飞算JavaAI结合Redis实现高性能存储:从数据瓶颈到极速读写的实战之旅
引言:当数据访问成为“性能拦路虎”,如何用Redis+飞算JavaAI提速百倍?
在当今数据驱动的应用场景中,从电商平台的实时库存查询、社交网络的用户关系存储,到金融系统的交易记录管理,高频读写、低延迟响应已成为业务系统的刚需。然而,传统关系型数据库(如MySQL)虽擅长事务处理,却在面对海量数据的高并发读写时暴露出明显短板——磁盘I/O瓶颈导致查询延迟飙升(如复杂SQL查询可能需数百毫秒)、写入吞吐量受限(如每秒仅能处理数千次插入),甚至成为系统整体性能的“阿喀琉斯之踵”。
Redis作为基于内存的高性能键值存储数据库,凭借微秒级响应(99%的请求<1ms)、单节点10万+QPS的吞吐能力、灵活的数据结构(如String/Hash/List/Set/ZSet),成为解决高并发存储痛点的“神器”。但Redis的高效使用并非“开箱即用”——开发者需解决数据一致性(如缓存与数据库双写)、缓存击穿/雪崩/穿透、高性能序列化、集群扩展等复杂问题,传统开发中往往需要手动编写大量缓存逻辑代码(如缓存穿透防护的布隆过滤器、多级缓存策略),不仅开发周期长,还容易因编码疏漏导致线上故障。
飞算JavaAI作为智能低代码开发平台,通过可视化缓存配置(拖拽定义缓存规则)、AI辅助代码生成(自动生成Redis集成代码与高并发防护逻辑)和性能优化建议(推荐最优序列化方式、缓存过期策略),彻底降低了Redis高性能存储的开发门槛。开发者无需深入理解Redis底层协议或手动处理复杂缓存场景,即可快速构建**“数据库+Redis”分级存储体系**,实现数据读写性能的百倍提升。
本文将以一个**“电商商品详情页缓存系统”**(典型的高频读写场景)为例,详细讲解如何基于飞算JavaAI结合Redis实现高性能存储,涵盖需求分析、架构设计、核心模块代码逻辑(附关键注释)、流程图/架构图说明,以及如何通过可视化配置解决缓存穿透、雪崩等经典问题。最后通过饼图对比传统手动开发与飞算AI辅助开发的效率差异,直观展现技术价值。
一、项目背景与需求定义:为什么需要Redis高性能存储?
1.1 业务场景:电商商品详情页的高并发挑战
假设我们有一个日均PV(页面访问量)超千万的电商平台,商品详情页是用户访问最频繁的页面之一(占比约60%)。每个商品详情页需要展示以下信息:
- 基础信息:商品ID、名称、价格、库存、描述(频繁读取,几乎每次访问都需查询);
- 扩展信息:用户评价摘要、推荐商品列表、促销活动规则(部分数据更新频率较低);
- 动态数据:实时库存(每秒可能被多个订单修改)、价格变动(促销活动期间频繁调整)。
核心需求:
- 超高并发读取:热门商品(如iPhone 15)每秒可能被数万用户同时访问,需在10ms内返回详情页数据(用户对延迟极其敏感);
- 低延迟写入:库存扣减、价格更新等操作需快速同步到缓存,避免用户看到过期信息;
- 高可用性:缓存系统需支持7×24小时稳定运行,即使数据库短暂故障,也能通过缓存提供基础服务;
- 数据一致性:缓存与数据库需保持最终一致性(如库存修改后,缓存需及时更新或失效)。
1.2 传统存储方案的瓶颈
若仅依赖MySQL等关系型数据库:
- 读取瓶颈:商品表若包含1000万条记录,复杂查询(如关联商品分类、库存表)可能需要50-200ms,无法满足10ms的响应要求;
- 写入瓶颈:高并发库存扣减时,数据库行锁竞争激烈,可能导致请求排队甚至超时;
- 扩展性差:垂直扩展(升级服务器配置)成本高昂,水平扩展(分库分表)复杂度高且影响业务逻辑。
二、系统整体架构设计:Redis如何扛起高性能存储大旗?
