对抗式域适应 (Adversarial Domain Adaptation)
坚持更新,坚持学习,更多知识还在探索中
文章目录
- 前言
- 一、域适应是什么?
- 二、DANN(Domain-Adversarial Neural Networks)
- 1.输入与特征提取(绿色部分)
- 2.分类分支(蓝色部分)
- 3.域判别分支(粉色部分)
- 4.梯度反转层(GRL)的作用
- 5.整体优化目标
- 6.更直观的理解
- 总结
前言
随着人工智能技术的快速发展,机器学习在各个领域的应用越来越广泛。然而,一个普遍存在的问题是,模型在一个数据集上训练得很好,但在另一个数据集上的表现却不尽如人意。这种现象通常被称为域偏移(Domain Shift),它是指训练数据和测试数据来自不同的分布。为了解决这个问题,域适应(Domain Adaptation)技术应运而生,它旨在使模型能够适应新的、未见过的数据分布。
在传统的监督学习中,我们通常需要大量带标签的数据进行训练,并且需要保证训练集和测试集中的数据分布相似。如果训练集和测试集的数据具有不同的分布,训练后的分类器在测试集上就没有好的表现。这种情况下该怎么办呢?
域适应,也称为域对抗(Domain Adversarial),是迁移学习中的一个重要分支,用以消除不同域之间的特征分布差异。其目的是把具有不同特征分布的源域(Source Domain)和目标域(Target Domain)映射到同一个特征空间,寻找某一种度量准则,使其在这个空间上的距离尽可能小。然后,我们在源域(带标签)上训练好的分类器,就可以直接用于目标域数据的分类。
本文将介绍域适应的基本概念、方法和应用,并重点讨论一种名为对抗式域适应神经网络(Domain-Adversarial Neural Networks,简称DANN)的技术。DANN通过引入一个域判别器来学习源域和目标域之间的特征差异,并通过对抗训练来最小化这些差异,从而提高模型在目标域上的泛化能力。
一、域适应是什么?
在传统监督学习中,我们经常需要大量带标签的数据进行训练,并且需要保证训练集和测试集中的数据分布相似。如果训练集和测试集的数据具有不同的分布,训练后的分类器在测试集上就没有好的表现。这种情况下该怎么办呢?
域适应(Domain Adaption),也可称为域对抗(Domain Adversarial),是迁移学习中一个重要的分支,用以消除不同域之间的特征分布差异。其目的是把具有不同分布的源域(Source Domain) 和目标域 (Target Domain) 中的数据,映射到同一个特征空间,寻找某一种度量准则,使其在这个空间上的“距离”尽可能近。然后,我们在源域 (带标签) 上训练好的分类器,就可以直接用于目标域数据的分类。
源域样本分布(带标签),目标域样本分布不带标签,它们具有共同的特征空间和标签空间,但源域和目标域通常具有不同的分布,这就意味着我们无法将源域训练好的分类器,直接用于目标域样本的分类。因此,在域适应问题中,我们尝试对两个域中的数据做一个映射,使得属于同一类(标签)的样本聚在一起。此时,我们就可以利用带标签的源域数据,训练分类器供目标域样本使用。
二、DANN(Domain-Adversarial Neural Networks)
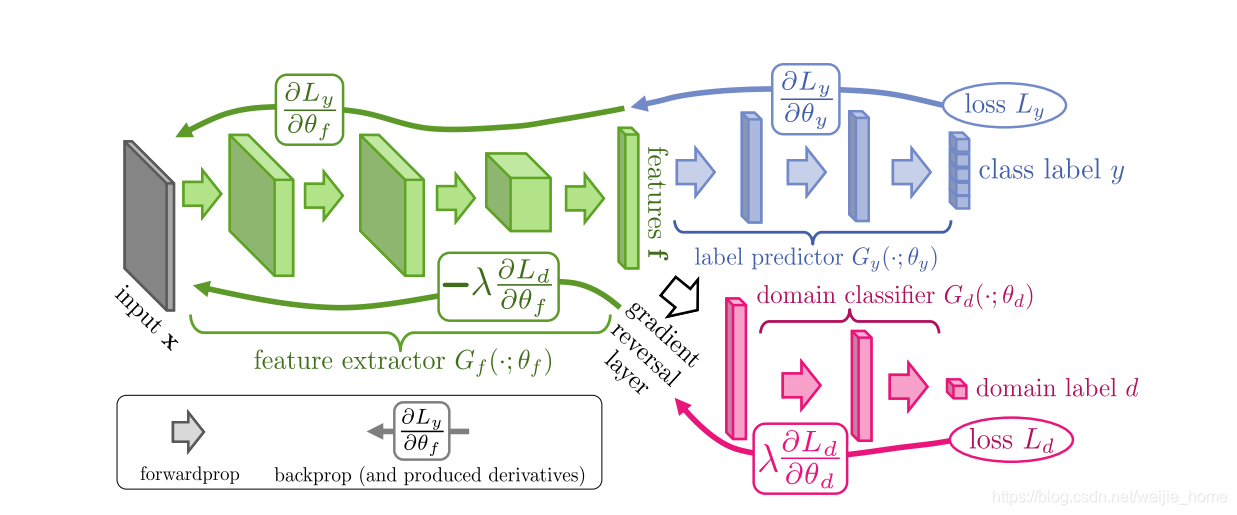
这个图其实就是 DANN (Domain-Adversarial Neural Network) 的标准流程图。它展示了如何通过 梯度反转层 (GRL) 来实现跨域特征对齐。
这图是对抗式域适应(ADA)的核心思想。通过对抗博弈(feature extractor(特征提取器) 想混淆域信息,domain classifier(域分类器) 想区分域信息),逼迫学到domain-invariant features,实现 源域 → 目标域的迁移。
这张图展示了 DANN 的对抗式域自适应框架:通过分类任务保证特征可用,通过梯度反转 + 域分类器保证特征跨域对齐。
1.输入与特征提取(绿色部分)

