基于 PaddleDetection实现目标算法识别
我使用的是百度开源的飞桨平台提供的开源目标识别算法:PaddleDetection
链接如下:https://github.com/PaddlePaddle/PaddleDetection
今天整理一下算法识别的功能实现,这个东西我研究了整整一周的时间才终于有了点效果。好难。
我查了好多好多资料,都没有一个很完整的教学,包括B站教学也没有,所以我必须要写这篇文章《从0到1实现完成的目标识别》
我将从几个方面非常详细的介绍整个开发部署流程。
- 显卡安装部署
- python环境搭建
- paddlepaddle安装
- labelme图像数据标记
- labelme数据转换coco数据集
- 模型训练
- 模型导出
- 模型推理预测
这8个非常完整详细的步骤贼详细的介绍我的每一步操作。希望能帮到大家。
下面开干!
这个网盘链接有这篇文章用到的所有。
通过网盘分享的文件:shareFile
链接: https://pan.baidu.com/s/1Iz6sMA2NdhYp4HwQu3fyXw?pwd=cmed 提取码: cmed
1.显卡安装部署
文件自行提取,我的版本是11.2,所以我后面安装的paddlepaddle也是11.2版本
1、安装cudn的显卡驱动一路一直下一步完成安装就可以了。
2、安装cudnn
首先要解压文件夹,
然后把这几个文件拷贝到:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.2
3、验证cudnn是否安装成功
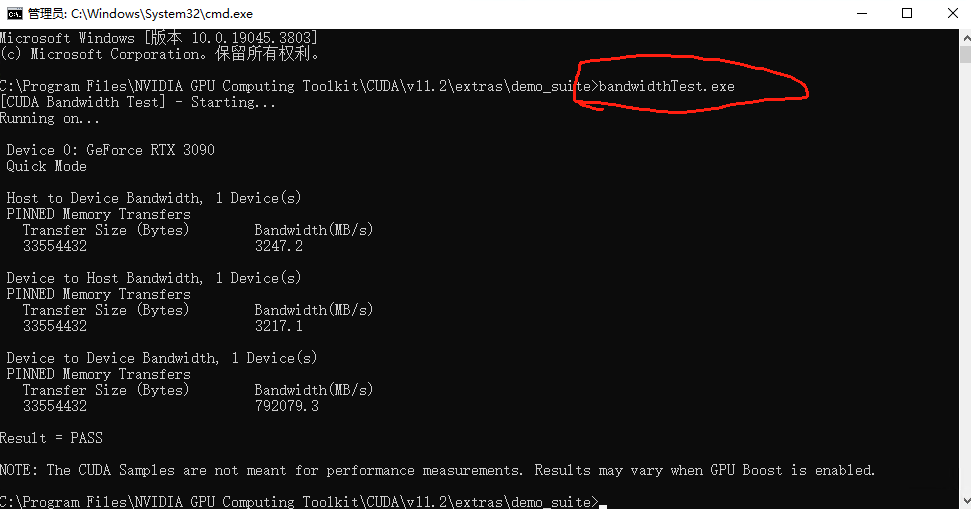
复制完后,在当前目录下进入 extras -> demo_suite,可以看到有 bandwidthTest.exe 和 deviceQuery.exe
并在路径中输入 cmd 打开命令行窗口
输入 bandwidthTest.exe ,输出下图:
输入 deviceQuery.exe,输出下图:
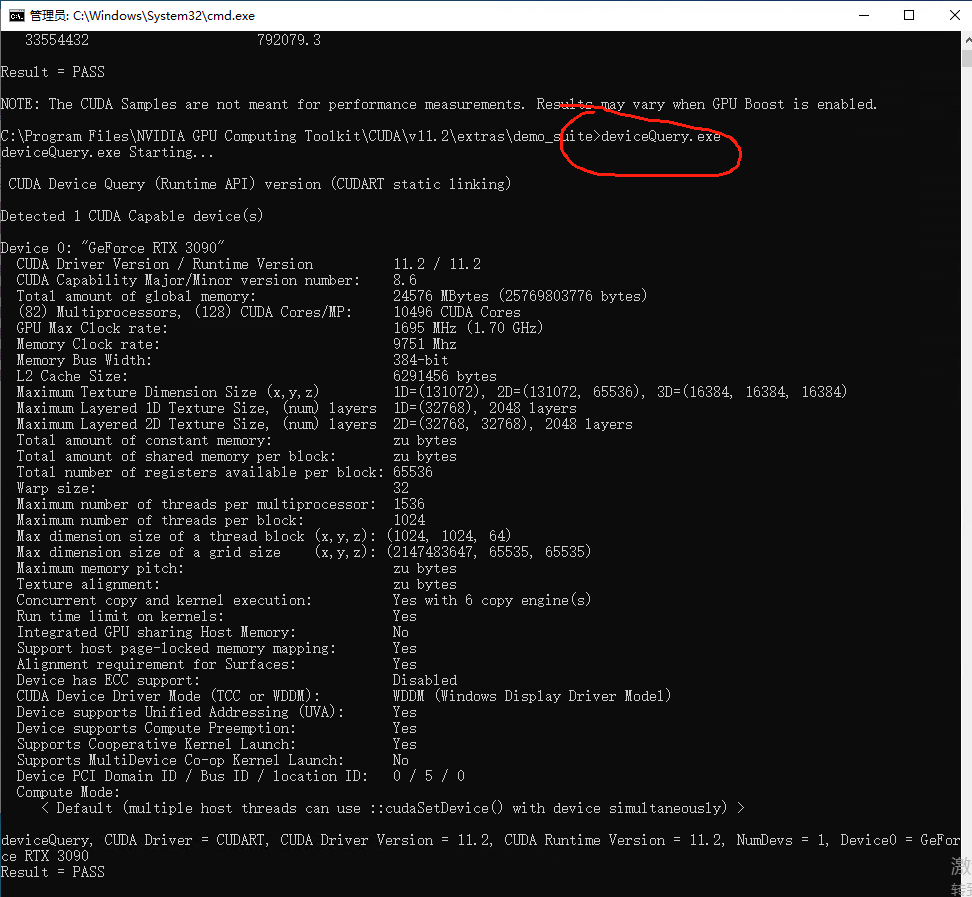
至此, CUDA 与 cudnn 安装成功,可以使用 GPU 加速了
2、python环境搭建
我这里使用Anaconda来搭建一个python的隔离环境,能够更好的跟其他python项目隔离。安装和删除都方便。
1、安装Anaconda
这个安装包也在网盘里,双击 Anaconda3-2024.06-1-Windows-x86_64.exe 安装,一路下一步就可以,就也不放截图了。
最后安装完,再home里会有一个图标如下,就是conda
2、打开conda
点击打开

3、创建python环境
输入命令,这里是使用python 3.10 ,(建议不懂的就全跟我保持一致)
ppyoloe :是容器名字,可以修改
conda create --name ppyoloe python=3.10
4、激活环境
ppyoloe : 是刚刚创建的环境名称
输入命令
conda activate ppyoloe
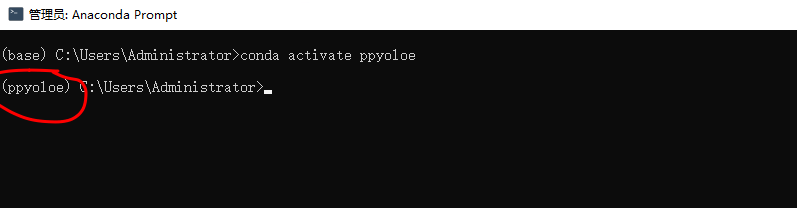
可以看到前缀已经是ppyoloe了,说明进到我们自己创建的环境了。
3.paddlepaddle安装
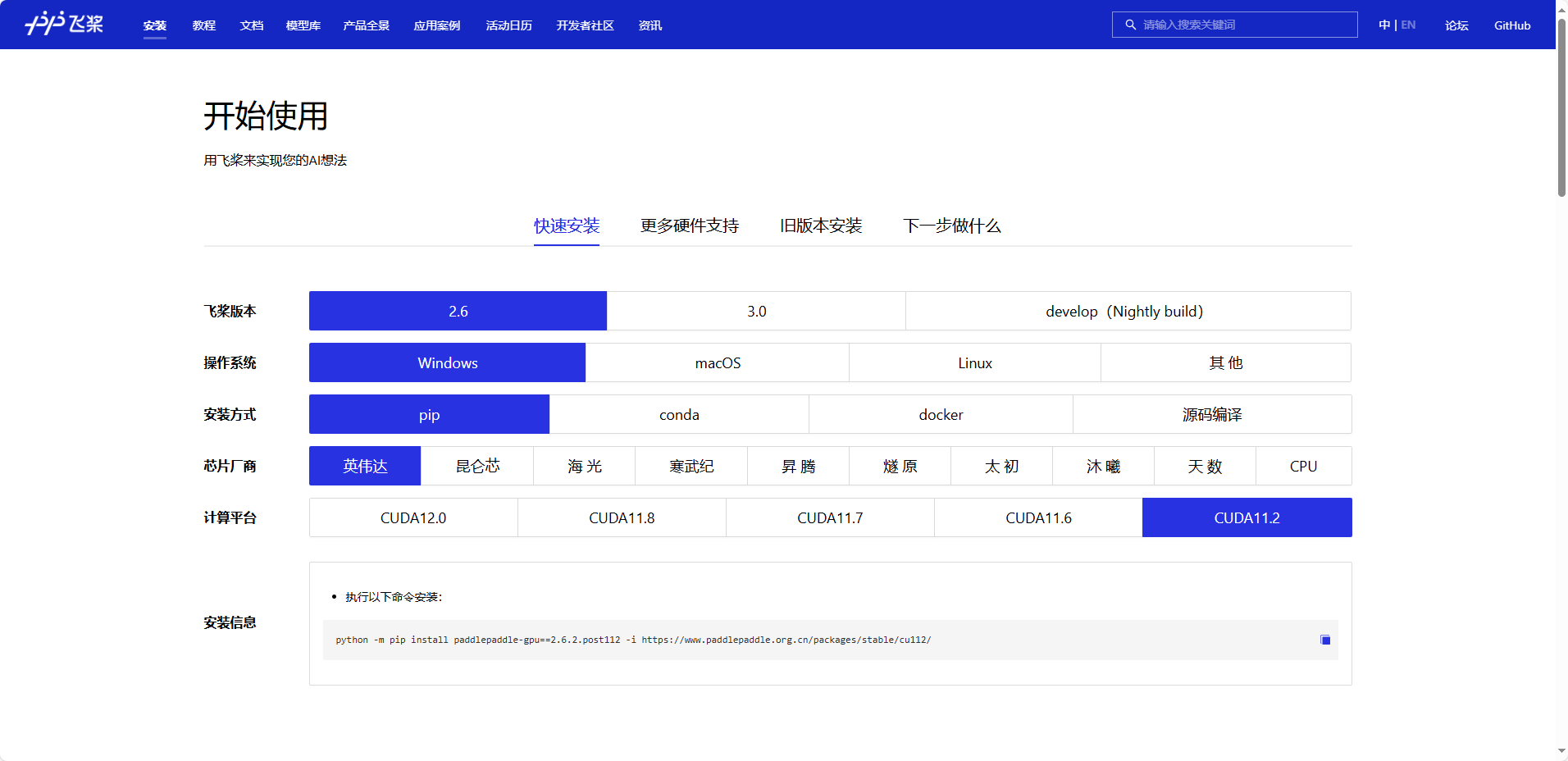
首先可以看一下官网:https://www.paddlepaddle.org.cn/install/quick?docurl=/documentation/docs/zh/install/pip/windows-pip.html
1、安装
我们安装就是复制他的链接。
python -m pip install paddlepaddle-gpu==2.6.2.post112 -i https://www.paddlepaddle.org.cn/packages/stable/cu112/运行这个命令要等有一会,他要下载东西。等着就好了。
2、验证安装
安装完成后您可以使用 python 进入 python 解释器,输入import paddle ,再输入 paddle.utils.run_check()
如果出现PaddlePaddle is installed successfully!,说明您已成功安装。
4.labelme图像数据标记
1、安装启动labelme
只需要一个命令直接下载安装
pip install labelme
启动labelme
输入命令
labelme
2、使用labelme

这就能看到labelme界面了。如下图
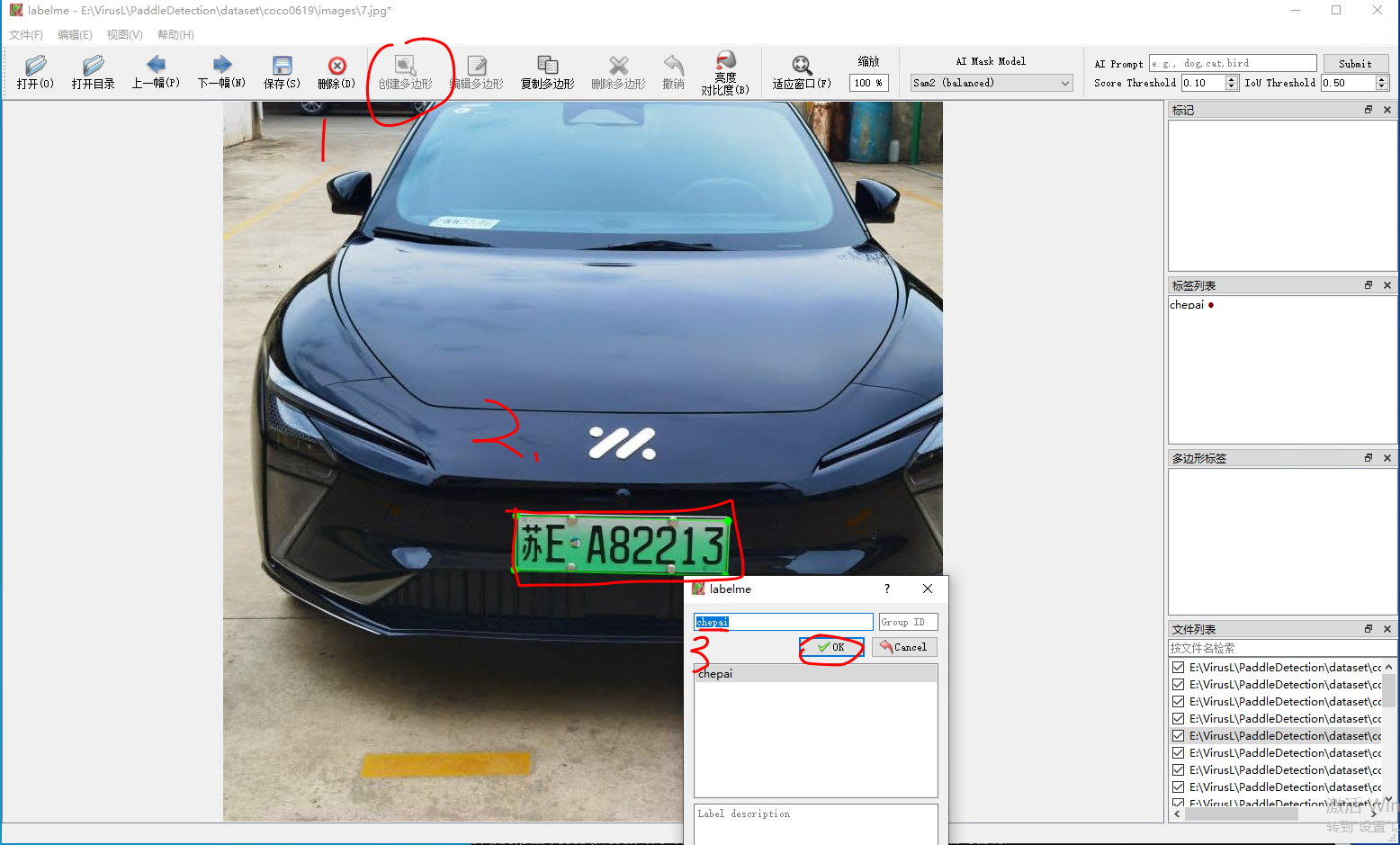
之后点击左上角的打开目录,打开我们自己的图片集就行了,
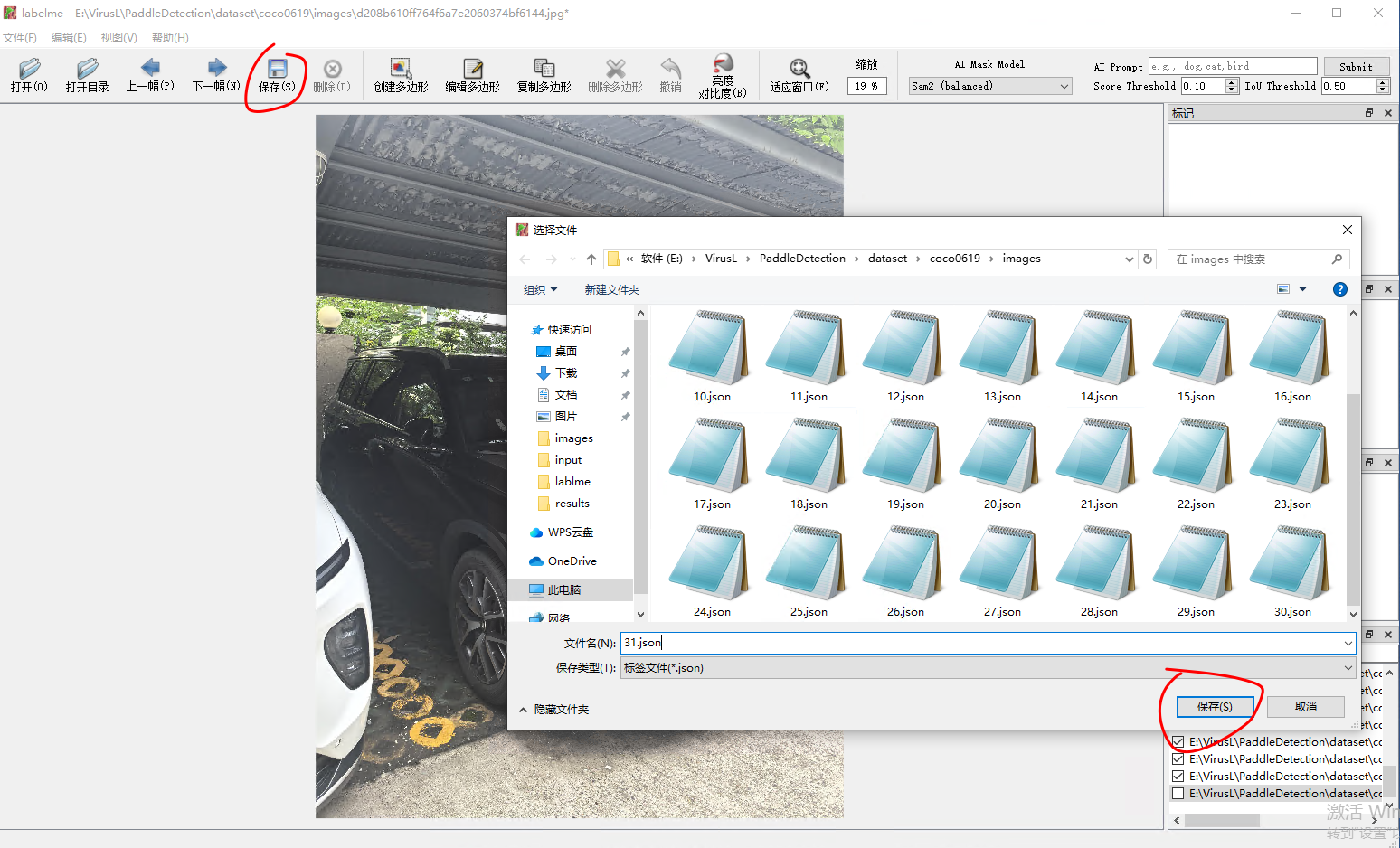
然后接下来就是标记图形了,按照我下面的操作就完成了一张图片的标记,保存之后就是生成了一个json文件。
3、labelme转换coco数据集
首先下载一下官网提供的源码文件:labelme2coco.py
import argparse
import collections
import datetime
import glob
import json
import os
import os.path as osp
import sys
import uuid
import imgviz
