【LLMs篇】19:vLLM推理中的KV Cache技术全解析
前言
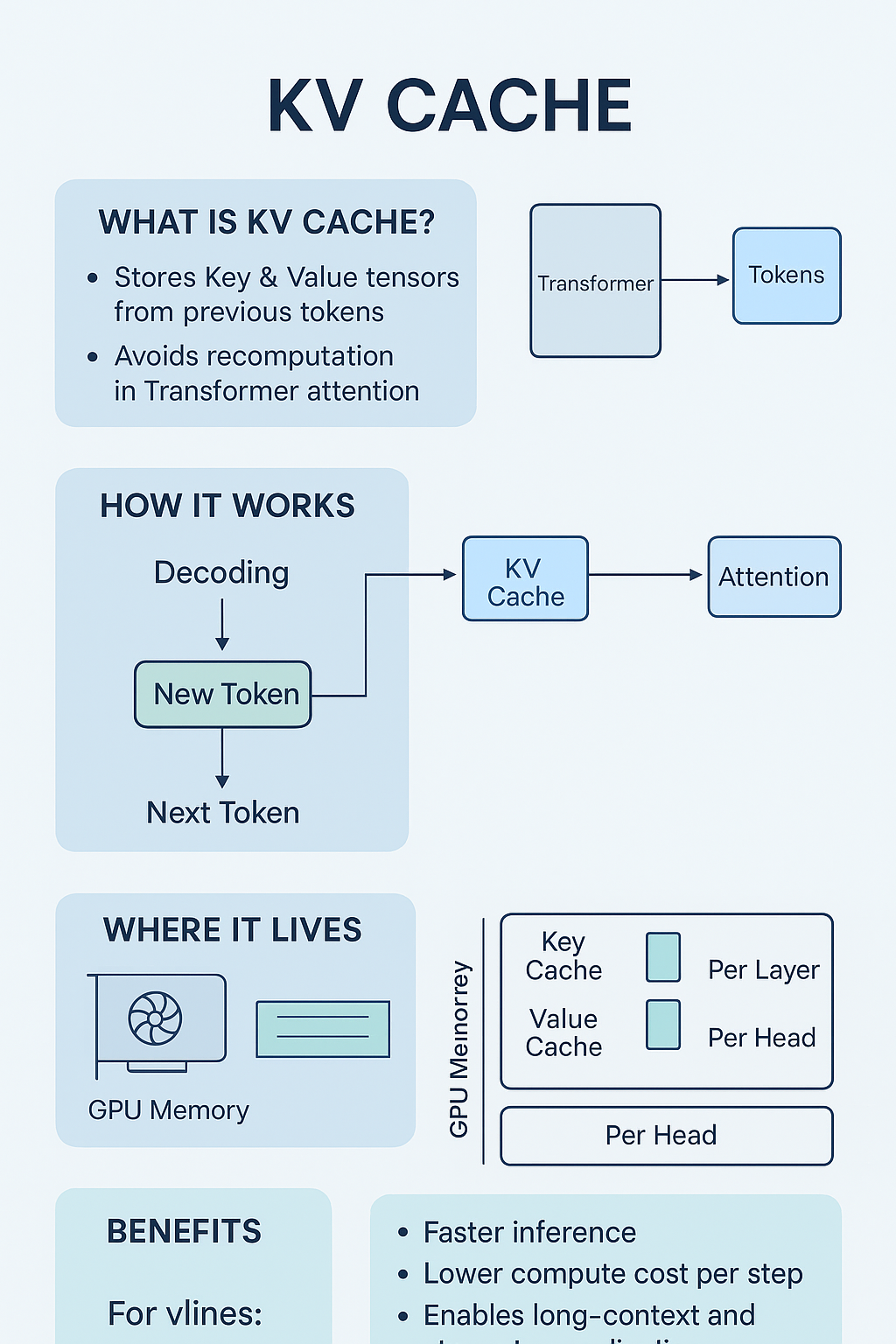
在大语言模型(LLM)推理优化的世界里,KV Cache技术就像是一把神奇的钥匙,能够显著提升推理速度和降低计算成本。本文将带您深入了解vLLM中KV Cache的工作原理、实现细节和优化策略,无论您是刚接触这个领域的新手,还是寻求深度技术洞察的专业人员。
第一章:基础概念篇 - 什么是KV Cache?
