DINOv3 论文精读(逐段解析)
DINOv3 论文精读(逐段解析)
论文地址:https://arxiv.org/abs/2508.10104
工程地址:https://github.com/facebookresearch/dinov3
2025
Meta AI 研究院
======================================================================
【论文总结】:DINOv3是一个突破性的自监督视觉基础模型,其核心技术创新围绕三个关键方面:大规模数据与模型协同扩展、Gram锚定技术解决密集特征退化、多阶段训练策略。首先,通过精心设计的三重数据策略(聚类策划+检索策划+标准数据集混合)和70亿参数ViT架构,实现了数据与模型的协同扩展,解决了传统自监督学习在规模化时的稳定性问题。其次,最具创新性的Gram锚定技术通过约束patch特征间的Gram矩阵相似性结构,有效解决了长期训练中密集特征质量退化的问题,使模型在保持全局语义理解能力的同时维持精确的空间定位能力。最后,采用多阶段训练流程:基础自监督训练→Gram锚定细化→高分辨率适应→知识蒸馏,每个阶段都针对特定目标进行优化,最终产生了一个真正通用的视觉编码器,在无需微调的情况下就能在目标检测、语义分割、深度估计等多种任务上达到最优性能,为计算机视觉领域树立了新的技术标杆。
======================================================================
Abstract
Self-supervised learning holds the promise of eliminating the need for manual data annotation, enabling models to scale effortlessly to massive datasets and larger architectures. By not being tailored to specific tasks or domains, this training paradigm has the potential to learn visual representations from diverse sources, ranging from natural to aerial images— using a single algorithm. This technical report introduces DINOv3, a major milestone toward realizing this vision by leveraging simple yet effective strategies. First, we leverage the benefit of scaling both dataset and model size by careful data preparation, design, and optimization. Second, we introduce a new method called Gram anchoring, which effectively addresses the known yet unsolved issue of dense feature maps degrading during long training schedules. Finally, we apply post-hoc strategies that further enhance our models’ flexibility with respect to resolution, model size, and alignment with text. As a result, we present a versatile vision foundation model that outperforms the specialized state of the art across a broad range of settings, without fine-tuning. DINOv3 produces high-quality dense features that achieve outstanding performance on various vision tasks, significantly surpassing previous self- and weakly-supervised foundation models. We also share the DINOv3 suite of vision models, designed to advance the state of the art on a wide spectrum of tasks and data by providing scalable solutions for diverse resource constraints and deployment scenarios.
【翻译】自监督学习有望消除手动数据标注的需求,使模型能够毫不费力地扩展到大规模数据集和更大的架构。通过不针对特定任务或领域进行定制,这种训练范式有潜力从多样化的来源学习视觉表示,从自然图像到航拍图像——使用单一算法。这份技术报告介绍了DINOv3,这是通过利用简单而有效的策略来实现这一愿景的重要里程碑。首先,我们通过仔细的数据准备、设计和优化来利用扩展数据集和模型大小的好处。其次,我们引入了一种称为Gram锚定的新方法,它有效地解决了密集特征图在长期训练计划中退化的已知但未解决的问题。最后,我们应用后处理策略,进一步增强我们模型在分辨率、模型大小和与文本对齐方面的灵活性。因此,我们提出了一个多功能的视觉基础模型,在不进行微调的情况下,在广泛的设置范围内超越了专业的最先进技术。DINOv3产生高质量的密集特征,在各种视觉任务上取得出色性能,显著超越了之前的自监督和弱监督基础模型。我们还分享了DINOv3视觉模型套件,旨在通过为不同资源约束和部署场景提供可扩展解决方案,在广泛的任务和数据范围内推进最先进技术。
【解析】自监督学习的本质是让模型从未标注的数据中自主学习有用的表示,这种方法的优势在于它不依赖人工标注,因此可以充分利用互联网上海量的图像数据。传统的监督学习需要为每张图像提供标签,这不仅成本高昂,而且限制了数据规模的扩展。而自监督学习通过设计巧妙的学习任务,让模型从数据本身的结构和模式中学习,从而绕过了标注瓶颈。DINOv3的第一个重要贡献是数据和模型的协同扩展。深度学习中,数据量和模型规模通常需要同步增长才能达到最佳效果。数据准备不仅包括收集更多图像,还涉及数据质量控制、多样性保证和分布平衡。模型设计则需要考虑如何有效利用增加的参数量,避免过拟合和训练不稳定等问题。第二个核心创新是Gram锚定技术。在长期训练过程中,密集特征图会逐渐失去细节信息,这是一个困扰自监督学习的关键问题。密集特征图包含图像中每个位置的特征信息,对于语义分割、目标检测等需要精确空间定位的任务至关重要。Gram锚定通过特定的正则化策略来保持这些密集特征的质量,确保模型在获得全局理解能力的同时,不会牺牲局部细节的表达能力。后处理策略的引入进一步提升了模型的实用性。最终的成果是一个真正通用的视觉基础模型,它在无需微调的情况下就能在多种任务上达到最优性能。"冻结骨干网络"的使用方式大大降低了模型部署的复杂性和计算成本,同时保证了在不同任务间的一致性表现。
1 Introduction
Foundation models have become a central building block in modern computer vision, enabling broad generalization across tasks and domains through a single, reusable model. Self-supervised learning (SSL) is a powerful approach for training such models, by learning directly from raw pixel data and leveraging the natural co-occurrences of patterns in images. Unlike weakly and fully supervised pretraining methods ( Radford et al. , 2021 ; Dehghani et al. , 2023 ; Bolya et al. , 2025 ) which require images paired with high-quality metadata, SSL unlocks training on massive, raw image collections. This is particularly effective for training large-scale visual encoders thanks to the availability of virtually unlimited training data. DINOv2 ( Oquab et al. , 2024 ) exemplifies these strengths, achieving impressive results in image understanding tasks ( Wang et al. , 2025 ) and enabling pre-training for complex domains such as histopathology ( Chen et al. , 2024 ). Models trained with SSL exhibit additional desirable properties: they are robust to input distribution shifts, provide strong global and local features, and generate rich embeddings that facilitate physical scene understanding. Since SSL models are not trained for any specific downstream task, they produce versatile and robust generalist features. For instance, DINOv2 models deliver strong performance across diverse tasks and domains without requiring task-specific finetuning, allowing a single frozen backbone to serve multiple purposes. Importantly, self-supervised learning is especially suitable to train on the vast amount of available observational data in domains like histopathology ( Vorontsov et al. , 2024 ), biology ( Kim et al. , 2025 ), medical imaging ( PérezGarcía et al. , 2025 ), remote sensing ( Cong et al. , 2022 ; Tolan et al. , 2024 ), astronomy ( Parker et al. , 2024 ), or high-energy particle physics ( Dillon et al. , 2022 ). These domain often lack metadata and have already been shown to benefit from foundation models like DINOv2. Finally, SSL, requiring no human intervention, is well-suited for lifelong learning amid the growing volume of web data.
【翻译】基础模型已成为现代计算机视觉的核心构建块,通过单个可重用模型实现跨任务和领域的广泛泛化。自监督学习(SSL)是训练此类模型的强大方法,通过直接从原始像素数据学习并利用图像中模式的自然共现性。与需要图像配对高质量元数据的弱监督和全监督预训练方法(Radford et al., 2021; Dehghani et al., 2023; Bolya et al., 2025)不同,SSL解锁了在大规模原始图像集合上的训练。由于几乎无限的训练数据的可用性,这对于训练大规模视觉编码器特别有效。DINOv2(Oquab et al., 2024)体现了这些优势,在图像理解任务中取得了令人印象深刻的结果(Wang et al., 2025),并为病理学等复杂领域的预训练提供了支持(Chen et al., 2024)。用SSL训练的模型表现出额外的理想特性:它们对输入分布偏移具有鲁棒性,提供强大的全局和局部特征,并生成有助于物理场景理解的丰富嵌入。由于SSL模型不是为任何特定的下游任务训练的,它们产生多功能且鲁棒的通用特征。例如,DINOv2模型在不需要任务特定微调的情况下,在各种任务和领域中提供强大的性能,允许单个冻结的骨干网络服务于多种目的。重要的是,自监督学习特别适合在病理学(Vorontsov et al., 2024)、生物学(Kim et al., 2025)、医学成像(PérezGarcía et al., 2025)、遥感(Cong et al., 2022; Tolan et al., 2024)、天文学(Parker et al., 2024)或高能粒子物理学(Dillon et al., 2022)等领域的大量可用观测数据上进行训练。这些领域通常缺乏元数据,并且已经被证明受益于像DINOv2这样的基础模型。最后,不需要人工干预的SSL非常适合在不断增长的网络数据量中进行终身学习。
【解析】基础模型的核心价值在于其"一次训练,处处使用"的特性。随着互联网数据的持续增长,模型需要能够不断适应新的数据分布和视觉概念,而自监督学习的无监督特性使这种持续学习成为可能。
Figure 1: (a) Evolution of linear probing results on ImageNet1k (IN1k) over the years, comparing fully(SL), weakly- (WSL) and self-supervised learning (SSL) methods. Despite coming into the picture later, SSL has quickly progressed and now reached the Imagenet accuracy plateau of recent years. On the other hand, we demonstrate that SSL offers the unique promise of high-quality dense features. With DINOv3, we markedly improve over weakly-supervised models on dense tasks, as shown by the relative performance of the best-in-class WSL models to DINOv3 (b). We also produce PCA maps of features obtained from high resolution images with DINOv3 trained on natural © and aerial images (d).
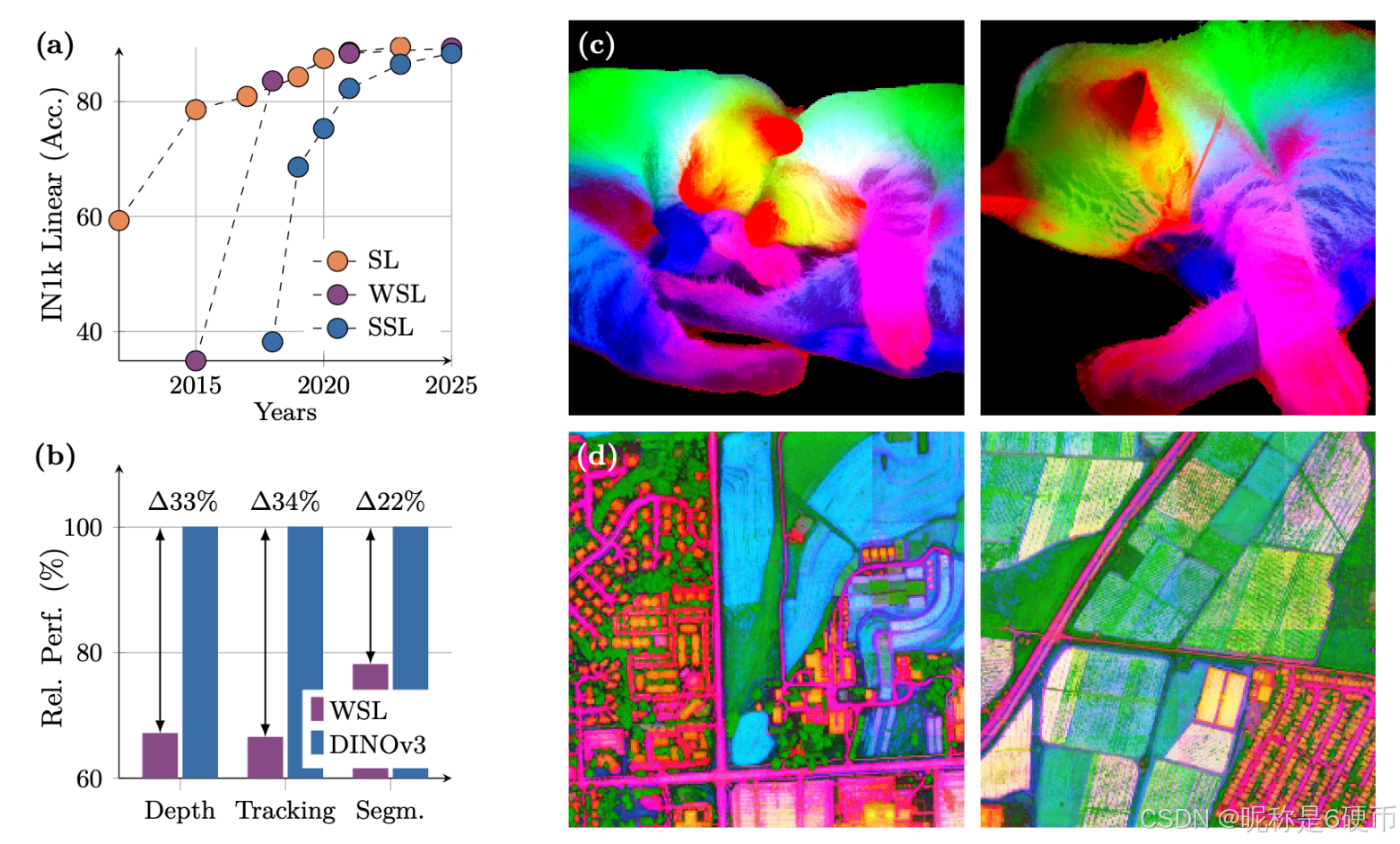
【翻译】图1:(a) 多年来ImageNet1k (IN1k)上线性探测结果的演变,比较了全监督(SL)、弱监督(WSL)和自监督学习(SSL)方法。尽管SSL出现较晚,但它快速发展,现在已经达到了近年来ImageNet准确率的平台期。另一方面,我们证明SSL提供了高质量密集特征的独特优势。通过DINOv3,我们在密集任务上显著超越了弱监督模型,如最佳WSL模型与DINOv3的相对性能所示(b)。我们还生成了从DINOv3在自然图像©和航拍图像(d)上训练得到的高分辨率图像特征的PCA图。
【解析】这个图表展示了自监督学习发展的技术突破。线性探测是评估预训练模型质量的标准方法,它将预训练的特征提取器冻结,只训练一个简单的线性分类器来完成下游任务。能够直接反映预训练模型学到的表示质量,而不受下游任务特定优化的影响。图中显示的演变过程反映了深度学习发展的三个主要阶段:全监督学习依赖大量人工标注数据,在早期取得了显著成功;弱监督学习利用图像与文本的配对关系,通过CLIP等模型实现了新的突破;自监督学习虽然起步较晚,但通过巧妙的任务设计避免了对标注数据的依赖,最终在性能上追平甚至超越了其他方法。密集特征质量的提升是DINOv3的核心优势。传统的视觉模型往往专注于全局图像理解,在提取局部细节特征时表现不佳。密集特征指的是模型对图像中每个位置都能产生有意义的特征表示,这对于语义分割、目标检测、深度估计等需要精确空间定位的任务至关重要。PCA可视化展示了模型学到的特征在语义上的连贯性和空间上的精确性,不同颜色区域对应不同的语义概念,颜色边界与实际物体边界的吻合程度反映了特征质量的高低。
In practice, the promise of SSL, namely producing arbitrarily large and powerful models by leveraging large amounts of unconstrained data, remains challenging at scale. While model instabilities and collapse are mitigated by the heuristics proposed by Oquab et al. ( 2024 ), more problems emerge from scaling further. First, it is unclear how to collect useful data from unlabeled collections. Second, in usual training practice, employing cosine schedules implies knowing the optimization horizon a priori, which is difficult when training on large image corpora. Third, the performance of the features gradually decreases after early training, confirmed by visual inspection of the patch similarity maps. This phenomenon appears in longer training runs with models above ViT-Large size (300M parameters), reducing the usefulness of scaling DINOv2.
【翻译】在实践中,SSL的潜力,即通过利用大量无约束数据来产生任意大型和强大的模型,在规模化时仍然具有挑战性。虽然Oquab等人(2024)提出的启发式方法缓解了模型不稳定性和崩溃问题,但进一步扩展时会出现更多问题。首先,如何从未标记的集合中收集有用数据尚不清楚。其次,在通常的训练实践中,采用余弦调度需要先验地知道优化视界,这在大型图像语料库上训练时很困难。第三,特征的性能在早期训练后逐渐下降,这通过补丁相似性图的视觉检查得到了证实。这种现象出现在ViT-Large规模以上(300M参数)模型的长期训练运行中,降低了扩展DINOv2的有用性。
【解析】这段话表明了自监督学习规模化过程中面临的三个技术挑战。数据收集的困难在于无标注数据的质量参差不齐,需要设计有效的数据筛选和预处理策略来确保训练数据的多样性和代表性,同时避免噪声数据对模型性能的负面影响。优化调度的问题源于深度学习训练的复杂性。余弦学习率调度是一种常用的学习率衰减策略,它要求预先设定总的训练步数,然后按照余弦函数的形状逐渐降低学习率。但在大规模数据集上,很难准确估计达到收敛所需的训练时间,这使得制定有效的学习率调度变得困难。最关键的问题是特征质量的退化现象。在长期训练过程中,模型虽然在全局任务上表现持续改善,但局部特征的质量却开始下降。这种现象可以通过补丁相似性图观察到:高质量的特征应该让语义相似的图像区域在特征空间中距离较近,而语义不同的区域距离较远。当这种相似性模式变得模糊或混乱时,说明模型的密集特征表示能力在退化。这个问题在大模型中更加严重,因为更多的参数和更长的训练时间放大了这种退化效应,这也是为什么简单地扩大DINOv2模型规模无法带来预期收益的根本原因。
Addressing the problems above leads to this work, DINOv3 , which advances SSL training at scale. We demonstrate that a single frozen SSL backbone can serve as a universal visual encoder that achieves stateof-the-art performance on challenging downstream tasks, outperforming supervised and metadata-reliant pre-training strategies. Our research is guided by the following objectives: (1) training a foundational model versatile across tasks and domains, (2) improving the shortcomings of existing SSL models on dense features, (3) disseminating a family of models that can be used off-the-shelf. We discuss the three aims in the following.
