awk 命令的使用
awk 命令的使用
awk 介绍
awk 是一个强大的文本分析工具。
awk 更像一门编程语言,他可以自定义变量,有条件语句,有循环,有数组,有正则,有函数等。
awk 按行读取数据,根据给出的条件进行查找,并在找出来的行中进行操作。
awk 有三种形势,awk,gawk,nawk,平时所说的awk其实就是gawk。
awk 是其取了三位创始人 Alfred Aho,Peter Weinberger, 和 Brian Kernighan 的 Family Name 的首字符。
使用 awk 可以完成无数的任务,我们简单的罗列几条:
- 文本处理
- 生成格式化的文本报告
- 运行一些简单的算术操作
- 执行一些常见的字符串操作
awk 命令
awk 命令格式
awk [options] 'script' file(s)
awk [options] -f scriptfile file(s)
script,定义如何处理数据。file,是 awk 处理的数据来源,awk 也可以来自其它命令的输出。-f scriptfile从脚本文件中读取awk命令,每行都是一个独立的script。
script 格式如下:
BEGIN { action }
pattern { action }
END { action }
脚本通常是被单引号或双引号包住,一个awk脚本通常由四部分组成:
-
BEGIN { action }语句块,awk 执行pattern { action }前要执行的脚本。 -
pattern { action }语句块,决定动作语句何时触发,可以是以下任意一种:- 正则表达式:使用通配符的扩展集。
- 关系表达式:使用运算符进行操作,可以是字符串或数字的比较测试。
- 模式匹配表达式:使用运算符
~(匹配)和~!(不匹配)。
-
END { action }语句块,awk 执行pattern { action }后要执行的脚本。 -
action部分,决定对数据如何处理,由一个或多个命令、函数、表达式组成,之间由换行符或分号隔开,并位于大刮号内。常见的action包括:变量或数组赋值、输出命令、内置函数、控制流语句。
BEGIN { action }、pattern { action }、END { action }都是可选项目。
awk 工作流
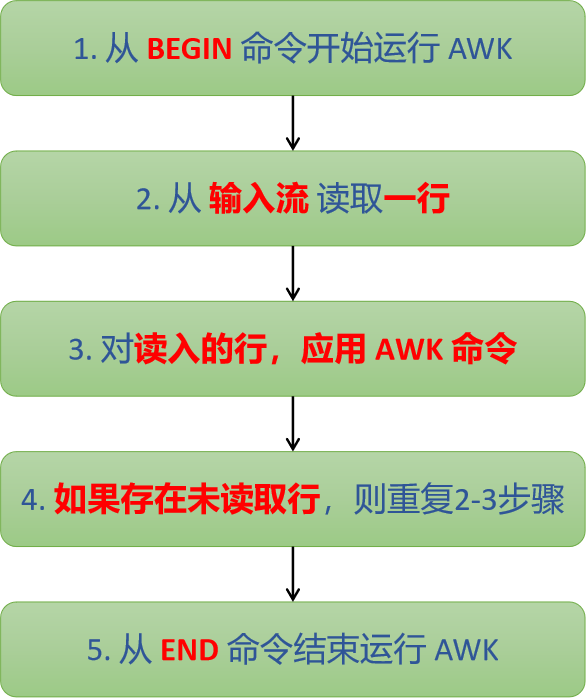
-
第一步: 执行
BEGIN { commands }语句块中的语句。在awk从输入输出流中读取行之前执行,通常在BEGIN语句块中执行如变量初始化,打印输出表头等操作。
-
第二步:**从文件或标准输入中读取一行,然后执行
pattern { commands }语句块。**它逐行读取数据,从第一行到最后一行重复这个过程,直到读取完所有行。pattern语句块中的通用命令是最重要的部分,它也是可选的。如果没有提供pattern语句块,则默认执行{ print },即打印每一个读取到的行。
{}类似一个循环体,会对文件中的每一行进行迭代,通常将变量初始化语句放在BEGIN语句块中,将打印结果等语句放在END语句块中。 -
第三步:当读至输入流末尾时,执行
END { command }语句块。在awk从输入流中读取完所有的行之后执行,比如打印所有行的分析结果,它也是一个可选语句块。
awk 示例
示例文件
[wsh@test ~ ✔]$ cat << 'EOF' > employee.txt
1) 张三 技术部 23
2) 李四 人力部 22
3) 王五 行政部 23
4) 赵六 技术部 24
5) 朱七 客服部 23
EOF
示例1: 打印雇员信息。
[wsh@test ~ ✔]$ awk '{ print }' employee.txt
1) 张三 技术部 23
2) 李四 人力部 22
3) 王五 行政部 23
4) 赵六 技术部 24
5) 朱七 客服部 23
示例2: 通过读取awk脚本,打印雇员信息。
[wsh@test ~ ✔]$ cat commands.awk
{ print }
[wsh@test ~ ✔]$ awk -f commands.awk employee.txt
1) 张三 技术部 23
2) 李四 人力部 22
3) 王五 行政部 23
4) 赵六 技术部 24
5) 朱七 客服部 23
示例3: 输出特定隔行。
[wsh@test ~ ✔]$ awk '/张三/ { print }' employee.txt
1) 张三 技术部 23
# 等同于
[wsh@test ~ ✔]$ awk '/张三/' employee.txt
1) 张三 技术部 23
$0,代表整行记录。
示例4: 统计满足特定条件的记录数。
AWK 中的所有变量都不需要初始化,并且会自动初始化为
0。
[wsh@test ~ ✔]$ awk '/技术/ { count=count+1 } END { print "Count="count }' employee.txt
运行以上代码,输出结果如下:
Count=2
示例5: 输出总长度大于 10 的行。
AWK 提供了一个内建的函数 **length(arg)∗∗用于返回字符串‘arg)** 用于返回字符串 `arg)∗∗用于返回字符串‘arg` 的总长度。
如果要获取某行的总长度,可以使用下面的语法:
length($0)。同样的,如果要获取某列/字段的总长度,可以使用语法:
length($n)。如果要判断某行的字符是否大于/小于/等于 N ,可以使用下面的语法:
length($0) > N。
[wsh@test ~ ✔]$ awk 'length($0)>10 { print $0 }' employee.txt
因为所有的行的总长度都大于 18,因此输出结果如下:
1) 张三 技术部 23
2) 李四 人力部 22
3) 王五 行政部 23
4) 赵六 技术部 24
5) 朱七 客服部 23
awk 综合示例
雇员信息表如下:
[wsh@test ~ ✔]$ cat employee.txt
1) 张三 技术部 23
2) 李四 人力部 22
3) 王五 行政部 23
4) 赵六 技术部 24
5) 朱七 客服部 23
示例文件结构:
- 每个雇员独占一行
- 每个雇员都包括以下字段:序号,名字,部门,年龄
- 每一行的多个字段之间使用空白作为分隔符,空白分隔符一般是空格 ( ) 或者制表符
\t
问题
我们想要获得以下输入结果
序号 姓名 部门 年龄
-------------------
1) 张三 技术部 23
2) 李四 人力部 22
3) 王五 行政部 23
4) 赵六 技术部 24
5) 朱七 客服部 23
-------------------
分析
从上面的结果中可以看出,整个输出结果分为三大部分
-
表头
序号 姓名 部门 年龄 ------------------- -
数据
每个雇员一样,且有着以下的结构
1) 张三 技术部 23 2) 李四 人力部 22 3) 王五 行政部 23 4) 赵六 技术部 24 5) 朱七 客服部 23 -
表尾
-------------------
根据我们刚刚学到的知识,AWK 程序结构分为三大部分,BEGIN 和 END 只会执行一次,看起来刚好可以用来输出表头,而 AWK 主体代码,是针对每一行执行的,因此,刚好可以用来输出数据。
解答
表头
为了输入表头,我们可以使用下面的 Shell 语句
[wsh@test ~ ✔]$ awk '
BEGIN { printf "序号\t名字\t部门\t年龄\n-------------------\n" }'
因为表头部分不需要处理输入文件,也不需要处理输入文件中的每一行,所以 AWK 主体代码都是可以忽略的,甚至包括输入文件都是可以忽略的。
运行以上代码,输出结果如下:
序号 名字 部门 年龄
-------------------
数据
对比想要的结果和输入的文件,可以看出输出结果并并没有对每一行做特殊处理,直接显示就好
因此,只需要在 BEGIN 块后面直接添加 { print } ,添加完代码如下:
[wsh@test ~ ✔]$ cat employee.txt | awk '
BEGIN { printf "序号\t名字\t部门\t年龄\n-------------------\n" }
{ print }
END {printf "-------------------\n"}'
运行以上代码,输出结果如下:
序号 名字 部门 年龄
-------------------
1) 张三 技术部 23
2) 李四 人力部 22
3) 王五 行政部 23
4) 赵六 技术部 24
5) 朱七 客服部 23
-------------------
如果把 命令写入到脚本文件中,也可以这样执行:
[wsh@test ~ ✔]$ vim commands.awk
BEGIN { printf "序号\t名字\t部门\t年龄\n-------------------\n" }
{ print }
END {printf "-------------------\n"}[wsh@test ~ ✔]$ awk -f commands.awk employee.txt
表尾
最后,从想要的结果中可以看出,整个结果最后还有一行虚线,这个,我们可以通过 END 语句来实现。
END 语句和 BEGIN 语句类似,我们就直接给结果了。
[wsh@test ~ ✔]$ cat employee.txt | awk '
BEGIN { printf "序号\t名字\t部门\t年龄\n-------------------\n" } { print }
END { printf "-------------------\n" }'
运行以上代码,输出结果如下:
序号 名字 部门 年龄
-------------------
1) 张三 技术部 23
2) 李四 人力部 22
3) 王五 行政部 23
4) 赵六 技术部 24
5) 朱七 客服部 23
-------------------
如果把 命令写入到脚本文件中,也可以这样执行:
[wsh@test ~ ✔]$ vim commands.awk
BEGIN { printf "序号\t名字\t部门\t年龄\n-------------------\n" } { print }
END { printf "-------------------\n" }[wsh@test ~ ✔]$ awk -f commands.awk employee.txt
awk 命令选项
–help 选项
用于输出 awk 命令的帮助信息。
[wsh@test ~ ✔]$ awk --help
Usage: awk [POSIX or GNU style options] -f progfile [--] file ...
Usage: awk [POSIX or GNU style options] [--] 'program' file ...
POSIX options: GNU long options: (standard)-f progfile --file=progfile-F fs --field-separator=fs-v var=val --assign=var=val
Short options: GNU long options: (extensions)-b --characters-as-bytes-c --traditional-C --copyright-d[file] --dump-variables[=file]-e 'program-text' --source='program-text'-E file --exec=file-g --gen-pot-h --help-L [fatal] --lint[=fatal]-n --non-decimal-data-N --use-lc-numeric-O --optimize-p[file] --profile[=file]-P --posix-r --re-interval-S --sandbox-t --lint-old-V --versionTo report bugs, see node `Bugs' in `gawk.info', which is
section `Reporting Problems and Bugs' in the printed version.gawk is a pattern scanning and processing language.
