数字分类:机器学习经典案例解析
一、MNIST
本章将使用MNIST数据集,这是一组由美国高中生和人口调查局员工手写的70 000个数字的图片,每张图片都用其代表的数字标记。这个数据集被广为使用,因此也被称作是机器学习领域的“Hello World”:但凡有人想到了一个新的分类算法,都会想看看在MNIST上的执行结果。
1、下载数据集
Scikit-Learn提供了许多助手功能来帮助我们下载流行的数据集,开箱即用,非常方便:
# 下载 MNIST 数据集
from sklearn.datasets import fetch_openml
mnist = fetch_openml('mnist_784', version=1, as_frame=False)
mnist.keys()
dict_keys(['data', 'target', 'frame', 'categories', 'feature_names', 'target_names', 'DESCR', 'details', 'url'])

从输出结果可以看到,Scikit-Learn 加载的数据集通常具有类似的字典结构,包括:
- DESCR键,描述数据集。
- data键,包含一个数组,每个实例为一行,每个特征为一列。
- target键,包含一个带有标记的数组。
2、查看数据集
我们来看看这些数组:
X, y = mnist["data"], mnist["target"]
X.shape
(70000, 784)
y.shape
(70000,)
28 * 28
784
共有7万张图片,每张图片有784个特征。因为图片是28×28像素,每个特征代表了一个像素点的强度,从0(白色)到255(黑色)。
先来看看数据集中的一个数字,我们只需要随手抓取一个实例的特征向量,将其重新形成一个28×28数组,然后使用Matplotlib的imshow函数将其显示出来:
%matplotlib inline
import matplotlib as mpl
import matplotlib.pyplot as pltsome_digit = X[0]
some_digit_image = some_digit.reshape(28, 28)
plt.imshow(some_digit_image, cmap=mpl.cm.binary)
plt.axis("off")plt.show()

看起来像5,而标签告诉我们没错:
y[0]
'5'
注意标签是字符,大部分机器学习算法希望是数字,让我们把y转换成整数:
import numpy as np
y = y.astype(np.uint8)

我们来看一下更多的数据(前100):
def plot_digit(data):image = data.reshape(28, 28)plt.imshow(image, cmap = mpl.cm.binary,interpolation="nearest")plt.axis("off")# EXTRA
def plot_digits(instances, images_per_row=10, **options):size = 28images_per_row = min(len(instances), images_per_row)# This is equivalent to n_rows = ceil(len(instances) / images_per_row):n_rows = (len(instances) - 1) // images_per_row + 1# Append empty images to fill the end of the grid, if needed:n_empty = n_rows * images_per_row - len(instances)padded_instances = np.concatenate([instances, np.zeros((n_empty, size * size))], axis=0)# Reshape the array so it's organized as a grid containing 28×28 images:image_grid = padded_instances.reshape((n_rows, images_per_row, size, size))# Combine axes 0 and 2 (vertical image grid axis, and vertical image axis),# and axes 1 and 3 (horizontal axes). We first need to move the axes that we# want to combine next to each other, using transpose(), and only then we# can reshape:big_image = image_grid.transpose(0, 2, 1, 3).reshape(n_rows * size,images_per_row * size)# Now that we have a big image, we just need to show it:plt.imshow(big_image, cmap = mpl.cm.binary, **options)plt.axis("off")
plt.figure(figsize=(9,9))
example_images = X[:100]
plot_digits(example_images, images_per_row=10)
save_fig("more_digits_plot")
plt.show()

至此,我们对分类任务的复杂程度已经有一个初步的感受了。
3、数据预处理
这时,按以往的习惯,我们需要创建一个测试集,并将其放在一边。事实上,MNIST数据集已经分成训练集(前6万张图片)和测试集(最后1万张图片)了,并且训练集数据已经帮我们做了混洗处理,这样能保证交叉验证时所有的折叠都差不多(保证每个折叠的数字平衡)。
X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:]
!有些机器学习算法对训练实例的顺序敏感,如果连续输入许多相似的实例,可能导致执行性能不佳,给数据集混洗正是为了确保这种情况不会发生。
二、训练二元分类器
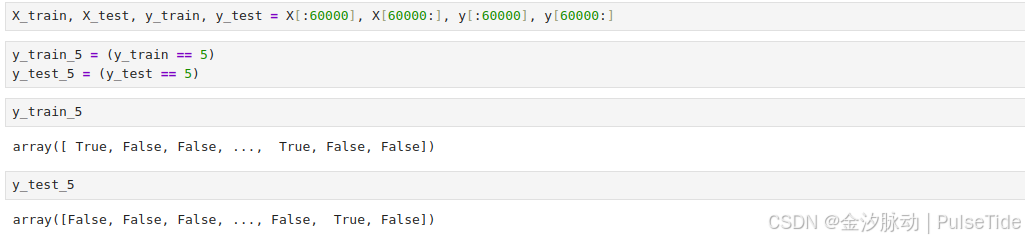
现在先简化问题,只尝试识别一个数字,比如数字5。那么这个“数字5检测器”就是一个二元分类器的示例,它只能区分两个类别:5和非5。先为此分类任务创建目标向量:
y_train_5 = (y_train == 5)
y_test_5 = (y_test == 5)
接着挑选一个分类器并开始训练。一个好的初始选择是随机梯度下降(SGD)分类器,使用Scikit-Learn的SGDClassifier类即可,这个分类器的优势是能够有效处理非常大型的数据集。
from sklearn.linear_model import SGDClassifiersgd_clf = SGDClassifier(max_iter=1000, tol=1e-3, random_state=42)
sgd_clf.fit(X_train, y_train_5)