【翻译】解决上述问题导致了这项工作,DINOv3,它推进了SSL的大规模训练。我们证明了单个冻结的SSL骨干网络可以作为通用视觉编码器,在具有挑战性的下游任务上达到最先进的性能,超越了监督学习和依赖元数据的预训练策略。我们的研究遵循以下目标:(1) 训练一个跨任务和领域的通用基础模型,(2) 改善现有SSL模型在密集特征方面的不足,(3) 传播一系列可以开箱即用的模型。我们在下文中讨论这三个目标。
【解析】通用视觉编码器的实现需要模型具备强大的特征抽象能力,能够从原始像素数据中提取出既包含全局语义信息又保留局部细节的多层次表示。这种表示需要具备足够的普适性,使得同一套特征能够同时支持图像分类、目标检测、语义分割、深度估计等多种视觉任务。第一个目标强调了基础模型的跨域泛化能力,这要求模型不仅能在自然图像上表现优异,还能适应医学影像、卫星图像、显微镜图像等专业领域的数据分布。第二个目标针对密集特征质量的提升,密集特征指模型对图像中每个空间位置都能产生有意义的特征表示,这对于需要精确空间定位的任务至关重要。现有SSL模型往往在长期训练过程中出现密集特征退化现象,导致局部细节信息丢失。第三个目标通过提供不同规模的预训练模型来满足不同计算资源约束下的应用需求,降低先进视觉技术的使用门槛。
Figure 2: Performance of the DINOv3 family of models, compared to other families of self- or weaklysupervised models, on different benchmarks. DINOv3 significantly surpasses others on dense benchmarks, including models that leverage mask annotation priors such as AM-RADIO ( Heinrich et al. , 2025 ).
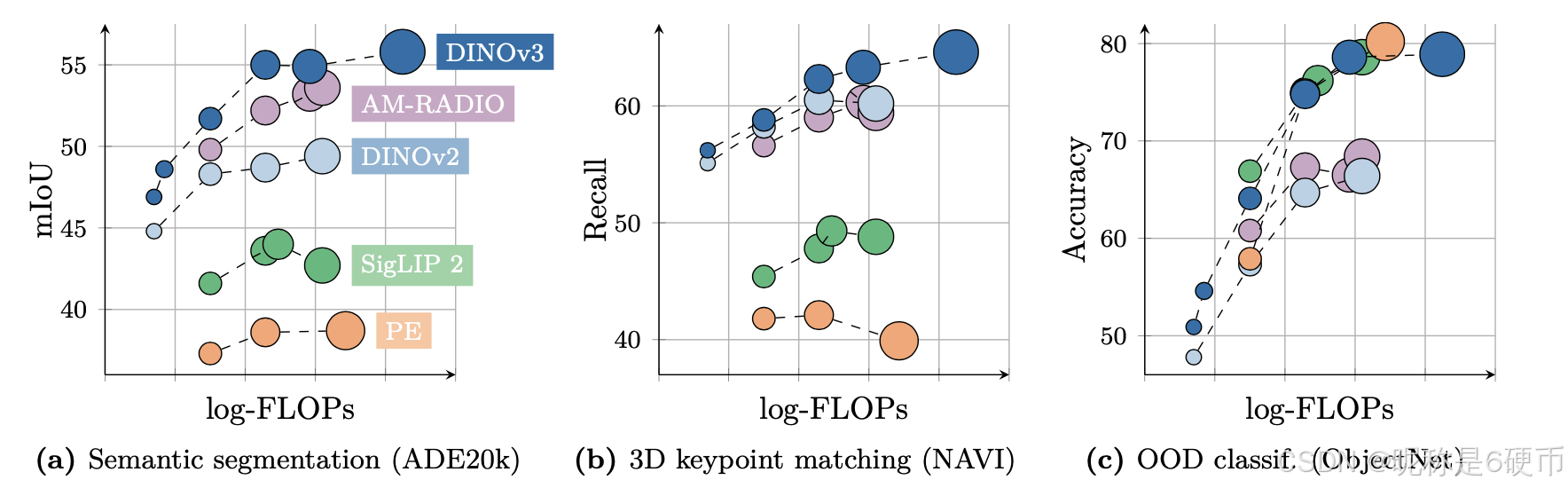
【翻译】图2:DINOv3模型家族与其他自监督或弱监督模型家族在不同基准测试上的性能比较。DINOv3在密集基准测试上显著超越其他模型,包括利用掩码标注先验的模型,如AM-RADIO (Heinrich et al., 2025)。
【解析】性能对比图展示了DINOv3在密集预测任务上的显著优势。密集基准测试任务对模型的局部特征表示能力要求极高,需要模型能够准确捕捉物体边界、纹理细节和空间关系。AM-RADIO等模型利用掩码标注先验,即通过人工标注的分割掩码来指导训练过程,虽然能够提供精确的空间定位信息,但需要大量的人工标注成本。DINOv3能够在完全无监督的情况下超越这些利用额外监督信号的方法,说明其自监督学习算法在特征学习上的有效性。
Strong & Versatile Foundational Models DINOv3 aims to offer a high level of versatility along two axes, which is enabled by the scaling of the model size and training data. First, a key desirable property for SSL models is to achieve excellent performance while being kept frozen, ideally reaching similar stateof-the-art results as specialized models. In that case, a single forward pass can deliver cutting-edge results across multiple tasks, leading to substantial computational savings—an essential advantage for practical applications, particularly on edge devices. We show the wide breadth of tasks that DINOv3 can successfully be applied to in Sec. 6 . Second, a scalable SSL training pipeline that does not depend on metadata unlocks numerous scientific applications. By pre-training on a diverse set of images, whether web images or observational data, SSL models generalize across a large set of domains and tasks. As illustrated in Fig. 1 (d), the PCA of DINOv3 features extracted from a high-resolution aerial image clearly allows to separates roads, houses, and greenery, highlighting the model’s feature quality.
【翻译】强大且多功能的基础模型 DINOv3旨在沿着两个轴提供高水平的多功能性,这通过模型大小和训练数据的扩展得以实现。首先,SSL模型的一个关键理想特性是在保持冻结状态下实现出色性能,理想情况下达到与专业模型相似的最先进结果。在这种情况下,单次前向传播可以在多个任务中提供前沿结果,从而带来大量的计算节省——这对于实际应用来说是一个重要优势,特别是在边缘设备上。我们在第6节中展示了DINOv3可以成功应用的任务的广泛范围。其次,不依赖元数据的可扩展SSL训练管道解锁了众多科学应用。通过在多样化的图像集合上进行预训练,无论是网络图像还是观测数据,SSL模型都能在大量领域和任务中泛化。如图1(d)所示,从高分辨率航拍图像中提取的DINOv3特征的PCA清楚地允许分离道路、房屋和绿地,突出了模型的特征质量。
【解析】DINOv3的多功能性设计体现在两个维度上。第一个维度是"冻结骨干网络"的通用性。第二个维度是跨领域的泛化能力。
Superior Feature Maps Through Gram Anchoring Another key feature of DINOv3 is a significant improvement of its dense feature maps. The DINOv3 SSL training strategy aims at producing models excelling at high-level semantic tasks while producing excellent feature maps amenable to solving geometric tasks such as depth estimation, or 3D matching. In particular, the models should produce dense features that can be used off-the-shelf or with little post-processing. The compromise between dense and global representation is especially difficult to optimize when training with vast amounts of images, since the objective of high-level understanding can conflict with the quality of the dense feature maps. These contradictory objectives lead to a collapse of dense features with large models and long training schedules. Our new Gram anchoring strategy effectively mitigates this collapse (see Sec. 4 ). As a result, DINOv3 obtains significantly better dense feature maps than DINOv2, staying clean even at high resolutions (see Fig. 3 ).
【翻译】通过Gram锚定实现优质特征图 DINOv3的另一个关键特性是其密集特征图的显著改进。DINOv3 SSL训练策略旨在产生在高级语义任务中表现出色的模型,同时产生适合解决诸如深度估计或3D匹配等几何任务的优秀特征图。特别是,模型应该产生可以开箱即用或只需很少后处理的密集特征。当使用大量图像进行训练时,密集表示和全局表示之间的妥协特别难以优化,因为高级理解的目标可能与密集特征图的质量冲突。这些矛盾的目标导致大型模型和长期训练计划中密集特征的崩溃。我们新的Gram锚定策略有效地缓解了这种崩溃(见第4节)。因此,DINOv3获得了比DINOv2显著更好的密集特征图,即使在高分辨率下也保持清晰(见图3)。
【解析】密集特征图质量的提升是DINOv3的核心技术突破之一。在计算机视觉中,模型需要同时具备两种不同层次的理解能力:全局语义理解和局部几何理解。全局语义理解关注的是"这是什么"的问题,比如识别图像中包含的物体类别、场景类型等高层语义信息;而局部几何理解则关注"在哪里"和"什么形状"的问题,需要对图像中每个像素位置都能产生有意义的特征表示,这对于深度估计、三维重建、精确分割等任务至关重要。传统上,这两个目标存在天然的冲突:为了获得更好的全局语义理解,模型倾向于学习更加抽象和概括的特征表示,这个过程往往会丢失局部的细节信息;而保持局部细节信息则可能影响模型对全局语义的抽象能力。在大规模长期训练过程中,这种冲突会导致"密集特征崩溃"现象——模型的密集特征图逐渐失去空间精确性和语义一致性,变得模糊和不可用。Gram锚定技术通过引入特定的正则化机制来解决这个问题。Gram矩阵原本是用来描述特征之间相关性的数学工具,在这里被用作锚定点,确保训练过程中密集特征的质量不会随着训练的进行而退化。这种方法使得DINOv3能够在保持强大全局理解能力的同时,产生高质量的密集特征图,这些特征图即使在高分辨率输入下也能保持清晰和准确。
The DINOv3 Family of Models Solving the degradation of dense feature map with Gram anchoring unlocks the power of scaling. As a consequence, training a much larger model with SSL leads to significant performance improvements. In this work, we successfully train a DINO model with 7B parameters. Since such a large model requires significant resources to run, we apply distillation to compress its knowledge into smaller variants. As a result, we present the DINOv3 family of vision models , a comprehensive suite designed to address a wide spectrum of computer vision challenges. This model family aims to advance the state of the art by offering scalable solutions adaptable to diverse resource constraints and deployment scenarios. The distillation process produces model variants at multiple scales, including Vision Transformer (ViT) Small, Base, and Large, as well as ConvNeXt-based architectures. Notably, the efficient and widely adopted ViT-L model achieves performance close to that of the original 7B teacher across a variety of tasks. Overall, the DINOv3 family demonstrates strong performance on a broad range of benchmarks, matching or exceeding the accuracy of competing models on global tasks, while significantly outperforming them on dense prediction tasks, as visible in Fig. 2 .
【翻译】DINOv3模型系列:通过Gram锚定解决密集特征图退化问题释放了缩放的力量。因此,使用SSL训练更大的模型带来了显著的性能改进。在这项工作中,我们成功训练了一个具有70亿参数的DINO模型。由于如此大的模型需要大量资源来运行,我们应用蒸馏将其知识压缩到较小的变体中。因此,我们提出了DINOv3视觉模型系列,这是一个旨在解决广泛的计算机视觉挑战的综合套件。该模型系列旨在通过提供适应不同资源约束和部署场景的可扩展解决方案来推进最先进技术。蒸馏过程产生了多个规模的模型变体,包括Vision Transformer (ViT) Small、Base和Large,以及基于ConvNeXt的架构。值得注意的是,高效且广泛采用的ViT-L模型在各种任务上实现了接近原始70亿参数教师模型的性能。总体而言,DINOv3系列在广泛的基准测试中表现出强劲的性能,在全局任务上匹配或超越竞争模型的准确性,同时在密集预测任务上显著超越它们,如图2所示。
【解析】自监督学习模型中,当模型规模超过一定阈值并进行长期训练时,密集特征图会出现质量退化现象,限制模型扩展的收益。Gram锚定通过特定的正则化机制保持特征图的内在结构稳定性,使得更大规模的模型训练成为可能。70亿参数模型在实际部署中面临巨大的计算资源挑战,知识蒸馏成为解决这一矛盾的关键手段,通过让小模型学习大模型的预测行为和内部表示,在保持性能的同时大幅降低计算成本。蒸馏过程不仅仅是简单的参数压缩,而是一种知识传递过程,大模型作为教师网络指导小模型的训练,使小模型能够获得超越其自身容量的表达能力。DINOv3模型通过提供从Small到Large的多个规模变体,用户可以根据具体的资源约束和性能需求选择最适合的模型。
Figure 3: High-resolution dense features. We visualize the cosine similarity maps obtained with DINOv3 output features between the patches marked with a red cross and all other patches. Input image at 4096×40964096\times40964096×4096 . Please zoom in , do you agree with DINOv3?

【翻译】图3:高分辨率密集特征。我们可视化了使用DINOv3输出特征在标有红十字的补丁与所有其他补丁之间获得的余弦相似性图。输入图像为4096×40964096\times40964096×4096。请放大查看,你同意DINOv3的结果吗?
【解析】这个可视化展示了DINOv3在超高分辨率图像上的密集特征提取能力。4096×40964096\times40964096×4096属于极高分辨率,余弦相似性度量用于评估特征质量,计算两个特征向量之间的夹角余弦值,值越接近1说明特征越相似,越接近0说明差异越大。通过选择图像中的特定位置(红十字标记)作为查询点,然后计算该位置的特征与图像中所有其他位置特征的相似性,可以直观地观察模型对语义概念的理解程度。高质量的视觉特征应该能够识别出语义相似的区域,比如同一个物体的不同部分、相似的纹理或材质等。可视化结果中相似性的空间分布模式能够反映模型是否真正理解了图像的语义结构,而不是仅仅基于低级的颜色或纹理特征进行匹配。高分辨率下的特征一致性对于需要精确空间定位的任务极其重要,它能够支持精细的图像分析和编辑应用。
Overview of Contributions In this work, we introduce multiple contributions to address the challenge of scaling SSL towards a large frontier model. We build upon recent advances in automatic data curation ( Vo et al. , 2024 ) to obtain a large “background” training dataset that we carefully mix with a bit of specialized data (ImageNet-1k). This allows leveraging large amounts of unconstrained data to improve the model performance. This contribution (i) around data scaling will be described in Sec. 3.1 .
We increase our main model size to 7B parameters by defining a custom variant of the ViT architecture. We include modern position embeddings (axial RoPE) and develop a regularization technique to avoid positional artifacts. Departing from the multiple cosine schedules in DINOv2, we train with constant hyperparameter schedules for 1M iterations. This allows producing models with stronger performance. This contribution (ii) on model architecture and training will be described in Sec. 3.2 .
With the above techniques, we are able to train a model following the DINOv2 algorithm at scale. However, as mentioned previously, scale leads to a degradation of dense features. To address this, we propose a core improvement of the pipeline with a Gram anchoring training phase. This cleans the noise in the feature maps, leading to impressive similarity maps, and drastically improving the performance on both parametric and non-parametric dense tasks. This contribution (iii) on Gram training will be described in Sec. 4 .
【翻译】贡献概述 在这项工作中,我们引入了多项贡献来解决将SSL扩展到大型前沿模型的挑战。我们基于自动数据策划的最新进展(Vo等人,2024)来获得一个大型"背景"训练数据集,我们将其与少量专业数据(ImageNet-1k)仔细混合。这允许利用大量无约束数据来改善模型性能。关于数据扩展的贡献(i)将在第3.1节中描述。
我们通过定义ViT架构的自定义变体将主模型大小增加到70亿参数。我们包括现代位置嵌入(轴向RoPE)并开发了一种正则化技术来避免位置伪影。与DINOv2中的多个余弦调度不同,我们使用恒定超参数调度训练100万次迭代。这允许产生性能更强的模型。关于模型架构和训练的贡献(ii)将在第3.2节中描述。
通过上述技术,我们能够大规模地训练遵循DINOv2算法的模型。然而,如前所述,规模导致密集特征的退化。为了解决这个问题,我们提出了使用Gram锚定训练阶段对管道的核心改进。这清理了特征图中的噪声,产生了令人印象深刻的相似性图,并大幅改善了参数化和非参数化密集任务的性能。关于Gram训练的贡献(iii)将在第4节中描述。
【解析】总结了DINOv3的三个技术贡献,每个贡献都针对自监督学习规模化过程中的难题。第一个贡献解决的是数据质量与数量的平衡问题。在大规模训练中,简单地增加数据量并不能保证模型性能的提升,因为网络数据的质量参差不齐,包含大量噪声和冗余信息。自动数据策划技术通过算法自动筛选和组织训练数据,确保数据的多样性和代表性。将大规模"背景"数据与精心策划的ImageNet-1k数据混合,既保证了数据的广度又确保了质量,混合策略能够让模型在保持泛化能力的同时获得更好的性能。第二个贡献涉及模型架构的创新设计。将模型规模扩展到70亿参数是一个巨大的技术挑战,需要解决计算效率、训练稳定性和位置编码等多个问题。轴向RoPE(Rotary Position Embedding)是一种先进的位置编码方法,能够更好地处理不同长度和分辨率的输入,同时保持计算效率。位置伪影是指由于位置编码不当导致的模型对图像中特定位置产生偏见的现象,正则化技术的引入有效缓解了这个问题。恒定超参数调度相比于复杂的余弦调度更加稳定,避免了学习率变化过于复杂导致的训练不稳定性。第三个贡献是最为关键的Gram锚定技术。在大规模训练过程中,虽然全局特征质量持续改善,但密集特征往往会出现退化现象,表现为特征图中出现噪声、空间一致性下降等问题。Gram矩阵能够捕捉特征之间的二阶统计信息,通过锚定机制确保特征图的空间一致性和语义连贯性,从而解决了规模化训练中密集特征退化的核心问题。
Following previous practice, the last steps of our pipeline consist of a high-resolution post-training phase and distillation into a series of high-performance models of various sizes. For the latter, we develop a novel and efficient single-teacher multiple-students distillation procedure. This contribution (iv) transfers the power of our 7B frontier model to a family of smaller practical models for common usage, that we describe in Sec. 5.2 .
