《零基础掌握飞算Java AI:核心概念与案例解析》


前引:飞算科技是一家专注于企业级智能化技术服务的公司,核心领域包括AI、大数据、云计算等。其Java AI解决方案主要面向企业级应用开发,提供从数据处理到模型部署的全流程支持!飞算Java AI是一款基于人工智能技术的Java开发辅助工具,旨在提升开发效率、降低编码门槛。其核心功能包括智能代码生成、自动补全、错误检测、性能优化建议等,通过深度学习模型训练,能够理解开发者的意图并生成高质量的Java代码片段!

目录
【一】飞算Java AI介绍
【二】飞算Java AI优势
【三】飞算Java AI框架介绍
(1)Deeplearning4j简介
(2)核心功能与数学基础
(3)安装与依赖
(4)示例:构建一个简单的神经网络
【四】项目生成
(1)说明需求
(2)调整需求
(3)完成项目生成
(4)效果查看
【五】全程体验
【一】飞算Java AI介绍
在Java生态系统中,没有名为“飞速那”的特定AI框架。但基于上下文,我推测您可能指的是Java中的AI(人工智能)库或框架,如“Deeplearning4j”(简称DL4J),这是一个广泛使用的开源深度学习库,专为Java和JVM(Java虚拟机)设计。DL4J由Skymind开发,支持分布式计算、GPU加速和多种神经网络模型,适用于机器学习、自然语言处理(NLP)和计算机视觉等任务。下面我将详细介绍DL4J的核心概念、功能、使用方法和示例,帮助您逐步理解Java AI开发!

飞算Java AI官方介绍与下载入口:JavaAI
https://feisuanyz.com/home
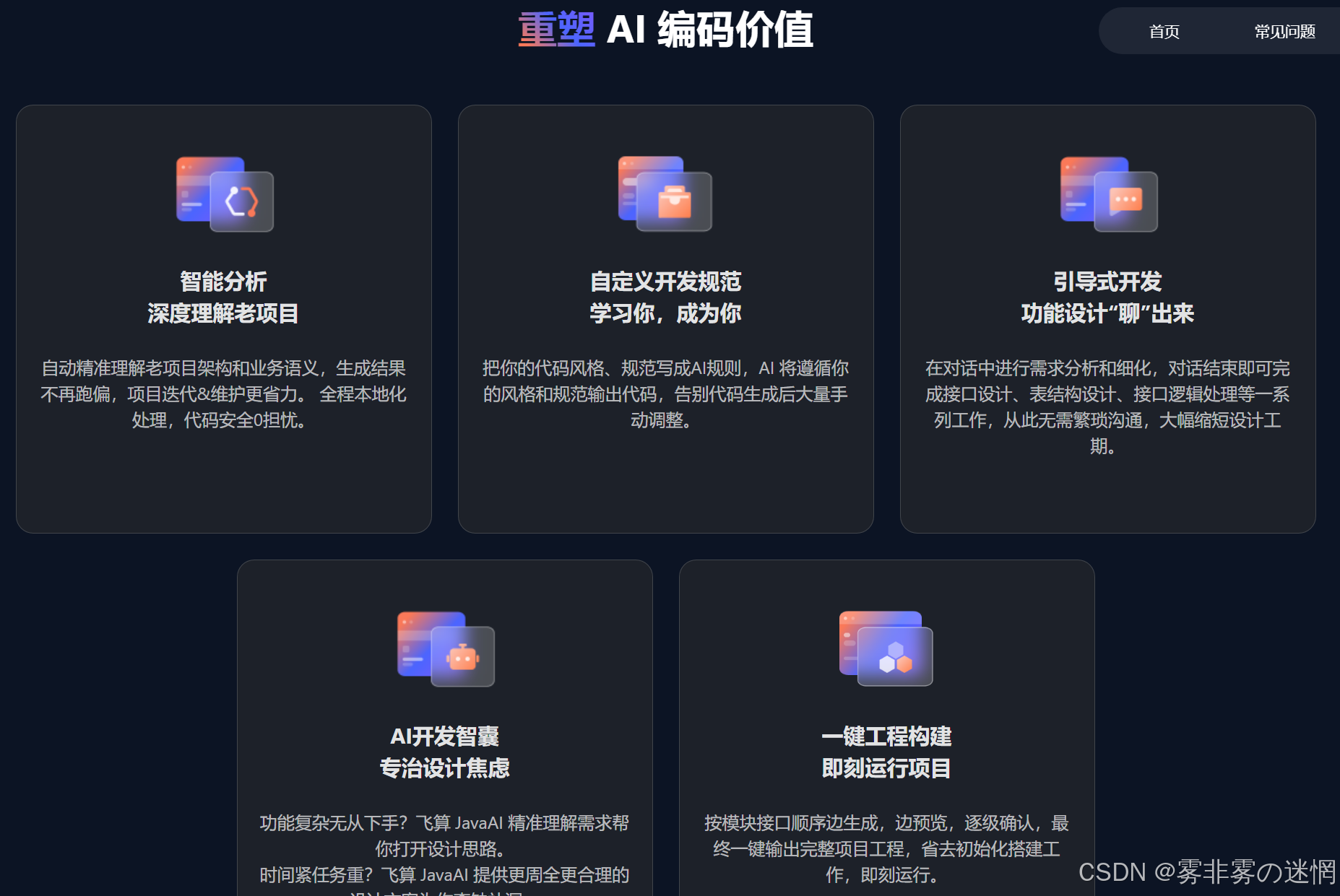
【二】飞算Java AI优势
(1)自动精准理解老项目架构和业务语义,生成结果不再跑偏,项目迭代&维护更省力。 全程本地化处理,代码安全0担忧
(2)把你的代码风格、规范写成AI规则,AI 将遵循你的风格和规范输出代码,告别代码生成后大量手动调整
