为了更强大的空间智能,如何将2D图像转换成完整、具有真实尺度和外观的3D场景?
本文介绍了一项关于空间智能领域的前沿研究成果——《Towards Scalable Spatial Intelligence via 2D-to-3D Data Lifting》,该论文被ICCV 2025接收,合作单位包括杜伦大学、阿里巴巴达摩院、清华大学和中科院-特斯联人工智能实验室。
在本研究中提出了一种可扩展的数据生成流程,能够将2D图像转换成完整、具有真实尺度和外观的3D场景。这一流程结合了深度估计、相机内外参预测与尺度校准等技术,大幅降低了构建3D数据集的成本,缓解了当前空间智能领域发展受制于3D数据匮乏的瓶颈。
作者生成并发布了两个大规模空间数据集(COCO-3D 和 Objects365-v2-3D),涵盖约2百万个3D场景和300多个类别的物体。通过大量实验结果表明,该方法是构建具备感知、理解并与物理环境交互的空间智能型AI系统的有效解决方案。
推文作者为许东舟,审校为黄星宇和邱雪。
论文链接:https://arxiv.org/pdf/2507.18678
项目主页:https://ZhangGongjie.github.io/TowardsSSI-page/
一、会议介绍

计算机视觉国际大会(International Conference on Computer Vision,ICCV)是计算机视觉领域内最重要的国际学术会议之一。