By default it reads standard input and writes standard output.Examples:gawk '{ sum += $1 }; END { print sum }' filegawk -F: '{ print $1 }' /etc/passwd
-F 选项
**作用:**用于定义awk程序的分隔符。awk程序的分隔符,是用于分割同一行数据的分割符号。默认分隔符是:空格。
语法:-F fs 或者 --field-separator=fs
**示例:**打印用户名和家目录
[wsh@test ~ ✔]$ head -n1 /etc/passwd
root:x:0:0:root:/root:/bin/bash[wsh@test ~ ✔]$ head -n 3 /etc/passwd | awk -F : '{ print $1,$2,$6 }'
root x /root
bin x /bin
daemon x /sbin
-v 选项
**作用:**用于预定义一些变量。这些预定义变量会在执行AWK 程序之前就定义好,准确的说,在 BEGIN 语句之前就已经定义。
示例:
-
借助
-v选项,可以将来自外部值(非stdin)传递给awk。[wsh@test ~ ✔]$ VAR=10000 [wsh@test ~ ✔]$ echo | awk -v VARIABLE=$VAR '{ print VARIABLE }' 10000 -
定义内部变量接收外部变量。
[wsh@test ~ ✔]$ var1="aaa" [wsh@test ~ ✔]$ var2="bbb" [wsh@test ~ ✔]$ echo | awk '{ print v1,v2 }' v1=$var1 v2=$var2 aaa bbb# 输入来自文件时 [wsh@test ~ ✔]$ awk '{ print v1,v2 }' v1=$var1 v2=$var2 /etc/hostname aaa bbb
-p 选项
**作用:**用于将当前的 awk 程序代码格式化并且输出到 file 文件中。
格式:--profile[=file] 或者 -p[file]
awk默认导出的 awk 程序代码格式化代码到 awkvars 文件中。
示例:
[wsh@test ~ ✔]$ awk --profile '
BEGIN { printf "====== OP ======\n"}
{ print }
END { printf "====== ED ======" }' employee.txt >awk.out
运行上面的 awk 程序,产生以下文件及其内容:
[wsh@test ~ ✔]$ ls
awk.out awkprof.out employee.txt
[wsh@test ~ ✔]$ cat awk.out
====== OP ======
1) 张三 技术部 23
2) 李四 人力部 22
3) 王五 行政部 23
4) 赵六 技术部 24
5) 朱七 客服部 23
====== ED ======
[wsh@test ~ ✔]$ cat awkprof.out # gawk profile, created Thu Aug 21 18:52:25 2025# BEGIN block(s)BEGIN {printf "====== OP ======\n"}# Rule(s){print $0}# END block(s)END {printf "====== ED ======"}
awk 内置变量
在上述的示例中,我们使用了很多 awk 内置变量。
我们可以使用 -d 选项,导出awk内置的预定义变量到 file 文件中。
格式:--dump-variables[=file] 或者-d[file]
awk默认导出的内置的预定义变量保存在文件 awkvars 文件中。
示例:
[wsh@test ~ ✔]$ awk -d ''
[wsh@test ~ ✔]$ cat awkvars.out
ARGC: 1
ARGIND: 0
ARGV: array, 1 elements
BINMODE: 0
CONVFMT: "%.6g"
ERRNO: ""
FIELDWIDTHS: ""
FILENAME: ""
FNR: 0
FPAT: "[^[:space:]]+"
FS: " "
IGNORECASE: 0
LINT: 0
NF: 0
NR: 0
OFMT: "%.6g"
OFS: " "
ORS: "\n"
RLENGTH: 0
RS: "\n"
RSTART: 0
RT: ""
SUBSEP: "\034"
TEXTDOMAIN: "messages"
我们把上面的输出结果整理如下:
| 变量 | 数据类型 | 默认值 |
|---|---|---|
| ARGC | number | 1 |
| ARGIND | number | 0 |
| ARGV | array | 1 elements |
| BINMODE | number | 0 |
| CONVFMT | string | “%.6g” |
| ERRNO | number | 0 |
| FIELDWIDTHS | string | “” |
| FILENAME | string | “” |
| FNR | number | 0 |
| FS | string | " " |
| IGNORECASE | number | 0 |
| LINT | number | 0 |
| NF | number | 0 |
| NR | number | 0 |
| OFMT | string | “%.6g” |
| OFS | string | " " |
| ORS | string | “\n” |
| RLENGTH | number | 0 |
| RS | string | “\n” |
| RSTART | number | 0 |
| RT | string | “” |
| SUBSEP | string | “\034” |
| TEXTDOMAIN | string | “messages” |
上面列出的这些变量,在 AWK 中扮演整重要的作用。
| 变 量 | 描述 |
|---|---|
| ARGC | 命令行参数的数目。 |
| ARGIND | 命令行中当前文件的位置(从0开始算)。 |
| ARGV | 包含命令行参数的数组。 |
| CONVFMT | 数字转换格式(默认值为%.6g) |
| ENVIRON | 环境变量关联数组。 |
| ERRNO | 最后一个系统错误的描述。 |
| FIELDWIDTHS | 字段宽度列表(用空格键分隔)。 |
| FILENAME | 当前文件名。 |
| FNR | 同NR,但相对于当前文件。 |
| FS | 字段分隔符(默认是任何空格)。 |
| IGNORECASE | 如 果为真,则进行忽略大小写的匹配。 |
| NF | 当前记录中的字段数。 |
| NR | 当前记录数(读入第几行数据)。 |
| OFMT | 数字的输出格式(默认值是%.6g)。 |
| OFS | 输 出字段分隔符(默认值是一个空格)。 |
| ORS | 输出记录分隔符(默认值是一个换行符)。 |
| RLENGTH | 由 match函数所匹配的字符串的长度。 |
| RS | 记录分隔符(默认是一个换行符)。 |
| RSTART | 由 match函数所匹配的字符串的第一个位置。 |
| SUBSEP | 数组下标分隔符(默认值是\034)。 |
| $n | 当前记录的第n个字段,字段间由 FS分隔。 |
| $0 | 完整的输入记录。 |
ARGC 变量
变量 ARGC 用于表示运行 awk 命令时传递了多少个参数,不包括 AWK 语句本身,也就是不包括单引号引起来的内容。
[wsh@test ~ ✔]$ awk 'BEGIN { print "Arguments="ARGC }' One Two Three Four
运行以上代码,输出结果如下:
Arguments=5
我们传递的参数,明明是 4 个,可为什么结果是 5 个呢?因为该数值还包含 awk 命令本身。
ARGV 变量
变量 ARGV 是一个数组,按照顺序保存了运行 awk 命令时传递的所有参数。
因为数组的下标从 0 开始,因此数组的的范围为 0 ~ ARGV - 1
[wsh@test ~ ✔]$ awk '
BEGIN { for (i=0;i<=ARGC-1;++i) { printf "ARGV[%d] = %s\n", i, ARGV[i] }
}' one two three four
运行以上代码,输出结果如下:
ARGV[0] = awk
ARGV[1] = one
ARGV[2] = two
ARGV[3] = three
ARGV[4] = four
FS 变量
变量 FS ,是 Field Separator 的缩写,是分割每一行为多个字段/列时的分割符号。默认为 空格 。
如果需要改变默认的分割符,可以使用 -F 命令行选项。
[wsh@test ~ ✔]$ awk 'BEGIN { print "FS=#"FS"#"}' | cat -A
运行以上代码,输出结果如下:
FS=# #$
从输出结果中可以看到,两个 # 号之间,有一个空格,这个就是字段分割符。
OFS 变量
变量 OFS 用于表示输出字段的分隔符,默认的值是一个空格 ( ' ' )。
这个变量指示了 print 函数由多个值的时候,每个值之间如何分隔。
下面的命令用于显示当前的输出分隔符
[wsh@test ~ ✔]$ awk 'BEGIN { print "OFS=#"OFS"#"}' | cat -A
运行以上代码,输出结果如下:
OFS=# #$
从输出结果中可以看到,两个 # 号之间,有一个空格,这个就是输出字段分割符。
NF 变量
变量 NF 是 Number of Fields 的缩写,用于表示当前行分割出来的字段/列数量。
下面的命令输出了当前每一行有被分割出了多少个字段。
[wsh@test ~ ✔]$ echo -e "一 二\n一 二 三\n一 二 三 四" | awk '{ print $0 "\t",NF }'
运行以上代码,输出结果如下:
一 二 2
一 二 三 3
一 二 三 四 4
变量 NF 还可以用于条件判断。
例如,下面的命令输出了哪些字段/列大于 2 的行。
[wsh@test ~ ✔]$ echo -e "一 二\n一 二 三\n一 二 三 四" | awk 'NF > 2'
运行以上代码,输出结果如下:
一 二 三
一 二 三 四
NR 变量
变量 NR 是 Number of Record 的缩写,用于表示当前行的行号,也就是处理到第几行。行编号从 1 开始。
下面的代码,用于在每一行数据的前面输出当前的行号
[wsh@test ~ ✔]$ echo -e "一 二\n一 二 三\n一 二 三 四" | awk '{ print NR". "$0 }'
运行以上代码,输出结果如下:
1. 一 二
2. 一 二 三
3. 一 二 三 四
变量 NR 还可以用于条件判断,例如下面的命令用于输出行号小于 3 的行,也就是第一第二行。
[wsh@test ~ ✔]$ echo -e "一 二\n一 二 三\n一 二 三 四" | awk 'NR < 3'
运行以上代码,输出结果如下:
一 二
一 二 三
FNR 变量
变量 FNR 是 File Number of Record 的缩写,用于表示在当前处理文件中当前行的行编号,也就是当前文件已经处理了多少行。
当我们需要处理多个文件时,该值会随着处理新文件时增加。行编号以 1 开始。
下面的代码,用于在每一行数据的前面输出当前的行号
[wsh@test ~ ✔]$ cp employee.txt employee-1.txt
[wsh@test ~ ✔]$ cp employee.txt employee-2.txt
[wsh@test ~ ✔]$ awk '{ print NR". " FNR". " $0 }' employee-1.txt employee-2.txt
运行以上代码,输出结果如下:
1. 1. 1) 张三 技术部 23
2. 2. 2) 李四 人力部 22
3. 3. 3) 王五 行政部 23
4. 4. 4) 赵六 技术部 24
5. 5. 5) 朱七 客服部 23
6. 1. 1) 张三 技术部 23
7. 2. 2) 李四 人力部 22
8. 3. 3) 王五 行政部 23
9. 4. 4) 赵六 技术部 24
10. 5. 5) 朱七 客服部 23
注意观察: 当处理第二个文件 employee.txt ,变量 NR 值接着上一次的值 5 变成 6 了,而变量 FNR 值重新从 1 开始编号。
变量 FNR 还可以用于条件判断。
**示例:**输出行号小于 3 的行,也就是第一第二行。
[wsh@test ~ ✔]$ awk 'FNR<3' employee-1.txt employee-2.txt
运行以上代码,输出结果如下:
1) 张三 技术部 23
2) 李四 人力部 22
1) 张三 技术部 23
2) 李四 人力部 22
RS 变量
变量 RS 用于指示 AWK 程序使用什么字符作为行分割符。默认情况下,RS 的值为换行符 \n。
[wsh@test ~ ✔]$ awk 'BEGIN { print "RS="RS }' | cat -A
运行以上代码,输出结果如下:
RS=$
$
**示例:**例如 RS统计文件中出现次数最多的10个单词,并输出单词数量。
[wsh@test ~ ✔]$ cat /usr/share/doc/lvm2/README | awk -v RS=' ' '{print $0}' | egrep -v '(^$)|(^[[:punct:]]+)' | sort | uniq -c | sort -nr | head
ORS 变量
变量 ORS 用于表示输出多行时的输出行分隔符,默认的值是新行 ( \n )。
下面的命令用于显示当前的多行输出分隔符:
[wsh@test ~ ✔]$ awk 'BEGIN { print "ORS="ORS }' | cat -A
运行结果如下
ORS=$
$
OFMT 变量
变量 OFMT 用于表示输出数字时如何格式化数字。默认值为 %.6g,也就是最多保留 6 位有效数字。
[wsh@test ~ ✔]$ awk 'BEGIN { print "OFMT="OFMT }'
运行以上命令,输出结果如下
OFMT=%.6g
CONVFMT 变量
变量 CONVFMT 用于表示输出数字时如何格式化数字。默认值为 %.6g,也就是最多保留 6 位有效数字。
[wsh@test ~ ✔]$ awk 'BEGIN { print "数字转换格式为="CONVFMT }'
运行上面的命令,输出结果为
数字转换格式为=%.6g
ENVIRON 变量
变量 ENVIRON 是一个关联数组,也就是一个哈希表,以键值对的方式保存了运行 AWK 时的环境变量。
[wsh@test ~ ✔]$ awk 'BEGIN { print ENVIRON["USER"] }'
运行以上代码,输出结果如下:
wsh
如果你想查看系统设置了哪些环境变量,可以直接在终端里输入 env 命令。
FILENAME 变量
变量 FILENAME 保存了当前正在处理的数据文件名。
不过需要注意的是,在 BEGIN 语句中 FILENAME 变量还处于未定义状态,也就是空字符串.
[wsh@test ~ ✔]$ awk 'END { print FILENAME }' employee.txt
运行上面的命令,输出结果为:
employee.txt
RLENGTH 变量
变量 RLENGTH 用于表示模式匹配中匹配到的字符串的长度。
[wsh@test ~ ✔]$ awk '
BEGIN { if (match("One Two Three", "T.*T")){ print RLENGTH }
}'
运行以上代码,输出结果如下:
5
匹配的内容是:Two T,正好是 5 个字符。
T.*T,是 patten 匹配,其中:
.代表任意字符。*代表前一个字符出现的任意次数。
RSTART 变量
变量 RSTART 用于表示模式匹配中第一个匹配到的字符串的位置。
[wsh@test ~ ✔]$ awk '
BEGIN { if (match("张三 李四 王五", "李四")){ print RSTART }
}'
运行以上代码,输出结果如下:
4
SUBSEP 变量
变量 SUBSEP 用于表示数组下标的分隔符,默认值为 \034。
[wsh@test ~ ✔]$ awk 'BEGIN { print "SUBSEP = " SUBSEP }' | cat -A
运行以上代码,输出结果如下:
SUBSEP = ^\$
$N
对于 AWK 来说,默认的分割符是空白符号,包括 “\t” 和空格 " "。当 AWK 使用分割符对每一行进行分割后,会对每一列/字段进行编号:
$1 $2 $3 ...,分别代表第1列,第2列,第3列…$0,代表一整行。
示例1:
[wsh@test ~ ✔]$ head -n1 /etc/passwd
root:x:0:0:root:/root:/bin/bash[wsh@test ~ ✔]$ head -n1 /etc/passwd |awk '{ print $0 }'
root:x:0:0:root:/root:/bin/bash[wsh@test ~ ✔]$ head -n1 /etc/passwd |awk -F : '{ print $1" "$6 }'
root /root
示例2: 统计 /usr/share/doc 目录下文件size最大的前10个,并显示文件size。
[wsh@test ~ ✔]$ sudo find /usr/share/doc -type f -ls | awk '{print $7,$11}' | sort -nr | head
725773 /usr/share/doc/rpm-4.11.3/ChangeLog.bz2
588023 /usr/share/doc/rsyslog-8.24.0/ChangeLog
548330 /usr/share/doc/xz-5.2.2/ChangeLog
521349 /usr/share/doc/yum-3.4.3/ChangeLog
509135 /usr/share/doc/grub2-common-2.02/grub.html
486761 /usr/share/doc/man-db-2.6.3/ChangeLog
412827 /usr/share/doc/tar-1.26/ChangeLog
411052 /usr/share/doc/findutils-4.5.11/ChangeLog
379303 /usr/share/doc/glib2-2.56.1/NEWS
360877 /usr/share/doc/parted-3.1/ChangeLog# 如何让文件的单位使用human size显示?
