深度学习——yolo学习
文章目录
- 一、yolov1
- 1.1基本概念
- 1.2原理介绍
- 1.3网络结构
- 1.4后处理
- 二、yolov2
- 2.1网络结构与改进
- 2.2总结
- 三、yolov3
- 四、yolov4
- 4.1网络结构
- 4.2优化策略
- 4.3IoU Loss
- 五、Yolov5
- 六、总结
参考视频:
论文精读https://www.bilibili.com/video/BV1jP4y197JZ?spm_id_from=333.788.player.switch&vd_source=67ba3568cbf6ea1d930339cd0f2092ba&p=5理论讲解https://www.bilibili.com/video/BV1yi4y1g7ro?spm_id_from=333.788.videopod.episodes&vd_source=67ba3568cbf6ea1d930339cd0f2092ba
一、yolov1
1.1基本概念
yolo(you only look once)是 单阶段目标检测算法,提出于 2016 年,由 Joseph Redmon 等人提出。
与传统方法(如 R-CNN 系列)不同:
- 不需要生成
候选区域(Region Proposals) - 传统方法多是重新利用分类器执行检测任务,yolo将目标检测视为
回归:【图像像素】——>【边界框坐标和类别概率】- 分类(Classification):核心是判断目标属于哪个预定义的类别,输出的是离散的类别标签或属于各类别的概率。例如传统检测方法(如 R-CNN)中,对生成的候选区域使用分类器判断其是否为目标及属于哪一类,输出的是 “猫”“狗” 等类别或对应的概率值。
- 回归(Regression):则是预测连续的数值,目标是让预测值尽可能接近真实的数值标签。YOLOv1直接预测边界框的坐标(x、y、w、h)等连续数值,以及反映边界框准确性的置信度(连续值),这些预测均通过网络输出连续的数值结果,而非离散的类别判断。
- 无需复杂的检测流程,整个检测流程是
单个网络,可直接针对检测性能进行端到端优化
1.2原理介绍
- Step1:它把图像划分成S×SS×SS×S的网格,若物体object中心落在某个网格单元内,
该网格单元就负责检测这个物体,需要预测该物体的边界框位置、置信度以及所属类别等信息。
- 在一张没有任何物体的空白图像中,所有网格单元都没有物体中心落入,则它们都不需要检测物品。
- 在包含少量物体的图像中,只有物体中心所在的少数网格单元需要检测对应的物品,其余网格无需检测。
假设图像中有 3 个物体,那么理论上只有 3 个网格会主动负责预测这些物体。
7*7=49个网格最多检测49个物体。

- Step2:
这个网格需要预测B个边界框,从不同角度猜测物体可能的位置、大小、可靠性。每个边界框包含:
位置(x,y):边界框中心点相对于【当前网格左上角】的偏移量,取值范围 [0,1]。
大小(w,h):边界框宽度和高度相对于【整张图片】的宽高比例,取值范围 [0,1]。
可靠性confidence:预测框是否包含目标以及框准不准。 confidence=P(object)×IOUpredtruthconfidence = P(object)×\text{IOU}_{\text{pred}}^{\text{truth}}confidence=P(object)×IOUpredtruthPr(Object)\text{Pr(Object)}Pr(Object):这个边界框里 “有物体的概率”,网格里没物体时值趋近 0;有物体时值接近 1 。
IOUpredtruth\text{IOU}_{\text{pred}}^{\text{truth}}IOUpredtruth:预测框和真实物体框的交并比。
如下图所示:假设有检测框的中心在图片中文位置是(200,150),宽度192,高度128。
- 则对于448*448的图片,被划分成7*7的网格,每个网格的大小是64*64。
- 中心点所在网格的坐标是(192,128)。由该网格负责检测当前物品。
- 相对于网格的偏移量:x=(200-192)/64=0.125。y=(150-128)/64=0.344。
- 相对与整张图片:w=192/448=0.429。h=64/448=0.286
- 因此(x, y, w, h) = (0.125,0.344,0.429,0.286)

- Step3:上述两步只知道框内有物品,但不知道物品是什么,因此
网格还需要预测C个物品的条件类别概率。网格内有物体的条件下,属于各类别的可能性=Pr(Classi∣Object)网格内有物体的条件下,属于各类别的可能性=\text{Pr(Class}_i | \text{Object})网格内有物体的条件下,属于各类别的可能性=Pr(Classi∣Object)- CCC 代表数据集中的类别总数,PASCAL VOC 数据集有 20 类,则C = 20。iii 指第 iii 类。
- 因此这个网格会输出 “属于狗的概率、属于自行车的概率、属于汽车的概率……” 等 20 个值。