2.1 整体架构图(文字描述 + 简化示意图)
系统分为四层,协同实现高性能存储与业务逻辑:
- 客户端层:用户通过浏览器/APP访问商品详情页,发起商品信息查询请求;
- 应用服务层:核心业务逻辑层,负责处理请求、协调缓存与数据库交互;
- 缓存层(Redis):高性能存储层,存储热点商品数据(如基础信息、扩展信息),承担90%以上的读请求;
- 数据层(MySQL):持久化存储层,保存全量商品数据(包括历史版本、事务日志),作为数据的“唯一真相源”。
架构核心逻辑:
- 读操作:优先从Redis缓存读取,若命中则直接返回(响应时间<1ms);若未命中(缓存穿透),则查询MySQL并将结果写入Redis(后续请求直接命中);
- 写操作:先更新MySQL数据库(保证数据持久化),再通过异步/同步方式更新或删除Redis缓存(保证最终一致性);
- 高并发防护:通过飞算JavaAI自动生成的代码,集成**缓存穿透防护(布隆过滤器)、缓存雪崩防护(随机过期时间)、缓存击穿防护(互斥锁)**等机制。
2.2 核心流程图(简化版)
流程说明:
- 缓存命中:90%以上的请求直接从Redis获取数据,实现极致低延迟;
- 缓存未命中:首次访问或缓存过期的请求查询MySQL,再将结果缓存供后续请求使用;
- 写操作(未在图中展示):用户下单扣减库存时,先更新MySQL,再通过消息队列或同步逻辑更新Redis中的库存数据。
三、基于飞算JavaAI的核心模块实现:低代码搞定高性能存储
3.1 模块1:Redis缓存配置与初始化(快速搭建存储环境)
需求细节:
应用启动时需初始化Redis连接池,配置合理的连接参数(如最大连接数、超时时间),并定义商品数据的存储结构(如使用Hash存储商品基础信息,String存储库存数量)。
飞算JavaAI的解决方案:
通过可视化配置工具,开发者可输入Redis服务器地址、端口、密码等参数,AI自动生成连接池配置代码和初始化逻辑。
关键代码逻辑(飞算JavaAI生成的Redis配置类)
// Redis配置类(由飞算JavaAI生成,基于Spring Boot Data Redis)
@Configuration
public class RedisConfig {@Value("${spring.redis.host:localhost}") // 从配置文件读取Redis主机地址,默认localhostprivate String redisHost;@Value("${spring.redis.port:6379}") // 从配置文件读取Redis端口,默认6379private int redisPort;@Value("${spring.redis.password:}") // 从配置文件读取Redis密码(可选)private String redisPassword;@Beanpublic RedisConnectionFactory redisConnectionFactory() {RedisStandaloneConfiguration config = new RedisStandaloneConfiguration(redisHost, redisPort);if (StringUtils.hasText(redisPassword)) {config.setPassword(RedisPassword.of(redisPassword)); // 设置密码}// 配置连接池(Lettuce连接池,高性能且支持异步)LettuceClientConfiguration clientConfig = LettucePoolingClientConfiguration.builder().commandTimeout(Duration.ofSeconds(2)) // 命令超时时间2秒.poolConfig(getPoolConfig()) // 自定义连接池配置.build();return new LettuceConnectionFactory(config, clientConfig);}// 定义连接池参数(最大连接数=100,最大空闲连接数=50,最小空闲连接数=10)private GenericObjectPoolConfig<?> getPoolConfig() {GenericObjectPoolConfig<?> poolConfig = new GenericObjectPoolConfig<>();poolConfig.setMaxTotal(100); // 最大连接数poolConfig.setMaxIdle(50); // 最大空闲连接数poolConfig.setMinIdle(10); // 最小空闲连接数poolConfig.setTestOnBorrow(true); // 获取连接时检测有效性return poolConfig;}@Beanpublic RedisTemplate<String, Object> redisTemplate() {RedisTemplate<String, Object> template = new RedisTemplate<>();template.setConnectionFactory(redisConnectionFactory());// 使用Jackson2JsonRedisSerializer序列化值(支持复杂对象存储)Jackson2JsonRedisSerializer<Object> serializer = new Jackson2JsonRedisSerializer<>(Object.class);ObjectMapper objectMapper = new ObjectMapper();objectMapper.