BEVFusion(2022-2023年)版本中文翻译解读+相关命令
Abstract
将相机和激光雷达信息融合已成为三维目标检测任务的事实标准。当前方法依赖于激光雷达传感器生成的点云作为查询,以利用图像空间中的特征。然而,人们发现,这种潜在假设使得当前的融合框架在激光雷达发生故障(无论是轻微还是严重)时,无法生成任何预测。这从根本上限制了其在真实自动驾驶场景中的部署能力。
与此相反,我们提出了一种令人惊讶的简洁而新颖的融合框架,命名为BEVFusion。其相机流不依赖于激光雷达数据的输入,从而解决了现有方法的弊端。我们实验证明,在正常训练设置下,我们的框架超越了最先进的方法。在模拟各种激光雷达故障的鲁棒性训练设置下,我们的框架在mAP(平均精度均值)方面显著超越了最先进的方法15.7%至28.9%。据我们所知,我们是第一个处理真实激光雷达故障、并且无需任何后处理程序即可部署到实际场景中的工作。代码已开源:
代码地址:代码地址
Introduction
基于视觉的感知任务,例如在三维空间中检测边界框,一直是全自动驾驶任务的关键方面。在传统车载视觉感知系统的所有传感器中,激光雷达和相机通常是提供周围世界精确点云和图像特征的两个最关键的传感器。在感知系统早期,人们为每个传感器设计了独立的深度模型,并通过后处理方法融合信息。值得注意的是,人们发现鸟瞰图(BEV)已成为自动驾驶场景的事实标准,因为一般来说,汽车不能飞行。然而,由于缺乏深度信息,仅凭图像输入通常难以回归三维边界框;类似地,当激光雷达未接收到足够的点时,在点云上分类对象也很困难。
最近,人们设计了激光雷达-相机融合深度网络,以更好地利用两种模态的信息。具体而言,大多数工作可以概括如下:
i) 给定激光雷达点云中的一个或几个点、激光雷达到世界坐标的变换矩阵和本质矩阵(相机到世界坐标);
ii) 人们将激光雷达点 或候选区域 转换到相机世界坐标并将其用作查询,以选择相应的图像特征。
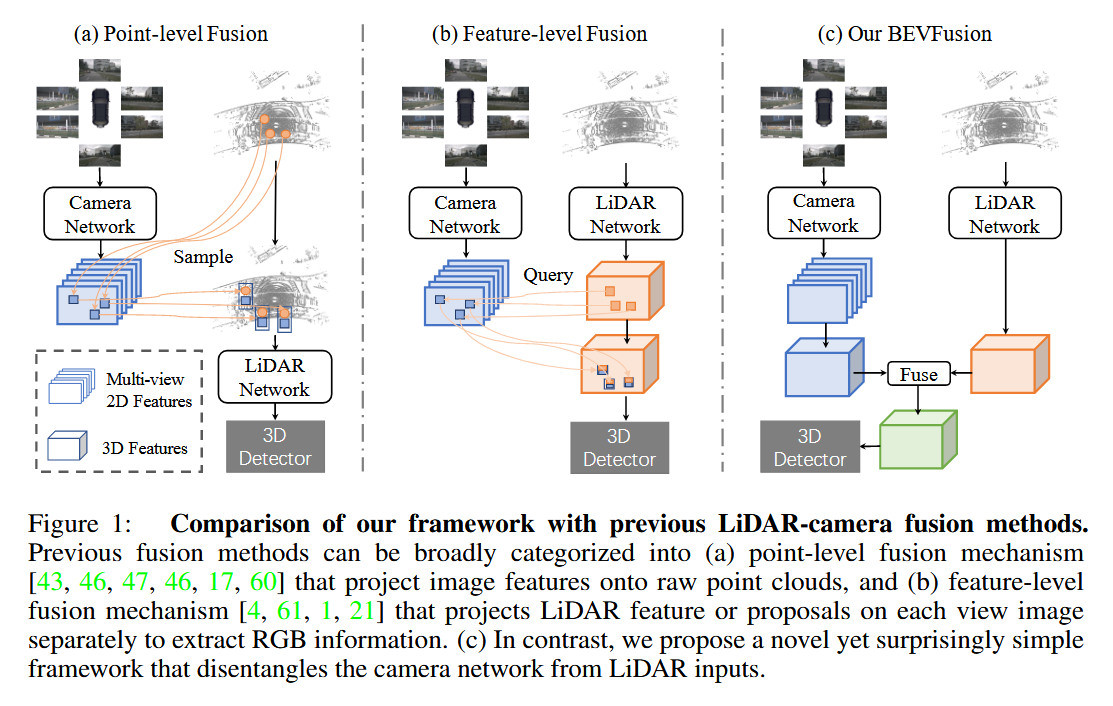
这一系列工作构成了三维BEV感知的最先进方法。然而,人们忽略了一个潜在的假设,即由于需要从激光雷达点生成图像查询,当前的激光雷达-相机融合方法本质上依赖于激光雷达传感器的原始点云,如图1所示。在现实世界中,人们发现如果激光雷达传感器输入缺失,例如由于物体纹理导致激光雷达点反射率低、内部数据传输的系统故障,甚至由于硬件限制激光雷达传感器的视场无法达到360度,当前的融合方法就无法产生有意义的结果1。这从根本上阻碍了这类工作在实际自动驾驶系统中的应用。
我们认为理想的激光雷达-相机融合框架应该是:每种模态的模型不应因其他模态的存在与否而失效,但两种模态同时存在将进一步提高感知精度。为此,我们提出了一种令人惊讶的简洁而有效的框架,该框架解耦了当前方法的激光雷达-相机融合依赖性,命名为BEVFusion。具体而言,如图1©所示,我们的框架具有两个独立的流,将来自相机和激光雷达传感器的原始输入编码到相同BEV空间中的特征。然后,我们设计了一个简单的模块,在这两个流之后融合这些BEV级别的特征,以便最终特征可以传递给现代任务预测头架构。
由于我们的框架是一种通用方法,我们可以将当前用于相机和激光雷达的单模态BEV模型整合到我们的框架中。我们适度地采用Lift-Splat-Shoot 作为我们的相机流,它将多视角图像特征投影到三维自车坐标特征,以生成相机BEV特征。类似地,对于激光雷达流,我们选择了三种流行的模型,两种基于体素的和一种基于柱状的,将激光雷达特征编码到BEV空间中。
相机Backbone:Lift-Splat-Shoot(LSS)作为其相机流的主干网络,将多视角的图像特征投影到三维车坐标系中的特征,生成相机在BEV空间中的特征。