- Step4:把 “边界框(位置、大小)、置信度(有物体且框准 )、类别概率(物体是啥 )” 三者结合,通过公式可得最终的概率为:
score=Pr(Classi∣Object)×P(Object)×IOUpredtruth=Pr(Classi)×IOUpredtruthscore=\text{Pr(Class}_i |\text{Object})×P(Object)×\text{IOU}_{\text{pred}}^{\text{truth}} =\text{Pr(Class}_i)×\text{IOU}_{\text{pred}}^{\text{truth}}score=Pr(Classi∣Object)×P(Object)×IOUpredtruth=Pr(Classi)×IOUpredtruth- 就能得到:
这个框里有一个物体,它属于【类别概率最大的】一类,概率是【类别概率与边界框置信度的乘积】,还能在图像中准确定位并标记出物体的位置和范围。
1.3网络结构
YOLOv1 网络的主要结构如下:
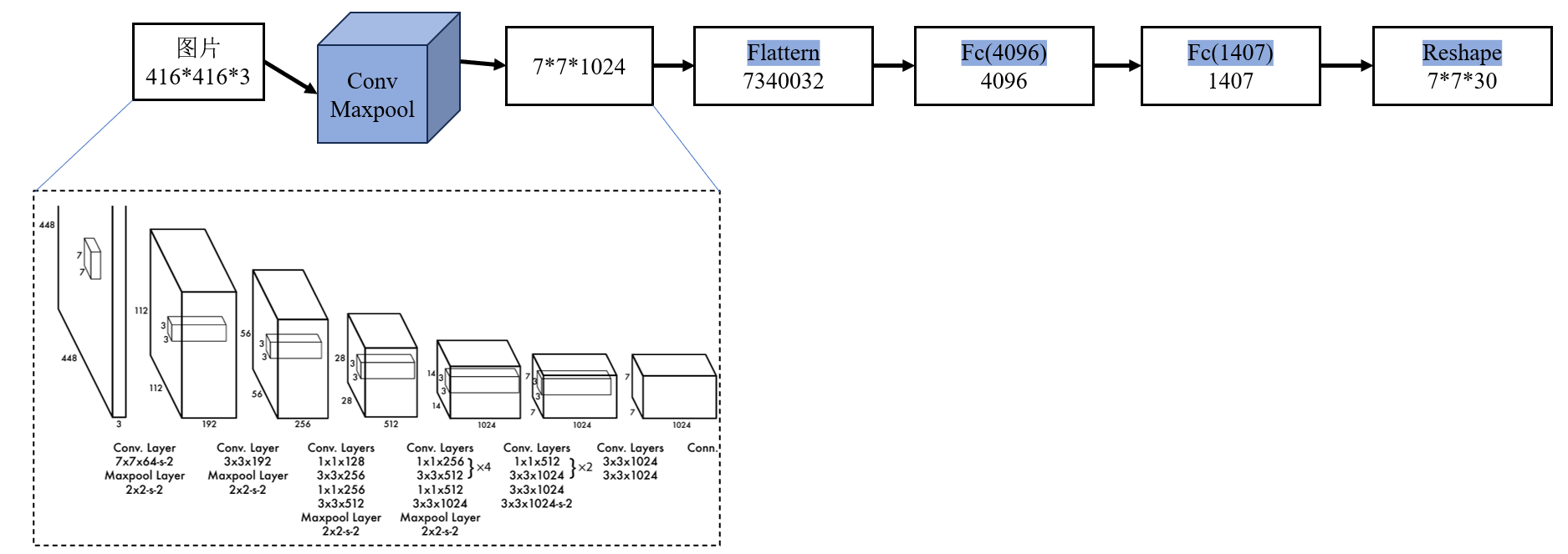
输入:固定尺寸图像,如 448×448×3特征提取层(Convolutional Backbone):类似 GoogLeNet 的卷积层组合,提取图像特征并进行空间压缩。检测层(Detection Layer):全连接层输出 S×S×(B×5+C),将卷积特征映射到边界框坐标 + 类别概率。输出:图像划分为 S×S 网格,每个网格预测 B 个边界框和对应的置信度(4+1),每个网格预测类别概率 C。输出张量:S×S×(B×5+C)。【S=7,B=2,C=20,最终输出的特征图大小7*7*30】

| 公式 | 含义 |
|---|---|
| S × S | 网格数 |
| B × 5 | 回归输出(边界框位置、大小、置信度) |
| C | 分类输出(类别概率) |
YOLO 把回归和分类放在同一输出向量中,并用不同损失函数训练。训练时同时优化回归和分类损失,使网络同时具备 定位能力和识别能力
- 回归任务:全连接层的部分节点用于输出连续的边界框坐标和置信度,使用 MSE 作为损失函数。
- 分类任务:同一全连接层的另一部分节点输出类别概率,使用平方误差。
Loss=坐标回归损失+置信度损失+类别损失Loss=坐标回归损失 + 置信度损失 + 类别损失Loss=坐标回归损失+置信度损失+类别损失
1.4后处理
在 YOLO 得到检测框(bounding box)、置信度和类别概率之后,还需要做一些 后处理操作 来得到最终可用的检测结果。
阈值过滤(Confidence Thresholding):去掉置信度低的预测框,减少误报
- 设定置信度阈值。只保留 confidence × class probability > threshold 的框
- 举例说明:如下图有5组数据,如果我们设 阈值 = 0.3,则只保留置信度 ≥ 0.3 的框:
- 保留下来的框:1、3、5
- 被删除的框:2、4
| 框编号 | 类别 | Score |
|---|---|---|
| 1 | 猫 | 0.85 |
| 2 | 猫 | 0.20 |
| 3 | 狗 | 0.60 |
| 4 | 猫 | 0.10 |
| 5 | 狗 | 0.90 |
非极大值抑制(NMS, Non-Maximum Suppression):YOLO 每个网格可能预测多个边界框,多个框可能 重叠预测同一个目标,NMS 的作用是 保留置信度最高的框,去掉重复框。
- 对每个类别的预测框按 score 排序。
- 从置信度最高的框开始,依次计算该框与其他框的 IoU。IoU 大于阈值(如 0.5)则删除重复框
- 剩下的框作为最终输出。保留框数量由 IoU 阈值和预测重叠情况决定。
假设现在阈值过滤后剩下了 4 个框预测 同一只猫:
| 框编号 | Score | 坐标 |
|---|---|---|
| A | 0.9 | (100,100,200,200) |
| B | 0.85 | (110,110,210,210) |
| C | 0.7 | (300,300,400,400) |
| D | 0.6 | (320,320,420,420) |
NMS 阈值 IoU = 0.5:
- 排序 → A > B > C > D
- 遍历 A → 保留 A
- IoU(A,B)=0.7 > 0.5 → 删除 B
- IoU(A,C)=0 → 保留 C
- IoU(A,D)=0 → 保留 D
- 遍历 C → 保留 C
- IoU(C,D)=0.6 > 0.5 → 删除 D
- 最终保留框:A, C
类别选择:对每个预测框,选择 概率最高的类别。也可以根据具体任务只保留感兴趣的类别。
边界框调整:YOLO 输出的 x,y,w,h 是 归一化到网格/图像的相对值,将其转换为 实际图像坐标。

二、yolov2
2.1网络结构与改进
1、Batch Normalization(批归一化):
每个卷积层后都加 BN(卷积→BN→激活函数)移除了 dropout,对输入特征进行归一化(均值 0、方差 1),避免某层输出值过大导致梯度消失。
2、High Resolution Classifier(高分辨率分类器)