import numpy as np
import labelme
from sklearn.model_selection import train_test_splittry:import pycocotools.mask
except ImportError:print("Please install pycocotools:\n\n pip install pycocotools\n")sys.exit(1)def to_coco(args, label_files, train):# 创建 总标签datanow = datetime.datetime.now()data = dict(info=dict(description=None,url=None,version=None,year=now.year,contributor=None,date_created=now.strftime("%Y-%m-%d %H:%M:%S.%f"),),licenses=[dict(url=None, id=0, name=None, )],images=[# license, url, file_name, height, width, date_captured, id],type="instances",annotations=[# segmentation, area, iscrowd, image_id, bbox, category_id, id],categories=[# supercategory, id, name],)# 创建一个 {类名 : id} 的字典,并保存到 总标签data 字典中。class_name_to_id = {}for i, line in enumerate(open(args.labels).readlines()):class_id = i - 1 # starts with -1class_name = line.strip() # strip() 方法用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列。if class_id == -1:assert class_name == "__ignore__" # background:0, class1:1, ,,continueclass_name_to_id[class_name] = class_iddata["categories"].append(dict(supercategory=None, id=class_id, name=class_name, ))if train:out_ann_file = osp.join(args.output_dir, "annotations", "instances_train2017.json")else:out_ann_file = osp.join(args.output_dir, "annotations", "instances_val2017.json")for image_id, filename in enumerate(label_files):label_file = labelme.LabelFile(filename=filename)base = osp.splitext(osp.basename(filename))[0] # 文件名不带后缀if train:out_img_file = osp.join(args.output_dir, "train2017", base + ".jpg")else:out_img_file = osp.join(args.output_dir, "val2017", base + ".jpg")print("| ", out_img_file)# ************************** 对图片的处理开始 *******************************************# 将标签文件对应的图片进行保存到对应的 文件夹。train保存到 train2017/ test保存到 val2017/img = labelme.utils.img_data_to_arr(label_file.imageData) # .json文件中包含图像,用函数提出来imgviz.io.imsave(out_img_file, img) # 将图像保存到输出路径# ************************** 对图片的处理结束 *******************************************# ************************** 对标签的处理开始 *******************************************data["images"].append(dict(license=0,url=None,file_name=base + ".jpg", # 只存图片的文件名# file_name=osp.relpath(out_img_file, osp.dirname(out_ann_file)), # 存标签文件所在目录下找图片的相对路径## out_img_file : "/coco/train2017/1.jpg"## out_ann_file : "/coco/annotations/annotations_train2017.json"## osp.dirname(out_ann_file) : "/coco/annotations"## file_name : ..