【翻译】按照以往的做法,我们管道的最后步骤包括高分辨率后训练阶段和蒸馏成一系列不同大小的高性能模型。对于后者,我们开发了一种新颖且高效的单教师多学生蒸馏程序。这一贡献(iv)将我们70亿参数前沿模型的能力转移到一系列较小的实用模型中,供常见使用,我们在第5.2节中描述。
【解析】描述了DINOv3训练流程的最终阶段。高分辨率后训练是在主要训练完成后进行的额外优化步骤,专门针对高分辨率输入进行模型调优,确保模型在处理高分辨率图像时仍能保持优秀的特征提取能力。通过单教师多学生的蒸馏策略,可以同时训练多个不同规模的学生模型,这些学生模型在保持相对较小计算量的同时,能够学习到教师模型的核心能力。
As measured in our thorough benchmarking, results in Sec. 6 show that our approach defines a new standard in dense tasks and performs comparably to CLIP derivatives on global tasks. In particular, with a frozen vision backbone , we achieve state-of-the-art performance on longstanding computer vision problems such as object detection (COCO detection, mAP 66.1) and image segmentation (ADE20k, mIoU 63.0), outperforming specialized fine-tuned pipelines. Moreover, we provide evidence of the generality of our approach across domains by applying the DINOv3 algorithm to satellite imagery, in Sec. 8 , surpassing all prior approaches.
【翻译】通过我们全面的基准测试,第6节的结果表明我们的方法在密集任务上定义了新标准,并在全局任务上与CLIP衍生模型表现相当。特别是,使用冻结的视觉骨干网络,我们在长期存在的计算机视觉问题上实现了最先进的性能,如目标检测(COCO检测,mAP 66.1)和图像分割(ADE20k,mIoU 63.0),超越了专门的微调管道。此外,我们通过在第8节将DINOv3算法应用于卫星图像,提供了我们方法跨领域通用性的证据,超越了所有先前的方法。
2 Related Work
Self-Supervised Learning Learning without annotations requires an artificial learning task that provides supervision in lieu for training. The art and challenge of SSL lies in carefully designing these so-called pre-text tasks in order to learn powerful representations for downstream tasks. The language domain, by its discrete nature, offers straightforward ways to set up such tasks, which led to many successful unsupervised pre-training approaches for text data. Examples include word embeddings ( Mikolov et al. , 2013 ; Bojanowski et al. , 2017 ), sentence representations ( Devlin et al. , 2018 ; Liu et al. , 2019 ), and plain language models ( Mikolov et al. , 2010 ; Zaremba et al. , 2014 ). In contrast, computer vision presents greater challenges due to the continuous nature of the signal. Early attempts mimicking language approaches extracted supervisory signals from parts of an image to predict other parts, e.g . by predicting relative patch position ( Doersch et al. , 2015 ), patch re-ordering ( Noroozi and Favaro , 2016 ; Misra and Maaten , 2020 ), or inpainting ( Pathak et al. , 2016 ). Other tasks involve re-colorizing images ( Zhang et al. , 2016 ) or predicting image transformations ( Gidaris et al. , 2018 ).
【翻译】自监督学习:无标注学习需要一个人工学习任务来代替训练中的监督信号。SSL的艺术和挑战在于精心设计这些所谓的代理任务,以便为下游任务学习强大的表示。语言领域由于其离散性质,提供了设置此类任务的直接方式,这导致了许多成功的文本数据无监督预训练方法。示例包括词嵌入(Mikolov等人,2013;Bojanowski等人,2017)、句子表示(Devlin等人,2018;Liu等人,2019)和普通语言模型(Mikolov等人,2010;Zaremba等人,2014)。相比之下,计算机视觉由于信号的连续性质而面临更大的挑战。早期模仿语言方法的尝试从图像的一部分提取监督信号来预测其他部分,例如通过预测相对补丁位置(Doersch等人,2015)、补丁重新排序(Noroozi和Favaro,2016;Misra和Maaten,2020)或修复(Pathak等人,2016)。其他任务涉及重新着色图像(Zhang等人,2016)或预测图像变换(Gidaris等人,2018)。
Among these tasks, inpainting-based approaches have gathered significant interest thanks to the flexibility of the patch-based ViT architecture ( He et al. , 2021 ; Bao et al. , 2021 ; El-Nouby et al. , 2021 ). The objective is to reconstruct corrupted regions of an image, which can be viewed as a form of denoising auto-encoding and is conceptually related to the masked token prediction task in BERT pretraining ( Devlin et al. , 2018 ). Notably, He et al. ( 2021 ) demonstrated that pixel-based masked auto-encoders (MAE) can be used as strong initializations for finetuning on downstream tasks. In the following, Baevski et al. ( 2022 ; 2023 ); Assran et al. ( 2023 ) showed that predicting a learned latent space instead of the pixel space leads to more powerful, higher-level features—a learning paradigm called JEPA: “Joint-Embedding Predictive Architecture” ( LeCun , 2022 ). Recently, JEPAs have also been extended to video training ( Bardes et al. , 2024 ; Assran et al. , 2025 ).
【翻译】在这些任务中,基于修复的方法由于基于patch的ViT架构的灵活性而获得了显著关注(He等人,2021;Bao等人,2021;El-Nouby等人,2021)。目标是重建图像的损坏区域,这可以被视为一种去噪自编码形式,在概念上与BERT预训练中的掩码token预测任务相关(Devlin等人,2018)。值得注意的是,He等人(2021)证明了基于像素的掩码自编码器(MAE)可以用作下游任务微调的强初始化。接下来,Baevski等人(2022;2023);Assran等人(2023)表明,预测学习的潜在空间而不是像素空间会产生更强大、更高级的特征——这种学习范式称为JEPA:“联合嵌入预测架构”(LeCun,2022)。最近,JEPA也已扩展到视频训练(Bardes等人,2024;Assran等人,2025)。
A second line of work, closer to ours, leverages discriminative signals between images to learn visual representations. This family of methods traces its origins to early deep learning research ( Hadsell et al. , 2006 ), but gained popularity with the introduction of instance classification techniques ( Dosovitskiy et al. , 2016 ; Bojanowski and Joulin , 2017 ; Wu et al. , 2018 ). Subsequent advancements introduced contrastive objectives and information-theoretic criteria ( Hénaff et al. , 2019 ; He et al. , 2020 ; Chen and He , 2020 ; Chen et al. , 2020a ; Grill et al. , 2020 ; Bardes et al. , 2021 ), as well as self clustering-based strategies ( Caron et al. , 2018 ; Asano et al. , 2020 ; Caron et al. , 2020 ; 2021 ). More recent approaches, such as iBOT ( Zhou et al. , 2021 ), combine these discriminative losses with masked reconstruction objectives. All of these methods show the ability to learn strong features and achieve high performance on standard benchmarks like ImageNet ( Russakovsky et al. , 2015 ). However, most face challenges scaling to larger model sizes ( Chen et al. , 2021 ).
【翻译】第二类与我们工作更接近的研究利用图像间的判别信号来学习视觉表示。这一方法系列源于早期深度学习研究(Hadsell等人,2006),但随着实例分类技术的引入(Dosovitskiy等人,2016;Bojanowski和Joulin,2017;Wu等人,2018)而获得了普及。后续的进展引入了对比目标和信息论准则(Hénaff等人,2019;He等人,2020;Chen和He,2020;Chen等人,2020a;Grill等人,2020;Bardes等人,2021),以及基于自聚类的策略(Caron等人,2018;Asano等人,2020;Caron等人,2020;2021)。更近期的方法,如iBOT(Zhou等人,2021),将这些判别损失与掩码重建目标相结合。所有这些方法都显示出学习强特征并在ImageNet(Russakovsky等人,2015)等标准基准上实现高性能的能力。然而,大多数方法在扩展到更大模型规模时面临挑战(Chen等人,2021)。
Vision Foundation Models The deep learning revolution began with the AlexNet breakthrough ( Krizhevsky et al. , 2012 ), a deep convolutional neural network that outperformed all previous methods on the ImageNet challenge ( Deng et al. , 2009 ; Russakovsky et al. , 2015 ). Already early on, features learned end-to-end on the large manually-labeled ImageNet dataset were found to be highly effective for a wide range of transfer learning tasks ( Oquab et al. , 2014 ). Early work on vision foundation models then focused on architecture development, including VGG ( Simonyan and Zisserman , 2015 ), GoogleNet ( Szegedy et al. , 2015 ), and ResNets ( He et al. , 2016 ).
【翻译】视觉基础模型 深度学习革命始于AlexNet的突破(Krizhevsky等人,2012),这是一个深度卷积神经网络,在ImageNet挑战赛上超越了所有先前的方法(Deng等人,2009;Russakovsky等人,2015)。早期就发现,在大型手动标注的ImageNet数据集上端到端学习的特征对于广泛的迁移学习任务非常有效(Oquab等人,2014)。早期的视觉基础模型工作随后专注于架构开发,包括VGG(Simonyan和Zisserman,2015)、GoogleNet(Szegedy等人,2015)和ResNets(He等人,2016)。
Given the effectiveness of scaling , subsequent works explored training larger models on big datasets. Sun et al. ( 2017 ) expanded supervised training data with the proprietary JFT dataset containing 300 million labeled images, showing impressive results. JFT also enabled significant performance gains for Kolesnikov et al. ( 2020 ). In parallel, scaling was explored using a combination of supervised and unsupervised data. For instance, an ImageNet-supervised model can be used to produce pseudo-labels for unsupervised data, which then serve to train larger networks ( Yalniz et al. , 2019 ). Subsequently, the availability of large supervised datasets such as JFT also facilitated the adaptation of the transformer architecture to computer vision ( Dosovitskiy et al. , 2020 ). In particular, achieving performance comparable to that of the original vision transformer (ViT) without access to JFT requires substantial effort ( Touvron et al. , 2020 ; 2022 ). Due to the learning capacity of ViTs, scaling efforts were further extended by Zhai et al. ( 2022a ), culminating in the very large ViT-22B encoder ( Dehghani et al. , 2023 ).
【翻译】鉴于扩展的有效性,后续工作探索了在大数据集上训练更大的模型。Sun等人(2017)使用包含3亿标注图像的专有JFT数据集扩展了监督训练数据,显示出令人印象深刻的结果。JFT也为Kolesnikov等人(2020)带来了显著的性能提升。与此同时,使用监督和无监督数据组合的扩展方法也被探索。例如,ImageNet监督模型可以用于为无监督数据生成伪标签,然后用于训练更大的网络(Yalniz等人,2019)。随后,大型监督数据集如JFT的可用性也促进了transformer架构在计算机视觉中的适应(Dosovitskiy等人,2020)。特别是,在无法访问JFT的情况下实现与原始视觉transformer(ViT)相当的性能需要大量努力(Touvron等人,2020;2022)。由于ViT的学习能力,扩展努力进一步扩展(Zhai等人,2022a),最终产生了非常大的ViT-22B编码器(Dehghani等人,2023)。
Given the complexity of manually labeling large datasets, weakly-supervised training —where annotations are derived from metadata associated with images—provides an effective alternative to supervised training. Early on, Joulin et al. ( 2016 ) demonstrated that a network can be pre-trained by simply predicting all words in the image caption as targets. This initial approach was further refined by leveraging sentence structures ( Li et al. , 2017 ), incorporating other types of metadata and involve curation ( Mahajan et al. , 2018 ), and scaling ( Singh et al. , 2022 ). However, weakly-supervised algorithms only reached their full potential with the introduction of contrastive losses and the joint-training of caption representations, as exemplified by Align ( Jia et al. , 2021 ) and CLIP ( Radford et al. , 2021 ).
【翻译】鉴于手动标注大数据集的复杂性,弱监督训练——其中标注源自与图像相关的元数据——为监督训练提供了有效的替代方案。早期,Joulin等人(2016)证明了网络可以通过简单地预测图像标题中的所有单词作为目标来进行预训练。这种初始方法通过利用句子结构(Li等人,2017)、纳入其他类型的元数据并涉及策划(Mahajan等人,2018)以及扩展(Singh等人,2022)得到进一步完善。然而,弱监督算法只有在引入对比损失和标题表示的联合训练后才达到其全部潜力,如Align(Jia等人,2021)和CLIP(Radford等人,2021)所示。
This highly successful approach inspired numerous open-source reproductions and scaling efforts . OpenCLIP ( Cherti et al. , 2023 ) was the first open-source effort to replicate CLIP by training on the LAION dataset ( Schuhmann et al. , 2021 ); following works leverage pre-trained backbones by fine-tuning them in a CLIP-style manner ( Sun et al. , 2023 ; 2024 ). Recognizing that data collection is a critical factor in the success of CLIP training, MetaCLIP ( Xu et al. , 2024 ) precisely follows the original CLIP procedure to reproduce its results, whereas Fang et al. ( 2024a ) use supervised datasets to curate pretraining data. Other works focus on improving the training loss, e.g . using a sigmoid loss in SigLIP ( Zhai et al. , 2023 ), or leveraging a pre-trained image encoder ( Zhai et al. , 2022b ). Ultimately though, the most critical components for obtaining cutting-edge foundation models are abundant high-quality data and substantial compute resources. In this vein, SigLIP 2 ( Tschannen et al. , 2025 ) and Perception Encoder (PE) ( Bolya et al. , 2025 ) achieve impressive results after training on more than 40B image-text pairs. The largest PE model is trained on 86B billion samples with a global batch size of 131K. Finally, a range of more complex and natively multimodal approaches have been proposed; these include contrastive captioning ( Yu et al. , 2022 ), masked modeling in the latent space ( Bao et al. , 2021 ; Wang et al. , 2022b ; Fang et al. , 2023 ; Wang et al. , 2023a ), and auto-regressive training ( Fini et al. , 2024 ).
【翻译】这种高度成功的方法启发了众多开源复现和扩展工作。OpenCLIP(Cherti等人,2023)是第一个通过在LAION数据集(Schuhmann等人,2021)上训练来复制CLIP的开源努力;后续工作通过以CLIP风格的方式微调预训练骨干网络来利用它们(Sun等人,2023;2024)。认识到数据收集是CLIP训练成功的关键因素,MetaCLIP(Xu等人,2024)精确遵循原始CLIP程序来复现其结果,而Fang等人(2024a)使用监督数据集来策划预训练数据。其他工作专注于改进训练损失,例如在SigLIP中使用sigmoid损失(Zhai等人,2023),或利用预训练图像编码器(Zhai等人,2022b)。然而,获得尖端基础模型的最关键组件最终是丰富的高质量数据和大量计算资源。在这方面,SigLIP 2(Tschannen等人,2025)和感知编码器(PE)(Bolya等人,2025)在超过400亿图像-文本对上训练后取得了令人印象深刻的结果。最大的PE模型在860亿样本上训练,全局批量大小为131K。最后,已经提出了一系列更复杂和本质上多模态的方法;这些包括对比标题(Yu等人,2022)、潜在空间中的掩码建模(Bao等人,2021;Wang等人,2022b;Fang等人,2023;Wang等人,2023a)和自回归训练(Fini等人,2024)。
In contrast, relatively little work has focused on scaling unsupervised image pretraining . Early efforts include Caron et al. ( 2019 ) and Goyal et al. ( 2019 ) utilizing the YFCC dataset ( Thomee et al. , 2016 ). Further progress has been achieved by focusing on larger datasets and models ( Goyal et al. , 2021 ; 2022a ), as well as initial attempts at data curation for SSL ( Tian et al. , 2021 ). Careful tuning of the training algorithms, larger architectures, and more extensive training data lead to the impressive results of DINOv2 ( Oquab et al. , 2024 ); for the first time, an SSL model matched or surpassed open-source CLIP variants on a range of tasks. This direction has recently been further pushed by Fan et al. ( 2025 ) by scaling to larger models without data curation, or by Venkataramanan et al. ( 2025 ) using open datasets and improved training recipes.
【翻译】相比之下,专注于扩展无监督图像预训练的工作相对较少。早期的努力包括Caron等人(2019)和Goyal等人(2019)利用YFCC数据集(Thomee等人,2016)。通过关注更大的数据集和模型(Goyal等人,2021;2022a),以及SSL数据策划的初步尝试(Tian等人,2021),取得了进一步的进展。训练算法的仔细调优、更大的架构和更广泛的训练数据导致了DINOv2的令人印象深刻的结果(Oquab等人,2024);这是SSL模型首次在一系列任务上匹配或超越开源CLIP变体。这一方向最近进一步被Fan等人(2025)通过扩展到更大的模型而不进行数据策划,或被Venkataramanan等人(2025)使用开放数据集和改进的训练配方所推动。
Dense Transformer Features A broad range of modern vision applications consume dense features of pre-trained transformers, including multi-modal models ( Liu et al. , 2023 ; Beyer et al. , 2024 ), generative models ( Yu et al. , 2025 ; Yao et al. , 2025 ), 3D understanding ( Wang et al. , 2025 ), video understanding ( Lin et al. , 2023a ; Wang et al. , 2024b ), and robotics ( Driess et al. , 2023 ; Kim et al. , 2024 ). On top of that, traditional vision tasks such as detection, segmentation, or depth estimation require accurate local descriptors. To enhance the quality of SSL-trained local descriptors, a substantial body of work focuses on developing local SSL losses . Examples include leveraging spatio-temporal consistency in videos, e.g . using point track loops as training signal ( Jabri et al. , 2020 ), exploiting the spatial alignment between different crops of the same image ( Pinheiro et al. , 2020 ; Bardes et al. , 2022 ), or enforcing consistency between neighboring patches ( Yun et al. , 2022 ). Darcet et al. ( 2025 ) show that predicting clustered local patches leads to improved dense representations. DetCon ( Hénaff et al. , 2021 ) and ORL ( Xie et al. , 2021 ) perform contrastive learning on region proposals but assume that such proposals exist a priori ; this assumption is relaxed by approaches such as ODIN ( Hénaff et al. , 2022 ) and SlotCon ( Wen et al. , 2022 ). Without changing the training objective, Darcet et al. ( 2024 ) show that adding register tokens to the input sequence greatly improves dense feature maps, and recent works find this can be done without model training ( Jiang et al. , 2025 ; Chen et al. , 2025 ).