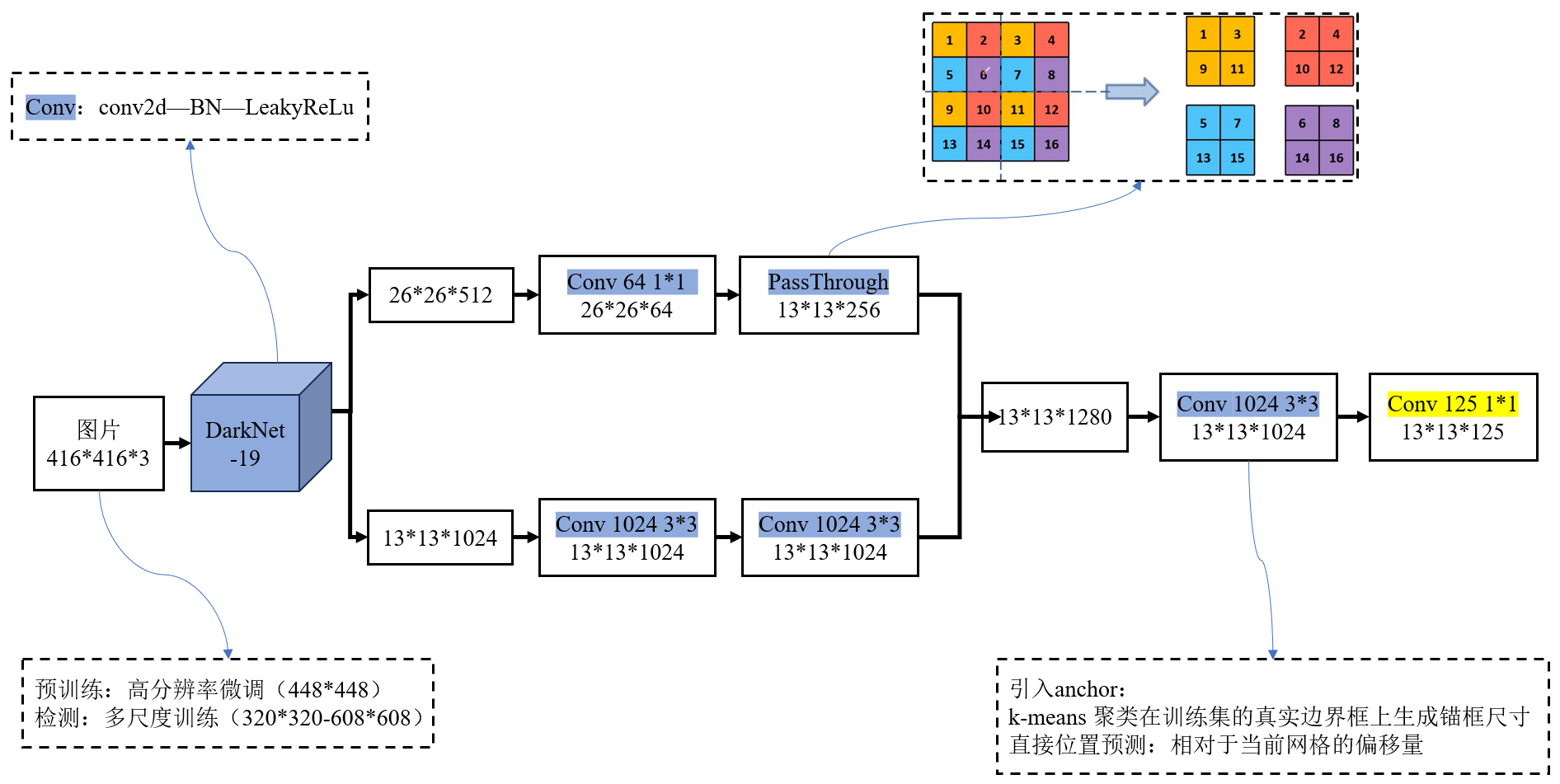
- YOLOv1 在 ImageNet 数据集上使用 224×224 分辨率预训练分类网络。
但在检测任务中直接切换到 448×448 分辨率,这种分辨率的突然提高,使模型需要适应新的输入分布。 - YOLOv2提出了一个很简单但有效的办法:
- 低分辨率预训练(224×224):首先在ImageNet 分类数据集上用 224×224 的低分辨率图像训练 。
- 高分辨率微调(448×448):在低分辨率预训练完成后,保持网络结构不变,改用448×448 的高分辨率图像在 ImageNet 上继续训练 10 个 epoch(少量迭代)。
- 迁移到检测任务(416×416):完成高分辨率分类器训练后,将网络迁移到检测任务,并将输入尺寸调整为 416×416(32 的倍数,确保下采样后特征图尺寸为整数)
输入分辨率提高(如 416×416,步长 32),S=416/32=13S=416/32=13S=416/32=13(13×13 网格),网格更密集,更利于小目标检测。
3、Convolutional With Anchor Boxes(去全连接 + 引入锚框)
- 全连接层的参数量由输入尺寸决定(如 448×448 特征图 flatten 后维度固定),导致模型只能处理固定尺寸图像。
- YOLOv1 每个网格只能预测 2 个边界框,而且只能对应一个物体,限制太死,直接预测边界框的坐标(x, y, w, h)对网络要求高
- YOLOv2 引入类似 Faster R-CNN 的 anchor boxes,
每个网格单元预测多个边界框(通常 5 个)。不再直接预测边界框的绝对坐标,而是预测 相对 anchor 的偏移量。这样模型不需要学从零开始画框,而是微调几个预设框,收敛更快,泛化更好。Anchor Boxes(锚框)是指预先定义一系列不同尺寸和宽高比的 “模板框”,网络只需要学习这些模板框的偏移量,而非直接预测坐标。就像裁缝先准备几种标准尺码的衣服(锚框),再根据顾客体型微调(偏移量)。- YOLOv2 的最终输出是一个三维张量,格式为:
S×S×(B×(4+1+C)),与YOLOv1不同的是,每个锚框都有对应的偏移量、置信度与目标类别。
4、Dimension Clusters(维度聚类)
使用 k-means 聚类算法在训练集的真实边界框上生成锚框尺寸,而非人工设定。
但是传统 k-means 使用欧氏距离(Euclidean distance),这种方式会倾向于选择大尺寸的框(大框的欧氏距离更大),而目标检测中更关注锚框与真实框的交并比(IOU),因此度量方式发生变化:当锚框与真实框的 IOU 越大,距离越小(越相似)。
距离=1−IOU(锚框,真实框)距离 = 1 - IOU (锚框,真实框)距离=1−IOU(锚框,真实框)
5、Direct location prediction(直接位置预测)
Faster R-CNN 通过预测四个偏移量(tx,ty,tw,th)(t _x,t _y, t _w,t _h)(tx,ty,tw,th),来实现从锚框到目标框的修正,其中中心坐标的偏移公式为:
tx=xg−xawa,ty=yg−yaha,tw=log(wgwa),th=log(hgha)t_x = \frac{x_g - x_a}{w_a}, \quad t_y = \frac{y_g - y_a}{h_a}, \quad t_w=log(\frac{w_g}{w_a}),\quad t_h=log(\frac{h_g}{h_a})tx=waxg−xa,ty=hayg−ya,tw=log(wawg),th=log(hahg)xp=tx×wa+xa,yp=ty×ha+ya,wp=wa×etw,hp=ha×ethx_p= t_x\times w_a+x_a,\quad y_p= t_y\times h_a+y_a,\quad w_p=w_a\times e^{t_w},\quad h_p=h_a\times e^{t_h}xp=tx×wa+xa,yp=ty×ha+ya,wp=wa×etw,hp=ha×eth
- 锚框(Anchor Box)A=(xa,ya,wa,ha)A=(x _a,y _a, w _a,h _a)A=(xa,ya,wa,ha)
- 预测的边界框(Predicted Box)P=(xp,yp,wp,hp)P=(x _p,y _p, w _p,h _p)P=(xp,yp,wp,hp)
- 真实目标框(Ground Truth Box)G=(xg,yg,wg,hg)G=(x _g,y _g, w _g,h _g)G=(xg,yg,wg,hg)
YOLOv2中预测每个边界框的参数,包括:边界框中心相对于网格的偏移量(tx,ty)(t_x, t_y)(tx,ty)边界框宽高相对于锚框的缩放因子(tw,th)(t_w, t_h)(tw,th)边界框的置信度(confidenceconfidenceconfidence)【偏移量的目标值是 “网格内的相对位置”】:
bx=σ(tx)+cx,by=σ(ty)+cybw=pw×etwbh=ph×ethb_x=σ(t_x)+c_x ,\quad b_y=σ(t_y)+c_y\quad b_w=p_w \times e^{t_w} \quad b_h=p_h \times e^{t_h} bx=σ(tx)+cx,by=σ(ty)+cybw=pw×etwbh=ph×eth
Confidence=σ(tc)Confidence=σ(t_c)Confidence=σ(tc)
- cx,cyc_x,c_ycx,cy:图像被划分为 S×SS×SS×S 个网格,第 iii 行第 jjj 列的网格左上角坐标为(cx,cy)=(i,j)(c_x,c_y)=(i,j)(cx,cy)=(i,j)
- pw,php_w, p_hpw,ph:预定义锚框的宽和高(维度聚类从训练数据中得到)
- bx,by,bw,bhb_x, b_y,b_w, b_hbx,by,bw,bh::预测边界框的中心坐标、实际宽度、实际高度。
6、Fine-Grained Features(细粒度特征)
YOLOv2 通过添加 passthrough 层来获取细粒度特征:
- 主干网络(Darknet-19)第 13 层输出的特征图大小是 26×26×512(低层特征,空间分辨率高),经过卷积层之后大小变成262664。
- 最后检测层使用的特征图是 13×13×1024(高层特征,语义强但空间分辨率低)。
Passthrough 操作:
- 先取出 26×26×64 特征图。每 2×2 的邻域像素块拉平成一个向量,相当于把分辨率缩小一半:从 26×26×64 → 13×13×256。
- 再把这个 13×13×356 特征图与 13×13×1024 高层特征 拼接:得到 13×13×3072 的特征图用于预测。
这种跨层链接的方式类似于残差网络的思想,通过融合不同层次的特征,让网络能够利用到更多的细节信息。
7、Multi-Scale Training(多尺度训练)
设网络的总下采样步长(stride)为 32(Darknet-19:5 次 2×2 池化 → 2⁵=32)。
- 候选输入尺寸取自区间 [320,608] 且必须是 32 的倍数:{320,352,384,…,608}。
- 每隔固定迭代数(10 个 iteration)随机挑一个尺寸作为新的输入大小,对接下来若干个 mini-batch 都用这个尺寸训练。随输入变化:
- 网格大小S也会跟着变:S=inputsizestrideS=\frac{input_size}{stride}S=strideinputsize。例如:320→10,416→13。直观上网络被反复“拉伸/压缩”去看同一批次分布的图像,让卷积核学会在不同像素密度下都能找对目标。
- 真实框(GT box)标签通常以归一化形式存储:(x,y,w,h)∈[0,1],当你把图像 resize 到新尺寸时,GT 的归一化坐标不变(因为它永远是“相对比例”)。
- 输出网格与回归目标:最终预测发生在 S×S 的网格上(训练时会把目标中心映射到对应的网格单元(例如 x*S,y*S),这一步随 S 自动变化,无需你手动改标签,只要用归一化坐标去计算即可。
- 维度聚类得到的 anchors 通常以像素为单位、相对某个基准输入尺寸(如 416)得到。当训练切换到新输入尺寸 时,要对 anchors 做等比例缩放。
8、Darknet-19 网络
| 对比项 | YOLOv1 主干网络 | YOLOv2 主干网络 |
|---|---|---|
| 网络名称 | 基于 GoogLeNet 的自定义网络 | Darknet-19 |
| 层数 | 24 层卷积层 + 2 层全连接层 | 19 层卷积层(无全连接层) |
| 卷积层 | 仅用 3×3 卷积 | 引入 1×1 卷积降维 |
| 池化层 | 5 层最大池化(步长 2,总下采样 32 倍) | 5 层最大池化(步长 2,总下采样 32 倍) |
| 全连接层 | 包含 2 层全连接层(输出边界框和类别) | 无全连接层,全卷积设计 |
2.2总结
| 类别 | 改进点 | 作用 |
|---|---|---|
| 网络结构改进 | Darknet-19 网络 | 网络主架构 |
| Batch Normalization | 提升收敛和准确率 | |
| 特征提取改进 | High Resolution Classifier | 提升小目标感知 |
| Fine-Grained Features | 融合浅层特征,改善小目标检测 | |
| 检测机制改进 | Convolutional With Anchor Boxes | 引入 anchor,提高 recall(找全) |
| Dimension Clusters | 聚类生成 anchor,更合理匹配 | |
| Direct Location Prediction | 预测相对偏移,增强稳定性 | |
| 训练策略改进 | Multi-Scale Training | 提升多尺度泛化能力 |
| 锚框 | 输入 | 输出 |
|---|---|---|
| 锚框的确定 | 训练集上,基于原始图片的真实框,执行k-means 聚类 | 得到 5 种锚框尺寸(宽*高)【归一化后】 |
