Hugging Face 核心组件介绍
Hugging Face 核心组件介绍
一、Hugging Face简介
Hugging Face 是一个开放的人工智能社区和平台,致力于提供方便易用的自然语言处理(NLP)模型和工具。它的核心价值在于通过 统一接口 快速访问海量预训练模型,并提供端到端的机器学习开发工具链,极大降低了构建智能应用的门槛。
在架构上,Hugging Face 包含模型库(Model Hub)、数据集库(Datasets)、训练工具(Transformers 和 Trainer API)、推理部署方案等多个模块,彼此协同支持开发者从模型训练、微调到推理部署的全流程。
1.1 主要包括
- 模型库(
Model Hub)
Hugging Face拥有全球最大的开源 AI 模型库,涵盖Transformer、Stable Diffusion、Whisper等多个领域,用户可以直接下载、微调或在线部署这些模型。 - 数据集(
Datasets)
提供了大量开源数据集,支持 NLP、计算机视觉、音频等多种任务,开发者可以直接使用或上传自己的数据集。 Transformers库
这是Hugging Face最受欢迎的Python库之一,支持BERT、GPT、T5等各种 Transformer 模型,并且提供了简单的 API 进行推理和训练。Inference API & SpacesInference API:提供基于云端的推理服务,用户可以直接调用 API 进行推理,而无需本地部署。Spaces:一个轻量级的应用部署平台,支持Gradio和Streamlit,方便开发者创建和分享AI Demo。
AutoTrain & PEFT(参数高效微调)AutoTrain:自动化机器学习训练工具,适合非专业开发者快速微调模型。PEFT:提供参数高效微调(如 LoRA)方法,降低计算成本,提高训练效率。
- 社区驱动 & 开源
Hugging Face依赖全球开发者和研究者的贡献,所有核心工具都是开源的,用户可以自由下载、修改和优化。它还组织 AI 竞赛和研究项目,促进 AI 技术的进步和共享。
1.2 适用场景
- 研究人员可以用
Hugging Face进行 NLP、CV 等前沿 AI 研究。 - 开发者可以快速集成 AI 模型,应用于聊天机器人、翻译、语音识别等任务。
- 企业可以通过
Hugging Face的 API 和云端服务,快速构建 AI 解决方案。
总的来说,Hugging Face 是一个集模型、数据、推理、社区于一体的 AI 生态平台,极大地降低了 AI 技术的门槛,推动了 AI 的普及和发展。
官网:https://huggingface.co
二、Hugging Face注册和安装
2.1 注册 Hugging Face 账户
- 访问
Hugging Face官方网站,点击右上角的“Sign Up”按钮。 - 输入你的邮箱、用户名和密码,完成注册流程。
