工具测试 - marker (Convert PDF to markdown + JSON quickly with high accuracy)
参考链接如下::
参考链接:https://github.com/datalab-to/marker?tab=readme-ov-file#llm-services
底层的OCR模型:https://github.com/datalab-to/surya
作用:开源免费🆓,多 GPU 推理、生成效果不错,可结合 llm 进行优化,后续可以多试试,对比对比其他工具,目前工作中够用就行,暂时还没必要自己训练。
1、测试和使用非常的简单:只需要 2 行:
1.1 安装:
pip install marker-pdf1.2 使用: 全部默认配置的话是这样的
marker_single ./2506.11763v1.pdf 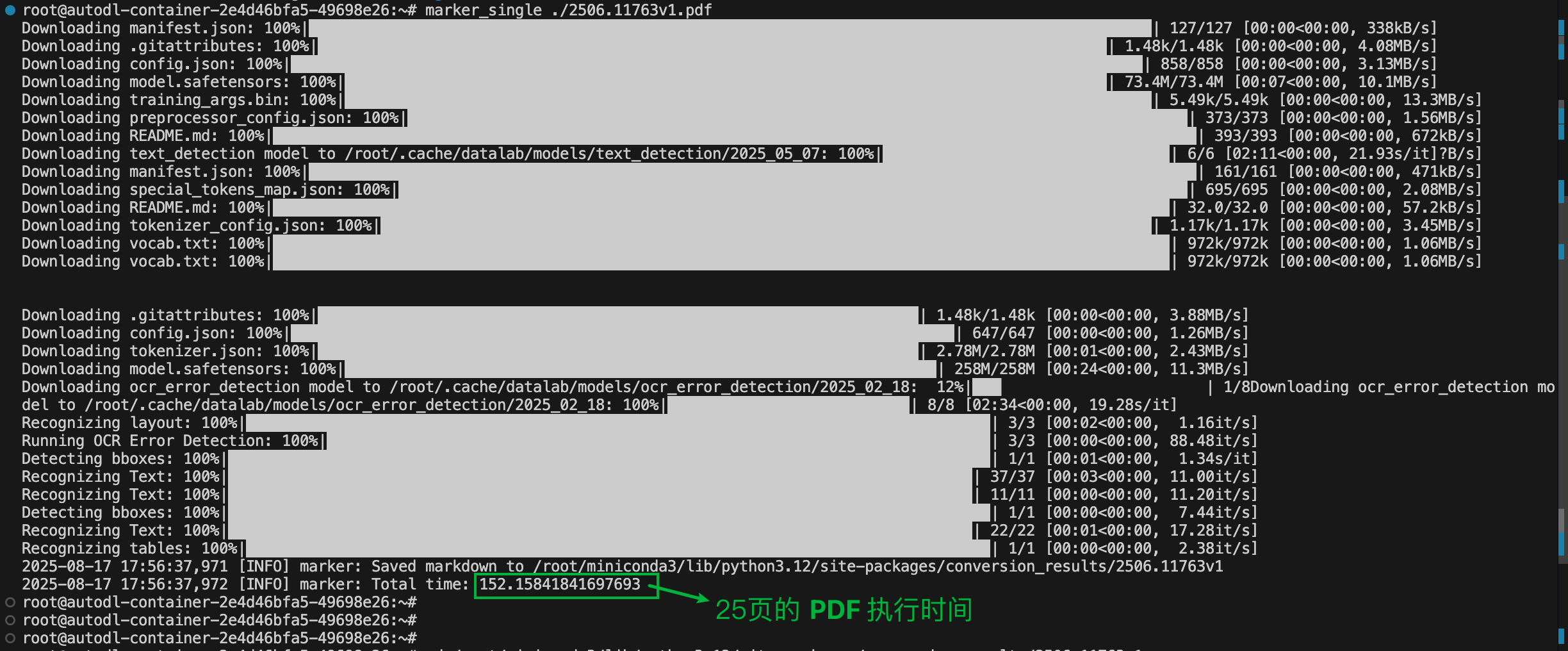
建议:
1、查看文档配置相关参数,我这里因为是 32 页文档,没有处理完成,处理了25 页(1.4w字(word 统计) 用时152s ,每秒接近 92 个字,使用的是 4090 GPU 机器。);
2、对比看看表格情况怎样?