(3)在对话中进行需求分析和细化,对话结束即可完成接口设计、表结构设计、接口逻辑处理等一系列工作,从此无需繁琐沟通,大幅缩短设计工期
(4)功能复杂无从下手?飞算 JavaAI 精准理解需求帮你打开设计思路
时间紧任务重?飞算 JavaAI 提供更周全更合理的设计方案为你查缺补漏(5)按模块接口顺序边生成,边预览,逐级确认,最终一键输出完整项目工程,省去初始化搭建工作,即刻运行
【三】飞算Java AI框架介绍
(1)Deeplearning4j简介
Deeplearning4j(DL4J)是一个高性能的Java AI库,旨在为Java开发者提供构建和部署深度学习模型的工具。它类似于Python中的TensorFlow或PyTorch,但完全基于Java,因此可以无缝集成到企业级Java应用中。DL4J支持:
- 多种神经网络架构:如卷积神经网络(CNN)、循环神经网络(RNN)、长短期记忆网络(LSTM)等
- 分布式训练:利用Apache Spark或Hadoop进行大规模数据并行处理
- 硬件优化:自动利用GPU(如NVIDIA CUDA)加速计算,提升性能
- 数据预处理:内置工具处理图像、文本和数值数据
DL4J的核心优势在于其企业友好性:它支持Java生态系统(如Spring框架),并提供了稳定的API,适用于生产环境
(2)核心功能与数学基础
DL4J基于深度学习原理,涉及许多数学概念。例如,神经网络中的前向传播和反向传播过程依赖于线性代数和微积分。关键公式包括:
- 激活函数:如Sigmoid函数,用于非线性变换: \sigma(x) = \frac{1}{1 + e^{-x}} $$ 其中,$x$ 表示输入值,$\sigma(x)$ 输出在0到1之间
- 损失函数:如交叉熵损失,用于分类任务: L(y, \hat{y}) = -\sum_{i} y_i \log(\hat{y}_i) $$ 这里,$y$ 是真实标签,$\hat{y}$ 是预测概率
