面试可能问到的问题思考-Redis
Redis连接池
一般不太会考虑redis连接池的问题,配合5,10之类的,都没有太大问题,只有在高并发的情况下,可能会因为连接池争抢,导致程序阻塞
生产上,可以配20甚至更高,以此来应对高并发情况
分布式锁
自己实现分布式锁
误删问题
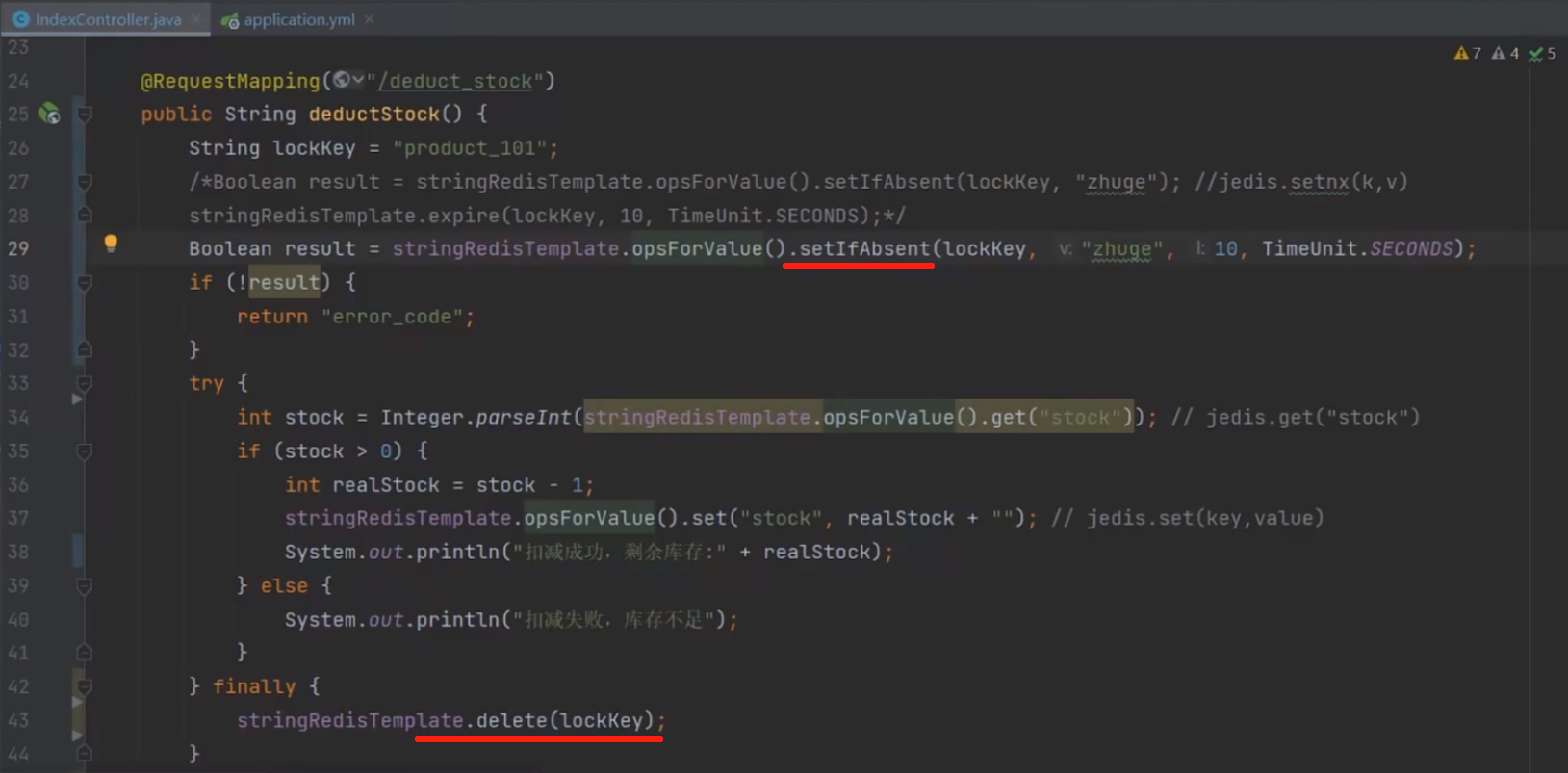
问题引入
持有锁的线程 1 出现阻塞,导致锁超时自动释放
线程2 请求获取锁,成功获得锁并开始执行业务逻辑
线程 1 唤醒,继续执行业务逻辑并删除锁 (误删其他线程的锁)
核心思路 :key 作为锁,value 用来标识是属于哪个进程的锁
解决方案
存入锁时,value 中放入当前线程的标识(声明锁的主人)