原始 PDF: 感觉差不多够用了,不够后面可以再加 LLM 增强
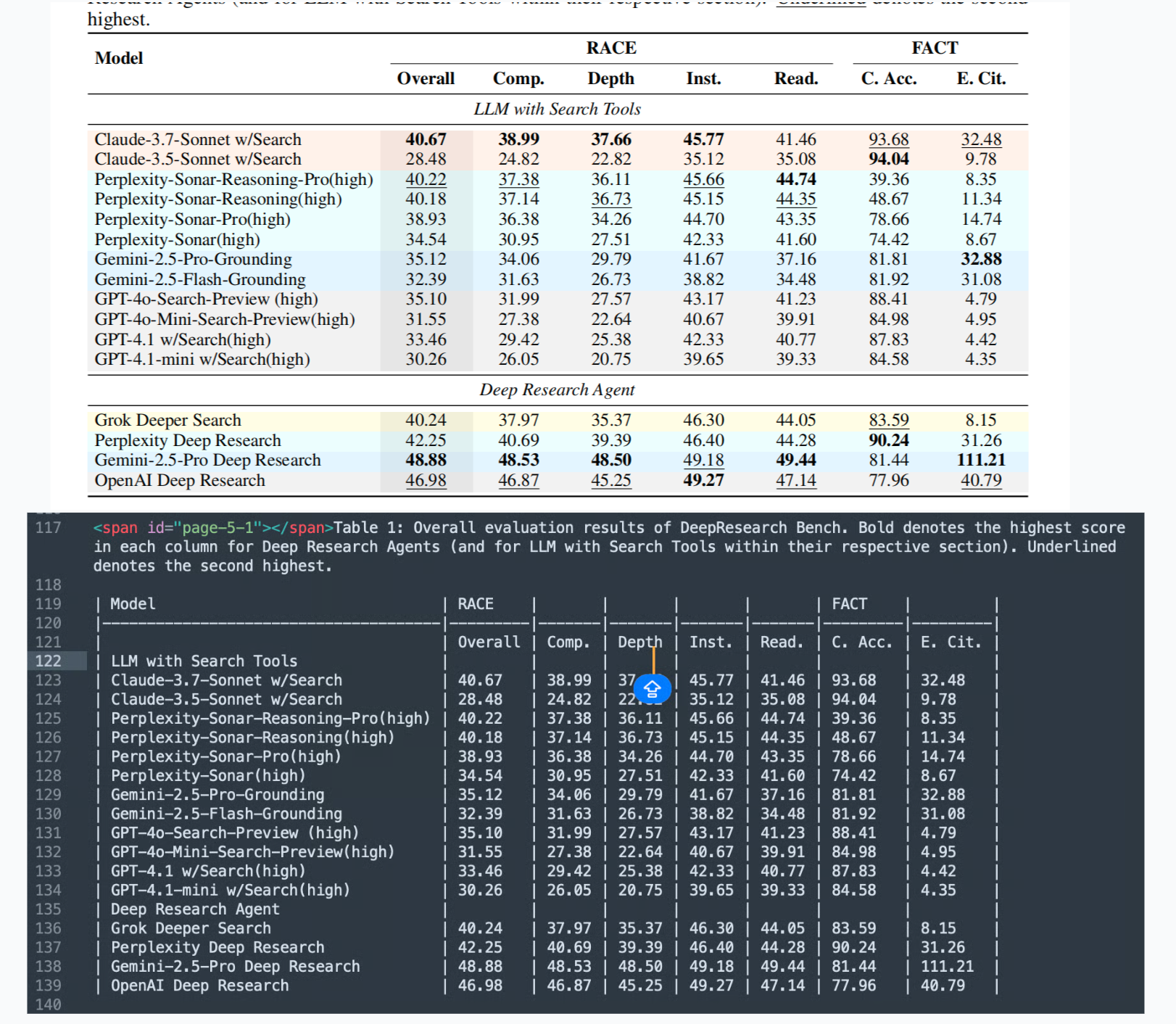
3、还可以多 GPU 执行,大家可以多多探索下
官方 -> Usage
First, some configuration:
- Your torch device will be automatically detected, but you can override this. For example,
TORCH_DEVICE=cuda. - Some PDFs, even digital ones, have bad text in them. Set
-force_ocrto force OCR on all lines, or thestrip_existing_ocrto keep all digital text, and strip out any existing OCR text. - If you care about inline math, set
force_ocrto convert inline math to LaTeX.