会议内容涵盖计算机视觉的各个方面,包括图像处理、模式识别、机器学习在视觉中的应用、三维场景重建、物体检测与识别、动作和事件的捕捉、人脸识别、虚拟现实以及增强现实等研究方向。ICCV 2025的投稿量有11239篇,最终收录了2699,录取率约为24%
会议官网:https://iccv.thecvf.com/
二、研究背景及主要贡献
2.1 研究背景
空间智能是指感知、推理与交互三维环境的能力,有望推动人工智能领域的下一轮重大突破,目前广泛应用于机器人、沉浸式增强/虚拟现实(AR/VR)和场景建模等多个方向。类似于多模态大语言模型的成功,空间智能的发展也依赖于海量、多样且具备标注的训练数据。然而,与互联网中丰富的文本、图像或视频资源不同,空间数据的获取往往需要专业硬件以及繁重而高成本的数据采集和标注流程。这一关键瓶颈显著限制了空间智能的发展,使得该领域始终未能迎来类似 ImageNet 规模的3D数据集来推动领域飞跃。
为了缓解3D数据的不足,现阶段的探索主要分为三类,但都具有各自的局限性:
(1)仿真模拟数据:通过使用游戏引擎等模拟器生成3D场景,此类方法成本低、速度快,但模拟环境的几何和物理细节简单化,导致训练的模型很难泛化到真实世界。
(2)AI生成的3D资产:现有方法主要局限于单个3D对象的生成,但拓展到逼真的场景级生成仍具有极大挑战性。生成的场景存在比例失调、外观不真实以及物体排列逻辑混乱等问题,大多呈现卡通渲染风格,难以应用于现实任务。
