第三阶段数据库-6:sql中函数,多表查询,运算符,索引,约束
0821:
1_Sql 里面常用的函数
(1)Count 计数
select Count(*) from Students;-- 返回Students表中行数
select count(distinct customer_id) from orders--不重复客户数(2)len():长度
select len('张三')--2
select len(StuName) from Students--返回Students表中每个StuName的长度(3)str():将数值转换为字符数据,可以指定长度和精度,
参数1为需要转换的数值,
参数2为最多字符串的总长度(包含数字和小数点,空格),默认为10
参数3为小数的位数,默认为0
注:如果指定的 length 小于数值的实际长度,会返回 ** 表示溢出。 结果字符串会靠右对齐,不足的长度会用空格填充。
select str(123.12345,6,2)--123.12
select str(123.12345,8,3)--123.123
select str(123.12345,10,3)--123.123(4)cast():实现数据类型的显示转换
select cast('2024-09-10' as date); -- 字符串 → 日期
select cast(quantity as varchar(50))from t; -- 数字 → 字符串(5)convert():类型转换 + 格式化(非标准扩展)
select convert(varchar,getDate(),120);-- 2025-08-21 15:30:00(6)getdate():获取当前时间
select getdate();2_sql 多表查询
(1)as 设置别名
--给列设置别名
select Phone as '手机号' from CustomerInfo
--给整张表设置别名
select * from CustomerInfo as c(2)连接分类
外连接(outer)
左连接:Left,左表为主,返回左表中的所有行,如果左表中行在右表中没有匹配行,则结果中右表中的列返回空值。
右连接,right,右表为主,返回右表中的所有行,如果右表中行在左表中没有匹配行,则结果中左表中的列返回空值。
全连接:返回左表和右表中的所有行。当某行在另一表中没有匹配行,则另一表中的列返回空值
内连接(inner)
等值连接:在连接条件中使用等于号(=)运算符,其查询结果中列出被连接表中的所有列,包括其中的重复列。
不等链接:在连接条件中使用除等于号之外运算符(>、<、<>、>=、<=、!>和!<)
交叉连接
不带where条件子句:它将会返回被连接的两个表的笛卡尔积,返回结果的行数等于两个表行数的乘积(例如:T_student和T_class,返回4*4=16条记录),如果带where,返回或显示的是匹配的行数
有where子句:往往会先生成两个表行数乘积的数据表,然后才根据where条件从中选择。cross join后加条件只能用where,不能用on
--多表查询
--外连接
--左连
select * from CustomerInfo as C
left outer join AddressInfo as A on C.AddressId=A.AddressId;
--左连
--as 可以省略,outer也可以省略,默认为outer
select * from CustomerInfo as C
left join UserInfo U on C.CreateUaerId=U.UserId;
--右连接
select * from CustomerInfo as C
right join UserInfo U on C.CreateUserId=U.UserId;
--全连接
select * from CustomerInfo as C
full join UserInfo U on C.CreateUserId=U.UserId;
--设置显示的列
select C.CustomerId,C.CustomerName,C.Sex,C.Age,C.Phone,A.ProvinceName,A.City,A.Area from CustomerInfo as C
left outer join AddressInfo as A on C.AddressId=A.AddressId;
--列可使用+显示在一列
select C.CustomerId,C.CustomerName,C.Sex,C.Age,C.Phone,A.ProvinceName+A.City+A.Area DataiAddress from CustomerInfo as C
left outer join AddressInfo as A on C.AddressId=A.AddressId;
--内连接
--等值连接
select * from CustomerInfo as C
inner join UserInfo U on C.CreateUserId=U.UserId;
--不等连接
select * from CustomerInfo as C
