Linux中Docker k8s介绍以及应用
Kubernetes(这里是主机上设置k8s)
官网: Kubernetes
初识 Kubernetes
-
Kubernetes 简介
-
为什么需要 Kubernetes
-
Kubernetes 能做什么
-
Kubernetes 不是什么?
简介
摘取官网: 概述 | Kubernetes
Kubernetes 这个名字源于希腊语,意为舵手或飞行员。
k8s 这个缩写是因为 k 和 s 之间有八个字符的关系。
Google 在 2014 年开源了 Kubernetes 项目。
Kubernetes 建立在 Google 大规模运行生产工作负载十几年经验的基础上, 结合了社区中最优秀的想法和实践。

Kubernetes 是一个可移植、可扩展的开源平台,用于管理容器化的工作负载和服务,可促进声明式配置和自动化。
Kubernetes 拥有一个庞大且快速增长的生态,其服务、支持和工具的使用范围相当广泛。
从 2014 年第一个版本发布以来,Kuberetes 迅速获得开源社区的追捧,包括 Red Hat、VMware 在内的很多有影响力的公司加入到开发和推广的阵营。
目前 Kubernetes 已经成为发展最快、市场占有率最高的容器编排引攀产品。
为什么需要 k8s
摘取官网: 概述 | Kubernetes
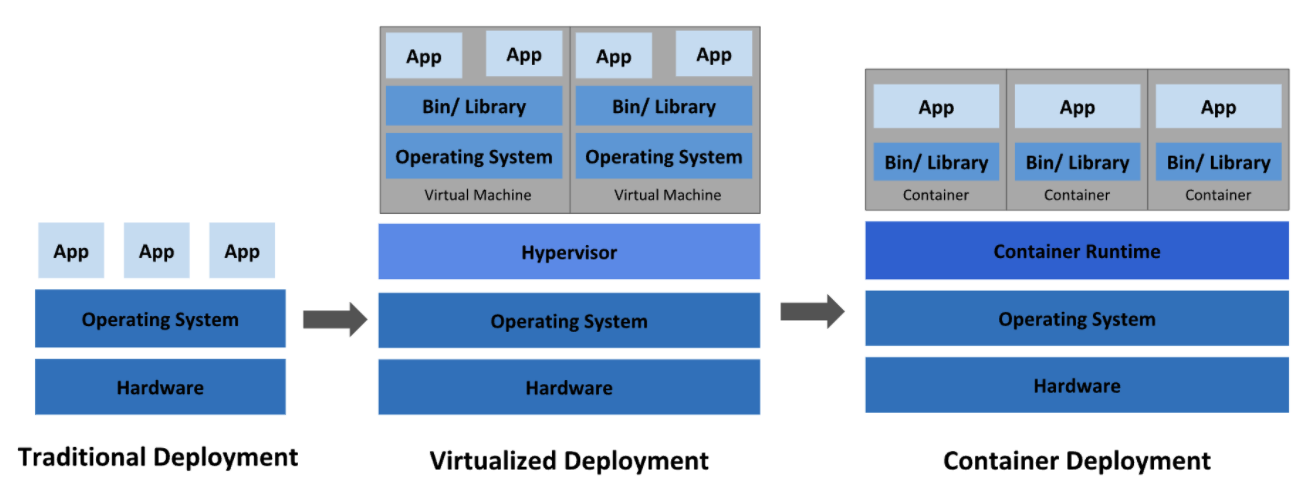
传统部署时代:
早期,各个组织是在物理服务器上运行应用程序。由于无法限制在物理服务器中运行的应用程序资源使用,因此会导致资源分配问题。 例如,如果在同一台物理服务器上运行多个应用程序, 则可能会出现一个应用程序占用大部分资源的情况,而导致其他应用程序的性能下降。 一种解决方案是将每个应用程序都运行在不同的物理服务器上, 但是当某个应用程式资源利用率不高时,剩余资源无法被分配给其他应用程式, 而且维护许多物理服务器的成本很高。
虚拟化部署时代:
因此,虚拟化技术被引入了。虚拟化技术允许在单个物理服务器的 CPU 上运行多台虚拟机(VM)。 虚拟化能使应用程序在不同 VM 之间被彼此隔离,且能提供一定程度的安全性, 因为一个应用程序的信息不能被另一应用程序随意访问。
虚拟化技术能够更好地利用物理服务器的资源,并且因为可轻松地添加或更新应用程序, 而因此可以具有更高的可扩缩性,以及降低硬件成本等等的好处。 通过虚拟化,可以将一组物理资源呈现为可丢弃的虚拟机集群。
每个 VM 是一台完整的计算机,在虚拟化硬件之上运行所有组件,包括其自己的操作系统。
容器部署时代:
容器类似于 VM,但是更宽松的隔离特性,使容器之间可以共享操作系统(OS)。 因此,容器比起 VM 被认为是更轻量级的。且与 VM 类似,每个容器都具有自己的文件系统、CPU、内存、进程空间等。 由于它们与基础架构分离,因此可以跨云和 OS 发行版本进行移植。容器的出现解决了应用和基础环境异构的问题,让应用可以做到一次构建,多次部署。不可否认容器是打包和运行应用程序的好方式,因此容器方式部署变得流行起来。但随着容器部署流行,仅仅是基于容器的部署仍有一些问题没有解决:
-
生产环境中, 需要管理运行着应用程序的容器,并确保服务不会下线。 例如,如果一个容器发生故障,则需要启动另一个容器。
-
高并发时,需要启动多个应用程序容器为系统提高高可用,并保证多个容器能负载均衡。
-
在维护、升级版本时,需要将运行应用程序容器从新部署,部署时必须对之前应用容器备份,一旦出现错误,需要手动启动之前容器保证系统运行。
如果以上行为交由给系统处理,是不是会更容易一些?那么谁能做到这些?
k8s 能做什么?
