论文阅读:Prompt Optimization in Large Language Models
地址:Prompt Optimization in Large Language Models
摘要
提示优化是提升大语言模型(Large Language Models, LLMs)下游任务性能的关键任务。本文中,提示被定义为从词汇表中选取的 n 元语法(n-grams)序列。因此,研究目标是筛选出在特定性能指标下最优的提示。提示优化可视为一个组合优化问题,其可能的提示数量(即组合搜索空间)等于词汇表大小(所有可能的 n 元语法数量)的提示长度次方。由于穷举搜索不切实际,亟需一种高效的搜索策略。本文提出一种贝叶斯优化(Bayesian Optimization)方法,该方法在组合搜索空间的连续松弛空间上执行。贝叶斯优化凭借其样本效率、模块化结构与灵活性,已成为黑盒优化的主流方法。研究采用 BoTorch 库(基于 PyTorch 构建的贝叶斯优化研究工具库)实现该方法。具体而言,本文聚焦于硬提示微调(Hard Prompt Tuning, HPT) :该方法直接搜索可添加到文本输入中的最优提示,无需访问大语言模型的内部参数,仅将其作为黑盒使用(例如作为 “模型即服务”(Model as a Service, MaaS)提供的 GPT-4)。尽管研究尚处于初步阶段且基于 “基础版” 贝叶斯优化算法,但以 RoBERTa 作为实验用大语言模型,在 6 个基准数据集上的实验结果表明:与其他最先进的黑盒提示优化方法相比,本文方法表现良好,且能够分析搜索空间大小、准确率与实际运行时间(wall-clock time)之间的权衡关系。
概述
1. 研究背景与动机
- 提示工程的痛点:现有大语言模型(如 GPT-3、ChatGPT)虽具备强指令跟随能力,但性能高度依赖提示质量;手动设计有效提示需大量试错,成本高且耗时,尤其在黑盒 LLM(仅能获取模型输出,无法访问梯度或参数) 场景下更具挑战性。
- 硬提示 vs 软提示:软提示(Soft Prompt Tuning)依赖连续值语言嵌入与梯度优化,仅适用于特定任务和模型;硬提示(Hard Prompt Tuning)基于离散 tokens,具备可移植性(跨 LLM 复用)和黑盒兼容性(适配 MaaS 场景,规避数据泄露与模型安全风险),因此成为本文研究焦点。
- 核心问题:提示优化本质是组合优化问题,搜索空间为∣V∣L(V为词汇表,L为提示长度),随词汇表与提示长度增长呈指数膨胀,传统方法难以高效搜索。
2. 核心创新与方法
- 核心思路:通过 “组合空间连续松弛” 将离散提示搜索转化为连续空间优化,结合贝叶斯优化实现高效搜索。
- 关键创新点:
- 验证了贝叶斯优化在黑盒 LLM 提示优化中的样本效率(无需大量查询模型即可找到较优提示);
- 相比其他黑盒方法,显著降低实际运行时间;
- 证明 “朴素连续松弛”(无需复杂嵌入)的可行性;
- 表明基于 BoTorch 的 “基础版” 贝叶斯优化算法已足够有效,无需针对组合 / 高维场景设计专用算法。
- 实验设计:
- 模型:RoBERTa-large(冻结参数,作为黑盒使用);
- 数据集:6 个 GLUE 基准数据集(MNLI、QQP、SST-2、MRPC、QNLI、RTE),覆盖自然语言推理、语义等价判断、情感分析等任务;
- 基线方法:ManualPrompt(手动提示)、BBT(黑盒微调)、RLPrompt(强化学习提示)、BDPL(黑盒离散提示学习)。
3. 实验结果
- 性能对比:本文提出的 “PrompT-BO” 方法在多数任务上(如 QQP、SST-2、MRPC)优于 4 种基线方法的平均性能(Avg B.B.),仅在 MNLI(词汇表最大)上表现较差(推测因 “朴素连续松弛” 对大词汇表适配不足);