现在可以用它来检测数字5的图片了:
sgd_clf.predict([some_digit])
array([ True])
分类器猜这个图像代表5(True),看起来这次它猜对了!那么,下面评估一下这个模型的性能。
三、性能测量
1、使用交叉验证
from sklearn.model_selection import cross_val_score
cross_val_score(sgd_clf, X_train, y_train_5, cv=3, scoring="accuracy")
array([0.95035, 0.96035, 0.9604 ])
相比于Scikit-Learn提供cross_val_score这一类交叉验证的函数,有时我们可能希望自己能控制得多一些。在这种情况下,我们可以自行实现交叉验证,操作也简单明了:
from sklearn.model_selection import StratifiedKFold
from sklearn.base import cloneskfolds = StratifiedKFold(n_splits=3, shuffle=True, random_state=42)for train_index, test_index in skfolds.split(X_train, y_train_5):clone_clf = clone(sgd_clf)X_train_folds = X_train[train_index]y_train_folds = y_train_5[train_index]X_test_fold = X_train[test_index]y_test_fold = y_train_5[test_index]clone_clf.fit(X_train_folds, y_train_folds)y_pred = clone_clf.predict(X_test_fold)n_correct = sum(y_pred == y_test_fold)print(n_correct / len(y_pred))
0.9669
0.91625
0.96785
以上代码实现:
- 每个折叠由
StratifiedKFold执行分层抽样产生,其所包含的各个类的比例符合整体比例。 - 每个迭代会创建一个分类器的副本,用训练集对这个副本进行训练,然后用测试集进行预测。
- 最后计算正确预测的次数,输出正确预测的比率。
从以上两个验证结果来看,所有折叠交叉验证的准确率(正确预测的比率)超过90%,貌似模型的效果还不错,但事实真是这样吗?让我们来看一个极端的分类器,它将每张图都分类成“非5”:
from sklearn.base import BaseEstimator
class Never5Classifier(BaseEstimator):def fit(self, X, y=None):passdef predict(self, X):return np.zeros((len(X), 1), dtype=bool)
never_5_clf = Never5Classifier()
cross_val_score(never_5_clf, X_train, y_train_5, cv=3, scoring="accuracy")
array([0.91125, 0.90855, 0.90915])
不可思议,这个极端分类器的准确率同样超过90%!实际上,这是因为只有大约10%的图片是数字5。所以即是这个分类器只是一个会猜“非5”的傻瓜,它也能有一个较高的准确度,这说明准确率通常无法成为分类器的首要性能指标,特别是当我们处
理有偏数据集时(即某些类比其他类更为频繁)。
2、混淆矩阵
评估分类器性能的更好方法是混淆矩阵,其总体思路就是统计A类别实例被分成为B类别的次数。要计算混淆矩阵,需要先有一组预测才能将其与实际目标进行比较。当然,可以通过测试集来进行预测,但是现在先不要动它(测试集最好留到项目的最后,准备启动分类器时再使用),作为替代,可以使用cross_val_predict函数:
from sklearn.model_selection import cross_val_predicty_train_pred = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3)

与cross_val_score函数一样,cross_val_predict函数同样执行K-折交叉验证,但返回的不是评估分数,而是每个折叠的预测,这意味着对于每个实例都可以得到一个干净的预测(“干净”的意思是模型预测时使用的数据在其训练期间从未见过)。
现在可以使用confusion_matrix函数来获取混淆矩阵了,只需要给出目标类别(y_train_5)和预测类别(y_train_pred)即可:
from sklearn.metrics import confusion_matrixconfusion_matrix(y_train_5, y_train_pred)
array([[53892, 687],[ 1891, 3530]])
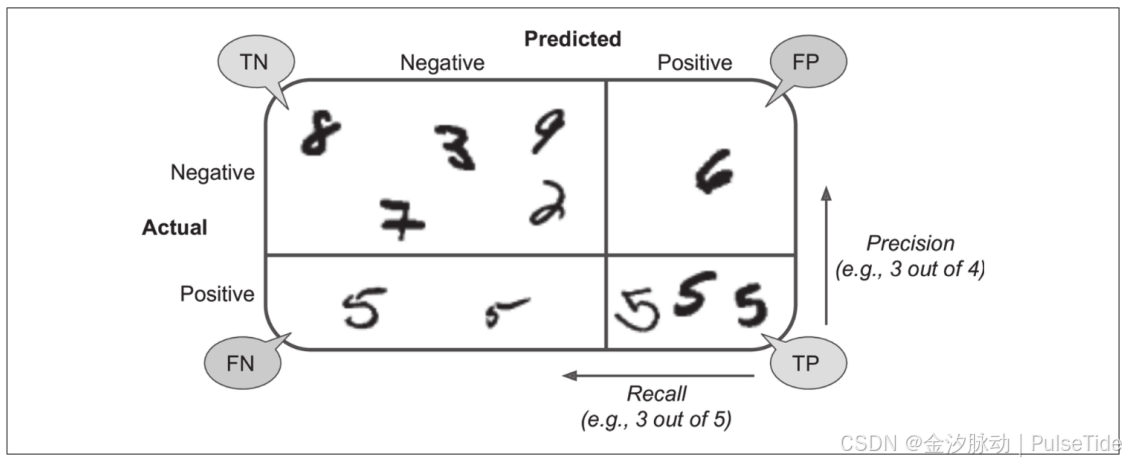
混淆矩阵中的行表示实际类别,列表示预测类别。
-
第一行表示所有“非5”(负类)的图片中:
53892张被正确地分为“非5”类别(真负类),687张被错误地分类成了“5”(假正类); -
第二行表示所有“5”(正类)的图片中:
1891张被错误地分为“非5”类别(假负类),3530张被正确地分在了“5”这一类别(真正类)。
一个完美的分类器只有真正类和真负类,所以它的混淆矩阵只会在其对角线上有非零值:
y_train_perfect_predictions = y_train_5 # pretend we reached perfection
confusion_matrix(y_train_5, y_train_perfect_predictions)
array([[54579, 0],[ 0, 5421]])
3、精度和召回率
混淆矩阵能提供大量信息,但有时我们可能希望指标更简洁一些。
-
正类预测的准确率是一个有意思的指标,它也称为分类器的精度,公式为:精度=TP/(TP+FP),其中TP是真正类的数量,FP是假正类的数量。
-
分类器正确检测到的正类实例的比率则称为召回率,公式为:召回率=TP/(TP+FN),其中FN是假负类的数量。
Scikit-Learn 提供了计算多种分类器指标的函数,使用 precision_score 计算精度:
from sklearn.metrics import precision_score, recall_scoreprecision_score(y_train_5, y_train_pred)
0.8370879772350012
cm = confusion_matrix(y_train_5, y_train_pred)
cm[1, 1] / (cm[0, 1] + cm[1, 1])
0.8370879772350012
使用 recall_score 计算召回率:
recall_score(y_train_5, y_train_pred)
0.6511713705958311
cm[1, 1] / (cm[1, 0] + cm[1, 1])
0.6511713705958311
现在再看,这个“数字5检测器”的准确率并没有到达已开始的90%那么高,当它说一张图片是5时,只有83.7%的概率是准确的,并且也只有65.1%的数字5被它检测出来了。
4、F1分数
我们可以将精度和召回率组合成一个单一的指标,称为F1F_1F1分数。当我们需要一个简单的方法来比较两种分类器时,这是个非常不错的指标。
F1F_1F1分数是精度和召回率的谐波平均值。正常的平均值平等对待所有的值,而谐波平均值会给予低值更高的权重。因此,只有当召回率和精度都很高时,分类器才能得到较高的F1F_1F1分数。