雷达Backbone:
- 基于体素的(Voxel-based)
- 将点云离散化为三维体素网络,将这些应用到卷积神经网络进行特征提取
- 论文中用的是典型网络CenterPoint
- 基于柱状的(Pillar-based)
- 将激光雷达点云离散化为二维柱状体
- 论文中改进的是PointPillars
可以参考博客 【激光雷达3D(6)】3D点云目标检测方法;CenterPoint、PV-RCNN和M3DETR的骨干网络选择存在差异
在nuScenes数据集上,我们简单的框架展示了强大的泛化能力。遵循相同的训练设置,BEVFusion分别将PointPillars和CenterPoint的平均精度均值(mAP)提高了18.4%和7.1%,并取得了69.2% mAP的卓越性能,与被认为是最先进方法的TransFusion 的68.9% mAP相比更优。在鲁棒性设置下,通过以0.5的概率随机丢弃目标边界框内的激光雷达点,我们提出了一种新颖的增强技术,并表明我们的框架显著超越了所有基线,mAP提升了15.7%至28.9%,展示了我们方法的鲁棒性。
我们的贡献总结如下:
i) 我们指出了当前激光雷达-相机融合方法中一个被忽视的限制,即对激光雷达输入的依赖性;
ii) 我们提出了一个简单而新颖的框架,将激光雷达相机模态解耦为两个独立的流,可以推广到多种现代架构;
iii) 我们在正常和鲁棒性设置下都超越了最先进的融合方法。
Related work
在此,我们根据三维检测方法的输入模态对其进行广义分类。
仅相机。 在自动驾驶领域,仅使用相机输入进行三维目标检测在近年来得到了广泛研究,这得益于KITTI基准测试。由于KITTI中只有一个前置摄像头,大多数方法都致力于解决单目三维检测问题。随着拥有更多传感器的自动驾驶数据集(如nuScenes 和 Waymo)的发展,出现了开发多视角图像输入方法 的趋势,这些方法被发现显著优于单目方法。然而,体素处理常常伴随着高计算成本。在常见的自动驾驶数据集中,Lift-Splat-Shoot (LSS) 使用深度估计网络来提取多视角图像的隐含深度信息,并将相机特征图转换为三维自车坐标系。另有一些方法 也受到LSS 的启发,并参考激光雷达来监督深度预测。类似的思想也可以在BEVDet(多视角三维目标检测的最先进方法)中找到。MonoDistill 和 LiGA Stereo 通过将激光雷达信息统一到相机分支来提高性能。
仅激光雷达。 激光雷达方法最初根据其特征模态分为两类:
i) 基于点的方法,直接在原始激光雷达点云上操作;
ii) 将原始点云转换为欧几里得特征空间,如三维体素 和特征柱。
最近,人们开始在单个模型中利用这两种特征模态以增强表示能力。另一类工作是利用鸟瞰图(BEV)平面的优势。
激光雷达-相机融合。 由于激光雷达和相机产生的特征通常包含互补信息,人们开始开发可以对两种模态进行联合优化的方法,并很快成为三维检测的事实标准。如图1所示,这些方法根据其融合机制可分为两类:(a) 点级融合,通过原始激光雷达点查询图像特征,然后将其作为额外的点特征拼接回去;(b) 特征级融合,首先将激光雷达点投影到特征空间 或生成候选区域,查询相关的相机特征,然后拼接回特征空间。后者构成了三维检测的最先进方法,具体而言,TransFusion 使用激光雷达特征的边界框预测作为候选区域来查询图像特征,然后采用类似Transformer的架构将信息融合回激光雷达特征。类似地,DeepFusion 将激光雷达特征投影到每个视角图像上作为查询,然后利用交叉注意力进行两种模态的融合。