(3)传感器采集数据:通过专业硬件(如 LiDAR、RGB-D 相机等)采集的高精度3D数据虽然真实度高,但这类数据采集和标注成本较高,规模有限且偏向于特定领域。
2.2 本文贡献
(1)提出了一套将2D图像构建大规模多样化、具有真实尺度的3D场景的空间数据生成流程,为空间智能提供新的数据来源。
(2)发布了两个大规模空间数据集 COCO-3D 与 Objects365-v2-3D,涵盖约200万个场景与300多个类别,适用于多样环境。
(3)通过广泛的实验证明,生成的数据在实例分割、语义分割、指代分割、问答与密集描述等任务中均提升了性能,验证了“2D到3D”范式在可扩展空间智能发展中的基础作用。
三、数据生成与统计
3.1 数据处理与生成流程

图1 “2D到3D数据升维”流程。
数据生成流程可以从 2D 图像中自动构建具备区域感知能力的 3D 注释信息,其核心是为每一张图像构建经过尺度校准的 3D 表示(如图 1 所示)。该流程分为相对深度估计、绝对尺度深度估计、尺度校准和相机参数预测(将 2D 物体投影到 3D 空间中)四个主要步骤。
相对深度估计能够捕捉精细的几何细节,但缺乏全局尺度;绝对尺度(度量)深度估计可提供准确的全局尺度,但往往会牺牲局部的几何精度。文中提出的方法结合了两者的优势,并通过尺度校准,生成既保留细节又具真实尺度的 3D 表示,如图2所示。
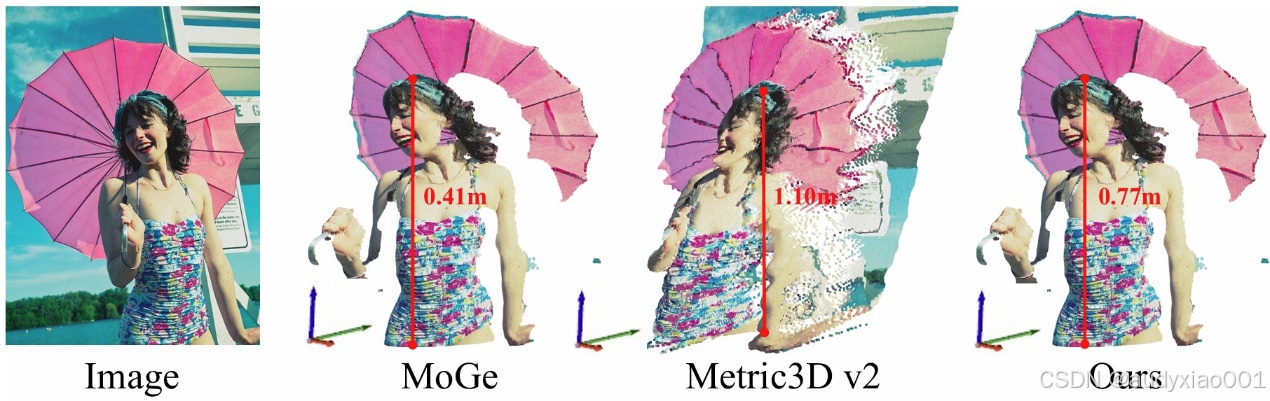
图2 不同深度估计方法生成的 3D 表示对比。