删除锁时,判断当前锁的 value 是否包含当前线程的标识(检查是否由主人自己解锁)
锁属于当前线程 → 删除
锁不属于当前线程 → 拒绝删除
原子性问题
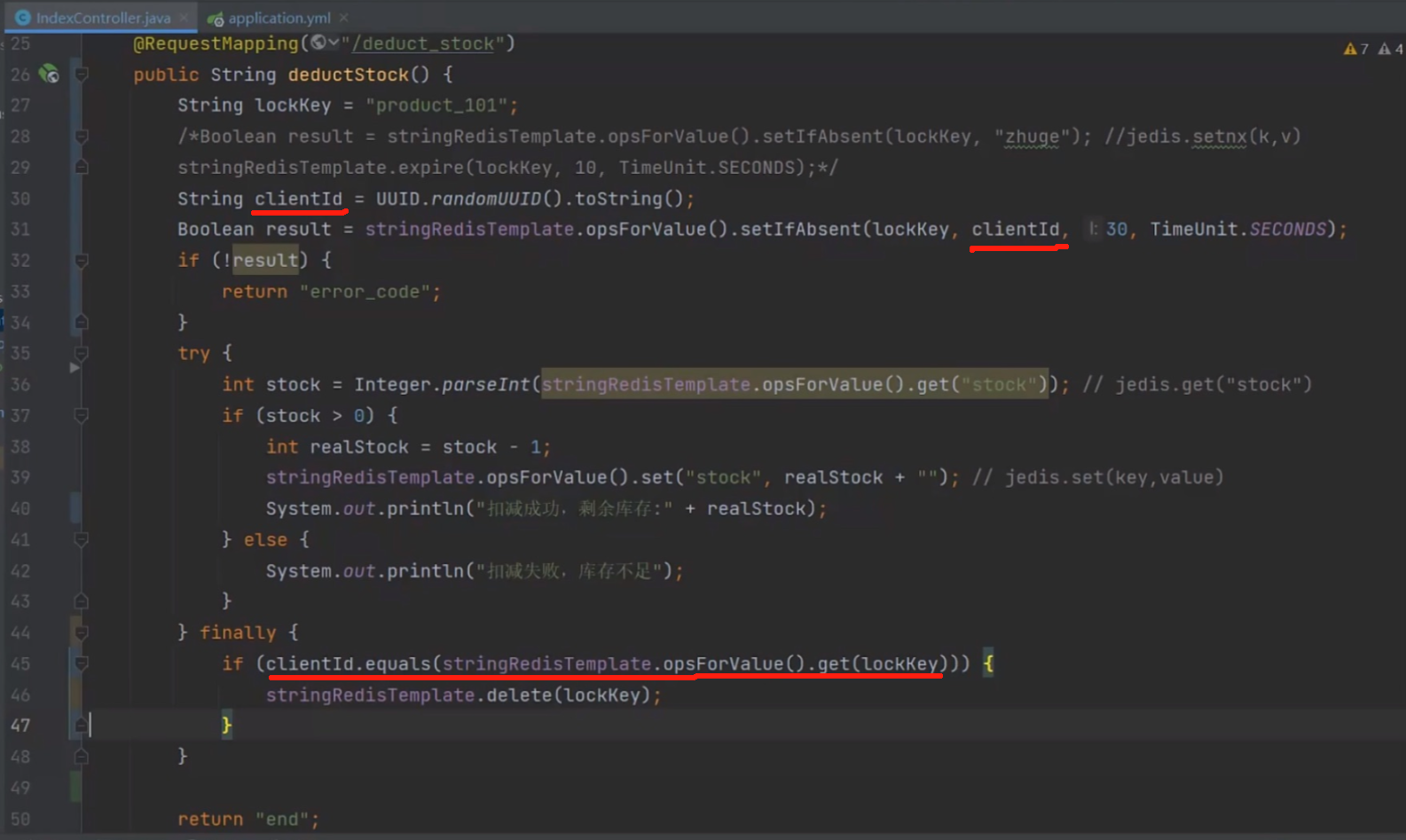
问题引入
线程 1 持有锁并执行业务逻辑后,已经判断锁属于自己(上面第45行已经执行完,还未执行第46行)
线程1准备删除锁,但是此时锁过期
线程2请求获取锁,获取锁成功
线程1继续执行删除锁逻辑(开始执行第46行) (误删其他线程的锁)
核心思路 :通过 Lua 脚本保证 “判断锁” 与 “删除锁” 的原子性Redis 的调用函数:redis.call('命令名称', 'key', '其它参数', ...)
