《PostgreSQL内核学习:slot_deform_heap_tuple 的分支消除与特化路径优化》
PostgreSQL内核学习:slot_deform_heap_tuple 的分支消除与特化路径优化
- 引言
- 补丁概述
- 提交信息
- 提交描述
- 优化目的
- 源码解读
- 慢速模式
- 定义
- 上下文与补丁中的作用
- 代码示例
- NULL 检查与 HeapTupleHasNulls
- 定义
- 代码定义
- 上下文与补丁中的作用
- 代码示例
- slot_deform_heap_tuple 函数
- slot_deform_heap_tuple_internal 函数
- 总结
声明:本文的部分内容参考了他人的文章。在编写过程中,我们尊重他人的知识产权和学术成果,力求遵循合理使用原则,并在适用的情况下注明引用来源。
本文主要参考了 postgresql-18 beta2 的开源代码和《PostgresSQL数据库内核分析》一书
引言
在数据库系统中,元组(tuple)解构(deformation)是将物理元组数据转换为逻辑表示(如Datum数组和isnull数组)的关键过程,广泛应用于查询执行的许多场景。
在 PostgreSQL 的查询执行过程中,slot_deform_heap_tuple 函数负责将物理元组(HeapTuple)解构为逻辑表示(TupleTableSlot 的 Datum 和 isnull 数组),这是扫描、连接和投影等操作的核心步骤。
然而,原始实现中存在性能瓶颈:每次解构属性时,函数都会重复检查元组是否包含 NULL 值(通过 HeapTupleHasNulls 和 NULL 位图)以及是否可以使用缓存的偏移量(attcacheoff),导致大量不必要的分支跳转和计算开销,尤其在解构密集型的 OLAP 工作负载中表现明显。这些重复检查在无 NULL 值或固定长度属性的常见场景下尤为冗余,降低了查询性能。
补丁概述
提交信息
下面为本次优化的提交信息,hash值为:58a359e585d0281ecab4d34cab9869e7eb4e4ca3。对应的描述信息见提交描述。
提交描述
为解决这一问题,本补丁(Speedup-tuple-deformation-with-additional-function-i)通过重构 slot_deform_heap_tuple 引入了内联函数 slot_deform_heap_tuple_internal,并分离了慢速模式(动态计算偏移量)和非慢速模式(使用缓存偏移量)以及有/无 NULL 值的解构逻辑。利用编译器的内联和常量折叠优化,补丁消除了不必要的分支检查,显著减少了 CPU 开销。测试表明,该优化在解构密集型 OLAP 工作负载中可带来 5-20% 的性能提升,从而提高 PostgreSQL 在大规模数据分析场景中的效率。具体通过以下方式减少性能开销::
- 减少
NULL检查:通过在循环开始时检查HeapTupleHasNulls,避免在每次循环中重复检查元组是否包含NULL值。如果元组没有NULL值,则使用无需NULL检查的简化循环。 - 优化慢速模式检查:通过分离“慢速模式”(
slow mode)和“非慢速模式”的解构逻辑,减少对attcacheoff偏移量的重复检查。一旦进入慢速模式,无需返回非慢速模式,从而简化后续处理。 - 编译器优化:通过将
