大数据毕业设计选题推荐-基于Hadoop的电信客服数据处理与分析系统-Spark-HDFS-Pandas
✨作者主页:IT研究室✨
个人简介:曾从事计算机专业培训教学,擅长Java、Python、微信小程序、Golang、安卓Android等项目实战。接项目定制开发、代码讲解、答辩教学、文档编写、降重等。
☑文末获取源码☑
精彩专栏推荐⬇⬇⬇
Java项目
Python项目
安卓项目
微信小程序项目
文章目录
- 一、前言
- 二、开发环境
- 三、系统界面展示
- 四、代码参考
- 五、系统视频
- 结语
一、前言
《基于Hadoop平台的电信客服数据处理与分析系统》是一个通过大数据分析平台,专为电信行业设计的客户数据分析系统。该系统主要采用Hadoop和Spark大数据框架,结合Python、Java开发语言(两个版本),利用Spark SQL和Pandas进行数据处理,支持海量数据的存储和高效分析。系统提供多个维度的数据分析,包括客户流失分析、消费行为分析、服务使用分析和客户特征分析,帮助电信公司精准地识别客户流失风险、优化服务包设计、提升客户满意度,并通过对客户特征的深入剖析,制定差异化的营销策略。系统后端采用Django和Spring Boot框架(两个版本),前端则使用Vue与ElementUI,以提供良好的用户体验。通过该系统,电信企业能够从海量数据中提取有价值的信息,实现数据驱动决策和业务优化。
选题背景
随着通信行业的快速发展,尤其是在互联网时代的推动下,电信行业面临着日益激烈的竞争和巨大的客户流失压力。特别是在客户需求多样化和技术进步的背景下,如何通过精准的数据分析提升客户体验、减少客户流失,成为电信公司亟待解决的核心问题。传统的数据分析手段在面对海量客户数据时,显得力不从心,尤其是在无法实时获取客户行为、消费和服务使用情况的情况下,很多业务决策缺乏数据支持。因此,基于大数据平台的客户数据处理与分析,已成为电信行业提升竞争力、制定精准营销战略的关键。
选题意义
本课题的研究不仅能够为电信公司提供一套高效的数据分析工具,还能通过对客户行为与需求的精确把握,帮助企业提高客户维系率并优化产品和服务。