摘取官网: 概述 | Kubernetes
这就是 Kubernetes 要来做的事情! Kubernetes 为提供了一个可弹性运行分布式系统的框架。
Kubernetes 会满足的扩展要求、故障转移的应用、提供部署模式等。
Kubernetes 为提供:
-
服务发现和负载均衡
Kubernetes 可以使用 DNS 名称或自己的 IP 地址来暴露容器。 如果进入容器的流量很大, Kubernetes 可以负载均衡并分配网络流量,从而使部署稳定。
-
存储编排
Kubernetes 允许自动挂载选择的存储系统,例如本地存储、公共云提供商等。
-
自动部署和回滚
可以使用 Kubernetes 描述已部署容器的所需状态, 它可以以受控的速率将实际状态更改为期望状态。 例如,可以自动化 Kubernetes 来为的部署创建新容器, 删除现有容器并将它们的所有资源用于新容器。
-
自动完成装箱计算/自动资源调度
为 Kubernetes 提供许多节点组成的集群,在这个集群上运行容器化的任务。 告诉 Kubernetes 每个容器需要多少 CPU 和内存 (RAM)。 Kubernetes 可以将这些容器按实际情况调度到的节点上,以最佳方式利用的资源。
-
自我修复/自愈能力
Kubernetes 将重新启动失败的容器、替换容器、杀死不响应用户定义的运行状况检查的容器, 并且在准备好服务之前不将其通告给客户端。
-
密钥与配置管理
Kubernetes 允许存储和管理敏感信息,例如密码、OAuth 令牌和 ssh 密钥。 可以在不重建容器镜像的情况下部署和更新密钥和应用程序配置,也无需在堆栈配置中暴露密钥。
k8s 不是什么?
Kubernetes 不是传统的、包罗万象的 PaaS(平台即服务)系统。
由于 Kubernetes 是在容器级别运行,而非在硬件级别,它提供了 PaaS 产品共有的一些普遍适用的功能, 例如部署、扩展、负载均衡,允许用户集成他们的日志记录、监控和警报方案。
但是,Kubernetes 不是单体式(monolithic)系统,那些默认解决方案都是可选、可插拔的。 Kubernetes 为构建开发人员平台提供了基础,但是在重要的地方保留了用户选择权,能有更高的灵活性。
Kubernetes:
-
不限制支持的应用程序类型。 Kubernetes 旨在支持极其多种多样的工作负载,包括无状态、有状态和数据处理工作负载。 如果应用程序可以在容器中运行,那么它应该可以在 Kubernetes 上很好地运行。
-
不部署源代码,也不构建的应用程序。 持续集成(CI)、交付和部署(CI/CD)工作流取决于组织的文化和偏好以及技术要求。
-
不提供应用程序级别的服务作为内置服务,例如中间件(例如消息中间件)、 数据处理框架(例如 Spark)、数据库(例如 MySQL)、缓存、集群存储系统 (例如 Ceph)。这样的组件可以在 Kubernetes 上运行,并且/或者可以由运行在 Kubernetes 上的应用程序通过可移植机制(例如开放服务代理)来访问。
-
不是日志记录、监视或警报的解决方案。 它集成了一些功能作为概念证明,并提供了收集和导出指标的机制。
-
不提供也不要求配置用的语言、系统(例如 jsonnet),它提供了声明性 API, 该声明性 API 可以由任意形式的声明性规范所构成。
-
不提供也不采用任何全面的机器配置、维护、管理或自我修复系统。
-
此外,Kubernetes 不仅仅是一个编排系统,实际上它消除了编排的需要。 编排的技术定义是执行已定义的工作流程:首先执行 A,然后执行 B,再执行 C。 而 Kubernetes 包含了一组独立可组合的控制过程,可以连续地将当前状态驱动到所提供的预期状态。 不需要在乎如何从 A 移动到 C,也不需要集中控制,这使得系统更易于使用且功能更强大、 系统更健壮,更为弹性和可扩展。
组件&架构
-
集群组件
-
核心概念
-
集群安装
集群组件
-
集群 cluster : 将同一个软件服务多个节点组织到一起共同为系统提供服务过程称之为该软件的集群。redis 集群、es集群、mongo 等。
-
k8s 集群:
-
多个节点: 3 个节点
-
-
master 节点/control plane 控制节点
-
-
-
work node: 工作节点(pod 容器:应用程序容器)