然而,当前融合机制的一个被忽视的假设是它们严重依赖激光雷达点云,事实上,如果激光雷达输入缺失,这些方法将不可避免地失效。这将阻碍此类算法在现实场景中的部署。与此相反,我们的BEVFusion是一种令人惊讶的简洁而有效的融合框架,它通过将相机分支与激光雷达点云解耦,从根本上克服了这个问题,如图1©所示。此外,同期工作 也解决了这个问题,并提出了有效的激光雷达-相机三维感知模型。
其他模态。 还有其他工作利用其他模态,例如通过特征图拼接融合相机-雷达。尽管这些方法很有趣,但它们超出了我们工作的范围。尽管同期工作 旨在在单个网络中融合多模态信息,但其设计仅限于一个特定的检测头,而我们的框架可以推广到任意架构。
BEVFusion: A General Framework for LiDAR-Camera Fusion
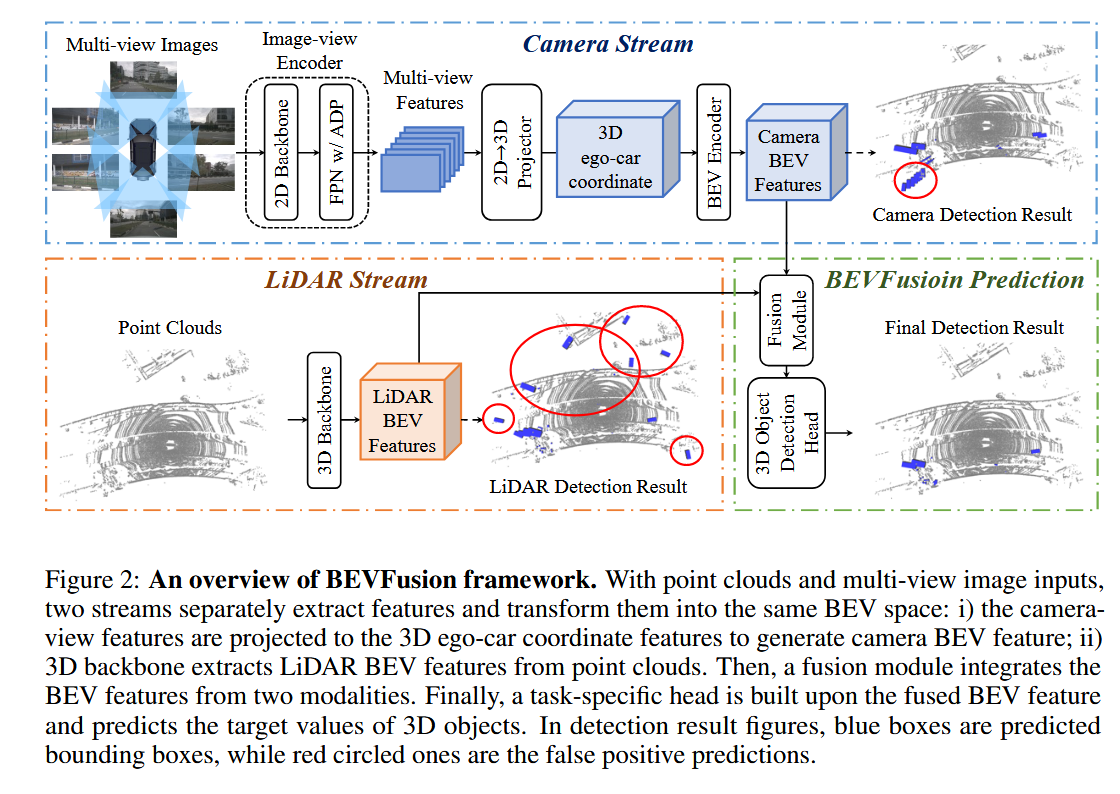
3.1 Camera stream architecture: From multi-view images to BEV space
由于我们的框架能够整合任何相机流,我们从一种流行的方法Lift-Splat-Shoot(LSS)开始。由于LSS最初是为BEV语义分割而非三维检测提出的,我们发现直接使用LSS架构会导致性能不佳,因此我们对LSS进行了适度修改以提高性能(详见第4.5节消融研究)。在图2(顶部),我们详细设计了我们的相机流,包括一个图像视图编码器,用于将原始图像编码为深层特征;一个视图投影模块,用于将这些特征转换为3D自我车辆坐标;以及一个编码器,最终将特征编码到鸟瞰图(BEV)空间。
图像视图编码器(Image-view Encoder)旨在将输入图像编码为语义信息丰富的深层特征。它由一个用于基本特征提取的2D骨干网络和一个用于尺度可变对象表示的颈部模块组成。与LSS使用卷积神经网络ResNet作为骨干网络不同,我们使用了更具代表性的Dual-Swin-Tiny作为骨干。遵循,我们在骨干网络之上使用标准特征金字塔网络(FPN)来利用多尺度分辨率的特征。为了更好地对齐这些特征,我们首次提出了一个简单的特征自适应模块(ADP)来细化上采样特征。具体来说,我们对每个上采样特征应用自适应平均池化和1 × 1卷积,然后再进行拼接。详细模块架构请参见附录A节。
视图投影模块(2D->3D Projector)。由于图像特征仍处于2D图像坐标中,我们设计了一个视图投影模块来将它们转换为3D自我车辆坐标。我们应用中提出的2D → 3D视图投影来构建相机BEV特征。所采用的视图投影模块将图像视图特征作为输入,并通过分类方式密集预测深度。然后,根据相机外参和预测的图像深度,我们可以推导出图像视图特征,以在预定义的点云中进行渲染,并获得一个伪体素V∈R(X×Y×Z×C)V ∈ R^(X×Y×Z×C)V∈R(X×Y×Z×C)。
BEV编码器模块(BEV encoder)。为了进一步将体素特征V∈R(X×Y×Z×C)V ∈ R^(X×Y×Z×C)V∈R(X×Y×Z×C)编码为BEV空间特征(FCamera∈R(X×Y×CCamera))(F_Camera ∈ R^(X×Y×C_Camera))(FCamera∈R(X×Y×CCamera)),我们设计了一个简单的编码器模块。我们没有应用池化操作或堆叠步长为2的3D卷积来压缩z维度,而是采用空间到通道(S2C)操作通过重塑将V从4D张量转换为3D张量V∈R(X×Y×(ZC))V ∈ R^(X×Y×(ZC))V∈R(X×Y×(ZC)),以保留语义信息并降低成本。然后,我们使用四个3×3卷积层逐步将通道维度减少到CCameraC_{Camera}CCamera并提取高级语义信息。与LSS基于下采样的低分辨率特征提取高级特征不同,我们的编码器直接处理全分辨率相机BEV特征,以保留空间信息
