【金融数据分析】用Python对金融产品价格进行时间序列分解
时间序列分解(Time series decomposition)指的是一种将时间序列数据分解成不同组成部分的方法。这种分解通常包括以下几个主要组成部分:
- 趋势(Trend):时间序列中长期变化的模式。趋势部分表示时间序列数据的长期平均水平,显示出数据随时间变化的总体趋势。
- 季节性(Seasonality):时间序列中重复出现的周期性模式。这表示数据随时间变化的周期性波动,例如每天、每周、每月或每年的变化模式。
- 循环(Cycles):时间序列中不规则但非周期性的波动。这些波动不与季节性模式相关,可能由于长期趋势或其他因素导致。
- 残差(Residual):残余部分是时间序列中未能由趋势、季节性和循环解释的部分,也被称为随机噪声。这表示无法被其他部分所解释的数据变化。
时间序列分解有助于理解时间序列数据中包含的不同成分和模式,从而使我们能更好地对数据进行建模、预测和分析。利用分解后的部分,可以更准确地了解数据的特点,并更好地构建预测模型。
为了学习如何使用Python进行时间序列分解,我们可以新建一个Jupyter Notebook,并导入需要用的库以及对可视化部分进行一些设置。这部分代码在前面的章节已经有所涉及,这里就不重复展示了。有需要的读者可以参见前两章的代码或下载随书附赠的本章代码进行研究。
直观观察时间序列数据的季节性模式
现在我们就开始准备实验用的数据,这次我们调用AKShare的接口获取北京碳排放权交易行情数据。使用的代码如下:
# 这里我们选择获取北京能源指数数据
df = ak.energy_carbon_domestic(symbol="北京")#为了方便读者下载使用,保存为Excel文件
df.to_excel('北京能源指数数据.xlsx', index=False)# 如果读者使用下载的Excel文件,用这行代码进行读取
df = pd.read_excel('北京能源指数数据.xlsx')#将日期设置为index
df.set_index('日期', inplace=True)
# 选择2014年1月1日至2020年12月31日的范围
df = df['2014-01-01':'2020-12-31']
#检查数据
df.info()
运行这段代码,会得到如下所示的结果:
<class 'pandas.core.frame.DataFrame'>
DatetimeIndex: 1890 entries, 2014-01-01 to 2020-12-31
Data columns (total 4 columns):# Column Non-Null Count Dtype
--- ------ -------------- ----- 0 成交价 1890 non-null float641 成交量 1890 non-null int64 2 成交额 1890 non-null float643 地点 1890 non-null object
dtypes: float64(2), int64(1), object(1)
memory usage: 73.8+ KB
在上面的代码中,我们获取了北京碳排放权交易的行情数据,并选择了从2014年1月1日至2020年12月31日的时间范围,且将日期设置为其索引(index)。最后我们使用.info()检查数据的信息——可以看到,数据框中共有1890条记录,而每个字段中都有1890条非空数据。也就是说,该数据框中没有空值,这就省去了填补空值的工作了。
为了直观地观察该数据是否存在季节性模式,我们可以使用第3章学过的代码对其进行可视化。具体如下:
#提取index中的年份并保存为新列
df["year"] = df.index.year#提取index中的月份并保存为新列
df["month"] = df.index.strftime("%b")import seaborn as snsplt.figure(dpi = 300)
sns.lineplot(data=df, x="month",y="成交价", hue="year", style="year", legend="full", palette="colorblind")
plt.title("北京能源指数 - 季节性模式")
plt.legend(loc='best')
plt.savefig('图6-1.jpg', dpi=300)
plt.show()
运行这段代码,可以得到如图所示的结果。
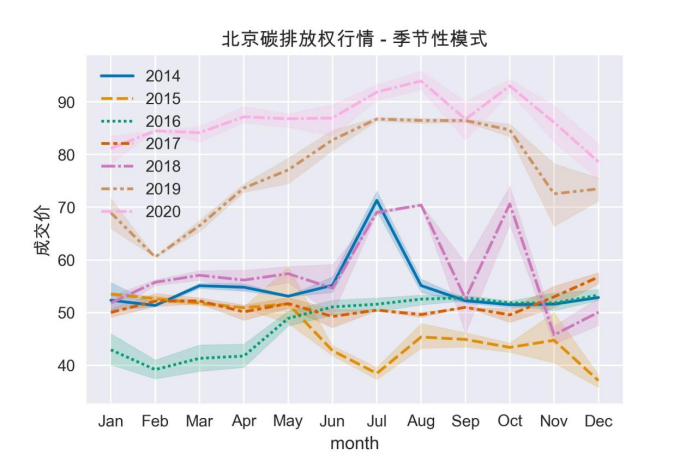
上面的代码创建了一个折线图,用于展示不同月份中北京市碳排放权交易成交价的变化,并使用不同的颜色和线型来区分不同年份的数据。直觉来看,在大部分年份中,似乎6-7月份的成交价都有所上升,但也有两年是例外的情况。
对数据进行滚动统计
在进行时间序列分解时,滚动统计是一种常用的预处理方法,可以消除一些不规则的波动或周期性的噪音,有助于更好地展现出时间序列的潜在模式。滚动统计将通过计算滚动窗口内的统计数据来平滑数据。
这种平滑化可以有助于减少噪音,使得时间序列中的潜在模式更易于识别和分析。这样做也可以使分解模型更准确,因为它可以帮助识别真正的趋势和季节性变化,而非噪音或随机波动。
常用的滚动统计方法包括滚动均值、滚动标准差等。这些方法对于光滑时间序列并去除短期内的波动和噪音非常有用,使得时间序列更加适合于接下来的分解分析。
接下来,我们可以在ChatGPT的帮助下,对前面的北京碳排放权交易行情数据进行滚动统计。使用提示词“现在有一个dataframe,日期为index,其中一列是成交价。我需要先将其重新采样,变成以月度为单位,每个月度中存储该月成交价均值的dataframe。然后在这个新的dataframe中添加两个列,分别是12个月的滚动均值和滚动标准差,请给出示例代码”。发送提示词,会得到ChatGPT生成的代码,经修改后如下:
# 以月度重新采样为均值
df = df[['成交价']]
monthly_df = df.resample('M').mean()# 计算12个月的滚动均值和滚动标准差
monthly_df['Rolling_Mean'] = monthly_df['成交价'].rolling(window=12).mean()
monthly_df['Rolling_Std'] = monthly_df['成交价'].rolling(window=12).std()# 输出包含滚动均值和滚动标准差的dataframe最新5条
monthly_df.tail()
运行这段代码,会得到如表所示的结果。
| 日期 | 成交价 | Rolling_Mean | Rolling_Std |
|---|---|---|---|
| 2020-08-31 | 93.975714 | 84.484803 | 6.335345 |
| 2020-09-30 | 86.711819 | 84.505330 | 6.342740 |
| 2020-10-31 | 93.042000 | 85.201932 | 6.806107 |
| 2020-11-30 | 86.094763 | 86.330226 | 5.519682 |