[wsh@test ~ ✔]$ sudo find /usr/share/doc -type f -ls | awk '{print $7,$11}' | sort -nr | head |awk '{print $2}' | xargs ls -lh
-rw-r--r--. 1 root root 402K Feb 2 2013 /usr/share/doc/findutils-4.5.11/ChangeLog
-rw-r--r--. 1 root root 371K Apr 7 2018 /usr/share/doc/glib2-2.56.1/NEWS
-rw-r--r--. 1 root root 498K May 20 2022 /usr/share/doc/grub2-common-2.02/grub.html
-rw-r--r--. 1 root root 476K Sep 18 2012 /usr/share/doc/man-db-2.6.3/ChangeLog
-rw-r--r--. 1 root root 353K Mar 3 2012 /usr/share/doc/parted-3.1/ChangeLog
-rw-r--r--. 1 root root 709K Sep 5 2014 /usr/share/doc/rpm-4.11.3/ChangeLog.bz2
-rw-r--r--. 1 root root 575K Jan 10 2017 /usr/share/doc/rsyslog-8.24.0/ChangeLog
-rw-r--r--. 1 root root 404K Mar 12 2011 /usr/share/doc/tar-1.26/ChangeLog
-rw-r--r--. 1 root root 536K Sep 29 2015 /usr/share/doc/xz-5.2.2/ChangeLog
-rw-r--r--. 1 root root 510K Jun 29 2011 /usr/share/doc/yum-3.4.3/ChangeLog
IGNORECASE 变量
变量 IGNORECASE 用于设置模式是否大小写敏感。
默认情况下,这个变量的值为 1 也就是大小写敏感,一旦我们设置为 0,那么模式匹配就是大小写敏感的。
[wsh@test ~ ✔]$ head -n1 /etc/passwd
root:x:0:0:root:/root:/bin/bash# 没有匹配到
[wsh@test ~ ✔]$ head -n1 /etc/passwd |awk '/ROOT/{ print $0 }'# 忽略大小写后匹配到
[wsh@test ~ ✔]$ head -n1 /etc/passwd |awk '
BEGIN { IGNORECASE=1 }
/ROOT/ { print $0}'
# 输出结果如下
root:x:0:0:root:/root:/bin/bash
PROCINFO 变量
PROCINFO 变量是一个关联数组,也就是一个哈希表,以键值对的方式保存着 AWK 进程的相关信息,例如真实有效的 UID 号,进程 ID 号等等。
[wsh@test ~ ✔]$ awk 'BEGIN { print PROCINFO["pid"] }'
3130
awk 运算符
| 运算符 | 描述 |
|---|---|
| =、+=、-=、*=、/=、%=、^=、**= | **赋值运算符:**直接赋值、加赋值、减赋值、乘赋值、除赋值、求余赋值、求幂赋值 |
| +、-、*、/、%、^、 | **算数运算符:**加、减、乘、除、求余、求幂 |
| ++、– | **自增和自减运算符:**自增1、自减1,作为前缀或后缀 |
| +、- | **一元运算符:**一元加、一元减 |
| <、<=、>、>=、==、!= | **关系运算符:**小于、小于等于、大于、大于等于、等于、不等于 |
| ~、!~ | **正则表达式运算符:**匹配和不匹配 |
| &&、||、! | **逻辑运算符:**逻辑与、逻辑或、逻辑非 |
赋值运算符
[wsh@test ~ ✔]$ awk 'BEGIN { x=5;x+=2;print "x="x }'
x=7
[wsh@test ~ ✔]$ awk 'BEGIN { x=5;x-=2;print "x="x }'
x=3
[wsh@test ~ ✔]$ awk 'BEGIN { x=5;x*=2;print "x="x }'
x=10
[wsh@test ~ ✔]$ awk 'BEGIN { x=5;x/=2;print "x="x }'
x=2.5
[wsh@test ~ ✔]$ awk 'BEGIN { x=5;x%=2;print "x="x }'
x=1
[wsh@test ~ ✔]$ awk 'BEGIN { x=5;x^=2;print "x="x }'
x=25
[wsh@test ~ ✔]$ awk 'BEGIN { x=5;x**=2;print "x="x }'
x=25
算数运算符
[wsh@test ~ ✔]$ awk 'BEGIN { x=5;x=x+2;print "x=",x }'
x=7
[wsh@test ~ ✔]$ awk 'BEGIN { x=5;x=x-2;print "x=",x }'
x=3
[wsh@test ~ ✔]$ awk 'BEGIN { x=5;x=x*2;print "x=",x }'
x=10
[wsh@test ~ ✔]$ awk 'BEGIN { x=5;x=x/2;print "x=",x }'
x=2.5
[wsh@test ~ ✔]$ awk 'BEGIN { x=5;x=x%2;print "x=",x }'
x=1
[wsh@test ~ ✔]$ awk 'BEGIN { x=5;x=x^2;print "x=",x }'
x=25
[wsh@test ~ ✔]$ awk 'BEGIN { x=5;x=x**2;print "x=",x }'
x=25
自增和自减运算符
# ++ 在变量后,变量先参与运算,然后再自增1
[wsh@test ~ ✔]$ awk 'BEGIN { x=5;y=x++ + 2;print "x="x,"y="y }'
x=6 y=7# ++ 在变量前,变量先自增1,然后再参与运算
[wsh@test ~ ✔]$ awk 'BEGIN { x=5;y=++x + 2;print "x="x,"y="y }'
x=6 y=8# -- 在变量后,变量先参与运算,然后再自增1
[wsh@test ~ ✔]$ awk 'BEGIN { x=5;y=x-- + 2;print "x="x,"y="y }'
x=4 y=7# -- 在变量前,变量先自减1,然后再参与运算
[wsh@test ~ ✔]$ awk 'BEGIN { x=5;y=--x+ 2;print "x="x,"y="y }'
x=4 y=6
一元运算符
AWK 中的一元运算符只有两个: 一元加号( + )、一元减号( - )。
- 一元加号使用 加号( + ) 表示。它的作用是将右边的操作数乘以
+1也就是乘以1。从某些方面说,一元加号( + )的作用就是将操作数转换为数字。
[wsh@test ~ ✔]$ awk 'BEGIN { x=-10;x=+x;print "x=",x }'
x=-10[wsh@test ~ ✔]$ awk 'BEGIN { x="name";x=+x;print "x=",x }'
x=0[wsh@test ~ ✔]$ awk 'BEGIN { x="123456";x=+x;print "x=",x }'
x=123456
- 一元加号使用 减号( - ) 表示。它的作用是将右边的操作数乘以
-1。从某些方面说,一元减号( - )的作用就是把操作数转换为数字,并执行0 - 操作数运算。
[wsh@test ~ ✔]$ awk 'BEGIN { x=-10;x=-x;print "x=",x }'
x=10
[wsh@test ~ ✔]$ awk 'BEGIN { x="name";x=-x;print "x=",x }'
x=0
[wsh@test ~ ✔]$ awk 'BEGIN { x="123456";x=-x;print "x=",x }'
x=-123456
关系运算符
等于运算符
AWK 中的小于比较运算符用 == 表示,如果左操作数等于右操作数,返回 true,否则返回 false。
[wsh@test ~ ✔]$ awk '
BEGIN {x=25y=25if (x==y) { print x"=="y }
}'
# 输出结果如下
25==25[wsh@test ~ ✔]$ awk '
BEGIN {x=25y=24if (x==y) { print x"=="y }
}'
第二个没有输出,是因为它不满足条件。
不等于运算符
AWK 中的小于比较运算符用 != 表示,如果左操作数不等于右操作数,返回 true,否则返回 false
[wsh@test ~ ✔]$ awk '
BEGIN {x=25y=25if (x!=y) { print x"!="y }
}'[wsh@test ~ ✔]$ awk '
BEGIN {x=25y = 24if (x!= y ) { print x"!="y }
}'
# 输出结果如下
25 != 24
第一个没有输出,是因为它不满足条件。
小于运算符
AWK 中的小于比较运算符用 < 表示,如果左操作数小于右操作数,返回 true,否则返回 false。
[wsh@test ~ ✔]$ awk '
BEGIN {x=25y=25if (x<y) { print x"<"y }
}'[wsh@test ~ ✔]$ awk '
BEGIN {x=25y=24if (x<y) { print x"<"y }
}'[wsh@test ~ ✔]$ awk '
BEGIN {x=25y=26if (x<y) { print x"<"y }
}'
# 输出结果如下
25 < 26
第一个和第二个没有输出,是因为它不满足条件。
小于等于运算符
AWK 中的小于等于比较运算符用 <= 表示,如果左操作数小于或等于右操作数,返回 true,否则返回 false。
[wsh@test ~ ✔]$ awk '
BEGIN {x=25;y=25;if (x<=y) { print x"<="y }
}'
# 输出结果如下
25<=25[wsh@test ~ ✔]$ awk '
BEGIN {x=25y=24if (x<=y) { print x"<="y }
}'[wsh@test ~ ✔]$ awk '
BEGIN {x=25y=26if (x<=y) { print x"<="y }
}'
# 输出结果如下
25 <= 26
第二个没有输出,是因为它不满足条件。
大于运算符
AWK 中的大于比较运算符用 > 表示,如果左操作数大于右操作数,返回 true,否则返回 false。
[wsh@test ~ ✔]$ awk '
BEGIN {x=25y=25if (x>y) { print x">"y }
}'[wsh@test ~ ✔]$ awk '
BEGIN {x=25y=24if (x>y) { print x">"y }
}'
# 输出结果如下
25>24[wsh@test ~ ✔]$ awk '
BEGIN {x=25y=26if (x>y) { print x">"y }
}'
可以看到,只有第二个有输出,那是因为第一个和第三个都不满足条件。
大于等于运算符
AWK 中的大于等于比较运算符用 >= 表示,如果左操作数大于或等于右操作数,返回 true,否则返回 false。
[wsh@test ~ ✔]$ awk '
BEGIN {x=25y=25if (x>=y) { print x">="y }
}'
# 输出结果如下
25>=25[wsh@test ~ ✔]$ awk '
BEGIN {x=25y=24if (x>=y) { print x">="y }
}'
# 输出结果如下
25>=24[wsh@test ~ ✔]$ awk '
BEGIN {x=25y=26if (x>=y) { print x">="y }
}'
第三个没有输出,是因为它不满足条件。
三目运算符
三目运算符可用来简化 if else 条件语句,和 C/C++ 甚至其它有三目运算符的语言具有一样的语法。
condition expression ? statement1 : statement2
当条件表达式 condition expression 返回 true 时,将执行 tement1,否则将执行 statement2。
例如,下面的范例,当 x>y 时,把 x 赋值给 max,否则把 y 赋值给 max。
[wsh@test ~ ✔]$ awk '
BEGIN {x=25b=15(x>y)?max=x:max=yprint "Max="max
}'
# 输出结果如下
Max=25
正则表达式运算符
AWK 支持正则表达式,而且为正则表达式提供了两种匹配方式。
匹配运算符 ~
语法:"string" ~ "patten"
AWK 使用一个 波浪线 ( ~ ) 作为正则表达式匹配运算。
匹配运算符用于在给定的字符串中查找要匹配的字符串,如果找到,则返回 true;否则返回 false。
例如下面的 awk 命令,在每一行中查找字符串 四 ,如果找到则输出当前行。
[wsh@test ~ ✔]$ awk '$0 ~ "四"' employee.txt
运行上面的 awk 命令,输出结果如下
2) 李四 人力部 22
不匹配运算符 !~
语法:"string" !~ "patten"
AWK 使用一个 感叹号 和波浪线 ( ~ ) 作为正则表达式不匹配运算符 ( !~ ) 。
不匹配运算符用于在给定的字符串中查找要匹配的字符串,如果没有找到,则返回 true;否则返回 false。
例如下面的 awk 命令,在每一行中查找字符串 四 ,如果没有发现则输出当前行。
[wsh@test ~ ✔]$ awk '$0 !~ "四"' employee.txt
运行上面的 awk 命令,输出结果如下
1) 张三 技术部 23
3) 王五 行政部 23
4) 赵六 技术部 24
5) 朱七 客服部 23
正则表达式
AWK 早早的就支持正则表达式了。
虽然支持的模式并没有 Perl 或 Python 那么强大,但是,作为行处理器,也足够使用了。
正则表达式最重要的作用,就是可以使用简单的语句完成复杂的任务。
| 字符 | 描述 |
|---|---|
| […] | 匹配 […] 中的任意一个字符 |
| [^…] | 匹配除了 […] 中字符的所有字符 |
| [a-z] | 匹配所有小写字母。 |
| [A-Z] | 匹配所有大写字母。 |
| [0-9] | 匹配所有数字。 |
| . | 匹配除换行符(\n、\r)之外的任何单个字符,相等于 [\^\n\r]。 |
| \ | 将下一个字符标记为或特殊字符、或原义字符、或向后引用、或八进制转义符。例如, ‘n’ 匹配字符 ‘n’。‘\n’ 匹配换行符。序列 ‘\’ 匹配 “”,而 ‘(’ 则匹配 “(”。 |
| | | 指明两项之间的一个选择。要匹配 |,请使用 |。 |
字符集
| 选项 | 描述 |
|---|---|
| [[:digit:]] | 数字: 0 1 2 3 4 5 6 7 8 9 等同于[0-9] |
| [[:xdigit:]] | 十六进制数字: 0 1 2 3 4 5 6 7 8 9 A B C D E F a b c d e f |
| [[:lower:]] | 小写字母:在 C 语言环境和ASCII字符编码中,对应于**[a-z]** |
| [[:upper:]] | 大写字母:在 C 语言环境和ASCII字符编码中,对应于[A-Z] |
| [[:alpha:]] | 字母字符:[[:lower:]和[[:upper:]];在C语言环境和ASCII字符编码中,等同于**[A-Za-z]** |
| [[:alnum:]] | 字母数字字符:[:alpha:]和[:digit:];在C语言环境和ASCII字符编码中,等同于**[0-9A-Za-z]** |
| [[:blank:]]或者[[:space:]] | 空白字符:在 C 语言环境中,它对应于制表符、换行符、垂直制表符、换页符、回车符和空格。 |
| [[:punct:]] | 标点符号:在C语言环境和ASCII字符编码中,它对应于!" # $ % &'()*+,-./:;<=>?@[]^_`{|}~ |
| [[:print:]]或者 [[:graph:]] | 可打印字符: [[:alnum:]]、[[:punct:]]。 |