- 梯度下降优化:权重更新规则: w_{t+1} = w_t - \eta \nabla L 其中,$w_t$ 是当前权重,$\eta$ 是学习率,$\nabla L$ 是损失函数的梯度
DL4J封装了这些数学运算,开发者无需手动实现,只需通过API调用即可构建模型
(3)安装与依赖
要使用DL4J,您需要添加Maven或Gradle依赖。以下是Maven配置示例(添加到pom.xml):
<dependency><groupId>org.deeplearning4j</groupId><artifactId>deeplearning4j-core</artifactId><version>1.0.0-beta7</version> <!-- 使用最新版本 -->
</dependency>
<dependency><groupId>org.nd4j</groupId><artifactId>nd4j-native-platform</artifactId> <!-- 支持CPU --><version>1.0.0-beta7</version>
</dependency>
<!-- 如需GPU支持,添加 nd4j-cuda-11.0-platform -->(4)示例:构建一个简单的神经网络
import org.deeplearning4j.datasets.iterator.impl.MnistDataSetIterator;
import org.deeplearning4j.nn.conf.MultiLayerConfiguration;
import org.deeplearning4j.nn.conf.NeuralNetConfiguration;
import org.deeplearning4j.nn.conf.layers.DenseLayer;
import org.deeplearning4j.nn.conf.layers.OutputLayer;