1.1 从Transformer说起
想象一下,您正在和朋友聊天。当朋友问"你昨天去哪里了?"时,您的大脑不仅要理解这个问题,还要回忆起昨天的经历来组织回答。大语言模型的工作方式与此类似,但它需要"记住"对话中的每一个词token。
在Transformer架构中,这种"记忆"机制主要通过自注意力机制(Self-Attention)实现:
Attention(Q, K, V) = softmax(QK^T/√d_k)V
其中:
- Q (Query):当前要处理的token的查询向量
- K (Key):所有历史token的键向量
- V (Value):所有历史token的值向量
1.2 KV Cache的核心思想
问题的提出:在生成每个新token时,模型需要重新计算所有历史token的Key和Value向量,这造成了大量重复计算。
KV Cache的解决方案:既然历史token的K和V向量在生成过程中不会改变,为什么不把它们缓存起来呢?
# 传统方式(每次都重新计算)
for step in range(sequence_length):K = compute_keys(all_tokens[:step+1]) # 重复计算V = compute_values(all_tokens[:step+1]) # 重复计算output = attention(Q, K, V)# KV Cache方式(增量计算)
K_cache, V_cache = [], []
for step in range(sequence_length):new_k = compute_key(current_token)new_v = compute_value(current_token)K_cache.append(new_k) # 只计算新的KV_cache.append(new_v) # 只计算新的Voutput = attention(Q, K_cache, V_cache)
1.3 性能提升的量化分析
使用KV Cache后的性能提升可以用以下公式估算:
加速比 = O(n²) / O(n) = n其中n是序列长度
实际测试数据显示:
- 延迟降低:70-90%的推理延迟减少
- 吞吐量提升:2-5倍的token生成速度提升
- 内存trade-off:以增加内存使用换取计算加速
第二章:vLLM中的KV Cache实现
2.1 vLLM架构概览
vLLM是一个高性能的LLM推理引擎,其KV Cache实现具有以下特点:
class vLLMKVCache:def __init__(self, max_seq_len, num_heads, head_dim, dtype):self.max_seq_len = max_seq_lenself.num_heads = num_headsself.head_dim = head_dim# 预分配内存块self.key_cache = torch.zeros((max_seq_len, num_heads, head_dim), dtype=dtype, device='cuda')self.value_cache = torch.zeros((max_seq_len, num_heads, head_dim), dtype=dtype, device='cuda')self.current_length = 0
2.2 PagedAttention:革命性的内存管理
vLLM的核心创新是PagedAttention技术,将KV Cache组织成固定大小的"页面":
class PagedKVCache:def __init__(self, page_size=16, max_pages=1000):self.page_size = page_size # 每页包含16个tokenself.max_pages = max_pages# 物理页面池self.key_pages = torch.zeros((max_pages, page_size, num_heads, head_dim))self.value_pages = torch.zeros((max_pages, page_size, num_heads, head_dim))# 逻辑到物理的映射表self.page_table = {}self.free_pages = list(range(max_pages))
PagedAttention的优势:
- 内存碎片减少:类似操作系统的虚拟内存管理
- 动态分配:按需分配和释放页面
- 共享机制:多个序列可以共享相同的prefix页面
- 内存利用率:相比传统方法提升60-80%
2.3 具体实现细节
2.3.1 KV Cache的初始化
def initialize_kv_cache(model_config, max_num_seqs, max_seq_len):"""初始化KV Cache"""num_layers = model_config.num_hidden_layersnum_heads = model_config.num_attention_headshead_dim = model_config.hidden_size // num_headskv_cache = []for layer in range(num_layers):layer_cache = {'key': torch.zeros((max_num_seqs, max_seq_len, num_heads, head_dim),dtype=torch.float16, device='cuda'),'value': torch.zeros((max_num_seqs, max_seq_len, num_heads, head_dim),dtype=torch.float16, device='cuda')}kv_cache.append(layer_cache)return kv_cache
2.3.2 增量更新机制
def update_kv_cache(kv_cache, layer_idx, seq_ids, new_keys, new_values, positions):"""增量更新KV Cache"""key_cache = kv_cache[layer_idx]['key']value_cache = kv_cache[layer_idx]['value']# 批量更新for i, seq_id in enumerate(seq_ids):pos = positions[i]key_cache[seq_id, pos] = new_keys[i]value_cache[seq_id, pos] = new_values[i]
2.3.3 注意力计算优化
def paged_attention_forward(query, key_cache, value_cache, page_table, context_lens, block_size=16