| [[:cntrl:]] | 控制字符。在 ASCII中, 这些字符对应八进制代码000到037和 177 (DEL)。 |
转义字符
| 字符 | 描述 |
|---|---|
| \cx | 匹配由x指明的控制字符。例如, \cM 匹配一个 Control-M 或回车符。x的值必须为 A-Z 或 a-z 之一。否则,将 c 视为一个原义的 ‘c’ 字符。 |
| \f | 匹配一个换页符。等价于 \x0c 和 \cL。 |
| \n | 匹配一个换行符。等价于 \x0a 和 \cJ。 |
| \r | 匹配一个回车符。等价于 \x0d 和 \cM。 |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。注意 Unicode 正则表达式会匹配全角空格符。 |
| \S | 匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。 |
| \w | 匹配字母、数字、下划线。等价于 [A-Za-z0-9_] |
| \W | 匹配任何非单词字符。等价于[^A-Za-z0-9_] |
| \t | 匹配一个制表符。等价于 \x09 和 \cI。 |
| \v | 匹配一个垂直制表符。等价于 \x0b 和 \cK。 |
限定次数
| 字符 | 描述 |
|---|---|
| * | 匹配前面的子表达式零次或多次。例如,zo*能匹配"z"以及"zoo"。 |
| + | 匹配前面的子表达式一次或多次。例如,'zo+'能匹配"zo"以及"zoo"。 |
| ? | 匹配前面的子表达式零次或一次。例如,"do(es)?“可以匹配"do”、“does"中的"does”、“doxy"中的"do”。?等价于{0,1}。 |
| {n} | n是一个非负整数。匹配确定的n次。例如,'o{2}‘不能匹配"Bob"中的’o’,但是能匹配"food"中的两个o。 |
| {n,} | n是一个非负整数。**至少匹配n次。*例如,'o{2,}‘不能匹配"Bob"中的’o’,但能匹配"foooood"中的所有o。'o{1,}‘等价于’o+’。'o{0,}'则等价于’o’。 |
| {,m} | m是一个非负整数。**最多匹配m次。**例如,'o{,2}‘不能匹配"Booob"中的’o’,但能匹配"food"中的所有o。'o{,2}‘等价于’o{0,2}’。 |
| {n,m} | m和n均为非负整数,其中n<=m。**最少匹配n次且最多匹配m次。**例如,"o{1,3}"将匹配"fooooood"中的前三个o。'o{0,1}‘等价于’o?’。请注意在逗号和两个数之间不能有空格。 |
| () | 标记一个子表达式的开始和结束位置。**子表达式可以获取供以后使用。**要匹配这些字符,请使用 ( 和 )。 |
定位符,使您能够匹配行首或行尾,单词内、单词开头或者单词结尾。
| 字符 | 描述 |
|---|---|
| ^ | **匹配行首位置。**例如,^wsh,匹配以wsh开头的行。 |
| $ | **匹配行末位置。**例如,wsh$,匹配以wsh结尾的行。 |
| \b | 匹配一个单词边界,即字与空格间的位置。 |
| \B | 非单词边界匹配。 |
| < | 匹配一个单词左边界。 |
| > | 匹配一个单词右边界。 |
示例:
-
.点号。[wsh@test ~ ✔]$ echo -e "cat\nbat\nfun\nfin\nfan" # 输出结果如下 cat bat fun fin fan[wsh@test ~ ✔]$ echo -e "cat\nbat\nfun\nfin\nfan" | awk '/f.n/' # 输出结果如下 fun fin fan -
^行首和$行位[wsh@test ~ ✔]$ echo -e "cat\nbat\nfun\nfin\nfan" | awk '/^fin/' # 输出结果如下 fin[wsh@test ~ ✔]$ echo -e "cat\nbat\nfun\nfin\nfan" | awk '/fin$/' # 输出结果如下 fin -
[]和[^][wsh@test ~ ✔]$ echo -e "cat\nbat\nfun\nfin\nfan" | awk '/f[ai]n/' # 输出结果如下 fin fan [wsh@test ~ ✔]$ echo -e "cat\nbat\nfun\nfin\nfan" | awk '/f[^ai]n/' # 输出结果如下 fun -
|多选1[wsh@test ~ ✔]$ echo -e "cat\nbat\nfun\nfin\nfan" | awk '/fan|cat/' # 输出结果如下 cat fan -
?0 次或 1 次[wsh@test ~ ✔]$ echo -e "Colour\nColor" | awk '/Colou?r/' # 输出结果如下 Colour Color -
*任意次数[wsh@test ~ ✔]$ echo -e "ca\ncat\ncatt" | awk '/cat*/' # 输出结果如下 ca cat catt -
+1 次以上[wsh@test ~ ✔]$ echo -e "111\n22\n123\n234\n456\n222" | awk '/2+/' # 输出结果如下 22 123 234 222 -
()子串[wsh@test ~ ✔]$ echo -e "Apple Juice\nApple Pie\nApple Tart\nApple Cake" | awk '/Apple (Juice|Cake)/' # 输出结果如下 Apple Juice Apple Cake
逻辑运算符
逻辑运算符包括 逻辑与( && )、逻辑或( || )、逻辑非 ( ! )
逻辑与( && )
逻辑与运算符使用两个 & 表示。
语法:expr1 && expr2。
逻辑与( && )运算符的计算结果遵循以下规则:
- 如果 expr1 和 expr2 的计算结果都为 true,则结果为 true; 否则返回 false。
- 当且仅当 expr1 的计算结果为 true 时,才会计算 expr2。
[wsh@test ~ ✔]$ awk '
BEGIN {num=5if (num>=0 && num<=7) { print "0<="num"<=7" }
}'
运行上面的 awk 命令,输出结果为
0<=5<=7
逻辑或( || )
逻辑或运算符使用 || 表示。
语法:expr1 || expr2。
逻辑或( || )运算符的计算结果遵循以下规则
- 如果 expr1 和 expr2 的计算结果只要有一个为 true,则结果为 true; 否则返回 false
- 当且仅当 expr1 的计算结果为 false 时,才会计算 expr2
[wsh@test ~ ✔]$ awk '
BEGIN {ch="\n"if (ch==" " || ch=="\t" || ch=="\n") { print "Current character is whitespace." }
}'
运行上面的 awk 命令,输出结果如下:
Current character is whitespace
逻辑非 ( ! )
逻辑非运算符使用 感叹号( !) 表示。
语法:! expr1。
逻辑非运算符返回 expr1 的逻辑补语,也就是说如果 expr1 的计算结果为 true,则返回 0; 否则返回 1。
例如下面的 AWK 命令,因为 name 为空字符串,所以 length(name) 的结果为 0,对 0 执行逻辑非运算,则为 true。
[wsh@test ~ ✔]$ awk '
BEGIN { site = ""if (! length(site)){ print "site is empty string." }
}'
运行上面的 awk 命令,输出结果如下:
site is empty string.
awk 判断语句
AWK 脱胎于 C 语言,自然也有着 C 语言的影子。
从某些方面说,与其他编程语言一样,AWK 提供条件语句来控制程序的流程。
不过 AWK 中的条件判断语言比较简单,就是简单的 if 语句、if-else 语句、if-else-if 语句
if 语句
AWK 中的 if 语句的语法格式如下
if (condition)action
如果有多个动作需要执行,我们可以把多个动作语句放在一对 大括号 {} 之中。
这种情况下,语法格式如下
if (condition) {action-1action-1..action-n
}
示例:使用 if 语句检查数字是否是偶数。
[wsh@test ~ ✔]$ awk 'BEGIN {num=10if (num%20) { printf "%d is even number.\n", num }
}'
运行以上 awk 命令,输出结果如下:
10 is even number.
if-else 语句
if-else 语句的语法格式如下:
if (condition)action-1
elseaction-2
在上面这个 if-else 语句中,如果 condition 条件返回 true 值,那么 action-1 语句块会执行,但如果 condition 条件返回 false 值,那么 action-2 语句块会执行。
示例:
[wsh@test ~ ✔]$ awk '
BEGIN {num=11if (num%2==0) { printf "%d is even number.\n", num }else{ printf "%d is odd number.\n", num}
}'
运行以上 awk 命令,输出结果如下
11 is odd number.
if-else_if 语句
AWK 中允许使用 if-else-if 语句来完成多个条件的判断。
if-else-if 语句本质上来说就是多个 if-else 语句。
示例:
[wsh@test ~ ✔]$ awk '
BEGIN {a = 30if (a==10) { print "a=10" }else if (a==20){ print "a=20" }else if (a==30) { print "a=30" }
}'
运行以上 awk 命令,输出结果如下
a=30
if-else_if-else 语句
AWK 中允许使用 if-else_if-else 语句来完成多个条件的判断。
示例:
[wsh@test ~ ✔]$ awk '
BEGIN {a = 30if (a==10) { print "a=10" }else if (a==20){ print "a=20" }else{ print "a=30" }
}'
运行以上 awk 命令,输出结果如下
a=30
awk 循环语句
循环 用于以重复方式执行一组动作。只要循环条件为真,循环执行就会继续。
AWK 中三大循环语句分别是:
for循环语句。while循环语句。do while循环语句。
AWK 中三大循环状态变更语句分别是:
break语句,退出当前循环。continue语句,终止当前迭代的执行,开始下一个迭代。exit语句,退出当前程序。
for 循环
语法格式如下:
for (initialization; condition; increment/decrement)action
for 循环的小括号内总共包含三大块语句,和两个必选的 分号 ;,三个语句都是可以省略的。
- 第一个语句称之为:初始化语句。只要执行一些初始化操作,比如初始化 循环变量。
- 第二个语句称之为:循环判断语句。也就是 检查条件,确定是否有必要进行下一次循环。
- 第三个语句称之为:循环变量递增语句。一般情况下用于递增循环变量。
当循环判断语句返回 true ,也就是当前循环允许被执行,那么就会执行后面的 action 语句块。只要 循环判断语句 一直返回 true,那么它就一直循环下去,永不退出。
第二个,我们要讲诉的是小括号内三大语句的执行时机。
- 初始化语句 在整个循环开始前执行,而且只会执行一次。
- 循环判断语句 会在每次循环前执行,如果不满足条件则退出整个循环,如果满足条件则执行 action
- 循环变量递增语句 会在每次循环结束后执行,用于递增循环变量。
好了,for 循环语句差不多就这些知识了,下面我们使用一个范例来演示一下
**示例1:**循环输出 1 2 3 4 5
[wsh@test ~ ✔]$ awk '
BEGIN {for (i=1;i<=5;++i) { print i}
}'
运行以上 awk 命令,输出结果如下:
1
2
3
4
5
**示例2:**9x9乘法表
[wsh@test ~ ✔]$ awk '
BEGIN {for (i=1;i<=9;i++){for (j=1;j<=i;j++){ printf "%d*%d=%-2d ",j,i,j*i } # 用%-2d使输出的更美观.print}
}'
运行以上 awk 命令,输出结果如下:
1*1=1
1*2=2 2*2=4
1*3=3 2*3=6 3*3=9
1*4=4 2*4=8 3*4=12 4*4=16
1*5=5 2*5=10 3*5=15 4*5=20 5*5=25
1*6=6 2*6=12 3*6=18 4*6=24 5*6=30 6*6=36
1*7=7 2*7=14 3*7=21 4*7=28 5*7=35 6*7=42 7*7=49
1*8=8 2*8=16 3*8=24 4*8=32 5*8=40 6*8=48 7*8=56 8*8=64
1*9=9 2*9=18 3*9=27 4*9=36 5*9=45 6*9=54 7*9=63 8*9=72 9*9=81
while 循环
语法格式如下:
while (condition)action
while 循环会在每次执行前检查循环条件 condition 的值是否为 true。只要为 true,就会执行 action ,那么循环就会一直下去。
**示例1:**循环输出 1 2 3 4 5
[wsh@test ~ ✔]$ awk '
BEGIN {i=1while (i < 6) { print i++i }
}'
运行以上 awk 命令,输出结果如下:
1
2
3
4
5
do-while 循环
do-while 循环会先执行一次循环代码,然后在判断条件是否允许下一次执行。
语法格式如下
doaction
while (condition)
示例:
[wsh@test ~ ✔]$ awk 'BEGIN {i = 1; do { print i; ++i } while (i < 6) }'
运行以上 awk 命令,输出结果如下
1
2
3
4
5
break 语句
break 语句的作用:退出当前循环。
break 语句的语法格式:break。
范例:sum 大于 50 就退出循环。
[wsh@test ~ ✔]$ awk '
BEGIN {sum=0for (i=0;i<20;++i){sum+=iif (sum>50) { break }else { print "Sum="sum }}
}'
运行以上 awk 命令,输出结果如下
Sum=0
Sum=1
Sum=3
Sum=6
Sum=10
Sum=15
Sum=21
Sum=28
Sum=36
Sum=45
continue 语句
continue 语句用于退出当前迭代,也就是剩下的语句不执行了,开始下一个迭代。
continue 语句的语法格式如下:continue。
示例:
[wsh@test ~ ✔]$ awk '
BEGIN {for (i=1;i<=20;++i){if (i%2==0) { print i }else { continue }}
}'
运行以上 awk 命令,输出结果如下:
2
4
6
8
10
12
14
16
18
20
exit 语句
exit 语句是用来退出awk程序的。它接受一个整数作为参数,作为 AWK 进程的退出状态代码。
如果未提供参数,则退出返回状态 0。
exit 语句的语法格式如下:exit (status_code)。
示例:
[wsh@test ~ ✔]$ awk '
BEGIN {sum=0for (i=0;i<20;++i){sum+=iif (sum>50) { exit(10) }else { print "Sum="sum }}
}'
运行以上 awk 命令,输出结果如下
Sum=0
Sum=1
Sum=3
Sum=6
Sum=10
Sum=15
Sum=21
Sum=28
Sum=36
Sum=45
在命令行/终端模式下,我们要如何检查程序的退出状态码呢?使用 $?。
[wsh@test ~ ✔]$ echo $?
