强化学习入门教程(附学习文档)
强化学习(Reinforcement Learning, RL)是一种机器学习的方法,它关注如何通过与环境交互来学习策略,以使某个累积奖励(cumulative reward)最大化
强化学习的基本概念
- 环境(Environment)
:智能体所处的外部世界,它可以是一个物理系统或模拟系统。
- 状态(State)
:描述环境在某一时刻的情况。
- 动作(Action)
:智能体能够对环境采取的操作。
- 奖励(Reward)
:环境在智能体执行动作后给予的即时反馈,用于评估该动作的好坏。
- 策略(Policy)
:智能体决定在给定状态下采取何种行动的规则或方法。
- 值函数(Value Function)
:用来估计从当前状态开始,遵循特定策略所能得到的长期奖励的预期值。
- 模型(Model)
:对环境的抽象表示,用于预测给定状态下采取特定动作后的结果。
强化学习的主要算法类型
- 价值迭代方法
:如Q-learning和SARSA等,这类方法试图直接学习值函数。
- 策略梯度方法
:直接优化策略本身,而不是通过值函数间接地优化策略。
- Actor-Critic方法
:结合了价值迭代和策略梯度的优点,同时学习一个策略(actor)和一个值函数(critic)
基于这三种架构,还拓展出DDPG, PPO, DPO,SAC之类的算法
下面给大家推荐Datawhale开源的JoyRL项目
强化学习入门不难,可以直接抄作业,按照下面的教程计划来就行

项目主要内容如下:
第一章:介绍强化学习概述(难度*)
对于没接触过强化学习的同学可以大概看一下,知道强化学习能应用于什么问题,包含哪些主要研究方向,有个总体的印象就行
第二章:介绍马尔科夫决策过程(难度**)
马尔科夫决策过程是后面推导价值函数的基础,具有重要作用,一定要领域其主要的思想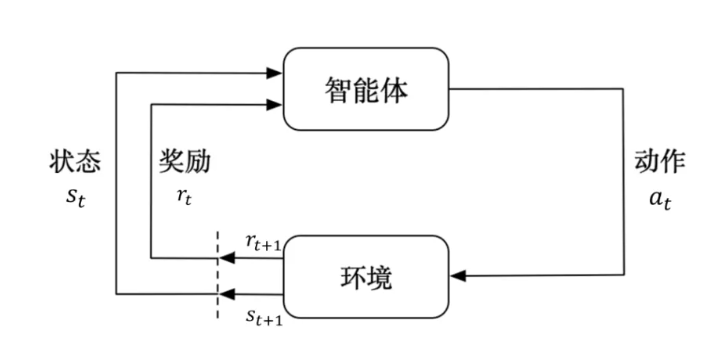
第三章:介绍动态规划算法(难度**)