- 效率优势:在相同硬件环境(2 vCPUs、13GB 内存、Tesla T4 GPU)下,PrompT-BO 运行时间显著短于 BDPL(如 MRPC 任务:379.02 秒 vs 571.75 秒;SST-2 任务:264.23 秒 vs 384.84 秒);
- 其他发现:提示长度并非越长越好(MRPC 任务中,25 长度提示测试最优分 79.76,50/75 长度反而下降),过长提示易过拟合且可移植性降低。
4. 结论
贝叶斯优化结合 “组合空间连续松弛” 可有效解决 LLM 硬提示优化的组合爆炸问题,是黑盒 LLM 提示优化的高效工具;其样本效率与时间优势源于贝叶斯优化的 “探索 - 利用平衡” 策略(基于高斯过程的概率模型与 UCB 采集函数)。
一、研究动机
1. 硬提示优化的 “组合爆炸” 问题
硬提示本质是从词汇表V中选取 n 元语法组成的长度为L的序列,其搜索空间为∣V∣L(∣V∣为词汇表大小),随∣V∣和L增长呈指数级膨胀(如 MNLI 任务中∣V∣=117056、L=10,搜索空间 cardinality 达≈4.8×1050),穷举搜索完全不切实际,传统启发式搜索方法也难以高效遍历空间。
2. 黑盒 LLM 的适配性问题
当前大量 LLM 以 “模型即服务(MaaS)” 形式提供(如 GPT-4),用户仅能获取模型输出,无法访问梯度或内部参数(黑盒约束)。软提示微调(Soft Prompt Tuning)依赖连续嵌入与梯度优化,仅适配特定任务和模型,无法跨 LLM 移植;而现有黑盒提示优化方法(如 BDPL、RLPrompt)要么样本效率低(需大量模型查询),要么运行时间长,难以平衡性能与效率。
3. 硬提示的 “有效性 - 可移植性 - 效率” 平衡问题
硬提示虽具备跨 LLM 可移植性(无需依赖模型参数)和黑盒兼容性,但现有方法要么依赖人工设计(ManualPrompt),成本高且性能不稳定;要么通过复杂算法(如强化学习、策略梯度)优化离散提示,存在过拟合风险(如过长提示易适配训练集但泛化差),且未充分解决 “搜索空间大小 - 准确率 - 运行时间” 的权衡问题。
二、相关工作(Related Works)
按 “连续 / 离散”“黑盒 / 白盒” 分类梳理现有提示优化方法:
| 类别 | 代表方法与特点 |
|---|---|
| 连续 / 黑盒 | BBT(低维子空间优化)、Clip-tuning(混合奖励无导数优化)、BDPL(策略梯度估计梯度) |
| 连续 / 白盒 | Prefix-tuning(嵌入空间梯度优化)、Optiprompt(冻结模型参数,优化嵌入) |
| 离散 / 黑盒 | GRIPS(迭代局部编辑 + 无梯度搜索)、APO(自然语言 “梯度” 提示修改)、EvoPrompt(进化算法) |
| 离散 / 白盒 | AUTOPROMPT(梯度驱动提示生成)、Fluent Prompt(预训练模型生成候选提示) |
| 贝叶斯优化相关工作 | InstructZero(两阶段软提示优化)、INSTINCT(用神经网络替代 GP 的 BO) |
三、论文方法架构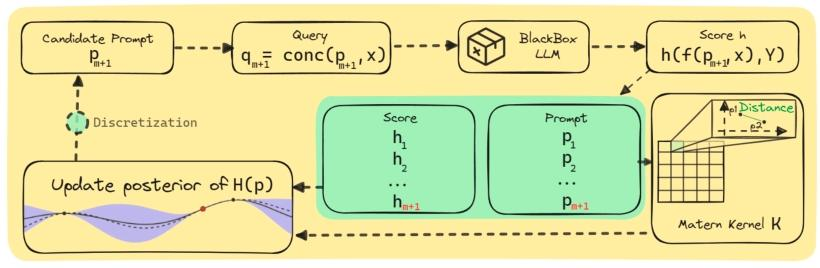
1. 问题建模
- 提示定义:提示p是长度为L的 n 元语法序列,选自词汇表V,即
;
- 目标函数:最大化任务性能期望,公式为:
其中,X为输入空间,Y为标签空间,f(p,x)是 LLM 对 “提示p+ 输入x” 的输出,h(⋅)是性能指标(分类任务用准确率或 F1 值,h=1表示预测正确,h=0表示错误),E表示对数据集分布D的期望。
2. 贝叶斯优化的硬提示微调(核心流程)
(1)贝叶斯优化基础框架
- 代理模型:采用高斯过程(Gaussian Process, GP)建模目标函数
,因 GP 能通过少量样本(提示 - 性能对)估计函数后验分布,适合黑盒优化的 “样本效率” 需求;
