Spring相关知识
bean生命周期
好的 👍 我给你梳理一下 Spring Bean 的生命周期,并且标注出每个阶段大概会发生什么。
🌱 Spring Bean 生命周期
一个 Bean 从创建到销毁,大致会经过以下几个阶段:
1. 实例化 (Instantiation)
- Spring 根据 配置(XML/注解/JavaConfig),使用反射创建 Bean 的实例。
- 这时还只是一个“空壳对象”,属性还没被赋值。
2. 属性赋值 (Populate Properties)
- Spring 进行 依赖注入(DI),将需要的依赖(其他 Bean、配置值等)注入到 Bean 中。
- 这一步会执行 setter 方法或构造函数注入。
3. BeanNameAware / BeanFactoryAware 等回调
-
如果 Bean 实现了某些 Aware 接口,Spring 会回调这些方法:
BeanNameAware.setBeanName():告诉 Bean 它在容器中的名字。BeanFactoryAware.setBeanFactory():告诉 Bean 它的 BeanFactory。ApplicationContextAware.setApplicationContext():告诉 Bean 它的 ApplicationContext。
4. BeanPostProcessor - 前置处理
- Spring 会调用 BeanPostProcessor.postProcessBeforeInitialization()。
- 常用于对 Bean 进行一些额外加工,比如自动代理(AOP 的核心就是这里介入)。
5. 初始化 (Initialization)
- 如果 Bean 实现了 InitializingBean 接口,会调用
afterPropertiesSet()方法。 - 如果在配置中指定了
init-method,会调用对应的方法。 - 这是 Bean 完全就绪前的最后一步初始化逻辑。
6. BeanPostProcessor - 后置处理
- Spring 会调用 BeanPostProcessor.postProcessAfterInitialization()。
- 在这里可以对 Bean 进行增强(比如 AOP 代理生成就在这一步)。
7. Bean 就绪 (Ready for use)
- 到这里,Bean 就可以被应用程序使用了。
- Spring IoC 容器中的 Bean 通常是 单例,整个容器中共享一份。
8. 销毁 (Destruction)
-
当容器关闭时:
- 如果 Bean 实现了 DisposableBean,会调用
destroy()方法。 - 如果配置了
destroy-method,也会被调用。
- 如果 Bean 实现了 DisposableBean,会调用
-
这一步主要用于释放资源(关闭连接、线程池等)。
🔄 总结成一个流程图
实例化 → 属性注入 → Aware回调 → 前置处理 → 初始化 → 后置处理 → 就绪使用 → 销毁
我之前一直觉得,初始化就是对对象进行赋值和相关准备逻辑。这里属性注入,似乎也是属性的赋值,所以我才一直觉得是属性注入归于初始化
👌 你这个理解其实很自然,很多人都会混淆。
因为“初始化”这个词在日常语境里确实包含“给属性赋值”+“准备逻辑”两方面。
但是在 Spring 框架里,它做了更细粒度的拆分:
🏗️ Spring 的划分逻辑
Spring 把 Bean 生命周期拆开,是为了 更好地给开发者介入点。
-
实例化 (Instantiation)
👉 new 一个对象,还没属性。 -
属性注入 (Populate Properties)
👉 Spring 把依赖(配置值、其他 Bean)“填充”进去。
(相当于“把材料和家具搬进房子”) -
初始化 (Initialization)
👉 Spring 通知 Bean:“你的依赖已经准备好了,你可以开始做额外逻辑了”。
(比如检查依赖是否齐全、启动资源连接、预热缓存等)InitializingBean.afterPropertiesSet()@PostConstructinit-method
🏡 打个比喻
想象你装修一套房子:
- 实例化:建好房子的毛坯结构。
- 属性注入:把家具、电器都搬进房子。
- 初始化:开通水电,安装 WiFi,调试一下确保能正常住人。
如果不分开,框架就很难在合适的时机让你“介入”,也就没有 @PostConstruct 这些钩子了。
📌 关键点
-
从 Java 面向对象角度看:给对象赋值,当然可以叫初始化。
-
从 Spring 语义看:
- 属性注入 = 依赖赋值。
- 初始化 = 注入完成后,执行额外的准备逻辑。
BeanPostProcessor.postProcessBeforeInitialization()。为什么这里都是BeanPostProcessor,这里既然分为前置处理和后置处理,那么应该叫做BeanProcessor才对
👍 你抓住了一个关键点。
确实,从直觉上看:
postProcessBeforeInitialization()postProcessAfterInitialization()
既然有“前置”和“后置”,名字里却写着 Post(后置),好像应该叫 BeanProcessor 才对。
🔍 为什么叫 BeanPostProcessor?