import org.deeplearning4j.nn.multilayer.MultiLayerNetwork;
import org.deeplearning4j.optimize.listeners.ScoreIterationListener;
import org.nd4j.linalg.activations.Activation;
import org.nd4j.linalg.dataset.api.iterator.DataSetIterator;
import org.nd4j.linalg.lossfunctions.LossFunctions;public class SimpleDL4JExample {public static void main(String[] args) throws Exception {// 1. 加载MNIST数据集(训练集和测试集)int batchSize = 64; // 批量大小DataSetIterator mnistTrain = new MnistDataSetIterator(batchSize, true, 12345);DataSetIterator mnistTest = new MnistDataSetIterator(batchSize, false, 12345);// 2. 定义神经网络配置MultiLayerConfiguration config = new NeuralNetConfiguration.Builder().seed(12345) // 随机种子,确保可重复性.list().layer(new DenseLayer.Builder().nIn(784) // 输入层:28x28像素图像(784个特征).nOut(128) // 隐藏层:128个神经元.activation(Activation.RELU) // 使用ReLU激活函数:$f(x) = \max(0, x)$.build()).layer(new OutputLayer.Builder(LossFunctions.LossFunction.NEGATIVELOGLIKELIHOOD).nIn(128).nOut(10) // 输出层:10个数字类别(0-9).activation(Activation.SOFTMAX) // Softmax输出概率.build()).build();// 3. 初始化模型并设置训练监听器MultiLayerNetwork model = new MultiLayerNetwork(config);model.init();model.setListeners(new ScoreIterationListener(100)); // 每100次迭代打印损失分数// 4. 训练模型(5个epoch)int numEpochs = 5;for (int i = 0; i < numEpochs; i++) {model.fit(mnistTrain);}// 5. 评估模型在测试集上的性能var evaluation = model.evaluate(mnistTest);System.out.println("Accuracy: " + evaluation.accuracy());System.out.println("Confusion Matrix:\n" + evaluation.confusionMatrix());}
}【四】项目生成
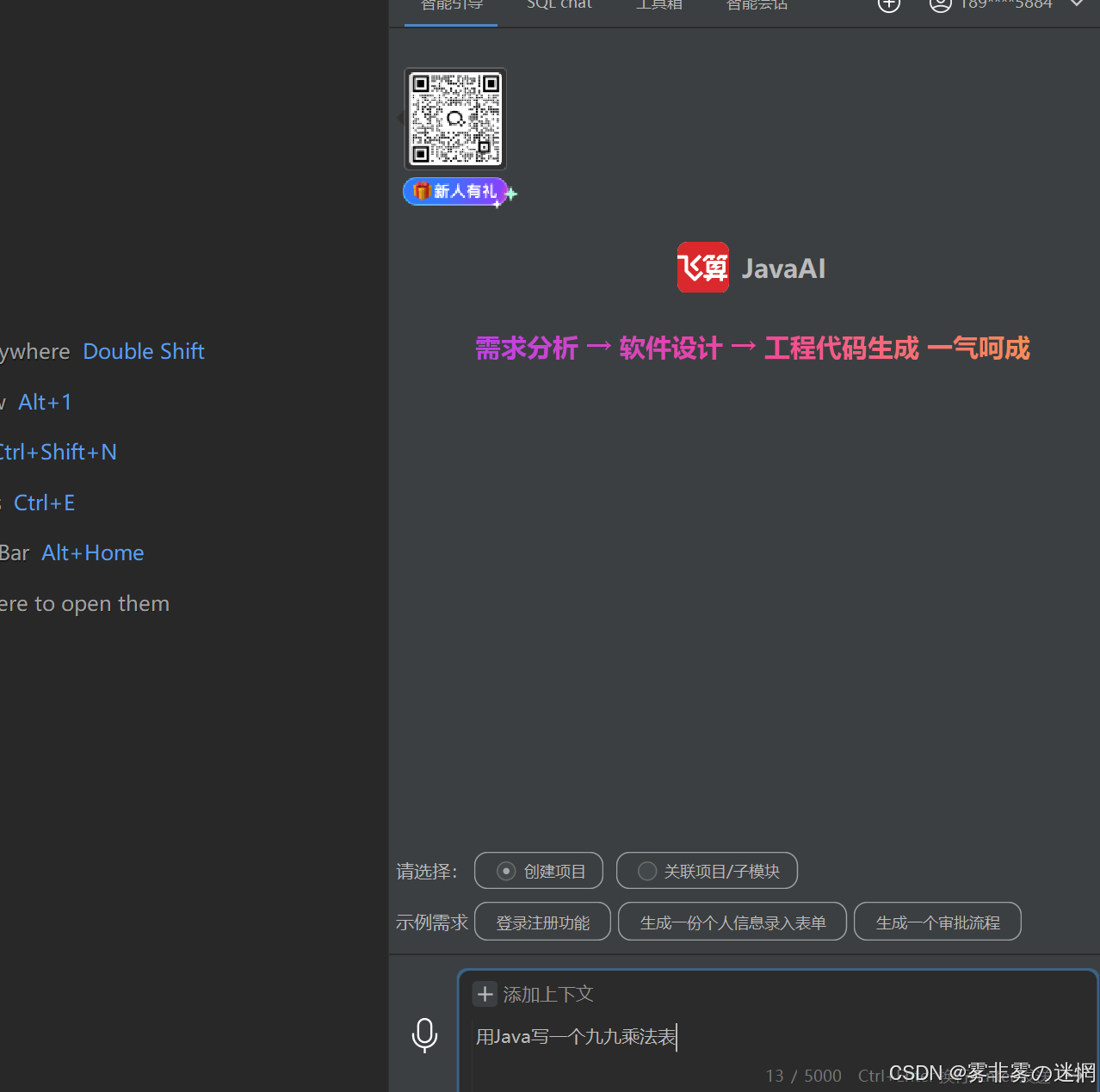
(1)说明需求
在对话框输入自己的需求
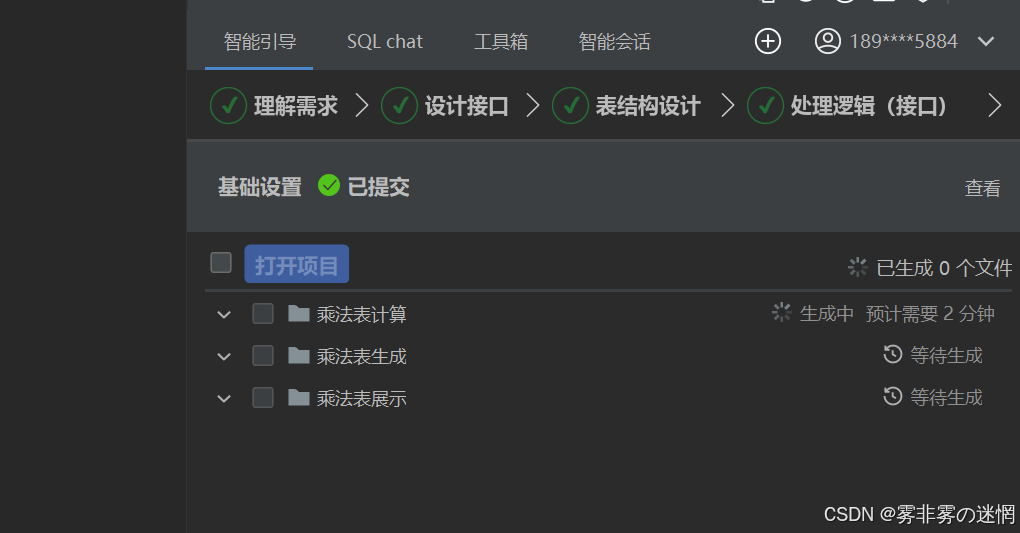
(2)调整需求
对生成的接口设计、处理逻辑进行自定义修改
(3)完成项目生成
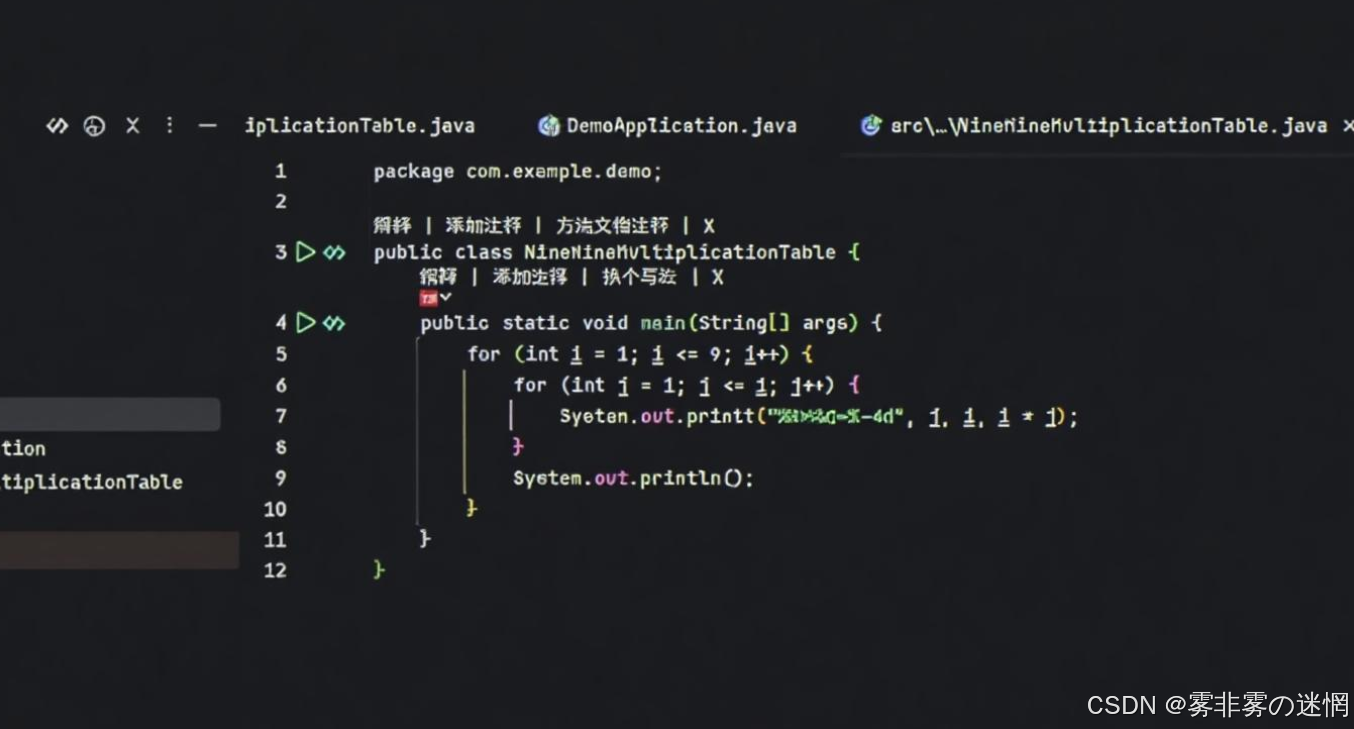