【翻译】密集Transformer特征:广泛的现代视觉应用消费预训练transformer的密集特征,包括多模态模型(Liu等人,2023;Beyer等人,2024)、生成模型(Yu等人,2025;Yao等人,2025)、3D理解(Wang等人,2025)、视频理解(Lin等人,2023a;Wang等人,2024b)和机器人技术(Driess等人,2023;Kim等人,2024)。除此之外,传统的视觉任务如检测、分割或深度估计都需要准确的局部描述符。为了提高SSL训练的局部描述符质量,大量工作专注于开发局部SSL损失。例子包括利用视频中的时空一致性,例如使用点轨迹循环作为训练信号(Jabri等人,2020),利用同一图像不同裁剪之间的空间对齐(Pinheiro等人,2020;Bardes等人,2022),或强制相邻patch之间的一致性(Yun等人,2022)。Darcet等人(2025)表明预测聚类的局部patch可以改善密集表示。DetCon(Hénaff等人,2021)和ORL(Xie等人,2021)对区域提议执行对比学习,但假设这些提议先验存在;这一假设被ODIN(Hénaff等人,2022)和SlotCon(Wen等人,2022)等方法放松了。在不改变训练目标的情况下,Darcet等人(2024)表明向输入序列添加寄存器token可以大大改善密集特征图,最近的工作发现这可以在不进行模型训练的情况下完成(Jiang等人,2025;Chen等人,2025)。
Figure 4: DINOv3 at very high resolution. We visualize dense features of DINOv3 by mapping the first three components of a PCA computed over the feature space to RGB. To focus the PCA on the subject, we mask the feature maps via background subtraction. With increasing resolution, DINOv3 produces crisp features that stay semantically meaningful. We visualize more PCAs in Sec. 6.1.1 .
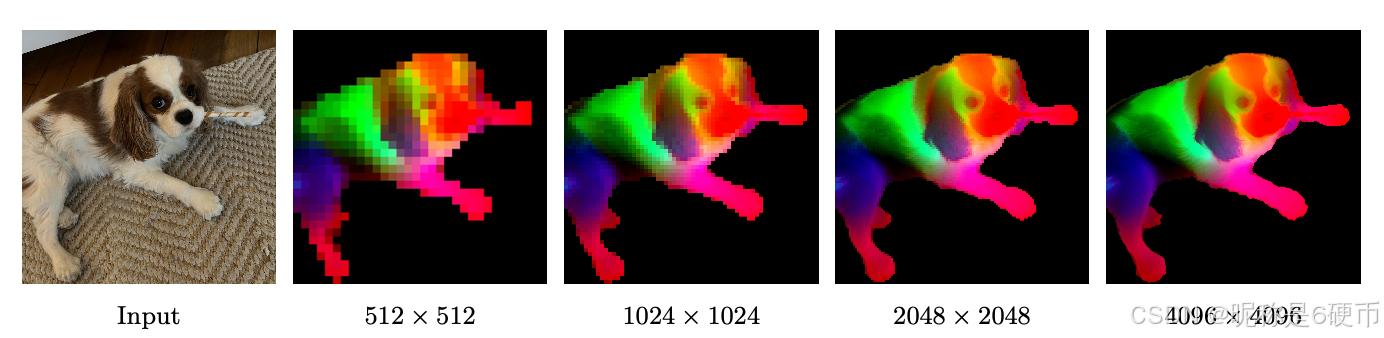
【翻译】图4:超高分辨率下的DINOv3。我们通过将在特征空间上计算的PCA的前三个主成分映射到RGB来可视化DINOv3的密集特征。为了将PCA聚焦在主体上,我们通过背景减法来掩蔽特征图。随着分辨率的增加,DINOv3产生清晰的特征,保持语义的意义。我们在第6.1.1节中可视化更多的PCA。
【解析】这里展示了DINOv3在处理高分辨率图像时的能力。PCA(主成分分析)是一种降维技术,用于提取数据中最重要的信息。在这个可视化中,研究者将DINOv3提取的高维特征向量通过PCA降维到3维,然后将这3个维度分别映射到RGB颜色的红、绿、蓝通道。这样做的目的是用颜色来表示特征的不同方面,让我们能够直观地看到模型在不同空间位置提取到的特征差异。背景减法通过移除背景像素的干扰,让PCA专注于分析前景物体的特征。图4展示了一个重要现象:当输入图像分辨率越来越高时,DINOv3能够提取出更加精细和清晰的特征表示,而且这些特征在语义上仍然是有意义的。这说明模型具有良好的多尺度特征提取能力,能够在保持语义理解的同时捕获细节信息。
A recent trend are distillation-based, " agglomerative " methods that combine information from multiple image encoders with varying in global and local feature quality, trained using different levels of supervision ( Ranzinger et al. , 2024 ; Bolya et al. , 2025 ): AM-RADIO ( Ranzinger et al. , 2024 ) combines the strengths of the fully-supervised SAM ( Kirillov et al. , 2023 ), the weakly-supervised CLIP, and the self-supervised DINOv2 into a unified backbone. The Perception Encoder ( Bolya et al. , 2025 ) similarly distills SAM(v2) into a specialized dense variant called PEspatial. They use an objective enforcing cosine similarity between student and teacher patches to be high, where their teacher is trained with mask annotations. Similar losses were shown to be effective in the context of style transfer, by reducing the inconsistency between the Gram matrices of feature dimensions ( Gatys et al. , 2016 ; Johnson et al. , 2016 ; Yoo et al. , 2024 ). In this work, we adopt a Gram objective to regularize cosine similarity between student and teacher patches, favoring them being close. In our case, we use earlier iterations of the SSL model itself as the teacher, demonstrating that early-stage SSL models effectively guides SSL training for both global and dense tasks.
【翻译】最近的趋势是基于蒸馏的"聚合"方法,这些方法结合来自多个图像编码器的信息,这些编码器在全局和局部特征质量上有所不同,使用不同级别的监督进行训练(Ranzinger等人,2024;Bolya等人,2025):AM-RADIO(Ranzinger等人,2024)将完全监督的SAM(Kirillov等人,2023)、弱监督的CLIP和自监督的DINOv2的优势结合到一个统一的骨干网络中。感知编码器(Bolya等人,2025)类似地将SAM(v2)蒸馏为一个专门的密集变体,称为PEspatial。它们使用一个目标来强制学生和教师补丁之间的余弦相似度很高,其中教师使用掩码标注进行训练。类似的损失在风格迁移的背景下被证明是有效的,通过减少特征维度的Gram矩阵之间的不一致性(Gatys等人,2016;Johnson等人,2016;Yoo等人,2024)。在这项工作中,我们采用Gram目标来正则化学生和教师补丁之间的余弦相似度,偏向于使它们接近。在我们的情况下,我们使用SSL模型本身的早期迭代作为教师,证明早期阶段的SSL模型有效地指导SSL训练,用于全局和密集任务。
【解析】这段话介绍了一种新兴的模型训练策略——聚合式蒸馏方法。知识蒸馏是一种模型压缩和知识传递技术,通常让小模型(学生)学习大模型(教师)的知识。但这里提到的"聚合"方法有所不同,它不是简单的模型压缩,而是将多个具有不同特长的预训练模型的知识整合到一个新的统一模型中。AM-RADIO方法很有代表性:它整合了三个不同训练方式的模型——SAM专长于分割任务(完全监督),CLIP擅长理解图文关系(弱监督),DINOv2在自监督学习方面表现出色。通过整合这些模型的优势,可以得到一个在多种任务上都表现良好的统一骨干网络。余弦相似度衡量两个向量夹角的指标,值越接近1说明两个向量越相似。在蒸馏过程中,通过最大化学生和教师网络对应补丁特征的余弦相似度,可以让学生网络学到教师网络的特征表示能力。Gram矩阵捕获特征之间的相关性模式,特别是在风格迁移任务中用于保持纹理和风格信息。本工作创新性地将早期训练阶段的同一个SSL模型作为教师,指导后续训练阶段,这种自我指导的策略既保持了全局任务的性能,又改善了密集预测任务的效果。
Other works focus on post-hoc improvements to the local features of SSL-trained models. For example, Ziegler and Asano ( 2022 ) fine-tune a pre-trained model with a dense clustering objective; similarly, Salehi et al. ( 2023 ) fine-tune by aligning patch features temporally, in both cases enhance the quality of local features. Closer to us, Pariza et al. ( 2025 ) propose a patch-sorting based objective to encourage the student and teacher to produce features with consistent neighbor ordering. Without finetuning, STEGO ( Hamilton et al. , 2022 ) learns a non-linear projection on top of frozen SSL features to form compact clusters and amplify correlation patterns. Alternatively, Simoncini et al. ( 2024 ) augment self-supervised features by concatenating gradients from different self-supervised objectives to frozen SSL features. Recently, Wysoczańska et al. ( 2024 ) show that noisy feature maps are significantly improved through a weighted average of patches.
【翻译】其他工作专注于对SSL训练模型的局部特征进行事后改进。例如,Ziegler和Asano(2022)使用密集聚类目标对预训练模型进行微调;类似地,Salehi等人(2023)通过在时间上对齐patch特征来进行微调,这两种情况都增强了局部特征的质量。与我们更接近的是,Pariza等人(2025)提出了基于patch排序的目标,以鼓励学生和教师产生具有一致邻居排序的特征。在不进行微调的情况下,STEGO(Hamilton等人,2022)在冻结的SSL特征之上学习非线性投影,以形成紧密的聚类并放大相关模式。另外,Simoncini等人(2024)通过将来自不同自监督目标的梯度连接到冻结的SSL特征来增强自监督特征。最近,Wysoczańska等人(2024)表明通过patch的加权平均可以显著改善噪声特征图。
【解析】这段话讨论的是改善自监督学习(SSL)模型局部特征质量的后处理方法。传统的SSL方法在训练完成后,其提取的局部特征(即patch级别的特征)可能存在质量不够理想的问题,因此研究者们开发了各种后处理技术来解决这一问题。密集聚类目标是指在每个空间位置都进行聚类操作,而不仅仅是全局特征聚类,这样可以让相似的局部区域在特征空间中更加紧密。时间对齐是利用视频序列中相同物体在不同帧中的对应关系来约束特征学习,确保同一物体的特征在时间维度上保持一致性。patch排序方法通过确保教师网络和学生网络对相同图像区域的相邻关系判断保持一致,来提高特征的空间连贯性。STEGO方法采用了一种无需重新训练的策略,它在已经训练好的SSL特征基础上添加一个可学习的非线性映射层,这个映射层专门用于增强特征的局部聚类性质和空间相关性。梯度连接技术通过融合不同自监督学习目标产生的梯度信息来丰富特征表示,这种方法能够综合多种自监督信号的优势。加权平均方法则是通过对邻近patch的特征进行加权融合来减少特征噪声,提高特征图的平滑性和一致性。
Related, but not specific to SSL, some recent works generate high-resolution feature maps from ViT feature maps ( Fu et al. , 2024 ), which are often low-resolution due to patchification of images. In contrast with this body of work, our models natively deliver high-quality dense feature maps that remain stable and consistent across resolutions, as shown in Fig. 4 .
【翻译】相关但不特定于SSL的一些最近工作从ViT特征图生成高分辨率特征图(Fu等人,2024),由于图像的patch化,这些特征图通常是低分辨率的。与这些工作相比,我们的模型原生地提供高质量的密集特征图,这些特征图在不同分辨率下保持稳定和一致,如图4所示。
【解析】这段话强调了DINOv3相对于其他方法的优势。Vision Transformer (ViT)由于其patch化的处理方式,即将输入图像分割成固定大小的patch块,导致输出的特征图分辨率相对较低。例如,如果输入图像是224×224像素,patch大小是16×16,那么得到的特征图只有14×14的空间分辨率。为了解决这个问题,一些研究工作开发了上采样或插值技术来从低分辨率的ViT特征图重建高分辨率特征图。然而,这类方法存在几个问题:首先,它们需要额外的计算开销来进行特征图重建;其次,重建过程可能引入伪影或失真;最重要的是,这些方法在处理不同分辨率输入时可能表现不一致。相比之下,DINOv3通过改进的架构设计和训练策略,能够直接产生高质量的密集特征图,无需后处理步骤。这些特征图不仅在空间上具有丰富的细节,而且在面对不同输入分辨率时能够保持特征质量的稳定性和一致性。
3 无监督大规模训练
DINOv3 is a next-generation model designed to produce the most robust and flexible visual representations to date by pushing the boundaries of self-supervised learning. We draw inspiration from the success of large language models (LLMs), for which scaling-up the model capacity leads to outstanding emerging properties . By leveraging models and training datasets that are an order of magnitude larger, we seek to unlock the full potential of SSL and drive a similar paradigm shift for computer vision, unencumbered by the limitations inherent to traditional supervised or task-specific approaches. In particular, SSL produces rich, high-quality visual features that are not biased toward any specific supervision or task, thereby providing a versatile foundation for a wide range of downstream applications. While previous attempts at scaling SSL models have been hindered by issues of instability, this section describes how we harness the benefits of scaling with careful data preparation, design, and optimization. We first describe the dataset creation procedure ( Sec. 3.1 ), then present the self-supervised SSL recipe used for this first training phase of DINOv3 ( Sec. 3.2 ). This includes the choice of architecture, loss functions, and optimization techniques. The second training phase, focusing on dense features, will be described in Sec. 4 .
【翻译】DINOv3是一个下一代模型,旨在通过推动自监督学习的边界来产生迄今为止最稳健和灵活的视觉表示。我们从大型语言模型(LLM)的成功中汲取灵感,对于这些模型,扩大模型容量会导致出色的新兴属性。通过利用比以往大一个数量级的模型和训练数据集,我们寻求释放SSL的全部潜力,并推动计算机视觉领域的类似范式转变,不受传统监督或任务特定方法固有限制的阻碍。特别是,SSL产生丰富、高质量的视觉特征,这些特征不偏向于任何特定的监督或任务,从而为广泛的下游应用提供了多功能的基础。虽然之前扩展SSL模型的尝试受到不稳定性问题的阻碍,但本节描述了我们如何通过仔细的数据准备、设计和优化来利用扩展的好处。我们首先描述数据集创建程序(第3.1节),然后介绍用于DINOv3第一个训练阶段的自监督SSL配方(第3.2节)。这包括架构、损失函数和优化技术的选择。专注于密集特征的第二个训练阶段将在第4节中描述。
Table 1: Influence of training data on features quality shown via performance on downstream tasks. We compare datasets curated with clustering ( Vo et al. , 2024 ) and retrieval ( Oquab et al. , 2024 ) to raw data and to our data mixture. This ablation study is run for a shorter schedule of 200k iterations.
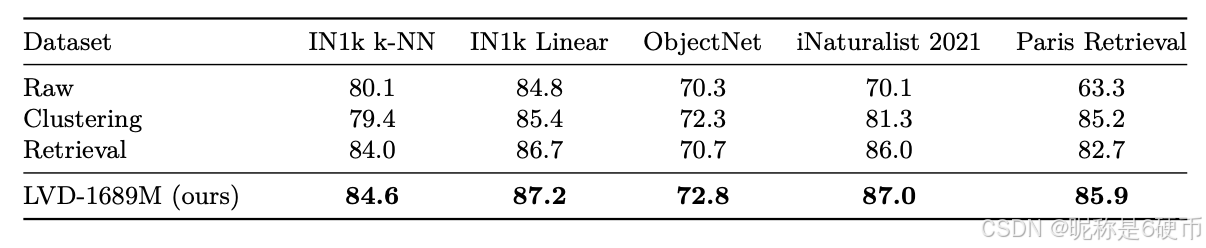
【翻译】表1:通过下游任务性能显示的训练数据对特征质量的影响。我们将使用聚类方法(Vo等人,2024)和检索方法(Oquab等人,2024)策划的数据集与原始数据和我们的数据混合进行比较。这项消融研究在200k次迭代的较短计划下运行。
3.1 数据准备
Data scaling is one of the driving factors behind the success of large foundation models ( Touvron et al. , 2023 ; Radford et al. , 2021 ; Xu et al. , 2024 ; Oquab et al. , 2024 ). However, increasing naively the size of the training data does not necessarily translate into higher model quality and better performance on downstream benchmarks ( Goyal et al. , 2021 ; Oquab et al. , 2024 ; Vo et al. , 2024 ): Successful data scaling efforts typically involve careful data curation pipelines. These algorithms may have different objectives: either focusing on improving data diversity and balance , or data usefulness —its relevance to common practical applications. For the development of DINOv3, we combine two complementary approaches to improve both the generalizability and performance of the model, striking a balance between the two objectives.