inner join UserInfo U on CreateUserId<>U.UserId;
--不等连接
select C.CustomerId,C.CustomerName,C.AddressId,A.AddressId, A.ProvinceName+A.City+A.Area as DataiAddress from CustomerInfo as C
inner join AddressInfo as A on C.AddressId<>A.AddressId;
--交叉连接
--不带where
select C.CustomerId,C.CustomerName,C.Age,A.AddressId, A.ProvinceName+A.City+A.Area as DataiAddress from CustomerInfo as C
cross join AddressInfo as A
--带where
select C.CustomerId,C.CustomerName,C.Age,A.AddressId, A.ProvinceName+A.City+A.Area as DataiAddress from CustomerInfo as C
cross join AddressInfo as A where C.AddressId=A.AddressId;3_Sql中的运算符
(1)sql中许多运算符与C#中类似,下面列举与c#中不同的并于c#中做对比
| 运算符 | sql | c# |
|---|---|---|
| = | 等于 | 赋值 |
| <> | 不等于 | != |
| and | 和 | && |
| or | 或 | || |
| Not | 取反 | ! |
| between | 如果操作数在某个范围之内,则结果为 TRUE | |
| in | 表达式的值是否在指定的列表或子查询结果中 | |
| like | 字符串模式匹配的运算符 |
4_Sql中的索引
(1)SQL Server 中的索引主要可以从数据结构和存储特性两个维度进行分类。下图清晰地展示了其分类体系:
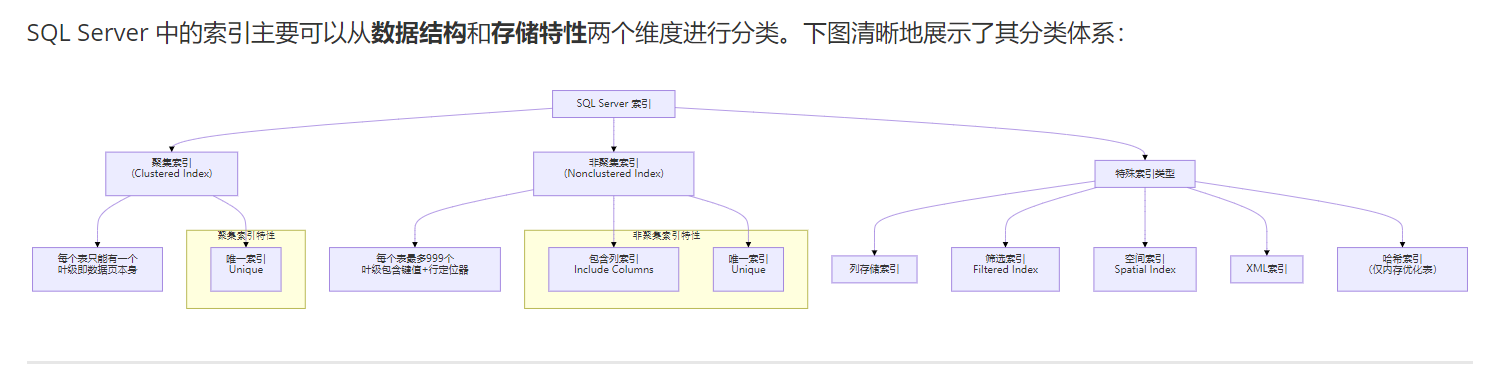
4.1_按数据结构分类 (核心分类)
(1)聚集索引 (Clustered Index)
定义:决定了表中数据的物理存储顺序。表的数据行本身就在磁盘上按照聚集索引键的顺序进行排序和存储。
特点:
一个表只能有一个聚集索引,因为数据本身只能按一种顺序物理存储。
聚集索引的叶子节点就是实际的数据页。找到索引键也就找到了完整的数据行。
创建主键(PRIMARY KEY)时,如果表上还没有聚集索引,SQL Server 默认会自动将其创建为聚集索引(除非特别指定为非聚集)。
何时使用:非常适合用于范围查询(如 between, >, <)、经常用 order by 排序的列、以及返回大量结果集的查询。
示例:
-- 创建表时定义聚集索引(通常作为主键) CREATE TABLE Employees (EmployeeID INT PRIMARY KEY CLUSTERED, -- 聚集索引FirstName NVARCHAR(50),LastName NVARCHAR(50) );-- 在现有表上创建聚集索引 CREATE CLUSTERED INDEX IX_Employees_LastName ON Employees (LastName);
(2). 非聚集索引 (Nonclustered Index)
定义:索引的结构与数据存储的结构完全分离。非聚集索引的键值顺序和数据行的物理顺序无关。
特点:
一个表可以有最多 999 个非聚集索引。
非聚集索引的叶子节点不包含实际的数据行,而是包含索引键值和一个指向该行数据存储位置的行定位器。
如果表有聚集索引,行定位器就是该行的聚集索引键。
如果表是堆(没有聚集索引),行定位器就是指向数据行的行标识符 (RID)。
查询时,如果非聚集索引不能覆盖所有需要的列,就需要通过行定位器去查找(Lookup) 数据页,这是一个额外的开销操作(称为 Key Lookup 或 RID Lookup)。
何时使用:非常适合用于点查询(精确匹配)、覆盖查询、以及WHERE子句或JOIN条件中常用的列。
示例:
-- 创建一个简单的非聚集索引 CREATE NONCLUSTERED INDEX IX_Employees_FirstName ON Employees (FirstName);-- 创建复合非聚集索引(多个列) CREATE NONCLUSTERED INDEX IX_Employees_LastName_FirstName ON Employees (LastName, FirstName);
4.2. 按存储特性分类 (特殊索引类型)
这些索引在核心数据结构的基础上,增加了特殊的存储或功能特性。
(1). 唯一索引 (Unique Index)
定义:确保索引键列不包含重复的值。
特点:
既可以应用于聚集索引,也可以应用于非聚集索引。
在创建
primary key或unique约束时,SQL Server 会自动在后台创建唯一索引来强制实现唯一性。
示例:
CREATE UNIQUE NONCLUSTERED INDEX UQ_Employees_SSN ON Employees (SocialSecurityNumber); -- 这将阻止插入SSN相同的员工记录
(2). 包含列索引 (Index with Included Columns)
定义:一种特殊的非聚集索引,在索引的叶子节点中不仅包含索引键列,还包含其他非键列(称为包含列)。
目的:使查询成为“覆盖查询”,避免昂贵的键查找(Key Lookup)操作。包含列只存储在叶子节点,不影响索引键的排序和查找效率。
何时使用:当查询的所有输出列和条件列都存在于索引中时(
SELECT列表中的列可以作为包含列)。示例:
-- 假设我们经常根据LastName查找FirstName和PhoneNumber CREATE NONCLUSTERED INDEX IX_Employees_LastName_Includes ON Employees (LastName) INCLUDE (FirstName, PhoneNumber); -- PhoneNumber不作为查找键,只包含在叶子节点-- 下面的查询将非常高效,无需回表查找 -- SELECT FirstName, PhoneNumber FROM Employees WHERE LastName = 'Smith';
(3). 筛选索引 (Filtered Index)
定义:一种经过优化的非聚集索引,它只包含表中满足特定筛选条件的数据行。
优点:
体积更小,存储和维护开销更低。
统计信息更准确(因为只针对数据子集),查询性能更好。
何时使用:适用于查询只针对表中某个数据子集的情况,例如稀疏数据、具有特定类别或状态的数据。
示例:
-- 只为活跃员工创建索引 CREATE NONCLUSTERED INDEX IX_Employees_Active_LastName ON Employees (LastName) WHERE IsActive = 1;-- 只为非空的Email创建唯一索引 CREATE UNIQUE NONCLUSTERED INDEX UQ_Employees_Email ON Employees (Email) WHERE Email IS NOT NULL;
(4). 列存储索引 (Columnstore Index)
定义:一种按列而不是按行存储数据的索引。它为数据仓库和大数据分析工作负载提供了极高的性能。
特点:
极高的数据压缩率,减少I/O开销。
非常适合执行大规模聚合查询,如 SUM, COUNT, AVG, GROUP BY)。
从 SQL Server 2016 开始,列存储索引支持可更新的行存储表。
类型:
聚集列存储索引 (Clustered Columnstore Index):将整个表转换为列存储格式,成为表的主要存储方式。
非聚集列存储索引 (Nonclustered Columnstore Index):在现有的行存储表上创建的一个额外的列存储副本。
示例:
-- 创建聚集列存储索引,整个表将按列存储 CREATE CLUSTERED COLUMNSTORE INDEX CCI_FactSales ON FactSales;-- 在现有表上创建非聚集列存储索引 CREATE NONCLUSTERED COLUMNSTORE INDEX NCCI_Employees ON Employees (EmployeeID, DepartmentID, Salary);
4.3.其他专用索引
空间索引 (Spatial Index):用于优化对
geometry或geography数据类型的列的空间操作查询。XML 索引:用于优化对 XML 数据类型的列的查询。
全文索引 (Full-Text Index):用于对字符文本数据进行复杂的词语模式匹配查询。
4.4.总结与选择策略
| 索引类型 | 数量限制 | 特点 | 适用场景 |
|---|---|---|---|
| 聚集索引 | 1个/表 | 数据即索引,物理有序 | 主键、范围查询、排序 |
| 非聚集索引 | 999个/表 | 索引与数据分离,逻辑有序 | 常用查询条件、连接条件 |
| 唯一索引 | - | 强制唯一性 | 主键、唯一约束、业务唯一字段 |
| 包含列索引 | - | 叶子节点包含额外列,避免回表 | 覆盖查询,SELECT列表中的列 |
| 筛选索引 | - | 只对数据子集建索引,体积小 | 稀疏数据、查询特定范围数据 |
| 列存储索引 | 1个聚集或多个非聚集/表 | 列式存储,压缩率高,批量处理 | 数据仓库、大数据聚合分析 |
建议:
先有聚集索引:通常为自增ID主键或最常用的有序查询字段。
按需添加非聚集索引:根据高频查询的
WHERE,JOIN,ORDER BY子句创建。利用包含列:让索引覆盖更多查询,减少键查找。
考虑筛选索引:对于查询只涉及部分数据的情况,它能大幅提升性能并降低开销。
OLAP用列存储:对于报表和分析型系统,优先考虑列存储索引。
5_sql中的约束
5.1. PRIMARY KEY (主键约束)
作用:唯一标识表中的每一行。不能为 NULL,且必须唯一。 语法:
-- 方式一:列级约束(单字段主键)
CREATE TABLE 表名 (列1 数据类型 PRIMARY KEY,列2 数据类型,...