slow和hasnulls参数设置为常量并内联调用slot_deform_heap_tuple_internal,利用编译器的分支消除和常量折叠功能生成更高效的代码。
优化目的
在 PostgreSQL 中,元组解构是将存储在磁盘上的物理元组(HeapTuple)转换为查询执行所需的逻辑表示(Datum/isnull 数组)的过程。这个过程在查询执行中被频繁调用,尤其在 OLAP 场景中(如数据分析查询),需要处理大量元组。原始的 slot_deform_heap_tuple 函数在每次循环中都会重复检查以下内容:
- 是否存在
NULL值(通过HeapTupleHasNulls和NULL位图检查)。- 是否可以使用缓存的偏移量(
attcacheoff)或需要重新计算偏移量(慢速模式)。
这些重复检查导致了大量的分支跳转,尤其是在元组不包含 NULL 值或偏移量可缓存的情况下,这些检查是多余的。分支跳转和条件检查会显著增加 CPU 的指令流水线开销,降低性能。
补丁的目标是通过减少不必要的条件检查和分支跳转,优化元组解构的性能。具体目标包括:
- 减少
NULL检查的开销:通过一次性检查元组是否包含NULL值,避免在每次属性解构时重复检查。 - 优化偏移量计算:通过分离慢速和非慢速模式的逻辑,减少对偏移量缓存的检查和更新操作。
- 利用编译器优化:通过内联和常量参数,生成更高效的机器代码,减少运行时开销。
- 提升整体性能:在解构密集型工作负载中(如
OLAP查询),实现5-20%的性能提升。
源码解读
慢速模式
定义
在 PostgreSQL 的 slot_deform_heap_tuple 函数中,“慢速模式”(slow mode)是指在解构元组(将物理元组转换为逻辑表示)时,无法直接使用缓存的属性偏移量(attcacheoff)来定位属性数据的一种处理方式。相反,需要动态计算每个属性的偏移量,这增加了计算开销。
上下文与补丁中的作用
- 在
PostgreSQL中,元组中的属性数据按照顺序存储,固定长度属性的偏移量可以预先计算并缓存(attcacheoff),从而加速访问。然而,当遇到以下情况时,缓存偏移量不可用,触发慢速模式:- 变长属性(如
varchar或text):这些属性的长度不固定,偏移量需要根据实际数据计算。 - 对齐要求:某些属性需要按特定字节对齐(例如,
8字节对齐的double),可能引入填充字节,导致偏移量无法简单递增。
- 变长属性(如
- 补丁通过分离慢速模式和非慢速模式的解构逻辑,减少了非慢速模式下的分支检查。例如,在非慢速模式下,函数直接使用
attcacheoff获取偏移量,而一旦进入慢速模式(通过slowp标志),后续解构不再尝试返回非慢速模式,从而简化逻辑。
代码示例
if (!slow && thisatt->attcacheoff >= 0)*offp = thisatt->attcacheoff; /* 非慢速模式:使用缓存偏移量 */
else*offp = att_pointer_alignby(*offp, thisatt->attalignby, -1, tp + *offp); /* 慢速模式:动态计算 */
- 补丁优化:通过内联函数