具体来说,文中采用 MoGe 作为相对深度预测器。它的特点是鲁棒性强,适用于真实图像场景。它首先估计一个三维点云,然后基于点云推导出相对深度图。并且,MoGe 引入了多尺度局部几何损失,能在仿射对齐条件下惩罚局部误差,从而保留较高的局部几何细节。度量深度估计模型则选择了 Metric3D v2,该模型以焦距作为输入,并在多种室内与室外场景上进行联合训练,具有良好的泛化能力。即使不能完美恢复细节结构,也能在大多数场景中能提供合理的全局尺度。
通过上述两个模块,分别可以得到来自 MoGe 的相对深度和来自Metric3D v2的度量深度。将两者结合,用来估算尺度因子,并由此得到尺度校准后的深度图。
为了将 2D 图像准确投影到 3D 空间,需要同时预测相机的内参(如焦距、主点)和外参(相机位姿,即旋转和平移)。研究中使用 WildCamera 预测内参,它具备尺度感知能力,并且可以检测图像裁剪区域,从而精确恢复主点和焦;外参预测采用的是 PerspectiveFields,它提供了每像素的向上向量和纬度值,能够构建旋转矩阵,使点云与标准三维数据集对齐。
最终,结合原2D标注或开放词汇检测模型输出的物体区域,将标注投影到3D点云中,形成高质量的3D实例与语义标注。
3.2 数据集统计
研究基于 COCO 数据集生成了 COCO-3D,经过滤与校验后,训练集包含117,183个3D 场景、验证集包含 4,951 个 3D 场景。每个样本至少包含一个有效物体,并且数据及其注释将对外公开。