要计算F1F_1F1分数,只需要调用f1_score即可:
from sklearn.metrics import f1_scoref1_score(y_train_5, y_train_pred)
0.7325171197343846
cm[1, 1] / (cm[1, 1] + (cm[1, 0] + cm[0, 1]) / 2)
0.7325171197343847
5、精度/召回率权衡
F1F_1F1分数对那些具有相近的精度和召回率的分类器更为有利。这不一定能一直符合我们的期望:在某些情况下,我们更关心的是精度,而另一些情况下,我们可能真正关心的是召回率。
例如,假设我们训练一个分类器来检测儿童可以放心观看的视频,那么我们可能更青睐那种拦截了很多好视频(低召回率)但是保留下来的视频都是安全(高精度)的分类器,而不是召回率虽高但是在产品中可能会出现一些非常糟糕的视频的分类器,在这种情况下,我们甚至需要添加一个人工流水线来检查分类器选出来的视频。
反过来说,如果我们练一个分类器通过图像监控来检测小偷:我们大概可以接受精度只有30%,但召回率能达到99%,此时安保人员会收到一些错误的警报,但是几乎所有的窃贼都在劫难逃。
遗憾的是,鱼和熊掌不可兼得,我们不能同时增加精度又减少召回率,反之亦然,这称为精度/召回率权衡。要理解这个权衡过程,我们来看看SGDClassifier如何进行分类决策:对于每个实例,它会基于决策函数计算出一个分值,如果该值大于阈值,则将该实例判为正类,否则便将其判为负类。
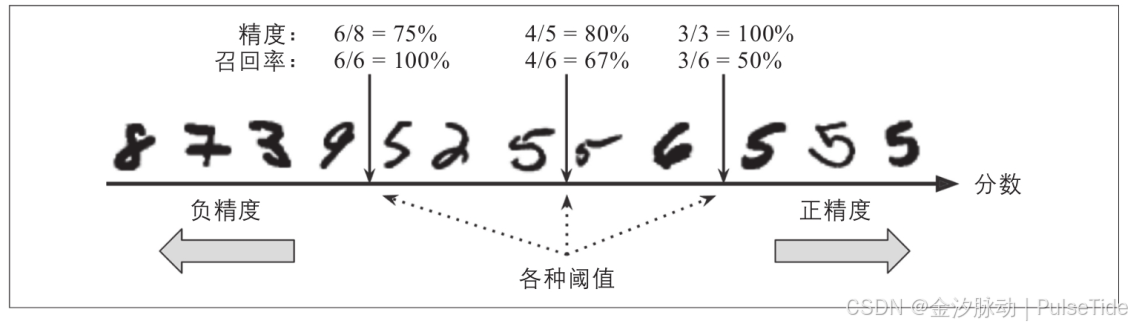
假设决策阈值位于中间箭头位置(两个5之间):在阈值的右侧可以找到4个真正类(真的5)和一个假正类(实际上是6)。因此,在该阈值下,精度为80%(4/5)。但是在6个真正的5中,分类器仅检测到了4个,所以召回率为67%(4/6)。
现在,如果提高阈值(将其挪动到右边箭头的位置),假正类(数字6)变成了真负类,因此精度得到提升(本例中提升到100%),但是一个真正类变成一个假负类,召回率降低至50%。反之,降低阈值则会在增加召回率的同时降低精度。
调用分类器的decision_function方法可以得到每个实例的分数:
y_scores = sgd_clf.decision_function([some_digit])
y_scores
array([2164.22030239])
我们可以根据这个分数,使用任意阈值进行预测:
threshold = 0
y_some_digit_pred = (y_scores > threshold)
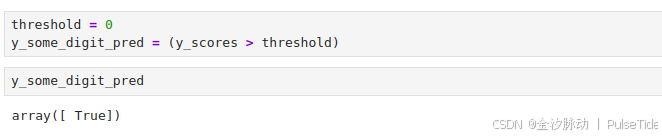
当阈值是0时,预测结果是True,则这个实例被认为是数字5。
threshold = 8000
y_some_digit_pred = (y_scores > threshold)
y_some_digit_pred
array([False])
当我们把阈值提升到8000时,预测结果是False,则这个实例被认为不是数字5。
那么要如何决定使用什么阈值呢?首先,使用 cross_val_predict 函数获取训练集中所有实例的分数,但是这次需要它返回的是决策分数而不是预测结果:
y_scores = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3,method="decision_function")

有了这些分数,可以使用precision_recall_curve函数来计算所有可能的阈值的精度和召回率:
from sklearn.metrics import precision_recall_curveprecisions, recalls, thresholds = precision_recall_curve(y_train_5, y_scores)
最后,使用Matplotlib绘制精度和召回率相对于阈值的函数图:
def plot_precision_recall_vs_threshold(precisions, recalls, thresholds):plt.plot(thresholds, precisions[:-1], "b--", label="Precision", linewidth=2)plt.plot(thresholds, recalls[:-1], "g-", label="Recall", linewidth=2)plt.legend(loc="center right", fontsize=16) # Not shown in the bookplt.xlabel("Threshold", fontsize=16) # Not shownplt.grid(True) # Not shownplt.axis([-50000, 50000, 0, 1]) # Not shownrecall_90_precision = recalls[np.argmax(precisions >= 0.90)]
threshold_90_precision = thresholds[np.argmax(precisions >= 0.90)]plt.figure(figsize=(8, 4)) # Not shown
plot_precision_recall_vs_threshold(precisions, recalls, thresholds)
plt.plot([threshold_90_precision, threshold_90_precision], [0., 0.9], "r:") # Not shown
plt.plot([-50000, threshold_90_precision], [0.9, 0.9], "r:") # Not shown
plt.plot([-50000, threshold_90_precision], [recall_90_precision, recall_90_precision], "r:")# Not shown
plt.plot([threshold_90_precision], [0.9], "ro") # Not shown
plt.plot([threshold_90_precision], [recall_90_precision], "ro") # Not shown
plt.show()
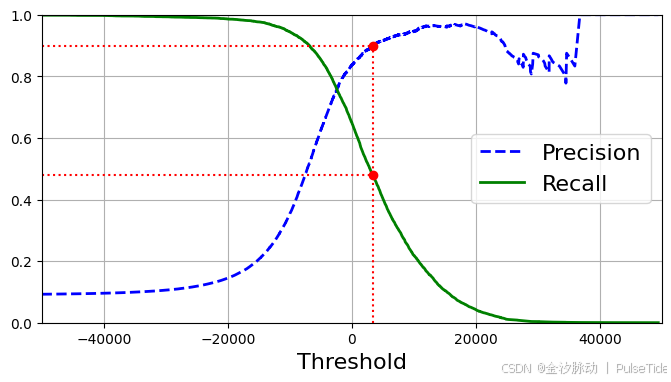
假设我们决定将精度设为90%,则需要根据图中曲线查找对应的阈值,更精确地说是可以搜索到能提供至少90%精度的最低阈值。np.argmax会给我们最大值的第一个索引,在这种情况下,它表示第一个True值:
threshold_90_precision = thresholds[np.argmax(precisions >= 0.90)]