可重入问题
锁过期问题
通过看门狗机制,实现锁续命
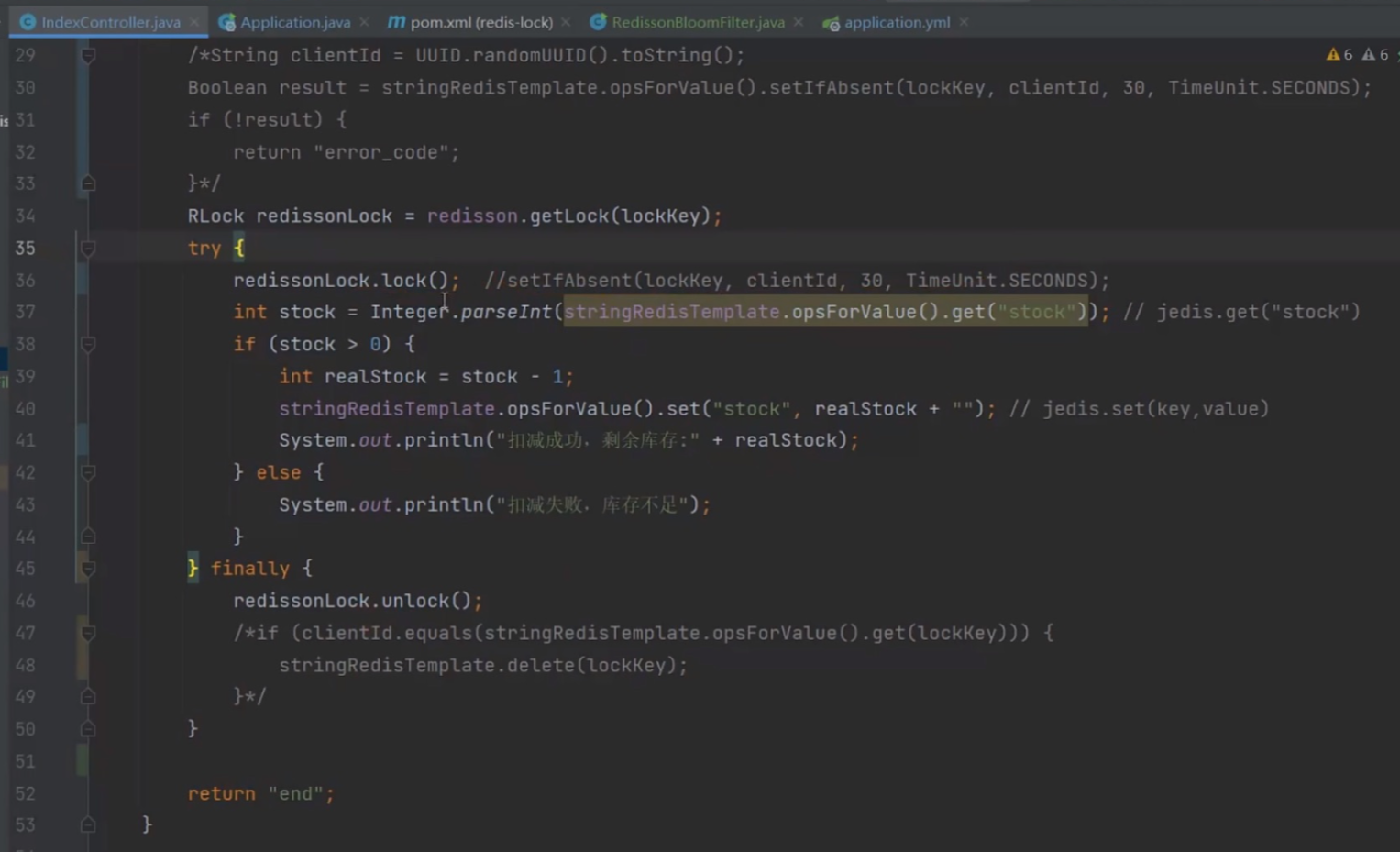
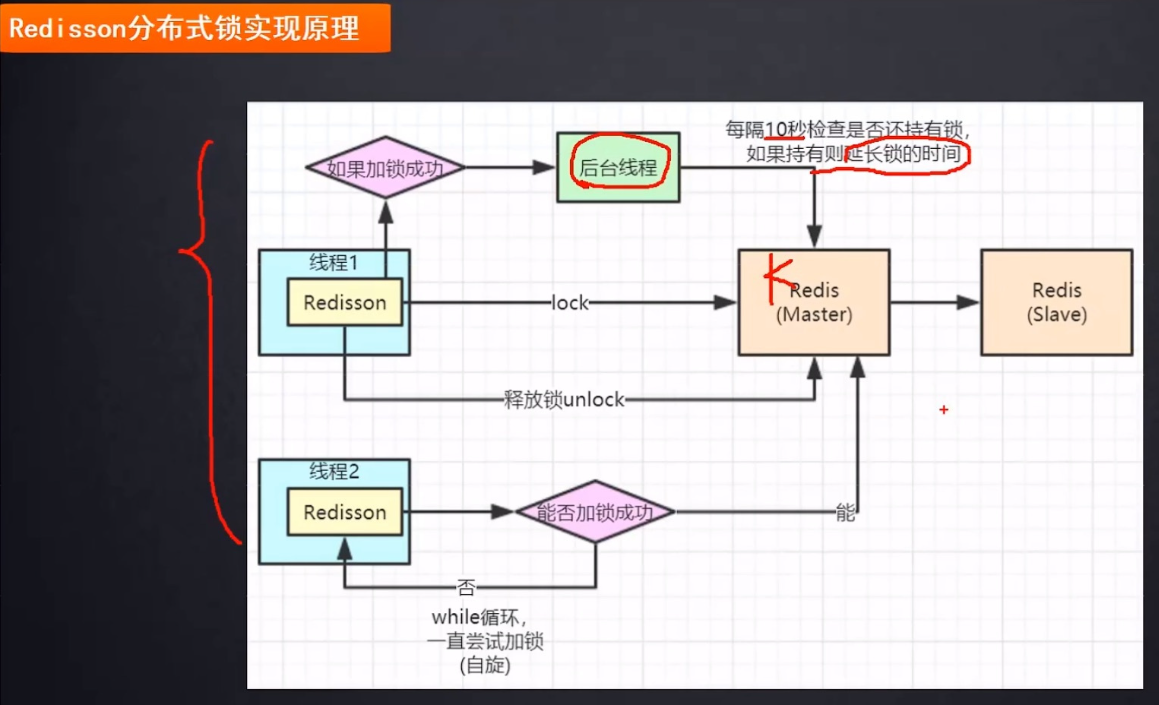
单独开一个线程,如果主线程任然在执行业务逻辑没释放锁,但是锁的过期时间快到了,则异步线程会延长锁的过期时间,也即为锁续命。
分布式读写锁
Redisson内部还实现了读写锁
原理
用hset命令,加一个mode ,mode有两个值read和write,如果加锁时,发现mode值为read,那么如果下一个请求进来,也是请求read,也可以放行。
如果下一个请求进来,是write,则该请求也要阻塞。
锁优化的最基本的优化原则:缩小加锁的粒度
锁优化的核心优化原则:分而治之(分段锁)比如某个库存key,并发太好,则把该库存分个10份,每一份对应一个key
参考连接:⭐Redis - 手动实现分布式锁 & Redisson 的使用_redisson java手动加载-CSDN博客
排行榜
利用redis的sorted set实现分数的排行榜,包含全局排行榜和每个人的朋友圈步数排行榜
利用redis的hmset,也就是hash结构,来存储每个用户的User对象信息(大对象包含不同字段)
利用zinterstore/zunionstore等命令(取交集/并集),实现最近7天,最近一个月之类的排行榜需求
凉了呀,面试官叫why哥设计一个排行榜。