-
-
当部署完 Kubernetes,便拥有了一个完整的集群。
一组工作机器,称为节点, 会运行容器化应用程序。
每个集群至少有一个工作节点。工作节点会托管 Pod,而 Pod 就是作为应用负载的组件。
控制平面管理集群中的工作节点和 Pod。
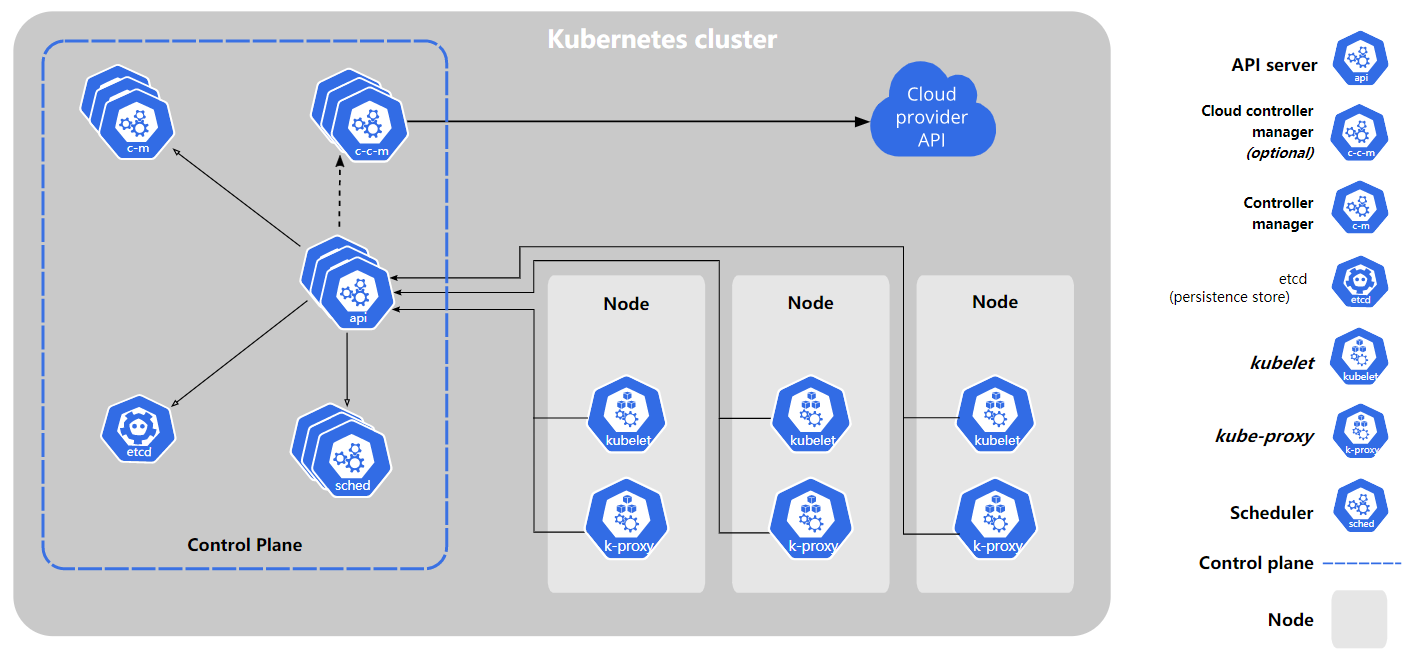
控制平面组件(Control Plane Components)
控制平面组件会为集群做出全局决策,比如资源的调度。 以及检测和响应集群事件,例如当不满足部署的 replicas 字段时, 要启动新的 pod)。
控制平面组件可以在集群中的任何节点上运行。 然而,为了简单起见,设置脚本通常会在同一个计算机上启动所有控制平面组件, 并且不会在此计算机上运行用户容器。
-
kube-apiserver
API server是 Kubernetes 控制平面的组件,
该组件负责公开了 Kubernetes API,负责处理接受请求的工作。 API server 是 Kubernetes 控制平面的前端。Kubernetes API 服务器的主要实现是 kube-apiserver。kube-apiserver设计上考虑了水平扩缩,也就是说,它可通过部署多个实例来进行扩缩。 可以运行kube-apiserver的多个实例,并在这些实例之间平衡流量。 -
etcd
一致且高度可用的键值存储,用作 Kubernetes 的所有集群数据的后台数据库。 -
kube-scheduler
kube-scheduler是控制平面的组件, 负责监视新创建的、未指定运行节点 node 的 Pods, 并选择节点来让 Pod 在上面运行。调度决策考虑的因素包括单个 Pod 及 Pods 集合的资源需求、软硬件及策略约束、 亲和性及反亲和性规范、数据位置、工作负载间的干扰及最后时限。 -
kube-controller-manager
kube-controller-manager 是控制平面的组件, 负责运行控制器进程。从逻辑上讲, 每个控制器都是一个单独的进程, 但是为了降低复杂性,它们都被编译到同一个可执行文件,并在同一个进程中运行。
这些控制器包括:
-
节点控制器(Node Controller):负责在节点出现故障时进行通知和响应
-
任务控制器(Job Controller):监测代表一次性任务的 Job 对象,然后创建 Pods 来运行这些任务直至完成
-
端点分片控制器(EndpointSlice controller):填充端点分片(EndpointSlice)对象(以提供 Service 和 Pod 之间的链接)。
-
服务账号控制器(ServiceAccount controller):为新的命名空间创建默认的服务账号(ServiceAccount)。
-
-
cloud-controller-manager (optional 可选)
一个 Kubernetes 控制平面组件, 嵌入了特定于云平台的控制逻辑。 云控制器管理器(Cloud Controller Manager)允许将的集群连接到云提供商的 API 之上, 并将与该云平台交互的组件同与的集群交互的组件分离开来。
cloud-controller-manager仅运行特定于云平台的控制器。 因此如果在自己的环境中运行 Kubernetes,或者在本地计算机中运行学习环境, 所部署的集群不需要有云控制器管理器。与kube-controller-manager类似,cloud-controller-manager将若干逻辑上独立的控制回路组合到同一个可执行文件中, 供以同一进程的方式运行。 可以对其执行水平扩容(运行不止一个副本)以提升性能或者增强容错能力。下面的控制器都包含对云平台驱动的依赖:
-
节点控制器(Node Controller):用于在节点终止响应后检查云提供商以确定节点是否已被删除
-
路由控制器(Route Controller):用于在底层云基础架构中设置路由
-
服务控制器(Service Controller):用于创建、更新和删除云提供商负载均衡器
-
Node 组件
节点组件会在每个节点上运行,负责维护运行的 Pod 并提供 Kubernetes 运行环境。
-
kubelet