通过深入分析客户的流失风险,电信公司可以提前识别出高风险用户,采取个性化的挽留措施,从而有效降低客户流失率。消费者消费行为分析则能帮助电信公司精准划分市场,制定不同的定价策略,提高整体的客户满意度和盈利能力。同时,服务使用分析能够指导电信公司根据市场需求优化现有服务组合,提升服务质量。综上所述,本课题不仅具有学术研究价值,更具备显著的实践意义,为电信行业的数字化转型提供有力的支持。
二、开发环境
- 大数据框架:Hadoop+Spark(本次没用Hive,支持定制)
- 开发语言:Python+Java(两个版本都支持)
- 后端框架:Django+Spring Boot(Spring+SpringMVC+Mybatis)(两个版本都支持)
- 前端:Vue+ElementUI+Echarts+HTML+CSS+JavaScript+jQuery
- 详细技术点:Hadoop、HDFS、Spark、Spark SQL、Pandas、NumPy
- 数据库:MySQL
三、系统界面展示
- 基于Hadoop平台的电信客服数据处理与分析系统界面展示:
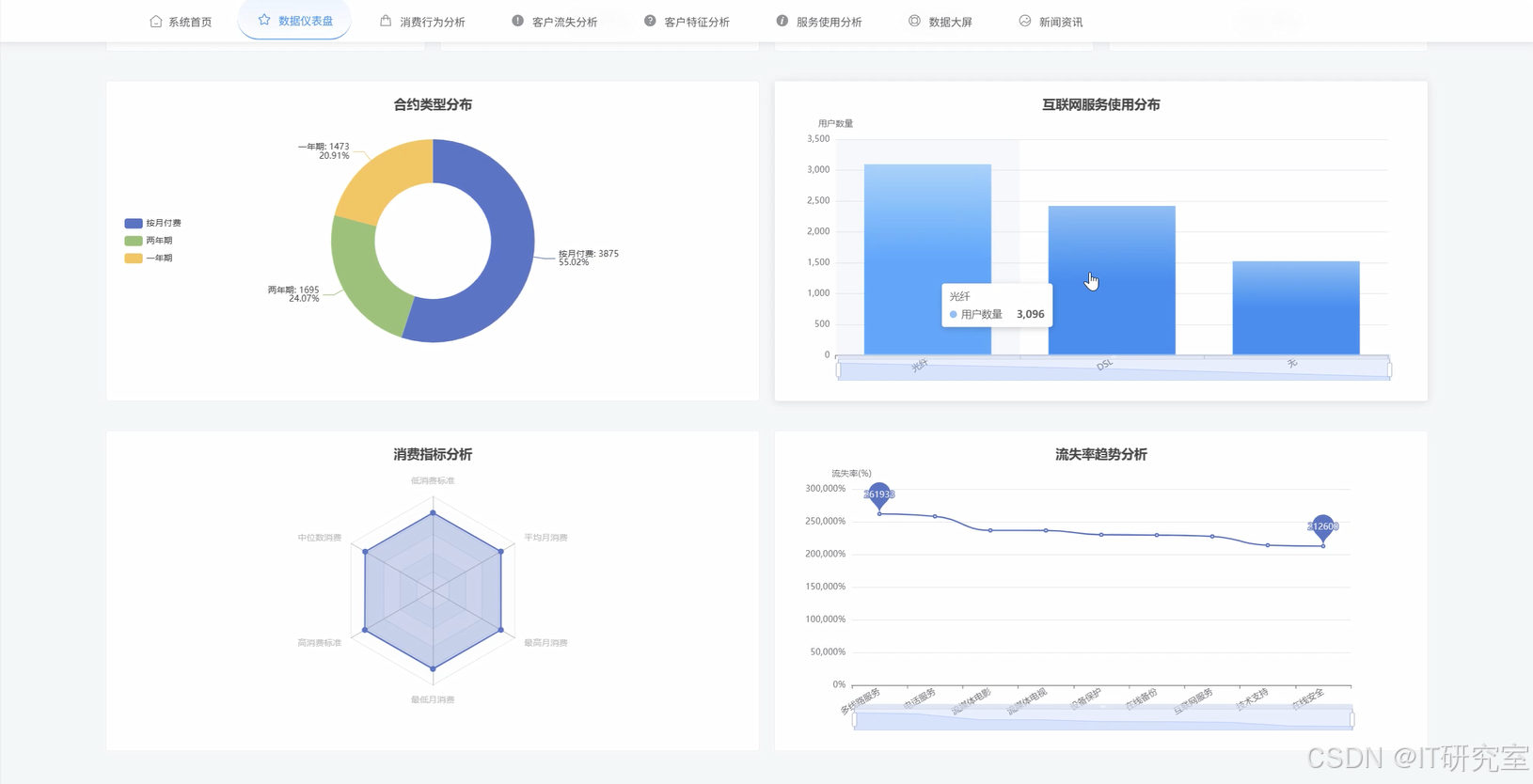
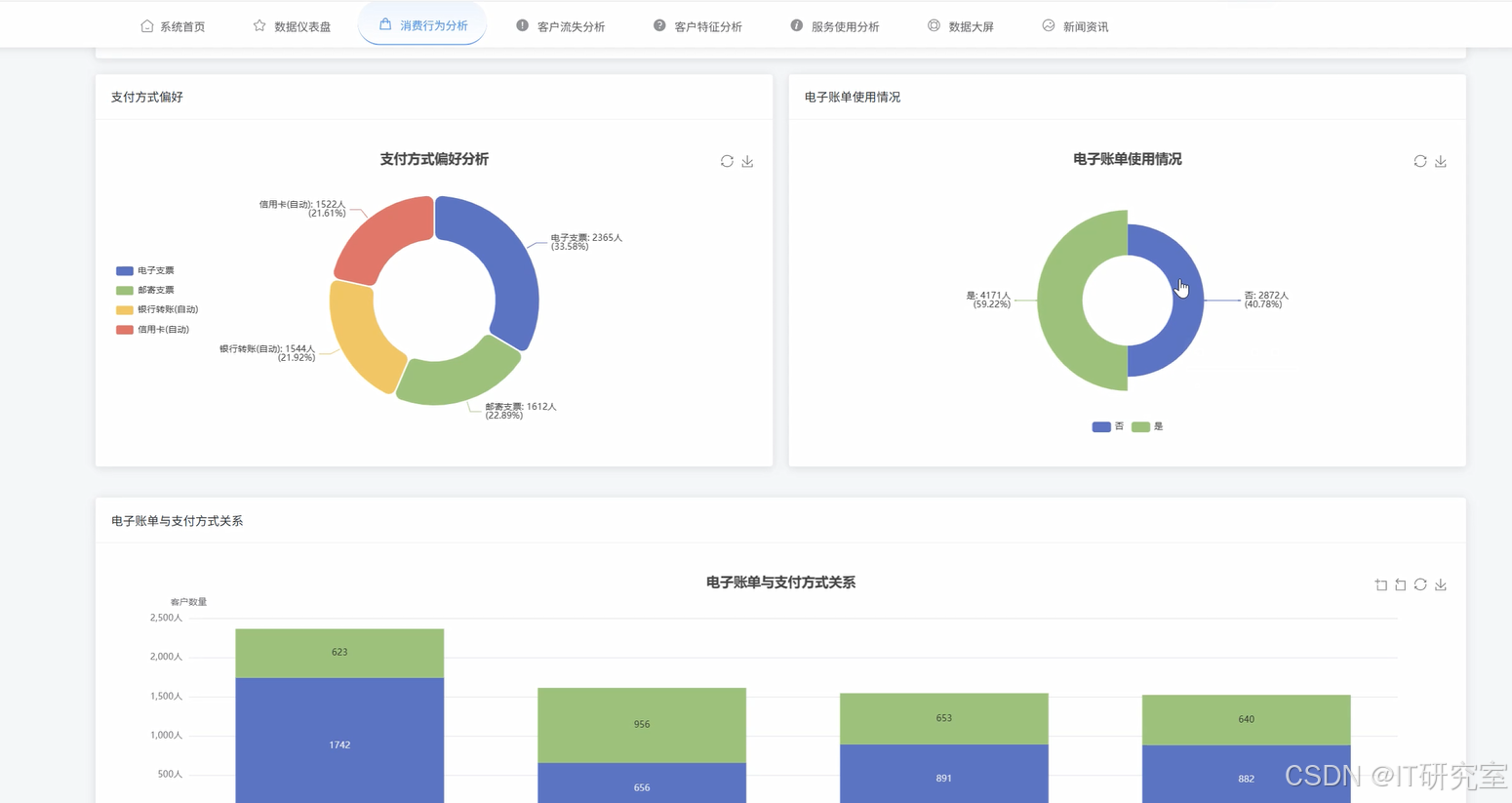
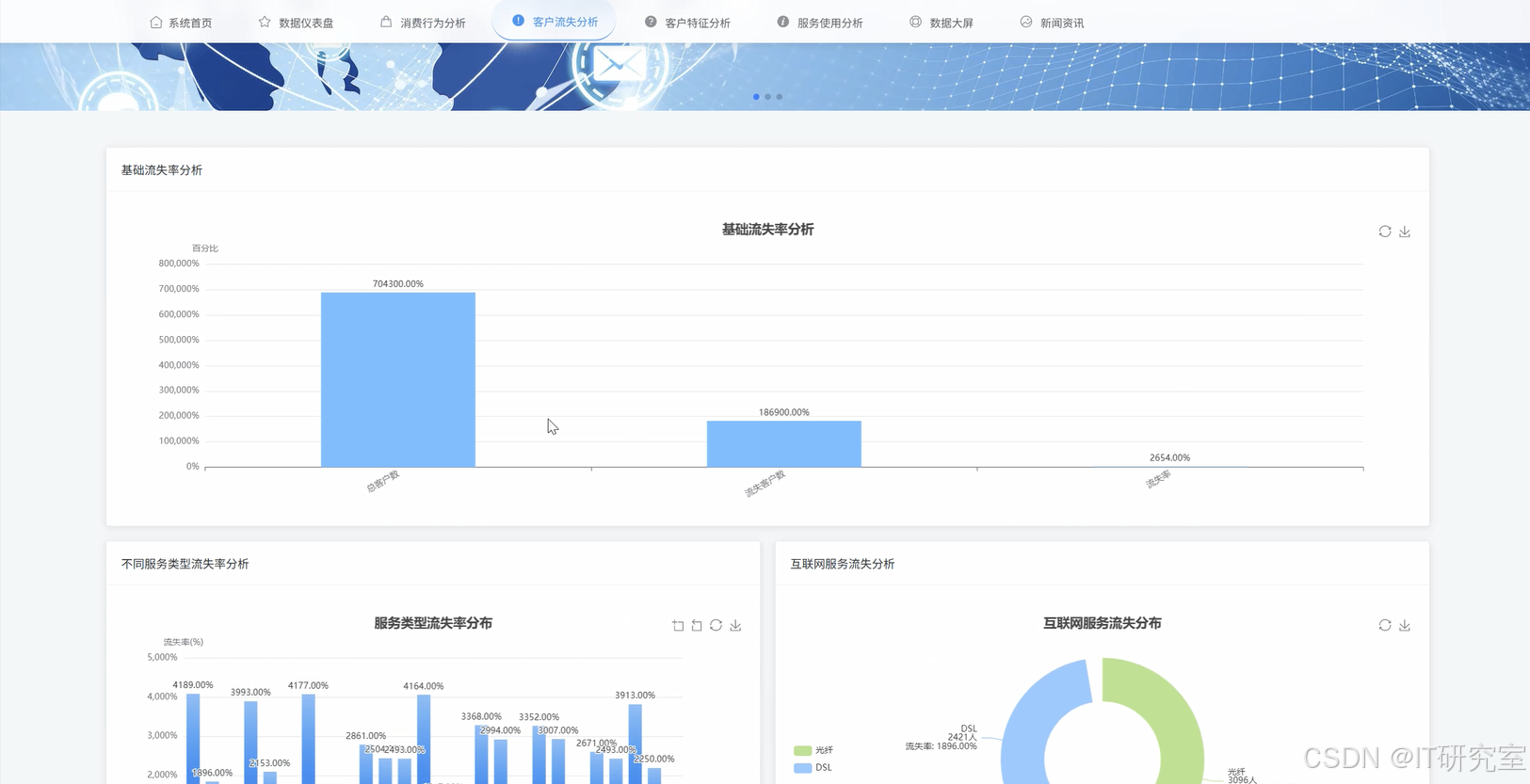
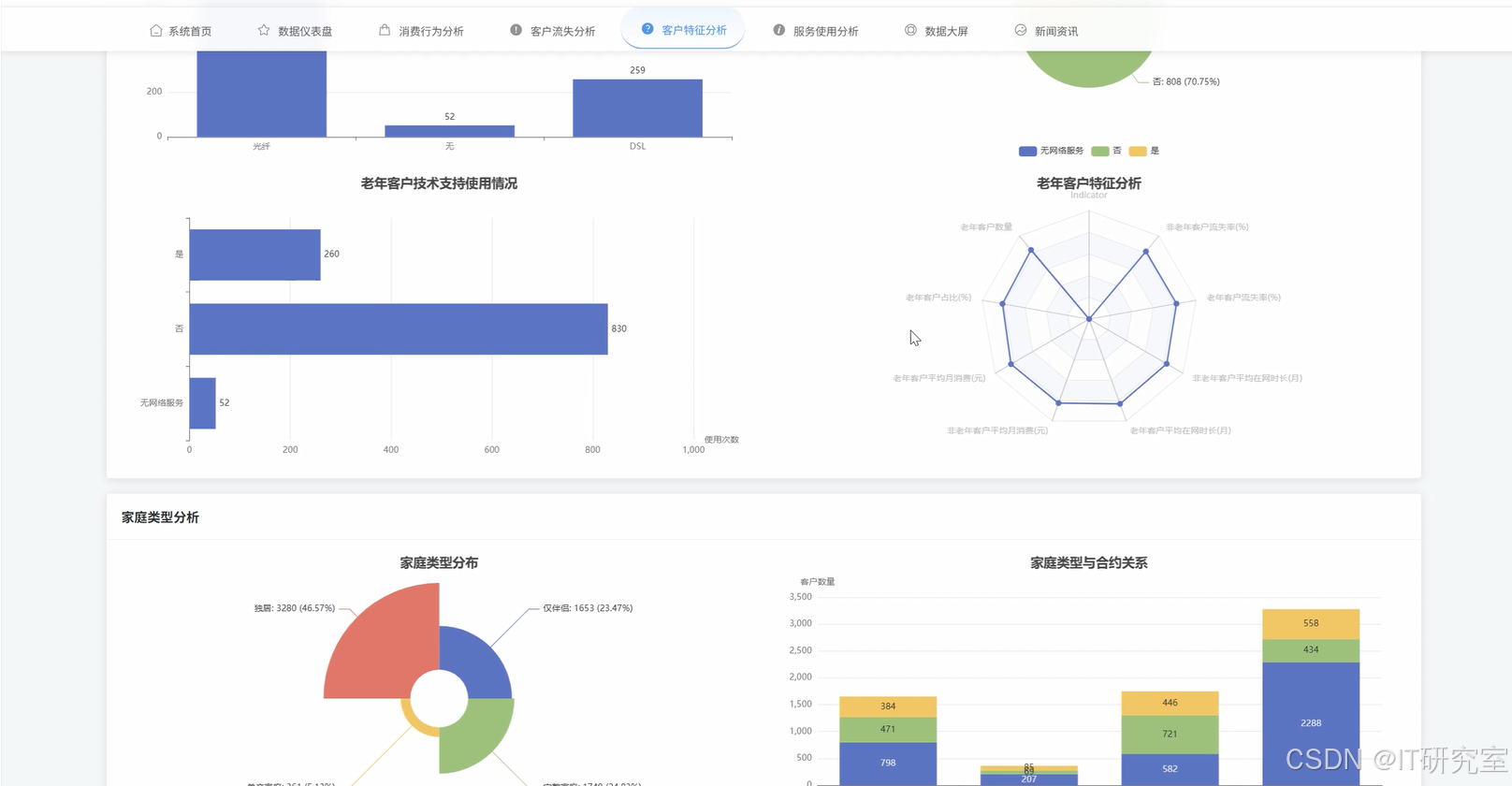
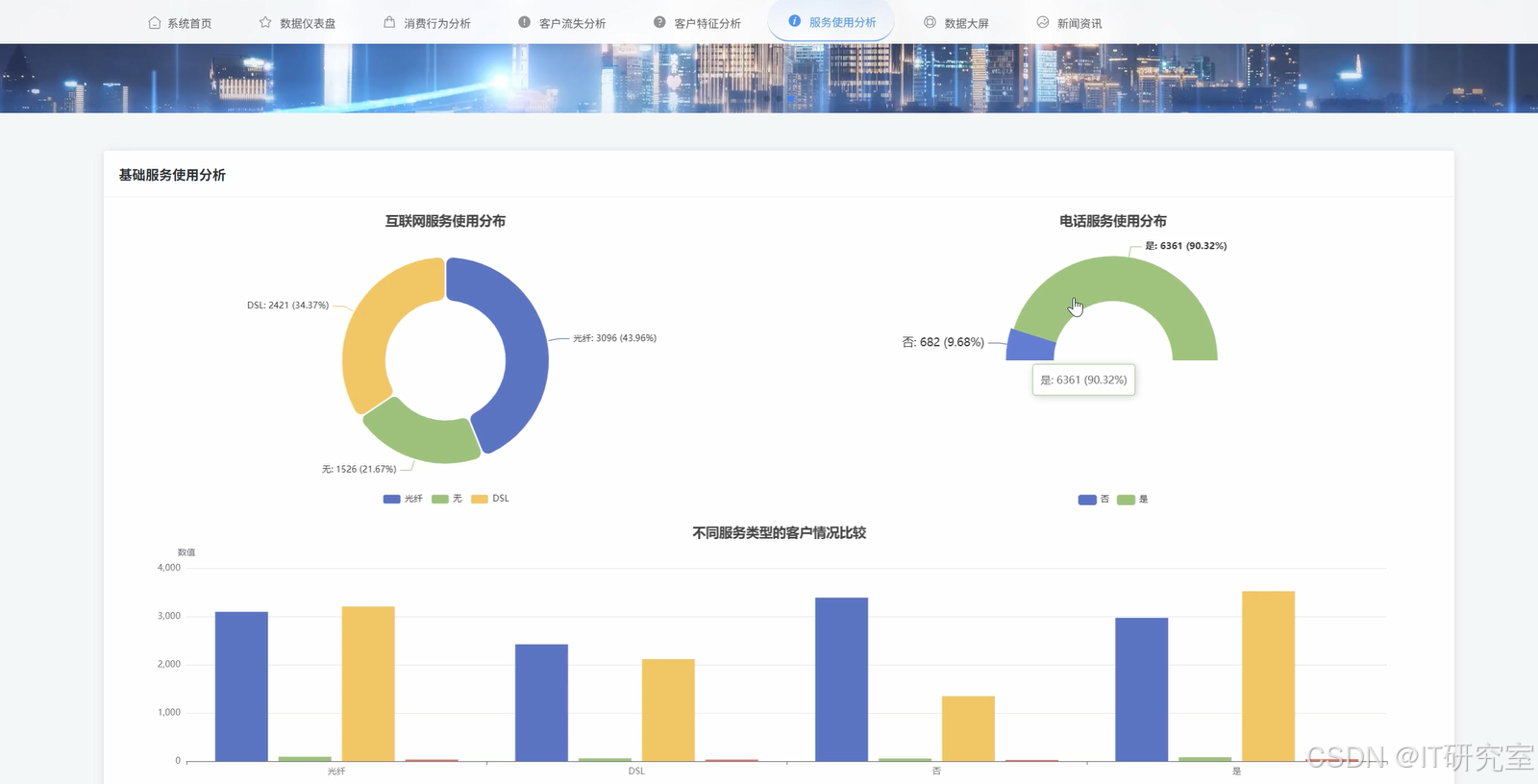
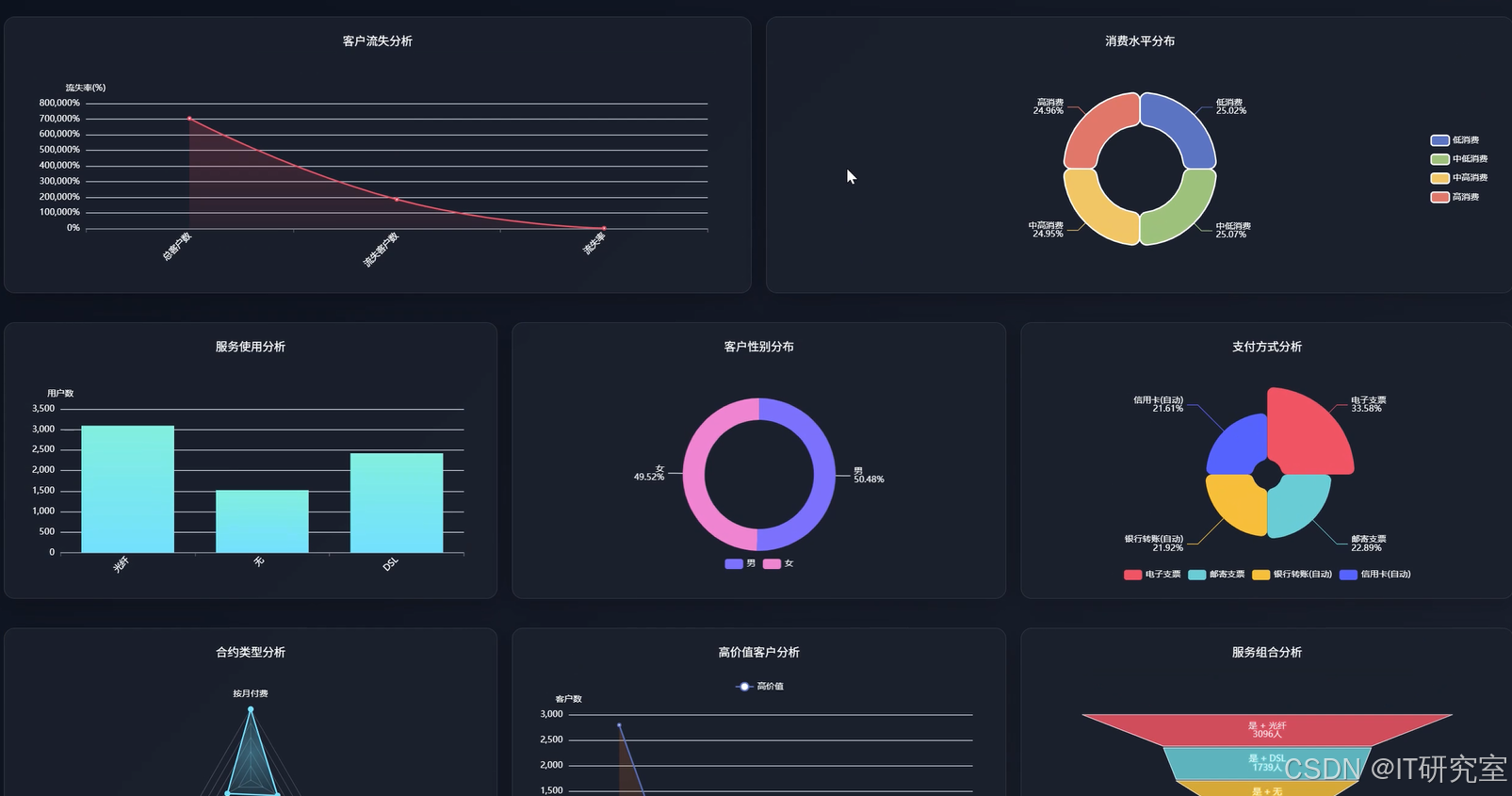
四、代码参考
- 项目实战代码参考:
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, when, count, avg, sum# 初始化SparkSession
spark = SparkSession.builder.appName("TelecomCustomerAnalysis").getOrCreate()# 1. 客户流失分析:按合约期进行流失率分析