Interactive App
I've included a streamlit app that lets you interactively try marker with some basic options. Run it with:
pip install streamlit streamlit-ace
marker_gui
Convert a single file
marker_single /path/to/file.pdf
You can pass in PDFs or images.
Options:
-page_range TEXT: Specify which pages to process. Accepts comma-separated page numbers and ranges. Example:-page_range "0,5-10,20"will process pages 0, 5 through 10, and page 20.-output_format [markdown|json|html|chunks]: Specify the format for the output results.-output_dir PATH: Directory where output files will be saved. Defaults to the value specified in settings.OUTPUT_DIR.-paginate_output: Paginates the output, using\\n\\n{PAGE_NUMBER}followed by * 48, then\\n\\n-use_llm: Uses an LLM to improve accuracy. You will need to configure the LLM backend - see below.-force_ocr: Force OCR processing on the entire document, even for pages that might contain extractable text. This will also format inline math properly.-block_correction_prompt: if LLM mode is active, an optional prompt that will be used to correct the output of marker. This is useful for custom formatting or logic that you want to apply to the output.-strip_existing_ocr: Remove all existing OCR text in the document and re-OCR with surya.-redo_inline_math: If you want the absolute highest quality inline math conversion, use this along with-use_llm.-disable_image_extraction: Don't extract images from the PDF. If you also specify-use_llm, then images will be replaced with a description.-debug: Enable debug mode for additional logging and diagnostic information.-processors TEXT: Override the default processors by providing their full module paths, separated by commas. Example:-processors "module1.processor1,module2.processor2"-config_json PATH: Path to a JSON configuration file containing additional settings.config --help: List all available builders, processors, and converters, and their associated configuration. These values can be used to build a JSON configuration file for additional tweaking of marker defaults.-converter_cls: One ofmarker.converters.pdf.PdfConverter(default) ormarker.converters.table.TableConverter. ThePdfConverterwill convert the whole PDF, theTableConverterwill only extract and convert tables.-llm_service: Which llm service to use if-use_llmis passed. This defaults tomarker.services.gemini.GoogleGeminiService.-help: see all of the flags that can be passed into marker. (it supports many more options then are listed above)
The list of supported languages for surya OCR is here. If you don't need OCR, marker can work with any language.
Convert multiple files
marker /path/to/input/folder
markersupports all the same options frommarker_singleabove.-workersis the number of conversion workers to run simultaneously. This is automatically set by default, but you can increase it to increase throughput, at the cost of more CPU/GPU usage. Marker will use 5GB of VRAM per worker at the peak, and 3.5GB average.
Convert multiple files on multiple GPUs
NUM_DEVICES=4 NUM_WORKERS=15 marker_chunk_convert ../pdf_in ../md_out
NUM_DEVICESis the number of GPUs to use. Should be2or greater.NUM_WORKERSis the number of parallel processes to run on each GPU.
Use from python
See the PdfConverter class at marker/converters/pdf.py function for additional arguments that can be passed.
from marker.converters.pdf import PdfConverter
from marker.models import create_model_dict
from marker.output import text_from_renderedconverter = PdfConverter(artifact_dict=create_model_dict(),
)
rendered = converter("FILEPATH")
text, _, images = text_from_rendered(rendered)
rendered will be a pydantic basemodel with different properties depending on the output type requested. With markdown output (default), you'll have the properties markdown, metadata, and images. For json output, you'll have children, block_type, and metadata.