kubelet 会在集群中每个节点(node)上运行。 它保证容器(containers)都运行在 Pods 中。
kubelet 接收一组通过各类机制提供给它的 PodSpecs, 确保这些 PodSpecs 中描述的容器处于运行状态且健康。 kubelet 不会管理不是由 Kubernetes 创建的容器。
-
kube-proxy
kube-proxy是集群中每个节点(node)上所运行的网络代理, 实现 Kubernetes 服务(Service)概念的一部分。
kube-proxy 维护节点上的一些网络规则, 这些网络规则会允许从集群内部或外部的网络会话与 Pod 进行网络通信。
如果操作系统提供了可用的数据包过滤层,则 kube-proxy 会通过它来实现网络规则。 否则,kube-proxy 仅做流量转发。
-
容器运行时(Container Runtime)
容器运行环境是负责运行容器的软件。
Kubernetes 支持许多容器运行环境,例如 containerd、 CRI-0、Docker 以及 Kubernetes CRI 的其他任何实现。
插件 (Addons)
-
DNS
尽管其他插件都并非严格意义上的必需组件,但几乎所有 Kubernetes 集群都应该有集群 DNS因为很多示例都需要 DNS 服务。
-
Web 界面(仪表盘)
Dashboard 是 Kubernetes 集群的通用的、基于 Web 的用户界面。 它使用户可以管理集群中运行的应用程序以及集群本身, 并进行故障排除。
-
容器资源监控
容器资源监控将关于容器的一些常见的时间序列度量值保存到一个集中的数据库中, 并提供浏览这些数据的界面。
-
集群层面日志
集群层面日志机制负责将容器的日志数据保存到一个集中的日志存储中, 这种集中日志存储提供搜索和浏览接口。
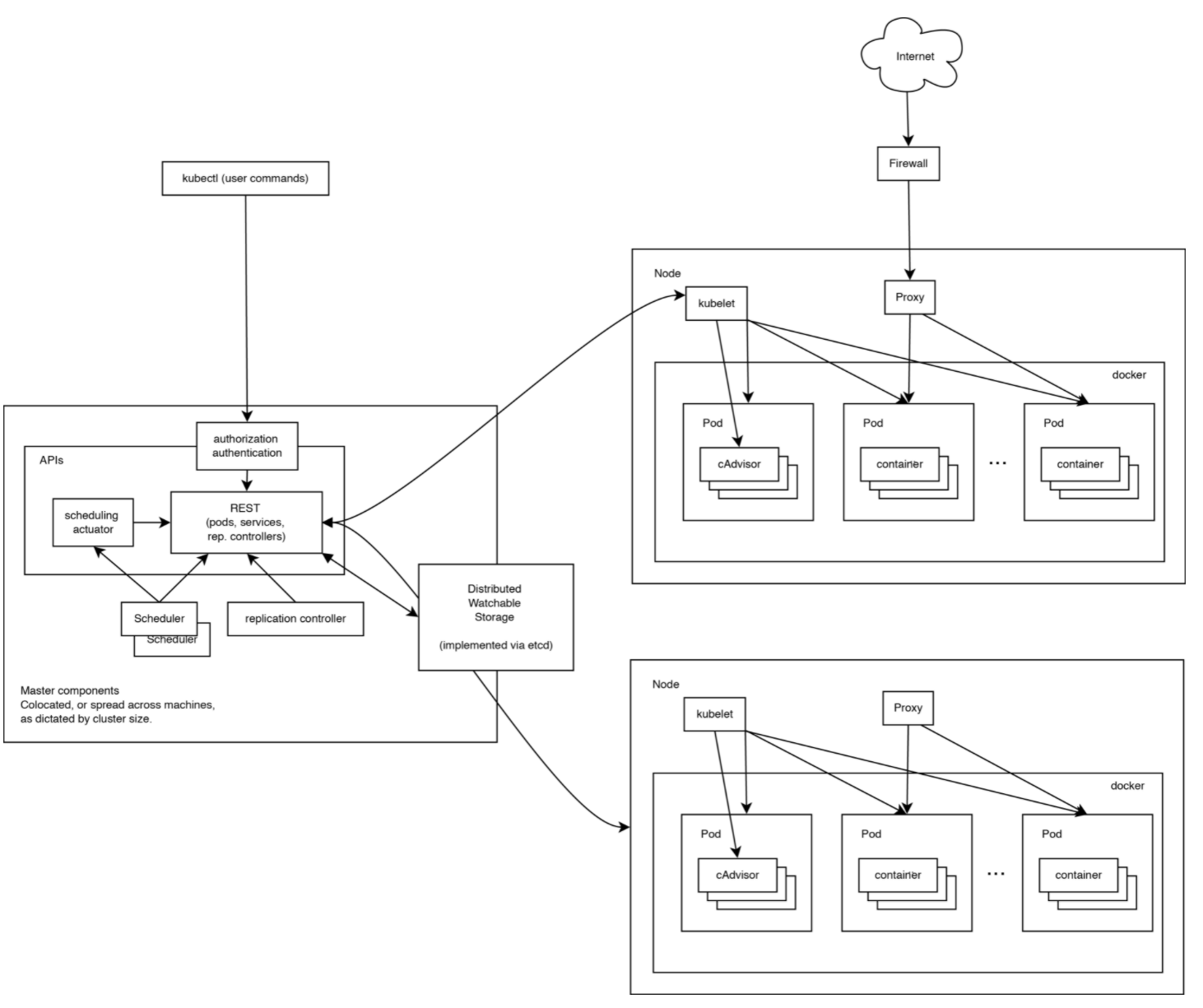
集群架构详细
总结
Kubernetes 集群由多个节点组成,节点分为两类:
一类是属于管理平面的主节点/控制节点(Master Node);一类是属于运行平面的工作节点(Worker Node)。
显然,复杂的工作肯定都交给控制节点去做了,工作节点负责提供稳定的操作接口和能力抽象即可。
集群搭建[重点]
-
minikube 只是一个 K8S 集群模拟器,只有一个节点的集群,只为测试用,master 和 worker 都在一起。
-
裸机安装 ==本次== 至少需要两台机器(主节点、工作节点个一台),需要自己安装 Kubernetes 组件,配置会稍微麻烦点。 缺点:配置麻烦,缺少生态支持,例如负载均衡器、云存储。
-
直接用云平台 Kubernetes 可视化搭建,只需简单几步就可以创建好一个集群。 优点:安装简单,生态齐全,负载均衡器、存储等都给配套好,简单操作就搞定
-
k3s ==课后作业==
安装简单,脚本自动完成。
优点:轻量级,配置要求低,安装简单,生态齐全。
裸机安装
环境准备
-
节点数量: 3 台虚拟机 centos7
-
硬件配置: 2G或更多的RAM,2个CPU或更多的CPU,硬盘至少10G 以上
-
网络要求: 多个节点之间网络互通,每个节点能访问外网
集群规划
-
k8s-node1:192.168.66.146
-
k8s-node2:192.168.66.152
-
k8s-node3:192.168.66.153
设置主机名
$ hostnamectl set-hostname k8s-node1
$ hostnamectl set-hostname k8s-node2
$ hostnamectl set-hostname k8s-node3同步 hosts 文件
如果 DNS 不支持主机名称解析,还需要在每台机器的
/etc/hosts文件中添加主机名和 IP 的对应关系:
cat >> /etc/hosts <<EOF
192.168.107.169 k8s-node1
192.168.107.170 k8s-node2
192.168.107.171 k8s-node3
EOF关闭防火墙
systemctl stop firewalld && systemctl disable firewalld关闭 SELINUX
注意: ARM 架构请勿执行,执行会出现 ip 无法获取问题!