- 后验计算:给定已评估提示集合P1:n={p1,...,pn}及其性能h={F(p1),...,F(pn)},GP 后验均值μ(p)与方差
为:
其中,K为核矩阵(元素Kij=k(pi,pj),k为核函数),I为单位矩阵,为噪声方差;
- 采集函数:采用 Upper Confidence Bound(UCB)平衡 “探索”(未评估的高方差区域)与 “利用”(已评估的高均值区域),公式为:
UCB(p)=μ(p)+βσ(p)(β为权衡系数,控制探索强度)。
(2)组合空间的连续松弛(关键创新)
- 问题:原始提示空间
是离散组合空间,GP 核函数(需衡量 “提示相似度”)难以直接适配;
- 松弛步骤:
- 索引映射:将每个 n 元语法映射为其在词汇表V中的整数索引,使提示p转化为整数向量(如p=[5,12,3],对应词汇表中第 5、12、3 个 n 元语法);
- 连续化:将整数索引视为实数(如5→5.0,12→12.0),转化为连续空间RL;
- 核函数选择:采用 Matern 核(ν=5/2),而非平滑的平方指数核,以适配连续化后目标函数可能的 “非平滑性”(因 n 元语法索引顺序不直接代表语义相似度);
- 离散化还原:对连续空间中优化得到的向量,通过 “四舍五入” 转回整数索引,再映射为离散 n 元语法序列,得到最终提示。
(3)算法流程(PrompT-BO)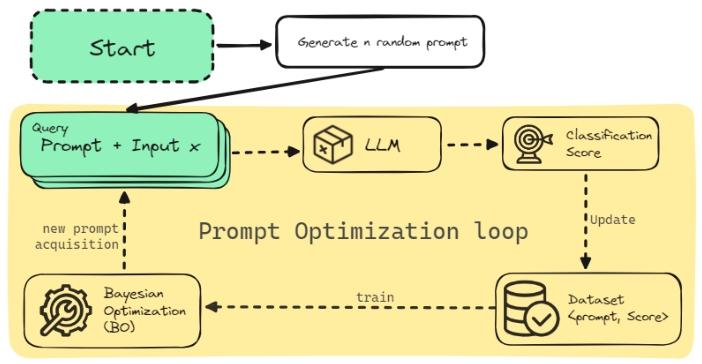
- 生成N个初始随机提示,评估其性能h,构建初始数据集D={(p1,h1),...,(pN,hN)};
- 用D拟合高斯过程模型(GP);
- 迭代k次:
- 优化 UCB 采集函数,得到连续空间中的候选提示
;
- 将
;
- 将(
- 优化 UCB 采集函数,得到连续空间中的候选提示
- 迭代结束后,D中性能最优的提示即为p∗。
四、实验数据集
1. 数据集
- MNLI(Multi-Genre Natural Language Inference):大型自然语言推理数据集,涵盖书面和口语英语的多种体裁,包含 43.3 万个标注句子对(标签为蕴含、矛盾、中立),任务是判断给定前提下车库的有效性。
- QQP(Quora Question Pairs):来自社区问答网站 Quora 的问题对数据集,包含超过 40 万个问题对,任务是判断两个问题是否语义等价(即能否用相同信息回答)。
- SST-2(Stanford Sentiment Treebank):斯坦福情感树库数据集,包含 6.7 万个电影评论,带有细粒度情感标签,任务是预测给定句子的情感为积极或消极。
- MRPC(Microsoft Research Paraphrase Corpus):来自在线新闻源的句子对数据集,包含 5800 个句子对,任务是识别每对句子是否语义等价(即是否传达相同含义)。
- QNLI(Question-answering NLI):源于斯坦福问答数据集(SQuAD),包含超过 10 万个由众包工作者在维基百科文章上提出的问题,任务是判断上下文句子是否包含问题的答案。
- RTE(Recognizing Textual Entailment):由新闻文章、图片标题等多种来源的句子对组成,任务是判断第二个句子是否由第一个句子蕴含(即第一个句子的真实性是否能保证第二个句子的真实性)。
2. 数据集划分与样本采样
为避免最优提示过拟合到训练数据,同时控制实验成本,论文采用以下划分与采样策略:
- 划分逻辑:对每个数据集,按 “类别平衡” 原则随机采样k个样本构建训练集,再采样另外k个不同样本构建验证集;将原数据集的验证集直接用作测试集,确保测试集与训练 / 验证集完全独立。
- 成本控制采样:由于 QQP 和某类数据集(原文提及 “RCT”,推测为笔误,核心指向验证集规模过大的数据集)的原始验证集规模过大,为节省计算成本,对这两类数据集的验证集随机采样 1000 个数据点用于实验。