\train2017\1.jpg out_ann_file文件所在目录下 找 out_img_file 的相对路径height=img.shape[0],width=img.shape[1],date_captured=None,id=image_id,))masks = {} # for areasegmentations = collections.defaultdict(list) # for segmentationfor shape in label_file.shapes:points = shape["points"]label = shape["label"]group_id = shape.get("group_id")shape_type = shape.get("shape_type", "polygon")mask = labelme.utils.shape_to_mask(img.shape[:2], points, shape_type)if group_id is None:group_id = uuid.uuid1()instance = (label, group_id)if instance in masks:masks[instance] = masks[instance] | maskelse:masks[instance] = maskif shape_type == "rectangle":(x1, y1), (x2, y2) = pointsx1, x2 = sorted([x1, x2])y1, y2 = sorted([y1, y2])points = [x1, y1, x2, y1, x2, y2, x1, y2]else:points = np.asarray(points).flatten().tolist()segmentations[instance].append(points)segmentations = dict(segmentations)for instance, mask in masks.items():cls_name, group_id = instanceif cls_name not in class_name_to_id:continuecls_id = class_name_to_id[cls_name]mask = np.asfortranarray(mask.astype(np.uint8))mask = pycocotools.mask.encode(mask)area = float(pycocotools.mask.area(mask))bbox = pycocotools.mask.toBbox(mask).flatten().tolist()data["annotations"].append(dict(id=len(data["annotations"]),image_id=image_id,category_id=cls_id,segmentation=segmentations[instance],area=area,bbox=bbox,iscrowd=0,))# ************************** 对标签的处理结束 *******************************************# ************************** 可视化的处理开始 *******************************************if not args.noviz:labels, captions, masks = zip(*[(class_name_to_id[cnm], cnm, msk)for (cnm, gid), msk in masks.items()if cnm in class_name_to_id])viz = imgviz.instances2rgb(image=img,labels=labels,masks=masks,captions=captions,font_size=15,line_width=2,)out_viz_file = osp.join(args.output_dir, "visualization", base + ".jpg")imgviz.io.imsave(out_viz_file, viz)# ************************** 可视化的处理结束 *******************************************with open(out_ann_file, "w") as f: # 将每个标签文件汇总成data后,保存总标签data文件json.dump(data, f)# 主程序执行