setenforce 0 && sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config关闭 swap 分区(运行内存)
swapoff -a && sed -ri 's/.*swap.*/#&/' /etc/fstab同步时间
$ yum install ntpdate -y
$ ntpdate time.windows.com安装 containerd
# 安装 yum-config-manager 相关依赖
$ yum install -y yum-utils device-mapper-persistent-data lvm2# 添加 containerd yum 源
$ yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo# 安装 containerd
$ yum install -y containerd.io cri-toolsContainerd 是一个行业标准的容器运行时,它最初由Docker公司开发并捐赠给云原生计算基金会(CNCF)。作为一个核心容器运行时,containerd负责管理容器的生命周期,包括镜像传输与存储、容器执行、网络配置等。它的设计目标是提供一个稳定、高效且可嵌入的容器运行时环境。
与 Docker 的区别
尽管 containerd 和 Docker 都用于支持容器化应用,它们在功能和使用场景上有所不同:
架构层次:
Docker 是一个完整的容器化平台,包含了从构建镜像到运行容器的一系列工具,如Docker CLI、Docker Daemon、docker-compose等。
Containerd 则是一个更底层的组件,专注于容器的运行时管理。它是Docker引擎的一部分,但也可以独立于Docker使用。
功能范围:
Docker提供了丰富的功能集合,包括但不限于镜像构建、容器编排、网络配置等。
Containerd则更加轻量级,仅关注于容器的生命周期管理,比如启动、停止容器,以及镜像的管理和分发。
与 Kubernetes 的关系
Kubernetes本身并不直接处理容器的创建和管理工作,而是通过容器运行时接口(CRI, Container Runtime Interface)与底层容器运行时交互。
这意味着Kubernetes可以支持多种容器运行时,包括containerd、CRI-O以及经典的Docker(通过dockershim,但在较新版本中已不再推荐使用)。
containerd 作为 Kubernetes 容器运行时:
自Kubernetes 1.20版本后,官方推荐使用containerd或CRI-O作为容器运行时,因为它们更符合Kubernetes的设计理念,提供了更高效的容器管理能力。
使用containerd可以减少系统的资源消耗,提高性能,同时保持与Kubernetes的良好兼容性。
过渡自 Docker 到 containerd:
对于已经使用Docker作为容器运行时的用户,迁移到containerd相对简单,因为containerd本身就是Docker引擎的一个组成部分。
此外,许多现代Kubernetes发行版默认集成了对containerd的支持。
# 配置 containerd
$ cat > /etc/containerd/config.toml <<EOF
[plugins.linux]
shim_debug = true
[plugins.cri.registry.mirrors."docker.io"]
endpoint = ["https://docker.m.daocloud.io"]
[plugins.cri]
sandbox_image = "registry.aliyuncs.com/google_containers/pause:3.9"
EOF
[plugins.linux] shim_debug = true启用 containerd 的 Shim 调试日志输出。
[plugins.cri.registry.mirrors."docker.io"] endpoint = ["https://docker.m.daocloud.io"]为 Docker Hub (
docker.io) 设置镜像加速地址。
[plugins.cri] sandbox_image = "registry.aliyuncs.com/google_containers/pause:3.9"指定 Kubernetes Pod 的沙箱容器(pause 容器)镜像地址。
Kubernetes 每个 Pod 启动时都需要一个 pause 容器作为基础容器。
# 启动 containerd(docker里面一个底层插件) 服务 并 开机配置自启动
$ systemctl enable containerd && systemctl restart containerd && systemctl status containerd # 配置 containerd 配置
$ cat > /etc/modules-load.d/containerd.conf <<EOF
overlay
br_netfilter
EOF这两个模块是运行容器(尤其是使用 containerd 或 Docker)时非常关键的内核支持模块:
overlay
-
OverlayFS 是一种联合文件系统(Union File System),允许将多个目录合并为一个虚拟文件系统。
-
容器镜像通常使用这种分层结构来构建和挂载容器文件系统。
-
containerd 和 Docker 默认使用
overlay2存储驱动,依赖此模块。
br_netfilter
-
启用网桥上的 netfilter(即 iptables)功能。
-
Kubernetes 和容器网络(如 CNI 插件)需要通过 iptables 来管理 Pod 和容器间的网络通信。
-
如果不加载这个模块,可能会导致容器无法访问外部网络或服务间通信异常。
拉取(下载)镜像
使用 ctr images pull 命令可以从指定的仓库拉取镜像。
ctr images pull docker.m.daocloud.io/library/openjdk:17-jdk-slim如果想从阿里云这样的私有仓库拉取镜像,需要指定完整的镜像地址,比如:
ctr images pull registry.aliyuncs.com/google_containers/pause:3.9列出本地镜像
要查看当前 containerd 中存储的所有镜像,可以使用:
ctr images list删除镜像
如果需要删除某个不再使用的镜像,可以使用 ctr images rm 命令,并提供要删除的镜像名称或ID
ctr images rm <image_name_or_id>创建并启动容器
创建并启动一个容器可以使用 ctr container create 和 ctr task start 命令。
ctr container create <image_name> <container_name>然后,启动这个容器:
ctr task start <container_name>这里 <image_name> 是想要运行的镜像名,而 <container_name> 是给这个容器起的名字。
# 配置 k8s 网络配置
$ cat > /etc/sysctl.d/k8s.conf <<EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
EOF| 参数 | 含义 |
|---|---|
net.bridge.bridge-nf-call-ip6tables = 1 | 桥接流量走 ip6tables |
net.bridge.bridge-nf-call-iptables = 1 | 桥接流量走 iptables |
net.ipv4.ip_forward = 1 | 启用 IPv4 转发 |
# 加载 overlay br_netfilter 模块
$ modprobe overlay
$ modprobe br_netfilter# 查看当前配置是否生效
$ sysctl -p /etc/sysctl.d/k8s.conf添加源
-
查看源
$ yum repolist-
添加源 x86
$ cat <<EOF > kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF所有的源文件都要移动到这里
$ mv kubernetes.repo /etc/yum.repos.d/-
添加源 ARM(电脑不是x86的)
$ cat << EOF > kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-aarch64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF$ mv kubernetes.repo /etc/yum.repos.d/安装 k8s
# 安装最新版本
$ yum install -y kubelet kubeadm kubectl注释:
kubelet 接收
kubeadm 搭建
kubectl 执行# 启动 kubelet
$ sudo systemctl enable kubelet && sudo systemctl start kubelet && sudo systemctl status kubelet执行的命令:
yum install -y kubelet kubeadm kubectlkubelet 是 Kubernetes 节点(Node)上的一个“代理”服务,它负责管理该节点上的容器生命周期,并与 Kubernetes 控制平面通信。
-
接收来自 API Server 的指令(比如创建 Pod)
-
确保容器处于期望状态(正常运行、重启失败容器等)
-
监控本机资源使用情况并上报给 API Server
-
执行健康检查(liveness/readiness probes)
kubeadm 是一个官方提供的工具,用于快速搭建 Kubernetes 集群。
-
初始化主控制面节点(
kubeadm init) -
将工作节点加入集群(
kubeadm join) -
升级现有集群版本
-
管理集群证书、配置等
kubectl 是 Kubernetes 的命令行客户端,用来与 Kubernetes 集群进行交互。
-
查看集群状态(Pod、Service、Deployment 等)
-
创建/删除/更新资源
-
进入容器终端(
exec)、查看日志(logs)等调试操作
| 工具名 | 角色 | 用途说明 | 是否安装 |
|---|---|---|---|
kubelet | 节点代理程序 | 管理容器生命周期,与 API Server 通信 | 每个节点都必须安装 |
kubeadm | 集群部署工具 | 初始化集群、加入节点、升级集群 | 主控节点必须安装 |
kubectl | 命令行客户端 | 操作和管理 Kubernetes 集群 | 每个节点都必须安装 |
注意:
kubelet默认会尝试连接 Kubernetes 控制平面,所以在没有完成集群初始化之前它会报错,这是正常的。
👨💻 开发者用
kubectl发号施令,🧰 管理员用
kubeadm搭建集群,🤖 每个节点用
kubelet执行任务。
初始化集群
-
注意: 初始化 k8s 集群仅仅需要再在 master 节点进行集群初始化!