- 注册成功后,你可以访问模型库、数据集和文档,也可以管理你的个人模型和项目。
2.2 安装 Hugging Face 库
Hugging Face 提供了 transformers 库,用于加载和使用模型。你可以使用以下命令来安装它:(电脑须安装基础环境:Anaconda, CUDA, cuDNN, pytorch)
$ pip install transformers
如果你还需要安装其他依赖库,如 datasets 和 tokenizers,可以使用以下命令:
$ pip install transformers datasets tokenizers
三、模型探索与下载
3.1 在模型库中搜索模型
Hugging Face 提供了一个庞大的模型库,你可以通过以下步骤来查找所需的模型:
- 访问模型库页面。
- 在搜索栏中输入关键字,如
"GPT-2"或"BERT",然后点击搜索。 - 你可以使用左侧的过滤器按任务、框架、语言等条件筛选模型。
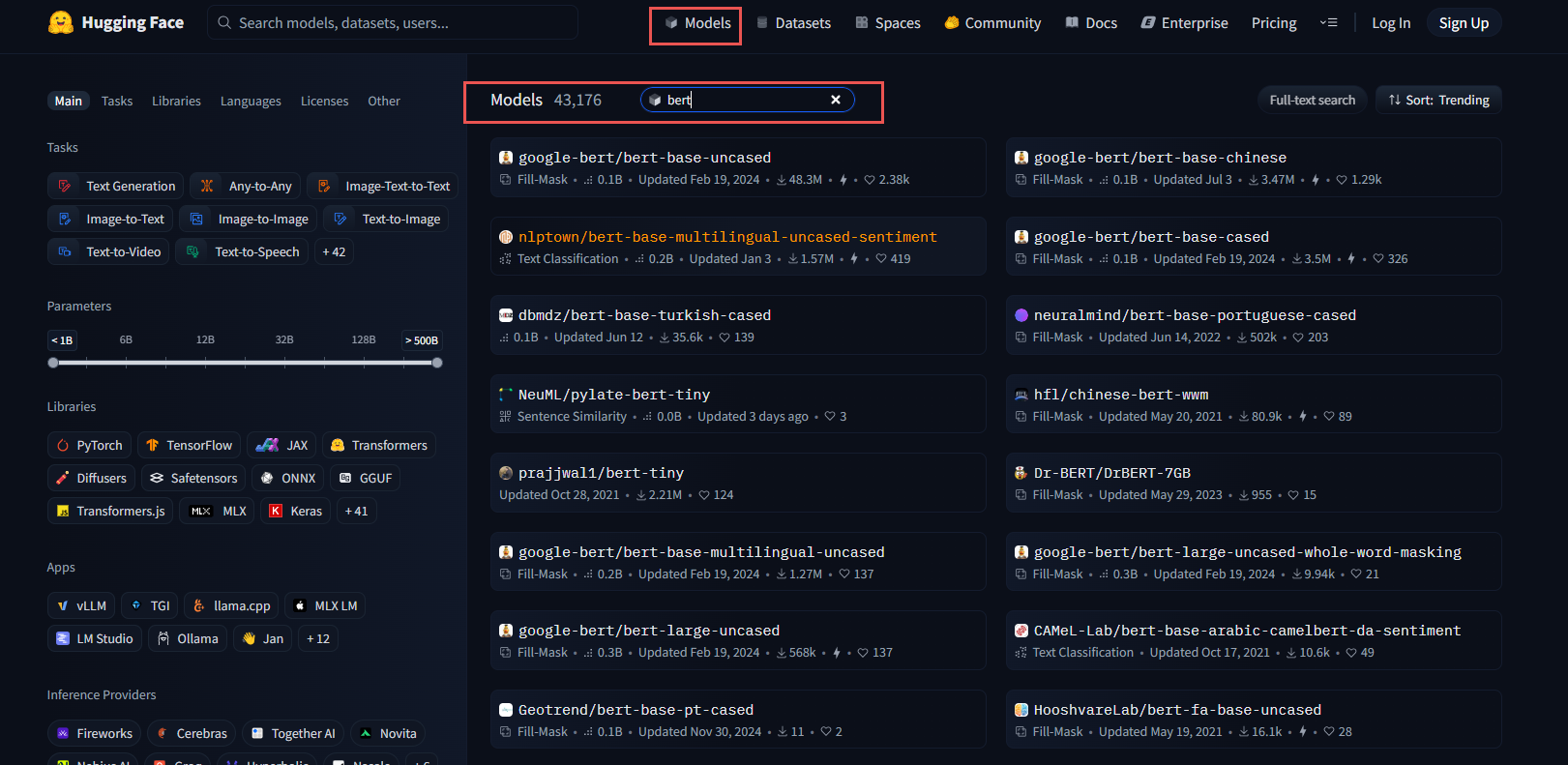
3.2 下载与加载模型到指定文件夹
找到所需模型后,你可以通过代码将模型下载到指定的文件夹,并加载模型:
# 将模型下载到本地调用
from transformers import AutoModel, AutoTokenizer# 替换为你选择的模型名称
model_name = "bert-base-uncased"
# 指定模型保存路径
cache_dir = "./my_model_cache"
#下载模型
model = AutoModelForCausalLM.from_pretrained(model_name, cache_dir=cache_dir)
#下载分词工具
tokenizer = AutoTokenizer.from_pretrained(model_name, cache_dir=cache_dir)print(f"模型分词器已下载到:{cache_dir}")
四、Hugging Face API 使用
4.1 匿名访问 API
通过 Hugging Face Inference API 匿名调用 在线模型 (注意:匿名访问的模型受限于公开权限),不稳定不推荐!
import requestsAPI_URL = "https://api-inference.huggingface.co/models/bert-base-chinese"# 不使用 Authorization 头以进行匿名访问
response = requests.post(API_URL, json={"inputs": "你好,Hugging Face!"})
print(response.json())
4.2 使用 Inference API
使用 Inference API在线调用大模型,在注册并获取 API Token 后,你可以使用自己的 API Token 进行访问,不稳定不推荐!