高可用
哨兵机制
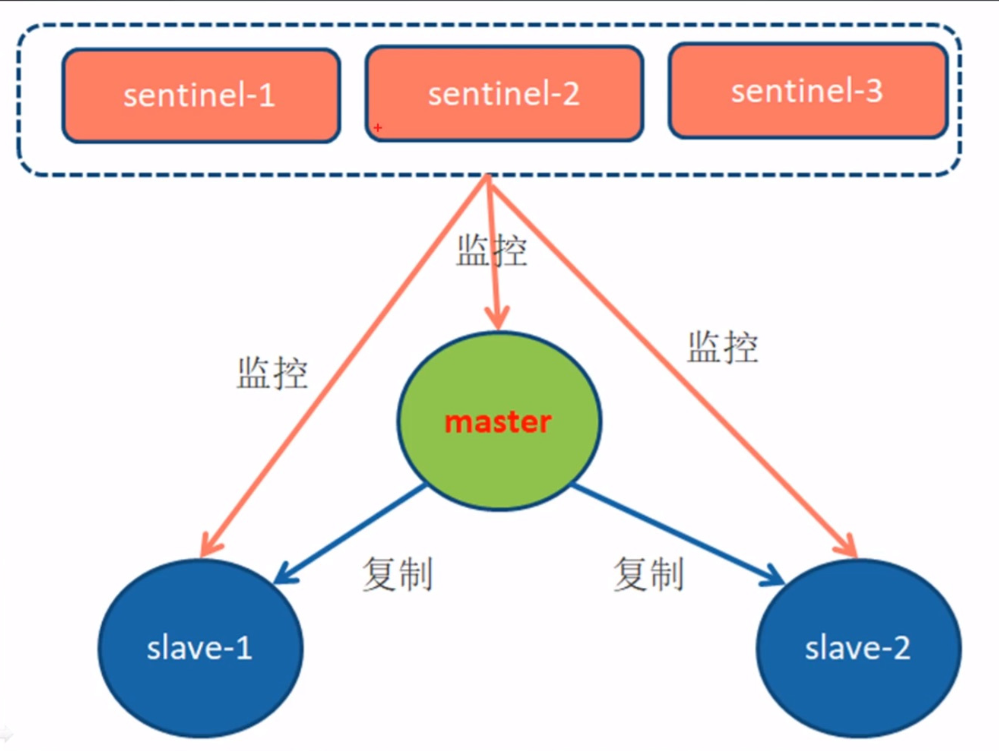


面试官内心os:你是真懂redis啊_哔哩哔哩_bilibili
服务恢复
线上 Redis 挂了,然后所有请求打到数据库导致数据库也挂了,此时该怎么恢复
1)服务挂还能怎么恢复,当然是重启服务啊。站在运维人员的角度,当然优先考虑是先把 Redis 和数据库服务重新启动起来啦。但是启动之前得先做个小操作,把流量摘掉,可以先把流量拦截在入口的地方,比如简单粗暴的通过 Nginx 的配置把请求都转到一个精心设计的错误页面,就是说这么一个意思。这样做的目的是为了防止流量过大,直接把新启动的服务,启动一个打挂一个的情况出现。
要是启动起来又扛不住了,请在心里默念分布式系统三大利器:缓存,拆分,加钱
缓存预热的角度答一个。
2)当 Redis 服务重新启动后,通过程序先放点已知的热点 key 进去后,系统再对外提供服务,防止缓存击穿的场景。
3)开发同学最多就是在设计服务的时候做到服务无状态,以达到快速水平扩容的目的
缓存击穿,缓存穿透,缓存雪崩
当周杰伦把QQ音乐干翻的时候,作为程序猿我看到了什么?
扩展
因为缓存与数据源之间的操作做不到原子性,导致数据不一致性,为了做一个兜底防止缓存中的数据与数据库中的数据长期保持不一致,一般都会给缓存加一个过期时间
经典面试题,大厂几个巧妙的方案,复杂高并发系统缓存设计
场景一