运行以上 awk 命令,输出结果如下
10
awk 数组
AWK 中的数组,既可以是普通数组,也可以是关联数组。也就是说,数组的索引/下标不必是连续的数字。
AWK 中的数组不用事先声明数组的大小,在运行时动态的增长。
创建和访问数组
AWK 中创建数组的语法很简单,创建数组和给数组添加/修改元素的方式语法一样。
语法:array_name[index] = value
array_name是数组的名字。index是数组的索引。value是分配给index下标/索引的值。
访问数组元素,也是通过下标。
语法:array_name[index]
**示例1:**以水果作为键,以水果颜色作为值。
[wsh@test ~ ✔]$ awk '
BEGIN {colour["芒果"] = "橘色";colour["橘子"] = "黄色";colour["苹果"] = "红色";print colour["芒果"],colour["橘子"],colour["苹果"]
}'
运行以上 awk 命令,输出结果如下:
橘色 黄色 红色
从上面的代码中可以看出,访问数组的方式也很简单,就是使用 array_name[index]。
打印数组所有元素
**示例1:**使用无序下标循环输出。
[wsh@test ~ ✔]$ awk 'BEGIN {colour["芒果"] = "橘色"colour["橘子"] = "黄色"colour["苹果"] = "红色"for (i in colour){ print i": "colour[i]}
}'
运行以上 awk 命令,输出结果如下:
苹果: 红色
芒果: 橘色
橘子: 黄色
**示例2:**使用有序下标循环输出。
[wsh@test ~ ✔]$ awk 'BEGIN {colour[0] = "橘色"colour[1] = "黄色"colour[2] = "红色"lens=length(colour)for (i=0;i<lens;i++){ print i": "colour[i]}
}'
说明: 版本够高的awk可以直接使用方法length()得到数组长度。如果传给length的变量是一个字符串,那么length返回的则字符串的长度。
运行以上 awk 命令,输出结果如下:
0: 橘色
1: 黄色
2: 红色
示例3: 统计文件/usr/share/doc/atk/README中出现频率最好的10个单词,并显示对应数量。
[wsh@test ~ ✔]$ cat commands.awk
{for (i=1;i<=NF;i++){count[$i]++}
}
END {for (i in count){print i" "count[i]}
}[wsh@test ~ ✔]$ cat /usr/share/doc/atk/README | awk -f commands.awk | sort -nr -k2 | awk '$1 !~ "^[[:punct:]]+"'| head
the 6
ATK 6
You 5
can 5
to 3
source 3
ninja 3
also 3
you 2
use 2
删除数组元素
向数组插入元素,我们使用的是 赋值运算符。而从数组中删除元素,我们可以使用 delete 语句。
delete 关键字用于从数组中删除一个元。
语法:delete array_name[index]
示例1:
[wsh@test ~ ✔]$ awk 'BEGIN {colour["芒果"] = "橘色"colour["橘子"] = "黄色"colour["苹果"] = "红色"delete colour["橘子"]for (i in colour){ print i": "colour[i]}
}'
运行以上 awk 命令,输出结果如下:
苹果: 红色
芒果: 橘色
多维数组
AWK 仅仅只支持一维数组,不支持多维数组。
但是,我们可以使用一维数组来模拟多维数组。
例如,下面这个 3x3 的二维数组。
100 200 300
400 500 600
700 800 900
array[0][0] 存储着值 100,array[0][1] 存储着值 200 ,因此类推…
为了在位置 [0][0] 存储 100, 在 AWK 中可以这么做:array["0,0"] = 100
虽然,看起来我们使用 0,0作为索引,但这些不是两个索引。实际上,它只是一个字符串 "0,0" 的索引。
使用这种方式,我们就可以轻松模拟多维数组
[wsh@test ~ ✔]$ awk 'BEGIN {array["0,0"] = 100;array["0,1"] = 200;array["0,2"] = 300;array["1,0"] = 400;array["1,1"] = 500;array["1,2"] = 600;# print array elementsprint "array[0,0] = " array["0,0"];print "array[0,1] = " array["0,1"];print "array[0,2] = " array["0,2"];print "array[1,0] = " array["1,0"];print "array[1,1] = " array["1,1"];print "array[1,2] = " array["1,2"];
}'
运行以上 awk 命令,输出结果如下
array[0,0] = 100
array[0,1] = 200
array[0,2] = 300
array[1,0] = 400
array[1,1] = 500
array[1,2] = 600
通过 0,1 这种字符串索引,我们还可以对多维数组执行各种操作,例如对 元素/索引 进行排序。而且,我们还可以使用 assort 和 asorti 函数对数组进行排序。
awk 函数
内置字符串函数
| 格式 | 描述 |
|---|---|
| gsub( Ere, Repl, [ In ] ) | 除了正则表达式所有具体值被替代这点,它和 sub 函数完全一样地执行。 |
| sub( Ere, Repl, [ In ] ) | 用 Repl 参数指定的字符串替换 In 参数指定的字符串中的由 Ere 参数指定的扩展正则表达式的第一个具体值。sub 函数返回替换的数量。出现在 Repl 参数指定的字符串中的 &(和符号)由 In 参数指定的与 Ere 参数的指定的扩展正则表达式匹配的字符串替换。如果未指定 In 参数,缺省值是整个记录($0 记录变量)。 |
| index( String1, String2 ) | 在由 String1 参数指定的字符串(其中有出现 String2 指定的参数)中,返回位置,从 1 开始编号。如果 String2 参数不在 String1 参数中出现,则返回 0(零)。 |
| length [(String)] | 返回 String 参数指定的字符串的长度(字符形式)。如果未给出 String 参数,则返回整个记录的长度($0 记录变量)。 |
| blength [(String)] | 返回 String 参数指定的字符串的长度(以字节为单位)。如果未给出 String 参数,则返回整个记录的长度($0 记录变量)。 |
| substr( String, M, [ N ] ) | 返回具有 N 参数指定的字符数量子串。子串从 String 参数指定的字符串取得,其字符以 M 参数指定的位置开始。M 参数指定为将 String 参数中的第一个字符作为编号 1。如果未指定 N 参数,则子串的长度将是 M 参数指定的位置到 String 参数的末尾 的长度。 |
| match( String, Ere ) | 在 String 参数指定的字符串(Ere 参数指定的扩展正则表达式出现在其中)中返回位置(字符形式),从 1 开始编号,或如果 Ere 参数不出现,则返回 0(零)。RSTART 特殊变量设置为返回值。RLENGTH 特殊变量设置为匹配的字符串的长度,或如果未找到任何匹配,则设置为 -1(负一)。 |
| tolower( String ) | 返回 String 参数指定的字符串,字符串中每个大写字符将更改为小写。大写和小写的映射由当前语言环境的 LC_CTYPE 范畴定义。 |
| toupper( String ) | 返回 String 参数指定的字符串,字符串中每个小写字符将更改为大写。大写和小写的映射由当前语言环境的 LC_CTYPE 范畴定义。 |
| printf(Format, Expr, Expr, . . . ) | 根据 Format 参数指定的 printf 子例程格式字符串来格式化 Expr 参数指定的表达式并返回最后生成的字符串。 |
asort 函数
作用: 按 ASCII 字符顺序对数组 arr 的值进行排序。排序完后下标从 1 开始重新索引。
语法: asort(arr[,d[,how]]
语法说明:
arr,必填,要排序的数组。d,选填,如果传递了该参数,那么就不会修改数组arr,而是把arr中的所有元素都拷贝到 数组d,然后对d进行排序。how,选填。
示例:
[wsh@test ~ ✔]$ awk 'BEGIN {arr[0]="Ten"arr[1]="Nine"arr[2]="One"print "Array elements before sorting:"for (i in arr) {print i": "arr[i]}printasort(arr)print "Array elements after sorting:"for (i in arr) {print i": "arr[i]}
}'
运行以上 awk 命令,输出结果如下:
Array elements before sorting:
0: Ten
1: Nine
2: OneArray elements after sorting:
1: Nine
2: One
3: Ten
asorti 函数
作用: 按 ASCII 字符顺序对数组 arr 的键进行排序。排序完后下标从 1 开始重新索引。 数组的值变更为位原先的下标值。
语法: asorti(arr[,d[,how]]
语法说明:
arr,必填,要排序的数组。d,选填,如果传递了该参数,那么就不会修改数组arr,而是把arr中的所有元素都拷贝到 数组d,然后对d进行排序。how,选填。
示例:
[wsh@test ~ ✔]$ awk 'BEGIN {arr["Ten"]=0arr["Nine"]=1arr["One"]=2print "Array elements before sorting:"for (i in arr) {print i": "arr[i]}printasorti(arr)print "Array elements after sorting:"for (i in arr) {print i": "arr[i]}
}'
运行以上 awk 命令,输出结果如下:
Array elements before sorting:
Ten: 0
One: 2
Nine: 1Array elements after sorting:
1: Nine
2: One
3: Ten
length 函数
作用: 用于返回一个字符串的总字节数。。
语法: length(str)
语法说明: str,要统计的字符串。
示例1: 英文字符串
[wsh@test ~ ✔]$ awk 'BEGIN {str="Hello, World !"print "\""str"\"", "的长度为:", length(str)
}'
运行以上 awk 命令,输出结果如下:
"Hello, World !" 的长度为: 14
示例2: 中文字符串
[wsh@test ~ ✔]$ awk 'BEGIN {str="你好!"print "\""str"\"", "的长度为:", length(str)
}'
运行以上 awk 命令,输出结果如下:
"你好!" 的长度为: 3
sub 函数
作用: 在一个字符串中查找指定的 字符串,找到之后则替换为另一个字符串。只会替换一次。
语法: sub(search[,sub],string)
语法说明:
search,要查找和替换的字符串。sub,要替换为的字符串。string,源字符串。
示例:
[wsh@test ~ ✔]$ awk 'BEGIN {str = "Hello, World"print "替换前:" strsub("o", "wsh", str)print "替换后:" str
}'
运行以上 awk 命令,输出结果如下:
替换前:Hello, World
替换后:Hellwsh, World
gsub 函数
作用: 在一个字符串中查找指定 模式 匹配的全部字符串,找到之后都替换为另一个字符串。
语法: gsub(regex, sub, string)
语法说明:
regex,要查找的模式。sub,要替换为的字符串。string,源字符串。
示例:
[wsh@test ~ ✔]$ awk 'BEGIN {str = "Hello, World"print "替换前:" strgsub("o[a-z]*", "wsh", str)print "替换后:" str
}'
运行以上 awk 命令,输出结果如下:
替换前:Hello, World
替换后:Hellwsh, Wwsh
index 函数
作用: 用于查找一个字符串在另一个字符串第一个出现的位置。如果找到则返回找到的位置,否则返回 0。
语法: index(str, sub)
语法说明:
str,被查找的字符串。sub,要查找的字符串,==不支持==正则表达式。
示例1:
[wsh@test ~ ✔]$ awk 'BEGIN {str="One Two Three"subs="One"ret=index(str, subs)printf "子串 \"%s\" 的位置为:%d\n", subs, ret
}'
运行以上 awk 命令,输出结果如下:
子串 "One" 的位置为:1
示例2:
[wsh@test ~ ✔]$ awk 'BEGIN {str="One Two Three"subs="Two"ret=index(str, subs)printf "子串 \"%s\" 的位置为:%d\n", subs, ret
}'
运行以上 awk 命令,输出结果如下:
子串 "Two" 的位置为:5
示例3:
[wsh@test ~ ✔]$ awk 'BEGIN {str="One Two Three"subs="Four"ret=index(str, subs)printf "子串 \"%s\" 的位置为:%d\n", subs, ret
}'
运行以上 awk 命令,输出结果如下:
子串 "Four" 的位置为:0
match 函数
作用: 用于查找匹配模式的第一个子串位置。如果没找到则返回 0,找到则返回最长子串的开始位置。
语法: match(str, regex)
语法说明:
str,被查找的字符串。regex,要查找的模式,==支持==正则表达式。
示例1: 找到的字符串在行首
[wsh@test ~ ✔]$ awk 'BEGIN {str="One Two Three Twoo Four"subs="On[[:alpha:]]*"ret=match(str, subs)printf "子串 \"%s\" 的位置:%d\n", subs, ret
}'
运行以上 awk 命令,输出结果如下:
子串 "On[[:alpha:]]*" 的位置:1
示例2: 找到的字符串在中间
[wsh@test ~ ✔]$ awk 'BEGIN {str="One Two Three Twoo Four"subs="Tw[[:alpha:]]*"ret=match(str, subs)printf "子串 \"%s\" 的位置:%d\n", subs, ret
}'
运行以上 awk 命令,输出结果如下:
子串 "Tw[[:alpha:]]*" 的位置:5
示例3: 找不到字符串
[wsh@test ~ ✔]$ awk 'BEGIN {str="One Two Three Twoo Four"subs="Ta[[:alpha:]]*"ret=match(str, subs)printf "子串 \"%s\" 的位置:%d\n", subs, ret
}'
运行以上 awk 命令,输出结果如下:
子串 "Ta[[:alpha:]]*" 的位置:0
split 函数
作用: 用于把一个字符串根据给定的 模式 分割成多个子串。如果没有传递 模式 则会使用变量 FS 的值。
变量
FS的默认值是 空白符 ,可以通过-f选项自定义。
语法: split(str, arr, regex)
语法说明:
str,被分割的字符串。arr,保存了分割之后的子串。regex,用于分割的模式。
示例1: 根据指定的模式分割字符串。
[wsh@test ~ ✔]$ awk 'BEGIN {str = "春,夏,秋,冬"split(str, arr, ",")printf "Array contains following values: "for (i in arr) {printf "%s ",arr[i]}
}'
运行以上 awk 命令,输出结果如下:
Array contains following values: 春 夏 秋 冬
示例2: 如果没有传递分割模式,则使用变量 FS 的值 根据指定的模式分割字符串。
[wsh@test ~ ✔]$ awk 'BEGIN {str = "春 夏 秋 冬"split(str, arr)printf "Array contains following values: "for (i in arr) {printf "%s ",arr[i]}
}'
运行以上 awk 命令,输出结果如下:
Array contains following values: 春 夏 秋 冬
示例3: 如果分割的模式没找到,则返回将整个字符串当作子串。
[wsh@test ~ ✔]$ awk 'BEGIN {str = "春 夏 秋 冬"split(str, arr, ",")printf "Array contains following values: "for (i in arr) {printf "%s ",arr[i]}
}'运行以上 awk 命令,输出结果如下:
Array contains following values: 春 夏 秋 冬
strtonum 函数
作用: 用于检查一个字符串是否数字并将它转换为十进制数字。
语法: strtonum(str)
语法说明: str是要转换的字符串。
转换规则如下:
- 如果字符串
str以数字0开始,则会当作一个八进制数字。 - 如果字符串
str以字符0x或0X开始,则会被当作一个十六进制数字。 - 否则会假设它是一个十进制数字。
- 如果以上都不是,则直接返回数字
0。
示例1: 八进制转十进制
[wsh@test ~ ✔]$ awk 'BEGIN {printf "八进制 \"123\" 转换成 十进制 \"%d\"\n",strtonum("0123")
}'
运行以上 awk 命令,输出结果如下:
八进制 "123" 转换成 十进制 "83"
示例2: 十六进制转十进制
[wsh@test ~ ✔]$ awk 'BEGIN {printf "十六进制 \"123\" 转换成 十进制 \"%d\"\n",strtonum("0x123")
}'
运行以上 awk 命令,输出结果如下:
十六进制 "123" 转换成 十进制 "291"
示例3: 不是数字字符串
[wsh@test ~ ✔]$ awk 'BEGIN {printf "不是数组字符串:\"%d\"\n",strtonum("你好")
}'
运行以上 awk 命令,输出结果如下:
不是数组字符串:"0"
示例4: 如果以数字开始则会尽量转换直到遇到不是数字的字符结束。
[wsh@test ~ ✔]$ awk 'BEGIN {printf "八进制 \"123\" 转换成 十进制 \"%d\"\n",strtonum("0123abc")
}'
运行以上 awk 命令,输出结果如下:
八进制 "123" 转换成 十进制 "83"
substr 函数
作用: 用于返回字符串 str 中的从 start 的位置开始,长度为 l 的子串。
语法: substr(str, start, l)
语法说明:
str,源字符串。start,子串开始位置。l,子串的长度。
示例:
[wsh@test ~ ✔]$ awk 'BEGIN {str="Hello, wsh@shell"subs=substr(str, 1, 5)print "子串为:" subs
}'
运行以上 awk 命令,输出结果如下:
子串为:Hello
tolower 函数
**作用:**用于将指定的字符串中的大写字母转换为小写字母。
语法: tolower(str)
语法说明: str,要转换的字符串。
示例:
[wsh@test ~ ✔]$ awk 'BEGIN {str = "HELLO, WORLD !"print str " 的小写:" tolower(str)
}'
运行以上 awk 命令,输出结果如下:
HELLO, WORLD ! 的小写:hello, world !
