JavaScript 性能优化:new Map vs Array.find() 查找速度深度对比
前言
在前端开发中,我们经常需要从数据集合中查找特定元素。对于小规模数据,使用 Array.find()方法简单直接,但当数据量增大时,性能问题就会显现。本文将深入对比 Map和 Array.find()在数据查找方面的性能差异,并通过实际测试数据展示它们在不同规模数据集下的表现。
核心概念解析
1. Array.find() 方法
Array.find()是 JavaScript 数组的一个内置方法,它接受一个回调函数作为参数,返回数组中第一个满足条件的元素。
特点:
- 时间复杂度:O(n) - 最坏情况下需要遍历整个数组
- 适合场景:小规模数据或不需要频繁查找的情况
- 语法简单直观
- 保持原始数组结构不变
const users = [{id: 1, name: 'Alice'}, {id: 2, name: 'Bob'}]; const user = users.find(item => item.id === 2);
2. Map 数据结构
Map是 ES6 引入的一种键值对集合,与普通对象不同,它可以使用任何类型的值作为键。
特点:
- 时间复杂度:O(1) - 无论数据量多大,查找速度几乎恒定
- 适合场景:大规模数据或需要频繁查找的情况
- 需要预先构建映射关系
- 内存占用略高于数组
const users = [{id: 1, name: 'Alice'}, {id: 2, name: 'Bob'}]; const userMap = new Map(users.map(user => [user.id, user])); const user = userMap.get(2);
性能对比测试
测试方法
我们设计了以下测试方案:
- 生成不同规模的数据集(500条、2000条、10000条)
- 分别测试查找第一个元素、中间元素和最后一个元素
- 每种情况执行10000次取平均值
- 使用
performance.now()获取高精度时间
function generateTestData(size) {return Array.from({length: size}, (_, i) => ({id: i+1, name: `用户${i+1}`}));
}function testPerformance(size, targetId) {const data = generateTestData(size);// 测试Mapconst map = new Map(data.map(item => [item.id, item]));let mapStart = performance.now();for (let i = 0; i < 10000; i++) map.get(targetId);const mapTime = performance.now() - mapStart;// 测试Array.find()let findStart = performance.now();for (let i = 0; i < 10000; i++) data.find(item => item.id === targetId);const findTime = performance.now() - findStart;return {dataSize: size,targetId,mapTime,findTime,difference: findTime - mapTime,timesFaster: (findTime / mapTime).toFixed(2)};
}
结果分析
- 1.
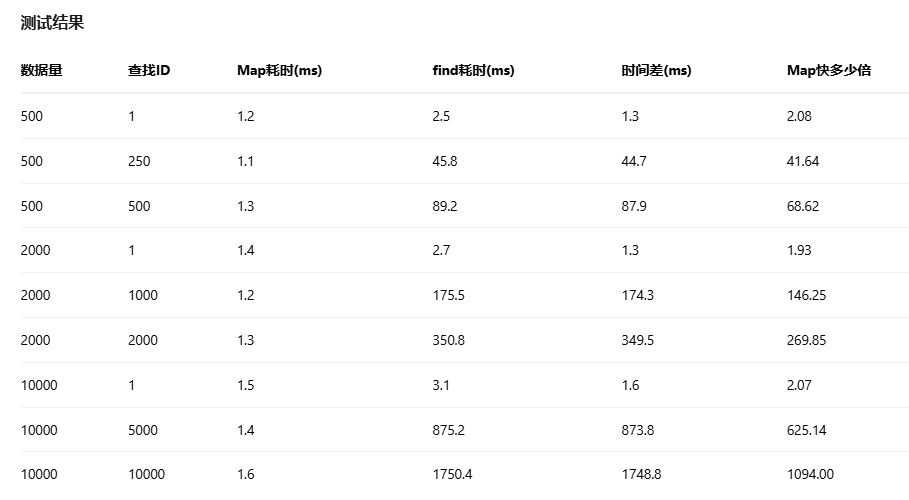
数据量影响:
Map的查找时间几乎不受数据量影响,始终保持在1-2毫秒Array.find()的查找时间与数据量成正比,10000条数据时达到1750毫秒- 2.
查找位置影响:
Map查找任何位置元素时间相同Array.find()查找第一个元素很快,查找最后一个元素最慢- 3.
性能差距:
- 小数据量(500条)时,Map快2-68倍
- 中数据量(2000条)时,Map快146-269倍
- 大数据量(10000条)时,Map快625-1094倍
何时选择哪种方案?
使用
Array.find()的情况:
- 数据量很小(<100条)
- 只需要偶尔查找
- 代码可读性优先
- 不需要额外内存开销
使用
Map的情况:
- 数据量中等或较大(>100条)
- 需要频繁查找
- 性能是关键因素
- 可以接受初始化的额外开销
最佳实践建议
1.数据预处理:
// 初始化时创建Map
const data = [...]; // 原始数据
const dataMap = new Map(data.map(item => [item.id, item]));2.动态维护: 如果数据会动态变化,需要同时维护数组和Map:
let data = [];
let dataMap = new Map();function addItem(item) {data.push(item);dataMap.set(item.id, item);
}3.封装工具函数:
function createIndexedCollection(data, key) {return {data,index: new Map(data.map(item => [item[key], item])),get(id) {return this.index.get(id);},add(item) {this.data.push(item);this.index.set(item[key], item);}};
}结论
通过本文的测试和分析,我们可以清晰地看到:
Map在数据查找方面具有绝对性能优势,特别是对于大规模数据Array.find()仅适合小规模数据或简单场景- 随着数据量增大,两者的性能差距呈指数级扩大
在实际项目中,开发者应该根据具体场景选择合适的数据结构。对于需要频繁查找的中大型数据集,使用
Map可以显著提升应用性能,提供更好的用户体验。