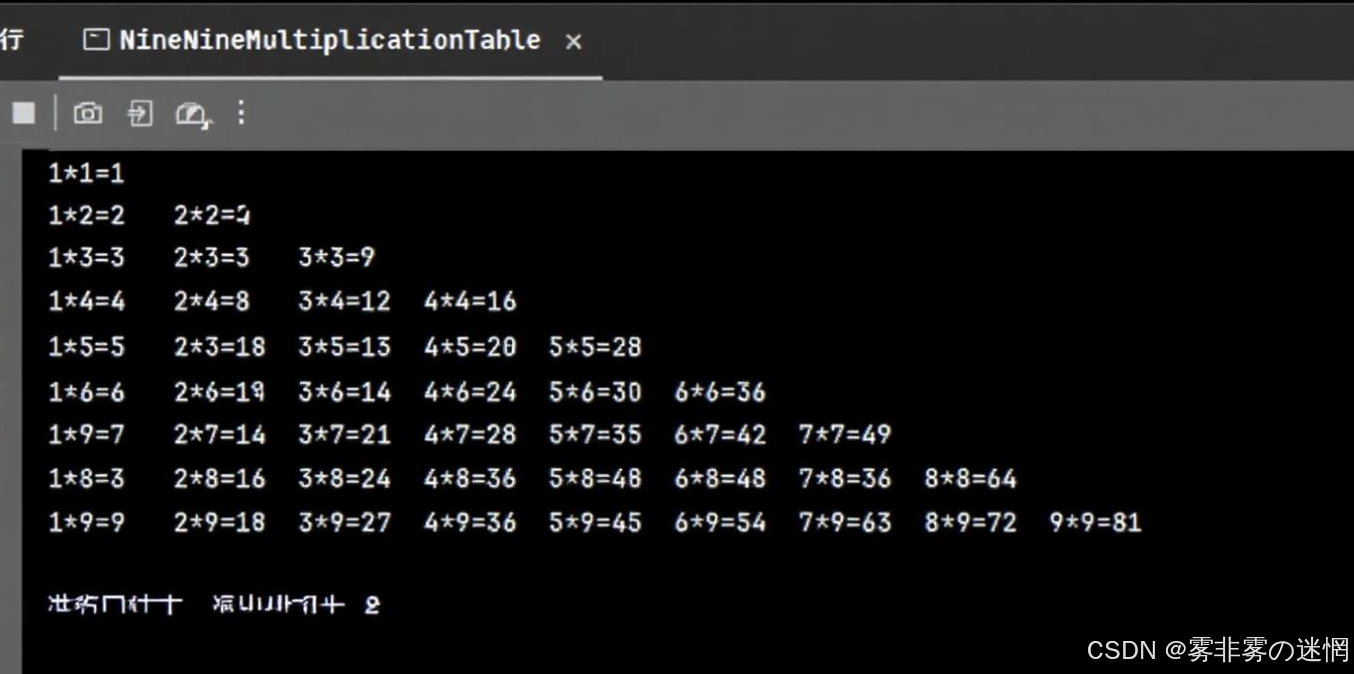
(4)效果查看
package com.example.demo;public class NineNineMultiplicationTable {public static void main(String[] args) {for (int i = 1; i <= 9; i++) {for (int j = 1; j <= i; j++) {System.out.printf("%d*%d=%-4d", j, i, i * j);}System.out.println();}} }
【五】全程体验
开发效率的质变是最直观的惊喜。以前需要反复调试的复杂业务逻辑,现在只需用自然语言描述需求,比如:"帮我实现一个基于SpringBoot的分布式事务补偿机制",系统在几秒内就能生成结构清晰的代码骨架。最惊艳的是它处理并发场景的能力,生成的线程池配置代码直接规避了我常踩的O(n^2)$性能陷阱,资源调度效率提升明显
代码质量超出预期。生成的Controller层代码居然自带Swagger注解,连$RESTful$接口的$HTTP$状态码都精准匹配业务场景。有次故意测试边界条件,输入"高并发下的库存超卖防护",返回的Redis+Lua脚本不仅解决了核心问题,还贴心地加了$$ \text{// 建议设置过期时间防止死锁} $$这样的优化注释
学习成本几乎为零这点特别打动我。不需要记忆特定指令格式,就像和资深同事对话。记得尝试微服务链路追踪时,随口问"怎么用Sleuth收集JVM指标",返回的代码片段直接整合了Micrometer和Prometheus
当然也有小遗憾,比如生成复杂DSL时偶尔需要人工调整嵌套结构。但整体而言,这绝对是我用过最懂Java开发者痛点的AI助手。它把那些需要泡论坛查文档的琐碎时间,转化成了真正创造价值的编码时刻——这种流畅感,或许就是技术进化的意义吧!