toupper 函数
作用: 用于将指定的字符串中的小写字母转换为大写字母。
语法: toupper(str)
语法说明: str,要转换的字符串。
示例:
[wsh@test ~ ✔]$ awk 'BEGIN {str = "hello, world !"print str " 的大写:" toupper(str)
}'
运行以上 awk 命令,输出结果如下:
hello, world ! 的大写:HELLO, WORLD !
内置算术函数
| 格式 | 描述 |
|---|---|
| atan2( y,x) | 返回 y/x的反正切。 |
| cos(x) | 返回x的余弦;x是弧度。 |
| sin(x) | 返回x的正弦;x是弧度。 |
| exp(x) | 返回x幂函数。 |
| log(x) | 返回x的自然对数。 |
| sqrt(x) | 返回x平方根。 |
| int(x) | 返回x的截断至整数的值。 |
| rand() | 返回任意数字 n,其中 0 <= n < 1。 |
| srand([expr]) | 将 rand 函数的种子值设置为 Expr 参数的值,或如果省略 Expr 参数则使用某天的时间。返回先前的种子值。 |
[wsh@test ~ ✔]$ awk 'BEGIN { srand()num=int(1000*rand())print num
}'
# 输出:78# 再次执行
[wsh@test ~ ✔]$ awk 'BEGIN { srand()num=int(1000*rand())print num
}'
# 输出:694
内置时间函数
| 格式 | 描述 |
|---|---|
| systime() | 得到时间戳,返回从1970年1月1日开始到当前时间(不计闰年)的整秒数。 |
| mktime( YYYY MM dd HH MM ss[ DST]) | 生成时间格式。 |
| strftime([format [, timestamp]]) | 格式化时间输出,将时间戳转为时间字符串 具体格式,见下表。 |
systime 函数
作用: 返回从格林威治时间 1970-01-01 00:00:00 UTC 以来经过的 秒数。
语法: systime()
示例: 输出当前时间戳
[wsh@test ~ ✔]$ awk 'BEGIN {print "当前时间的时间戳为:" systime()
}'运行上面的 awk 指令,输出结果如下:
当前时间的时间戳为:1680697550
mktime 函数
作用: 用于将指定格式的 时间字符串 转换为 时间戳。
语法: mktime(datespec)
语法说明: datespec,指定格式的 时间字符串,符合以下格式 YYYY MM DD HH MM SS 。
示例: 将当前时间转换为时间戳格式。
[wsh@test ~ ✔]$ awk 'BEGIN {print "当前时间的时间戳为:" mktime("2019 05 30 21 27 10")
}'
运行上面的 awk 指令,输出结果如下:
当前时间的时间戳为:1559222830
strftime 函数
作用: 用于将一个 时间戳 格式的时间根据指定的 时间格式化 转成字符串形式。
语法: strftime([format [, timestamp[, utc-flag]]])
语法说明:
format,时间格式化符。timestamp,时间戳。utc-flag,utc中的一些额外选项。
示例:
[wsh@test ~ ✔]$ awk 'BEGIN { print strftime("%c",systime()) }'
Wed 05 Apr 2023 08:42:46 PM CST[wsh@test ~ ✔]$ awk 'BEGIN {print strftime("当前时间是:%m/%d/%Y %H:%M:%S", systime())
}'
当前时间是:04/05/2023 20:35:28
strftime日期和时间格式说明如下:
| 格式符 | 说明 |
|---|---|
| %a | 本地化的星期几,例如 星期四 |
| %A | 本地化的星期几缩写,例如 四 |
| %b | 本地化的月份所写,例如 5月 |
| %B | 本地化的月份,例如 五月 |
| %c | [C 语言](https://wsh@shell ~/l/yufei/cprogramming/cprogramming-basic-index.html) 中的 %A %B %d %T %Y 的格式,例如 2019年05月30日 星期四 21时08分37秒 |
| %C | 本年度的世纪部分。也就是四位数字年份的前两位,例如 2019 年中的 20 |
| %d | 当月中的第几天,范围为 01-31,例如 30 |
| %D | 格式 %m/%d/%y 的简写,例如 05/30/19 |
| %e | 当月中的第几天,范围为 1-31,如果小于 10 则在前面补空格,如 1 补全为 1 |
| %F | ISO 8601 日期格式中的 %Y-%m-%d 的别名 |
| %g | ISO 8601 日期格式中的周数除以 100 的值,范围 00-99 例如 1993 年 1 月 1 日 是 1992 年的第 53 周。 大家可以翻翻日历,因为 1993 年 1 月 1 日和 1992 年的最后一天在同一周内。 |
| %G | IOS 周数制下的完整年费,类似于四位数年份,例如 2019 |
| %h | 格式 %b 的别名 |
| %H | 24小时制的当前时间的时,范围为 00–23 |
| %I | 12小时制的当前时间的时,范围为 01–12 |
| %j | 一年中的第几天,范围为 001–366 |
| %m | 当前时间的月,范围为 01–12 |
| %M | 当前时间的分,范围为 00–59 |
| %n | 换行符 \n |
| %p | 本地化的 12 小时制时间格式中的 AM 或 PM,也就是本地化的上午或下午表示形式 |
| %r | 本地化的 12 小时制时间格式,类似于 [C 语言](https://wsh@shell ~/l/yufei/cprogramming/cprogramming-basic-index.html) 中的 %I:%M:%S %p |
| %R | 格式 %H:%M 的缩写 |
| %S | 当前时间的秒,范围为 00-60 。60 主要考虑闰秒 |
| %t | 制表符 \t |
| %T | 格式 %H:%M:%S 的缩写 |
| %u | 一周中的第几天,也就是星期几,范围为 1–7。每周以星期一开始 |
| %U | 一年中的第几周,范围为 00-53。第一周从第一个星期日开始。 |
| %V | 一年中的第几周,范围为 01-53。第一周从第一个星期一开始。 |
| %w | 一周中的第几天,也就是星期几,范围为 0–6。每周以星期日开始 |
| %W | 一年中的第几周,范围为 00-53。第一周从第一个星期一开始。 |
| %x | 本地化的完整日期表示,类似于 %A %B %d %Y,例如 星期四 五月 30 2019 |
| %X | 本地化的完整时间表示,类似于 [C 语言](https://wsh@shell ~/l/yufei/cprogramming/cprogramming-basic-index.html) 中的 %T ,例如 07:06:05 |
| %y | 两位十进制年份,即取年份的后两位,范围为 00-99,比如 2019 则返回 19 |
| %Y | 完整的 4 位十进制年份,例如 2019 |
| %z | 以 +HHMM 格式的时区偏移。是 RFC 822 或 RFC 1036 日期格式中的组成部分。 |
| %Z | 时区名称或时区名称缩写。如果没有时区则返回空字符串 '' |
内置其他函数
getline 函数
作用: 从标准输入、管道或者当前正在处理的文件之外的其他输入文件获得输入。它负责从输入获得下一行的内容,并给NF,NR和FNR等内建变量赋值。如果得到一条记录,getline函数返回1,如果到达文件的末尾就返回0,如果出现错误,例如打开文件失败,就返回-1。
-
语法1:
getline()**使用说明:**它既没有参数,也没有返回值,因此调用的时候可以直接输入
getline不用后面加括号。
示例1: 隔行打印。
[wsh@test ~ ✔]$ cat employee.txt
1) 张三 技术部 23
2) 李四 人力部 22
3) 王五 行政部 23
4) 赵六 技术部 24
5) 朱七 客服部 23[wsh@test ~ ✔]$ awk ' { getline; print $0 }' employee.txt
运行以上 awk 命令,输出结果如下:
2) 李四 人力部 22
4) 赵六 技术部 24
5) 朱七 客服部 23
程序执行过程:
- 当程序开始执行第一行的时候,遇到
getline,这时候不得不从输入缓存里读取下一行,也就是第二行,导致第一行的 $0,$1 … 被第二行代替,因此print $0直接输出了第二行。 print $0执行完之后,开始进入下一个迭代,这时候因为第二行已经读取了,处于缓存头部的是第三行,然后又因为 getline 语句,导致了第四行的输出。- 当开始第三个循环的时候,已经读取到第五行,这时候,当前的 $0 等等也就是第五行的数据。然后调用 getline ,因为已经到了文件末尾,getline 没有读取到数据,那就不会执行替换,$0,$1 …还是之前那个,也就是第五行数据。
**示例2:**合并行。
[wsh@test ~ ✔]$ awk '
{if (NR%2==1) { printf $0"\t" }getlineprint $0
}' employee.txt
运行以上 awk 命令,输出结果如下:
1) 张三 技术部 23 2) 李四 人力部 22
3) 王五 行政部 23 4) 赵六 技术部 24
5) 朱七 客服部 23 5) 朱七 客服部 23
-
语法2:
getline() var**使用说明:**变量var包含了特定行的内容。
示例:
[wsh@test ~ ✔]$ awk '
BEGIN {printf "Enter your name: "getline nameprint "Your name is : "name
}'
Enter your name:
chengmo
chengmo
运行以上 awk 命令,输出结果如下:
Enter your name: wsh
Your name is : wsh
- 语法3:
- 当其右侧有输入重定向符 (
<) 时,getline则作用于定向输入文件。 - 当其左侧有管道符 (
|) 时,getline则作用于管道左侧的命令输出。
- 当其右侧有输入重定向符 (
示例1:逐行读取文件内容
[wsh@test ~ ✔]$ awk '
BEGIN {while(getline < "/etc/passwd"){ print $0}close("/etc/passwd")
}'
示例2:逐行读取文件内容
[wsh@test ~ ✔]$ awk '
BEGIN { while( "cat /etc/passwd" | getline ){ print $0 }close("/etc/passwd")
}'
next 函数
作用: 跳过处理当前行,直接处理下一行。
语法: next()
使用说明: 它既没有参数,也没有返回值,因此调用的时候可以直接输入 next 不用后面加括号。
**示例:**当处理到 王五 的时候直接略过,继续处理下一行。
[wsh@test ~ ✔]$ awk '
{ if ($2 ~/王五/) { next }{ print $0 }
}' employee.txt
运行以上 awk 命令,输出结果如下:
1) 张三 技术部 23
2) 李四 人力部 22
4) 赵六 技术部 24
5) 朱七 客服部 23
以上语句等同于:
[wsh@test ~ ✔]$ awk '{if ($2 ~/王五/) getline; print $0}' employee.txt
思考:以下语句执行结果。
[wsh@test ~ ✔]$ awk '{next; print $0 }' employee.txt
运行以上 awk 命令,输出结果为空,如下:
执行结果说明:读取任何一行时,都执行 next 语句跳过,所以输出是空。
nextfile 函数
作用: 跳过处理当前文件,直接处理下一文件。从下一个文件的第一行开始处理。
语法: nextfile()
使用说明: 它既没有参数,也没有返回值,因此调用的时候可以直接输入 nextfile 不用后面加括号。
示例: 当处理到第二列中包含 王五 字符串的时候,直接跳过当前文件执行,继续执行下一个文件。
[wsh@test ~ ✔]$ awk '
{ if ($2 ~ /王五/) { nextfile }print $0
}' employee-1.txt employee-2.txt
运行以上 awk 命令,输出结果如下:
1) 张三 技术部 23
2) 李四 人力部 22
1) 张三 技术部 23
2) 李四 人力部 22
return 函数
作用: 用于在用户自定义的函数中返回一个值。
语法: return(expr)
使用说明: awk 程序计算 expr 表达式的结果并将结果作为函数的返回值。如果没有传递 expr,那么 return 返回的结果是未定义的。
示例:我们首先在当前目录下创建一个文件 fns.awk 然后输入以下 AWK 命令
[wsh@test ~ ✔]$ vim return.awk
function msadd(num1, num2) {result=num1+num2return result
}BEGIN {res=msadd(15, 27)print "15+27=" res
}
运行上面的 awk 命令,输出结果如下:
[wsh@test ~ ✔]$ awk -f return.awk
15+27=42
system 函数
作用: 用于执行系统脚本命令,并返回脚本执行的退出状态。
语法: system(command)
使用说明: command,要执行的脚本命令。
退出状态分为以下几种:
- 返回状态
0,表示命令执行成功。 - 返回状态非零,表示命令执行失败。
示例:
[wsh@test ~ ✔]$ awk '
BEGIN {ret=system("date")print "返回值为="ret
}'
运行上面的 awk 命令,输出结果如下
Wed Apr 5 05:44:01 PM CST 2023
返回值为=0
close 函数
**作用:**关闭已经打开的管道。
语法: close(cmd, [read_or_write])
使用说明:
cmd,要关闭的管道。read_or_write,要关闭的管道方向。如果省略该参数,则关闭管道;如果为to则关闭输入管道。
示例:
[wsh@test ~ ✔]$ awk 'BEGIN {cmd = "tr [a-z] [A-Z]"print "hello, world !" |& cmdclose(cmd, "to")cmd |& getline outprint out;close(cmd);
}'
运行以上 awk 命令,输出结果如下
HELLO, WORLD !
