大数据计算引擎(一)——Spark
介绍
Spark实现了高效的DAG执行引擎,可以通过基于内存,多线程来高效处理数据流,Spark基于内存的运算要快100倍以上,基于硬盘的运算也要快10倍以上。Cluster Manager 是集群资源的管理者。Spark支持3种集群部署模式:Standalone、Yarn、Mesos;Worker Node 工作节点,管理本地资源;Driver Program。运行应用的 main() 方法并且创建了 SparkContext。由Cluster Manager分配资源,SparkContext 发送 Task 到 Executor 上执行;Executor:在工作节点上运行,执行 Driver 发送的 Task,并向 Driver 汇报计算结果;
RDD(可分区的,可序列化的,可缓存,可容错,有依赖的,可广播的弹性分布式数据集)
序列化
在实际开发中会自定义一些对RDD的操作,此时需要注意的是
- 初始化工作是在Driver端进行的
- 实际运行程序是在Executor端进行的
这就涉及到了进程通信,是需要序列化的。
依赖
Lineage(血统)是RDD(弹性分布式数据集)之间依赖关系的完整记录。它如同一个族谱,精确记录了数据如何通过一系列转换操作从原始状态演变为最终结果。
Lineage的核心作用
容错恢复:当节点故障导致数据丢失时,Spark根据Lineage重新计算丢失的数据
执行优化:Spark利用Lineage创建高效的执行计划(DAG)
惰性计算:Spark延迟执行直到需要结果,Lineage记录所有待执行操作
高效存储:不需要复制数据,只需记录转换关系
Lineage的两种依赖关系
依赖类型
特点
图示
例子
窄依赖
每个父RDD分区最多被一个子RDD分区使用
父分区 → 子分区
map(), filter(), union()
宽依赖
每个父RDD分区被多个子RDD分区使用(需要Shuffle)
父分区 → 多个子分区
groupByKey(), reduceByKey(), join()
缓存
persist、cache、unpersist
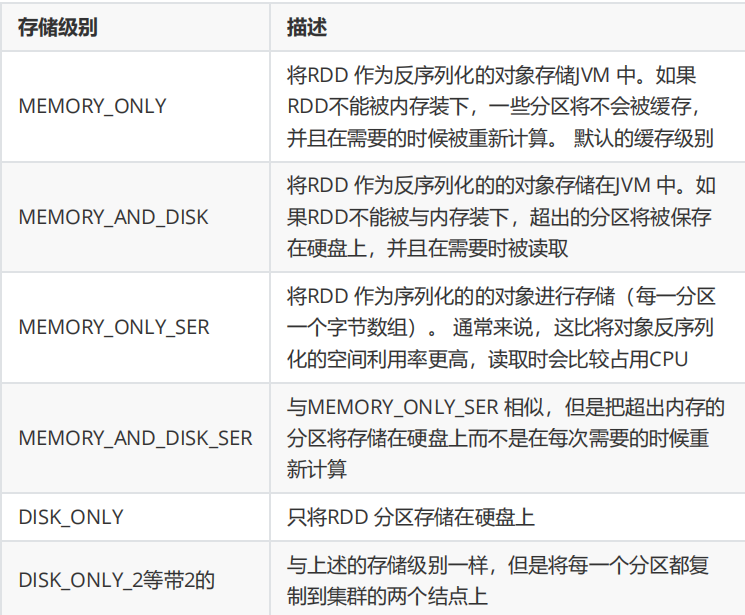
容错
checkpoint 是把 RDD 保存在 HDFS中,是多副本可靠存储,此时依赖链可以丢掉,斩断了依赖链。
分区
本地模式:spark-shell --master local[N] spark.default.parallelism = N
伪分布式:spark-shell --master local-cluster[x,y,z] spark.default.parallelism = x * y
分布式模式:spark.default.parallelism = max(应用程序持有executor的core总数, 2)
经过上面的规则,就能确定了spark.default.parallelism的默认值(配置文件spark-default.conf中没有显示的配置。如果配置了,则spark.default.parallelism = 配置的值)SparkContext初始化时,同时会生成两个参数,由上面得到的spark.default.parallelism推导出这两个参数的值:// 从集合中创建RDD的分区数sc.defaultParallelism = spark.default.parallelism// 从文件中创建RDD的分区数sc.defaultMinPartitions = min(spark.default.parallelism, 2)// 查看rdd分区数rdd.getNumPartitions
分区器
只有Key-Value类型的RDD才可能有分区器,Value类型的RDD分区器的值是None。HashPartitioner:最简单、最常用,也是默认提供的分区器。对于给定的key,计算其hashCode,并除以分区的个数取余,如果余数小于0,则用 余数+分区的个数,最后返回的值就是这个key所属的分区ID。该分区方法可以保证key相同的数据出现在同一个分区中。用户可通过partitionBy主动使用分区器,通过partitions参数指定想要分区的数量。RangePartitioner:简单的说就是将一定范围内的数映射到某一个分区内。在实现中,分界的算法尤为重要,用到了水塘抽样算法。sortByKey会使用RangePartitioner。自定义分区器:
class MyPartitioner(n: Int) extends Partitioner{ override def numPartitions: Int = n override def getPartition(key: Any): Int = { val k = key.toString.toInt k / 100 } }
广播
广播变量将变量在节点的 Executor 之间进行共享(由Driver广播出去);广播变量用来高效分发较大的对象。向所有工作节点(Executor)发送一个较大的只读值,以供一个或多个操作使用。 使用广播变量的过程如下:
- 对一个类型 T 的对象调用 SparkContext.broadcast 创建出一个 Broadcast[T]对象。 任何可序列化的类型都可以这么实现(在 Driver 端)
- 通过 value 属性访问该对象的值(在 Executor 中)
- 变量只会被发到各个 Executor 一次,作为只读值处理
val productBC = sc.broadcast(productRDD.collectAsMap())val productInfo = productBC.value
累加器
累加器的作用:可以实现一个变量在不同的 Executor 端能保持状态的累加;累计器在 Driver 端定义,读取;在 Executor 中完成累加;累加器也是 lazy 的,需要 Action 触发;Action触发一次,执行一次,触发多次,执行多次;累加器一个比较经典的应用场景是用来在 Spark Streaming 应用中记录某些事件的数量;LongAccumulator 用来累加整数型DoubleAccumulator 用来累加浮点型CollectionAccumulator 用来累加集合元素val acc1 = sc.longAccumulator("totalNum1") val acc2 = sc.doubleAccumulator("totalNum2") val acc3 = sc.collectionAccumulator[String]("allWords") val rdd = data.map { word => acc1.add(word.length) acc2.add(word.length) acc3.add(word) word } rdd.count rdd.collect println(acc1.value) println(acc2.value) println(acc3.value)
作业提交
spark-submit \ --master yarn \ --deploy-mode cluster \ --name my-spark-job \ --class com.example.MyApp \ --executor-memory 4g \ --driver-memory 2g \ --executor-cores 2 \ --num-executors 10 \ --queue production \ --conf spark.yarn.maxAppAttempts=3 \ my-application.jar \ arg1 arg2作业提交原理
- 客户端提交作业:spark-submit --master yarn --deploy-mode cluster --class ... 客户端将作业提交给 YARN ResourceManager(RM)。
- RM 在集群的某个 NodeManager(NM)上启动一个容器(Container),并在此容器中运行 ApplicationMaster(即 Spark Driver)。
- Driver 在容器内启动,并向 RM 申请资源(Executor 容器)。
- RM 分配多个容器给 AM。
- AM 与 NodeManagers 通信,在分配的容器中启动 Executor 进程。
- Executors 向 Driver 注册。(反向注册)
- Driver 将任务分发给 Executors 执行。
- 客户端可断开连接,作业在集群内独立运行。
- 作业完成后,AM 释放资源并退出。
Shuffle原理
Shuffle是MapReduce计算框架中的一个特殊的阶段,介于Map 和 Reduce 之间。当Map的输出结果要被Reduce使用时,输出结果需要按key排列,并且分发到Reducer上去,这个过程就是shuffle。
- Hash Shuffle V1:每个Shuffle Map Task需要为每个下游的Task创建一个单独的文件;Shuffle过程中会生成海量的小文件。同时打开过多文件、低效的随机IO
- Hash Base Shuffle V2 核心思想:允许不同的task复用同一批磁盘文件,有效将多个 task的磁盘文件进行一定程度上的合并,从而大幅度减少磁盘文件的数量,进而提升 shuffle write的性能。一定程度上解决了Hash V1中的问题,但不彻底。
- Sort Base Shuffle大大减少了shuffle过程中产生的文件数,提高Shuffle的效率;
调优
RDD复用,缓存/持久化,巧用filter,使用高性能算子,设置合理并行度,广播大变量;
SQL
DataFrame = RDD[Row] + Schema;
Dataset(Dataset = RDD[case class].toDS)sql语句:SparkSQL更简洁。val ds: Dataset[Info] = spark.createDataset(rdd) ds.createOrReplaceTempView("t1") spark.sql( """ |select id, tag | from t1 | lateral view explode(split(tags, ",")) t2 as tag |""".stripMargin).show
感谢阅读!!!