def main():parser = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter)parser.add_argument("--input_dir", help="input annotated directory")parser.add_argument("--output_dir", help="output dataset directory")parser.add_argument("--labels", help="labels file", required=True)parser.add_argument("--noviz", help="no visualization", action="store_true")args = parser.parse_args()if osp.exists(args.output_dir):print("Output directory already exists:", args.output_dir)sys.exit(1)os.makedirs(args.output_dir)print("| Creating dataset dir:", args.output_dir)if not args.noviz:os.makedirs(osp.join(args.output_dir, "visualization"))# 创建保存的文件夹if not os.path.exists(osp.join(args.output_dir, "annotations")):os.makedirs(osp.join(args.output_dir, "annotations"))if not os.path.exists(osp.join(args.output_dir, "train2017")):os.makedirs(osp.join(args.output_dir, "train2017"))if not os.path.exists(osp.join(args.output_dir, "val2017")):os.makedirs(osp.join(args.output_dir, "val2017"))# 获取目录下所有的.jpg文件列表feature_files = glob.glob(osp.join(args.input_dir, "*.jpg"))print('| Image number: ', len(feature_files))# 获取目录下所有的joson文件列表label_files = glob.glob(osp.join(args.input_dir, "*.json"))print('| Json number: ', len(label_files))# feature_files:待划分的样本特征集合 label_files:待划分的样本标签集合 test_size:测试集所占比例# x_train:划分出的训练集特征 x_test:划分出的测试集特征 y_train:划分出的训练集标签 y_test:划分出的测试集标签x_train, x_test, y_train, y_test = train_test_split(feature_files, label_files, test_size=0.3)print("| Train number:", len(y_train), '\t Value number:', len(y_test))# 把训练集标签转化为COCO的格式,并将标签对应的图片保存到目录 /train2017/print("—" * 50)print("| Train images:")to_coco(args, y_train, train=True)# 把测试集标签转化为COCO的格式,并将标签对应的图片保存到目录 /val2017/print("—" * 50)print("| Test images:")to_coco(args, y_test, train=False)if __name__ == "__main__":print("—" * 50)main()print("—" * 50)接下来,我们要在ppyoloe的环境中先cd到我们的这个图片路径下,然后执行下面的命令。
python labelme2coco.py --input_dir images --output_dir coco --labels labels.txt
上面的命令中:
images是刚刚生成的json文件的文件夹名,我这里用的是相对路径;
coco 是指定生成的文件夹名,这个不能存在;
labels.txt 是一个标签文件,里面保存刚刚标记的标签名。
labels.txt文件如下:
__ignore__
_background_
chepai
运行完命令后会有coco文件夹生成
打开后是这样的目录结构,并且里面都有数据,就说明你成功了。
5、模型训练
1、下载源码
先在git上下载项目源码,我直接给出gitee的地址,国内gitee比较好访问。
https://gitee.com/paddlepaddle/PaddleDetection.git
这个官网有安装教程可以看一下,我下面直接贴官网关键操作的教程吧。
# 克隆PaddleDetection仓库
cd <path/to/clone/PaddleDetection>
git clone https://github.com/PaddlePaddle/PaddleDetection.git# 安装其他依赖
cd PaddleDetection
pip install -r requirements.txt# 编译安装paddledet
python setup.py install# 安装后确认测试通过:
python ppdet/modeling/tests/test_architectures.py# 测试通过后会提示如下信息:
.......