-- 注意这里是在管理机上运行
$ kubeadm init \
--apiserver-advertise-address=192.168.107.169 \ 注意这里需要你的管理机ip
--pod-network-cidr=10.244.0.0/16 \
--image-repository registry.aliyuncs.com/google_containers \
--cri-socket=unix:///var/run/containerd/containerd.sockkubeadm init
作用:初始化一个新的 Kubernetes 控制平面节点(Control Plane Node)。
-
创建静态 Pod 的 YAML 文件(如 kube-apiserver、kube-controller-manager 等)
-
拉取所需镜像并启动核心组件
-
输出后续加入集群的命令(
kubeadm join)
--apiserver-advertise-address=192.168.66.146
作用:指定 API Server 监听的 IP 地址。
-
这个地址会被其他节点用来连接到主控节点。
-
如果的服务器有多个网卡或 IP,必须明确指定监听哪个 IP
--pod-network-cidr=10.244.0.0/16
作用:指定 Kubernetes 集群中 Pod 使用的网络地址段。
-
所有 Pod 将在这个 CIDR 范围内分配 IP。
-
必须与后面选择的 CNI 网络插件兼容(例如 Flannel 默认使用
10.244.0.0/16)
--image-repository registry.aliyuncs.com/google_containers
作用:指定拉取 Kubernetes 组件镜像的仓库地址。
-
不指定时会从
k8s.gcr.io拉取镜像,但国内访问困难。
--cri-socket=unix:///var/run/containerd/containerd.sock
作用:指定使用的容器运行时接口(CRI)套接字路径。
-
Kubernetes 通过这个 socket 与底层容器运行时通信(如 containerd 或 Docker)。
-
如果使用的是
containerd,它的默认 socket 是/var/run/containerd/containerd.sock。
运行过后会出现下面图片出现的话,全部复制,在当前管理机上运行

# 添加新节点
$ kubeadm token create --print-join-command --ttl=0| 参数 | 作用 |
|---|---|
kubeadm token create | 创建一个用于节点加入的新 token |
--print-join-command | 输出完整的 kubeadm join 命令 |
--ttl=0 | 设置 token 永不过期 |

清除集群(这里是出现错误时使用)
在运行过 kubeadm init 的主控节点上执行以下命令:
kubeadm reset这个命令会做以下事情:
-
停止并清理 kubelet 配置
-
删除旧的集群证书和配置文件
-
清理 iptables 规则
-
清理 CNI 网络配置
-
提示可以重新运行
kubeadm init来重新初始化
注意:
kubeadm reset不会自动卸载 Kubernetes 组件(如 kubelet、kubeadm、kubectl)或删除镜像。
如果遇到一些警告或错误导致无法重置,可以加上 --force 参数:
kubeadm reset --force停止 kubelet 并重置:(这里是出现错误时使用)
systemctl stop kubelet
rm -rf /etc/kubernetes/
rm -rf /var/lib/kubelet/
systemctl daemon-reexec
systemctl daemon-reload
systemctl start kubelet这将彻底清除所有 Kubernetes 的运行状态和配置。
配置集群网络
在使用 kubeadm 初始化 Kubernetes 集群并让工作节点(worker nodes)加入之前,通常需要先配置集群网络插件。
这是因为 Kubernetes 的 Pod 网络对于集群内部的通信至关重要,尤其是当工作节点加入后,它们需要能够正确地与主节点和其他节点上的 Pod 进行通信。
为什么需要先配置集群网络?
-
Pod 间通信:Kubernetes 中的每个 Pod 都需要一个唯一的 IP 地址,并且这些 Pod 能够跨节点进行通信。这依赖于 CNI(容器网络接口)插件来实现。
-
服务发现和负载均衡:许多 Kubernetes 服务(如 DNS、Ingress 控制器等)依赖于正确的网络配置来确保它们可以被其他组件和服务发现及访问。
-
kube-proxy:虽然
kube-proxy是 Kubernetes 自带的一个组件,用于管理 Service 的网络规则,但它也需要一个有效的 Pod 网络来正常工作。 -
Kubernetes 集群必须安装 CNI 网络插件 才能让 Pod 相互通信
执行顺序
-
初始化主节点:使用
kubeadm init命令来初始化的 Kubernetes 主节点。 -
配置集群网络:在主节点上安装并配置一个 CNI 网络插件(例如 Flannel、Calico)。
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml -
加入工作节点:一旦网络插件成功部署并且运行正常(可以通过检查 Pod 状态来确认),可以安全地将工作节点加入到集群中,使用由
kubeadm init输出提供的kubeadm join命令。
创建配置: kube-flannel.yml , 执行 kubectl apply -f kube-flannel.yml
-
注意: 只在主节点执行即可!