【翻译】数据扩展是大型基础模型成功背后的驱动因素之一(Touvron等人,2023;Radford等人,2021;Xu等人,2024;Oquab等人,2024)。然而,简单地增加训练数据的规模并不一定能转化为更高的模型质量和在下游基准测试上的更好性能(Goyal等人,2021;Oquab等人,2024;Vo等人,2024):成功的数据扩展工作通常涉及仔细的数据策划管道。这些算法可能有不同的目标:要么专注于改善数据的多样性和平衡性,要么专注于数据的有用性——即其与常见实际应用的相关性。在DINOv3的开发中,我们结合了两种互补的方法来改善模型的泛化性和性能,在两个目标之间取得平衡。
【解析】这段话阐述了在训练大型AI模型时数据处理的复杂性。数据扩展不仅仅是简单地收集更多数据,大量的低质量或不相关数据可能会引入噪声,影响模型的学习效果,甚至可能导致模型过拟合到无关的模式上。DINOv3一方面要确保模型具有良好的泛化能力,能够处理各种未见过的情况;另一方面要确保模型在实际应用中表现出色,能够解决真实世界的问题。
Data Collection and Curation We build our large-scale pre-training dataset by leveraging a large data pool of web images collected from public posts on Instagram. These images already went through platformlevel content moderation to help prevent harmful contents and we obtain an initial data pool of approximately 17 billions of images. Using this raw data pool, we create three dataset parts . We construct the first part by applying the automatic curation method based on hierarchical kkk -means from Vo et al. ( 2024 ). We employ DINOv2 as image embeddings, and use 5 levels of clustering with the number of clusters from the lowest to highest levels being 200M, 8M, 800k, 100k, and 25k respectively. After building the hierarchy of clusters, we apply the balanced sampling algorithm proposed in Vo et al. ( 2024 ). This results in a curated subset of 1,689 million images (named LVD-1689M) that guarantees a balanced coverage of all visual concepts appearing on the web. For the second part, we adopt a retrieval-based curation system similar to the procedure proposed by Oquab et al. ( 2024 ). We retrieve images from the data pool that are similar to those from selected seed datasets, creating a dataset that covers visual concepts relevant for downstream tasks. For the third part, we use raw publicly available computer vision datasets including ImageNet1k ( Deng et al. , 2009 ), ImageNet22k ( Russakovsky et al. , 2015 ), and Mapillary Street-level Sequences ( Warburg et al. , 2020 ). This final part allows us to optimize our model’s performance, following Oquab et al. ( 2024 ).
【翻译】数据收集和策划:我们通过利用从Instagram公开帖子收集的网络图像大数据池来构建我们的大规模预训练数据集。这些图像已经经过平台级内容审核,以帮助防止有害内容,我们获得了大约170亿张图像的初始数据池。使用这个原始数据池,我们创建了三个数据集部分。我们通过应用Vo等人(2024)基于分层kkk-means的自动策划方法来构建第一部分。我们使用DINOv2作为图像嵌入,并使用5个聚类级别,从最低到最高级别的聚类数量分别为200M、8M、800k、100k和25k。在构建聚类层次结构后,我们应用Vo等人(2024)提出的平衡采样算法。这产生了一个包含16.89亿张图像的策划子集(命名为LVD-1689M),保证对网络上出现的所有视觉概念的平衡覆盖。对于第二部分,我们采用类似于Oquab等人(2024)提出的程序的基于检索的策划系统。我们从数据池中检索与来自选定种子数据集的图像相似的图像,创建一个涵盖与下游任务相关的视觉概念的数据集。对于第三部分,我们使用原始的公开可用的计算机视觉数据集,包括ImageNet1k(Deng等人,2009)、ImageNet22k(Russakovsky等人,2015)和Mapillary街道级序列(Warburg等人,2020)。这最后一部分使我们能够优化模型的性能,遵循Oquab等人(2024)的做法。
【解析】DINOv3的整个数据准备流程采用了三重策略来确保数据质量和多样性。第一部分采用分层聚类方法,这是一种无监督的数据组织技术。分层k-means聚类通过多个层次逐步细化数据分组,从最粗糙的200M个聚类开始,逐步细化到25k个聚类。层次化设计,在不同的抽象层次上捕获视觉概念的相似性。在最高层,聚类可能按照基本的视觉属性(如颜色、纹理)分组;在较低层,聚类则更加精细,可能按照具体的对象类别或场景类型分组。平衡采样算法确保每个聚类在最终数据集中都有适当的代表性,避免某些视觉概念被过度或不足采样。第二部分的检索基础策划方法采用了不同的策略,它不是依赖数据的内在结构,而是基于与特定种子数据集的相似性来选择数据。有目的地收集与特定应用领域相关的数据,确保模型在实际应用中的有效性。种子数据集通常是精心策划的高质量数据集,通过检索与这些数据相似的图像,可以扩展高质量数据的规模。第三部分直接使用已有的标准计算机视觉数据集,这些数据集经过了广泛的验证和使用,能够为模型提供稳定的性能基准。这种三重策略的组合确保了数据集既具有广泛的覆盖性(通过聚类方法),又具有任务相关性(通过检索方法),同时保持了与现有基准的兼容性(通过标准数据集)。
Data Sampling During pre-training, we use a sampler to mix different data parts together. There are several different options for mixing the above data components. One is to train with homogeneous batches of data that come from a single, randomly selected component in each iteration. Alternatively, we can optimize the model on heterogeneous batches that are assembled by data from all components, selected using certain ratios. Inspired by Charton and Kempe ( 2024 ), who observed that it is beneficial to have homogeneous batches consisting of very high quality data from a small dataset, we randomly sample in each iteration either a homogeneous batch from ImageNet1k alone or a heterogeneous batch mixing data from all other components. In our training, homogeneous batches from ImageNet1k account for 10% of training.
【翻译】数据采样 在预训练期间,我们使用采样器将不同的数据部分混合在一起。有几种不同的选项来混合上述数据组件。一种是使用同质批次进行训练,这些批次来自每次迭代中随机选择的单个组件。另一种方法是,我们可以在异质批次上优化模型,这些批次由来自所有组件的数据组装而成,使用特定比例进行选择。受到Charton和Kempe(2024)的启发,他们观察到拥有由小数据集中非常高质量数据组成的同质批次是有益的,我们在每次迭代中随机采样要么是仅来自ImageNet1k的同质批次,要么是混合来自所有其他组件数据的异质批次。在我们的训练中,来自ImageNet1k的同质批次占训练的10%。
【解析】同质批次(homogeneous batches)指的是每个训练批次中的所有样本都来自同一个数据源或具有相似的特征分布,优势在于能够让模型在每次更新时专注学习特定类型数据的模式,避免不同数据源之间的干扰。异质批次(heterogeneous batches)则是将来自不同数据源的样本混合在一个批次中,这种方式能够让模型同时接触到多样化的数据模式,促进模型的泛化能力。DINOv3采用的混合策略是一种平衡方案:大部分时间(90%)使用异质批次来确保模型能够学习到丰富多样的视觉模式,同时保留10%的时间使用来自ImageNet1k的同质批次。ImageNet1k作为计算机视觉领域的经典数据集,具有高质量的标注和良好的数据分布,专门使用这些高质量数据的同质批次可以为模型提供稳定可靠的学习信号,有助于模型收敛到更好的局部最优解。这种策略的设计思路来源于Charton和Kempe的研究发现,他们证明了高质量小数据集的同质批次训练能够显著提升模型性能,因为高质量数据能够提供更清晰、更一致的学习目标,减少噪声数据对模型训练的负面影响。
Table 2: Comparison of the teacher architectures used in DINOv2 and DINOv3 models. We keep the model 40 blocks deep, and increase the embedding dimension to 4096. Importantly, we use a patch size of 16 pixels, changing the effective sequence length for a given resolution.
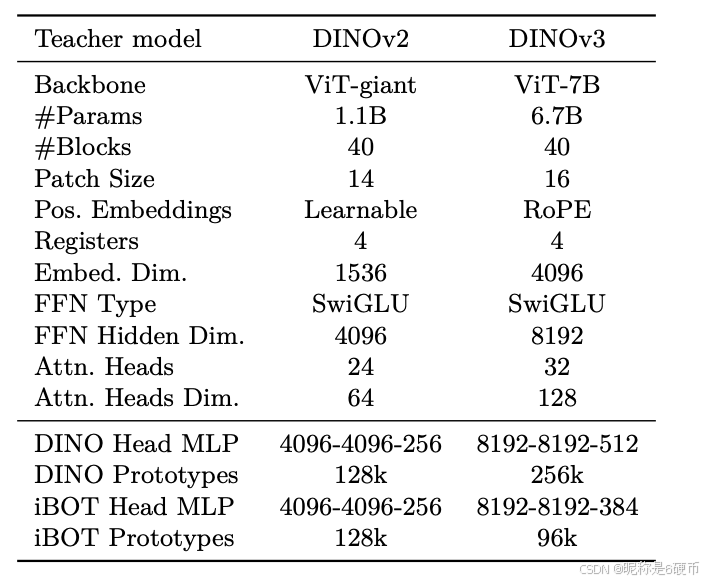
【翻译】表2:DINOv2和DINOv3模型中使用的教师架构比较。我们保持模型40个块的深度,并将嵌入维度增加到4096。重要的是,我们使用16像素的patch大小,这改变了给定分辨率下的有效序列长度。
Data Ablation To assess the impact of our data curation technique, we perform an ablation study to compare our data mix against datasets curated with clustering or retrieval-based methods alone, and the raw data pool. To this end, we train a model on each dataset and compare their performance on standard downstream tasks. For efficiency, we use a shorter schedule of 200k iterations instead of 1M iterations. In Tab. 1 , it can be seen that no single curation technique works best across all benchmarks, and that our full pipeline allows us to obtain the best of both worlds.
【翻译】数据消融 为了评估我们数据策划技术的影响,我们进行了一项消融研究,将我们的数据混合与仅使用聚类或基于检索方法策划的数据集以及原始数据池进行比较。为此,我们在每个数据集上训练一个模型,并比较它们在标准下游任务上的性能。为了提高效率,我们使用200k次迭代的较短计划,而不是1M次迭代。从表1中可以看出,没有单一的策划技术在所有基准测试中都表现最佳,我们的完整流程使我们能够获得两全其美的效果。
3.2 自监督大规模训练
While models trained with SSL have demonstrated interesting properties ( Chen et al. , 2020b ; Caron et al. , 2021 ), most SSL algorithms have not been scaled-up to larger models sizes. This is either due to issues with training stability ( Darcet et al. , 2025 ), or overly simplistic solutions that fail to capture the full complexity of the visual world. When trained at scale ( Goyal et al. , 2022a ), models trained with SSL do not necessarily show impressive performance. One notable exception is DINOv2, a model with 1.1 billion parameters trained on curated data, matching the performance of weakly-supervised models like CLIP ( Radford et al. , 2021 ). A recent effort to scale DINOv2 to 7 billion parameters ( Fan et al. , 2025 ) demonstrates promising results on global tasks, but with disappointing results on dense prediction. Here, we aim to scale up the model and data, and obtain even more powerful visual representations with both improved global and local properties.
【翻译】虽然使用SSL训练的模型已经展现出有趣的特性(Chen等人,2020b;Caron等人,2021),但大多数SSL算法还没有扩展到更大的模型规模。这要么是由于训练稳定性问题(Darcet等人,2025),要么是过于简单的解决方案无法捕获视觉世界的全部复杂性。当大规模训练时(Goyal等人,2022a),使用SSL训练的模型不一定表现出令人印象深刻的性能。一个值得注意的例外是DINOv2,这是一个在策划数据上训练的11亿参数模型,与像CLIP这样的弱监督模型的性能相匹配(Radford等人,2021)。最近将DINOv2扩展到70亿参数的努力(Fan等人,2025)在全局任务上显示出有前景的结果,但在密集预测上结果令人失望。在这里,我们的目标是扩大模型和数据规模,获得更强大的视觉表示,同时改进全局和局部特性。
【解析】自监督学习(SSL)扩展到大规模模型时面临多重挑战。首先是训练稳定性问题,大型模型在自监督训练过程中容易出现梯度爆炸、梯度消失或收敛困难等问题,这些问题在有监督学习中通过标签信息的指导相对容易解决,但在自监督学习中需要更精巧的技术手段。其次是表示学习的复杂性,现实世界的视觉信息具有极高的复杂性和多样性,简单的自监督目标函数可能无法捕获这种复杂性,导致学到的表示过于简化。DINOv2作为成功案例的重要性在于它证明了自监督学习在大规模数据和模型上的可行性,其11亿参数的规模和与CLIP相匹配的性能打破了人们对自监督学习局限性的认知。然而,将模型进一步扩展到70亿参数时遇到的问题揭示了一个重要现象:全局任务和密集预测任务对模型表示的要求不同。全局任务(如图像分类)主要关注整体语义信息,而密集预测任务(如语义分割、目标检测)需要精细的局部空间信息。这种差异说明在扩展模型规模时,需要特别关注如何平衡全局表示和局部表示的学习,确保模型在获得更强全局理解能力的同时不丢失空间细节信息。
Learning Objective We train the model with a discriminative self-supervised strategy which is a mix of several self-supervised objectives with both global and local loss terms. Following DINOv2 ( Oquab et al. , 2024 ), we use an image-level objective ( Caron et al. , 2021 ) LDINO\mathcal{L}_{\mathrm{DINO}}LDINO , and balance it with a patch-level latent reconstruction objective ( Zhou et al. , 2021 ) LiBOT\mathcal{L}_{\mathrm{iBOT}}LiBOT . We also replace the centering from DINO with the Sinkhorn-Knopp from SwAV ( Caron et al. , 2020 ) in both objectives. Each objective is computed using the output of a dedicated head on top of the backbone network, allowing for some specialization of features before the computation of the losses. Additionally, we use a dedicated layer normalization applied to the backbone outputs of the local and global crops. Empirically, we found this change to stabilize ImageNet kNNclassification late in training (+0.2 accuracy) and improve dense performance ( e.g . +1+1+1 mIoU on ADE20k segmentation, -0.02 RMSE on NYUv2 depth estimation). In addition, a Koleo regularizer LKoleo\scriptstyle{\mathcal{L}}_{\mathrm{Koleo}}LKoleo is added to encourage the features within a batch to spread uniformly in the space ( Sablayrolles et al. , 2018 ). We use a distributed implementation of Koleo in which the loss is applied in small batches of 16 samples—possibly across GPUs. Our initial training phase is carried by optimizing the following loss:
【翻译】学习目标 我们使用一种判别式自监督策略来训练模型,该策略混合了几个包含全局和局部损失项的自监督目标。遵循DINOv2(Oquab等人,2024),我们使用图像级目标(Caron等人,2021)LDINO\mathcal{L}_{\mathrm{DINO}}LDINO,并将其与patch级潜在重构目标(Zhou等人,2021)LiBOT\mathcal{L}_{\mathrm{iBOT}}LiBOT平衡。我们还将DINO中的centering替换为SwAV(Caron等人,2020)中的Sinkhorn-Knopp方法,应用于两个目标。每个目标都使用骨干网络顶部专用头的输出来计算,允许在计算损失之前对特征进行一些专门化。此外,我们使用专用的层归一化应用于局部和全局裁剪的骨干输出。根据经验,我们发现这种变化能够稳定训练后期的ImageNet kNN分类(+0.2准确率)并改善密集性能(例如,ADE20k分割+1 mIoU,NYUv2深度估计-0.02 RMSE)。另外,添加了Koleo正则化器LKoleo\scriptstyle{\mathcal{L}}_{\mathrm{Koleo}}LKoleo来鼓励批次内的特征在空间中均匀分布(Sablayrolles等人,2018)。我们使用Koleo的分布式实现,其中损失应用于16个样本的小批次中——可能跨GPU。我们的初始训练阶段通过优化以下损失进行:
【解析】DINOv3的学习目标设计采用了多目标融合的策略,同时优化全局语义理解和局部空间细节保持。DINO损失(LDINO\mathcal{L}_{\mathrm{DINO}}LDINO)作为图像级目标,主要负责学习整体语义表示,它通过教师-学生网络的知识蒸馏机制,让学生网络学习教师网络对整张图像的全局理解。iBOT损失(LiBOT\mathcal{L}_{\mathrm{iBOT}}LiBOT)则专注于patch级的潜在重构,这个目标确保模型能够从局部patch的特征中重构出丢失的信息,从而保持对空间细节的敏感性。Sinkhorn-Knopp算法的引入替代了原始DINO中的centering操作,这是一个重要的技术改进。Centering操作的目的是防止模型输出坍塌到同一点,但简单的centering可能会影响特征的表达能力。Sinkhorn-Knopp算法通过迭代优化的方式实现更加平衡的特征分布,它将特征分布问题建模为最优传输问题,能够更好地保持特征的多样性和区分性。专用头的设计允许不同的损失函数在特征空间的不同子空间中进行优化,这种架构设计避免了不同目标之间的直接冲突,让每个目标都能在适合自己的特征表示空间中进行优化。层归一化的应用进一步稳定了训练过程,特别是在处理不同尺度的全局和局部裁剪时,层归一化确保了特征的数值稳定性。Koleo正则化器的作用是防止特征坍塌和促进特征多样性,它通过惩罚批次内特征之间的过度相似性,鼓励模型学习更加丰富和均匀分布的特征表示,这对于自监督学习尤为重要,因为缺乏显式标签指导容易导致特征退化。
LPre=LDINO+LiBOT+0.1∗LDKoleo.\mathcal{L}_{\mathrm{Pre}}=\mathcal{L}_{\mathrm{DINO}}+\mathcal{L}_{\mathrm{iBOT}}+0.1*\mathcal{L}_{\mathrm{DKoleo.}} LPre=LDINO+LiBOT+0.1∗LDKoleo.
Figure 5: Evolution of the cosine similarities (a) and of the accuracy on ImageNet1k linear (IN1k) and segmentation on VOC for ViT-g (b) and ViT-7B ©. We observe that the segmentation performance is maximal when the cosine similarities between the patch tokens and the class tokens are low. As training progresses, these similarities increase and the performance on dense tasks decreases.