为进一步评估合成流程是否保持了真实世界的尺度信息,作者分析了 person、cup、bottle、chair 等示例充足类别的高度分布。如图3所示,各类别的高度分布与现实期望高度相符。例如“person”高度大致分布在0.5m–2.0m,以适应半身、坐姿以及儿童等情况。其中有部分“person”实例显得更矮,是因为只能在图像见到身体的部分。其他类别的高度统计也在合理范围内,进一步证明了合成的数据集具有可靠性。
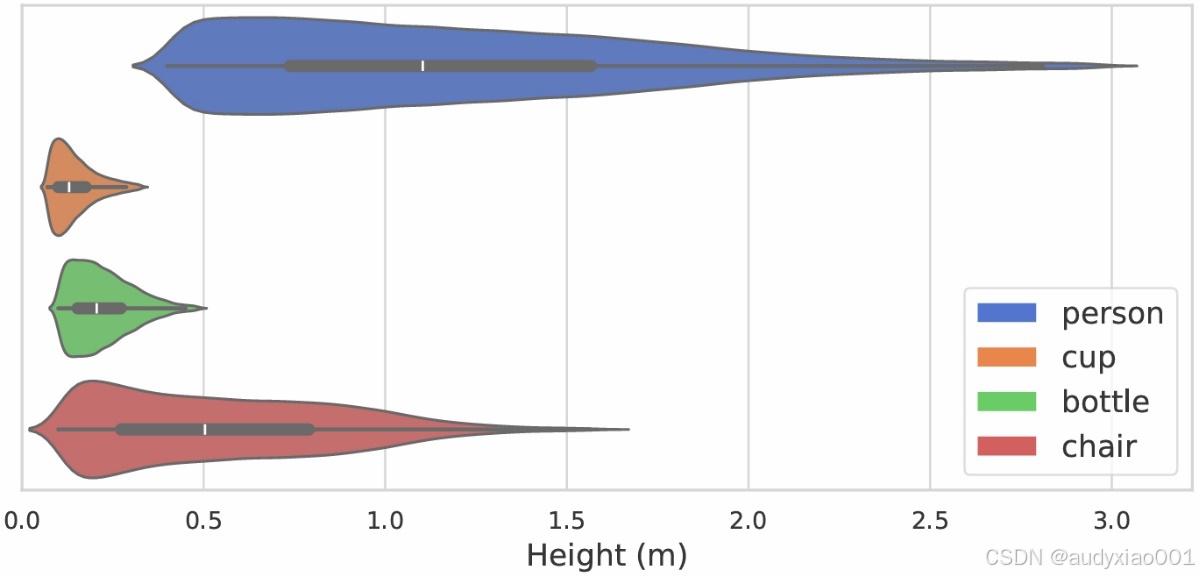
图 3 COCO-3D 中四个常见类别的高度分布。
四、实验及结果
4.1 3D实例分割
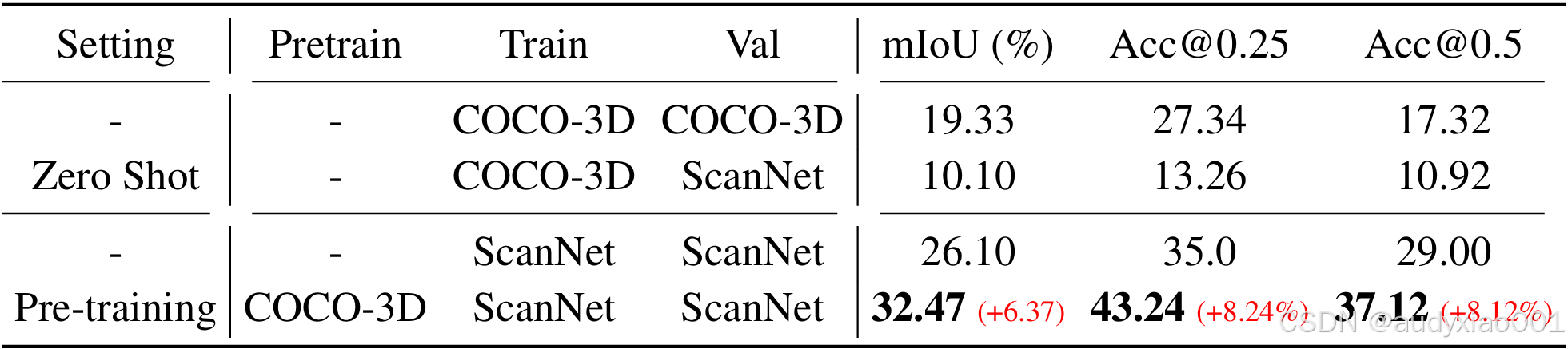
实验中首先评估了合成数据对3D实例分割的影响,表1结果显示,相较于直接在真实数据集ScanNet上进行训练,引入 COCO-3D进行预训练后,能有效提升模型的性能,尤其是mAP提升了约4%。
表1 点云实例分割结果。

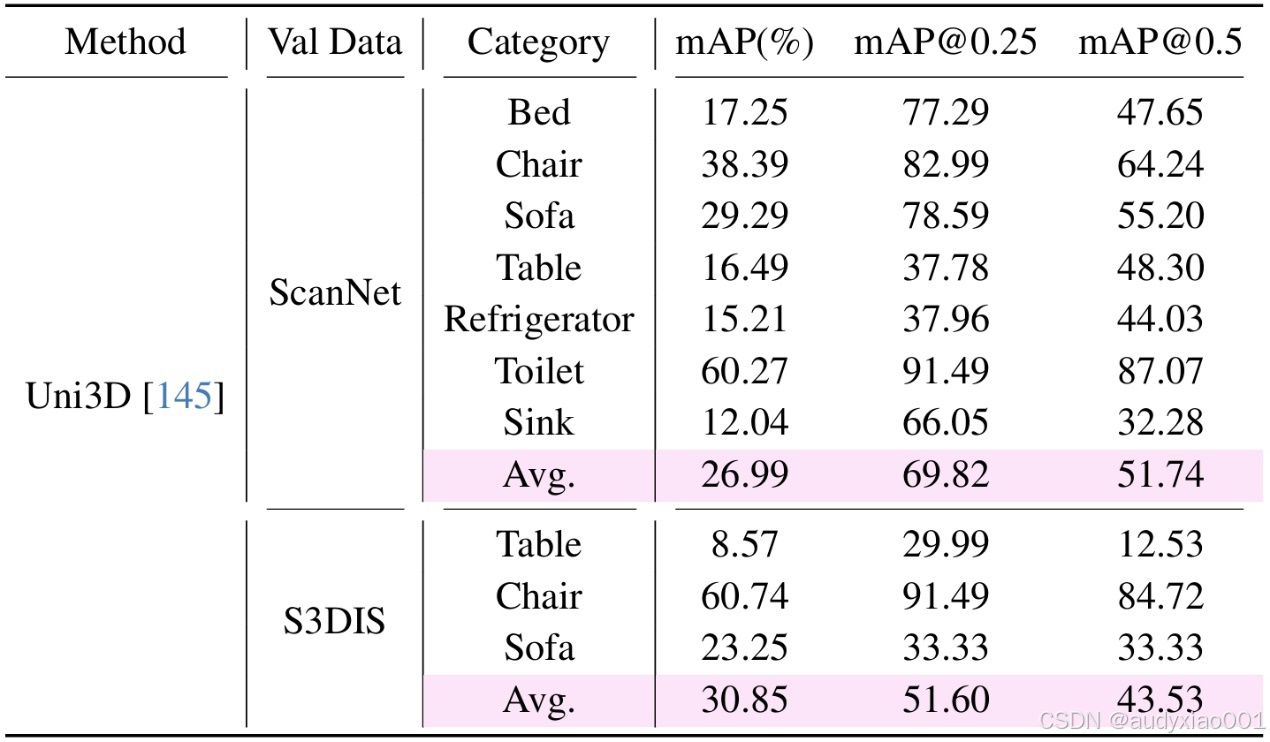
表2评估了方法的零样本泛化性能,即仅在 COCO-3D 上训练,不在目标数据集上做任何微调,直接应用到 ScanNet 和 S3DIS 等真实数据集。在这种设置下,模型仍然能在部分类别上取得不错的效果,例如“toilet”类别上,mAP 超过 60%。证明了合成数据中的空间和语义特征具有较强的可迁移性。
表2 点云实例分割零样本评估。
4.2 3D语义分割