| 2020-12-31 | 78.629130 | 86.758297 | 4.547034 |
上面的示例代码将时间序列数据按月度重新采样为均值,然后使用 rolling 函数计算了成交价的12个月滚动均值和滚动标准差,并将它们存储在新的DataFrame monthly_df中。大家可以根据实际数据对示例代码进行相应调整。
接下来我们再用可视化的方法对结果进行观察,使用的代码非常简单:
monthly_df.plot(figsize=(15,10))
plt.savefig('图6-2.jpg', dpi=300)
运行代码,会得到如图所示的结果。
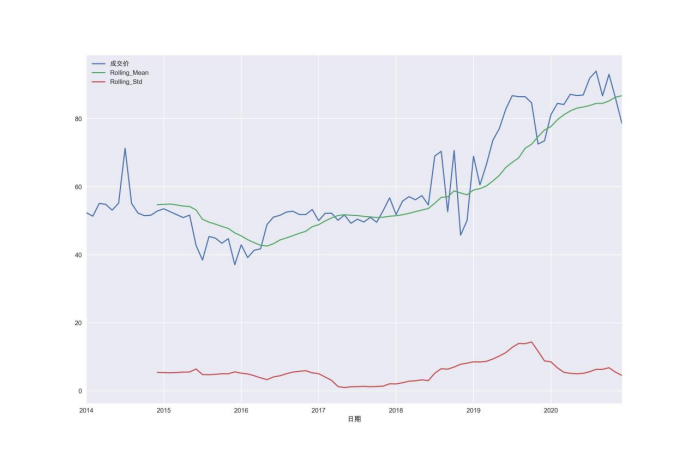
上面的代码中,我们根据数据框monthly_df中的数据绘制了一个折线图。在这种情况下,由于我们已经对成交价进行了月度重新采样,并计算了滚动均值和滚动标准差,因此这个绘图包括了月度成交价、12个月滚动均值和滚动标准差的趋势线。如果我们想观察时间序列数据和相关的滚动统计变化趋势,这种绘图方式可以提供一个全面的视觉呈现。
使用“加法模型”进行季节性分解
加法模型是时间序列分解方法之一,用于将时间序列数据分解为不同的组成部分。这种模型假定时间序列数据是由几个部分相加而成,通常包括:
- 趋势(Trend):描述数据随时间变化的长期趋势,是数据的总体增长或减少的部分。
- 季节性(Seasonality):描述数据基于季节性或周期性变化的部分,这些是数据在特定时间段内出现的重复模式。
- 残差(Residual):不由趋势和季节性解释的部分,代表了趋势和季节性模型无法解释的随机波动。
加法模型假设这些部分是独立的,并且未来的趋势、季节性和残差的变化与时间无关,可以简化对数据的理解和预测。
数学上,一个时间序列可以表示为加法模型的总和:
时间序列 = 趋势 + 季节性 + 残差
此方法的目的是将数据中的这些部分分离出来,使数据的趋势、季节性和随机性更加清晰。
接下来,我们可以在ChatGPT的协助下,对时间序列数据进行季节分解,使用提示词“还是上面的monthly_df,我希望使用additive model对其进行季节分解,并将结果进行可视化,请给出示例代码”。发送提示词,会得到ChatGPT生成的代码,经修改后如下:
# 这里用到statsmodels
import statsmodels.api as sm# 使用加法模型进行季节分解
decomposition = sm.tsa.seasonal_decompose(monthly_df['成交价'],model='additive')
decomposition.plot()
plt.savefig('图6-3.jpg', dpi=300)
plt.show()
运行代码,我们会得到如图所示的结果。
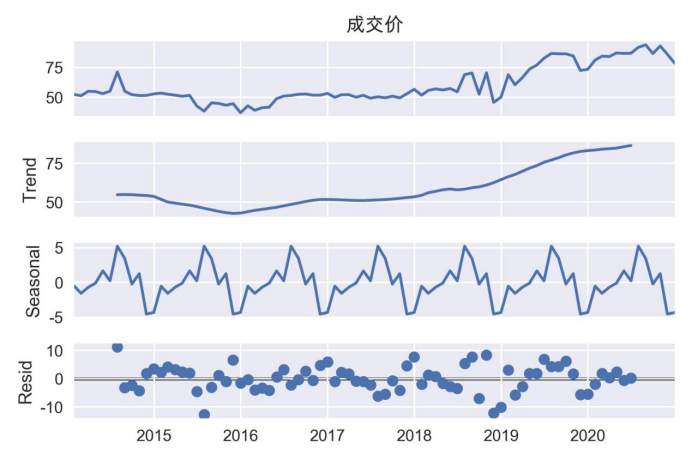
我们的这段代码使用了 statsmodels 库的 seasonal_decompose 函数对 monthly_df 数据框中名为“成交价”的列执行加法模型的季节性分解。最后,绘制了分解结果,展示趋势、季节性和残差。从图6-3中可以看到,“Trend”展示了数据的长期趋势,即原始数据中除去季节性和残差部分的变化趋势。可以看到在这几年中,北京碳排放权的成交价是逐年上涨的;而“Seasonal”季节性图显示了数据中季节性变化的模式,“Resid”残差图则显示了分解后未能解释的随机波动。
参考书目
北京大学出版社《巧用AI大模型轻松学会Python金融数据分析》
北京大学出版社《人工智能大模型:机器学习基础》