论文阅读 2025-8-9 [DiC, DropKey]
闲来没事,找点近一年的论文看看
1. DiC: Rethinking Conv3x3 Designs in Diffusion Models
✨ 一句话总结:DiC用沙漏架构+稀疏跳跃+条件门控重构纯Conv3x3扩散模型,在速度碾压Transformer的同时性能反超,为实时生成任务开辟新路径。
背景
扩散模型现状:
- 主流架构从CNN-注意力混合(如U-Net)转向纯Transformer(如DiT、U-ViT),生成质量优异但推理速度慢(自注意力计算开销大)。
- 加速尝试(如高效注意力、SSM架构)效果有限,难以满足实时需求。
卷积的潜力:
- Conv3x3是硬件友好的极速操作(支持Winograd加速),但传统设计在扩散模型中性能不足(感受野有限,扩展性差)。
可以看出,这篇论文就是要重新设计CNN的合适结构去解决Diffusion推理慢的问题。
核心问题
如何设计纯Conv3x3架构,使其在扩散模型中同时实现:
✅ 高生成质量(对标Transformer)
✅ 极快推理速度
✅ 强可扩展性(模型增大时性能持续提升)
Motivation
- 卷积的硬件效率远超自注意力,但现有纯Conv3x3扩散模型性能落后。
- 需系统性改进架构与条件机制,释放Conv3x3在生成任务中的潜力。
架构设计
(1)作者死磕conv3x3
选择3x3卷积作为基础操作单元,是因为它速度极快,硬件(GPU)和算法(如Winograd)对其进行了极好的优化,计算量远低于其他卷积类型(如深度可分离卷积),并行度高且内存访问开销小,简单说就是“性价比”最高的基础模块;我们的目标正是仅用这个最简单的积木块来搭建高性能模型。在设计中,我们借鉴了老牌扩散模型(如DDPM的U-Net)中的卷积块结构,但进行了关键简化:直接移除自注意力模块,只保留纯卷积操作。具体而言,每个基本块由GroupNorm、SiLU激活、3x3卷积、GroupNorm、SiLU激活和3x3卷积顺序组成,并采用残差连接(输入直接加到输出上)且通道数保持不变,这构成了纯卷积扩散模型的起点,既保持了结构的简洁高效,又确保了高吞吐量和硬件友好性。
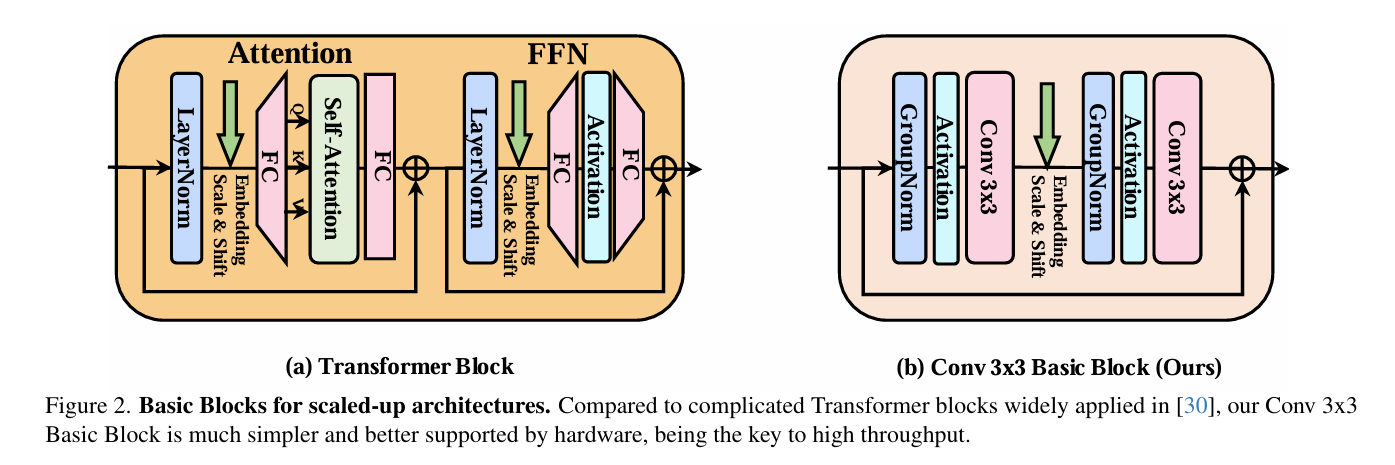
(2)模型结构
现在基础Block设计好了,那么整体的网络应该怎么处理呢?