此时,阈值设置为3370.0194991439557是最佳方案,我们可以在训练集上使用该阈值进行预测得到精度和召回率:
y_train_pred_90 = (y_scores >= threshold_90_precision)
precision_score(y_train_5, y_train_pred_90)
0.9000345901072293
recall_score(y_train_5, y_train_pred_90)
0.4799852425751706
很好,现在我们有一个90%精度的分类器了!
另一种找到好的精度/召回率权衡的方法是直接绘制精度和召回率的函数图:
def plot_precision_vs_recall(precisions, recalls):plt.plot(recalls, precisions, "b-", linewidth=2)plt.xlabel("Recall", fontsize=16)plt.ylabel("Precision", fontsize=16)plt.axis([0, 1, 0, 1])plt.grid(True)plt.figure(figsize=(8, 6))
plot_precision_vs_recall(precisions, recalls)
plt.plot([recall_90_precision, recall_90_precision], [0., 0.9], "r:")
plt.plot([0.0, recall_90_precision], [0.9, 0.9], "r:")
plt.plot([recall_90_precision], [0.9], "ro")
plt.show()
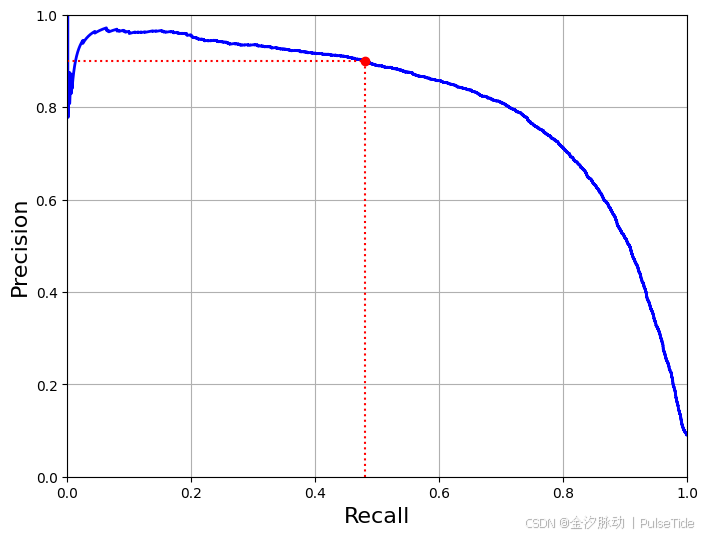
从图中可以看到,从80%的召回率往右,精度开始急剧下降。我们可能会尽量在这个陡降之前选择一个精度/召回率权衡——比如召回率60%,当然,如何选择取决于我们的项目需求。
6、ROC曲线
还有一种经常与二元分类器一起使用的工具,叫作受试者工作特征曲线(简称ROC)。它与精度/召回率曲线非常相似,但绘制的不是精度和召回率,而是真正类率(召回率的另一名称)和假正类率(FPR)。FPR是被错误分为正类的负类实例比率,它等于1减去真负类率(TNR),真负类率是被正确分类为负类的负类实例比率,也称为特异度。因此,ROC曲线绘制的是灵敏度(召回率)和(1减去特异度)的关系。
要绘制ROC曲线,首先需要使用roc_curve函数计算多种阈值的TPR和FPR:
from sklearn.metrics import roc_curvefpr, tpr, thresholds = roc_curve(y_train_5, y_scores)
然后,使用Matplotlib绘制FPR对TPR的曲线:
def plot_roc_curve(fpr, tpr, label=None):plt.plot(fpr, tpr, linewidth=2, label=label)plt.plot([0, 1], [0, 1], 'k--') # dashed diagonalplt.axis([0, 1, 0, 1]) # Not shown in the bookplt.xlabel('False Positive Rate (Fall-Out)', fontsize=16) # Not shownplt.ylabel('True Positive Rate (Recall)', fontsize=16) # Not shownplt.grid(True) # Not shownplt.figure(figsize=(8, 6)) # Not shown
plot_roc_curve(fpr, tpr)
fpr_90 = fpr[np.argmax(tpr >= recall_90_precision)] # Not shown
plt.plot([fpr_90, fpr_90], [0., recall_90_precision], "r:") # Not shown
plt.plot([0.0, fpr_90], [recall_90_precision, recall_90_precision], "r:") # Not shown
plt.plot([fpr_90], [recall_90_precision], "ro") # Not shown
plt.show()
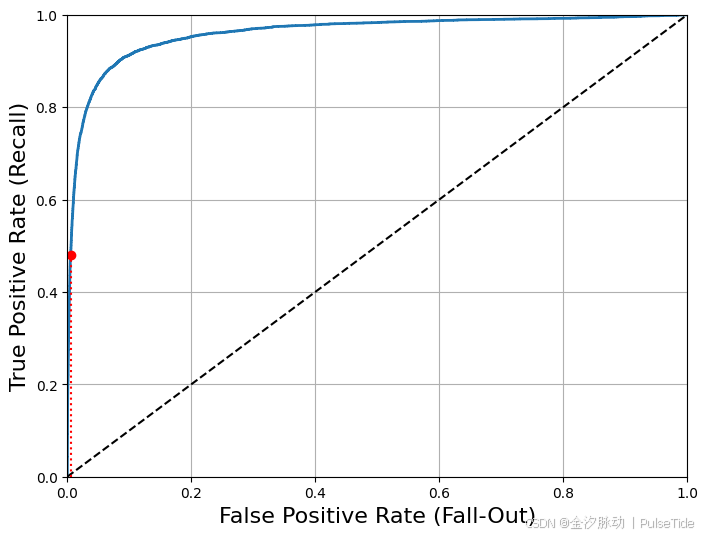
同样这里再次面临一个折中权衡:召回率(TPR)越高,分类器产生的假正类(FPR)就越多。虚线表示纯随机分类器的ROC曲线,一个优秀的分类器应该离这条线越远越好(向左上角)。
有一种比较分类器的方法是测量曲线下面积(AUC),完美的分类器的ROC AUC等于1,而纯随机分类器的ROC AUC等于0.5。Scikit-Learn提供计算ROC AUC的函数:
from sklearn.metrics import roc_auc_scoreroc_auc_score(y_train_5, y_scores)
0.9604938554008616
!使用那种曲线?
由于ROC曲线与精度/召回率(PR)曲线非常相似,因此你可能会问如何决定使用哪种曲线。有一个经验法则是,当正类非常少见或者你更关注假正类而不是假负类时,应该选择PR曲线,反之则是ROC曲线。例如,看前面的ROC曲线图(以及ROC AUC分数),你可能会觉得分类器真不错。但这主要是因为跟负类(非5)相比,正类(数字5)的数量真的很少。相比之下,PR曲线清楚地说明分类器还有改进的空间(曲线还可以更接近左上角)。
现在我们来训练一个RandomForestClassifier分类器,并比较它和SGDClassifier分类器的ROC曲线和ROC AUC分数。首先,获取训练集中每个实例的分数,但是由于它的工作方式不同,RandomForestClassifier类没有decision_function方法,相反,它有dict_proba方法。
Scikit-Learn的分类器通常都会有这两种方法中的一种(或两种都有),dict_proba 方法会返回一个数组,其中每行代表一个实例,每列代表一个类别,意思是某个给定实例属于某个给定类别的概率(例如,这张图片有70%的可能是数字5):
from sklearn.ensemble import RandomForestClassifier
forest_clf = RandomForestClassifier(n_estimators=100, random_state=42)
y_probas_forest = cross_val_predict(forest_clf, X_train, y_train_5, cv=3,method="predict_proba")
roc_curve 函数需要标签和分数,但是我们不提供分数,而是提供类概率,我们直接使用正类的概率作为分数值:
y_scores_forest = y_probas_forest[:, 1] # score = proba of positive class
fpr_forest, tpr_forest, thresholds_forest = roc_curve(y_train_5,y_scores_forest)
现在可以绘制ROC曲线了:
recall_for_forest = tpr_forest[np.argmax(fpr_forest >= fpr_90)]plt.figure(figsize=(8, 6))
plt.plot(fpr, tpr, "b:", linewidth=2, label="SGD")
plot_roc_curve(fpr_forest, tpr_forest, "Random Forest")
plt.plot([fpr_90, fpr_90], [0., recall_90_precision], "r:")
plt.plot([0.0, fpr_90], [recall_90_precision, recall_90_precision], "r:")
plt.plot([fpr_90], [recall_90_precision], "ro")
plt.plot([fpr_90, fpr_90], [0., recall_for_forest], "r:")
plt.plot([fpr_90], [recall_for_forest], "ro")
plt.grid(True)
plt.legend(loc="lower right", fontsize=16)
plt.show()
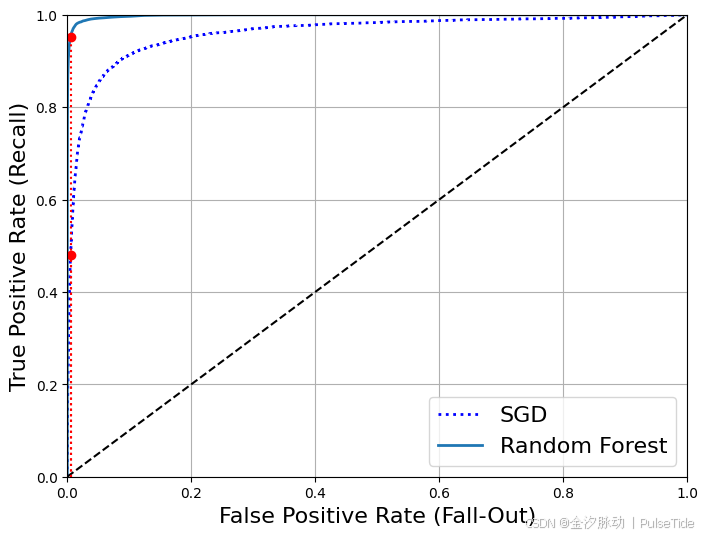
RandomForestClassifier的ROC曲线看起来比SGDClassifier好很多,它离左上角更接近,因此它的ROC AUC分数也高
得多:
roc_auc_score(y_train_5, y_scores_forest)
0.9983436731328145
再测一测精度和召回率的分数:
y_train_pred_forest = cross_val_predict(forest_clf, X_train, y_train_5, cv=3)
precision_score(y_train_5, y_train_pred_forest)
0.9905083315756169
recall_score(y_train_5, y_train_pred_forest)
0.8662608374838591
99.0%的精度和86.6%的召回率!
四、多类分类器
二元分类器在两个类中区分,而多类分类器(也称为多项分类器)可以区分两个以上的类。有一些算法(如随机森林分类器或朴素贝叶斯分类器)可以直接处理多个类,也有一些严格的二元分类器(如支持向量机分类器或线性分类器)。但是,有多种策略可以让我们用几个二元分类器实现多类分类的目的。
要创建一个系统将数字图片分为10类(从0到9),一种方法是训练10个二元分类器,每个数字一个(0-检测器、1-检测器、2-检测器,以此类推)。然后,当我们需要对一张图片进行检测分类时,获取每个分类器的决策分数,哪个分类器给分最高,就将其分为哪个类。这称为一对剩余(OvR)策略,也称为一对多(one-versus-all)。
另一种方法是为每一对数字训练一个二元分类器:一个用于区分0和1,一个区分0和2,一个区分1和2,以此类推。这称为一对一(OvO)策略。如果存在N个类别,那么这需要训练N×(N-1)/2个分类器。对于MNIST问题,这意味着要训练45个二元分类器!当需要对一张图片进行分类时,我们需要运行45个分类器来对图片进行分类,最后看哪个类获胜最多。OvO的主要优点在于,每个分类器只需要用到部分训练集对其必须区分的两个类进行训练。
有些算法(例如支持向量机分类器)在数据规模扩大时表现糟糕。对于这类算法,OvO是一个优先的选择,因为在较小训练集上分别训练多个分类器比在大型数据集上训练少数分类器要快得多。但是对大多数二元分类器来说,OvR策略还是更好的选择。
Scikit-Learn可以检测到我们尝试使用二元分类算法进行多类分类任务,它会根据情况自动运行OvR或者OvO。例如我们用sklearn.svm.SVC类来试试SVM分类器:
from sklearn.svm import SVCsvm_clf = SVC(gamma="auto", random_state=42)
svm_clf.fit(X_train[:1000], y_train[:1000]) # y_train, not y_train_5
svm_clf.predict([some_digit])
array([5], dtype=uint8)
这段代码使用原始目标类0到9(y_train)在训练集上对SVC进行训练,而不是以“5”和“剩余”作为目标类(y_train_5),然后做出预测(在本例中预测正确)。而在内部,Scikit-Learn实际上训练了45个二元分类器,获得它们对图片的决策分数,然后选择了分数最高的类。
要想知道是不是这样,可以调用decision_function方法,它会返回10个分数,每个类1个,而不再是每个实例返回1个分数:
some_digit_scores = svm_clf.decision_function([some_digit])
some_digit_scores
array([[ 2.81585438, 7.09167958, 3.82972099, 0.79365551, 5.8885703 ,9.29718395, 1.79862509, 8.10392157, -0.228207 , 4.83753243]])
最高分确实是对应数字5这个类别:
np.argmax(some_digit_scores)
5
svm_clf.classes_
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], dtype=uint8)