);-- 方式二:表级约束(可用于单字段或多字段复合主键)
CREATE TABLE 表名 (列1 数据类型,列2 数据类型,...PRIMARY KEY (列1) -- 单字段-- PRIMARY KEY (列1, 列2) -- 多字段复合主键
);-- 使用 ALTER TABLE 添加
ALTER TABLE 表名
ADD PRIMARY KEY (列名);示例:
CREATE TABLE Users (UserID INT PRIMARY KEY,UserName VARCHAR(50)
);-- 或者
CREATE TABLE OrderItems (OrderID INT,ProductID INT,Quantity INT,PRIMARY KEY (OrderID, ProductID) -- 复合主键
);5.2. FOREIGN KEY (外键约束)
作用:确保一个表中的数据匹配另一个表中存在的值,维护表之间的引用完整性。 语法:
-- 在 CREATE TABLE 中定义
CREATE TABLE 从表名 (列1 数据类型,列2 数据类型,外键列 数据类型,...FOREIGN KEY (外键列) REFERENCES 主表名 (主表列名)[ON DELETE {CASCADE | SET NULL | SET DEFAULT | NO ACTION}][ON UPDATE {CASCADE | SET NULL | SET DEFAULT | NO ACTION}]
);-- 使用 ALTER TABLE 添加
ALTER TABLE 从表名
ADD FOREIGN KEY (外键列) REFERENCES 主表名 (主表列名);引用操作 (ON DELETE / ON UPDATE):
CASCADE:当主表记录被删除或更新时,自动删除或更新从表中的匹配行。SET NULL:当主表记录被删除或更新时,将从表中的外键列设置为 NULL。SET DEFAULT:当主表记录被删除或更新时,将从表中的外键列设置为默认值。NO ACTION(默认):拒绝执行会导致引用完整性被破坏的删除或更新操作。
示例:
CREATE TABLE Orders (OrderID INT PRIMARY KEY,UserID INT,OrderDate DATE,FOREIGN KEY (UserID) REFERENCES Users(UserID) ON DELETE CASCADE
);5.3. UNIQUE (唯一约束)
作用:确保列中的所有值都是不同的。允许有 NULL 值(但通常只能有一个 NULL,取决于数据库系统)。 语法:
-- 列级约束
CREATE TABLE 表名 (列1 数据类型 UNIQUE,列2 数据类型,...
);-- 表级约束(可为约束命名)
CREATE TABLE 表名 (列1 数据类型,列2 数据类型,...CONSTRAINT 约束名 UNIQUE (列1)-- CONSTRAINT 约束名 UNIQUE (列1, 列2) -- 复合唯一键
);-- 使用 ALTER TABLE 添加
ALTER TABLE 表名
ADD UNIQUE (列名);
-- 或
ALTER TABLE 表名
ADD CONSTRAINT 约束名 UNIQUE (列名);示例:
CREATE TABLE Products (ProductID INT PRIMARY KEY,ProductCode VARCHAR(10) UNIQUE, -- 确保产品代码唯一ProductName VARCHAR(100)
);5.4. CHECK (检查约束)
作用:确保列中的值满足一个指定的条件(布尔表达式)。 语法:
-- 列级约束
CREATE TABLE 表名 (列1 数据类型 CHECK (条件表达式),列2 数据类型,...