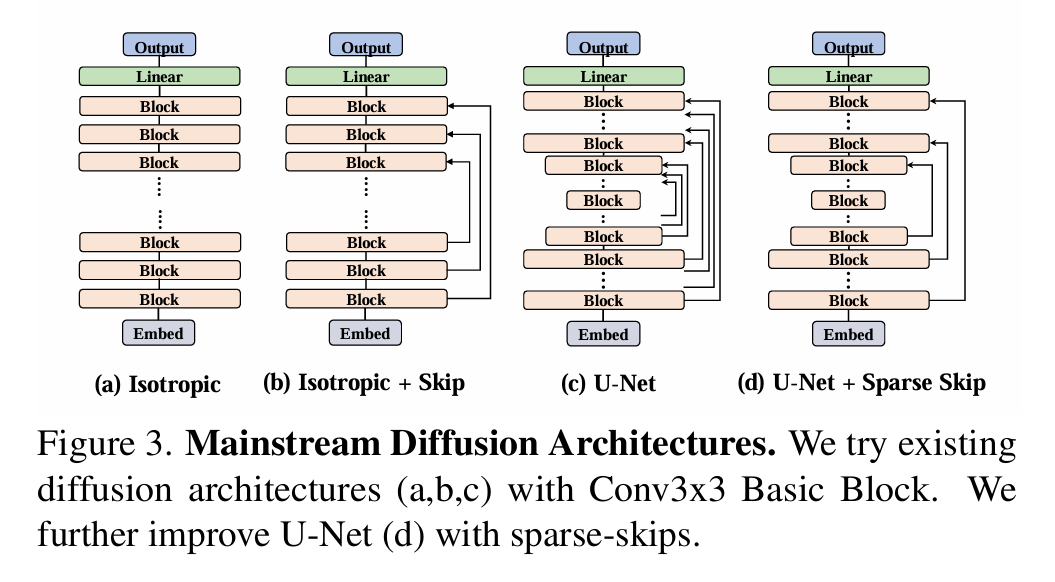
作者探讨了几种网络结构。
(a) 直筒型 (Isotropic): 像 DiT/Transformer 那样,从头到尾特征图大小不变(不上下采样),就是一层层堆叠基本块。结果:最差。 因为 Conv3x3 感受野太小,堆很深才能看到全局,效率低效果差。
(b) 带跳跃的直筒型 (Isotropic + Skip): 还是特征图大小不变,但在堆叠的块之间加长距离跳跃连接(像 U-ViT)。结果:比纯直筒好点,但还不够。
(c)沙漏型/U-Net (U-Net Hourglass): 经典编码器-解码器结构。编码器一路下采样(缩小图,增大感受野),解码器一路上采样(放大图),中间还有密集的跳跃连接(把编码器信息直接传给解码器对应层)。结果:明显最好!
但作者发现,当模型变大变深时,传统 U-Net 这种每层都跳的密集跳跃太“奢侈”了,解码器要处理太多跳过来的信息,又费算力又占内存,很多跳跃其实没多大用,反而拖累模型变大。于是作者想了个新招:稀疏跳跃连接。意思就是别每层都跳,改成隔几层跳一次(比如只跳第一层到第一层、第四层到第四层,中间的二三层不跳)。这样好处很大:跳的连接少了,计算和内存开销大减;去掉没用的跳跃,信息传递更高效;
(3) 剩下的一些小改进
- 个性化条件嵌入 (针对沙漏式网络有效)
老模型(如DDPM)采用单一条件嵌入表(即“一个词表通吃”)为整个U-Net结构提供提示语,但这忽略了U-Net的层级特性:编码器早期层处理高分辨率细节特征(如边缘和纹理),而解码器后期层处理低分辨率整体特征(如物体形状和场景),二者任务迥异,如同让小学生和大学生共用同一本教材,必然导致效果打折;为此,DiC引入分阶段专属词表(Stage-Specific Embeddings)的改进方案,即为U-Net中每个分辨率相同阶段(一组基本块)配置独立的条件嵌入表,使编码器底层能获取适配细节理解的提示、解码器高层能获取适配整体把握的提示,从而显著提升性能(FID指标从11.49降至10.07),而代价仅增加少量参数(14M,占模型总量2%)和计算量(12M FLOPs),相对于整体收益几乎可忽略不计,性价比极高。
- 在哪里设置条件输入?(借助DiT的成功经验)
有两种选择:(1)在模型第一个conv3x3的前面输入(2)在模型第二个conv3x3的前面输入
作者发现在第二个前面会好一点点 (就是图哪里scale and shift的地方)
那么选好了输入的地方,该怎么输入呢?
- 为增强条件响应的灵活性,DiC直接借鉴了Diffusion Transformer (DiT) 中的AdaLN机制,引入条件门控(Conditional Gating),其核心不仅对特征图进行常规的缩放(scale)和平移(shift),还额外学习一个通道维度的门控向量,如同为每个特征通道配置可动态调节的“小开关”,实现更精细的特征调控,使模型能自适应不同条件(如图像类别),进一步将FID降至6.54;尽管该设计非原创,但因其高效易集成且收益显著,成为提升模型性能的关键补充。
- 采用GELU而不是SiLU (借助ConvNeXt的成功经验)
作为一项次要但有效的优化,DiC 模型将原先广泛用于 CNN 的 SiLU(Swish)激活函数统一替换为 Transformer 领域标配的 GELU;这一改动直接借鉴了 ConvNeXt 的成功经验(该工作通过引入 Transformer 风格组件显著提升了 CNN 性能),在 DiC 的纯卷积结构中验证有效——尽管提升幅度有限,却能稳定优化生成质量(FID 指标从 6.54 降至 6.26);作者虽知存在更新的激活函数候选,但为兼顾实现简单性与训练稳定性,最终选择了经过大规模实践验证的 GELU,以最小代价换取可靠收益。
2. DropKey
最近在小红书刷到一个特别有意思的帖子,为什么自己写的多头自注意力机制不够torch自带的MultiheadAttention好呢?