执行说明:
-
第一行,
cmd = "tr [a-z] [A-Z],定义了一个系统命令,我们会使用这个命令开启一个 双向通讯管道。 -
第二行,
print "hello, world !" |& cmd。-
|& cmd,这句话的意思是使用|&输出重定向运算符打开一个 双向通讯管道 连接当前 AWK 程序和刚刚定义的命令。 -
print "hello, world !" |& cmd,就是把print函数的输出结果重定向到刚刚定义的 双向通讯管道。说的直白一点,就是
print函数为tr命令提供了输入。双向通讯管道,AWK 程序和外部程序都可以对其读写。
-
-
第三行
close(cmd, "to"),用于关闭刚刚打开的 双向通讯管道 的输入进程。 -
第四行
cmd |& getline out,把tr命令的执行结果使用管道运算符&|重定向到getline函数。getline 函数会把结果储存到out变量中。 -
最后一行
close(cmd)用于关闭刚刚打开的 双向通讯管道。
fflush 函数
**作用:**用于刷新打开的输出文件或管道关联的任何缓冲区,就是把 储存在内存中的数据保存到文件或者管道中。
语法:fflush([output-expr])。
使用说明:
output-expr是要刷新的缓冲区。- 如果没有传递
output-expr,那么默认刷新 标准输出。 - 如果传递的是 空字符串
'',那么会刷新所有当前 awk 程序打开的文件或者管道。 - 否则,刷新指定的文件或管道。
**示例:**暂无。
用户自定义函数
函数定义
函数定义语法:
function function_name(argument1, argument2, ...) { function body
}
语法说明:
-
必须以
function关键字开始,然后紧跟着一个或多个 空格(' ') -
在空格的后面紧跟着 函数名,函数名必须以 字母开始,可以由字母、数字、下划线组成。但是 AWK 同时规定,所有的 AWK 保留字都不能用于函数名。
-
在函数名字后,必须紧跟着 一对英文括号。
-
在 右括号() 之后,必须有一对 英文大括号(
{})- 大括号可以和小括号同一行,也可以不同行,这个没有限制。
- 右小括号和左大括号之间可以有任意数量的空格,这个也没有限制。
下面的三种语法都是正确的:
# 大括号和小括号在同一行 function hello(){}# 左大括号和小括号在同一行 function hello(){ }# 左大括号和右大括号都在新的一行 function hello() { } -
函数可以有一个或多个参数,参数必须放在 小括号内,参数之间由 英文逗号(
,) 分隔。# 没有参数 function hello(){ }# 有一个参数 username function hello(username){ }# 两个或两个以上参数需要逗号分隔 function hello(username,greeting) { } -
大括号内可以有任意数量的 AWK 语句,语句之间必须以 分号(
;) 分隔。# 一条语句 function hello(username,greeting) {printf "%s,%s\n", greeting, username; }# 多条语句 function hello(username,greeting) {print "Hello 简单教程";printf "%s,%s\n", greeting, username; } -
函数可以有返回值,也可以没有,如果需要返回值,则必须在大括号里使用
return关键字,语法格式如下:return [要返回的值]例如要返回用户名,可以直接使用:
return 'wsh'
示例:
# 多条语句
function hello(username,greeting) {print "Hello 简单教程";printf "%s,%s\n", greeting, username;return username;
}
函数调用
定义好了函数之后,我们就能像调用内置函数那样调用我们自定义的函数。
调用无参数 hello
hello;
调用有参数函数
hello("简单教程","你好");
调用有返回值的函数
username = hello("简单教程","你好");
示例1: 创建两个自定义函数,用来返回两个参数中较小/较大的值。
# 返回较小的那个数字
function find_min(num1, num2)
{if (num1<num2)return num1elsereturn num2
}# 返回较大的那个数字
function find_max(num1, num2)
{if (num1>num2)return num1elsereturn num2
}
为了方便调用函数,我们再创建一个函数 main,同时接受两个数字作为参数,并在这个 main 函数中调用上面创建的两个函数。
function main(num1, num2)
{# 找出较小的数字result=find_min(10, 20)print "Minimum="result# 找出较大的数字result=find_max(10, 20)print "Maximum="result
}
至于调用函数 main,我们可以像平时调用内置函数一样。
[wsh@test ~ ✔]$ awk `BEGIN { main(10, 20) }'
命令文件
一般情况下,当语句比较复杂的时候,我们习惯于把所有代码都放到文件中,这样既方便修改,也不会搞得那么复杂。
我们可以在当前目录下新建一个文件 commands.awk 文件名随意,但一般都以 .awk 结尾。
# 返回较小的那个数字
function find_min(num1, num2)
{if (num1<num2)return num1elsereturn num2
}# 返回较大的那个数字
function find_max(num1, num2)
{if (num1>num2)return num1elsereturn num2
}function main(num1, num2)
{# 找出较小的数字result=find_min(10, 20)print "Minimum="result# 找出较大的数字result=find_max(10, 20)print "Maximum="result
}# 调用 main()
BEGIN { main(10, 20) }
然后使用下面的命令运行我们的 fns.awk 文件
[wsh@test ~ ✔]$ awk -f commands.awk
运行结果如下
Minimum=10
Maximum=20
awk 输出重定向
AWK 程序同样支持 重定向 操作,也就是支持把数据输出到 文件 上。
AWK 的重定向操作一般出现在 print 或 printf 语句后面。
AWK中的重定向与 [shell](https://wsh@shell ~/l/yufei/shell/shell-basic-index.html) 命令中的重定向类似,只是它们写在 AWK 程序中。
覆盖重定向 >
**作用:**用于将输出结果重定向到某个文件。重定向操作符 > 会先删除文件的原先内容然后再写入数据,也就是说原先的内容不存在了。
语法: print DATA > output-file
重定向操作符 > 会把 print 的输出结果写入到文件 output-file 中。如果 output-file 不存在,重定向操作符 > 会先创建文件。
示例:
[wsh@test ~ ✔]$ echo "olddata:Hello World!" > /tmp/message.txt
[wsh@test ~ ✔]$ cat /tmp/message.txt
olddata:Hello World![wsh@test ~ ✔]$ awk 'BEGIN { print "newdata:Hello wsh!" > "/tmp/message.txt" }'
[wsh@test ~ ✔]$ cat /tmp/message.txt
newdata:Hello wsh!
追加重定向 >>
**作用:**追加重定向 >>,就是把输出输出到文件的末尾,而不是覆盖原先的内容。
语法:print DATA >> output-file
追加重定向 >>会把 print 的输出结果 追加 到 output-file 文件的末尾,原先的数据还在。
如果 output-file 文件不存在,那么会先创建文件然后再输入数据。
示例:
[wsh@test ~ ✔]$ echo "olddata:Hello World!" > /tmp/message.txt
[wsh@test ~ ✔]$ cat /tmp/message.txt
olddata:Hello World![wsh@test ~ ✔]$ awk 'BEGIN { print "newdata:Hello wsh!" >> "/tmp/message.txt" }'
[wsh@test ~ ✔]$ cat /tmp/message.txt
olddata:Hello World!
newdata:Hello wsh!
管道 |
**作用:**使用管道将awk输出发送到另一个程序。
语法:print items | command
示例:
[wsh@test ~ ✔]$ awk 'BEGIN { print "hello, world !" | "tr [a-z] [A-Z]" }'
运行上面的 awk 命令,输出结果如下:
HELLO, WORLD !
双向管道 |&
作用: 使用 |& 符号打开一个双向管道,AWK 程序和外部程序都可以对打开的管道进行读写。
语法:print items |& command
示例:
[wsh@test ~ ✔]$ awk 'BEGIN {cmd = "tr [a-z] [A-Z]"print "hello, world !" |& cmdclose(cmd, "to")cmd |& getline outprint outclose(cmd)
}'
运行上面的 awk 命令,输出结果如下:
HELLO, WORLD !