五、基线设计
选取 4 种主流黑盒提示优化方法作为对照组(基线),所有对照组与实验组均使用冻结参数的 RoBERTa-large 模型:
-
ManualPrompt(手动提示)
唯一非自动化的基线方法,基于人工编写的提示进行零样本评估,代表 “传统手动提示工程” 的性能水平,用于验证自动化提示优化方法的优势。该对照组的设计逻辑是通过人工经验构建提示,与自动化方法形成 “人工 vs 算法” 的对比基准。 -
BlackBoxTuning(BBT)
属于 “连续 / 黑盒” 类提示优化方法,通过协方差矩阵自适应进化策略(一种无导数优化算法)优化 “前缀式连续提示”,核心思路是在低维随机子空间中搜索最优连续提示,而非直接优化离散 n-grams。文献表明该方法优于手动提示、GPT-3 的上下文学习及梯度基方法,是连续型黑盒提示优化的代表性基线。 -
Reinforcement Learning Prompt(RLPrompt)
属于 “离散 / 黑盒” 类提示优化方法,基于强化学习(RL)构建参数高效的策略网络,通过训练过程中的奖励信号(任务性能)优化离散提示序列,最终生成适配特定任务的离散提示。该方法的核心优势是通过 RL 的 “探索 - 奖励” 机制适配离散搜索空间,代表强化学习在提示优化中的应用水平。 -
Black-box Discrete Prompt Learning(BDPL)
同样属于 “离散 / 黑盒” 类方法,通过方差缩减策略梯度算法估计 “离散提示分类分布参数” 的梯度,间接实现离散提示的优化。该方法在 RoBERTa 和 GPT-3 上的实验已验证其在 8 个基准数据集上的性能提升,是离散型黑盒提示优化的核心对比基线(论文后续还将 PrompT-BO 与 BDPL 单独对比运行时间)。 -
Avg B.B.(Black Box 平均性能)
为更直观体现 PrompT-BO 的优势,论文将上述 4 种基线方法的性能取平均值,作为 “黑盒提示优化方法平均水平” 的综合基准,用于快速判断 PrompT-BO 是否超越主流方法的整体表现。
六、实验设计
本论文的实验流程围绕 “PrompT-BO 算法的验证” 展开,分为实验设置、算法执行、结果筛选、性能与效率评估四个核心阶段,具体步骤如下:
1. 实验前置设置
- 模型选择:采用 RoBERTa-large 模型的 “掩码语言建模(masked token prediction)” 版本(通过 Hugging Face 库调用),该版本因需对整个序列的上下文进行理解以预测掩码 token,更适配提示优化任务对 “上下文关联” 的需求;
- 数据集处理:对 6 个 GLUE 基准数据集(MNLI、QQP、SST-2、MRPC、QNLI、RTE)按 “类别平衡” 原则划分训练集(随机采样k个样本 / 类)、验证集(另采样k个不同样本 / 类),原数据集的验证集直接作为测试集;针对 QQP 等验证集规模过大的数据集,额外随机采样 1000 个样本以控制计算成本;
- 硬件环境:所有实验(含对照组)均在同一台机器上执行,配置为 2 vCPUs(2.2 GHz)、13 GB 内存、1 块 Tesla T4 GPU(16 GB VRAM),确保运行时间对比的公平性。
2. PrompT-BO 算法执行流程
- 初始提示生成与评估:生成N个随机离散提示(基于高 PMI 的 n-grams 词汇表),将每个提示与训练集输入拼接后输入 RoBERTa-large,计算其任务性能(如准确率、F1),构建初始数据集D={(p1,y1),...,(pN,yN)}(yi为提示pi的性能得分);
- 高斯过程(GP)模型初始化:用初始数据集D拟合 GP 模型,以 Matern 核(ν=5/2)建模 “提示 - 性能” 的映射关系,估计目标函数F(p)=E(X,Y)(h(f(p,x),Y))的后验分布;