import requests#使用Token访问在线模型
API_URL = "https://api-inference.huggingface.co/models/uer/gpt2-chinese-cluecorpussmall"
API_TOKEN = "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"
headers = {"Authorization": f"Bearer {API_TOKEN}"}response = requests.post(API_URL,headers=headers,json={"inputs":"你好,Hugging face"})
print(response.json())
五、使用 Transformers 库
Transformers 是由 Hugging Face 提供的一个强大的自然语言处理(NLP)库,旨在通过简单的 API 接口,使开发者能够使用预训练的深度学习模型来处理各种 NLP 任务,如文本分类、文本生成、翻译等。
# 安装transformers库
$ pip install transformers
随着深度学习和大数据技术的发展,NLP 的应用已经深入到日常生活的方方面面。Transformers 库通过封装一系列经过大规模语料训练的模型,极大地降低了 NLP 应用的门槛,成为了学术研究与工业实践中的热门工具。
Transformer模型:一种基于注意力机制的架构,广泛应用于 NLP 任务。- 预训练与微调:通过大规模的无监督预训练,模型能捕捉通用语言特征,然后在特定任务上进行微调以实现更高的性能。
BERT, GPT, T5等模型:各具特色的变体模型满足不同的需求。
5.1 Transformers 的几个概念
Pipeline 是 transformers 库中的一个高级工具,它将复杂的自然语言处理任务(如文本分类、命名实体识别、翻译等)模型的推理过程封装起来,让使用者可以用简单的代码完成复杂的任务。
Tokenizer在自然语言处理(NLP)中是一个关键组件,它负责将文本字符串转换成模型可以处理的结构化数据形式,通常是将文本切分成 tokens 或单词、短语、子词等单位。这些 tokens 是模型理解文本的基础。Tokenizer的类型和复杂性可以根据任务需求而变化,从简单的基于空格的分割到更复杂的基于规则或机器学习的分词方法。
Tokenizer的主要功能:
- 分词:将句子拆分成单词或子词。例如,中文分词器会将“自然语言处理”拆分成“自然”、“语言”、“处理”,而英文Tokenizer可能使用Subword Tokenization如Byte-Pair Encoding (BPE)来处理罕见词。
- 添加特殊标记:在序列的开始和结束添加特殊标记,如BERT中的[CLS]和[SEP],用于特定任务的序列分类或区分输入片段。
- 编码:将tokens转换为数字ID,这些ID是模型的输入。每个token在词汇表中有一个唯一的ID。
- 处理填充和截断:为了确保输入序列的一致长度,Tokenizer可以对较短的序列进行填充,对较长的序列进行截断。
- 生成Attention Mask:在某些模型中,Tokenizer还会生成一个Attention Mask,指示哪些输入位置是实际的tokens(通常标记为1),哪些是填充的(标记为0)。
CUDA(Compute Unified Device Architecture)是由 NVIDIA 开发的并行计算平台和编程模型,旨在利用 NVIDIA 图形处理器(GPU)的强大算力加速计算任务。它打破了 GPU 传统上仅用于图形渲染的局限,让开发者能够通过编写特定代码,将 GPU 作为高效的并行计算处理器使用。
CUDA 是 NVIDIA GPU 算力释放的关键技术,它将 GPU 从图形处理器拓展为通用计算平台,通过 CUDA 开发者能够以相对低的成本实现高性能计算,加速复杂任务的落地,其生态(如支持的框架、库和工具)也在持续扩展,成为现代计算基础设施的重要组成部分。