这是因为 Spring 的命名习惯 和它的生命周期设计有关。
-
不是处理 Bean 的创建过程,而是处理 Bean 创建之后的过程
BeanPostProcessor只会在 Bean 实例化 + 属性注入完成之后 才介入。- 它不会参与
new Bean()或依赖注入的环节。 - 所以它处理的逻辑都属于 “Bean 已经创建完了(post-creation)” 的范围。
-
“BeforeInitialization / AfterInitialization” 只是两个切点
- Spring 定义的 “Initialization” = 执行初始化回调(如
@PostConstruct、afterPropertiesSet())。 postProcessBeforeInitialization():在初始化方法 调用之前 介入。postProcessAfterInitialization():在初始化方法 调用之后 介入。- 但二者都还是在 Bean 创建之后 (post) 的逻辑,所以统称
BeanPostProcessor。
- Spring 定义的 “Initialization” = 执行初始化回调(如
-
历史兼容性
- Spring 早期就把这个接口叫做
BeanPostProcessor。 - 后来虽然扩展出 “before / after” 两个切点,但为了不破坏兼容性,保持了原名。
- Spring 早期就把这个接口叫做
🏗️ 小结
BeanPostProcessor之所以叫 Post,是因为它处理的时机在 Bean 实例化 + 属性注入之后。- 它不会介入 Bean 的“构造”过程,而只处理“后加工”阶段。
- “before / after” 指的是 初始化方法的前后,不是指 Bean 创建的前后。
👉 换句话说:
BeanPostProcessor = Bean 创建完成后的加工器
- BeforeInitialization → 初始化回调前
- AfterInitialization → 初始化回调后
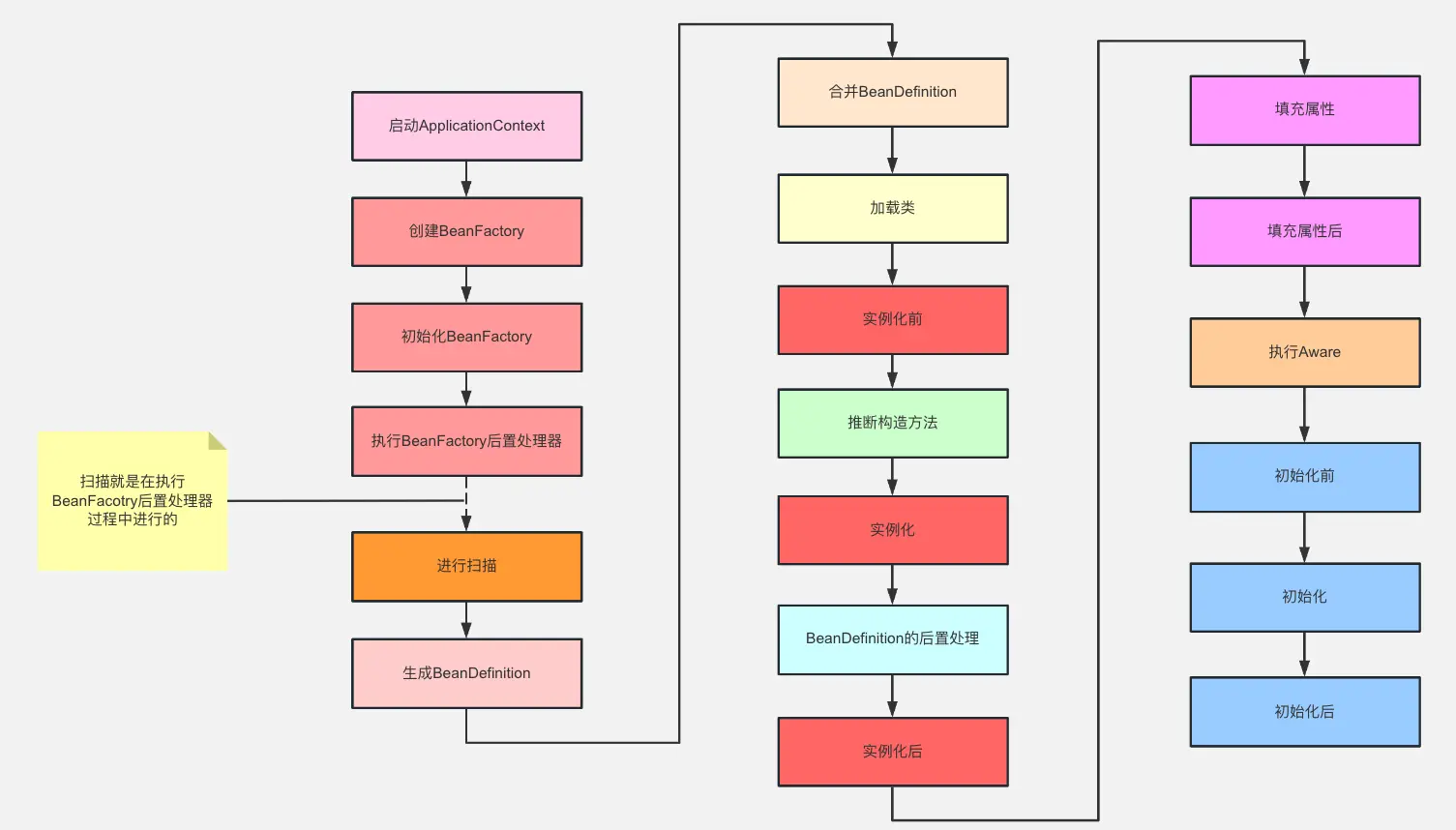
这里实例化后,之前的一些操作是什么,都讲解一下
我看了一下你发的这个图 👍,它分成了 Spring 容器启动流程 和 Bean 创建流程。你问的“实例化之前的一些操作”,就是在 实例化 (new 对象) 之前,Spring 容器对 Bean 要做的一系列准备。
我逐个解释一下图里的步骤(重点在实例化之前的环节):
🌱 容器启动阶段(ApplicationContext)
-
启动 ApplicationContext
- 你调用
new ClassPathXmlApplicationContext()或AnnotationConfigApplicationContext()的时候,Spring 容器启动。
- 你调用