def churn_by_contract_analysis(df):contract_churn = df.groupBy("Contract").agg(count("Churn").alias("TotalCustomers"),sum(when(col("Churn") == 1, 1).otherwise(0)).alias("ChurnedCustomers"))contract_churn = contract_churn.withColumn("ChurnRate", (col("ChurnedCustomers") / col("TotalCustomers")) * 100)return contract_churn# 2. 消费水平分布分析:通过消费金额划分客户消费层次
def consumption_level_analysis(df):df = df.withColumn("ConsumptionLevel", when(col("MonthlyCharges") < 30, "Low").when((col("MonthlyCharges") >= 30) & (col("MonthlyCharges") < 70), "Medium").otherwise("High"))consumption_level = df.groupBy("ConsumptionLevel").agg(count("CustomerID").alias("CustomerCount"),avg("MonthlyCharges").alias("AverageMonthlyCharges"))return consumption_level# 3. 增值服务订购模式分析:分析增值服务的订购组合模式
def value_added_services_analysis(df):value_added_services = df.select("CustomerID", "OnlineSecurity", "OnlineBackup", "DeviceProtection", "TechSupport", "StreamingTV", "StreamingMovies")service_combinations = value_added_services.groupBy("OnlineSecurity", "OnlineBackup", "DeviceProtection", "TechSupport", "StreamingTV", "StreamingMovies").agg(count("CustomerID").alias("CustomerCount"))return service_combinations五、系统视频
基于Hadoop的电信客服数据处理与分析系统项目视频:
大数据毕业设计选题推荐-基于Hadoop的电信客服数据处理与分析系统-Spark-HDFS-Pandas
结语
大数据毕业设计选题推荐-基于Hadoop的电信客服数据处理与分析系统-Spark-HDFS-Pandas
大家可以帮忙点赞、收藏、关注、评论啦~
源码获取:⬇⬇⬇
精彩专栏推荐⬇⬇⬇
Java项目
Python项目
安卓项目
微信小程序项目