[root@k8s-node1 data]# kubectl apply -f kube-flannel.yml Unable to connect to the server: dial tcp: lookup localhost on 192.168.66.2:53: no such host
如果遇到这个错误,请配置
kubectl的访问权限
mkdir /testtouch kube-flannel.yml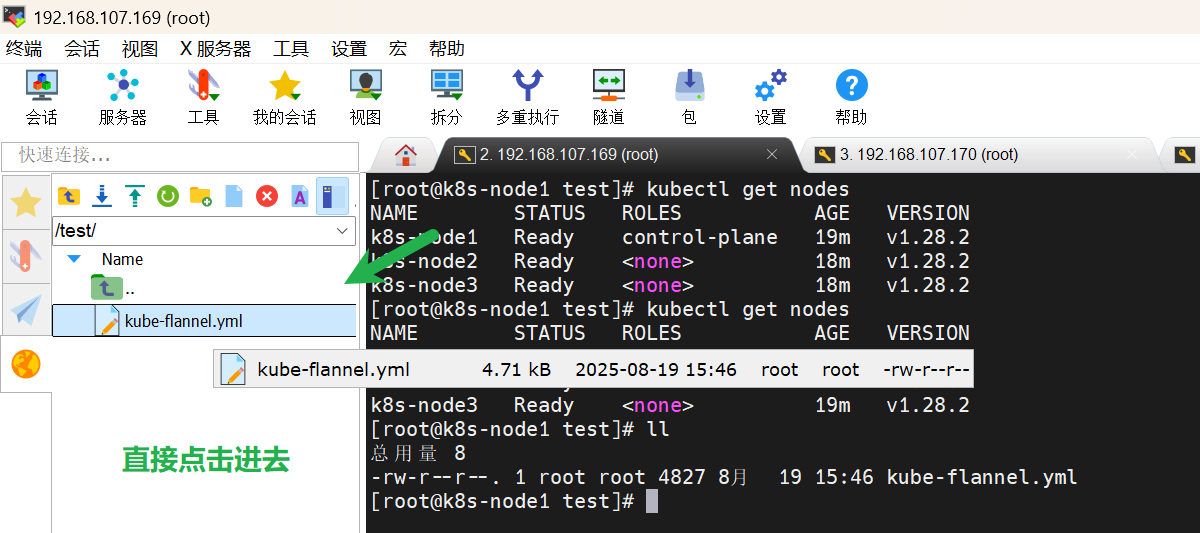
---
kind: Namespace
apiVersion: v1
metadata:name: kube-flannellabels:pod-security.kubernetes.io/enforce: privileged
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:name: flannel
rules:
- apiGroups:- ""resources:- podsverbs:- get
- apiGroups:- ""resources:- nodesverbs:- get- list- watch
- apiGroups:- ""resources:- nodes/statusverbs:- patch
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:name: flannel
roleRef:apiGroup: rbac.authorization.k8s.iokind: ClusterRolename: flannel
subjects:
- kind: ServiceAccountname: flannelnamespace: kube-flannel
---
apiVersion: v1
kind: ServiceAccount
metadata:name: flannelnamespace: kube-flannel
---
kind: ConfigMap
apiVersion: v1
metadata:name: kube-flannel-cfgnamespace: kube-flannellabels:tier: nodeapp: flannel
data:cni-conf.json: |{"name": "cbr0","cniVersion": "0.3.1","plugins": [{"type": "flannel","delegate": {"hairpinMode": true,"isDefaultGateway": true}},{"type": "portmap","capabilities": {"portMappings": true}}]}net-conf.json: |{"Network": "10.244.0.0/16","Backend": {"Type": "vxlan"}}
---
apiVersion: apps/v1
kind: DaemonSet
metadata:name: kube-flannel-dsnamespace: kube-flannellabels:tier: nodeapp: flannel
spec:selector:matchLabels:app: flanneltemplate:metadata:labels:tier: nodeapp: flannelspec:affinity:nodeAffinity:requiredDuringSchedulingIgnoredDuringExecution:nodeSelectorTerms:- matchExpressions:- key: kubernetes.io/osoperator: Invalues:- linuxhostNetwork: truepriorityClassName: system-node-criticaltolerations:- operator: Existseffect: NoScheduleserviceAccountName: flannelinitContainers:- name: install-cni-plugin#image: flannelcni/flannel-cni-plugin:v1.1.0 for ppc64le and mips64le (dockerhub limitations may