slot_deform_heap_tuple_internal和常量参数(slow = false),编译器生成更高效的非慢速模式代码,减少分支跳转。
NULL 检查与 HeapTupleHasNulls
定义
HeapTupleHasNulls 是一个宏,用于检查元组是否包含 NULL 值。它通过检查元组头的 t_infomask 字段是否设置了 HEAP_HASNULL 标志(0x0001)来判断。
代码定义
#define HEAP_HASNULL 0x0001 /* 元组包含 NULL 属性 */
#define HeapTupleHasNulls(tuple) \(((tuple)->t_data->t_infomask & HEAP_HASNULL) != 0)
t_infomask是HeapTupleHeader中的一个字段,存储元组的元信息。- 如果
t_infomask & HEAP_HASNULL不为0,表示元组包含至少一个NULL属性,需使用NULL位图(t_bits)来标识哪些属性为NULL。
上下文与补丁中的作用
- 在元组解构过程中,检查属性是否为
NULL是关键步骤。如果元组包含NULL值,解构函数需要访问NULL位图(t_bits)来确定每个属性的状态,这增加了分支检查的开销。 - 如果
HeapTupleHasNulls(tuple)返回false,表示元组没有NULL值,可以跳过NULL位图检查,从而简化解构逻辑。 - 补丁优化了这一过程,通过在
slot_deform_heap_tuple中一次性调用HeapTupleHasNulls设置hasnulls标志,并根据hasnulls的值选择不同的解构路径:hasnulls = false:使用无需NULL检查的简化循环。hasnulls = true:包含NULL位图检查的逻辑。
代码示例
bool hasnulls = HeapTupleHasNulls(tuple); /* 检查元组是否包含 NULL 值 */
if (!hasnulls)attnum = slot_deform_heap_tuple_internal(slot, tuple, attnum, natts, false, false, &off, &slow);
- 补丁优化:通过将
hasnulls作为常量传递给slot_deform_heap_tuple_internal,编译器可以消除不必要的NULL检查分支,显著提高性能,尤其在无NULL值的常见场景下。
slot_deform_heap_tuple 函数
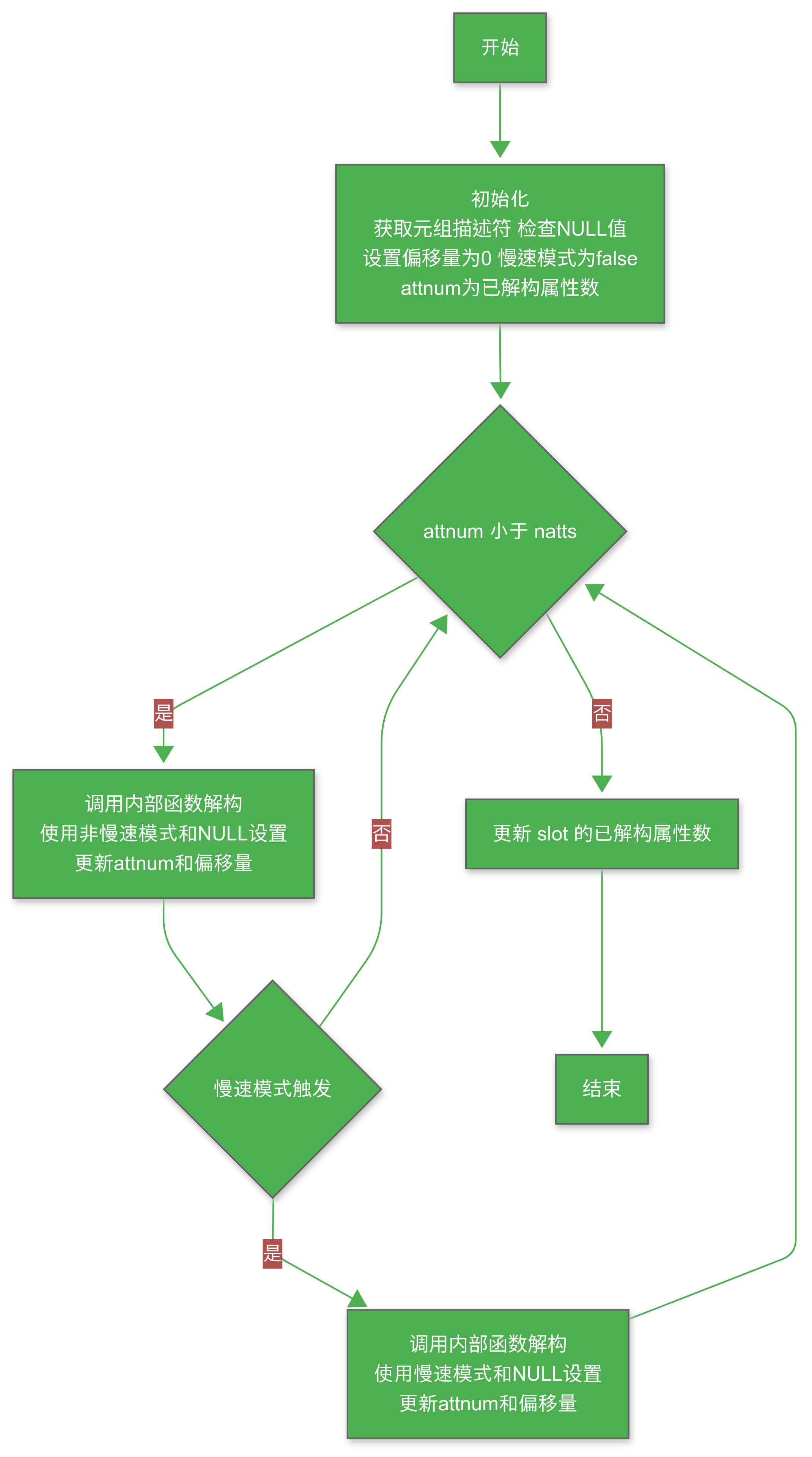
slot_deform_heap_tuple 是 PostgreSQL 中用于将物理元组(HeapTuple)解构为逻辑表示(TupleTableSlot 的 Datum 和 isnull 数组)的核心函数。这个过程是将存储在磁盘上的紧凑元组数据转换为查询执行引擎可直接使用的格式。函数支持增量解构,即只解构需要的属性,而无需重复处理已解构的属性,从而提高效率。
