深入理解强化学习的target network
文章目录
-
-
- **问题所在:追逐一个移动的目标 (The Moving Target Problem)**
- **解决方案:引入 Target Network**
- **Target Network 如何更新?**
- **整合到 DQN 算法流程中**
- **总结**
- 案例分析:cartpole
-
Target Network 是深度强化学习(尤其是基于价值学习的方法,如DQN)中一个里程碑式的技巧。不夸张地说,没有它,DQN 算法就很难稳定地训练起来。
要理解它,我们得先从它要解决的问题入手:训练的不稳定性。
问题所在:追逐一个移动的目标 (The Moving Target Problem)
想象一下,在没有 Target Network 的普通 Q-Learning 中,我们如何更新我们的神经网络(我们称之为 Q-Network)。我们的目标是让网络的预测值 Q(S, A) 尽可能接近一个“目标值”。这个目标值通常由贝尔曼方程给出,我们称之为 TD Target (时序差分目标)。
对于一个状态转移 (S, A, R, S’),TD Target 的计算公式是:
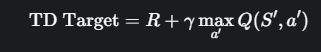
其中:
- R 是我们获得的奖励。
- γ (gamma) 是折扣因子。
- m a x a ′ Q ( S ′ , a ′ ) max_{a'} Q(S', a') maxa′Q(S′,a′) 是我们的网络对下一个状态 S’ 能获得的最大 Q 值的估计。
然后,我们用这个 TD Target 来计算损失(通常是均方误差MSE),并更新网络权重 θ:
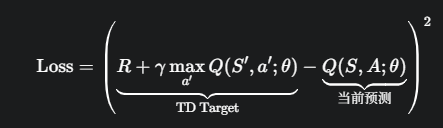
问题来了:请注意,TD target和当前预测都使用了同一个网络权重 θ。这意味着,在每一步训练中:
- 我们计算一个目标值,这个目标值依赖于当前的网络 Q ( S ′ , a ′ ; θ ) Q(S', a'; θ) Q(S′,a′;θ)。
- 我们又用这个目标值去更新同一个网络 Q ( S , A ; θ ) Q(S, A; \theta) Q(S,A;θ)。
这就像一个“自己追自己”的游戏。你每朝着目标迈出一步,目标本身也因为你的移动而改变了位置。这会导致非常严重的问题:
- 剧烈震荡:策略可能在几个好的选择之间来回摇摆,无法稳定收敛。
- 发散:在某些情况下,Q 值可能会被错误地不断放大,最终导致梯度爆炸,训练彻底失败。
一个绝佳的比喻是:
想象你在用相机给一个朋友拍照。你(Q-Network)正在努力调整焦距(更新权重),让朋友(TD Target)的影像变得清晰。但问题是,你的朋友非常调皮,每次你一动相机,他也跟着动一下。在这种情况下,你将很难对上焦。
解决方案:引入 Target Network
为了解决这个“移动目标”问题,DeepMind 的研究者们提出了一个非常聪明的技巧:使用两个网络。
- 在线网络 (Online Network) Q ( S , A ; θ ) Q(S, A; \theta) Q(S,A;θ):
- 这是我们一直在谈论的主要网络。
- 它的权重 θ 在每一步训练中都会被更新。
- 它负责根据当前状态选择动作(执行策略),也是我们最终要得到的模型。
- 它就像是那个正在努力调焦的摄影师。
- 目标网络 (Target Network) Q ( S ′ , a ′ ; θ − ) Q(S', a'; \theta^-) Q(S′,a′;θ−):
- 这是在线网络的一个克隆体,拥有完全相同的结构。
- 它的权重 θ − θ^- θ− 是周期性地、延迟地从在线网络那里复制过来的,在两次复制之间保持固定。
- 它只用于一件事:计算 TD Target 中的 m a x a ′ Q ( S ′ , a ′ ) max_{a'} Q(S', a') maxa′Q(S′,a′) 部分。
- 它就像是那个被摄影师要求保持这个姿势别动的朋友。
通过这个设计,我们的损失函数被修改为:

现在,TD Target 由一个权重 θ − θ^- θ− 被“冻结”住的网络来计算。这个目标在一段时间内是稳定不变的。在线网络 Q ( S , A ; θ ) Q(S, A; \theta) Q(S,A;θ) 有了一个固定的目标去追赶,训练过程因此变得稳定得多。
Target Network 如何更新?
Target Network 的权重 θ − θ^- θ− 不是通过梯度下降来学习的,它只是定期地从在线网络那里“同步”权重。同步主要有两种方式:
- 硬更新 (Hard Update):这是 DQN 论文中的原始方法。每隔 C 个训练步骤(例如 C=10000),直接把在线网络的权重完整地复制给目标网络。