!当训练分类器时,目标类的列表会存储在classes_属性中,按值的大小排序。在本例里,classes_数组中每个类的索引正好对应其类本身(例如,索引上第5个类正好是数字5这个类),但是一般来说,不会这么恰巧。
如果想要强制Scikit-Learn使用一对一或者一对剩余策略,可以使用OneVsOneClassifier或OneVsRestClassifier类,只需要创建一个实例,然后将分类器传给其构造函数(它甚至不必是二元分类器)。例如,下面这段代码使用OvR策略,基于SVC创建了一个多类分类器:
from sklearn.multiclass import OneVsRestClassifier
ovr_clf = OneVsRestClassifier(SVC(gamma="auto", random_state=42))
ovr_clf.fit(X_train[:1000], y_train[:1000])
ovr_clf.predict([some_digit])
array([5], dtype=uint8)
len(ovr_clf.estimators_)
10
训练SGDClassifier或者RandomForestClassifier同样简单:
sgd_clf.fit(X_train, y_train)
sgd_clf.predict([some_digit])
array([3], dtype=uint8)
这次Scikit-Learn不必运行OvR或者OvO了,因为SGD分类器直接就可以将实例分为多个类,调用decision_function可以获得分类器将每个实例分类为每个类的概率列表,让我们看一下SGD分类器分配到的每个类:
sgd_clf.decision_function([some_digit])
array([[-31893.03095419, -34419.69069632, -9530.63950739,1823.73154031, -22320.14822878, -1385.80478895,-26188.91070951, -16147.51323997, -4604.35491274,-12050.767298 ]])
使用cross_val_score函数来评估SGDClassifier的准确性:
cross_val_score(sgd_clf, X_train, y_train, cv=3, scoring="accuracy")
array([0.87365, 0.85835, 0.8689 ])
在所有的测试折叠上都超过了87%。如果是一个纯随机分类器,准确率大概是10%,所以这个结果不是太糟,但是依然有提升的空间。例如,将输入进行简单缩放可以将准确率提到89%以上:
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train.astype(np.float64))
cross_val_score(sgd_clf, X_train_scaled, y_train, cv=3, scoring="accuracy")
array([0.8983, 0.891 , 0.9018])
五、误差分析
在这里,假设我们已经找到了一个有潜力的模型,现在我们希望找到一些方法对其进一步改进,方法之一就是分析其错误类型。
首先看看混淆矩阵,使用cross_val_predict函数进行预测,然后调用confusion_matrix函数:
y_train_pred = cross_val_predict(sgd_clf, X_train_scaled, y_train, cv=3)
conf_mx = confusion_matrix(y_train, y_train_pred)
conf_mx
array([[5577, 0, 22, 5, 8, 43, 36, 6, 225, 1],[ 0, 6400, 37, 24, 4, 44, 4, 7, 212, 10],[ 27, 27, 5220, 92, 73, 27, 67, 36, 378, 11],[ 22, 17, 117, 5227, 2, 203, 27, 40, 403, 73],[ 12, 14, 41, 9, 5182, 12, 34, 27, 347, 164],[ 27, 15, 30, 168, 53, 4444, 75, 14, 535, 60],[ 30, 15, 42, 3, 44, 97, 5552, 3, 131, 1],[ 21, 10, 51, 30, 49, 12, 3, 5684, 195, 210],[ 17, 63, 48, 86, 3, 126, 25, 10, 5429, 44],[ 25, 18, 30, 64, 118, 36, 1, 179, 371, 5107]])
数字有点多,使用Matplotlib的matshow函数来查看混淆矩阵的图像表示通常更加方便:
plt.matshow(conf_mx, cmap=plt.cm.gray)
plt.show()