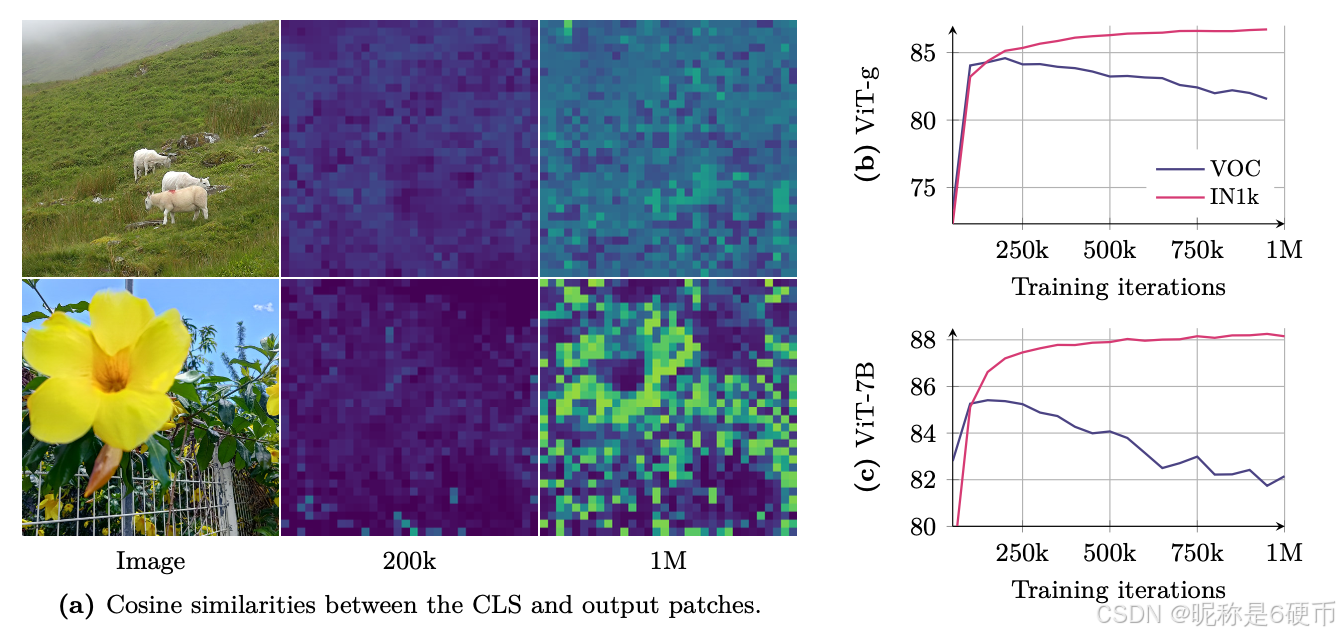
【翻译】图5:余弦相似度的演化(a)以及ViT-g(b)和ViT-7B(c)在ImageNet1k线性(IN1k)和VOC分割上的准确率。我们观察到当patch token和class token之间的余弦相似度较低时,分割性能达到最大值。随着训练的进行,这些相似度增加,密集任务的性能下降。
【解析】这个现象揭示了Vision Transformer在长期训练过程中的一个问题:全局表示和局部表示之间的竞争关系。在Vision Transformer中,class token(分类token)负责聚合整个图像的全局信息,而patch token则保留局部空间信息。当这两种token之间的余弦相似度较低时,说明它们保持着相对独立的表示空间,patch token能够保留丰富的局部细节信息,这对于需要精确空间定位的密集预测任务(如语义分割)是至关重要的。随着训练的深入,模型逐渐倾向于将更多信息集中到class token中以优化全局任务的性能,这导致patch token与class token的表示越来越相似。这种相似度的增加实际上说明patch token正在失去其独特的局部表示能力,变得更像全局特征的副本。这种现象在大规模模型(如7B参数的ViT)中尤为明显,因为更大的模型容量使得这种特征同质化现象更容易发生。这个发现对理解自监督学习中的表示塌陷问题具有重要意义,也为后续提出的Gram Anchoring方法提供了理论基础。
Updated Model Architecture For the model scaling aspect of this work, we increase the size of the model to 7B parameters, and provide in Tab. 2 a comparison of the corresponding hyperparameters with the 1.1B parameter model trained in the DINOv2 work. We also employ a custom variant of RoPE: our base implementation assigns coordinates in a normalized [−1,1][-1,1][−1,1] box to each patch, then applies a bias in the multi-head attention operation depending on the relative position of two patches. In order to improve the robustness of the model to resolutions, scales and aspect ratios, we employ RoPE-box jittering . The coordinate box [−1,1][-1,1][−1,1] is randomly scaled to [−s,s][-s,s][−s,s] , where s∈[0.5,2]s\in[0.5,2]s∈[0.5,2] . Together, these changes enable DINOv3 to better learn detailed and robust visual features, improving its performance and scalability.
【翻译】更新的模型架构 对于这项工作的模型扩展方面,我们将模型大小增加到70亿参数,并在表2中提供了与DINOv2工作中训练的11亿参数模型对应超参数的比较。我们还采用了RoPE的自定义变体:我们的基础实现为每个patch分配归一化[−1,1][-1,1][−1,1]框中的坐标,然后根据两个patch的相对位置在多头注意力操作中应用偏置。为了提高模型对分辨率、尺度和纵横比的鲁棒性,我们采用RoPE-box抖动。坐标框[−1,1][-1,1][−1,1]被随机缩放到[−s,s][-s,s][−s,s],其中s∈[0.5,2]s\in[0.5,2]s∈[0.5,2]。这些变化共同使DINOv3能够更好地学习详细和鲁棒的视觉特征,提高其性能和可扩展性。
【解析】模型架构的更新主要围绕两个核心方面:规模扩展和位置编码优化。将参数量从11亿扩展到70亿代表了一个重大的规模跃升,这不仅仅是简单的参数数量增加,而是模型表示能力的质的提升。这种规模的增长使模型能够捕获更复杂的视觉模式和更细粒度的特征关系。RoPE(Rotary Position Embedding)的自定义实现是一个重要的技术创新。传统的位置编码方法在处理可变分辨率图像时存在局限性,而RoPE通过为每个patch分配归一化坐标系统[−1,1][-1,1][−1,1]中的位置,能够更灵活地处理不同尺寸的输入。多头注意力机制中的位置相关偏置使模型能够显式地利用空间关系信息,这对于理解图像中对象之间的空间布局至关重要。RoPE-box抖动技术是一个数据增强策略,通过随机缩放坐标框到[−s,s][-s,s][−s,s]范围(其中sss在0.5到2之间变化),模型在训练过程中接触到不同的空间尺度信息。这种抖动策略强制模型学习尺度不变的特征表示,提高了对不同分辨率、尺度和纵横比图像的泛化能力。这种设计特别重要,因为在实际应用中,输入图像的尺寸和比例往往是多变的,模型需要具备处理这种变化的鲁棒性。
Optimization Training large models on very large datasets represents a complicated experimental workflow. Because the interplay between model capacity and training data complexity is hard to assess a priori , it is impossible to guess the right optimization horizon. To overcome this, we get rid of all parameter scheduling, and train with constant learning rate, weight decay, and teacher EMA momentum. This has two main benefits. First, we can continue training as long as downstream performance continues to improve. Second, the number of optimization hyperparameters is reduced, making it easier to choose them properly. For the training to start properly, we still use a linear warmup for learning rate and teacher temperature. Following common practices, we use AdamW ( Loshchilov and Hutter , 2017 ), and set the total batch size to 4096 images split across 256 GPUs. We train our models using the multi-crop strategy ( Caron et al. , 2020 ), taking 2 global crops and 8 local crops per image. We use square images with a side length of 256/112 pixels for global/local crops, which, along with the change in patch size, results in the same effective sequence length per image as in DINOv2 and a total sequence length of 3 . 7M tokens per batch. Additional hyperparameters can be found in App. C and in the code release.
【翻译】优化 在超大数据集上训练大型模型代表了一个复杂的实验工作流程。由于模型容量和训练数据复杂性之间的相互作用很难先验评估,因此不可能猜测正确的优化时间范围。为了克服这个问题,我们去除所有参数调度,使用恒定的学习率、权重衰减和教师EMA动量进行训练。这有两个主要好处。首先,只要下游性能继续提高,我们就可以继续训练。其次,优化超参数的数量减少了,使得正确选择它们变得更容易。为了让训练正确开始,我们仍然对学习率和教师温度使用线性预热。遵循常见做法,我们使用AdamW(Loshchilov和Hutter,2017),并将总批次大小设置为4096张图像,分布在256个GPU上。我们使用多裁剪策略(Caron等人,2020)训练模型,每张图像采用2个全局裁剪和8个局部裁剪。我们使用边长为256/112像素的正方形图像进行全局/局部裁剪,结合patch大小的变化,这导致每张图像的有效序列长度与DINOv2相同,每批次总序列长度为3.7M个token。额外的超参数可以在附录C和代码发布中找到。
Figure 6: Evolution of the cosine similarity between the patch noted in red and all other patches. As training progresses, the features produced by the model become less localized and the similarity maps become noisier.
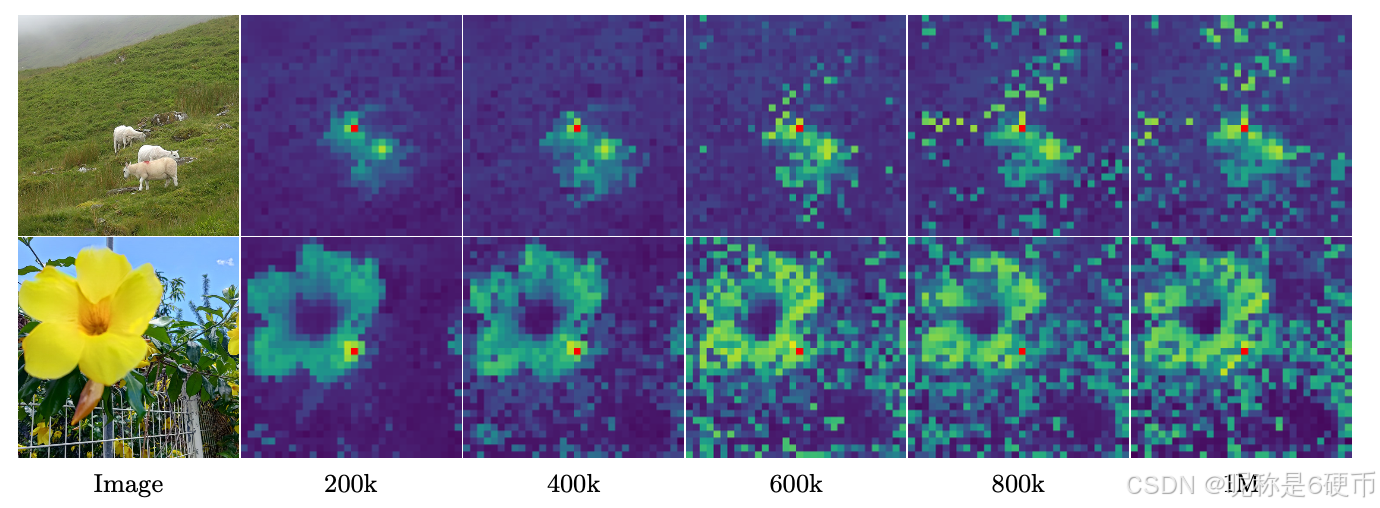
【翻译】图6:标记为红色的patch与所有其他patch之间余弦相似度的演化。随着训练的进行,模型产生的特征变得不那么局部化,相似度图变得更加嘈杂。
【解析】这个可视化清晰地展示了长期训练过程中patch级特征质量的退化现象。在训练初期,相似度图显示出良好的空间局部性,即相邻的patch具有较高的相似度,而距离较远的patch相似度较低,这说明模型能够很好地保持空间邻近性的语义一致性。随着训练迭代次数的增加,这种空间局部性逐渐丧失,原本应该与参考patch相似度较低的远距离patch开始显示出不合理的高相似度。这种现象的根本原因在于模型在优化全局表示性能的过程中,逐渐将更多的语义信息集中到class token中,导致patch token失去了独特的局部表示能力。相似度图的噪声增加说明模型无法稳定地区分不同空间位置的特征,这直接影响了需要精确空间定位的密集预测任务的性能。
4 Gram锚定:密集特征的正则化方法
To fully leverage the benefits of large-scale training, we aim to train the 7B model for an extended duration, with the notion that it could potentially train indefinitely. As expected, prolonged training leads to improvements on global benchmarks. However, as training progresses, the performance degrades on dense tasks ( Figs. 5b and 5c ). This phenomenon, which is due to the emergence of patch-level inconsistencies in feature representations, undermines the interest behind extended training. In this section, we first analyze the loss of patch-level consistency, then propose a new objective to mitigate it, called Gram anchoring . We finally discuss the impact of our approach on both training stability and model performance.
【翻译】为了充分利用大规模训练的好处,我们的目标是对70亿参数模型进行长时间训练,认为它可能可以无限期地训练下去。正如预期的那样,长时间训练导致全局基准测试的改进。然而,随着训练的进行,密集任务的性能下降(图5b和5c)。这种现象是由于特征表示中出现patch级不一致性,破坏了长时间训练的意义。在本节中,我们首先分析patch级一致性的丢失,然后提出一个新的目标来缓解它,称为Gram锚定。我们最后讨论我们方法对训练稳定性和模型性能的影响。
【解析】大规模模型的长期训练呈现出一个矛盾现象:全局性能和局部性能的分化发展趋势。在理想情况下,随着训练时间的延长和参数规模的增大,模型应该在所有任务上都表现出持续的性能提升。然而,实际观察到的现象却表明,70亿参数的大模型在长期训练过程中会出现性能分化。全局任务(如图像分类)的性能确实随着训练时间延长而稳步改善,这说明模型在学习整体语义表示方面确实受益于更多的训练迭代。但密集预测任务(如语义分割、目标检测)的性能却逐渐恶化,这暴露了一个深层次的问题。这种性能分化的根源在于patch级特征表示的一致性逐渐丧失。在Vision Transformer架构中,图像被分割成多个patch,每个patch都有对应的特征表示。在训练初期,相邻或语义相关的patch往往具有相似的特征表示,这种空间连续性对于密集预测任务至关重要。然而,随着训练的深入,这种patch级的一致性开始退化,相邻patch的特征表示可能变得截然不同,导致特征图中出现不规则的跳跃和不连续性。这种不一致性虽然可能不影响全局语义理解(因为全局任务主要依赖于整体特征聚合),但对需要精确空间定位和边界判断的密集任务造成严重损害。因此,需要设计专门的机制来在长期训练过程中维持patch级特征的空间一致性,这就是Gram锚定方法提出的动机。
4.1 训练过程中Patch级一致性的丢失
During extended training, we observe consistent improvements in global metrics but a notable decline in performance on dense prediction tasks. This behavior was previously observed, to a lesser extent, during the training of DINOv2, and also discussed in the scaling effort of Fan et al. ( 2025 ). However, to the best of our knowledge, it remains unresolved to date. We illustrate the phenomenon in Figs. 5b and 5c , which present the performance of the model across iterations on both image classification and segmentation tasks. For classification, we train a linear classifier on ImageNet-1k using the CLS token and report top-1 accuracy. For segmentation, we train a linear layer on patch features extracted from Pascal VOC and report mean Intersection over Union (mIoU). We observe that both for the ViT-g and the ViT-7B, the classification accuracy monotonically improves throughout training. However, segmentation performance declines in both cases after approximately 200k iterations, falling below its early levels in the case of the ViT-7B.
【翻译】在长期训练过程中,我们观察到全局指标的持续改善,但密集预测任务的性能显著下降。这种行为之前在DINOv2的训练中也观察到过(程度较轻),Fan等人(2025)的扩展工作中也讨论过。然而,据我们所知,这个问题至今仍未解决。我们在图5b和5c中展示了这种现象,呈现了模型在图像分类和分割任务上随迭代次数变化的性能。对于分类,我们使用CLS token在ImageNet-1k上训练线性分类器并报告top-1准确率。对于分割,我们在从Pascal VOC提取的patch特征上训练线性层并报告平均交并比(mIoU)。我们观察到,对于ViT-g和ViT-7B,分类准确率在整个训练过程中单调提高。然而,在大约200k迭代后,两种情况下的分割性能都出现下降,在ViT-7B的情况下甚至低于早期水平。
To better understand this degradation, we analyze the quality of patch features by visualizing cosine similarities between patches. Fig. 6 shows the cosine similarity maps between the backbone’s output patch features and a reference patch (highlighted in red). At 200k iterations, the similarity maps are smooth and well-localized, indicating consistent patch-level representations. However, by 600k iterations and beyond, the maps degrade substantially, with an increasing number of irrelevant patches with high similarity to the reference patch. This loss of patch-level consistency correlates with the drop in dense task performance.
【翻译】为了更好地理解这种退化,我们通过可视化patch之间的余弦相似度来分析patch特征的质量。图6显示了主干网络输出的patch特征与参考patch(用红色突出显示)之间的余弦相似度图。在20万次迭代时,相似度图平滑且定位良好,表明patch级表示的一致性。然而,到了60万次迭代及以后,相似度图显著退化,越来越多不相关的patch与参考patch表现出高相似度。这种patch级一致性的丢失与密集任务性能的下降相关。
【解析】可视化分析Vision Transformer训练过程中patch级特征质量变化的。在20万次迭代的早期阶段,余弦相似度图呈现出理想的空间连续性特征:与参考patch在空间上相邻的patch显示出较高的相似度,而距离较远的patch则表现出较低的相似度。这种空间局部性说明模型成功学习到了空间邻近性与语义相似性之间的对应关系,这是进行精确空间定位任务的基础。然而,随着训练进行到60万次迭代,这种理想的空间结构开始瓦解。原本应该与参考patch语义差异较大的远距离patch开始异常地显示出高相似度,这打破了空间连续性假设。标志着patch级特征表示失去了空间定位能力,模型无法再准确区分不同空间位置的语义差异。这种patch级一致性的丧失直接导致了密集预测任务性能的下降,因为这些任务需要模型在像素级或区域级进行精确的语义判断,而混乱的空间相似度关系会产生错误的预测边界和不连续的分割结果。
These patch-level irregularities differ from the high-norm patch outliers described in Darcet et al. ( 2024 ). Specifically, with the integration of register tokens, patch norms remain stable throughout training. However, we notice that the cosine similarity between the CLS token and the patch outputs gradually increases during training. This is expected, yet it means that the locality of the patch features diminishes. We visualize this phenomenon in Fig. 5a , which depicts the cosine maps at 200k and 1M iterations. In order to mitigate the drop on dense tasks, we propose a new objective specifically designed to regularize the patch features and ensure a good patch-level consistency, while preserving high global performance.