feat_m = self.base_network.forward_features(mid)
feat_t = self.base_network.forward_features(target)
2.分类分支(蓝色部分)

这保证了特征对 任务类别 y 有判别能力。
ce_none = nn.CrossEntropyLoss(reduction="none", label_smoothing=self.args.label_smoothing)
per = ce_none(self.classifier_layer(feat_m), mid_label) # [B]
loss_m = per.mean()
3.域判别分支(粉色部分)

这意味着:
- 域分类器要学会区分源域和目标域
- 特征提取器通过反转的梯度
被迫学习让不同域的特征更接近.
# 1. GRL (梯度反转层)
grl_m = grad_reverse(feat_m, self.args.lambda2)
grl_t = grad_reverse(feat_t, self.args.lambda2)# 2. 域判别器 (domain classifier)
Dm = self.domain_discriminator(grl_m).view(-1)
Dt = self.domain_discriminator(grl_t).view(-1)# 3. 域对抗损失
bce = nn.BCEWithLogitsLoss()
loss_adv = 0.5 * (bce(Dm, torch.zeros_like(Dm)) + # mid → 0bce(Dt, torch.ones_like(Dt)) # target → 1
)
transfer_loss = self.args.lambda3 * loss_adv4.梯度反转层(GRL)的作用
- 前向传播时,GRL 就是恒等映射(直接输出特征)。
- 反向传播时,GRL 会把梯度乘上 −λ。
- 这样,特征提取器的目标就从“帮助域分类器”变成了“欺骗域分类器”。
5.整体优化目标

6.更直观的理解
-
分类分支:学任务相关特征(比如 plankton 种类)。
-
域对抗分支:逼迫特征在源域和目标域上长得像(domain-invariant)。
-
GRL:像“拔河”,让特征提取器在两种需求之间找到平衡。
总结
未完待续,,,更多知识还在探索中~