混淆矩阵看起来很不错,因为大多数图片都在主对角线上,这说明它们被正确分类。数字5看起来比其他数字稍稍暗一些,这可能意味着数据集中数字5的图片较少,也可能是分类器在数字5上的执行效果不如在其他数字上好。
让我们把焦点放在错误上。首先,我们需要将混淆矩阵中的每个值除以相应类中的图片数量,这样比较的就是错误率而不是错误的绝对值,这个过程也称为标准化:
row_sums = conf_mx.sum(axis=1, keepdims=True)
norm_conf_mx = conf_mx / row_sums
row_sums
array([[5923],[6742],[5958],[6131],[5842],[5421],[5918],[6265],[5851],[5949]])
用0填充对角线,只保留错误,重新绘制结果:
np.fill_diagonal(norm_conf_mx, 0)
plt.matshow(norm_conf_mx, cmap=plt.cm.gray)
plt.show()

现在可以清晰地看到分类器产生的错误种类了。记住,每行代表实际类,而每列表示预测类。第8列看起来非常亮,说明有许多图片被错误地分类为数字8了,然而,第8行不那么差,实际上数字8被正确分类为数字8。注意,错误不是完全对称的,比如,数字3和数字5经常被混淆(在两个方向上)。
使用混淆矩阵的彩色图更容易分析:
# 混淆矩阵
from sklearn.metrics import ConfusionMatrixDisplayy_train_pred = cross_val_predict(sgd_clf, X_train_scaled, y_train, cv=3)
plt.rc('font', size=9) # extra code – make the text smaller
ConfusionMatrixDisplay.from_predictions(y_train, y_train_pred)
plt.show()