5.1 文本生成
你可以将模型下载到本地,然后使用 pipeline 进行文本生成:
# 本地离线调用GPT2
from transformers import AutoModelForCausalLM,AutoTokenizer,pipeline# 确保模型已经下载
# 设置模型具体包含config.json的目录,只支持绝对路径
model_dir = r"D:\PycharmProjects\demo_1\trsanformers_test\model\uer\gpt2-chinese-cluecorpussmall\models--uer--gpt2-chinese-cluecorpussmall\snapshots\c2c0249d8a2731f269414cc3b22dff021f8e07a3"#加载模型和分词器
model = AutoModelForCausalLM.from_pretrained(model_dir)
tokenizer = AutoTokenizer.from_pretrained(model_dir)#使用加载的模型和分词器创建生成文本的pipeline
generator = pipeline("text-generation",model=model,tokenizer=tokenizer,device="cuda")#生成文本
# output = generator("你好,我是一款语言模型,",max_length=50,num_return_sequences=1)
output = generator(# 生成文本的输入种子文本(prompt)。模型会根据这个初始文本,生成后续的文本"你好,我是一款语言模型,",# 指定生成文本的最大长度。这里的 50 表示生成的文本最多包含 50 个标记(tokens)max_length=50,# 参数指定返回多少个独立生成的文本序列。值为 1 表示只生成并返回一段文本。num_return_sequences=1,# 该参数决定是否截断输入文本以适应模型的最大输入长度。如果 True,超出模型最大输入长度的部分将被截断;如果 False,模型可能无法处理过长的输入,可能会报错。truncation=True,# 该参数控制生成文本的随机性。值越低,生成的文本越保守(倾向于选择概率较高的词);值越高,生成的文本越多样(倾向于选择更多不同的词)。0.7 是一个较为常见的设置,既保留了部分随机性,又不至于太混乱。temperature=0.7,# 该参数限制模型在每一步生成时仅从概率最高的 k 个词中选择下一个词。这里 top_k=50 表示模型在生成每个词时只考虑概率最高的前 50 个候选词,从而减少生成不太可能的词的概率。top_k=50,# 该参数(又称为核采样)进一步限制模型生成时的词汇选择范围。它会选择一组累积概率达到 p 的词汇,模型只会从这个概率集合中采样。top_p=0.9 意味着模型会在可能性最强的 90% 的词中选择下一个词,进一步增加生成的质量。top_p=0.9,# 该参数控制生成的文本中是否清理分词时引入的空格。如果设置为 True,生成的文本会清除多余的空格;如果为 False,则保留原样。默认值即将改变为 False,因为它能更好地保留原始文本的格式。clean_up_tokenization_spaces=True
)
print(output)
5.2 文本分类
你可以将模型下载到本地,然后使用 pipeline 进行文本分类:
from transformers import BertTokenizer,BertForSequenceClassification,pipeline#设置具体包含config.json的目录,只支持绝对路径
model_dir = r"model\bert-base-chinese"#加载模型和分词器