某业务需要缓存预热,系统启动部署时,把大量的key设置了同样的过期时间,如果刚好过了这个过期时间点,大量的请求打到数据库,这就是缓存雪崩
解决方案,就是设置过期时间 = 固定时间间隔 + 随机数
场景二
缓存穿透,就是查数据库时如果没有查到就在redis中放一个null值,但是大量null值会撑爆redis内存,这时八股文会说用布隆过滤器,但是布隆过滤器解决数据删除是一个问题
关键点还是要,从根本上排查为啥上游会有查null key的,这才是正确方向
场景三
某个热key失效后,大量请求打进数据库,就是缓存击穿
比如有某一个慢sql在平时不会执行,如果某个热key失效后,大量的请求查不到缓存,才会执行这个sql,这个慢sql就会把系统拖死
- 解决方案,成熟的解决方案就是把DB的执行当成一个临界资源,抢到锁的才能去执行DB
- 锁又分为单机锁和分布式锁,分布式锁才能保证整个集群只有一个请求达到数据库,而单机锁则是每次最多能放进来集群机器数N的请求进来
没抢到锁的请求,如何处理
- 拿不到锁,就阻塞等待(这种策略不可取,容易拖死系统,因为无法确定阻塞时间多长,阻塞时,会不会大量的请求把RPC连接池打爆)
- 返回默认值:设置key/value时,在value中加一个字段,这个字段就是逻辑的过期时间,代码每次查询到缓存后,去判断一下这个时间,如果这个时间当前已经过期,则去抢分布式锁查询数据库从而更新缓存、如果抢锁失败,则直接返回这个逻辑上过期的value值(这其实也是一种弱一致的解决方案)