这部分研究了合成数据对 3D 语义分割的影响,实验中选取了SpUNet、PTv2、Uni3D 三种基线模型。表3显示,三种基线方法在使用 COCO-3D进行预训练之后,各项评估指标都有显著提升。尤其是SpUNet在经预训练后,mIoU 的提升幅度达到了31个百分点。这种显著的提升证明了合成数据能为模型提供高质量的空间信息,使其在真实数据上也具有更强的准确性。
表3 点云语义分割结果。
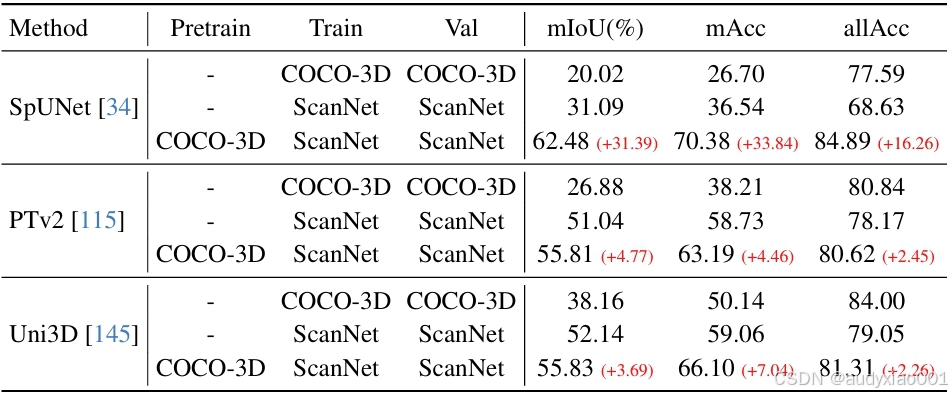
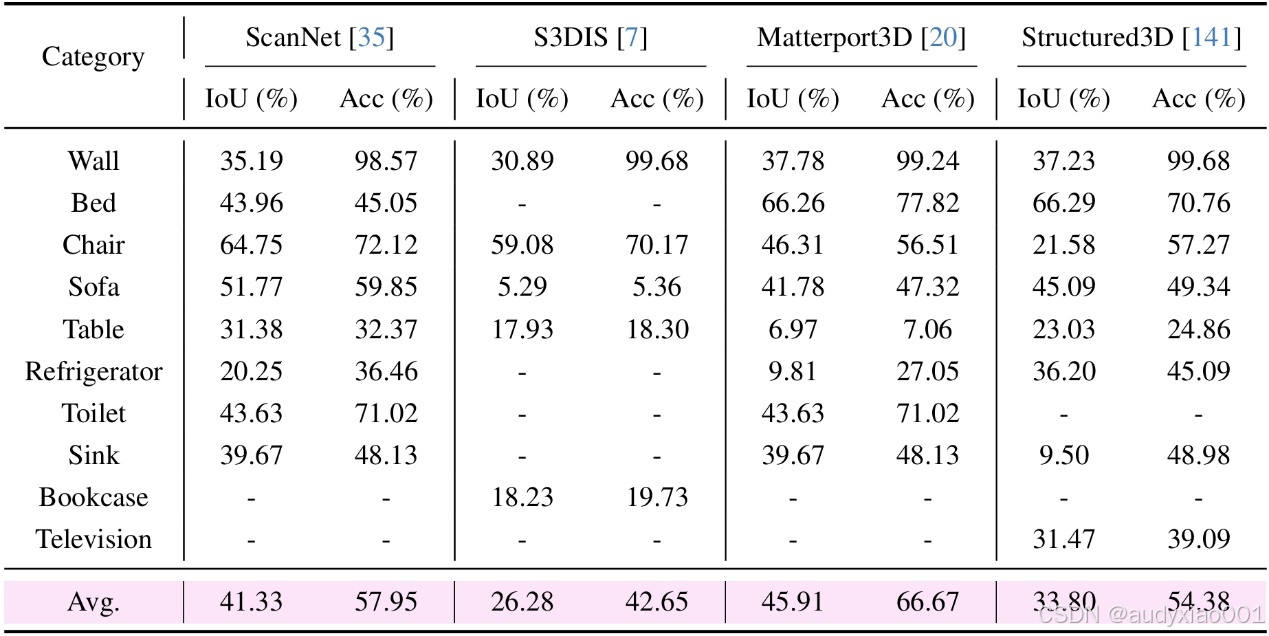
表4展示了零样本语义分割的能力。模型仅在 COCO-3D 上进行训练后,直接在真实数据集上进行测试,能够在多类物体上输出理想的分割结果。进一步说明了合成数据还能为跨域分割任务提供有用的知识基础。
表4 点云语义分割零样本评估。
4.3 指向式实例分割
该部分评估了合成三维数据在指向式 3D 实例分割任务中的作用,并以 TGNN 在 ScanNet 上训练为基线。零样本测试(在 COCO-3D 上训练,测试于 ScanNet)性能有明显下降。如表5所示,当结合 COCO-3D 、ScanNet 进行训练时,各项性能较基线均提升了超6%,表明合成数据可通过增加训练多样性增强性能与泛化能力。仅通过 COCO-3D 进行训练时,模型也具备一定的指代分割能力,但弱于真实数据。
表5 指向式点云实例分割结果。
4.4 3D大语言模型任务