);-- 表级约束(更灵活,可以引用多个列)
CREATE TABLE 表名 (列1 数据类型,列2 数据类型,列3 数据类型,...CONSTRAINT 约束名 CHECK (条件表达式)
);-- 使用 ALTER TABLE 添加
ALTER TABLE 表名
ADD CHECK (条件表达式);
-- 或
ALTER TABLE 表名
ADD CONSTRAINT 约束名 CHECK (条件表达式);示例:
CREATE TABLE Employees (EmployeeID INT PRIMARY KEY,FirstName VARCHAR(50),LastName VARCHAR(50),Age INT CHECK (Age >= 18), -- 确保年龄大于等于18Salary DECIMAL(10,2) CHECK (Salary > 0),-- 表级CHECK,确保结束日期晚于开始日期StartDate DATE,EndDate DATE,CONSTRAINT CHK_Dates CHECK (EndDate > StartDate OR EndDate IS NULL)
);5.5. NOT NULL (非空约束)
作用:强制列不接受 NULL 值。 语法:
-- 只能在列级定义
CREATE TABLE 表名 (列1 数据类型 NOT NULL,列2 数据类型,...
);-- 使用 ALTER TABLE 添加(通常需要先处理已有的NULL值)
ALTER TABLE 表名
ALTER COLUMN 列名 SET NOT NULL;-- PostgreSQL 语法
ALTER TABLE 表名
ALTER COLUMN 列名 SET NOT NULL;-- SQL Server / MS Access 语法
ALTER TABLE 表名
ALTER COLUMN 列名 数据类型 NOT NULL;示例:
CREATE TABLE Customers (CustomerID INT PRIMARY KEY,CustomerName VARCHAR(100) NOT NULL, -- 姓名不能为空ContactName VARCHAR(100)
);5.6. DEFAULT (默认约束)
作用:当向表中插入新记录时,如果没有为某个列指定值,数据库会自动使用默认值。 语法:
-- 在 CREATE TABLE 中定义
CREATE TABLE 表名 (列1 数据类型 DEFAULT 默认值,列2 数据类型,...
);-- 使用 ALTER TABLE 添加
ALTER TABLE 表名
ALTER COLUMN 列名 SET DEFAULT 默认值;示例:
CREATE TABLE Orders (OrderID INT PRIMARY KEY,OrderDate DATE DEFAULT GETDATE(), -- SQL Server: 默认为当前日期-- OrderDate DATE DEFAULT CURRENT_DATE, -- PostgreSQL/MySQLStatus VARCHAR(20) DEFAULT 'Pending'
);5.6.综合示例
创建一个包含多种约束的表:
CREATE TABLE Employees (EmployeeID INT PRIMARY KEY, -- 主键NationalID VARCHAR(20) UNIQUE, -- 唯一约束FirstName VARCHAR(50) NOT NULL, -- 非空LastName VARCHAR(50) NOT NULL, -- 非空DepartmentID INT NOT NULL,BirthDate DATE CHECK (BirthDate < '2005-01-01'), -- 检查约束HireDate DATE DEFAULT CURRENT_DATE, -- 默认约束Salary DECIMAL(10, 2) CHECK (Salary > 0), -- 检查约束-- 表级外键约束FOREIGN KEY (DepartmentID) REFERENCES Departments(DepartmentID) ON DELETE CASCADE
);5.7.删除约束
使用 ALTER TABLE 语句来删除约束。你需要知道约束的名称(如果定义时未命名,数据库会自动生成一个,通常需要查询系统表来查看)。
-- 通用语法(MySQL, SQL Server 可能略有不同)
ALTER TABLE 表名
DROP CONSTRAINT 约束名;-- 删除主键 (MySQL 和 SQL Server 语法)
ALTER TABLE 表名
DROP PRIMARY KEY;-- 删除外键
ALTER TABLE 表名
DROP FOREIGN KEY 外键约束名; -- MySQL
-- 或
ALTER TABLE 表名
DROP CONSTRAINT 外键约束名; -- SQL Server / PostgreSQL5.8.提示
命名约束:最好使用
CONSTRAINT 约束名语法为约束(除了NOT NULL)显式命名,这样在后续需要修改或删除时会非常方便。数据库差异:虽然核心语法是标准的,但不同的数据库管理系统(MySQL, PostgreSQL, SQL Server, Oracle)在细节上(如
ALTER TABLE修改列的语法、DEFAULT值的函数、查看约束名的系统表)可能存在差异。使用时请查阅特定数据库的文档。性能:约束(尤其是外键和复杂
CHECK约束)会在数据插入、更新和删除时带来额外的开销,因为数据库需要验证这些操作是否满足约束条件。在设计大型、高并发的系统时需要权衡数据完整性和性能。