/** slot_deform_heap_tuple* 给定一个 TupleTableSlot,从槽的物理元组中提取数据到其 Datum/isnull 数组。* 数据提取直到第 natts 个列(调用者必须确保这是一个合法的列编号)。** 这是 heap_deform_tuple 的增量版本:* 每次调用时,我们提取需要的属性,而无需重新计算之前已提取的属性的信息。* slot->tts_nvalid 表示已提取的属性数量。** 该函数标记为始终内联,因此不同类型槽的 offp 参数会被优化消除。*/
static pg_attribute_always_inline void
slot_deform_heap_tuple(TupleTableSlot *slot, HeapTuple tuple, uint32 *offp,int natts)
{bool hasnulls = HeapTupleHasNulls(tuple); // 检查元组是否包含 NULL 值int attnum; // 当前处理的属性编号uint32 off; // 元组数据中的偏移量bool slow; // 是否可以使用/设置 attcacheoff(缓存偏移量)?/* 只能提取元组拥有的属性数量 */natts = Min(HeapTupleHeaderGetNatts(tuple->t_data), natts); // 取元组头中的属性数和 natts 的最小值/** 检查这是不是该元组的第一次调用,并初始化或恢复循环状态*/attnum = slot->tts_nvalid; // 获取已解构的属性数量if (attnum == 0){/* 从第一个属性开始 */off = 0; // 偏移量初始化为 0slow = false; // 非慢速模式(可以使用缓存偏移量)}else{/* 恢复上一次执行的状态 */off = *offp; // 使用传入的偏移量slow = TTS_SLOW(slot); // 获取槽的慢速模式标志}/** 如果未设置慢速模式,尝试使用不包含非固定偏移量检查的解构代码。* 在解构过程中,如果遇到 NULL 值或变长属性,将切换到包含非固定偏移量检查的* 解构方法,即慢速模式。因为性能关键,我们内联 slot_deform_heap_tuple_internal,* 将 slow 和 hasnulls 参数作为常量传递,允许编译器生成专门的代码,* 移除已知为 false 的比较和后续分支。*/if (!slow){/* 元组没有 NULL 值?可以跳过 NULL 检查 */if (!hasnulls)attnum = slot_deform_heap_tuple_internal(slot,tuple,attnum,natts,false, /* 慢速模式:false */false, /* 无 NULL 值 */&off,&slow); // 更新偏移量和慢速模式标志elseattnum = slot_deform_heap_tuple_internal(slot,tuple,attnum,natts,false, /* 慢速模式:false */true, /* 有 NULL 值 */&off,&slow); // 更新偏移量和慢速模式标志}/* 如果还有工作要做,则必须处于慢速模式 */if (attnum < natts){/* XXX 是否值得为 hasnulls 为 false 的情况添加单独调用? */attnum = slot_deform_heap_tuple_internal(slot,tuple,attnum,natts,true, /* 慢速模式:true */hasnulls,&off,&slow); // 更新偏移量和慢速模式标志}/** 保存状态以供下次执行*/slot->tts_nvalid = attnum; // 更新已解构的属性数量*offp = off; // 保存当前偏移量if (slow)slot->tts_flags |= TTS_FLAG_SLOW; // 设置慢速模式标志elseslot->tts_flags &= ~TTS_FLAG_SLOW; // 清除慢速模式标志
}
函数的主要步骤:
- 检查元组属性数量:确保只解构元组实际拥有的属性(通过
HeapTupleHeaderGetNatts)。 - 初始化状态:根据是否是第一次调用,设置初始偏移量(
off)和慢速模式标志(slow)。 - 选择解构路径:
- 如果不在慢速模式(
slow == false),尝试使用优化的解构逻辑。 - 根据元组是否包含
NULL值(hasnulls),选择是否跳过NULL检查。 - 调用内联函数
slot_deform_heap_tuple_internal处理实际解构。
- 如果不在慢速模式(
- 处理慢速模式:如果遇到变长属性或对齐问题,切换到慢速模式,继续解构剩余属性。
- 保存状态:更新槽的已解构属性数量(
tts_nvalid)、偏移量(offp)和慢速模式标志。
优化点:
- 减少分支检查:通过分离无
NULL值和慢速模式的逻辑,减少不必要的条件检查。 - 内联优化:使用
pg_attribute_always_inline和常量参数(slow和hasnulls),让编译器生成高效代码。 - 增量解构:只解构需要的属性,避免重复计算。
slot_deform_heap_tuple_internal 函数
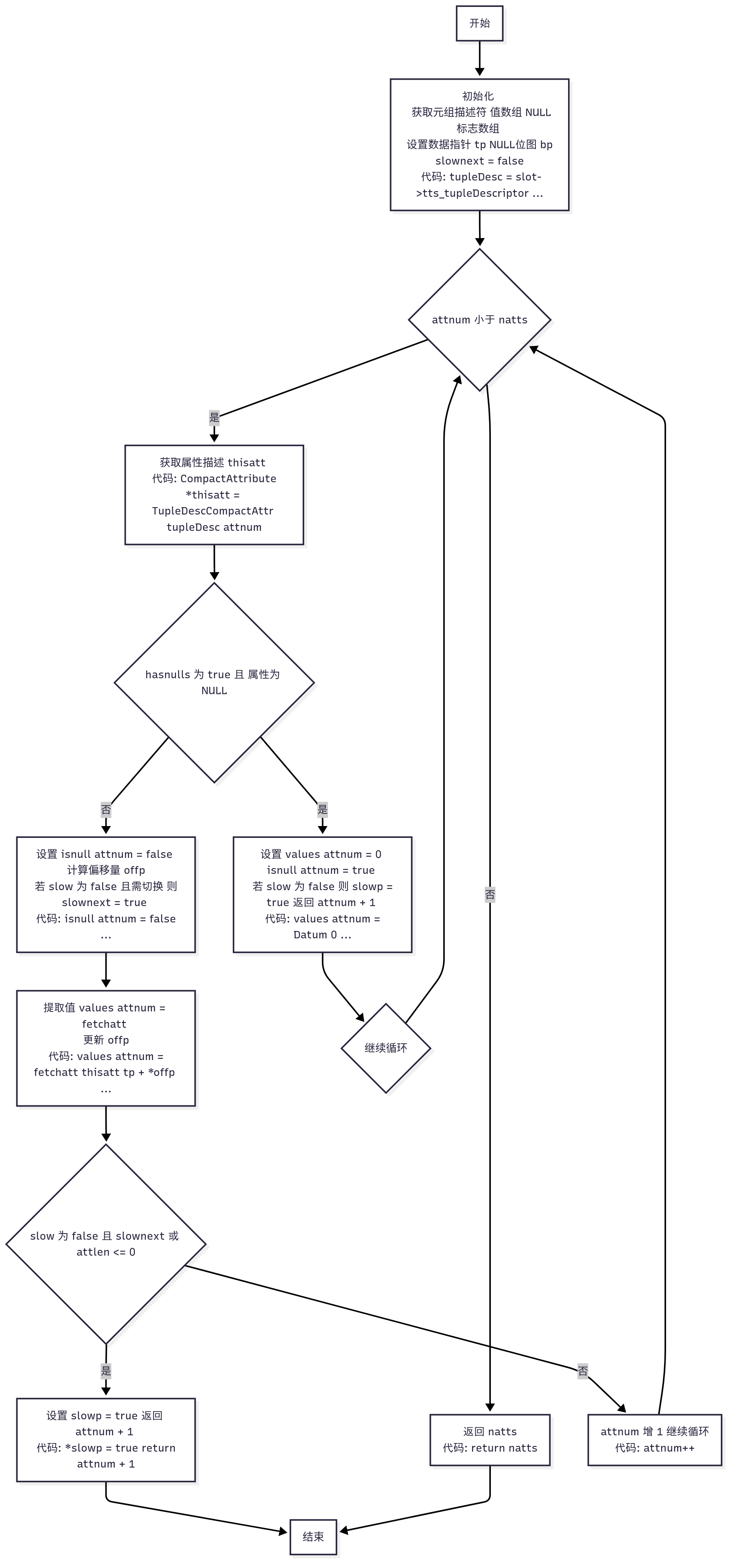
slot_deform_heap_tuple_internal 是 slot_deform_heap_tuple 的辅助函数,用于将物理元组(HeapTuple)中的属性解构到 TupleTableSlot 的 Datum(tts_values)和 isnull(tts_isnull)数组中。它通过内联和常量参数(slow 和 hasnulls)优化性能,允许编译器生成专门化的代码路径,减少分支检查。该函数支持增量解构,从指定的属性编号(attnum)开始,直到解构 natts 个属性或因需要慢速模式而中断。
/** slot_deform_heap_tuple_internal* 用于 slot_deform_heap_tuple 的始终内联辅助函数,* 通过为 slow 和 hasnulls 的不同组合生成专门化代码。* 例如,如果元组没有 NULL 值,则无需为每个属性检查 hasnulls。* 调用者可将 hasnulls 设置为常量 false,让编译器移除常量 false 的分支,* 生成更优化的代码。** 返回值:下一个待解构的属性编号,当解构完所有请求的属性时,可能等于 natts。* offp 是输入/输出参数,表示元组数据中开始解构的字节偏移量,返回时设置为下一个* 属性应开始解构的偏移量。slowp 在后续解构需要使用 slow=true 的函数版本时设为 true。** 调用者不能假设返回 attnum(即完成所有属性解构)时不需要慢速模式,* 因为最后一个属性可能触发了慢速模式的切换。*/
