2025年8月第3周AI资讯
今天为大家总结近一周值得关注的AI新闻:
1.IDE 国内版公测–CodeBuddy丨支持最新 DeepSeek V3.1

CodeBuddy IDE 国内版正式开放公测!🚀
无需邀请码,即刻免费使用最新 DeepSeek V3.1 模型
官网下载地址(Beta 版):https://copilot.tencent.com/ide/
用 CodeBuddy,真正实现一个人变成一整个开发团队的极致提效体验,一站式产品工作台,助你规划、开发和发布应用 ⬇️
产品设计:一句话生成可落地交互原型,支持上传图片及局部调优
研发编码:内置 Figma,设计稿秒变可维护源码。同时,内置腾讯云开发 CloudBase、EdgeOne Pages 及 Supabase,帮助开发者自动配置数据库、用户认证等后端服务,快速构建、部署站点和无服务器应用
部署验证:通过 CloudStudio 一键部署至沙箱环境,并生成可分享链接
2.ToonComposer – 腾讯联合港中文、北大推出的AI动画制作工具
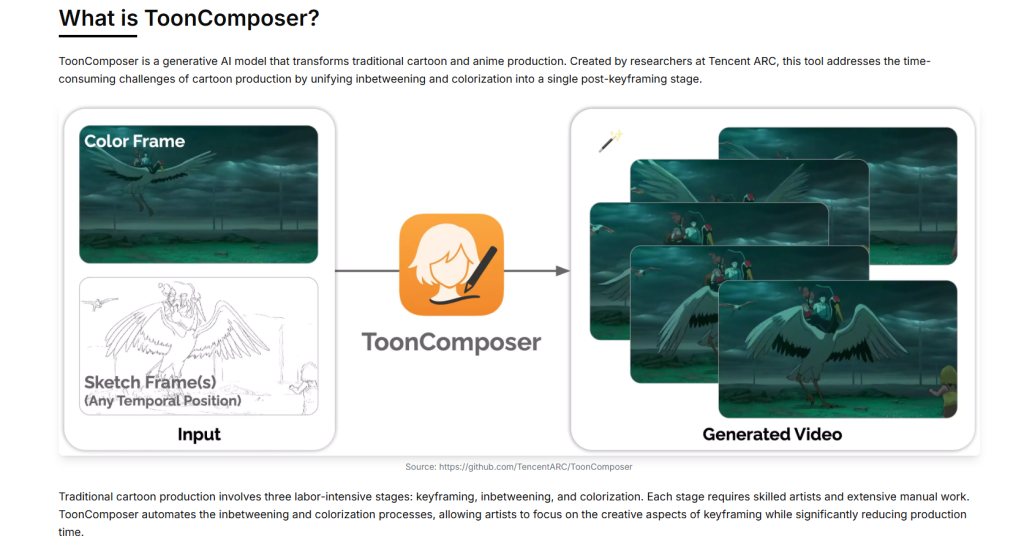
ToonComposer 是香港中文大学、腾讯 PCG ARC 实验室和北京大学研究人员共同推出的生成式 AI 工具,几秒能将草图转化成专业级动画。ToonComposer基于生成式后关键帧技术,将传统动画制作中的中间帧生成和上色环节整合为自动化过程,仅需一个草图和一个上色参考帧,能生成高质量的动画视频。工具支持稀疏草图注入和区域控制,让艺术家能准控制动画效果,大幅减少人工工作量,提高创作效率,为动画制作带来革命性变革。
ToonComposer的主要功能:
- 生成式后关键帧:将动画制作中的中间帧生成和上色环节整合为自动化过程,仅需一个草图和一个上色参考帧,能完整的卡通视频,显著减少人工工作量。
- 精确草图关键帧控制:艺术家通过稀疏的关键帧草图在时间轴的任何位置引导动画,处理复杂动作时能保持高精度和高质量。
- 区域控制:用户能选择性地在草图中留白,用画笔工具标记这些区域,ToonComposer 能智能地根据上下文或提示填充留白区域,进一步减少艺术家的工作量。
3.全能图像编辑模型Qwen-Image-Edit来啦
Qwen-Image-Edit基于20B的Qwen-Image模型进⼀步训练,成功将Qwen-Image的独特的文本渲染能力延展至图像编辑领域,实现了对图片中文字的精准编辑。此外,Qwen-Image-Edit将输⼊图像同时输⼊到Qwen2.5-VL(实现视觉语义控制)和VAE Encoder(实现视觉外观控制),从而兼具语义与外观的双重编辑能⼒。如需体验最新模型,欢迎访问 Qwen Chat (chat.qwen.ai)并选择“图像编辑”功能。
Qwen-Image-Edit的主要特性包括:
- 语义与外观双重编辑: Qwen-Image-Edit不仅⽀持low-level的视觉外观编辑(如元素的添加、删除、修改等,要求图片其他区域完全不变),也支持 high-level 的视觉语义编辑(如 IP 创作、物体旋转、风格迁移等,允许整体像素变化但保持语义一致)。
- 精准⽂字编辑: Qwen-Image-Edit 支持中英文双语文字编辑,可在保留原有字体、字号、风格的前提下,直接对图片中的文字进行增、删、改等操作。
- 强⼤的基准性能: 在多个公开基准测试中的评估表明,Qwen-Image-Edit 在图像编辑任务上具备SOTA性能,是一个强大的图像编辑基础模型。