作者使用 LL3DA评估了 COCO-3D 对 3D 视觉-语言任务的帮助,包括 ScanRefer(引用式描述)、Nr3D(自然语言 3D 定位)和 ScanQA(3D 问答)。表6显示,COCO-3D 预训练在所有任务和评测指标上均有提升,说明了合成数据能够增强模型的语言-视觉对齐能力,使其在多任务中表现更均衡。
表6 LL3DA“3D通用模型”在有无 COCO-3D 预训练下的性能表现。

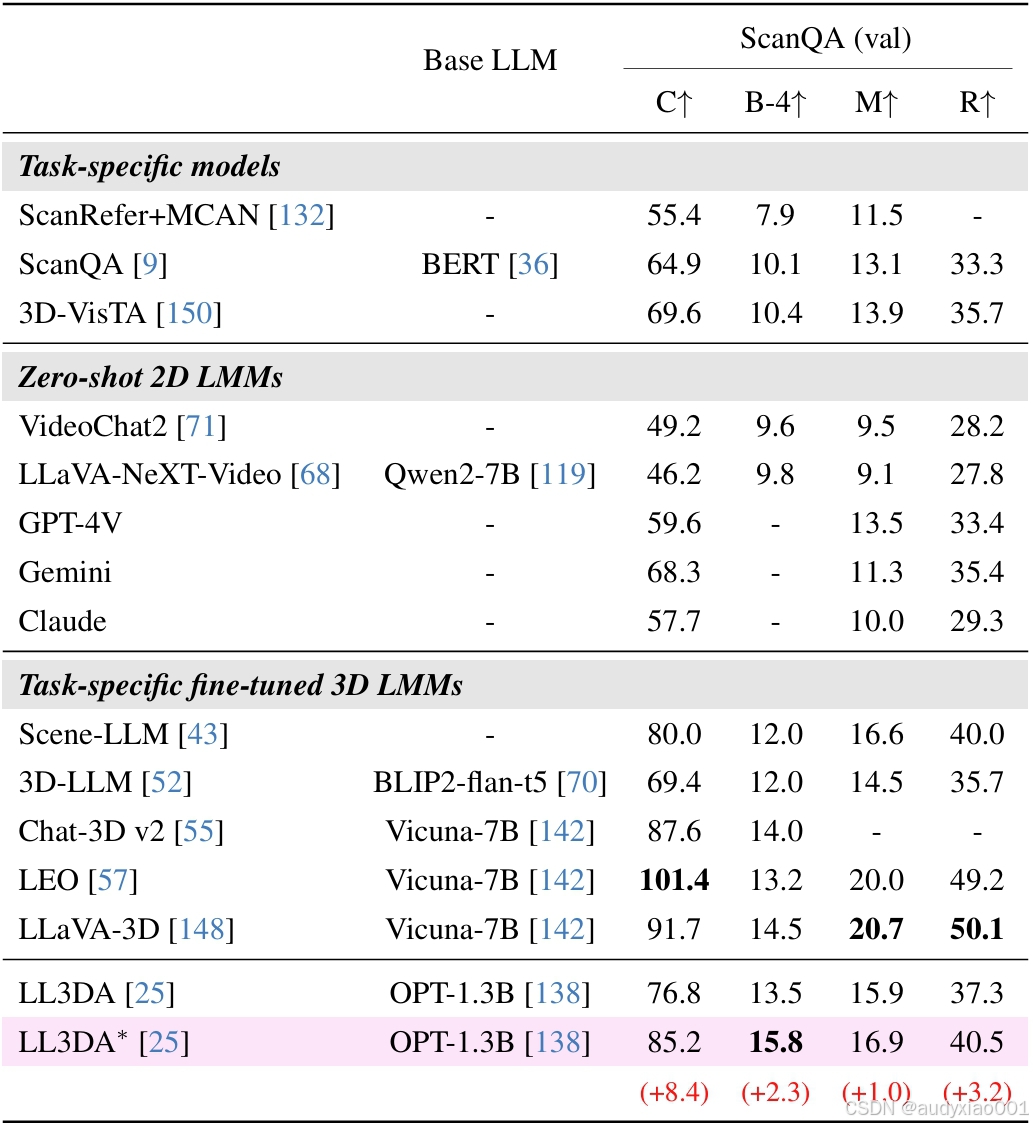
表 7 比较了不同3D LLM 在 ScanQA 上(仅用 ScanQA 微调)的表现:相较于使用 7B 级模型,1.3B的 LL3DA在微调过后也能获得相当甚至更优的性能。当引入 COCO-3D 预训练后,性能又得到进一步提升,能匹配或超越某些专为该任务微调的7B级模型,尤其BLEU-4甚至达到了最佳的15.8%。进一步表明了合成数据在填补 3D 视觉-语言任务训练数据缺口方面具有巨大潜力,能使较小模型也具备与大模型相媲美的空间理解和推理能力。
表 7 ScanQA 上的 3D 问答任务结果。
五、总结
文中提出了一种用来解决空间智能领域中由于缺乏充足优质数据问题的新方法——从大规模、带标注的2D图像数据集中生成高质量的空间数据。利用现有2D标注构建真实多样、贴近日常环境的3D场景,构建出了 COCO-3D、 Objects365-v2-3D 等大规模空间数据集。经实验结果表明,从2D到3D的升维能够有效推动3D空间的感知、推理等核心任务。