| 锚框的使用 | 输入图片经过 Darknet-19 网络提取特征后,得到最终的 13×13 特征图(416×416 输入下) | 图片被划分为 13×13 个网格。每个网格都要分配 5 个预设的锚框 |
| 锚框的稳定 | 直接位置预测 | 不直接预测边界框的绝对坐标,而是预测锚框的偏移量 |
三、yolov3
参考博文与部分图来源:https://blog.csdn.net/qq_37541097/article/details/81214953链接
YOLOv3的网络结构图如下所示:

Step1:多尺度特征提取:YOLOv3 使用 Darknet-53 作为 主干网络,借鉴 ResNet 的残差结构(Residual Connections),训练更深的网络(53 层卷积),替代 YOLOv2 的 Darknet-19,提高了特征表达能力。
Backbone:Darknet-53:从输入到输出,每次下采样均通过步长为 2 的 3×3 卷积层实现,配合残差块的堆叠,在降低分辨率的同时保留关键特征。网络通过 5 次下采样逐步降低特征图分辨率,每个下采样阶段之间由若干残差块组成(分别为 1、2、8、8、4 个残差块)。【2+(12)+1+(22)+1+(82)+1+(82)+1+(4*2)+(全连接层)】=53。

Convolutional:Conv2d——BN——LeakyReLuResidual(残差块):ResNet(Residual Network) 的核心组件。- 在深度学习中,我们希望通过堆叠更多的卷积层来提升网络的特征提取能力。但是当网络层数过深时,会遇到两个问题:梯度消失/爆炸或能力退化问题。

- 主分支(Main Path):包含 1~2 层卷积【1×1 降维 + 3×3 提特征】,用于提取特征并输出 “残差”(输入与输出的差异)。
- 捷径分支(Shortcut Path):直接将输入特征图跳过主分支,与主分支的输出相加(元素级加法),形成 “残差连接”。
- 在深度学习中,我们希望通过堆叠更多的卷积层来提升网络的特征提取能力。但是当网络层数过深时,会遇到两个问题:梯度消失/爆炸或能力退化问题。
以输入 416×416 为例,主干(Darknet-53)总下采样 32 倍,得到这三层:
| 预测层 | 特征图尺寸 | 主要负责 |
|---|---|---|
| Scale-1 | 52×52 | 小目标 |
| Scale-2 | 26×26 | 中目标 |
| Scale-3 | 13×13 | 大目标 |
Step2:多尺度特征融合。YOLOv3 借鉴了 FPN(Feature Pyramid Network特征金字塔网络) 的思路(自顶向下 + 横向连接 的特征融合)。
- 先从最深层得到高语义、低分辨率特征(13×13) → 第一次预测。
- 将(13×13)上采样成(26×26),与更浅层的(26×26)特征拼接,卷积融合 → 第二次预测。
- 将(26×26)上采样成(52×52),与更浅层的(52×52)特征拼接、卷积融合 → 第三次预测。


Step3:多尺度预测输出
- 训练前对所有 GT 的 (w,h) 做 k-means(IoU 距离) 聚类 得到 9 个 anchors。
- 把 9 个 anchors划分为 3 组(小/中/大),分别给三层使用(每层 3 个)。
- 在某个尺度做预测时,会把该层使用的 3 个 anchors 按不同尺度归一到该特征图坐标系。
- 在每一个尺度,YOLOv3 的输出 shape 都是:
S×S×[3×(4+1+C)]。所以最终输出一共有:【13×13×3 个预测框】+【26×26×3 个预测框】+【52×52×3 个预测框】。
| 特征图大小 | 锚框大小 | 预测框数量 |
|---|---|---|
| 13×13 | (10,13)、(16,30)、(33,23)(10,13)、(16,30)、(33,23)(10,13)、(16,30)、(33,23) | 13×13×3 |
| 26×26 | (30,61)、(62,45)、(59,119)(30,61)、(62,45)、(59,119)(30,61)、(62,45)、(59,119) | 26×26×3 |
| 52×52 | (30,61)、(62,45)、(59,119)(30,61)、(62,45)、(59,119)(30,61)、(62,45)、(59,119) | 52×52×3 |
Step4:尺度整合:三个尺度的预测结果会被统一处理:
- 将预测框坐标从特征图映射回原图,合并三个尺度的候选框。
- 过滤低置信度框(如置信度 < 0.5)。
- 对剩余框执行非极大值抑制(NMS),去除重叠冗余框
- 最终输出跨尺度的检测结果。
类别预测(多标签分类):
- YOLOv1、YOLOv2 使用 Softmax 分类,即每个预测框属于一个类别。
- YOLOv3 改进为 多标签分类(multi-label classification):使用 独立的 logistic 回归 来预测每个类别的概率,而不是 Softmax。适用于 多标签场景(例如一张图可能同时属于“狗”和“宠物”)。
四、yolov4
参考博文:https://blog.csdn.net/qq_37541097/article/details/123229946链接