-
创建 BeanFactory
- ApplicationContext 内部其实是基于
DefaultListableBeanFactory。 - BeanFactory 是最底层的 IoC 容器,负责管理 Bean 的注册和获取。
- ApplicationContext 内部其实是基于
-
初始化 BeanFactory
- 为 BeanFactory 设置一些必要的组件,比如
BeanPostProcessor、BeanFactoryPostProcessor等。
- 为 BeanFactory 设置一些必要的组件,比如
-
执行 BeanFactory 后置处理器
- 扫描、解析配置(XML/注解)就是在这里进行的。
- 例如:
ConfigurationClassPostProcessor会去扫描@Configuration、@ComponentScan,把类信息解析成BeanDefinition。
-
生成 BeanDefinition
- 扫描结果(类信息)被转换成 BeanDefinition,注册到 BeanFactory 的
beanDefinitionMap里。 - 这里还没有 new Bean,只是“元数据”。
- 扫描结果(类信息)被转换成 BeanDefinition,注册到 BeanFactory 的
🌱 Bean 创建流程(实例化之前)
当容器要创建一个具体 Bean 时,流程是:
-
合并 BeanDefinition
- 如果有父 BeanDefinition(继承关系)、注解/配置合并,Spring 会在这里整合成一个完整的定义。
-
加载类 (Load Class)
- 根据 BeanDefinition 里的 className,反射加载对应的 Class 对象。
-
实例化前(Instantiation Aware)
-
在真正 new 对象之前,Spring 会先调用一些 InstantiationAwareBeanPostProcessor。
-
比如:
- 判断是否需要用代理类替代原始类(AOP 在这一步可能就决定走代理工厂)。
- 也可以在这里“短路”,直接返回一个代理 Bean,而不是走普通的构造函数。
-
-
推断构造方法
-
Spring 会判断用哪个构造方法来实例化:
- 默认无参构造
- 有
@Autowired的构造 - 或者最匹配的构造函数
-
📌 然后才是 实例化 (new)
- 选定构造方法后,用反射创建对象 → 才进入你问的“实例化”阶段。
✅ 总结
在 实例化之前,主要做了这些事:
- 准备 BeanDefinition(配置扫描、合并)。
- 加载 class 对象。
- 调用 InstantiationAwareBeanPostProcessor → 机会点:是否要直接返回代理对象。
- 推断用哪个构造方法。
才会执行 实例化 (new)。