# 按行归一化的混淆矩阵
plt.rc('font', size=10) # extra code
ConfusionMatrixDisplay.from_predictions(y_train, y_train_pred,normalize="true", values_format=".0%")
plt.show()

现在我们可以很容易地看到,只有82%的数字5的图像被正确分类,模型对数字5的图像犯的最常见错误是将它们错误分类为数字8(10%的概率)。
如果我们想让错误更加突出,那么可以尝试将零权重放在正确的预测上:
# 按行归一化的错误
sample_weight = (y_train_pred != y_train)
plt.rc('font', size=10) # extra code
ConfusionMatrixDisplay.from_predictions(y_train, y_train_pred,sample_weight=sample_weight,normalize="true", values_format=".0%")
plt.show()

现在我们可以更清楚地看到分类器所犯错误的种类:类8的列现在非常亮,这证实许多图像被错误分类为8。注意,我们已经排除了正确的预测,因此这里的百分比是错误占比,所有错误中有65%的概率是误分类为8。
当然也可以按列进行归一化,只需要设置normalize=“pred”:
ConfusionMatrixDisplay.from_predictions(y_train, y_train_pred,sample_weight=sample_weight,normalize="pred", values_format=".0%")
plt.show()

我们可以看到错误分类的数字7,它有56%的概率是数字9。
分析混淆矩阵通常可以帮助我们深入了解如何改进分类器。通过以上例子来看,我们的精力可以花在改进数字8的分类错误上。例如,可以试着收集更多看起来像数字8的训练数据,以便分类器能够学会将它们与真实的数字区分开来。或者,也可以开发一些新特征来改进分类器,例如,写一个算法来计算闭环的数量(例如,数字8有两个,数字6有一个,数字5没有)。再或者,还可以对图片进行预处理(例如,使用Scikit-Image、Pillow或OpenCV)让某些模式更为突出,比如闭环之类的。
分析单个的错误也可以为分类器提供洞察:它在做什么?它为什么失败?但这通常更加困难和耗时。例如,我们来看看数字3和数字5的示例:
cl_a, cl_b = 3, 5
X_aa = X_train[(y_train == cl_a) & (y_train_pred == cl_a)]
X_ab = X_train[(y_train == cl_a) & (y_train_pred == cl_b)]
X_ba = X_train[(y_train == cl_b) & (y_train_pred == cl_a)]
X_bb = X_train[(y_train == cl_b) & (y_train_pred == cl_b)]plt.figure(figsize=(8,8))
plt.subplot(221); plot_digits(X_aa[:25], images_per_row=5)
plt.subplot(222); plot_digits(X_ab[:25], images_per_row=5)
plt.subplot(223); plot_digits(X_ba[:25], images_per_row=5)
plt.subplot(224); plot_digits(X_bb[:25], images_per_row=5)plt.show()

左侧的两个5×5矩阵显示了被分类为数字3的图片,右侧的两个5×5矩阵显示了被分类为数字5的图片。分类器弄错的数字(即左下方和右上方的矩阵)里,确实有一些写得非常糟糕,即便是人类也很难做出区分(例如,第1行的数字5看起来真的很像数字3)。然而,对我们来说,大多数错误分类的图片看起来还是非常明显的错误,我们很难理解分类器为什么会弄错,原因在于,我们使用的简单的SGDClassifier模型是一个线性模型,它所做的就是为每个像素分配一个各个类别的权重,当它看到新的图像时,将加权后的像素强度汇总,从而得到一个分数进行分类,而数字3和数字5只在一部分像素位上有区别,所以分类器很容易将其弄混。
数字3和数字5之间的主要区别是在于连接顶线和下方弧线的中间那段小线条的位置。如果写的数字3将连接点略往左移,分类器就可能将其分类为数字5,反之亦然。换言之,这个分类器对图像移位和旋转非常敏感。因此,减少数字3和数字5混淆的方法之一,就是对图片进行预处理,确保它们位于中心位置并且没有旋转。这也同样有助于减少其他错误。
六、多标签分类
到目前为止,每个实例都只会被分在一个类里。而在某些情况下,我们希望分类器为每个实例输出多个类。例如,动物识别的分类器:如果在一张照片里识别出多种动物怎么办?当然,应该为识别出来的每种动物都附上一个标签。假设分类器经过训练,已经可以识别出三种动物:老鼠、猫、狗,那么当看到一张猫和老鼠的照片时,它应该输出[1,1,0](意思是“是老鼠,是猫,不是狗”)这种输出多个二元标签的分类系统称为多标签分类系统。
为了阐释清楚,这里不讨论动物识别,让我们来看一个更为简单的示例:
from sklearn.neighbors import KNeighborsClassifiery_train_large = (y_train >= 7)
y_train_odd = (y_train % 2 == 1)
y_multilabel = np.c_[y_train_large, y_train_odd]knn_clf = KNeighborsClassifier()
knn_clf.fit(X_train, y_multilabel)
这段代码会创建一个y_multilabel数组,其中包含两个数字图片的目标标签:第一个表示数字是否是大数(7、8、9),第二个表示是否为奇数。下一行创建一个KNeighborsClassifier实例(它支持多标签分类,不是所有的分类器都支持),然后使用多个目标数组对它进行训练。
现在用它做一个预测,注意它输出两个标签:
knn_clf.predict([some_digit])
array([[False, True]])
结果是正确的!数字5确实不大(False),为奇数(True)。
评估多标签分类器的方法很多,如何选择正确的度量指标取决于项目本身。比如方法之一是测量每个标签的F1F_1F1分数(或者之前讨论过的任何其他二元分类器指标),然后简单地计算平均分数。下面这段代码计算所有标签的平均F1F_1F1分数:
y_train_knn_pred = cross_val_predict(knn_clf, X_train, y_multilabel, cv=3)
f1_score(y_multilabel, y_train_knn_pred, average="macro")
0.976410265560605
这里假设所有的标签都同等重要,但实际可能不是这样。特别地,如果训练的照片里狗比老鼠和猫要多很多,我们可能想给区分狗的分类器更高的权重。一个简单的办法是给每个标签设置一个等于其自身支持的权重(也就是具有该目标标签的实例的数量)。为此,只需要在上面的代码中设置average="weighted"即可。
f1_score(y_multilabel, y_train_knn_pred, average="weighted")
七、多输出分类
我们即将讨论的最后一种分类任务称为多输出-多类分类(或简单地称为多输出分类)。简单来说,它是多标签分类的泛化,其标签也可以是多类的(比如它可以有两个以上可能的值)。
为了说明这一点,构建一个系统去除图片中的噪声。给它输入一张有噪声的图片,它将(希望)输出一张干净的数字图片,与其他MNIST图片一样,以像素强度的一个数组作为呈现方式。请注意,这个分类器的输出是多个标签(一个像素点一个标签),每个标签可以有多个值(像素强度范围为0到225)。所以这是个多输出分类器系统的示例。
还是先从创建训练集和测试集开始,使用NumPy的randint函数为MNIST图片的像素强度增加噪声,目标是将图片还原为原始图片:
noise = np.random.randint(0, 100, (len(X_train), 784))
X_train_mod = X_train + noise
noise = np.random.randint(0, 100, (len(X_test), 784))
X_test_mod = X_test + noise
y_train_mod = X_train
y_test_mod = X_test
左边是有噪声的输入图片,右边是干净的目标图片:
some_index = 0
plt.subplot(121); plot_digit(X_test_mod[some_index])
plt.subplot(122); plot_digit(y_test_mod[some_index])
plt.show()