4.1网络结构
YOLOv4 的架构分为 Backbone(主干网络)、Neck(颈部特征融合)、Head(检测头) 三部分。

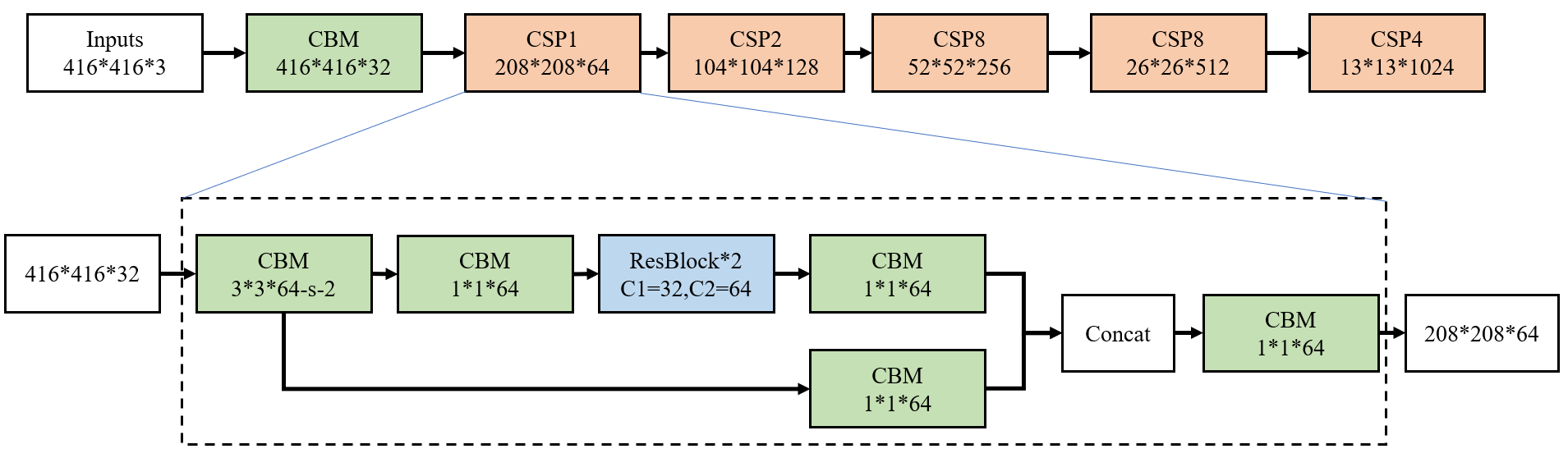
Backbone:CSPDarknet53:在YOLOv3的DarkNet的基础上,增加了CSP结构。计算量更低,减少冗余梯度流。特征表达更强,保持网络宽度和深度的平衡。精度更高,尤其在小目标检测上更有优势。
改进1:CSP(Cross Stage Partial Network)结构:
- Cross Stage(跨阶段)指的是在神经网络的不同阶段之间建立连接,使得特征能够在不同阶段之间进行传递和融合,而不是仅仅在单个阶段内进行处理。
- Partial(局部)表示将特征图分成多个部分,一部分直接传递到下一个阶段,另一部分经过一些卷积操作后再与前一部分合并,通过这种方式减少重复计算,提高计算效率,同时增强网络的学习能力和泛化性能。
- CSP 残差块(CSP Residual Block)
- 输入特征 → 沿通道分割为两部分(Part A 和 Part B):
- Part A:直接作为捷径分支,不经过任何卷积,直接传递到输出端;
- Part B:进入卷积分支,经过 1×1 卷积降维 →
多个残差子块→ 1×1 卷积升维; - 最终,Part A 与卷积分支输出通道拼接(Concat) → 1×1 卷积整合特征 → 输出。
改进2:Mish函数:其设计灵感结合了 ReLU、Swish 等函数的优点:
f(x)=x⋅tanh(softplus(x))=x⋅tanh(ln(1+ex))f(x)=x⋅tanh(softplus(x))=x⋅tanh(ln(1+ex))f(x)=x⋅tanh(softplus(x))=x⋅tanh(ln(1+ex))
- 平滑性:Mish 在全域内是连续可导的(比 ReLU、Leaky ReLU 更平滑),对反向传播更友好。
- 非单调性:Mish 在 x<0 的时候有轻微的负区间,这让网络在学习时保留了一些负值信息(类似 Swish)。
- 边界情况:当 x→−∞,softplus(x)→0,所以 f(x)→0。当 x→+∞,softplus(x)→x,tanh(x)→1,所以 f(x)→x。
| 输出特征 | 大小 | 特点 |
|---|---|---|
| 浅层特征 | (52×52×256) | 分辨率高,包含边缘、纹理等细节信息,适合小目标检测 |
| 中层特征 | (26×26×512) | 平衡细节与语义,适合中目标检测。 |
| 深层特征 | (13×13×1024) | 分辨率低,语义信息丰富(如目标类别、整体轮廓),适合大目标检测。 |
Neck:PANet【特征融合与增强】:在 YOLOv3 的、多尺度目标检测FPN(Feature Pyramid Network)的自顶向下(Top-down)+ 横向连接(Lateral connection)基础上,增加PAN(Path Aggregation Network)自底向上的特征聚合路径。不仅有 FPN 的 top-down 信息流,还增加 bottom-up 信息流。
沿用:自顶向下的FPN(特征金字塔网络)

改进:SPP(Spatial Pyramid Pooling,空间金字塔池化):SPP 通常放在 CSPDarknet53 主干网络的最后一层卷积特征图之后,送入检测头之前。
| 最大池化操作(stride=1,padding 保持尺寸不变) | 意义 |
|---|---|
| 1×1 池化 | 保留局部细节 |
| 5×5 最大池化 | 捕捉稍大的区域上下文 |
| 9×9 最大池化 | 更大范围的全局信息 |
| 13×13 最大池化 | 全局语义 |
| 拼接后的特征 | 融合不同尺度的上下文信息512*4=2048 |

改进:自下而上的PAN(路径聚合网络)
传统特征金字塔网络(FPN)的两个局限:
- 高层特征(语义强但分辨率低)向低层传递时,信息损失较多,不利于小目标检测。
- 特征融合仅单向(自顶向下),缺乏低层到高层的反馈机制,导致低层细节特征利用不充分。
因此将低层特征经过下采样后与高层特征进行融合。
- 低层融合后的特征(52×52×128,细节最丰富)通过下采样(如 3×3 卷积 + 步长 2)与中层中间特征(26×26×256)再次融合,得到26×26×256的特征;
- 该特征继续下采样与高层特征(13×13×512)融合,得到13×13×512的特征;
- 同时保留低层融合后的特征作为52×52×128的输出。

Head:检测头结构与 YOLOv3 类似(3 个尺度特征图 + 9 个锚框)。
每个分支输出的特征图中,每个通道对应特定的预测值,可拆解为:
- 每个网格点上有 3 个锚框(×3);
- 每个锚框包含:4 个边界框偏移量、1 个置信度、n个类别概率。
4.2优化策略
Bag of Freebies(训练阶段的改进技巧)&& Bag of Specials
- 骨干网络的BoF:CutMix 和 Mosaic 数据增强、、类别标签平滑
| 对比维度 | Mosaic | CutMix |
|---|---|---|