【翻译】这些patch级的不规律性与Darcet等人(2024)描述的高范数patch异常值不同。具体来说,通过集成寄存器token,patch范数在整个训练过程中保持稳定。然而,我们注意到CLS token和patch输出之间的余弦相似度在训练过程中逐渐增加。这是预期的,但这说明patch特征的局部性在减弱。我们在图5a中可视化了这种现象,描绘了20万次和100万次迭代时的余弦图。为了缓解密集任务上的性能下降,我们提出了一个新的目标,专门设计用于正则化patch特征并确保良好的patch级一致性,同时保持高全局性能。
【解析】这里提到的patch级不规律性与之前文献中描述的高范数异常值问题在本质上是不同的。Darcet等人观察到的高范数patch异常值主要是指某些patch的特征向量范数异常大,这会影响整个网络的数值稳定性。而register token的引入有效解决了这个范数异常问题,使得所有patch的特征范数在训练过程中保持相对稳定。然而,DINOv3面临的是一个更深层的结构性问题:CLS token与patch token之间的余弦相似度逐渐增加。在理想情况下,CLS token应该聚合全局信息,而patch token应该保持局部空间信息,两者应该在功能上有所区分。相似度的增加说明patch token正在失去其独特的局部表示能力,变得越来越像全局特征的副本。这种现象在图5a的对比中清晰可见:20万次迭代时patch特征还能保持良好的空间局部性,但到100万次迭代时这种局部性基本消失。这促使研究者提出Gram锚定方法,该方法通过显式的正则化来维持patch级特征的空间一致性,既保证了全局表示的学习效果,又防止了局部特征质量的退化。
Figure 7: Evolution trough the training iterations of the patch-level iBOT loss, the global loss DINO (applied to the global crops) and the newly introduced Gram loss. We highlight the iterations of the refinement step LRef\mathcal{L}_{\mathrm{Ref}}LRef which uses the Gram objective.
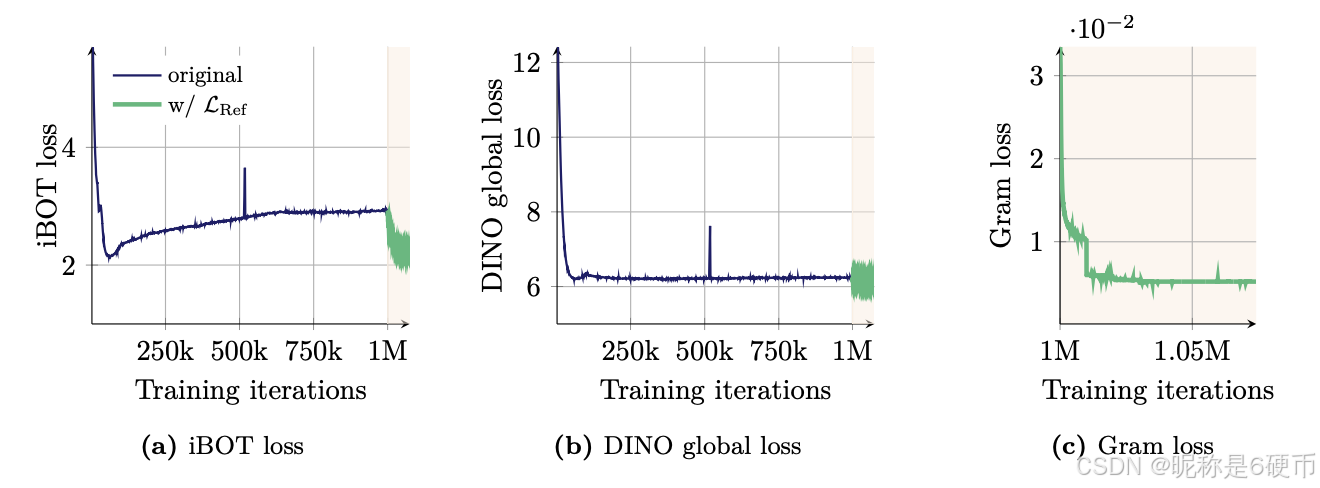
【翻译】图7:patch级iBOT损失、全局DINO损失(应用于全局裁剪)和新引入的Gram损失在训练迭代过程中的演化。我们突出显示了使用Gram目标的细化步骤LRef\mathcal{L}_{\mathrm{Ref}}LRef的迭代次数。
4.2 Gram锚定目标
Throughout our experiments, we have identified a relative independence between learning strong discriminative features and maintaining local consistency, as observed in the lack of correlation between global and dense performance. While combining the global DINO loss with the local iBOT loss has begun to address this issue, we observe that the balance is unstable, with global representation dominating as training progresses. Building on this insight, we propose a novel solution that explicitly leverages this independence.
【翻译】在我们的实验中,我们发现学习强判别特征和维持局部一致性之间存在相对独立性,这从全局性能和密集性能之间缺乏相关性中可以观察到。虽然将全局DINO损失与局部iBOT损失结合已经开始解决这个问题,但我们观察到这种平衡是不稳定的,随着训练的进行,全局表示占主导地位。基于这一洞察,我们提出了一个明确利用这种独立性的新解决方案。
We introduce a new objective which mitigates the degradation of patch-level consistency by enforcing the quality of the patch-level consistency, without impacting the features themselves. This new loss function operates on the Gram matrix: the matrix of all pairwise dot products of patch features in an image. We want to push the Gram matrix of the student towards that of an earlier model, referred to as the Gram teacher . We select the Gram teacher by taking an early iteration of the teacher network, which exhibits superior dense properties. By operating on the Gram matrix rather than the feature themselves, the local features are free to move, provided the structure of similarities remains the same. Suppose we have an image composed of PPP patches, and a network that operates in dimension ddd . Let us denote by XS\mathbf{X}_{S}XS (respectively XG\mathbf{X}_{G}XG ) the P×dP\times dP×d matrix of L2{\bf L}_{2}L2 -normalized local features of the student (respectively the Gram teacher). We define the loss LGram\mathcal{L}_{\mathrm{Gram}}LGram as follows:
【翻译】我们引入了一个新的目标,通过强化patch级一致性的质量来缓解patch级一致性的退化,而不影响特征本身。这个新的损失函数作用于Gram矩阵:图像中patch特征所有成对点积的矩阵。我们希望将学生模型的Gram矩阵推向早期模型的Gram矩阵,我们称之为Gram教师。我们通过选择教师网络的早期迭代来选择Gram教师,该迭代表现出优越的密集特性。通过操作Gram矩阵而不是特征本身,局部特征可以自由移动,只要相似性结构保持相同。假设我们有一个由PPP个patch组成的图像,以及一个在维度ddd上操作的网络。让我们用XS\mathbf{X}_{S}XS(分别用XG\mathbf{X}_{G}XG)来表示学生模型(分别是Gram教师)的L2{\bf L}_{2}L2归一化局部特征的P×dP\times dP×d矩阵。我们定义损失LGram\mathcal{L}_{\mathrm{Gram}}LGram如下:
【解析】Gram锚定方法的创新在于通过操作Gram矩阵来间接约束patch特征的空间结构,而不是直接对特征向量本身进行约束。Gram矩阵是一个P×PP \times PP×P的对称矩阵,其中每个元素Gij=xiTxjG_{ij} = \mathbf{x}_i^T \mathbf{x}_jGij=xiTxj表示第iii个patch和第jjj个patch特征向量之间的点积,本质上捕获了patch之间的相似性关系。这种设计的巧妙之处在于,它保持了特征学习的灵活性:patch特征向量仍然可以在高维空间中自由演化和优化,只要它们之间的相对相似性结构与参考模型保持一致。Gram教师的选择策略也很重要,研究团队选择训练早期阶段的模型作为参考,因为早期模型在局部一致性方面表现更好,能够提供理想的空间结构模板。通过让当前训练中的学生模型的Gram矩阵向早期Gram教师的Gram矩阵靠拢,可以有效地"修复"在长期训练过程中丢失的空间局部性。L2{\bf L}_{2}L2归一化确保了不同patch特征向量具有相同的范数,使得Gram矩阵中的值主要反映角度相似性而不是幅度差异,这有助于稳定训练过程并确保相似性度量的准确性。这种方法的另一个优势是它不会直接干预全局特征学习过程,因为它主要作用于局部patch之间的相互关系,而全局表示主要由class token承载,从而实现了局部一致性维持和全局性能优化的解耦。
LGram=∥XS⋅XS⊤−XG⋅XG⊤∥F2.\mathcal{L}_{\mathrm{Gram}}=\left\|\mathbf{X}_{S}\cdot\mathbf{X}_{S}^{\top}-\mathbf{X}_{G}\cdot\mathbf{X}_{G}^{\top}\right\|_{\mathrm{F}}^{2}. LGram=XS⋅XS⊤−XG⋅XG⊤F2.
We only compute this loss on the global crops. Even though it can be applied early on during the training, for efficiency, we start only after 1M iterations. Interestingly, we observe that the late application of LGram\mathcal{L}_{\mathrm{Gram}}LGram still manages to “repair” very degraded local features. In order to further improve performance, we update the Gram teacher every 10k iterations at which the Gram teacher becomes identical to the main EMA teacher. We call this second step of training the refinement step , which optimizes the objective LRef\mathcal{L}_{\mathrm{Ref}}LRef , with
LRef=wDLDINO+LiBOT+wDKLDKoleo+wGramLGram.\mathcal{L}_{\mathrm{Ref}}=w_{\mathrm{D}}\mathcal{L}_{\mathrm{DINO}}+\mathcal{L}_{\mathrm{iBOT}}+w_{\mathrm{DK}}\mathcal{L}_{\mathrm{DKoleo}}+w_{\mathrm{Gram}}\mathcal{L}_{\mathrm{Gram}}. LRef=wDLDINO+LiBOT+wDKLDKoleo+wGramLGram.
【翻译】我们只在全局裁剪上计算这个损失。尽管它可以在训练早期应用,但为了效率,我们只在100万次迭代后开始。有趣的是,我们观察到延迟应用LGram\mathcal{L}_{\mathrm{Gram}}LGram仍然能够"修复"严重退化的局部特征。为了进一步提高性能,我们每10k次迭代更新一次Gram教师,此时Gram教师变得与主EMA教师相同。我们称训练的第二步为细化步骤,它优化目标LRef\mathcal{L}_{\mathrm{Ref}}LRef。
【解析】Gram锚定损失的是效率与效果的平衡考量。首先,损失计算只作用于全局裁剪而非局部裁剪,这是因为全局裁剪包含了完整图像的所有patch信息,能够提供完整的空间相似性结构,而局部裁剪只是图像的部分区域,无法反映完整的空间关系。其次,选择在100万次迭代后才引入LGram\mathcal{L}_{\mathrm{Gram}}LGram损失是一个关键的时序决策。在训练初期,模型仍在学习基础的视觉表示,patch级一致性问题尚未显现,过早引入额外的约束可能会干扰基础特征的学习。而在100万次迭代后,模型已经学到了丰富的语义表示,但开始出现patch级一致性退化,此时引入Gram锚定能够精确地解决目标问题。即使在特征已经严重退化的后期阶段引入Gram损失,仍然能够有效"修复"局部特征质量,这说明Vision Transformer的特征表示具有良好的可塑性。Gram教师的动态更新策略也很关键:每10k次迭代将Gram教师更新为当前的EMA教师,确保参考模板始终保持相对新鲜的状态,避免使用过时的特征结构作为约束目标。细化阶段的损失函数LRef\mathcal{L}_{\mathrm{Ref}}LRef是多个损失项的加权组合,包括全局DINO损失、局部iBOT损失、DKoleo损失和新的Gram损失,各项权重wDw_{\mathrm{D}}wD、wDKw_{\mathrm{DK}}wDK、wGramw_{\mathrm{Gram}}wGram的设置需要精心调节,以确保在修复局部特征一致性的同时不损害已经学到的全局表示能力。
We visualize the evolution of different losses in Fig. 7 and observe that applying the Gram objective significantly influences the iBOT loss, causing it to decrease more rapidly. This suggests that the stability introduced by the stable Gram teacher positively impacts the iBOT objective. In contrast, the Gram objective does not have a significant effect on the DINO losses. This observation implies that the Gram and iBOT objectives impact the features in a similar way, whereas the DINO losses affect them differently.
【翻译】我们在图7中可视化了不同损失的演化,观察到应用Gram目标显著影响iBOT损失,使其下降得更快。这说明稳定的Gram教师引入的稳定性对iBOT目标产生积极影响。相比之下,Gram目标对DINO损失没有显著效果。这一观察说明Gram和iBOT目标以相似的方式影响特征,而DINO损失则以不同的方式影响它们。
【解析】这段分析揭示了不同损失函数之间的相互作用机制。图7的损失演化曲线显示,当引入Gram锚定目标后,iBOT损失的下降速度明显加快,这种现象背后反映了深层的特征学习机制。iBOT损失主要关注patch级别的掩码重建任务,需要模型在局部patch之间建立准确的空间相关性,而Gram矩阵恰好编码了patch之间的相似性结构。因此,稳定的Gram教师提供的空间结构约束直接有助于iBOT目标的优化,两者在feature space中存在互补的约束作用。具体来说,Gram约束确保了patch特征之间的相似性关系保持空间连续性,而这种连续性正是iBOT掩码重建任务所需要的先验知识,使得模型能够更容易地从周围未被掩码的patch中推断出被掩码patch的内容。相反,DINO损失主要作用于全局class token,关注整体图像的语义表示学习,它的优化路径相对独立于patch之间的局部相似性结构。因此Gram目标对DINO损失的影响较小,这种差异性说明了Vision Transformer中全局特征学习和局部特征学习在某种程度上是解耦的。这种观察为理解多目标训练中不同损失函数的相互作用提供了重要洞察,也验证了Gram锚定方法能够选择性地改善局部特征质量而不损害全局表示能力。
Figure 8: Evolution of the results on different benchmarks after applying our proposed Gram anchoring method. We visualize results when continuing the original training with our refinement step, noted ’ LRef\mathcal{L}_{\mathrm{Ref}}{}^{}LRef '. We also plot results obtained when using higher-resolution features for the Gram objective as introduced in following Sec. 4.3 and noted ’ LHRef\boldsymbol{\mathcal{L}}_{\mathrm{HRef}}LHRef '. We highlight the iterations which use the Gram objective.
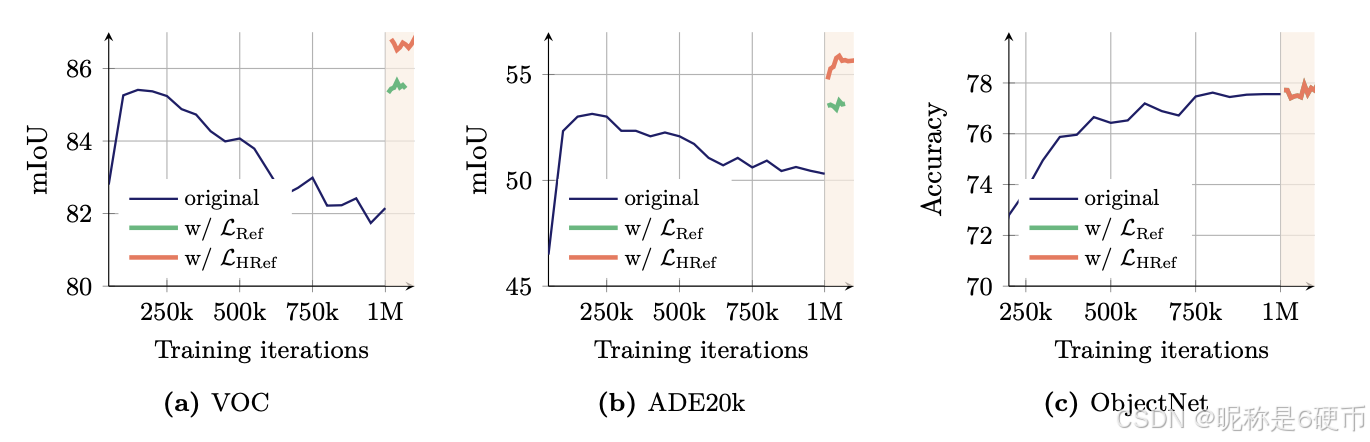
【翻译】图8:应用我们提出的Gram锚定方法后不同基准测试结果的演化。我们可视化了使用细化步骤继续原始训练的结果,记为’LRef\mathcal{L}_{\mathrm{Ref}}{}^{}LRef‘。我们还绘制了使用高分辨率特征进行Gram目标的结果,如4.3节中介绍的,记为’LHRef\boldsymbol{\mathcal{L}}_{\mathrm{HRef}}LHRef'。我们突出显示了使用Gram目标的迭代次数。
【解析】图8展示了Gram锚定方法在多个benchmark上的效果演化,图中包含两条主要曲线:LRef\mathcal{L}_{\mathrm{Ref}}LRef代表基础的Gram锚定细化过程,而LHRef\boldsymbol{\mathcal{L}}_{\mathrm{HRef}}LHRef则代表结合高分辨率特征的进阶版本。图中突出显示的Gram目标应用迭代区间对于理解方法的时序效应至关重要,因为它显示了Gram锚定不是在整个训练过程中持续应用,而是在特定的refinement阶段引入。这种阶段性应用策略避免了早期训练中不必要的约束,让模型首先学习基础的视觉表示,然后在后期通过Gram约束来修复局部特征质量。不同benchmark的表现变化趋势:密集预测任务(如语义分割)通常显示出更显著的改善,因为这些任务对patch级特征的空间一致性更为敏感,而全局分类任务的改善相对较小但依然稳定,这验证了方法对全局表示学习的无害性。高分辨率版本LHRef\boldsymbol{\mathcal{L}}_{\mathrm{HRef}}LHRef的进一步性能提升说明了高质量Gram教师的重要性,通过使用更细致的空间结构作为约束目标,能够指导学生模型学习到更精确的局部特征表示。
Regarding performance, we observe the impact of the new loss is almost immediate. As shown in Fig. 8 , incorporating Gram anchoring leads to significant improvements on dense tasks within the first 10k iterations. We also see notable gains on the ADE20k benchmark following the Gram teacher updates. Additionally, longer training further benefits performance on the ObjectNet benchmark and other global benchmarks show mild impact from the new loss.