----------------------------------------------------------------------
Ran 7 tests in 12.816s
OK
跟上面一样就是成功了。
2、模型训练
3、配置文件
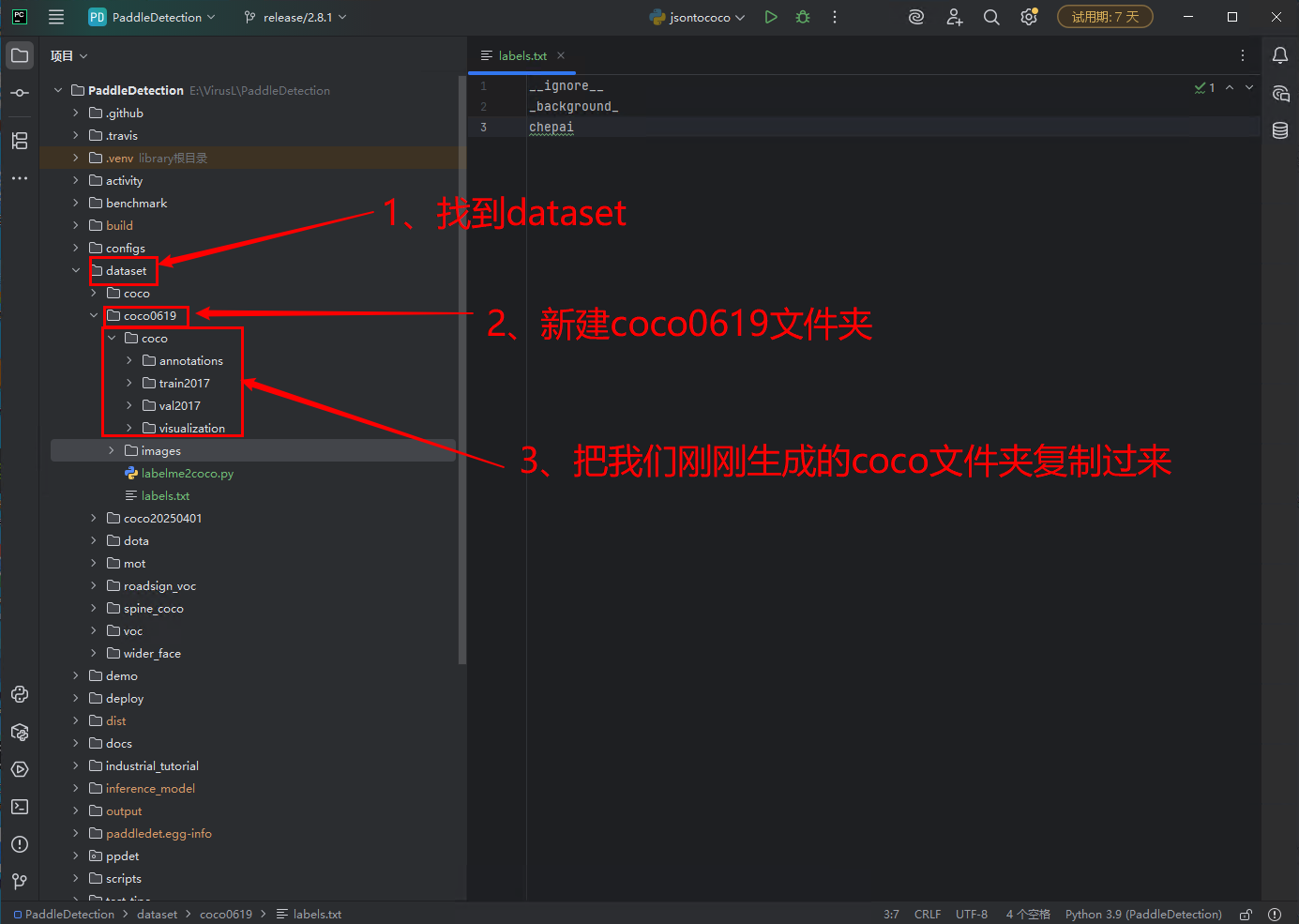
下面开始重点部分,简单修改一下配置文件。
configs->yolov3->yolov3_r50vd_dcn_270e_coco.yml ,找到这个文件,可以每个版本的这个文件位置不太一样啊,那就搜索一下。
我做一下简单解释:这个yolov3其实就是一个识别算法,configs文件夹下面都是配置文件,其实可以选择任何一种算法,例如还有ppyoloe文件夹,那这个就是它这种算法,选择这个也行,我一开始就用的ppyoloe算法,后来又换的这个算法。这都可以。
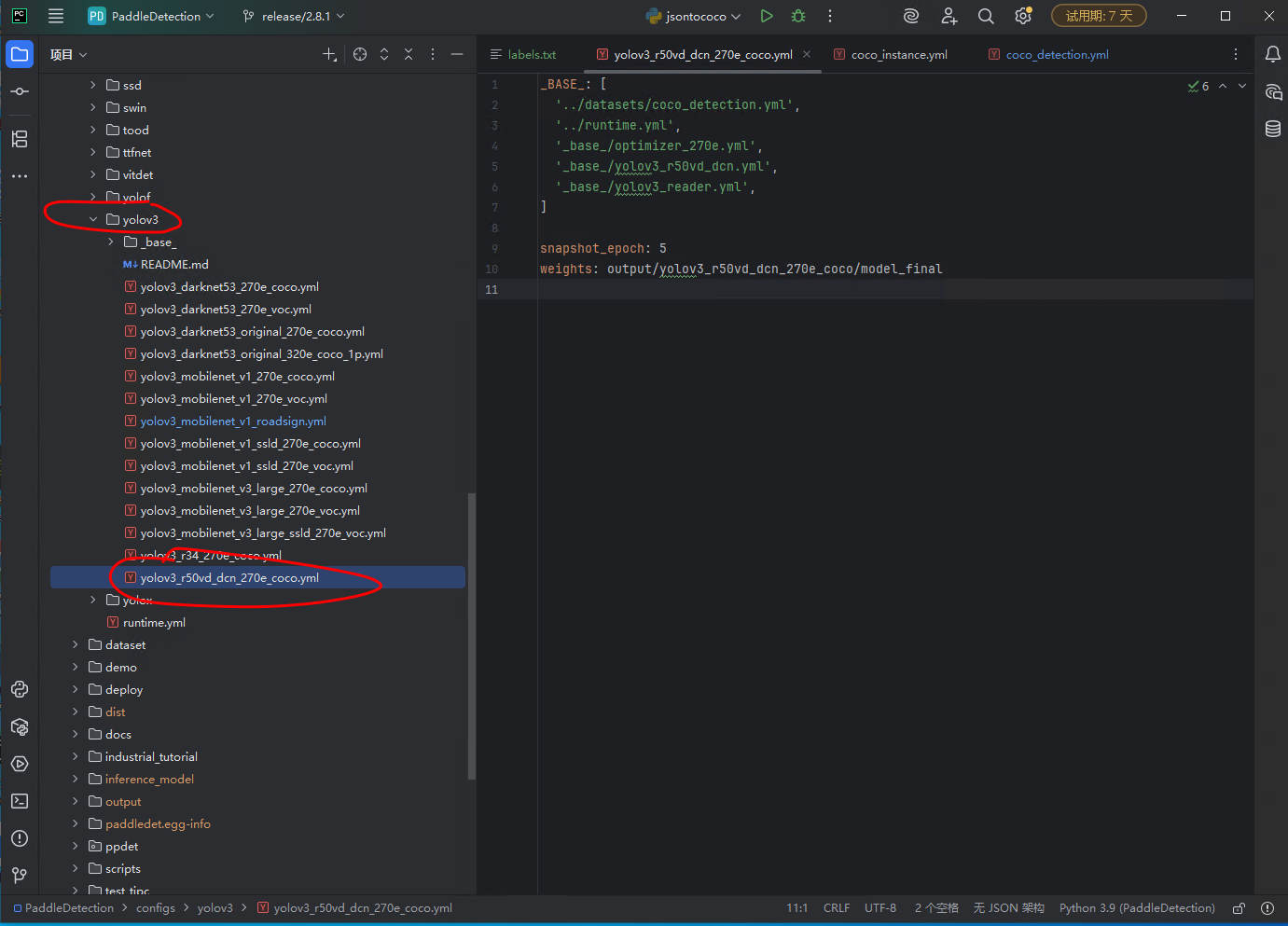
然后我们看一下这个配置文件,首先第一行有个配置,“‘…/datasets/coco_detection.yml’”很重要,我们也只需要改这一个配置文件就行。
接下来找到打开这个文件,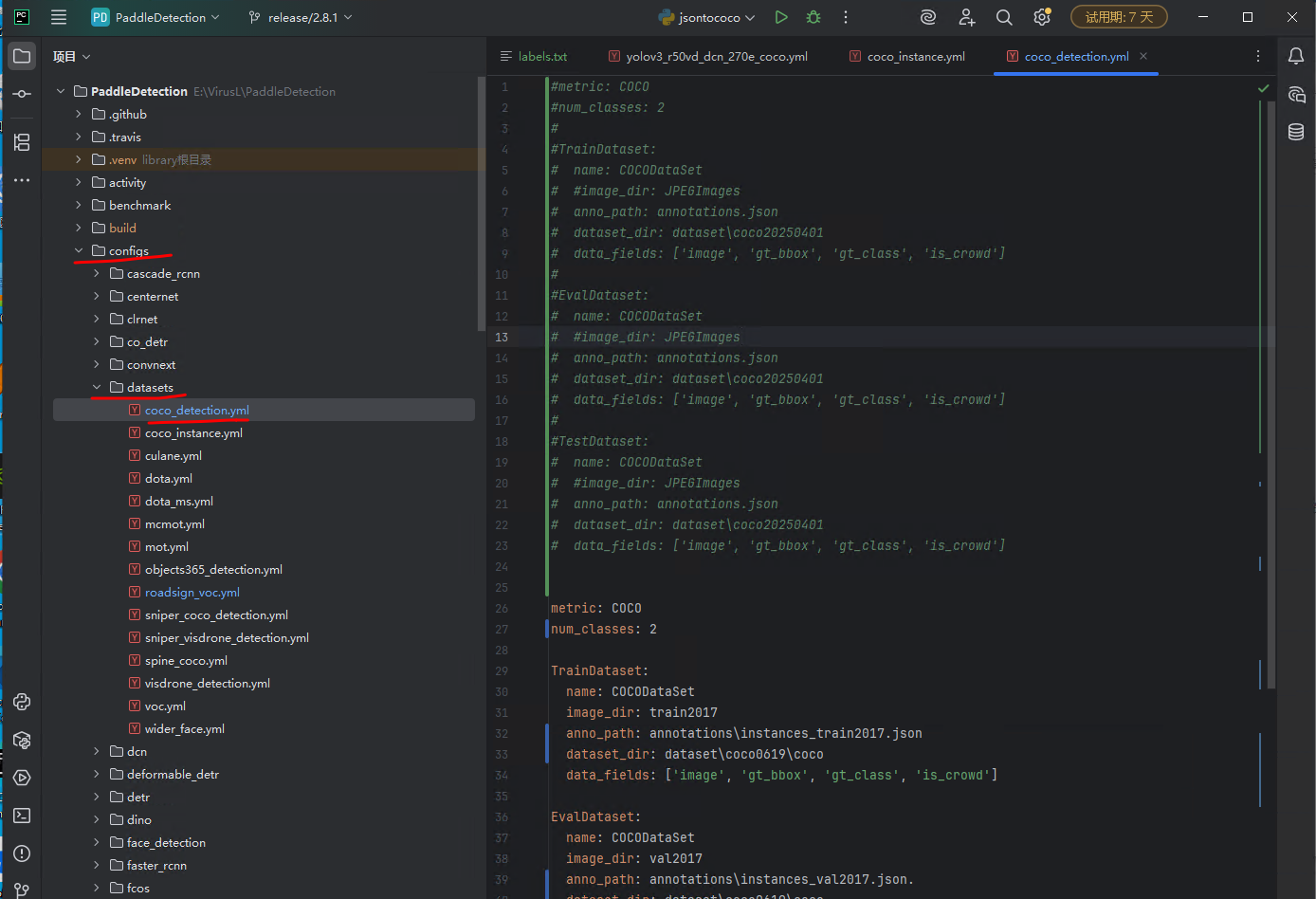
右侧文件中,我注释掉的是原本的内容,下面是我重新写的要训练我们自己模型的配置。
metric: COCO