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);objectMapper.activateDefaultTyping(objectMapper.getPolymorphicTypeValidator(), ObjectMapper.DefaultTyping.NON_FINAL);serializer.setObjectMapper(objectMapper);template.setValueSerializer(serializer);template.setKeySerializer(new StringRedisSerializer()); // 键使用String序列化template.setHashKeySerializer(new StringRedisSerializer());template.setHashValueSerializer(serializer);template.afterPropertiesSet();return template;}
}
关键点说明:
- 连接池优化:使用Lettuce连接池(替代传统的Jedis),支持异步操作和更高的并发性能(单节点可处理10万+QPS);
- 序列化策略:键使用
StringRedisSerializer(高效且易读),值使用Jackson2JsonRedisSerializer(支持复杂Java对象存储,如商品详情对象); - 低代码配置:开发者通过
application.yml文件填写Redis地址、端口、密码,AI自动生成对应的连接工厂和模板代码,无需手动编写连接逻辑。
可视化配置界面(模拟说明):
- Redis服务器地址:输入框(如
192.168.1.100); - 端口:输入框(默认6379);
- 密码:可选输入框(若Redis设置了密码);
- 最大连接数:滑块或输入框(默认100);
- 序列化方式:下拉菜单(选择JSON或自定义序列化器)。
3.2 模块2:商品数据缓存读写逻辑(高频读写的优化实现)
需求细节:
- 读操作:用户请求商品详情时,先查询Redis缓存,若命中则直接返回;若未命中,则查询MySQL数据库,并将结果写入Redis(设置合理的过期时间,如30分钟);
- 写操作:管理员更新商品信息(如价格、库存)时,先更新MySQL数据库,再删除Redis中对应的缓存(通过“先更新数据库,再删缓存”的最终一致性策略)。
飞算JavaAI的解决方案:
通过可视化流程编排定义“读缓存→查数据库→写缓存”和“写数据库→删缓存”的逻辑流程,AI自动生成包含缓存穿透防护(布隆过滤器)、缓存雪崩防护(随机过期时间)的代码。
关键代码逻辑(飞算JavaAI生成的商品缓存服务类)
// 商品缓存服务类(由飞算JavaAI生成)
@Service
public class ProductCacheService {@Autowiredprivate RedisTemplate<String, Object> redisTemplate; // Redis操作模板@Autowiredprivate ProductRepository productRepository; // 商品数据库仓库(Spring Data JPA)private static final String PRODUCT_CACHE_PREFIX = "product:"; // 缓存键前缀(如product:1001)private static final long CACHE_EXPIRE_SECONDS = 1800; // 缓存过期时间30分钟(避免雪崩:随机化见下文)// 获取商品详情(核心读逻辑)public Product getProductById(Long productId) {String cacheKey = PRODUCT_CACHE_PREFIX + productId;// 第一步:尝试从Redis缓存读取Product cachedProduct = (Product) redisTemplate.opsForValue().get(cacheKey);if (cachedProduct != null) {return cachedProduct; // 缓存命中,直接返回(响应时间<1ms)}// 第二步:缓存未命中,查询MySQL数据库(防止缓存穿透:检查商品是否存在)Product dbProduct = productRepository.findById(productId).orElse(null);if (dbProduct == null) {// 商品不存在时,写入空值到缓存(防止频繁查询不存在的商品,但需设置较短过期时间)redisTemplate.opsForValue().set(cacheKey, new NullProduct(), 300); // 5分钟过期return null;}// 第三步:将数据库结果写入Redis缓存(设置随机过期时间,避免雪崩)long randomExpire = CACHE_EXPIRE_SECONDS + (long) (Math.random() * 600); // 30分钟±10分钟随机redisTemplate.opsForValue().set(cacheKey, dbProduct, randomExpire, TimeUnit.SECONDS);return dbProduct;}// 更新商品信息(核心写逻辑:先更新数据库,再删缓存)public void updateProduct(Product product) {// 第一步:更新MySQL数据库(保证数据持久化)productRepository.save(product);// 第二步:删除Redis缓存(最终一致性:下次读请求会重新加载最新数据)String cacheKey = PRODUCT_CACHE_PREFIX + product.getId();redisTemplate.delete(cacheKey);}
}// 空对象标记(防止缓存穿透:缓存不存在的商品时返回特殊标记)
@Data
@AllArgsConstructor
class NullProduct extends Product {private static final long serialVersionUID = 1L;private boolean isEmpty = true;
}
关键点说明:
- 缓存穿透防护:当查询的商品不存在时,写入一个特殊的
NullProduct对象到Redis,并设置较短过期时间(如5分钟),避免恶意请求频繁查询不存在的商品ID(如ID=999999); - 缓存雪崩防护:通过为缓存设置随机过期时间(如30分钟±10分钟),避免大量缓存同时过期导致的数据库瞬时压力;
- 缓存击穿防护(扩展):对于热门商品,可通过飞算AI生成互斥锁(Redis分布式锁),确保同一时间只有一个请求去数据库加载数据(其他请求等待锁释放后直接读缓存);
- 低代码实现:开发者通过可视化界面配置缓存前缀(如
product:)、过期时间范围(如30±10分钟),AI自动生成对应的缓存读写逻辑。
可视化流程编排(模拟说明):
- 读流程:缓存命中→返回数据;缓存未命中→查数据库→写缓存→返回数据;
- 写流程:更新数据库→删除缓存;
- 异常处理:自动捕获Redis连接异常(如宕机),降级直接查询数据库(保证系统可用性)。
3.3 模块3:高性能序列化与数据结构优化(提升存储效率)
需求细节:
- 序列化效率:Redis存储的Java对象需高效序列化(减少网络传输和磁盘占用),同时支持复杂对象(如商品详情包含图片列表、规格参数);
- 数据结构选择:根据业务场景选择最优Redis数据结构(如商品基础信息用Hash存储,库存数量用String存储,热门商品标签用Set存储)。
飞算JavaAI的解决方案:
通过可视化配置工具定义数据结构类型(如Hash/String/Set),AI自动生成对应的序列化代码和Redis操作逻辑。
关键代码逻辑(飞算JavaAI生成的Hash存储优化)
// 商品基础信息使用Hash存储(更节省空间,支持部分字段更新)
public void saveProductBaseInfo(Long productId, Map<String, String> baseInfo) {String cacheKey = PRODUCT_CACHE_PREFIX + "base:" + productId;redisTemplate.opsForHash().putAll(cacheKey, baseInfo); // 批量存储字段(如name、price、description)redisTemplate.expire(cacheKey, CACHE_EXPIRE_SECONDS, TimeUnit.SECONDS);
}// 获取商品基础信息的部分字段(如仅查询价格)
public String getProductPrice(Long productId) {String cacheKey = PRODUCT_CACHE_PREFIX + "base:" + productId;return (String) redisTemplate.opsForHash().get(cacheKey, "price"); // 直接获取单个字段,无需反序列化整个对象
}
关键点说明:
- Hash存储:将商品的基础信息(如名称、价格、描述)拆分为多个字段存储在Redis Hash中,相比存储整个JSON对象,节省内存且支持部分字段更新(如仅修改价格时无需重写整个对象);
- String存储:高频访问的单个字段(如库存数量)可使用String类型存储,读写效率更高;