):"""PagedAttention前向计算"""batch_size, num_heads, head_dim = query.shape# 收集所有相关的KV页面key_blocks = []value_blocks = []for seq_id in range(batch_size):seq_len = context_lens[seq_id]num_blocks = (seq_len + block_size - 1) // block_sizeseq_key_blocks = []seq_value_blocks = []for block_idx in range(num_blocks):physical_block = page_table[seq_id][block_idx]seq_key_blocks.append(key_cache[physical_block])seq_value_blocks.append(value_cache[physical_block])key_blocks.append(torch.cat(seq_key_blocks, dim=0)[:seq_len])value_blocks.append(torch.cat(seq_value_blocks, dim=0)[:seq_len])# 执行注意力计算attention_scores = torch.matmul(query, key_blocks.transpose(-2, -1))attention_weights = torch.softmax(attention_scores / math.sqrt(head_dim), dim=-1)output = torch.matmul(attention_weights, value_blocks)return output
第三章:高级优化技术
3.1 内存管理策略
3.1.1 LRU淘汰机制
class LRUKVCache:def __init__(self, max_cache_size):self.max_cache_size = max_cache_sizeself.cache = {}self.access_order = []def get(self, seq_id):if seq_id in self.cache:# 更新访问顺序self.access_order.remove(seq_id)self.access_order.append(seq_id)return self.cache[seq_id]return Nonedef put(self, seq_id, kv_data):if len(self.cache) >= self.max_cache_size:# 淘汰最久未使用的oldest = self.access_order.pop(0)del self.cache[oldest]self.cache[seq_id] = kv_dataself.access_order.append(seq_id)
3.1.2 Prefix共享优化
def share_prefix_cache(sequences, kv_cache):"""共享相同前缀的KV Cache"""prefix_map = {}for seq_id, tokens in enumerate(sequences):# 查找最长公共前缀for length in range(len(tokens), 0, -1):prefix = tuple(tokens[:length])if prefix in prefix_map:# 复用现有的KV Cacheshared_seq_id = prefix_map[prefix]copy_kv_cache(kv_cache, shared_seq_id, seq_id, length)breakelse:prefix_map[prefix] = seq_id
3.2 并行化策略
3.2.1 Tensor并行
class TensorParallelKVCache:def __init__(self, world_size, rank):self.world_size = world_sizeself.rank = rank# 每个GPU负责一部分注意力头self.local_heads = num_heads // world_sizeself.head_offset = rank * self.local_headsdef split_kv_heads(self, keys, values):"""按注意力头分割KV"""start_idx = self.head_offsetend_idx = start_idx + self.local_headslocal_keys = keys[:, start_idx:end_idx, :]local_values = values[:, start_idx:end_idx, :]return local_keys, local_values
3.2.2 Pipeline并行
class PipelineKVCache:def __init__(self, pipeline_stages):self.stages = pipeline_stagesself.stage_caches = [KVCache() for _ in range(pipeline_stages)]def forward_stage(self, stage_id, hidden_states, kv_cache):"""单个pipeline阶段的处理"""# 从上一阶段接收KV Cacheif stage_id > 0:kv_cache = self.receive_kv_from_prev_stage()# 当前阶段计算new_hidden_states = self.layers[stage_id](hidden_states, kv_cache)# 发送KV Cache到下一阶段if stage_id < len(self.stages) - 1:self.send_kv_to_next_stage(kv_cache)return new_hidden_states
3.3 量化技术
3.3.1 KV Cache量化