| 输入图像数量 | 4 张 | 2 张 |
| 拼接方式 | 田字形拼接(无重叠逻辑) | 裁剪替换(区域覆盖) |
| 核心目标 | 提升小目标样本与背景多样性 | 增强遮挡场景鲁棒性 |
| 适用场景 | 目标检测(尤其多尺度模型) | 图像分类、目标检测 |
- 骨干网络的BoS:Mish 激活函数、跨阶段局部连接(CSP)、多输入加权残差连接(MiWRC)
- 检测器的BoF:CIoU 损失、CmBN、DropBlock 正则化、Mosaic 数据增强、自对抗训练、消除网格敏感性、为单个真实标注使用多个锚框、余弦退火调度器 、优化超参数、随机训练尺寸
DropBlock 正则化:DropBlock 不再像 Dropout 那样随机独立地丢弃单个神经元,而是以一个连续的区域(block)为单位进行丢弃。

- 检测器的BoS:Mish 激活函数、SPP 模块、SAM 模块、PAN 路径聚合模块、DIoU - NMS
4.3IoU Loss
Focal Loss
FL(pt)=−αt∗(1−pt)γ∗log(pt)FL(p_t) = -α_t * (1 - p_t)^γ * log(p_t)FL(pt)=−αt∗(1−pt)γ∗log(pt)
- ptp_tpt 是模型对目标类别的预测概率
- 当真实标签 y=1 时,pt=pp_t = ppt=p, ;
- 当真实标签 y=0 时,pt=1−pp_t = 1-ppt=1−p,
- αtα_tαt 是平衡因子(用于解决类别不平衡问题)
- 当真实标签 y=1 时,αt=αα_t = ααt=α,
- 当真实标签 y=0 时,αt=1−αα_t = 1-ααt=1−α
- γ(γ≥0)γ(γ ≥ 0)γ(γ≥0)是聚焦参数(用于降低易分类样本的权重,聚焦于难分类样本)
IoU Loss(交并比损失)
IoU=∣A∩B∣∣A∪B∣IoU = \frac{|A \cap B|}{|A \cup B|}IoU=∣A∪B∣∣A∩B∣
其中,A和B分别表示预测边界框和真实边界框,∣A∩B∣|A \cap B|∣A∩B∣是两个框的交集面积,∣A∪B∣|A \cup B|∣A∪B∣是并集面积。
IoU Loss 可以表示为:LIoU=1−IoUL_{IoU} = 1 - IoULIoU=1−IoU
GIoU Loss(global广义交并比)
IoU作为损失函数会出现的问题:
- 如果两个框没有相交,根据定义,oU=0,不能反映两者的距离大小(重合度)。同时
因为Ioss=0,没有梯度回传,无法进行学习训练。 - IoU无法精确的反映两者的重合度大小。如下图所示,三种情况IoU都相等,但看得
出来他们的重合度是不一样的,左边的图回归的效果最好,右边的最差。

它在 IoU 的基础上,引入了最小包围框(能够同时包含预测框和真实框的最小矩形框):
GIoU Loss 表示为:LGIoU=1−GIoU=1−(IoU−∣C−(A∪B)∣∣C∣)L_{GIoU} = 1 - GIoU=1-( IoU - \frac{|C - (A \cup B)|}{|C|})LGIoU=1−GIoU=1−(IoU−∣C∣∣C−(A∪B)∣)
C表示最小包围框的面积。即上图中虚线的框。
DIoU Loss(distance距离交并比)
LDIoU=1−DIoU=1−(IoU−ρ2(b,bgt)c2)L_{\text{DIoU}} = 1 - \text{DIoU}=1-(\text{IoU} - \frac{\rho^2(b, b^{gt})}{c^2})LDIoU=1−DIoU=1−(IoU−c2ρ2(b,bgt))其中各参数含义:
- IoU\text{IoU}IoU:预测框 bbb 与真实框 bgtb^{gt}bgt 的交并比,即 IoU=∣A∩B∣∣A∪B∣\text{IoU} = \frac{|A \cap B|}{|A \cup B|}IoU=∣A∪B∣∣A∩B∣。
- ρ2(b,bgt)\rho^2(b, b^{gt})ρ2(b,bgt):预测框中心点与真实框中心点之间的欧氏距离的平方(空间距离度量)。
- ccc:能够同时包含预测框和真实框的最小包围框的对角线长度(用于归一化距离,确保尺度不变性)。
CIoU Loss(Complete完全交并比)
LCIoU=1−CIoU=1−(IoU−ρ2(b,bgt)c2−αv)L_\text{CIoU}=1−CIoU=1−(\text{IoU} - \frac{\rho^2(b, b^{gt})}{c^2}−αv)LCIoU=1−CIoU=1−(IoU−c2ρ2(b,bgt)−αv)
vvv 是宽高比的差异项,α\alphaα 是一个权重因子,用于平衡IoU项和宽高比差异项。
| 损失函数 | 核心优化目标 | 局限性 |
|---|---|---|
| IoU | 重叠区域 | 无重叠时梯度消失;对包含关系不敏感 |
| GIoU | 重叠区域 + 最小包围框面积 | 包含关系时退化为 IoU;收敛较慢 |
| DIoU | 重叠区域 + 中心点距离 | 未考虑宽高比差异 |
| CIoU | 重叠区域 + 中心点距离+宽高比差异 | 考虑因素全面 |
五、Yolov5
相较于 YOLOv3、YOLOv4,YOLOv5 最大的特点是:
- 用 PyTorch 框架实现(YOLOv4 主要基于 Darknet 框架),更易于工程应用和二次开发;
- 提供了从小到大的多个版本(n/s/m/l/x),满足不同的计算资源和精度需求;
改进1:新增 Focus 层
在网络最前端增加 Focus 层,替代传统的初始卷积层,提升特征提取效率。
- 将输入图像(如 640×640×3)按像素位置进行切片(每隔一个像素取点),得到 4 个 320×320×3 的子图。
- 拼接后形成 320×320×12 的特征图(通道数翻倍),再通过 1 个 3×3 卷积将通道数调整为 64。
改进2:CSP 模块结构
YOLOv5模块 将 CSPDarknet53 中的 CSP 模块拆分为两种变体,分别用于 Backbone 和 Neck:
- Backbone中使用 CSP1_X:将输入特征分为两部分,一部分直接传递(保留原始特征),另一部分经过X个残差块(如 CSP1_3 含 3 个残差块)。
- Neck中使用 CSP2_X 模块:取消残差连接,改用单纯的卷积 + 拼接,更侧重特征融合而非特征深化。
改进3:用 SPPF(Spatial Pyramid Pooling - Fast) 替代 SPP(高效多尺度池化)
通过 3 个连续的 5×5 最大池化(带 padding)实现与 SPP 等价的多尺度感受野(1×1、5×5、9×9)。
输入→5×5 池化→5×5 池化→5×5 池化,将结果与原始输入拼接。
六、总结
| 版本 | Backbone 结构 | 核心特点 |
|---|---|---|
| YOLOv1 | 自定义 CNN(24 层卷积 + 2 层全连接) | 首次将目标检测视为回归问题,结构简单但特征提取能力有限。 |
| YOLOv2 | Darknet-19(19 层卷积 + 1 层全连接) | 引入批量归一化(BN)、锚框(Anchor),用卷积替代全连接,提升特征复用能力。 |
| YOLOv3 | Darknet-53(53 层卷积) | 采用残差连接(Residual),加深网络深度,增强语义特征提取,支持多尺度输出。 |
| YOLOv4 | CSPDarknet53 | 引入 CSP 结构(跨阶段部分连接),减少计算量的同时保留梯度流,配合 Mish 激活函数。 |
| YOLOv5 | CSPDarknet53(改进版) | 优化 CSP 结构(CSP1_X 用于主干,CSP2_X 用于 neck),加入 Focus 层(切片操作)提升初始特征提取效率。 |
| 版本 | Neck 结构 | 核心特点 |
|---|---|---|
| YOLOv1 | 无独立 neck,直接由 backbone 输出特征 | 仅用单尺度特征(448×448→7×7),小目标检测能力弱。 |
| YOLOv2 | 无独立 neck,通过 passthrough 层融合特征 | 将高分辨率特征(13×13)与低分辨率特征(26×26)拼接,初步支持多尺度。 |
| YOLOv3 | FPN(特征金字塔网络) | 自顶向下传递高层语义特征,与低层特征融合,输出 3 个尺度(13×13、26×26、52×52)。 |
| YOLOv4 | SPP + PANet | 1. SPP 模块:多尺度池化(1×1、5×5 等)增强高层特征;2. PANet:在 FPN 基础上增加自底向上路径,强化低层细节传递。 |
| YOLOv5 | PANet(改进版)+ 卷积融合 | 沿用 PANet 双向路径,加入 SPPF(简化版 SPP)提升效率。 |
| 版本 | Head | 结构核心特点 |
|---|---|---|
| YOLOv1 | 全连接层输出 | 直接预测 7×7 网格的边界框(每个网格 2 个框)、类别和置信度,无锚框。 |
| YOLOv2 | 卷积层输出(锚框预测) | 用卷积层替代全连接,基于锚框预测偏移量,支持端到端训练。 |
| YOLOv3 | 多尺度卷积预测 | 每个尺度特征图通过 1×1 卷积输出预测(3 个锚框 / 网格),通道数为((4+1+n)×3)。 |
| YOLOv4 | 多尺度卷积预测(优化) | 沿用 YOLOv3 结构,引入 CIoU 损失、Mish 激活函数,提升边界框回归精度。 |
| YOLOv5 | 检测头与特征图解耦(可选) | 输出层与 v3/v4 类似,但支持 “解耦头”(分类和回归分支分离),提升预测效率。 |
| 版本 | 核心优化策略 |
|---|---|
| YOLOv1 | 端到端回归思想;网格划分预测目标。 |
| YOLOv2 | 锚框机制;维度聚类(k-means)生成锚框;多尺度训练(320~608)。 |
| YOLOv3 | 多尺度检测;残差网络;分类用 softmax,支持多标签预测。 |
| YOLOv4 | 数据增强:Mosaic(4 图拼接)、CutMix、自对抗训练;损失函数:CIoU Loss;正则化:DropBlock;优化器:SGD + 余弦退火。 |
| YOLOv5 | 数据增强:Mosaic、RandomAffine(随机仿射);自适应锚框计算;优化器:Adam;工程化:模型轻量化(n/s/m/l/x 版本),支持动态输入尺寸。 |