num_classes: 2 # 这个是我们labelme标记时的一共设置了多少个类别,然后类别+1。(我这里写的2是因为我只有一个类别)TrainDataset: # 训练数据集name: COCODataSet image_dir: train2017 # 图片目录anno_path: annotations\instances_train2017.json # 数据集目录,是相对于下面的dataset_dir的路径dataset_dir: dataset\coco0619\coco # 这里必须写到 coco这个文件夹路径data_fields: ['image', 'gt_bbox', 'gt_class', 'is_crowd'] # 不用改EvalDataset: # 评估数据集name: COCODataSetimage_dir: val2017anno_path: annotations\instances_val2017.json.dataset_dir: dataset\coco0619\cocodata_fields: ['image', 'gt_bbox', 'gt_class', 'is_crowd']TestDataset: # 预测数据集name: COCODataSetimage_dir: train2017anno_path: annotations\instances_train2017.jsondataset_dir: dataset\coco0619\cocodata_fields: ['image', 'gt_bbox', 'gt_class', 'is_crowd']
ok,到现在,配置文件也修改完了,开始训练。
4、模型训练命令
打开Anaconda,输入下面命令,注意,一定要先cd到咱们的python项目目录下在运行命令,如下图
python tools/train.py -c configs/yolov3/yolov3_r50vd_dcn_270e_coco.yml -o use_gpu=true
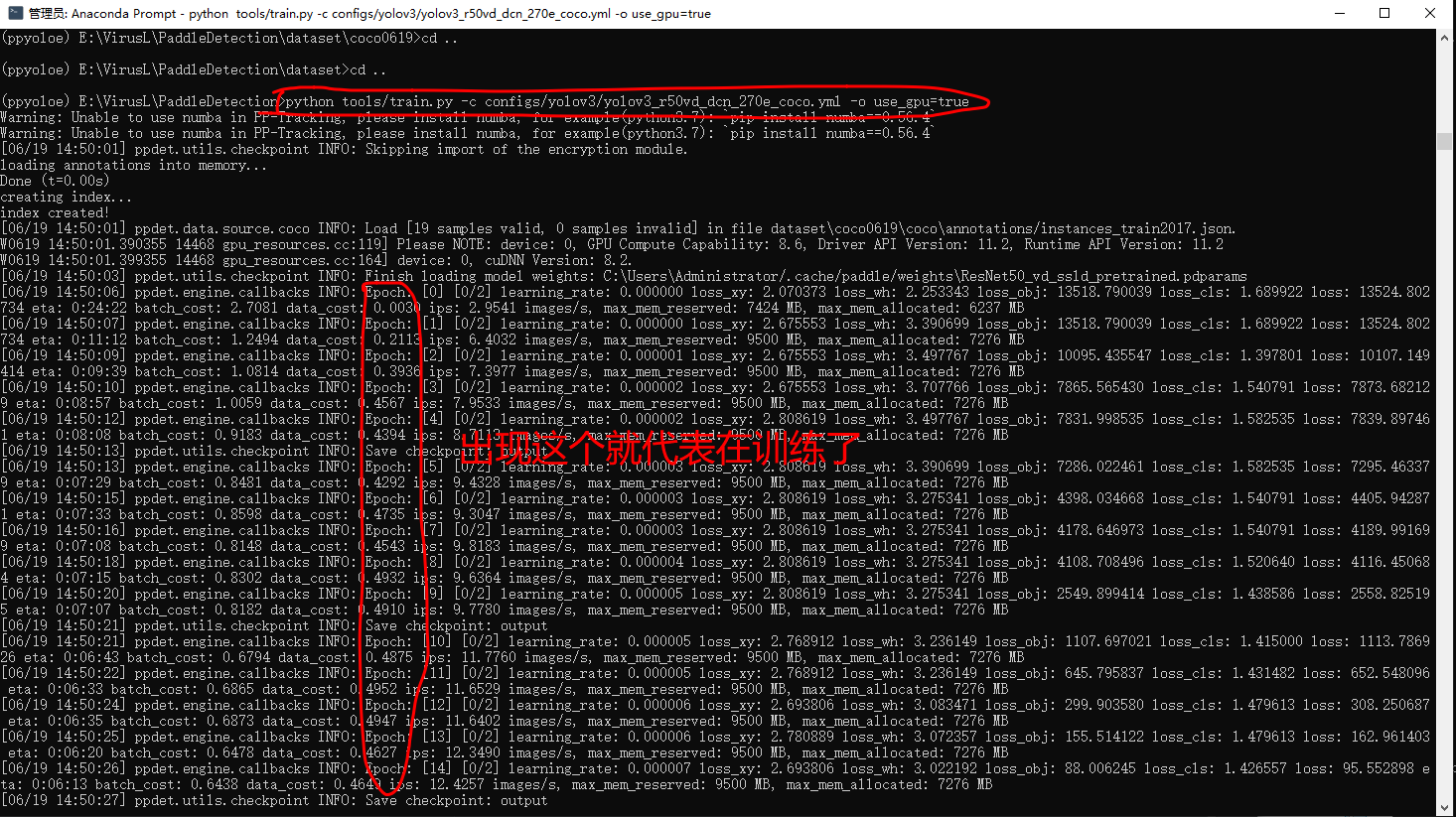
如果几百上千张图片,大概率要训练三四个小时,这个在cmd中有一个打印 eta ,是预计完成时间。
等待。。。。。
等训练完成后,模型会输出到out文件夹。
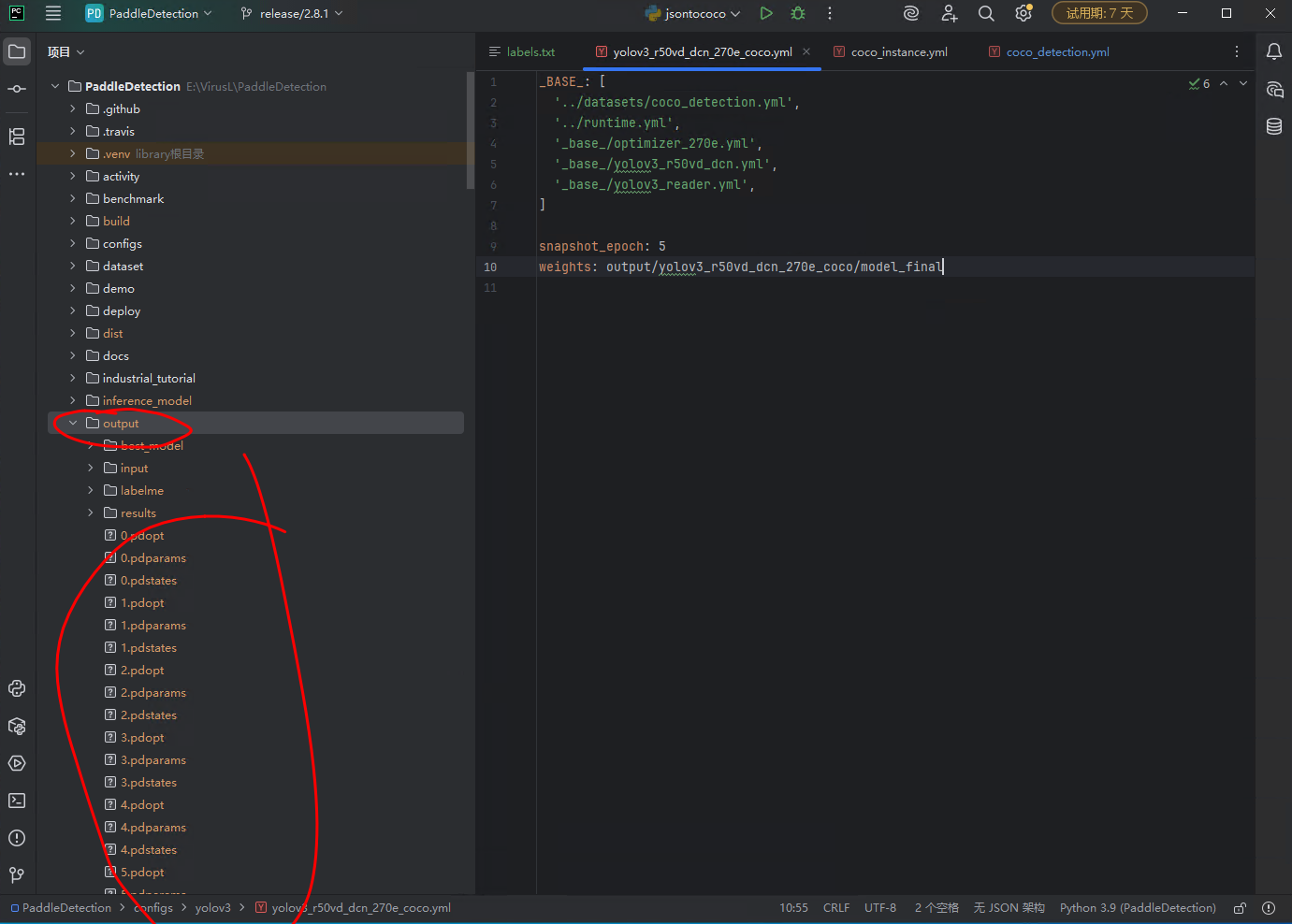
可以看到out文件夹下有很多文件,但是其实我这里好像有文件,它直接把模型输入到out了,但是我的配置文件配置的输出路径是这个 yolov3_r50vd_dcn_270e_coco.yml文件里的这个 “weights: output/yolov3_r50vd_dcn_270e_coco/model_final”,按道理应该再创建一个yolov3_r50vd_dcn_270e_coco文件夹再保存model_final,但是但是但是,没有,我也不知道为啥,但是不影响先继续,所以你们再训练完模型后要看一下具体生成的模型保存到了哪里,下一步模型导出的时候要用这个地址。
6.模型导出命令
python tools/export_model.py -c configs/yolov3/yolov3_r50vd_dcn_270e_coco.yml --output_dir=./inference_model -o weights=output/model_final.pdparams