- 迭代优化与模型更新:迭代k次以搜索最优提示:
- 优化 Upper Confidence Bound(UCB)采集函数,在连续松弛空间中找到候选提示pnew;
- 将pnew通过 “四舍五入” 转回整数索引,还原为离散提示,评估其在验证集上的性能ynew;
- 将(pnew,ynew)加入D,更新 GP 模型的后验分布;
- 最优提示筛选:迭代结束后,选择 “验证集性能最优” 的提示(而非训练集最优,避免过拟合),在独立的测试集上评估最终性能。
3. 对照组实验执行
对 ManualPrompt、BBT、RLPrompt、BDPL 四种基线方法,均采用与 PrompT-BO 相同的数据集划分、模型版本与硬件环境,按各方法的原始实现逻辑(如 BBT 的低维子空间优化、BDPL 的策略梯度估计)执行实验,记录其在测试集上的性能得分,用于后续对比。
七、评价指标
1. 性能评价指标
根据 6 个数据集的任务特性(自然语言推理、语义匹配、情感分析等),选择适配的分类任务评价指标,确保结果的合理性与可解释性:
-
准确率(Accuracy)
用于MNLI、SST-2、QNLI、RTE四个任务:计算公式为 “预测正确的样本数 / 总样本数”,适用于类别分布相对均衡的任务(如 SST-2 的积极 / 消极情感分类、QNLI 的 “包含答案 / 不包含答案” 二分类)。论文中这四类任务的性能结果均以准确率为核心指标,且标注了三次实验的标准差(如 PrompT-BO 在 MNLI 上的准确率为 29.6±1.7)。 -
F1 分数(F1-Score)
用于QQP、MRPC两个任务:作为 “精确率(Precision)” 与 “召回率(Recall)” 的调和均值(公式为F1=2×Precision+RecallPrecision×Recall),适用于可能存在类别不平衡的 “文本语义匹配” 任务(如 QQP 中 “等价” 与 “不等价” 问题对的分布可能不均),能更全面反映模型在正负样本上的性能平衡。 -
平均性能(Avg)与标准差(Std)
为综合评估方法的稳定性与整体表现,论文对每种方法在 6 个任务上的性能取平均值(如 PrompT-BO 的平均性能为 58.6,Avg B.B. 的平均性能为 58.46),并标注三次重复实验的标准差(如 BDPL 在 MNLI 上的标准差为 1.8),用于衡量方法性能的波动程度。
2. 效率评价指标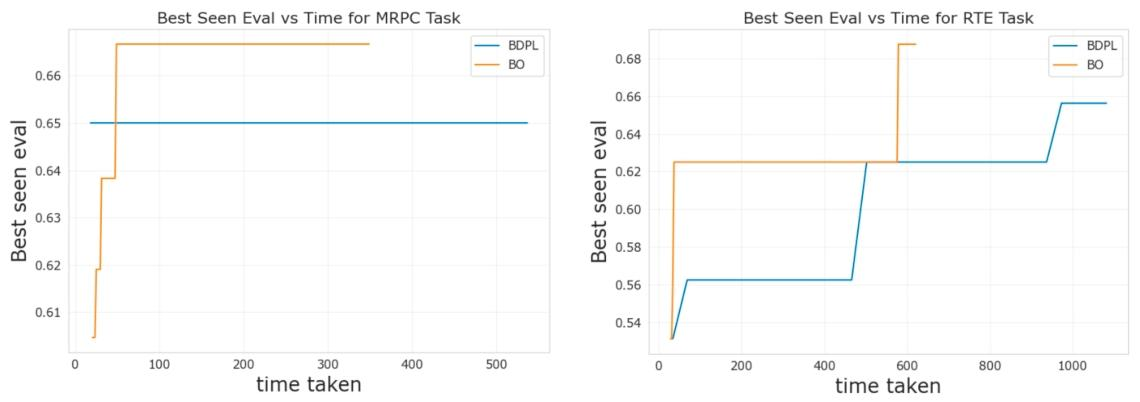
以 “运行时间(wall-clock time,单位:秒)” 为核心指标,衡量各方法的计算效率,具体记录 “提示优化算法时间 + RoBERTa 模型查询时间” 的总耗时:
- 实验表明,RoBERTa 模型的查询时间(即 “提示 + 输入” 的推理时间)是总耗时的主要组成部分;
- PrompT-BO 在所有任务上的运行时间均显著短于 BDPL(如 MRPC 任务:379.02 秒 vs 571.75 秒;SST-2 任务:264.23 秒 vs 384.84 秒),该指标验证了贝叶斯优化 “样本效率” 带来的时间优势。
八、实验结论
1. 贝叶斯优化是黑盒硬提示优化的有效工具
通过将离散组合搜索空间 “连续松弛”(整数索引→连续值→四舍五入还原离散提示),结合高斯过程(GP)代理模型与 UCB 采集函数,贝叶斯优化能有效解决硬提示的组合爆炸问题 —— 该方法无需复杂语义嵌入,仅通过 “朴素连续松弛” 即可实现高效搜索,在多数任务(QQP、SST-2、MRPC、QNLI、RTE)上的性能优于 ManualPrompt、BBT、RLPrompt、BDPL 四种基线方法的平均水平(Avg B.B.),仅在 MNLI(词汇表最大,∣V∣=117056)上因 “朴素松弛” 适配性不足表现较差<RichMediaReference>、。