4.AudioGenie – 腾讯AI Lab推出的多模态音频生成工具
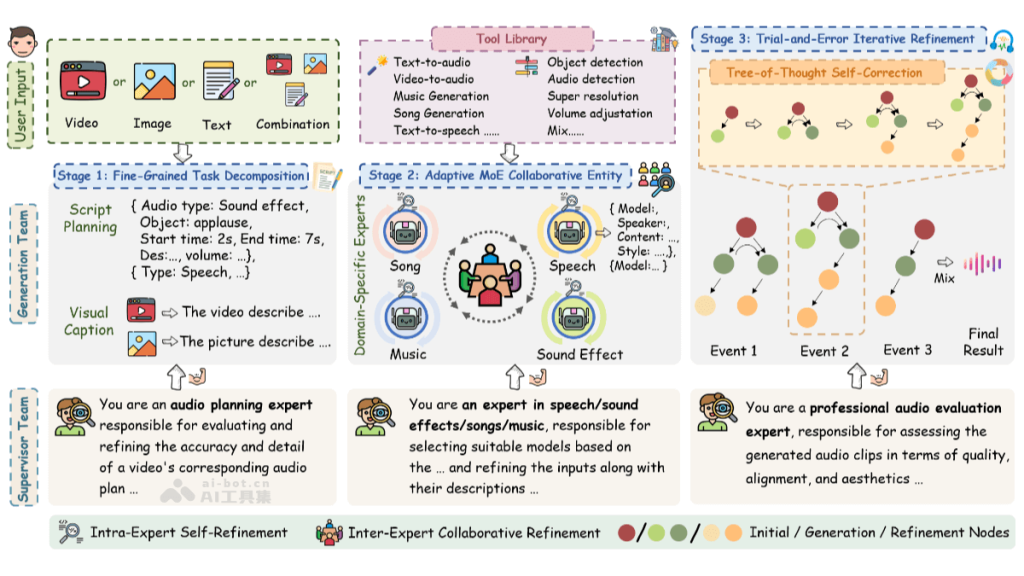
AudioGenie是腾讯AI Lab团队推出的多模态音频生成工具,能从视频、文本、图像等多种模态输入生成音效、语音、音乐等多种音频输出。工具采用无训练的多智能体框架,通过生成团队和监督团队的双层架构实现高效协同。生成团队负责将复杂的输入分解为具体的音频子事件,通过自适应混合专家(MoE)协作机制动态选择最适合的模型进行生成。监督团队则负责时空一致性验证,通过反馈循环进行自我纠错,确保生成的音频高度可靠。
AudioGenie建立了全球首个针对多模态到多音频生成(MM2MA)任务的基准测试集MA-Bench,包含198个带有多类型音频注释的视频。在测试中,AudioGenie在9项指标、8项任务中均达到或接近最先进水平,尤其在音质、准确性、内容对齐和美学体验方面表现出色。
5.智元推出行业首个机器人世界模型开源平台 Genie Envisioner

智元机器人推出行业首个面向真实世界机器人操控的统一世界模型平台 — Genie Envisioner(GE)。
根据官方介绍,不同于传统“数据 — 训练 — 评估”割裂的流水线模式,GE 将未来帧预测、策略学习与仿真评估首次整合进以视频生成为核心的闭环架构,使机器人在同一世界模型中完成从“看”到“想”再到“动”的端到端推理与执行。基于 3000 小时真机数据,GE-Act 不仅在跨平台泛化和长时序任务执行上显著超越现有 SOTA,更为具身智能打开了从视觉理解到动作执行的全新技术路径。
有关链接:
- **Project page:**https://genie-envisioner.github.io/
- **Arxiv:**https://arxiv.org/abs/2508.05635
- **Github:**https://github.com/AgibotTech/Genie-Envisioner
GE 平台通过构建统一的视频生成世界模型,将这些分散的环节集成到一个闭环系统中。基于约 3000 小时的真实机器人操控视频数据,GE 建立了从语言指令到视觉空间的直接映射,保留了机器人与环境交互的完整时空信息。
6.v0.app-新一代AI 辅助 Web 开发工具
v0.app 是 Vercel 推出 AI 辅助 Web 开发工具。工具结合生成式 AI 和现代 Web 技术,能帮助用户快速构建从简单组件到全栈应用的各种项目。工具引入 AI Agent模式,具备自主规划、编码和调试能力,能根据用户需求生成完整的应用。用户用自然语言描述需求,v0 能生成代码、设计界面并提供技术支持。工具支持实时协作、代码编辑和一键部署,适合产品经理、营销人员和工程师等各类用户,极大提升开发效率和用户体验。
v0.app的主要功能
- 全栈应用开发:支持从简单组件到复杂全栈应用的构建,涵盖前端、后端、数据库和外部 API 集成。
- AI Agent 智能体:具备自主规划、编码和调试能力,能根据用户需求生成完整的应用。
- 自然语言交互:用户用自然语言描述需求,无需编码知识,v0 自动实现技术细节。
- 实时协作与编辑:支持团队协作,用户能在工具中直接编辑生成的代码,支持双向 Git 同步。
- 一键部署:基于 Vercel 的企业级基础设施,用户能快速将应用部署上线,无需复杂配置。
- 多语言支持:用户能用多种语言描述需求,v0 自动翻译并生成代码。
- 设计与代码生成:支持将设计图(如 Figma)直接转换为可运行的代码,实现像素级还原。