3.2 LiDAR stream architecture: From point clouds to BEV space
同样,我们的框架可以整合任何将激光雷达点转换为BEV特征(FLiDAR∈R(X×Y×CLiDARF_{LiDAR} ∈ R^(X×Y×C_{LiDAR}FLiDAR∈R(X×Y×CLiDAR)的网络作为我们的激光雷达流。一种常见的方法是学习原始点的参数化体素化,以减少Z维度,然后利用包含稀疏3D卷积的网络,高效地在BEV空间中生成特征。在实践中,我们采用三种流行的方法——PointPillars、CenterPoint 和 TransFusion 作为我们的激光雷达流,以展示我们框架的泛化能力。
3.3 Dynamic fusion module
为了有效融合来自相机 (FCamera∈R(X×Y×CCamera))(F_{Camera} ∈ R^(X×Y×C_{Camera}))(FCamera∈R(X×Y×CCamera))和激光雷达 FLiDAR∈R(X×Y×CLiDAR)F_{LiDAR} ∈ R^(X×Y×C_{LiDAR})FLiDAR∈R(X×Y×CLiDAR) 传感器的BEV特征,我们在图3中提出了一个动态融合模块。给定在相同空间维度下的两个特征,一个直观的想法是将它们拼接并通过可学习的静态权重进行融合。受Squeeze-and-Excitation机制 的启发,我们应用了一个简单的通道注意力模块来选择重要的融合特征。我们的融合模块可以表述为:
Ffused=fadaptive(fstatic([FCamera,FLiDAR])),(1)F_{\text{fused}} = f_{\text{adaptive}}(f_{\text{static}}([F_{\text{Camera}}, F_{\text{LiDAR}}])), \quad (1)Ffused=fadaptive(fstatic([FCamera,FLiDAR])),(1)
其中,[·, ·] 表示沿通道维度的拼接操作。fstaticf_{\text{static}}fstatic 是一个静态通道和空间融合函数,通过一个3 × 3卷积层实现,旨在将拼接特征的通道维度降低到CLiDARC_{\text{LiDAR}}CLiDAR。对于输入特征 F∈RX×Y×CLiDARF \in R^{X \times Y \times C_{\text{LiDAR}}}F∈RX×Y×CLiDAR,fadaptivef_{\text{adaptive}}fadaptive 的表述为:
fadaptive(F)=σ(Wfavg(F))⋅F,(2)f_{\text{adaptive}}(F) = \sigma (Wf_{\text{avg}}(F)) \cdot F, \quad (2)fadaptive(F)=σ(Wfavg(F))⋅F,(2)
其中,WWW 表示线性变换矩阵(例如,1x1卷积),favgf_{\text{avg}}favg 表示全局平均池化,σ\sigmaσ 表示sigmoid函数。
3.4 Detection Head
由于我们框架的最终特征位于BEV空间中,我们可以利用早期工作中流行的检测头模块。这进一步证明了我们框架的泛化能力。本质上,我们基于三种流行的检测头类别,即基于锚点的、基于无锚点的 和基于变换的 方法,对我们的框架进行了比较。
下载数据集命令
wget https://motional-nuscenes.s3.amazonaws.com/public/v1.0/v1.0-trainval01_blobs.tgz