“-o weights=output/model_final.pdparams” 这个参数就是上面的模型保存位置,我的模型就这这个位置,大家看自己的模型保存到了哪里,然后调整一下参数。

模型导出很快,我导出到了inference_model 目录下。
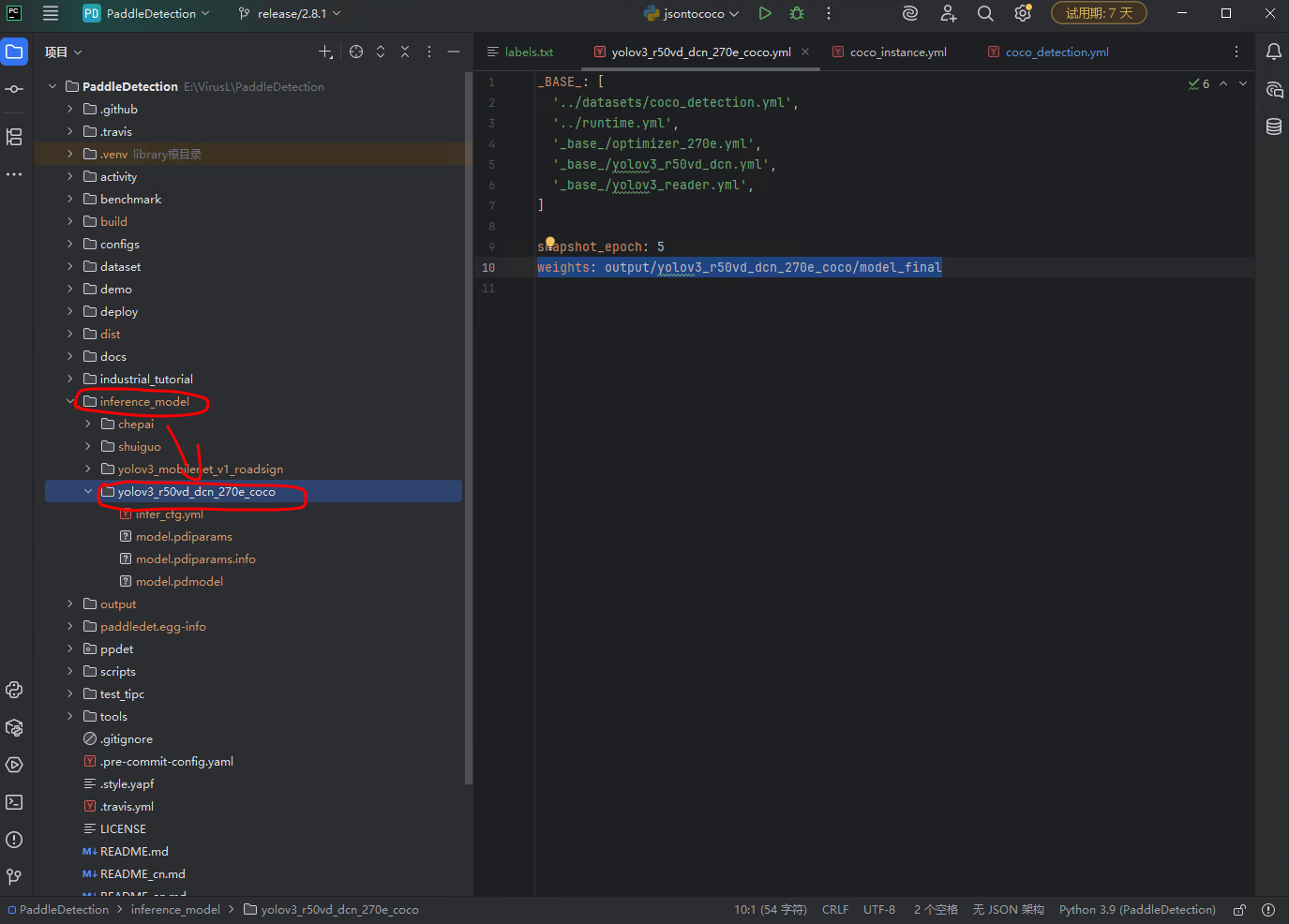
到此,模型导出完成,可以部署到任意服务器进行目标识别了。
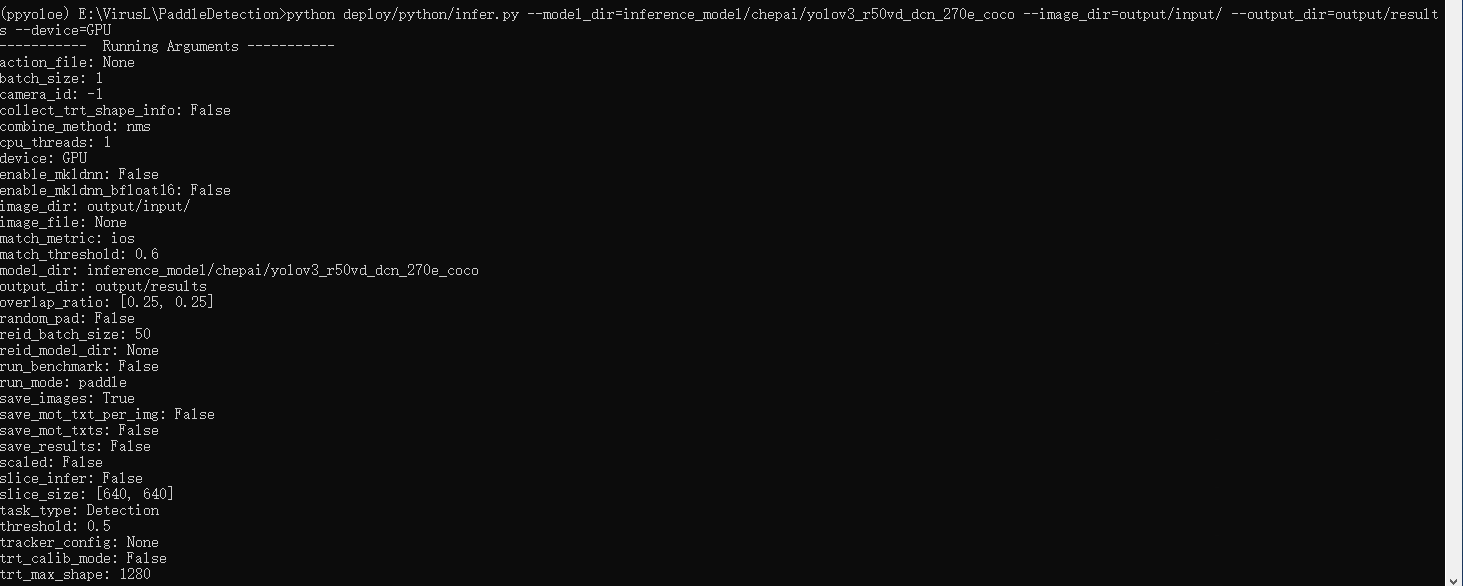
7.模型推理预测
python deploy/python/infer.py --model_dir=inference_model/yolov3_r50vd_dcn_270e_coco --image_dir=output/input/ --output_dir=output/results --device=GPU
image_dir参数就是想要识别的图片目录,把要识别的图片放到这个文件夹下,运行命令,识别结果就会输出到output_dir配置的目录下。
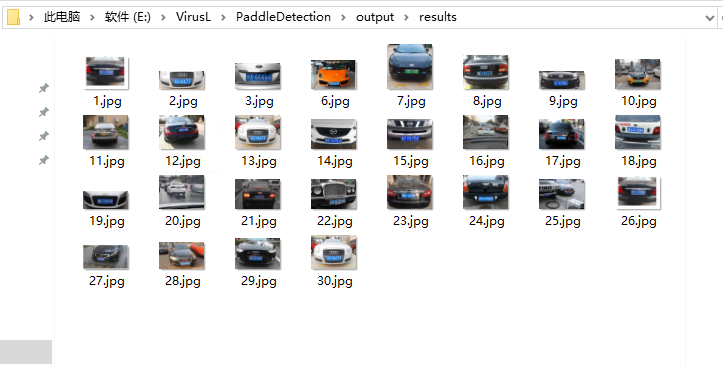
打开一张看看,

可以看到i经识别出来了,但是不太精准,这是因为我的模型训练数据太少了,我一共就标注了30张图片,这是远远不够的,我后来在项目中测试,想要准确度高一定要达到每个场景的图片要在100张以上才行,才能够做到识别准确。
但是我们的识别效果已经达到了。
完结,大家有问题可以留言。