static pg_attribute_always_inline int
slot_deform_heap_tuple_internal(TupleTableSlot *slot, HeapTuple tuple,int attnum, int natts, bool slow,bool hasnulls, uint32 *offp, bool *slowp)
{TupleDesc tupleDesc = slot->tts_tupleDescriptor; // 元组描述符,包含属性元信息Datum *values = slot->tts_values; // 存储解构后的属性值bool *isnull = slot->tts_isnull; // 存储属性是否为 NULL 的标志HeapTupleHeader tup = tuple->t_data; // 元组头,包含元组元信息char *tp; // 指向元组数据部分的指针bits8 *bp = tup->t_bits; // 指向元组 NULL 位图的指针bool slownext = false; // 标记是否需要切换到慢速模式tp = (char *) tup + tup->t_hoff; // 初始化数据指针,跳过元组头for (; attnum < natts; attnum++) // 循环解构每个属性,直到 natts{CompactAttribute *thisatt = TupleDescCompactAttr(tupleDesc, attnum); // 获取当前属性描述if (hasnulls && att_isnull(attnum, bp)) // 检查属性是否为 NULL{values[attnum] = (Datum) 0; // NULL 属性值设为 0isnull[attnum] = true; // 标记为 NULLif (!slow) // 如果当前是非慢速模式{*slowp = true; // 标记需要切换到慢速模式return attnum + 1; // 返回下一个属性编号,中断解构}elsecontinue; // 在慢速模式下,继续下一个属性}isnull[attnum] = false; // 标记属性非 NULL/* 计算当前属性的偏移量 */if (!slow && thisatt->attcacheoff >= 0) // 非慢速模式且有缓存偏移量*offp = thisatt->attcacheoff; // 使用缓存的偏移量else if (thisatt->attlen == -1) // 如果是变长属性{/** 只有当偏移量已正确对齐时,才能缓存变长属性的偏移量,* 以确保无论对齐与否,偏移量都有效。