def quantize_kv_cache(keys, values, bits=8):"""量化KV Cache到指定位数"""def quantize_tensor(tensor, bits):# 计算量化参数min_val = tensor.min()max_val = tensor.max()scale = (max_val - min_val) / (2**bits - 1)zero_point = min_val# 量化quantized = torch.round((tensor - zero_point) / scale)quantized = torch.clamp(quantized, 0, 2**bits - 1)return quantized.to(torch.uint8), scale, zero_point# 分别量化K和Vq_keys, k_scale, k_zero = quantize_tensor(keys, bits)q_values, v_scale, v_zero = quantize_tensor(values, bits)return {'keys': q_keys, 'key_scale': k_scale, 'key_zero': k_zero,'values': q_values, 'value_scale': v_scale, 'value_zero': v_zero}def dequantize_kv_cache(quantized_cache):"""反量化KV Cache"""keys = quantized_cache['keys'].float()keys = keys * quantized_cache['key_scale'] + quantized_cache['key_zero']values = quantized_cache['values'].float()values = values * quantized_cache['value_scale'] + quantized_cache['value_zero']return keys, values
第四章:实际应用与案例分析
4.1 聊天机器人场景
class ChatBotKVManager:def __init__(self):self.conversation_cache = {}self.max_context_length = 4096def process_message(self, user_id, message):"""处理用户消息并维护对话上下文"""# 获取或创建用户的KV Cacheif user_id not in self.conversation_cache:self.conversation_cache[user_id] = {'kv_cache': self.initialize_cache(),'token_count': 0,'conversation_history': []}user_cache = self.conversation_cache[user_id]# 检查是否需要截断历史if user_cache['token_count'] > self.max_context_length:user_cache = self.truncate_context(user_cache)# 编码新消息new_tokens = self.tokenizer.encode(message)# 使用现有KV Cache进行推理response = self.generate_response(new_tokens, user_cache['kv_cache'])# 更新缓存self.update_cache(user_cache, new_tokens, response)return response
4.2 代码生成场景
在代码生成任务中,KV Cache特别有效,因为代码往往具有结构化的上下文:
class CodeGenerationOptimizer:def __init__(self):self.function_cache = {} # 缓存函数级别的KVself.import_cache = {} # 缓存import语句的KVdef generate_code(self, prompt):"""优化的代码生成"""# 解析prompt中的导入语句imports = self.extract_imports(prompt)# 复用import的KV Cacheimport_kv = self.get_cached_imports(imports)# 识别函数定义模式function_patterns = self.extract_function_patterns(prompt)# 使用模式匹配复用相似函数的KVpattern_kv = self.get_pattern_cache(function_patterns)# 组合缓存进行生成combined_kv = self.combine_caches([import_kv, pattern_kv])return self.model.generate(prompt, kv_cache=combined_kv)
4.3 性能监控与调优
class KVCacheProfiler:def __init__(self):self.metrics = {'cache_hit_rate': 0.0,'memory_usage': 0.0,'access_patterns': {},'eviction_count': 0}def profile_cache_performance(self, kv_cache_manager):"""分析KV Cache性能"""# 缓存命中率total_requests = kv_cache_manager.total_requestscache_hits = kv_cache_manager.cache_hitsself.metrics['cache_hit_rate'] = cache_hits / total_requests# 内存使用情况memory_used = kv_cache_manager.get_memory_usage()total_memory = kv_cache_manager.max_memoryself.metrics['memory_usage'] = memory_used / total_memory# 访问模式分析self.analyze_access_patterns(kv_cache_manager.access_log)return self.metricsdef suggest_optimizations(self):"""基于profile结果提出优化建议"""suggestions = []if self.metrics['cache_hit_rate'] < 0.7:suggestions.append("考虑增加cache大小或优化淘汰策略")if self.metrics['memory_usage'] > 0.9:suggestions.append("启用KV量化或增强压缩")return suggestions
第五章:前沿技术与未来发展
5.1 Multi-Query Attention (MQA)
MQA通过共享Key和Value的投影矩阵来减少KV Cache的内存占用:
class MQAKVCache:def __init__(self, num_query_heads, num_kv_heads, head_dim):self.num_query_heads = num_query_headsself.num_kv_heads = num_kv_heads # << num_query_headsself.head_dim = head_dim# KV头数量大大减少self.kv_cache_size = num_kv_heads * head_dimdef compute_attention(self, query, key, value):"""MQA注意力计算"""# Query: [batch, seq_len, num_query_heads, head_dim]# Key/Value: [batch, seq_len, num_kv_heads, head_dim]# 复制KV到匹配Query头数heads_per_kv = self.num_query_heads // self.num_kv_headsexpanded_key = key.repeat_interleave(heads_per_kv, dim=2)expanded_value = value.repeat_interleave(heads_per_kv, dim=2)return self.scaled_dot_product_attention(query, expanded_key, expanded_value)
5.2 Grouped Query Attention (GQA)
GQA是MQA的改进版本,在性能和内存之间找到更好的平衡:
class GQAKVCache:def __init__(self, num_query_heads, num_groups, head_dim):self.num_query_heads = num_query_headsself.num_groups = num_groupsself.num_kv_heads = num_groups # 介于1和num_query_heads之间self.heads_per_group = num_query_heads // num_groupsdef group_attention(self, query, key, value):"""分组注意力计算"""batch_size, seq_len, _, head_dim = query.shape# 重新组织Query为组结构query_grouped = query.view(batch_size, seq_len, self.num_groups, self.heads_per_group, head_dim)# 对每个组独立计算注意力outputs = []for group_idx in range(self.num_groups):group_query = query_grouped[:, :, group_idx] # [batch, seq, heads_per_group, head_dim]group_key = key[:, :, group_idx:group_idx+1].expand(-1, -1, self.heads_per_group, -1)group_value = value[:, :, group_idx:group_idx+1].expand(-1, -1, self.heads_per_group, -1)group_output = self.scaled_dot_product_attention(group_query, group_key, group_value)outputs.append(group_output)return torch.cat(outputs, dim=2)
5.3 稀疏注意力与KV Cache
class SparseKVCache:def __init__(self, sparsity_pattern="local_global"):self.sparsity_pattern = sparsity_patternself.local_window = 512self.global_tokens = 128def create_sparse_mask(self, seq_len):"""创建稀疏注意力掩码"""mask = torch.zeros(seq_len, seq_len)if self.sparsity_pattern == "local_global":# 局部窗口for i in range(seq_len):start = max(0, i - self.local_window // 2)end = min(seq_len, i + self.local_window // 2)mask[i, start:end] = 1# 全局tokenmask[:, :self.global_tokens] = 1mask[:self.global_tokens, :] = 1return mask.bool()def sparse_attention(self, query, key, value, mask):"""稀疏注意力计算"""scores = torch.matmul(query, key.transpose(-2, -1))scores = scores.masked_fill(~mask, float('-inf'))weights = torch.softmax(scores, dim=-1)return torch.matmul(weights, value)
5.4 动态KV Cache压缩
class DynamicKVCompressor:def __init__(self, compression_ratio=0.5):self.compression_ratio = compression_ratioself.importance_threshold = 0.1def compute_token_importance(self, attention_weights):"""计算token重要性分数"""# 基于注意力权重计算重要性importance_scores = attention_weights.mean(dim=(0, 1)) # 平均所有头和batchreturn importance_scoresdef compress_kv_cache(self, kv_cache, attention_weights):"""动态压缩KV Cache"""importance_scores = self.compute_token_importance(attention_weights)# 选择重要的tokennum_keep = int(len(importance_scores) * (1 - self.compression_ratio))_, important_indices = torch.topk(importance_scores, num_keep)# 压缩KV Cachecompressed_kv = {'keys': kv_cache['keys'][:, important_indices],'values': kv_cache['values'][:, important_indices],'indices': important_indices}return compressed_kv