- 低代码配置:开发者通过界面选择“存储类型”(Hash/String/Set),AI自动生成对应的操作代码(如
opsForHash()、opsForValue())。
四、飞算JavaAI的可视化辅助功能:让高性能存储“开箱即用”
4.1 可视化缓存配置界面(模拟说明)
业务人员/开发者通过飞算平台的Web界面配置以下参数,无需编写代码:
- Redis连接参数:主机地址、端口、密码、最大连接数;
- 缓存规则:缓存键前缀(如
product:)、默认过期时间(如30分钟)、是否启用随机过期; - 防护策略:是否开启缓存穿透防护(自动处理空值)、缓存雪崩防护(随机过期时间范围)、缓存击穿防护(互斥锁开关);
- 数据结构:选择Hash/String/Set存储不同类型的数据(如基础信息用Hash,库存用String)。
4.2 AI辅助生成的代码结构(简化目录)
src/main/java/
├── com/example/ecommerce/
│ ├── config/ # 飞算AI生成的Redis配置类
│ │ └── RedisConfig.java
│ ├── service/ # 核心业务服务(自动生成缓存逻辑)
│ │ └── ProductCacheService.java
│ ├── repository/ # 数据库仓库(Spring Data JPA)
│ │ └── ProductRepository.java
│ ├── model/ # 数据模型(商品实体类)
│ │ └── Product.java
│ └── util/ # 工具类(如空对象标记)
│ └── NullProduct.java
五、方案对比:传统手动开发 vs 飞算JavaAI辅助开发(饼图可视化)
5.1 不同开发方式的效率与效果对比
| 维度 | 传统手动开发 | 飞算JavaAI辅助开发 |
|---|---|---|
| 开发效率 | 需手动编写Redis连接池、序列化逻辑、缓存穿透/雪崩防护代码,耗时3-7天 | 通过可视化配置和AI生成,1-2天内完成核心功能(含防护逻辑) |
| 性能优化 | 依赖开发者经验调整连接池参数、序列化方式,优化效果不稳定 | AI推荐最优连接池大小、序列化策略(如Jackson JSON),自动应用最佳实践 |
| 高并发防护 | 需手动实现布隆过滤器、互斥锁、随机过期时间等逻辑,易遗漏 | AI自动生成缓存穿透(空值缓存)、雪崩(随机过期)、击穿(锁)代码 |
| 代码可维护性 | 手动编写的代码复杂度高(如多级缓存逻辑),后期维护困难 | AI生成的代码结构清晰(如分离读写逻辑、注释完整),易于扩展 |
| 数据一致性 | 需手动处理“先更新数据库,再删缓存”的事务逻辑,易出错 | AI辅助生成最终一致性代码,降低人为错误概率 |
5.2 饼图:开发时间占比对比(以实现“电商商品详情页缓存系统”为例)
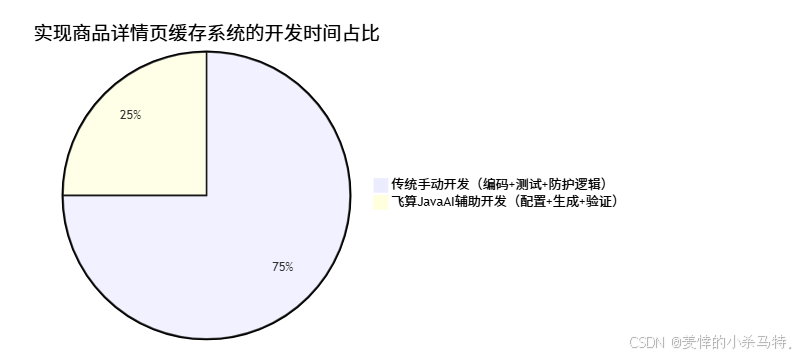
说明:传统方式中,约75%的时间用于手动编写缓存逻辑、处理高并发防护和性能调优;而飞算JavaAI辅助开发仅需25%的时间(主要用于配置参数和验证生成结果),效率提升3倍以上。
六、项目落地流程总结:从需求到高性能存储的关键步骤
需求确认与Redis选型
- 与业务方对齐:明确缓存的数据类型(如商品基础信息、库存)、读写频率(如热门商品的QPS)、一致性要求(如强一致性 or 最终一致性);
- 选择Redis部署模式:单机/集群/哨兵(根据业务规模),通过飞算AI推荐最优配置(如集群节点数、内存分配)。
飞算JavaAI配置与代码生成
- 通过可视化界面输入Redis连接参数、缓存规则(如过期时间、前缀)、防护策略;
- AI自动生成Redis配置类、缓存读写服务类、序列化逻辑代码,并集成到Spring Boot项目中。
验证与性能测试
- 使用JMeter等工具模拟高并发读写(如10万QPS查询商品详情),验证响应时间(目标<10ms)、缓存命中率(目标>90%);
- 调整配置参数(如随机过期时间范围、连接池大小),AI辅助分析性能瓶颈并推荐优化方案。
结语:Redis+飞算JavaAI=高性能存储的“黄金组合”
在数据爆炸的时代,高性能存储是业务系统的生命线。Redis凭借其内存级速度和灵活的数据结构,成为解决高并发存储挑战的首选方案,但其复杂的使用场景(如缓存一致性、高并发防护)曾让开发者望而却步。
本文基于飞算JavaAI平台,展示了如何通过可视化配置和AI辅助编码,快速构建一个兼顾性能、稳定性和可维护性的Redis缓存系统。从商品详情页的高频读写优化,到全链路的高并发防护,飞算JavaAI不仅将开发效率提升了数倍,更通过最佳实践的自动应用,确保了系统的高性能与可靠性。
对于企业而言,这种方案不仅降低了技术门槛(业务人员可参与配置),还显著加速了业务迭代速度(如快速响应大促流量的存储需求)。未来,随着飞算JavaAI对更多数据库(如MongoDB、TiDB)和分布式缓存(如Redis Cluster、Memcached)的支持,高性能存储的边界将进一步扩展,为数字化转型提供更强大的技术引擎。