*/if (!slow && *offp == att_nominal_alignby(*offp, thisatt->attalignby))thisatt->attcacheoff = *offp; // 缓存偏移量else{*offp = att_pointer_alignby(*offp, // 计算对齐后的偏移量thisatt->attalignby,-1,tp + *offp);if (!slow)slownext = true; // 标记需要切换到慢速模式}}else{/* 非变长属性,可安全使用 att_nominal_alignby */*offp = att_nominal_alignby(*offp, thisatt->attalignby); // 计算固定长度属性的偏移量if (!slow)thisatt->attcacheoff = *offp; // 缓存偏移量}values[attnum] = fetchatt(thisatt, tp + *offp); // 提取属性值到 values 数组*offp = att_addlength_pointer(*offp, thisatt->attlen, tp + *offp); // 更新偏移量到下一个属性/* 检查是否需要切换到慢速模式 */if (!slow){/** 如果上述代码设置了 slownext 或当前属性不是固定长度,* 则无法继续解构。*/if (slownext || thisatt->attlen <= 0){*slowp = true; // 标记需要慢速模式return attnum + 1; // 返回下一个属性编号,中断解构}}}return natts; // 返回 natts,表示完成所有属性解构
}
函数的主要步骤:
- 初始化:获取元组描述符、数据指针(
tp)、NULL位图(t_bits)等,设置初始状态。 - 循环解构:
- 检查属性是否为
NULL(如果hasnulls = true),并设置values和isnull。 - 计算属性偏移量(
*offp),优先使用缓存偏移量(attcacheoff),否则根据属性类型(固定长度或变长)和对齐要求计算。 - 提取属性值(
fetchatt)并更新偏移量。
- 检查属性是否为
- 慢速模式切换:如果遇到变长属性或对齐问题,设置
slownext或*slowp,中断非慢速模式循环。 返回值:返回下一个待解构的属性编号(attnum + 1或natts),并更新*offp和*slowp。
优化点:
- 减少
NULL检查:通过hasnulls = false跳过不必要的NULL位图检查。 - 减少偏移量检查:在非慢速模式(
slow = false)下优先使用缓存偏移量,减少计算。 - 编译器优化:通过内联和常量参数(
slow和hasnulls),消除冗余分支,生成高效代码。
总结
本补丁通过引入内联辅助函数 slot_deform_heap_tuple_internal,显著优化了 PostgreSQL 中 slot_deform_heap_tuple 的元组解构性能。针对 OLAP 场景中频繁的元组解构操作,补丁分离了慢速模式(处理变长属性或对齐问题)和非慢速模式,以及有/无 NULL 值的逻辑,利用编译器内联和常量折叠消除冗余分支检查。测试表明,该优化在无 NULL 值或固定长度属性的常见场景下,可减少 5-20% 的 CPU 开销,提升查询效率。此外,建议添加防御性检查(如偏移量验证)以增强鲁棒性,确保元组数据异常时及时报错。总体而言,补丁通过精简逻辑和编译器优化,为大规模数据分析提供了高效、可靠的元组解构方案。