moe并行
混合专家模型 (MoE) 详解
1.MOE
通常来讲,模型规模的扩展会导致训练成本显著增加,计算资源的限制成为了大规模密集模型训练的瓶颈。为了解决这个问题,一种基于稀疏 MoE 层的深度学习模型架构被提出,即将大模型拆分成多个小模型(专家,expert), 每轮迭代根据样本决定激活一部分专家用于计算,达到了节省计算资源的效果; 并引入可训练并确保稀疏性的门控( gate )机制,以保证计算能力的优化。
与密集模型不同,MoE 将模型的某一层扩展为多个具有相同结构的专家网络( expert ),并由门控( gate )网络决定激活哪些 expert 用于计算,从而实现超大规模稀疏模型的训练。
以下图为例,模型包含 3 个模型层,如(a)到(b)所示,将中间层扩展为具有 n 个 expert 的 MoE 结构,并引入 Gating network 和 Top_k 机制,MoE 细节如下图©所示。
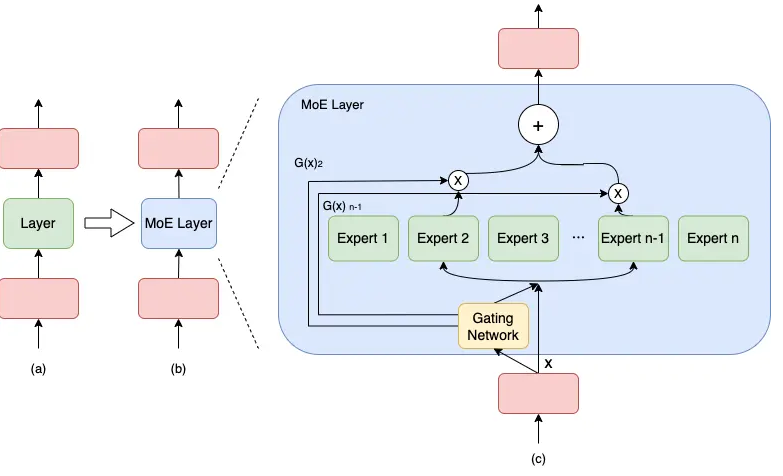
计算过程如下述公式:
M o E ( x ) = ∑ i = 1 n G ( x ) i E i ( x )