model = BertForSequenceClassification.from_pretrained("bert-base-chinese",cache_dir=model_dir)
tokenizer = BertTokenizer.from_pretrained("bert-base-chinese",cache_dir=model_dir)#创建分类pipleine
classifier = pipeline("text-classification",model=model,tokenizer=tokenizer,device="cuda")#进行文本分类
result = classifier("你好,我是一款语言模型")
print(result)print(model)
六、datasets 库核心方法
Datasets 模块为处理机器学习数据提供高效接口,支持流式加载和多格式转换,解决传统数据预处理复杂的问题。
主要特点:
• 支持多种数据格式,CSV、JSON、Parquet、文本等
• 支持懒加载与缓存,节省内存和加速训练准备
• 支持分布式加载,便于大规模训练环境
• 兼容与 Transformers 无缝集成
6.1 加载在线数据集
通过
load_dataset方法加载任何数据集 。
from datasets import load_dataset# 列出所有可用数据集
print(list_datasets())#在线加载数据
dataset = load_dataset(path="lansinuote/ChnSentiCorp",cache_dir="data/")
print(dataset)
#转为csv格式
dataset.to_csv(path_or_buf=r"D:\PycharmProjects\demo_02\data\ChnSentiCorp.csv")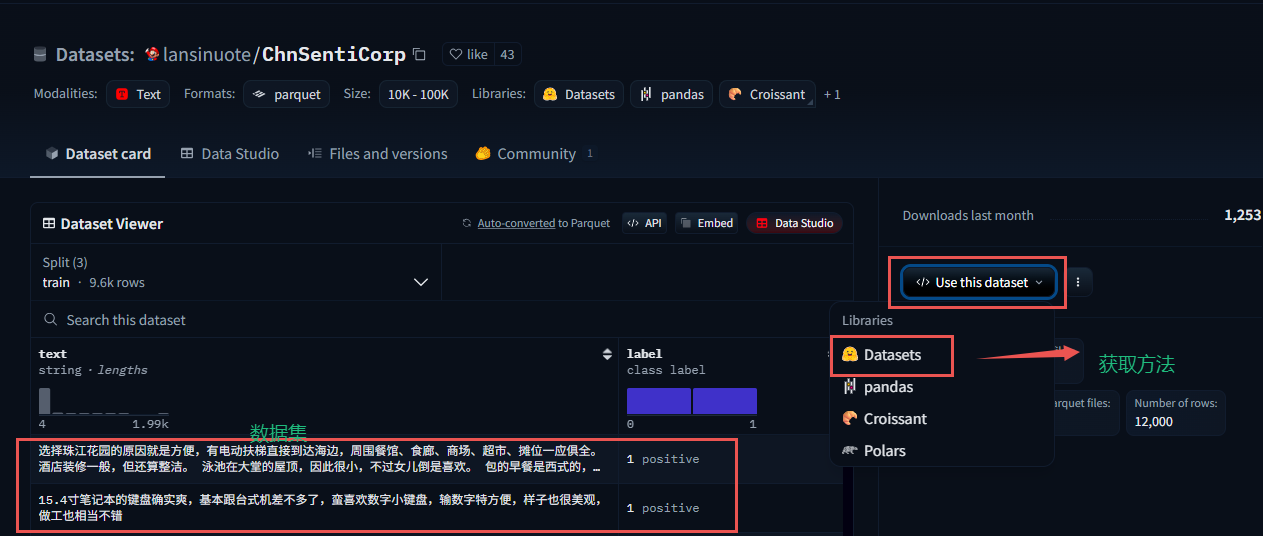
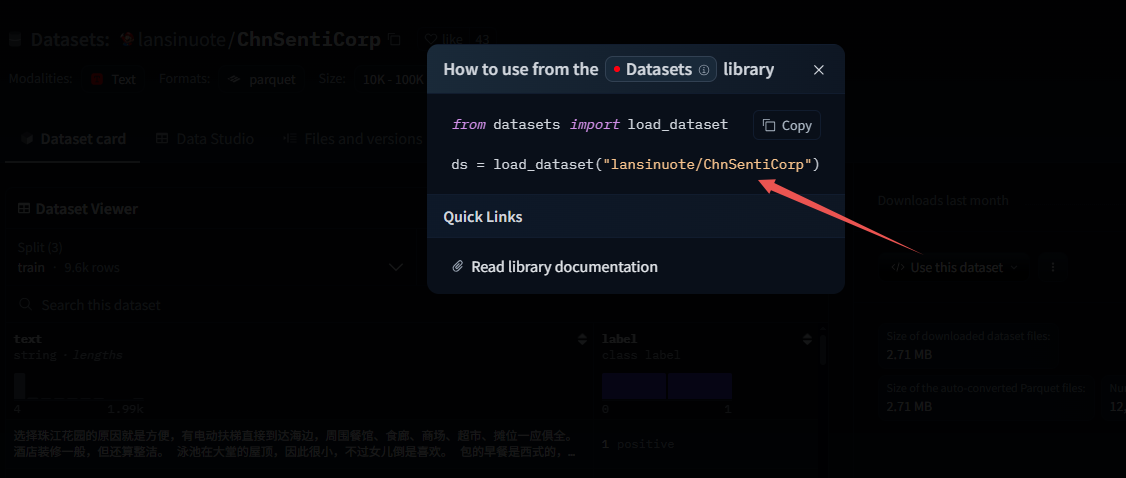
6.2 加载磁盘数据集
加载本地磁盘上的数据。
from datasets import load_from_disk# 从本地磁盘加载数据集
datasets = load_from_disk(r"D:\PycharmProjects\demo_02\data\ChnSentiCorp")
print(datasets)train_data = datasets["test"]
for data in train_data:print(data)#扩展:加载CSV格式数据
dataset = load_dataset(path="csv", data_files=r"D:\PycharmProjects\demo_02\data\hermes-function-calling-v1.csv")
print(dataset)
七、模型的结构
读到这里大家肯定很好奇笔者在上面代码中下载到本地的模型到底长什么样子,模型里面都有什么文件,接下里以 BERT 模型为例,我们来看一下模型里面都有哪些文件。

上图是笔者在本地加载的模型文件,有用的文件都在 snapshots 文件夹下。其中:
config.json是模型的配置文件,对模型做了简单说明,说明了模型的头、模型的结构、模型的参数。- 其中
vocab_size说明模型最多能识别21128个字符。

-
special_tokens文件中包含的特殊字符,UNK就是未识别的字符串,即超出2128个字符外的识别不了的。 -
tokenizer_config是分词器的配置文件。 -
vocab.txt是字典文件,存储模型能识别出的字符。一句话在分词器处理之后,编码器先转码成字典中的数字即位置编码大模型会把每次字转换为字典的索引(注意这里还不是向量化)。(中文分词和英文不一样,英文分词是一个单词一分,中文是一个汉字一分)