本章主要讲解了动态规划的思想及其在强化学习上应用的两个算法(策略迭代和价值迭代),这两种算法虽然目前很少会用到,但是对于推导更复杂的强化学习算法起到了奠定基础的作用,建议掌握
第四章:介绍免模型预测(难度**)
免预测模型包括蒙特卡洛方法和时序差分方法,有模型,免模型,预测与控制,这些都是强化学习的重要概念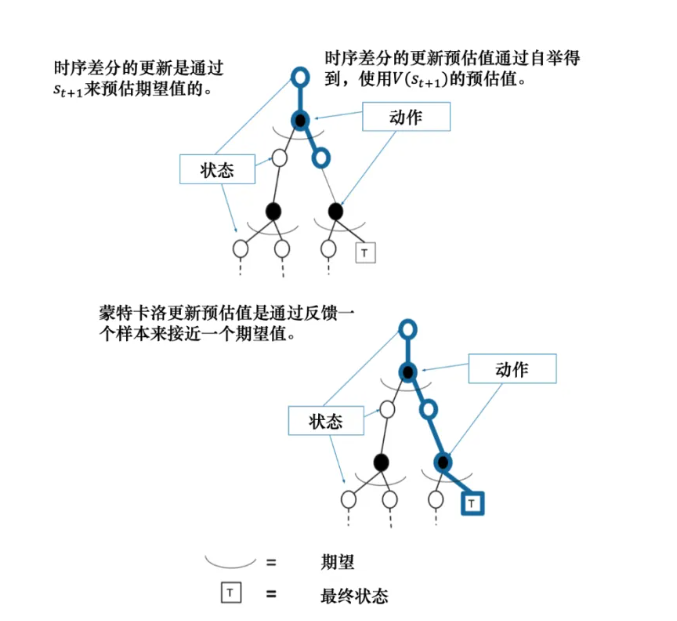
第五章:介绍免模型控制(难度**)
免模型则是指不需要知道环境的状态转移概率的一类算法,实际上很多经典的强化学习算法都是免模型控制的。本章会重点介绍两种基础的免模型算法,Q-learning 和 Sarasa ,也都是基于时序差分的方法
第六章:介绍深度学习基础(难度*)
主要是讲解关于线性回归,梯度下降,全连接之类的深度学习基础,如果有深度学习基础的同学完全可以跳过
第七章:介绍DQN算法(难度**)
DQN算法实在Q-learning算法的基础上引入了深度神经网络来近似动作价值函数,从而能够处理高维的状态空间。第八章是对DQN算法的进阶介绍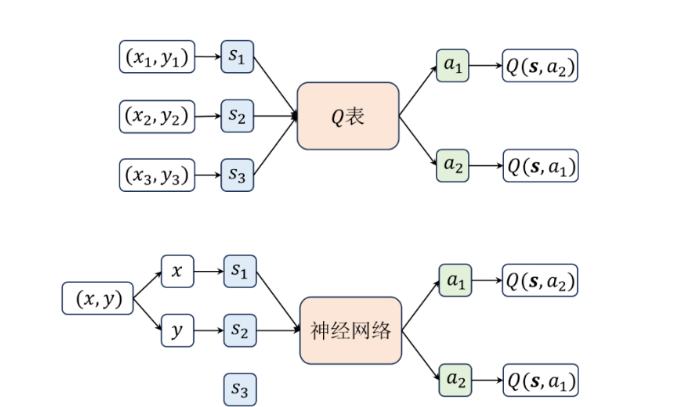
第九章:介绍策略梯度(难度***)
基于价值算法有一些缺点,比如无法表示连续动作,高方差以及探索与利用的平衡问题,策略梯度算法是一类直接对策略进行优化的算法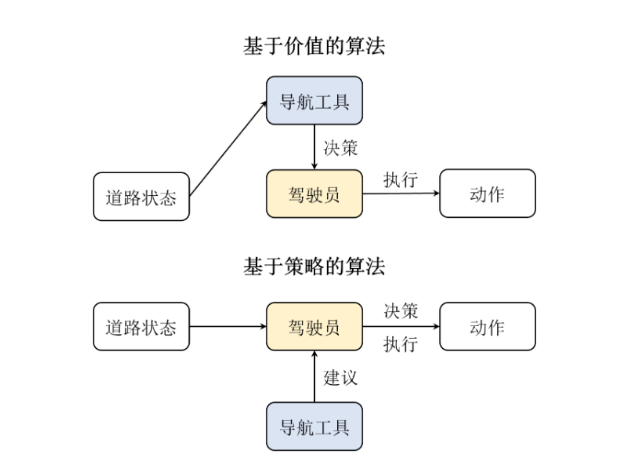
第十章:介绍Actor-Critic算法(难度***)
主要介绍了 A2C与 A3C算法,相比于前一章讲的强化学习算法,主要优化了 Critic部分的估计,提高了算法的收敛速度。并且通过引入异步训练的方式来进一步提高这类算法的收敛速度,实践中我们会用 multiprocessing 等多进程模块来实现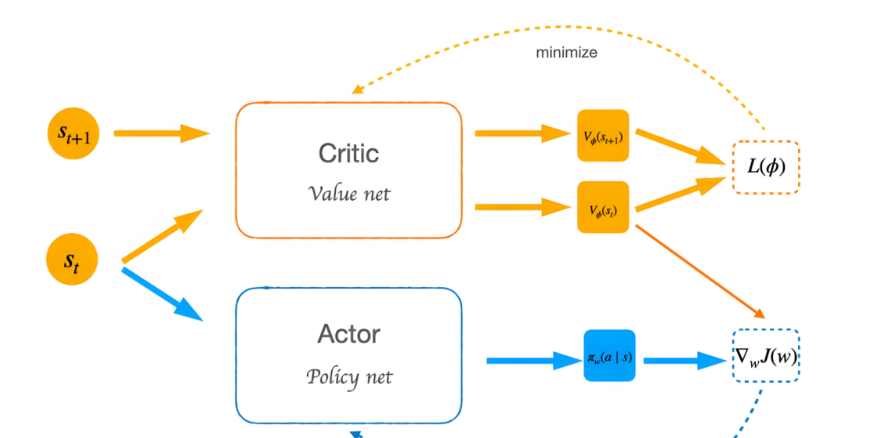
后面11-13章,介绍DDPG, PPO和SAC算法,属于进阶的内容
把前面十章的内容学完,就算是强化学习入门了,可以配合一些视频教程来学习,后面再学一些DPO,RLHF之类的算法
强化学习教程PDF获取