第六章:最佳实践与部署指南
6.1 生产环境配置
class ProductionKVCacheConfig:"""生产环境KV Cache配置"""def __init__(self, model_size, expected_qps, hardware_spec):self.model_size = model_sizeself.expected_qps = expected_qpsself.hardware_spec = hardware_spec# 根据模型大小和硬件配置推荐参数self.recommended_config = self.calculate_optimal_config()def calculate_optimal_config(self):"""计算最优配置参数"""config = {}# 基于GPU内存计算最大批处理大小gpu_memory_gb = self.hardware_spec['gpu_memory']model_memory_gb = self.estimate_model_memory()# 为KV Cache预留内存(通常是模型大小的50-70%)kv_memory_budget = (gpu_memory_gb - model_memory_gb) * 0.8# 计算最大序列长度和批处理大小config['max_seq_len'] = min(4096, self.calculate_max_seq_len(kv_memory_budget))config['max_batch_size'] = self.calculate_max_batch_size(kv_memory_budget)# 页面大小优化config['page_size'] = 16 # 通常16是最佳选择# 量化设置if gpu_memory_gb < 24: # 较小GPU启用量化config['enable_kv_quantization'] = Trueconfig['kv_quantization_bits'] = 8return config
6.2 监控与告警
class KVCacheMonitor:def __init__(self, alert_thresholds):self.alert_thresholds = alert_thresholdsself.metrics_collector = MetricsCollector()def collect_metrics(self, kv_cache_manager):"""收集KV Cache相关指标"""metrics = {'memory_usage_percent': kv_cache_manager.get_memory_usage_percent(),'cache_hit_rate': kv_cache_manager.get_hit_rate(),'avg_sequence_length': kv_cache_manager.get_avg_sequence_length(),'eviction_rate': kv_cache_manager.get_eviction_rate(),'page_utilization': kv_cache_manager.get_page_utilization()}# 检查告警条件self.check_alerts(metrics)return metricsdef check_alerts(self, metrics):"""检查告警条件"""if metrics['memory_usage_percent'] > self.alert_thresholds['memory']:self.send_alert('HIGH_MEMORY_USAGE', metrics['memory_usage_percent'])if metrics['cache_hit_rate'] < self.alert_thresholds['hit_rate']:self.send_alert('LOW_CACHE_HIT_RATE', metrics['cache_hit_rate'])
6.3 A/B测试框架
class KVCacheABTest:def __init__(self):self.experiments = {}self.traffic_splitter = TrafficSplitter()def create_experiment(self, name, control_config, treatment_config, traffic_percent):"""创建A/B测试实验"""self.experiments[name] = {'control': control_config,'treatment': treatment_config,'traffic_percent': traffic_percent,'metrics': {'control': [], 'treatment': []}}def route_request(self, request, experiment_name):"""根据实验配置路由请求"""experiment = self.experiments[experiment_name]if self.traffic_splitter.should_use_treatment(experiment['traffic_percent']):# 使用实验组配置return self.process_with_config(request, experiment['treatment'])else:# 使用对照组配置return self.process_with_config(request, experiment['control'])
结语:KV Cache技术的现状与展望
KV Cache技术已经成为现代LLM推理系统的核心组件。从最初的简单缓存机制,到vLLM的PagedAttention创新,再到最新的稀疏注意力和动态压缩技术,这个领域正在快速发展。
关键收益总结
- 性能提升:70-90%的延迟降低,2-5倍的吞吐量提升
- 成本优化:显著降低推理成本,提高资源利用率
- 用户体验:更流畅的交互体验,更快的响应时间
未来发展方向
- 硬件协同设计:与专用AI芯片的深度集成
- 算法创新:更高效的注意力机制和缓存策略
- 系统优化:跨设备、跨集群的分布式KV Cache
- 智能化管理:基于AI的缓存策略自动优化
实践建议
对于技术团队:
- 从业务场景出发选择合适的KV Cache策略
- 重视监控和性能调优
- 持续关注最新技术发展
对于研究人员:
- 探索新的注意力机制和缓存算法
- 关注硬件特性与算法的协同设计
- 推动标准化和最佳实践的建立
KV Cache技术的发展远未结束,它将继续是LLM推理优化的重要战场。