贴主给出了需要注意的点:
- 多头注意力的Dropout并不是drop掉输出,而是drop掉attn_weight
这个Trick是cvpr2023 DropKey这篇论文提出的,讲了ViT通过Drop掉权重(也就是drop掉Key,为什么不叫DropWeight,我不懂)而不是softmax之后的值。
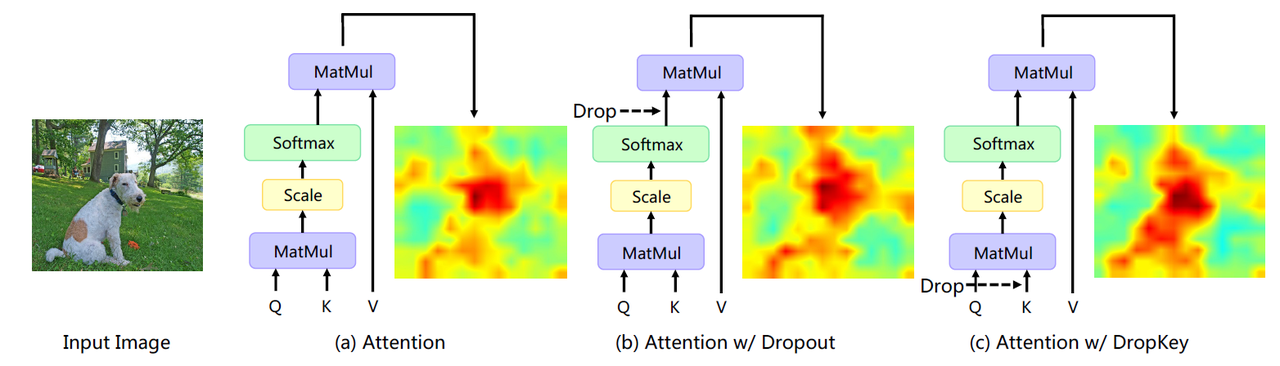
具体的实现是很简单的几行代码:

我看了一下torch实现的代码,现在的drop确实是drop掉weight,而不是softmax之后的值。
这篇论文还讲了蒙特卡洛算法来bridge因为drop导致的train和test之间的代沟,我看一下这部分的内容,额外学习一下。
同时作者还论证了随着层数的增加,dropout的概率应该降低,这让模型学习得更好:
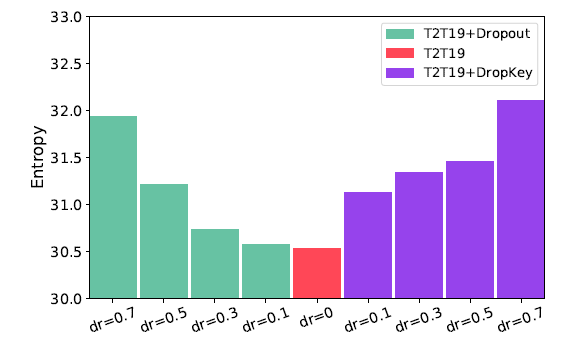
小的熵值表示模型更聚焦于sparse patches,由于class token对于聚合整张图的信息有帮助,这里计算它的熵作为模型提取全局信息能力的度量。从这个图可以看出,当Dropout变小的时候,模型提取全局信息能力更强,因此后续的层dropout应该小一些。
- 这里实验的具体实现应该就是:计算 cls-token 和其他image patch token的attention weight,因为weight是0-1的一个概率,我们可以把它输入进去这个熵的公式,然后得到这个token的熵,最后所有token的熵求一个平均。如果是多头注意力,那么就每个头再求一次平均。
- 低熵值:意味着向量中只有少数几个权重值很大,其他都很小。这表示该注意力头高度聚焦在少数几个关键的图像块上(sparse patches)。
- 高熵值:意味着向量中所有权重值都比较平均。这表示该注意力头将注意力平滑地分散在更多的图像块上,关注的是更全局的特征。
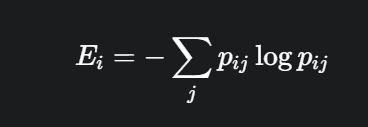
但是作者页论证了dropkey的一些不足:
- 未对齐的期望 [推理阶段没有 Dropout] 会对模型产生一定的负面影响,因此作者使用两种方法来对齐期望。
- 第一种,用蒙特卡罗法估算,通过执行多次随机下降,并在每次下降操作后计算注意力权重矩阵。 最后,将计算出的多重权重矩阵的平均值用作下一步的输入。
- 第二个,在没有 DropKey 的情况下微调模型,作为 DropKey 训练后的额外阶段。作者通过实验验证第二种策略的性能更好。