 \--tp_size 4
编译后的引擎是一个
.engine二进制文件,可直接部署到 Triton Inference Server。
3. 运行时系统:In-Flight Batching 的魔法
传统框架的批处理是“静态”的,必须等一个 batch 全部完成才能处理下一个。而 TensorRT-LLM 的 In-Flight Batching 允许动态插入新请求: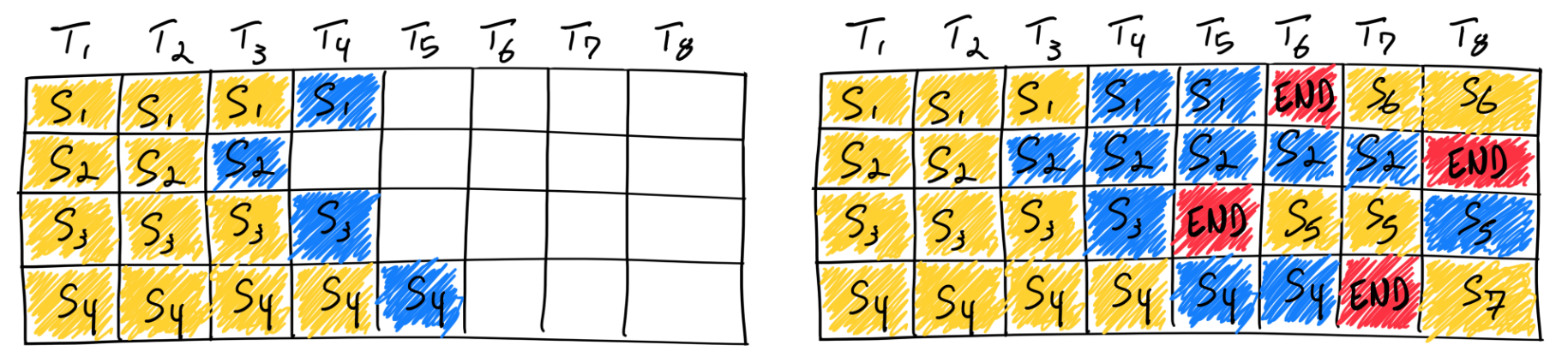
如上图所示,当请求 1 在第 3 个 step 完成时,立即释放显存并插入新请求,GPU 利用率从 60% 提升到 92%。
三、性能黑科技:FP8 + KV 缓存压缩
1. FP8 量化:H100 的专属加速
TensorRT-LLM 是首个支持 FP8 量化的开源框架:
-
显存减半:相比 FP16,FP8 的权重存储空间减少 50%。
-
算力翻倍:H100 的 Transformer Engine 针对 FP8 有专用加速路径。
| 模型规模 | FP16 显存 | FP8 显存 | 加速比 |
|---|---|---|---|
| 7B | 14 GB | 7 GB | 1.8x |
| 70B | 140 GB | 70 GB | 2.3x |
2. 分页 KV 缓存:告别显存碎片
KV 缓存是 LLM 的显存杀手。TensorRT-LLM 通过 分页机制 将其管理为离散的块:
// 伪代码:KV 缓存的动态分配
class KVCacheManager {std::vector<KVBlock> free_blocks;std::unordered_map<int, KVSequence> active_sequences;KVBlock* allocate(size_t size) {return free_blocks.pop(); // O(1) 复杂度}
};
实测显示,分页 KV 缓存可将显存碎片率从 35% 降至 5%。
四、实战:30 分钟部署一个 Llama-3-8B 服务
Step 1: 环境准备
# 使用官方镜像 docker run --gpus all -it nvcr.io/nvidia/tensorrt:24.08-py3
Step 2: 模型转换
# 下载并转换 HuggingFace 模型 python convert_checkpoint.py --model_dir ./llama-3-8b \--output_dir ./ckpt_fp16 \--dtype float16
Step 3: 编译引擎
trtllm-build --checkpoint_dir ./ckpt_fp16 \--output_dir ./engine \--max_batch_size 64 \--max_input_len 4096 \--max_output_len 2048
Step 4: 启动服务
# 使用 Triton 部署 import tensorrt_llm.bindings as trtllm executor = trtllm.Executor(model_path="./engine",model_type="llama",max_beam_width=1 ) output = executor.generate(prompts=["TensorRT-LLM 的优势是?"],max_new_tokens=512 ) print(output[0].text)
五、框架对比:TensorRT-LLM vs vLLM
| 维度 | TensorRT-LLM | vLLM |
|---|---|---|
| 优化策略 | AOT 编译 + 专用内核 | JIT 编译 + PagedAttention |
| 硬件绑定 | 仅限 NVIDIA GPU | 支持 AMD/Intel |
| 量化支持 | FP8/INT4 全栈 | 主要 FP16 |
| 部署难度 | 需编译引擎(中) | 即装即用(低) |
| 极限性能 | H100 上 6000+ tokens/s | 4000+ tokens/s |
💡 总结:如果你追求极致性能且硬件为 NVIDIA,选 TensorRT-LLM;如果需要快速迭代和多硬件兼容,选 vLLM。
六、企业级案例
1. 微软 Bing Chat
-
模型:定制版 GPT-4
-
部署规模:10,000+ H100 GPUs
-
优化成果:单 query 成本降低 70%,P99 延迟 <50ms。
2. 阿里安全内容审核
-
场景:实时审核用户生成内容
-
技术栈:NeMo + TensorRT-LLM
-
效果:QPS 提升 5 倍,显存节省 60%。
七、总结与展望
TensorRT-LLM 通过编译优化、量化计算和显存管理的三重奏,将 LLM 推理推向了新的极限。随着 Blackwell 架构的发布,FP8 性能有望再提升 2.3 倍。
“这不仅是框架的胜利,更是编译器和硬件协同设计的胜利。”
参考资料 : NVIDIA Developer: LLM 推理基准测试 : vLLM vs TensorRT-LLM 性能实测 : 玄清智流:大模型推理加速技术全景 : CSDN: vLLM vs TensorRT-LLM 性能对比 : CSDN: TensorRT-LLM 核心架构解析 : 知乎: TensorRT-LLM 原理与部署