2. PrompT-BO 具备显著的样本效率与时间效率优势
- 样本效率:贝叶斯优化的 “探索 - 利用平衡” 策略(基于 GP 后验分布与 UCB 函数)能减少无效模型查询,仅需少量初始随机提示(N个)和迭代(k次)即可找到较优提示,样本效率优于 BDPL、RLPrompt 等黑盒方法<RichMediaReference>;
- 时间效率:在相同硬件环境(2 vCPUs、13GB 内存、Tesla T4 GPU)下,PrompT-BO 运行时间大幅短于 BDPL(如 MRPC 任务:379.02 秒 vs 571.75 秒;SST-2 任务:264.23 秒 vs 384.84 秒),且 BO 自身计算开销不足 1 秒,效率优势源于样本效率提升(减少模型查询时间,而模型查询是总耗时的主要组成部分)<RichMediaReference>、。
3. 提示长度与性能并非正相关,过长提示易过拟合
实验表明,提示长度增加不必然带来性能提升:以 MRPC 任务为例,25 长度提示的测试最优得分(79.76)高于 50 长度(78.44)和 75 长度(78.42),说明过长提示易过拟合训练数据,且降低可移植性,这与 GLUE 基准相关研究结论一致<RichMediaReference>、。
4. 基础版 BO 算法已能满足需求,无需复杂定制
现有组合优化场景的 BO 方法常需设计专用算法或核函数,而论文验证:基于 BoTorch 的 “基础版” BO 算法(单任务 GP+Matern 核 + UCB 采集函数),无需针对高维组合空间定制优化,即可在多数任务上达到优异性能,降低了方法的复杂度与应用门槛。
九、创新点
1. 提出 “组合空间朴素连续松弛” 方法,突破离散搜索瓶颈
针对硬提示的组合空间难以直接优化的问题,论文设计两步松弛策略:先将 n 元语法映射为词汇表中的整数索引(转化为整数向量),再将整数视为实数转化为连续空间;优化后通过 “四舍五入” 还原为离散索引与 n 元语法序列。该方法无需复杂语义嵌入,仅通过简单数值转换实现 “离散 - 连续 - 离散” 闭环,且选用 Matern 核(ν=5/2)适配连续化后目标函数的非平滑性,兼顾简便性与有效性。
2. 验证贝叶斯优化(BO)在黑盒硬提示优化中的样本效率优势
贝叶斯优化凭借高斯过程(GP)代理模型(可通过少量样本估计函数后验)和 UCB 采集函数(平衡探索 - 利用),显著降低模型查询次数:实验表明,PrompT-BO 仅需少量初始随机提示(N个)和迭代(k次),即可找到性能较优的提示,样本效率优于 BDPL、RLPrompt 等黑盒方法,且核心得益于 BO 的 “概率建模 - 定向搜索” 策略,避免无效探索。
3. 实现 “性能 - 运行时间” 双重提升,显著优化效率
相比现有黑盒方法,PrompT-BO 在相同硬件环境(2 vCPUs、13GB 内存、Tesla T4 GPU)下,运行时间大幅缩短:如 MRPC 任务中,PrompT-BO 耗时 379.02 秒,BDPL 需 571.75 秒;SST-2 任务中,PrompT-BO 耗时 264.23 秒,BDPL 需 384.84 秒。效率提升源于 BO 的样本效率(减少模型查询次数,而模型查询是总耗时的主要组成部分),且 BO 自身计算开销不足 1 秒,几乎无额外成本。
4. 证明 “基础版 BO 算法足够有效”,降低方法复杂度
现有组合优化场景的 BO 方法常需设计专用算法或复杂核函数,而论文通过实验验证:基于 BoTorch 的 “基础版” BO 算法(单任务 GP+UCB 采集函数),无需针对高维组合空间定制优化,即可在 6 个 GLUE 数据集上(除 MNLI 外)优于 4 种基线方法的平均性能(Avg B.B.),证明 “朴素松弛 + 基础 BO” 的组合能平衡性能与复杂度,降低实际应用门槛。