执行说明:
-
第一行
cmd = "tr [a-z] [A-Z]"定义了一个系统命令,我们会使用这个命令开启一个 双向通讯管道。 -
第二行
print "hello, world !" |& cmd。我们先来看
|& cmd,这句话的意思是使用|&输出重定向运算符打开一个 双向通讯管道 连接当前 AWK 程序和刚刚定义的命令。然后
print "hello, world !" |& cmd就是把print函数的输出结果重定向到刚刚定义的 双向通讯管道。说的直白一点,就是
print函数为tr命令提供了输入。 -
第三行
close(cmd, "to")用于关闭刚刚打开的 双向通讯管道 的输入进程。 -
第四行
cmd |& getline out把tr命令的执行结果使用管道运算符&|重定向到getline函数。getline 函数会把结果储存到out变量中。 -
最后一行
close(cmd)用于关闭刚刚打开的 双向通讯管道。
awk 美化输出
AWK 的输出,主要还是靠 print 和 printf 两个函数,而这两个函数,我们前面已经用过很多次了。
本章我们就来看看 printf 支持哪些输出格式吧。
printf 函数语法
语法:printf fmt, expr-list
参数说明:
fmt,用于指定变量的输出格式。expr-list,用于指定输出的变量。
示例:printf "%f\n", 18
说明:
%f\n是输出格式,用于指定如何输出传递的参数。像%f这种由 百分号(%) 和其它预定义的字符构成的字符串又称之为 格式化符。18则是要输出的参数。
[wsh@test ~ ✔]$ awk 'BEGIN { printf "%f\n", 18 }'
运行上面的 awk 命令,输出结果如下:
18.000000
printf 转义字符
AWK 的 printf 函数从 C 语言 借鉴而来,它所支持的 转义字符 也基本从 C 语言借鉴而来。
因此,如果你熟悉 C 语言的 printf() 函数,那么对于 AWK 的转义字符也会得心应手。
换行符 \n
AWK 中的 新行(换行符) \n 表示。
因此,如果你想要 Hello World 中的每一个单词一行。
Hello
World
那么你只需要将 Hello World 中的 空格( ' ' ) 换成 \n 即可
[wsh@test ~ ✔]$ awk 'BEGIN { printf "Hello\nWorld\n" }'
运行上面的 awk 命令,输出结果如下:
Hello
World
后面那个
\n是为了保证 终端( shell ) 的提示符在新的一行。
制表符\t
如果你想要两个或更多个字符串/字段之间有一定的间隔,一种方法是添加相当数量的 空格,比如我们想要 Hello 和 World 两个单词之间有四个空格,则可以直接使用四个空格分开。
Hello World
另一种更简单的方法,就是使用 水平分隔符(制表符)\t 。
Hello\tWorld
一般情况下,一个 \t 的间隙相当于 2 个或 4 个空格,这取决于配置。
示例:
[wsh@test ~ ✔]$ awk 'BEGIN { printf "编号\t姓名\t部门\t年龄\n";printf "编号 姓名 部门 年龄\n";}'
运行上面的 awk 命令,输出结果如下:
编号 姓名 部门 年龄
编号 姓名 部门 年龄
从上面的输出可以看出,在我这台电脑上,一个 \t 等于 4 个空格。
垂直分隔符 \v
垂直分隔符 \v 看起来有点和 水平分隔符(制表符)\t 类似,但是,前者的功能并不是在竖直方向拉出一定的空间,而是在 新行中空出上一行所占用的空间
简单的来说,就是制作一个 楼梯 效果。
[wsh@test ~ ✔]$ awk 'BEGIN { printf "编号\v姓名\v部门\v年龄\n"}'
运行上面的 awk 命令,输出结果如下:
编号姓名部门年龄
退格符 \b
退格符 \b 的作用,就是在之前的字符串基础上,往回退一个 字符。从某些方面说,就是删除一个前面的字符。
比如 Hello\bWorld 输出的效果就是 HellWorld,也就是 \b 之前的那个 o 被删除了。
示例:
[wsh@test ~ ✔]$ awk 'BEGIN { printf "Field 1 Field 2 Field 3 Field 4\n" }'
[wsh@test ~ ✔]$ awk 'BEGIN { printf "Field\b1 Field\b2 Field\b3 Field\b4\n" }'
运行上面的 awk 命令,输出结果如下:
Field 1 Field 2 Field 3 Field 4
Fiel1 Fiel2 Fiel3 Fiel4
从输出结果中可以看出,每一个 \b 都会用于删除前一个字符和 \b 本身。
回车符 \r
在很多地方,或许你也经常听到 回车符,也就是 \r,虽然回车符和换行符的效果看起来类似,但它们实实在在的有点区别的。
- 换行符(
\n) 是在 新行 继续输出。 - 回车符(
\r) 则是删除当前行的所有已经输出,然后回到当前行的开始重新输出。 - 回车换行(
\r\n) 的意思就是回到当前行的开始并且在新行输出,从某些方面说,其实就是 换行
示例:
\n
[wsh@test ~ ✔]$ awk 'BEGIN { printf "Field 1\nField 22\nField 333\nField 4444\n" }'
运行上面的 awk 命令,输出结果如下:
Field 1
Field 22
Field 333
Field 4444
\r
[wsh@test ~ ✔]$ awk 'BEGIN { printf "Field 1\rField 22\rField 333\rField 4444\n\n" }'
运行上面的 awk 命令,输出结果如下:
Field 4444
\r\n
[wsh@test ~ ✔]$ awk 'BEGIN { printf "Field 1\r\nField 22\r\nField 333\r\nField 4444\n" }'
运行上面的 awk 命令,输出结果如下:
Field 1
Field 22
Field 333
Field 4444
从结果中可以看出,\r\n 和 \n 的作用类似,而 \r 则是实打实的从当前行开始输出。
换页符 (\f)
换页符 (\f) 顾名思义,就是 走纸换页,一般在 打印机打印 时才会生效,用于从一个 新页 开始输出。
如果不是在 打印机,那么输出效果和 竖直分割符(\v) 的效果类似
[wsh@test ~ ✔]$ awk 'BEGIN { printf "Sr No\fName\fSub\fMarks\n" }'
运行上面的 awk 命令,输出结果如下
Sr NoNameSubMarks
printf 格式化符
AWK 的 printf 函数从 C 语言 借鉴而来,那么它所支持的 格式化符 也基本从 C 语言借鉴而来。
因此,如果你熟悉 C 语言的 printf() 函数,那么对于 AWK 的格式化符也会得心应手。
单个字符 %c
如果你想要将一个数字输出为 单个字符,可以使用 %c 格式化符:
- 如果传递的是数字,这个数字必须是 ASCII 所支持的,也就是说 小于 128。
- 如果传递的是字符串,那么只有 第一个字符 会被输出,其它的则直接省略。
[wsh@test ~ ✔]$ awk 'BEGIN { printf "ASCII value 65 = character %c\n", 65 }'
ASCII value 65 = character A[wsh@test ~ ✔]$ awk 'BEGIN { printf "ASCII value 156 = character %c\n", 156 }'
ASCII value 156 = character [wsh@test ~ ✔]$ awk 'BEGIN { printf "ASCII value twle = character %c\n", "twle" }'
ASCII value twle = character t
字符串 %s
格式化符 %s 用于输出一个字符串。准确的说是将数据先转换为字符串后输出。
[wsh@test ~ ✔]$ awk 'BEGIN { printf "年龄 = %s\n", 28.1119 }'
运行以上 awk 命令,输出结果如下:
年龄 = 28.1119
当然了,%s 还可以原样输出传递的字符串,例如:
[wsh@test ~ ✔]$ awk 'BEGIN { printf "网站 = %s\n", "https://wsh@shell/"}'
运行以上 awk 命令,输出结果如下
网站 = https://wsh@shell/
整数 %d 和 %i
%d 和 %i 格式化符的作用一样,把传递的参数转换为 整数 后输出:
- 如果传递的是 浮点数(小数),那么只会输出 整数部分,小数部分直接忽略。
- 如果传递的是 非整数 ,则直接输出
0。 - 如果传递的是 字符串整数,则会转换为 整数 后输出。
[wsh@test ~ ✔]$ awk 'BEGIN { printf "价格 = %d\n", 80 }'
价格 = 80[wsh@test ~ ✔]$ awk 'BEGIN { printf "价格 = %d\n", 80.66 }'
价格 = 80[wsh@test ~ ✔]$ awk 'BEGIN { printf "价格 = %d\n", "80.66" }'
价格 = 80[wsh@test ~ ✔]$ awk 'BEGIN { printf "价格 = %d\n", "wsh@shell" }'
价格 = 0
浮点数 %f
浮点数格式化符 %f 会把传递的参数先转换为 **浮点数(小数)**后输出。
- 转换的时候,如果小数位数太多(默认多余 6 位)则会触发四舍五入。
- 如果传递的是字符串,首先会转换成
0然后再转换为浮点数。
[wsh@test ~ ✔]$ awk 'BEGIN { printf "价格 = %f\n", 80 }'
价格 = 80.000000[wsh@test ~ ✔]$ awk 'BEGIN { printf "价格 = %f\n", 80.6699999 }'
价格 = 80.670000[wsh@test ~ ✔]$ awk 'BEGIN { printf "价格 = %f\n", "80.66" }'
价格 = 80.660000[wsh@test ~ ✔]$ awk 'BEGIN { printf "价格 = %f\n", "wsh@shell" }'
价格 = 0.000000
科学计数法 %e 和 %E
%e 和 %E 的作用一样,把传递的参数先用 科学计数法 表示然后输出。
如果传递的是字符串,首先会转换成 0 然后再转换为科学计数法。
[wsh@test ~ ✔]$ awk 'BEGIN { printf "价格 = %e\n", 80 }'
价格 = 8.000000e+01[wsh@test ~ ✔]$ awk 'BEGIN { printf "价格 = %e\n", 80.6699999 }'
价格 = 8.067000e+01[wsh@test ~ ✔]$ awk 'BEGIN { printf "价格 = %e\n", "80.66" }'
价格 = 8.066000e+01[wsh@test ~ ✔]$ awk 'BEGIN { printf "价格 = %e\n", "wsh@shell" }'
价格 = 0.000000e+00
%E 会把科学计数法中的 e 字母大写E。
[wsh@test ~ ✔]$ awk 'BEGIN { printf "价格 = %E\n", 80 }'
价格 = 8.000000E+01[wsh@test ~ ✔]$ awk 'BEGIN { printf "价格 = %E\n", 80.6699999 }'
价格 = 8.067000E+01[wsh@test ~ ✔]$ awk 'BEGIN { printf "价格 = %E\n", "wsh@shell" }'
价格 = 0.000000E+00[wsh@test ~ ✔]$ awk 'BEGIN { printf "价格 = %E\n", "80.66" }'
价格 = 8.066000E+01
格式化符 %g 和 %G
%g 和 %G 的作用是一样的,会根据传递的参数选择 %e 或 %f 格式化符,具体选哪个,取决于转后后的结果谁更短(位数更少)。
-
当给定的数字去掉首尾的空格后, 整数 部分总位数小于等于 6 时,使用的是
%f模式,且总共只保留 6 位数字,还会发生四舍五入。[wsh@test ~ ✔]$ awk 'BEGIN { printf "%g\n",12345.234567 }' 12345.2 [wsh@test ~ ✔]$ awk 'BEGIN { printf "%G\n",12345.234567 }' 12345.2 -
当给定的数字去掉首尾的空格后, 整数 部分总位数大于 6 时,采用的是
%e和%E模式,且会去掉首尾的空格,并保留 6 位有效小数。[wsh@test ~ ✔]$ awk 'BEGIN { printf "%g\n",01234567.2345678 }' 1.23457e+06 [wsh@test ~ ✔]$ awk 'BEGIN { printf "%G\n",01234567.2345678 }' 1.23457E+06
八进制 %o
%o 用于输出一个 无符号八进制数字,准确的说是将数据先转换为无符号八进制数据后输出。
[wsh@test ~ ✔]$ awk 'BEGIN { printf "十进制 10 = 八进制 %o\n", 10}'
运行以上 awk 命令,输出结果如下:
十进制 10 = 八进制 12
带前缀的八进制%#o:
[wsh@test ~ ✔]$ awk 'BEGIN { printf "十进制 10 = 八进制 %#o\n", 10}'
十进制 10 = 八进制 012
十进制 %u
格式化符 %u 用于输出一个 无符号十进制数字,准确的说是将数据先转换为无符号十进制数据然后输出
[wsh@test ~ ✔]$ awk 'BEGIN { printf "无符号 10 = %u\n", 10 }'
运行以上 awk 命令,输出结果如下:
无符号 10 = 10
而对于小于 0 的数据,则会先转换为无符号十进制数字再输出,转换方式为先抛弃小数,然后求补码。
[wsh@test ~ ✔]$ awk 'BEGIN { printf "无符号 -11.332 = %u\n", -11.332 }'
运行以上 awk 命令,输出结果如下:
无符号 -11.332 = 18446744073709551605
十六进制 %x 和 %X
格式化符 %x 和 %X 可以用来将一个 大于 0 的十进制 转换成为 十六进制。
区别:
%X格式化生成的十六进制是大写字母。%x格式化生成的十六进制是小写字母。
[wsh@test ~ ✔]$ awk 'BEGIN { printf "15转换为十六进制为: %x\n", 15}'
15转换为十六进制为: f[wsh@test ~ ✔]$ awk 'BEGIN { printf "15转换为十六进制为: %X\n", 15}'
15转换为十六进制为: F
带前缀的十六进制 %#x 和 %#X :
[wsh@test ~ ✔]$ awk 'BEGIN { printf "15转换为十六进制为: %#x\n", 15}'
15转换为十六进制为: 0xf
[wsh@test ~ ✔]$ awk 'BEGIN { printf "15转换为十六进制为: %#X\n", 15}'
15转换为十六进制为: 0XF
百分号 %%
使用 两个百分号(%%) 来输出一个 %。
[wsh@test ~ ✔]$ awk 'BEGIN { printf "百分比 = %d%%\n", 80.66 }'
百分比 = 80%
printf 其他格式输出
指定宽度
AWK 使用 printf 输出时,默认是参数多长就输出多长。
但如果我们想要位某个参数指定固定的长度,则可以在 百分号(%) 后面,格式化字符之前添加指定的 长度。
默认情况下,当输出是 右对齐的,且左边默认使用 **空格(' ') **填充。
例如,对于 %d 如果我们要指定占用宽度为 10 ,则可以使用格式化符 %10d。
[wsh@test ~ ✔]$ awk '
BEGIN { num1=10num2=20printf "Num1=%10d\nNum2=%10d\n", num1, num2
}'
运行上面的 awk 命令,输出结果如下
Num1= 10
Num2= 20
左对齐
在我们指定了宽度的前提下,如果我们希望格式化输出的字符是左对齐,则需要在百分号后类型之前面添加 负号(-)。
[wsh@test ~ ✔]$ awk '
BEGIN { num1=10num2=12356printf "Num1=%-7d\nNum2=%-7d\n", num1,num2
}' | cat -A
运行上面的范例,输出结果如下
Num1=10 $
Num2=12356 $
前缀 0
如果要将右对齐左侧的 空格填充 改成 0 ,则需要在 百分号(%) 后面,宽度数字之前 添加 0 ,例如 %7d 改成 %07d。
填充字符只能是 0 或者 ’ ',如果是其它字符,默认是没有任何效果的。
[wsh@test ~ ✔]$ awk '
BEGIN { num1=-10num2=20printf "Num1=%07d\nNum2=%07d\n", num1, num2
}'
运行上面的 awk 命令,输出结果如下
Num1=-000010
Num2=0000020
数字前缀的正负号
AWK 支持输出时在数字前面添加 正负号(±),也就是说,把 10.00 改成 +10.00,把 -10.00 改成 -10.00.
要在数字前面添加正负号,只需要在 百分号(%) 后类型之前添加一个 **正号(+)**即可,比如 %d 改成 %+d,比如 %f 改成 %+f。
示例1:
[wsh@test ~ ✔]$ awk 'BEGIN { num1=-10num2=20printf "Num1=%+d\nNum2=%+d\n", num1, num2
}'
输出结果为
Num1=-10
Num2=+20
示例2:
[wsh@test ~ ✔]$ awk '
BEGIN { num1=-10.234num2=20.456printf "Num1=%+f\nNum2=%+f\n", num1, num2
}'
输出结果为:
Num1=-10.234000
Num2=+20.456000