【AI】模型量化--模型量化技术基础
1. 背景
对于接触过AI模型的人来说,经常会听说一个词语模型量化,那什么是模型量化?为什么需要模型量化?有哪些常用的模型量化技术呢?模型量化有哪些挑战?本文将一一展开叙述。
2. 概念
模型量化是一种在深度学习和机器学习领域中广泛应用的技术,旨在通过减少模型中数据的表示精度来降低模型的存储需求和计算成本,同时尽量保持模型的性能。简单的说就是将模型中的权重和激活值从较高精度的数据类型(如 32 位浮点数)转换为较低精度的数据类型(如 8 位整数)的过程。
3. 为什么要量化?
3.1 减少存储需求
模型权重大小的计算公式如下:
模型大小 = 参数量 x 每个参数所占字节数
以LLAMA 13B举例,在不同的精度下,模型大小如下:

从上图可以看到,当模型精度越小时模型权重也越小。因此量化有助于降低模型的大小,减少存储需求,存储包括磁盘和显存。
3.2 加速推理
在深度学习中,矩阵乘法和卷积等运算占据了大量的计算量。低精度数据类型(如 8 位整数)的计算在硬件上通常可以比高精度数据类型(如 32 位浮点数)更高效地完成。以整数运算为例,硬件可以同时处理多个整数运算,利用并行计算的优势,大大提高计算速度。因此在相同硬件上,可以更快速的计算出结果。
下图是NVIDIA Hopper架构的H100的架构图,在模型推理过程中,模型权重数值和激活值在TensorCore和显存之间存在频繁的数据交换。如果能减少数据交换的大小,便可以提升模型的推理效率。因为在当前的模型推理中,制约模型推理速度的最大因素是显存带宽而非算力本身。
综上所述,通过加快计算和减少显存和TensorCore数据交换均可以加速推理。

3.3 其他优势
由于量化模型需要更低的存储和更高效的计算,因此附带优势包括可以有效的节省硬件成本,降低功耗,利益在价格相对低廉的硬件上部署等等。
4. 量化技术
对称量化和非对称量化确实是量化技术中两种核心方法,它们通过不同的策略将高精度数据(如浮点数)映射到低精度表示(如整数),以优化存储和计算效率。在介绍对称量化和非对称量化前需要提两个概念,也就是量化的两个重要过程,一个是量化(Quantize),另一个是反量化(Dequantize),如下图所示:

4.1 对称量化
1.21, -1.31, 0.22
0.83, 2.11, -1.53
0.79, -0.54, 0.84
假设对上述矩阵进行INT8量化,按照如下步骤进行:
- 确定原始矩阵中的最大绝对值:对于给定的矩阵,找到绝对值最大的元素。在此例子中,数据绝对值的最大值是2.11。
- 计算缩放因子(scale):由于INT8对称量化的范围为[-127, 127],缩放因子为 max_abs / 127。这里,max_abs为2.11,因此 scale = 2.11 / 127 ≈ 0.016614。
- 对每个元素进行量化:将原始矩阵中的每个元素除以缩放因子,然后将结果四舍五入到最近的整数。得到的数值即为INT8对称量化后的值,并且应确保结果在[-127, 127]范围内。由于最大值已被正确缩放为127,其他元素的结果不会超过范围。
- 在需要进行反量化时,使用量化后的值乘以缩放因子.
上述矩阵的数值量化后数值如下图所示:
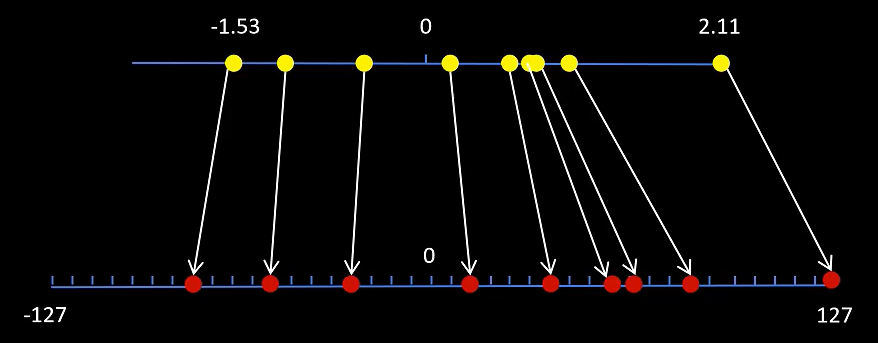
量化和反量化示意图如下所示:

将输入X和权重W使用对称量化,对称量化结果如下:

4.2 非对称量化
1.21, -1.31, 0.22
0.83, 2.11, -1.53
0.79, -0.54, 0.84
假设对上述矩阵进行UINT8非对称量化,按照如下步骤进行:
- 确定最大值和最小值。在此例子中,最小值是-1.53,最大值是2.11。
- 计算缩放因子(scale):scale = (max_value - min_value) /(255) ,缩放因子为 scale =(2.11 - (-1.53))/255=(3.64) /255≈0.0142745。
- 对每个元素x进行量化:对于每个元素x,计算量化后的q=round( (x - (-1.53)) /scale ),等价于:q=round( (x +1.53) *70.05494505 )。
- 在需要进行反量化时,使用量化后的值乘以缩放因子.
上述矩阵的数值量化后数值如下图所示:
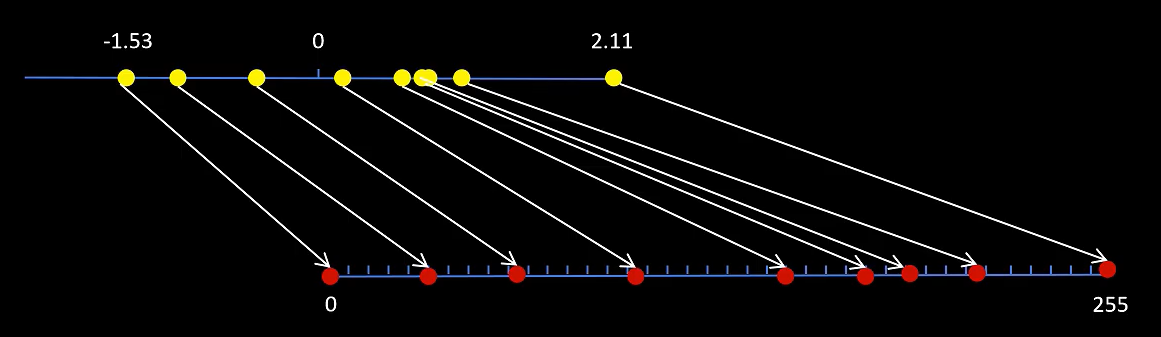
量化和反量化示意图:
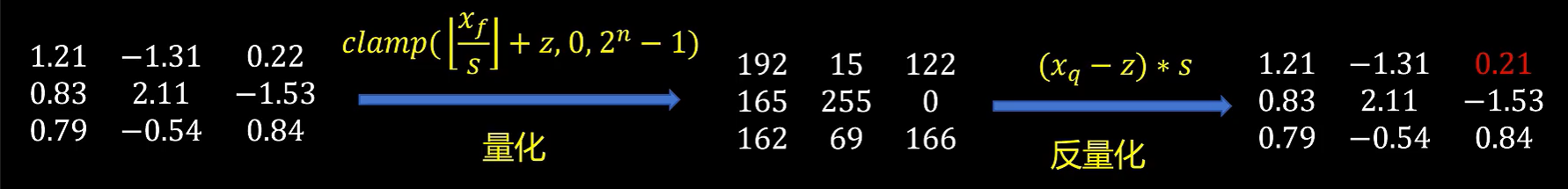
将输入X和权重W使用非对称量化,非对称量化结果如下:

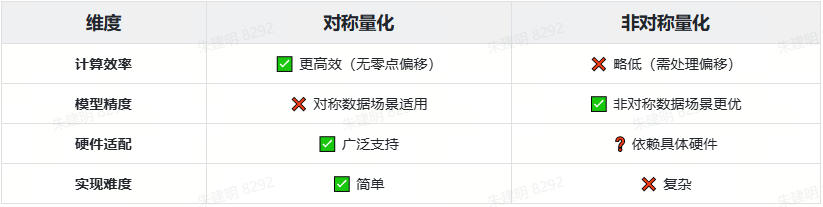
4.3 对称量化和非对称量化对比
4.3.1 优势

4.3.1 总结