apply)image: docker.m.daocloud.io/rancher/mirrored-flannelcni-flannel-cni-plugin:v1.1.0command:- cpargs:- -f- /flannel- /opt/cni/bin/flannelvolumeMounts:- name: cni-pluginmountPath: /opt/cni/bin- name: install-cni#image: flannelcni/flannel:v0.20.2 for ppc64le and mips64le (dockerhub limitations may apply)image: docker.m.daocloud.io/rancher/mirrored-flannelcni-flannel:v0.20.2command:- cpargs:- -f- /etc/kube-flannel/cni-conf.json- /etc/cni/net.d/10-flannel.conflistvolumeMounts:- name: cnimountPath: /etc/cni/net.d- name: flannel-cfgmountPath: /etc/kube-flannel/containers:- name: kube-flannel#image: flannelcni/flannel:v0.20.2 for ppc64le and mips64le (dockerhub limitations may apply)image: docker.m.daocloud.io/rancher/mirrored-flannelcni-flannel:v0.20.2command:- /opt/bin/flanneldargs:- --ip-masq- --kube-subnet-mgrresources:requests:cpu: "100m"memory: "50Mi"limits:cpu: "100m"memory: "50Mi"securityContext:privileged: falsecapabilities:add: ["NET_ADMIN", "NET_RAW"]env:- name: POD_NAMEvalueFrom:fieldRef:fieldPath: metadata.name- name: POD_NAMESPACEvalueFrom:fieldRef:fieldPath: metadata.namespace- name: EVENT_QUEUE_DEPTHvalue: "5000"volumeMounts:- name: runmountPath: /run/flannel- name: flannel-cfgmountPath: /etc/kube-flannel/- name: xtables-lockmountPath: /run/xtables.lockvolumes:- name: runhostPath:path: /run/flannel- name: cni-pluginhostPath:path: /opt/cni/bin- name: cnihostPath:path: /etc/cni/net.d- name: flannel-cfgconfigMap:name: kube-flannel-cfg- name: xtables-lockhostPath:path: /run/xtables.locktype: FileOrCreate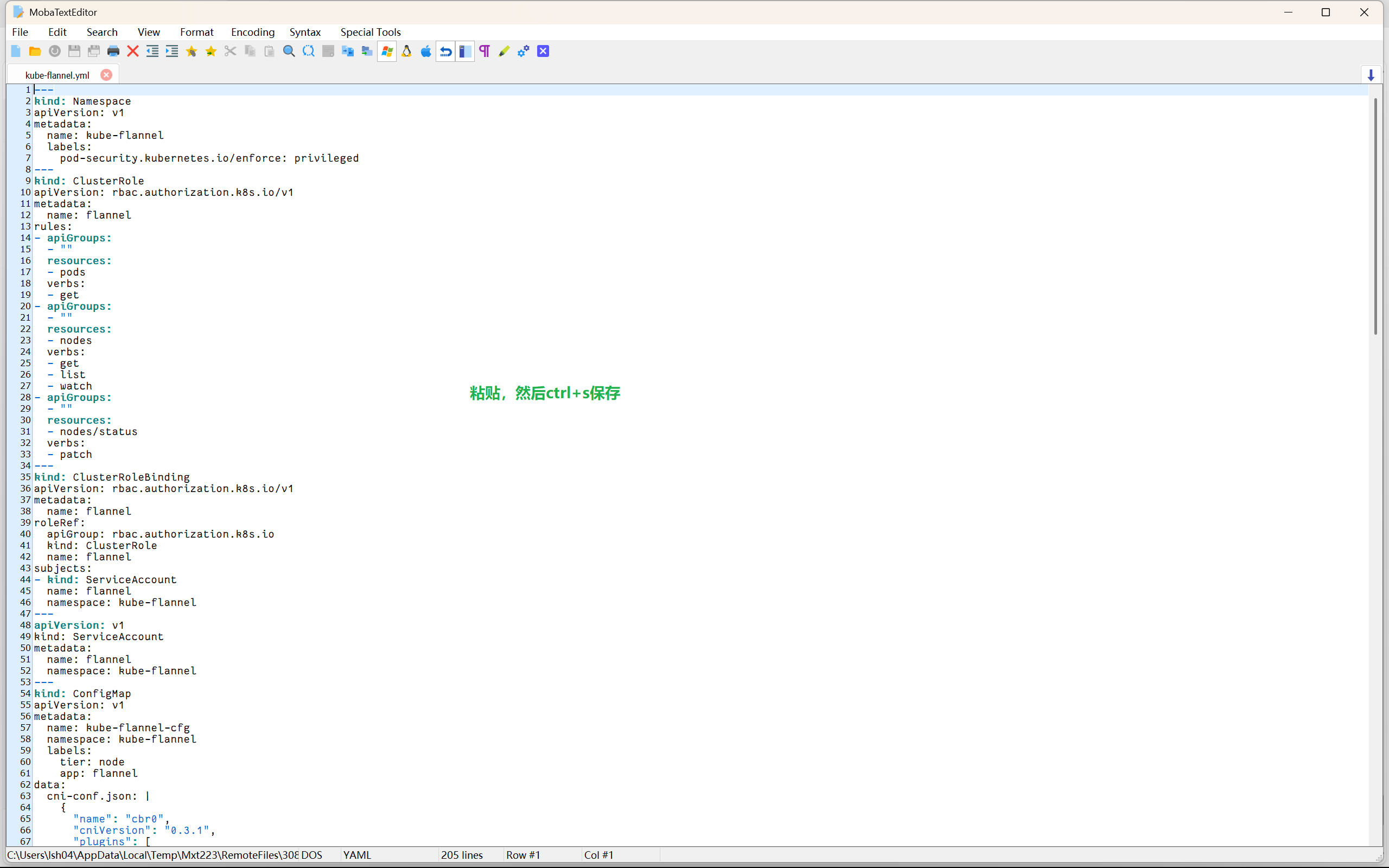
查看集群状态
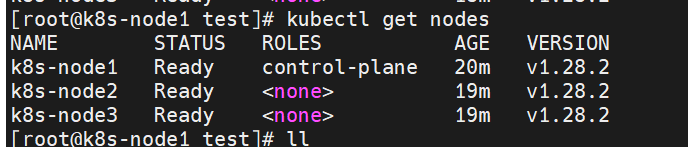
kubectl get nodes
为什么工作节点显示
NotReady?这是正常现象,特别是在刚刚加入 worker 节点之后。因为:
Kubernetes 需要一些时间来初始化节点上的组件(如 kubelet、容器运行时)。
Flannel 网络插件还未完全部署完成或正在配置中,导致节点无法通信。
一旦 Flannel 插件部署完成并正确配置了网络,这些节点应该会自动变为
Ready状态。
需要等几分钟
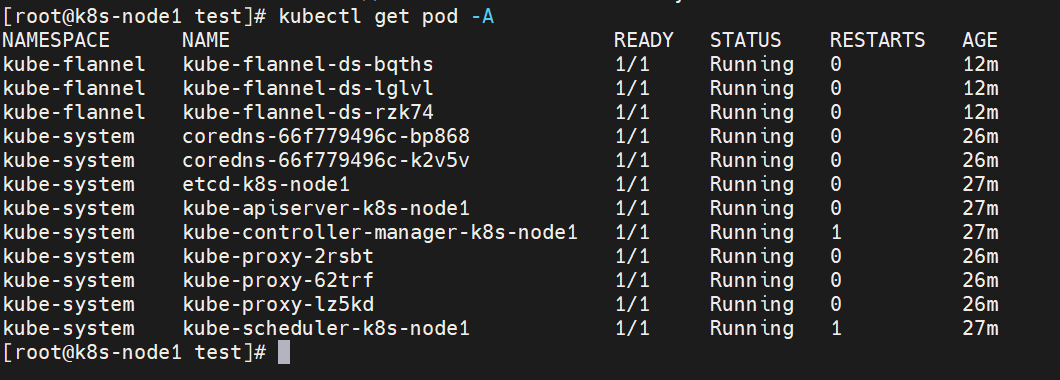
查看集群系统 pod 运行情况,下面所有 pod 状态为 Running 代表集群可用
kubectl get pod -A