现在通过训练分类器,清洗这张图片:
knn_clf.fit(X_train_mod, y_train_mod)
clean_digit = knn_clf.predict([X_test_mod[some_index]])
plot_digit(clean_digit)

看起来效果不错,离目标够接近了。
习题1
为MNIST数据集构建一个分类器,并在测试集上达成超过97%的准确率。提示:KNeighborsClassifier对这个任务非常有效,只需要找到合适的超参数值即可(试试对weights和n_neighbors这两个超参数进行网格搜索)。
在KNN算法中,权重(weights)和邻居数量(n_neighbors)是关键的超参数,需在模型训练前手动设置以优化性能。
- n_neighbors:指定用于预测的最近邻居数量,默认为5。较小值(如3)可能捕捉噪声导致过拟合,较大值(如10)易忽略局部模式造成欠拟合,需在两者间平衡。
- weights:定义邻居的权重计算方式:
uniform:所有邻居权重相等,不考虑距离。distance:权重与距离成反比,较近的邻居影响更大。
param_grid通过网格搜索同时优化这两个参数,以找到最佳组合提升模型准确率。
from sklearn.model_selection import GridSearchCVparam_grid = [{'weights': ["uniform", "distance"], 'n_neighbors': [3, 4, 5]}]knn_clf = KNeighborsClassifier()
grid_search = GridSearchCV(knn_clf, param_grid, cv=5, verbose=3)
grid_search.fit(X_train, y_train)
# 最佳参数
grid_search.best_params_
{'n_neighbors': 4, 'weights': 'distance'}
# 最佳得分
grid_search.best_score_
0.9716166666666666
# 使用测试集测试效果
from sklearn.metrics import accuracy_scorey_pred = grid_search.predict(X_test)
accuracy_score(y_test, y_pred)
0.9714
习题2
写一个可以将MNIST图片向任意方向(上、下、左、右)移动一个像素的功能。然后对训练集中的每张图片,创建四个位移后的副本(每个方向一个),添加到训练集。最后,在这个扩展过的训练集上训练模型,测量其在测试集上的准确率。我们应该能注意到,模型的表现甚至变得更好了!这种人工扩展训练集的技术称为数据增广或训练集扩展。
from scipy.ndimage.interpolation import shiftdef shift_image(image, dx, dy):image = image.reshape((28, 28))shifted_image = shift(image, [dy, dx], cval=0, mode="constant")return shifted_image.reshape([-1])
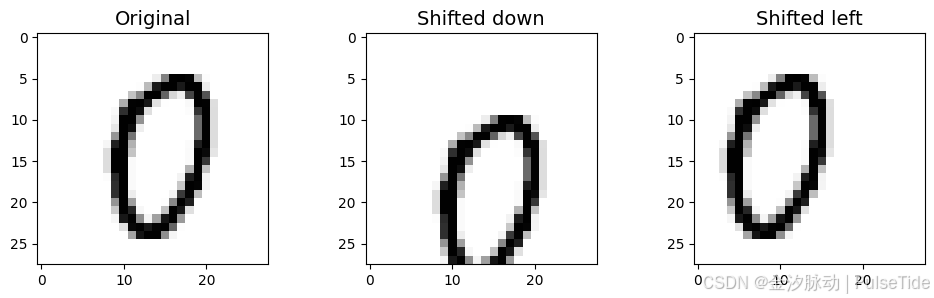
封装函数shift_image可以对图片image进行(dx,dy)像素偏移,对训练集的第1000个实例进行5像素的偏移测试:
image = X_train[1000]
shifted_image_down = shift_image(image, 0, 5)
shifted_image_left = shift_image(image, -5, 0)plt.figure(figsize=(12,3))
plt.subplot(131)
plt.title("Original", fontsize=14)
plt.imshow(image.reshape(28, 28), interpolation="nearest", cmap="Greys")
plt.subplot(132)
plt.title("Shifted down", fontsize=14)
plt.imshow(shifted_image_down.reshape(28, 28), interpolation="nearest", cmap="Greys")
plt.subplot(133)
plt.title("Shifted left", fontsize=14)
plt.imshow(shifted_image_left.reshape(28, 28), interpolation="nearest", cmap="Greys")
plt.show()
X_train_augmented = [image for image in X_train]
y_train_augmented = [label for label in y_train]for dx, dy in ((1, 0), (-1, 0), (0, 1), (0, -1)):for image, label in zip(X_train, y_train):X_train_augmented.append(shift_image(image, dx, dy))y_train_augmented.append(label)X_train_augmented = np.array(X_train_augmented)
y_train_augmented = np.array(y_train_augmented)
对训练集所有实例进行上下左右偏移,并做数据混合:
shuffle_idx = np.random.permutation(len(X_train_augmented))
X_train_augmented = X_train_augmented[shuffle_idx]
y_train_augmented = y_train_augmented[shuffle_idx]
使用最佳参数初始化一个分类器实例:
knn_clf = KNeighborsClassifier(**grid_search.best_params_)
训练模型:
knn_clf.fit(X_train_augmented, y_train_augmented)
使用测试集测试效果:
y_pred = knn_clf.predict(X_test)
accuracy_score(y_test, y_pred)
0.9763
从结果上看,通过简单的数据增强,模型性能得到了小幅度的提升。