从数据抽取到加载:如何保障ETL中间环节的高效与稳定
在大型企业的数据集成项目中,一个常见问题是数据同步延迟。例如,某零售集团在高峰期需要实时更新库存与销售数据,但由于ETL中间环节处理效率低,导致分析报表延迟30分钟以上,直接影响决策与运营。本文面向企业IT负责人、数据架构师、后端工程师,重点解析如何在ETL(Extract-Transform-Load)流程的核心环节保障高效稳定。
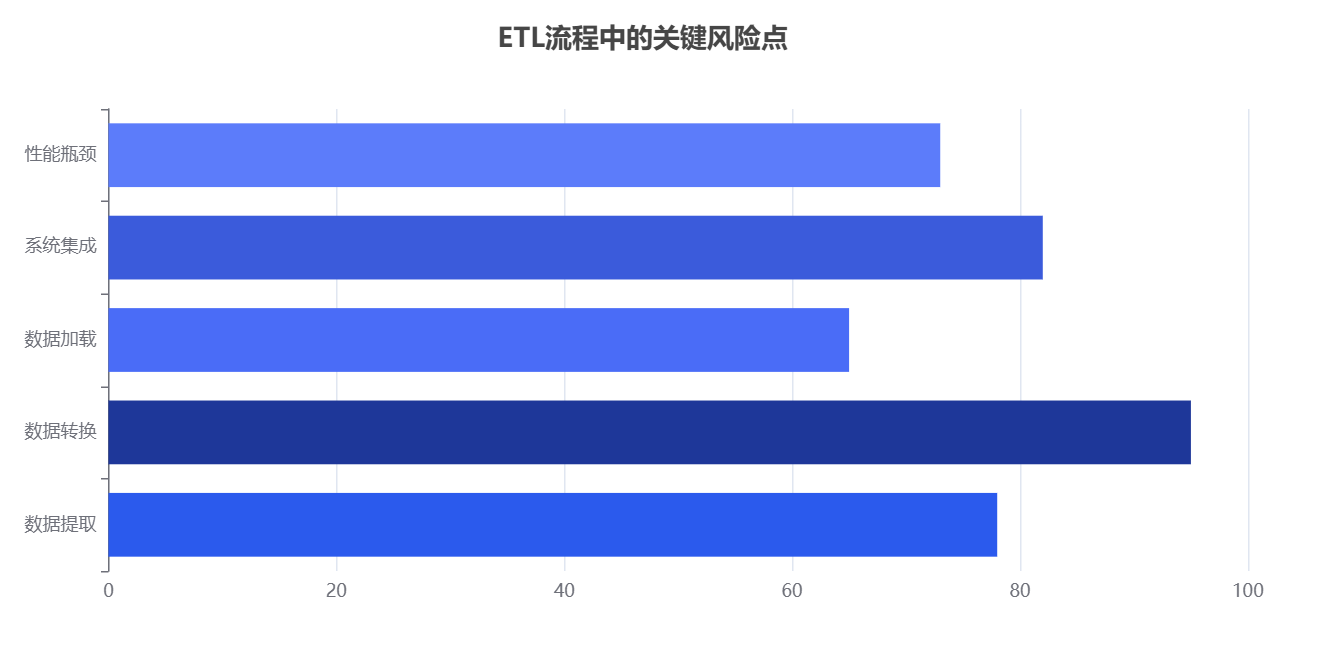
为什么ETL中间环节是性能瓶颈的高发地?
ETL的抽取与加载阶段相对可控,但数据转换(Transform)环节最易成为性能瓶颈。原因包括:
-
数据规模暴增:原始数据每天以TB级别增长,传统处理框架无法线性扩展。
-
逻辑复杂度高:业务规则频繁变更,导致SQL脚本或数据管道过于冗长。
-
缺乏资源隔离:计算资源与生产系统竞争,影响主业务稳定性。
根据IDC数据集成与分析报告(2024) ,超过63%的企业在数据集成阶段遇到性能问题,其中近一半发生在数据转换环节。
如何通过异步架构减少数据处理延迟?
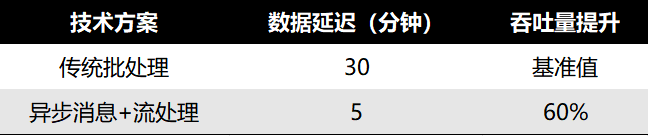
核心结论:引入异步消息队列与流处理框架,可将延迟降低50%以上。
-
步骤1:采用分布式消息队列(如Kafka)缓冲数据
消息队列可解耦上下游,提高数据接入的弹性。 -
步骤2:使用流式计算替代批处理(如Flink、Spark Streaming)
实时计算引擎支持数据边到边处理,减少等待周期。 -
步骤3:资源动态扩缩容
通过Kubernetes自动伸缩,保障高峰期处理能力。
性能对比示例:
如何确保数据转换逻辑的可维护性与可追溯性?
核心结论:使用数据血缘与元数据管理工具,可降低后期维护成本30%。
-
采用数据血缘追踪工具(如Apache Atlas)
清晰记录数据从抽取到加载的每一步变换,便于问题定位。 -
构建可视化的ETL管道(如dbt、Airflow)
通过可视化DAG(有向无环图)管理任务依赖,减少人为错误。 -
版本化管控数据模型与转换脚本
使用Git或CI/CD流程控制数据管道迭代。
如何通过监控与告警机制提前发现风险?
核心结论:实时监控指标+智能告警,可避免超过80%的生产事故。
-
关键指标:任务执行时间、失败率、数据延迟、吞吐量
-
工具实践:
-
Prometheus + Grafana 进行可视化监控
-
Airflow自带任务重试和失败通知功能
-
-
自动化运维:设置阈值触发扩容或切换备份管道
案例:某金融企业通过监控平台将ETL失败率从 2.3% 降至0.4% ,显著提升生产稳定性。
如何选择高效的ETL工具与平台?
核心结论:根据业务规模与实时性需求匹配工具。
-
中小型企业:Fivetran、dbt,低运维成本,适合快速集成。
-
大型企业/高并发:Apache Airflow、Flink,支持高度定制化与弹性。
-
混合方案:结合云原生ETL平台(如ETLCloud)与本地计算资源,实现灵活调度。
总结:稳定高效的ETL中间环节是企业数据战略的基石
要保障ETL过程高效稳定,需从架构解耦、任务可视化、元数据追踪、实时监控等多维度入手。通过异步消息队列、流式计算框架和智能运维手段,企业可显著降低数据延迟与故障率。这不仅优化了数据集成流程,也为企业实时分析与决策支持提供了保障。