wget https://motional-nuscenes.s3.amazonaws.com/public/v1.0/v1.0-trainval02_blobs.tgz
wget -c https://motional-nuscenes.s3.amazonaws.com/public/v1.0/v1.0-trainval03_blobs.tgz
wget https://motional-nuscenes.s3.amazonaws.com/public/v1.0/v1.0-trainval04_blobs.tgz
wget https://motional-nuscenes.s3.amazonaws.com/public/v1.0/v1.0-trainval05_blobs.tgz
wget https://motional-nuscenes.s3.amazonaws.com/public/v1.0/v1.0-trainval06_blobs.tgz
wget https://motional-nuscenes.s3.amazonaws.com/public/v1.0/v1.0-trainval07_blobs.tgz
wget https://motional-nuscenes.s3.amazonaws.com/public/v1.0/v1.0-trainval08_blobs.tgz
wget https://motional-nuscenes.s3.amazonaws.com/public/v1.0/v1.0-trainval09_blobs.tgz
wget https://motional-nuscenes.s3.amazonaws.com/public/v1.0/v1.0-trainval10_blobs.tgz相关命令
# 在mini数据集上准备数据集内容
python tools/create_data.py nuscenes --root-path ./data/nuscenes --out-dir ./data/nuscenes --extra-tag nuscenes --version v1.0-mini
# 使用完整路径
python tools/create_data.py nuscenes --root-path /root/CodeFolder/BEVFusion/bevfusion/data/nuscenes --out-dir /root/CodeFolder/BEVFusion/bevfusion/data/nuscenes --extra-tag nuscenes --version v1.0-mini
# 若报错fork(),则在前面加上这一行
RDMAV_FORK_SAFE=1 torchpack dist-run -np 1 python tools/train.py configs/nuscenes/det/centerhead/lssfpn/camera/256x704/swint/default.yaml --model.encoders.camera.backbone.init_cfg.checkpoint pretrained/swint-nuimages-pretrained.pth --run-dir train_result
# 可视化结果
RDMAV_FORK_SAFE=1 torchpack dist-run -np 1 python tools/visualize.py train_result/configs.yaml --mode gt --checkpoint train_result/latest.pth --bbox-score 0.5 --out-dir vis_resulte