【翻译】关于性能,我们观察到新损失的影响几乎是立即的。如图8所示,引入Gram锚定在前10k次迭代内就在密集任务上带来了显著改善。我们还看到在Gram教师更新后ADE20k基准测试中的显著收益。此外,更长时间的训练进一步提升了ObjectNet基准测试的性能,其他全局基准测试显示出新损失的轻微影响。
4.3 利用高分辨率特征
Recent work shows that a weighted average of patch features can yield stronger local representations by smoothing outlier patches and enhancing patch-level consistency ( Wysoczańska et al. , 2024 ). On the other hand, feeding higher-resolution images into the backbone produces finer and more detailed feature maps. We leverage the benefits of both observations to compute high-quality features for Gram teacher. Specifically, we first input images at twice the normal resolution into the Gram teacher, then 2×2\times2× down-sample the resulting feature maps with the bicubic interpolation to achieve the desired smooth feature maps that match the size of the student output. Fig. 9a visualizes the Gram matrices of patch features obtained with images at resolutions 256 and 512, as well as those obtained after 2 ×\times× down-sampling features from the 512-resolution (denoted as ‘downsamp.’). We observe that the superior patch-level consistency in the higher-resolution features is preserved through down-sampling, resulting in smoother and more coherent patch-level representations. As a side note, our model can seamlessly process images at varying resolutions without requiring adaptation, thanks to the adoption of Rotary Positional Embeddings (RoPE) introduced by Su et al. ( 2024 ).
【翻译】最近的工作表明,patch特征的加权平均可以通过平滑异常patch并增强patch级一致性来产生更强的局部表示(Wysoczańska et al.,2024)。另一方面,将更高分辨率的图像输入主干网络会产生更精细和更详细的特征图。我们利用这两个观察的优势来计算Gram教师的高质量特征。具体来说,我们首先将两倍正常分辨率的图像输入Gram教师,然后使用双三次插值对生成的特征图进行2×2\times2×下采样,以获得与学生输出大小匹配的所需平滑特征图。图9a可视化了在分辨率256和512下获得的patch特征的Gram矩阵,以及从512分辨率特征进行2×\times×下采样后获得的Gram矩阵(标记为’downsamp.')。我们观察到高分辨率特征中优越的patch级一致性通过下采样得以保持,从而产生更平滑、更连贯的patch级表示。顺便提一下,由于采用了Su等人(2024)引入的旋转位置嵌入(RoPE),我们的模型可以无缝处理不同分辨率的图像而无需适应。
【解析】这里介绍的高分辨率Gram锚定技术是对基础Gram锚定方法的改进。核心思想是通过结合两个独立的研究发现来构建更优质的Gram教师模型。第一个发现是patch特征的加权平均能够平滑异常patch并增强空间一致性,这种平滑操作有助于消除由于数据噪声或训练不稳定导致的局部特征不连续性。第二个发现是高分辨率输入能够产生更精细的特征图,包含更丰富的空间细节信息。研究团队巧妙地将这两个优势结合:首先使用2×2\times2×的高分辨率图像作为Gram教师的输入,这样可以获得包含更多空间细节的特征表示,然后通过双三次插值进行2×2\times2×下采样,将特征图尺寸调整到与学生模型输出相匹配。双三次插值是一种高质量的图像缩放算法,它通过考虑周围16个像素的加权平均来计算新的像素值,这种插值方法不仅能够保持图像的细节信息,还能产生平滑的过渡效果,从而实现了前述两个优势的完美结合。图9a的可视化结果验证了这种方法的有效性:高分辨率特征确实具有更好的patch级一致性,而且这种一致性在下采样过程中得以保持,最终产生的特征表示既包含丰富的空间细节又具有良好的空间连续性。值得注意的是,模型能够处理不同分辨率输入的能力来源于旋转位置嵌入(RoPE)的使用,RoPE通过将位置信息编码为旋转矩阵的形式,使得模型能够自然地泛化到训练时未见过的序列长度,这对于处理不同分辨率图像(对应不同数量的patch)至关重要。
We compute the Gram matrix of the down-sampled features and use it to replace XG\mathbf{X}_{G}XG in the objective LGram\mathcal{L}_{\mathrm{Gram}}LGram . We note the new resulting refinement objective as LHRef\mathcal{L}_{\mathrm{HRef}}LHRef . This approach enables the Gram objective to effectively distill the improved patch consistency of smoothed high-resolution features into the student model. As shown in Fig. 8 and Fig. 9b , this distillation translates into better predictions on dense tasks, yielding additional gains on top of the benefit brought by LRef\mathcal{L}_{\mathrm{Ref}}LRef ( +2+2+2 mIoU on ADE20k). We also ablate the choice of Gram teacher in Fig. 9b . Interestingly, choosing the Gram teacher from 100k or 200k does not significantly impact the results, but using a much later Gram teacher (1M iterations) is detrimental because the patch-level consistency of such a teacher is inferior.
【翻译】我们计算下采样特征的Gram矩阵,并用它来替换目标LGram\mathcal{L}_{\mathrm{Gram}}LGram中的XG\mathbf{X}_{G}XG。我们将新的细化目标记为LHRef\mathcal{L}_{\mathrm{HRef}}LHRef。这种方法使Gram目标能够有效地将平滑高分辨率特征的改进patch一致性蒸馏到学生模型中。如图8和图9b所示,这种蒸馏转化为密集任务上更好的预测,在LRef\mathcal{L}_{\mathrm{Ref}}LRef带来的好处基础上产生额外收益(在ADE20k上+2 mIoU)。我们还在图9b中消融了Gram教师的选择。有趣的是,从100k或200k选择Gram教师对结果没有显著影响,但使用更晚的Gram教师(1M次迭代)是有害的,因为这样的教师的patch级一致性较差。
【解析】高分辨率Gram锚定方法的具体实现涉及将高质量的下采样特征矩阵XG\mathbf{X}_{G}XG替换到原始的Gram损失函数中,形成新的高分辨率细化目标LHRef\mathcal{L}_{\mathrm{HRef}}LHRef。这种替换的本质是将Gram锚定的参考标准从普通分辨率的早期模型特征提升到高分辨率平滑处理后的特征,从而为学生模型提供更高质量的空间结构约束。蒸馏过程的工作机制是:高分辨率Gram教师产生的Gram矩阵包含更精确的patch间相似性关系,当学生模型的Gram矩阵被约束向这个高质量参考靠拢时,学生模型被迫学习到更准确的空间特征表示。实验结果显示,这种改进在密集预测任务上带来了额外的性能提升,特别是在ADE20k语义分割任务上获得了2个mIoU的额外收益,这说明改进的空间特征质量直接转化为了实际应用性能的提升。关于Gram教师选择时机的消融研究揭示了一个重要的训练动态:100k和200k迭代的教师模型在性能上相当,说明在这个时间段内模型的patch级一致性相对稳定,而1M迭代的教师模型性能反而下降,这验证了前面提到的长期训练导致patch级一致性退化的现象。这个观察进一步支持了选择早期训练阶段模型作为Gram教师的策略,因为早期模型确实保持了更好的局部空间结构,能够为后续的特征学习提供更有效的指导。这种时机选择的重要性说明,在自监督学习中,不同训练阶段的模型具有不同的特征学习特性,合理利用这些特性能够显著改善最终的模型质量。
Finally, we qualitatively illustrate the effect of Gram anchoring to patch-level consistency in Fig. 10 which visualizes the Gram matrices patch features obtained with the initial training and high-resolution Gram anchoring refinement. We observe great improvements in feature correlations that our high-resolution refinement procedure brings about.
【翻译】最后,我们在图10中定性地说明了Gram锚定对patch级一致性的影响,该图可视化了通过初始训练和高分辨率Gram锚定细化获得的patch特征的Gram矩阵。我们观察到我们的高分辨率细化过程带来的特征相关性的巨大改善。
Figure 9: Quantitative and qualitative study of the impact of high-resolution Gram. We show (a) the improved cosine maps after down-sampling the high-resolution maps into smaller ones, and (b) the quantitative improvements brought by varying the training iteration and the resolution of the Gram teacher.

【翻译】图9:高分辨率Gram影响的定量和定性研究。我们展示了(a)将高分辨率图下采样为较小图后改进的余弦图,以及(b)通过改变训练迭代次数和Gram教师分辨率带来的定量改进。
Figure 10: Qualitative effect of Gram anchoring. We visualize cosine maps before and after using the refinement objective LHRef\mathcal{L}_{\mathrm{HRef}}LHRef . The input resolution of the images is 1024×10241024\times10241024×1024 pixels.

【翻译】图10:Gram锚定的定性效果。我们可视化了使用细化目标LHRef\mathcal{L}_{\mathrm{HRef}}LHRef前后的余弦图。图像的输入分辨率为1024×10241024\times10241024×1024像素。
5 后训练
This section presents post-training stages. This includes a high-resolution adaptation phase enabling effective inference at different input resolutions ( Sec. 5.1 ), model distillation producing quality and efficient smallersized models ( Sec. 5.2 ), and text alignment adding zero-shot capabilities to DINOv3 ( Sec. 5.3 ).
【翻译】本节介绍训练后阶段。这包括支持在不同输入分辨率下有效推理的高分辨率适应阶段(第5.1节),产生高质量和高效小尺寸模型的模型蒸馏(第5.2节),以及为DINOv3添加零样本能力的文本对齐(第5.3节)。
5.1 分辨率扩展
We train our model at a relatively small resolution of 256, which gives us a good trade-off between speed and effectiveness. For a patch size of 16, this setup leads to the same input sequence length as DINOv2, which was trained with resolution 224 and patch size 14. However, many contemporary computer vision applications require processing images at significantly higher resolutions, often 512×512512\times512512×512 pixels or greater, to capture intricate spatial information. The inference image resolution is also not fixed in practice and varies depending on specific use cases. To address this, we extend our training regime with a high-resolution adaptation step ( Touvron et al. , 2019 ). To ensure high performance across a range of resolutions, we utilize mixed resolutions , sampling differently-sized pairs of global and local crops per mini-batch. Specifically, we consider global crop sizes from { 512 , 768 } and local crop sizes from {112,168,224,336}\{112,168,224,336\}{112,168,224,336} and train the model for 10k additional iterations.
【翻译】我们在相对较小的256分辨率下训练模型,这为我们提供了速度和效果之间的良好权衡。对于16的patch大小,这种设置导致与DINOv2相同的输入序列长度,DINOv2使用224分辨率和14的patch大小进行训练。然而,许多当代计算机视觉应用需要处理显著更高分辨率的图像,通常是512×512512\times512512×512像素或更大,以捕获复杂的空间信息。推理图像分辨率在实践中也不是固定的,会根据具体用例而变化。为了解决这个问题,我们通过高分辨率适应步骤扩展了我们的训练方案(Touvron et al.,2019)。为了确保在各种分辨率下的高性能,我们利用混合分辨率,为每个小批次采样不同大小的全局和局部裁剪对。具体来说,我们考虑来自{512, 768}的全局裁剪大小和来自{112,168,224,336}\{112,168,224,336\}{112,168,224,336}的局部裁剪大小,并额外训练模型10k次迭代。
【解析】这段描述了DINOv3在高分辨率适应方面的训练策略。首先要理解为什么需要高分辨率适应:虽然模型在256分辨率下训练可以获得速度和效果的平衡,但实际应用中往往需要处理更高分辨率的图像来获取更精细的空间细节信息。高分辨率适应的难点在于如何让在低分辨率下训练的模型能够有效处理高分辨率输入而不损失性能。解决方案是采用混合分辨率训练策略,这种方法通过在同一个小批次内混合使用不同分辨率的图像来让模型逐步适应分辨率变化。全局裁剪尺寸{512, 768}提供了整体图像的高分辨率版本,而局部裁剪尺寸{112,168,224,336}\{112,168,224,336\}{112,168,224,336}则提供了不同尺度的局部区域视图。这种设计模拟了真实应用中的多尺度处理需求,让模型能够同时学习全局和局部的高分辨率特征表示。10k额外迭代的训练时间相对较短,说明这是一个高效的适应过程,不需要从头重新训练整个模型。patch大小16与分辨率256的组合产生的序列长度与DINOv2的224分辨率和patch大小14相同,这种设计保证了模型架构的兼容性和计算复杂度的一致性,便于进行公平的性能比较。混合分辨率训练的关键优势在于它能够让模型在保持原有低分辨率性能的同时,获得处理高分辨率图像的能力
Figure 11: Effect of high resolution adaptation. Results before (‘Pre-HR’) and after (‘Post-HR’) resolution scaling ( Sec. 5.1 ) on (a) linear classification on ImageNet, (b) applied OOD to ObjectNet, © linear semantic segmentation on ADE20k, and (d) segmentation tracking on DAVIS at different evaluation resolutions.
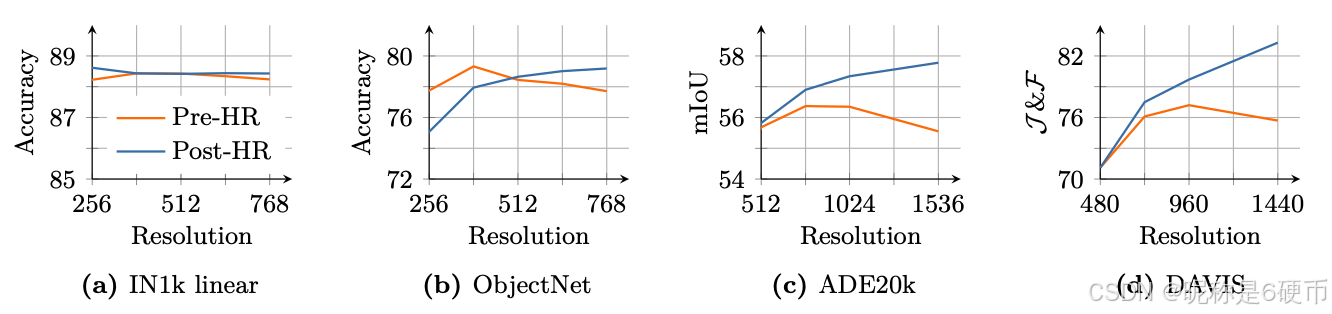
【翻译】图11:高分辨率适应的效果。在不同评估分辨率下,分辨率缩放(第5.1节)前(‘Pre-HR’)和后(‘Post-HR’)的结果:(a) ImageNet上的线性分类,(b) 应用于ObjectNet的OOD,© ADE20k上的线性语义分割,(d) DAVIS上的分割跟踪。
【解析】图11通过四个不同的任务展示了高分辨率适应的效果,这些任务覆盖了从全局分类到密集预测的各种计算机视觉应用。ImageNet线性分类任务测试模型的全局图像理解能力,这是最基础的视觉识别任务。ObjectNet的分布外(OOD)测试评估模型的泛化能力,特别是对于与训练数据分布不同的图像的处理能力。ADE20k语义分割任务测试模型的密集预测能力,需要为图像中的每个像素分配语义标签,这对特征的空间精确性要求很高。DAVIS分割跟踪任务结合了时序信息和空间分割,测试模型在视频序列中维持目标一致性的能力。通过比较Pre-HR和Post-HR的结果,可以清楚地看到高分辨率适应训练对不同任务的影响程度。通常情况下,需要精细空间信息的密集预测任务(如语义分割和跟踪)会从高分辨率适应中获得更显著的改善,因为高分辨率能够提供更详细的空间结构信息。而全局分类任务的改善可能相对较小,因为分类主要依赖于全局语义特征而非精细的空间细节。
Similar to the main training, a key component of this high-resolution adaptation phase is the addition of Gram anchoring, using the 7B teacher as Gram teacher. We found this component to be essential: without it, the model performance on dense prediction tasks degrades significantly. The Gram anchoring encourages the model to maintain consistent and robust feature correlations across spatial locations, which is crucial when dealing with the increased complexity of high-resolution inputs.
【翻译】与主要训练类似,高分辨率适应阶段的一个关键组件是添加Gram锚定,使用7B教师作为Gram教师。我们发现这个组件是必不可少的:没有它,模型在密集预测任务上的性能会显著下降。Gram锚定鼓励模型在空间位置上保持一致和稳健的特征相关性,这在处理高分辨率输入增加的复杂性时至关重要。
Empirically, we observe that this relatively brief but targeted high-resolution step substantially enhances the overall model’s quality and allows it to generalize across a wide range of input sizes, as shown visually in Fig. 4 . In Fig. 11 , we compare our 7B model before and after adaptation. We find that resolution scaling leads to a small gain on ImageNet classification (a) with relatively stable performance w.r.t. resolution. However, in ObjectNet OOD transfer (b), we observe that the performance tends to degrade slightly for lower resolutions, while improving for higher resolutions. This is largely compensated by the improvement in the quality of local features at high resolution, shown by the positive trend in segmentation on ADE20k © and tracking on DAVIS (d). Adaptation leads to local features that improve with image size , leveraging the richer spatial information available at larger resolutions and effectively enabling high-resolution inference. Interestingly, the adapted model supports resolutions way beyond the maximum training resolution of 768— we visually observe stable feature maps at resolutions above 4k ( c.f . Fig. 4 ).
【翻译】经验上,我们观察到这个相对简短但有针对性的高分辨率步骤大幅提升了模型的整体质量,并允许其在广泛的输入尺寸范围内泛化,如图4所示。在图11中,我们比较了适应前后的7B模型。我们发现分辨率缩放在ImageNet分类(a)上带来了小幅收益,相对于分辨率具有相对稳定的性能。然而,在ObjectNet OOD迁移(b)中,我们观察到性能在低分辨率时趋于轻微下降,而在高分辨率时有所改善。这在很大程度上被高分辨率局部特征质量的改善所补偿,这在ADE20k分割©和DAVIS跟踪(d)的积极趋势中得到体现。适应导致局部特征随图像尺寸改善,利用更大分辨率下可用的更丰富空间信息,有效地实现高分辨率推理。有趣的是,适应后的模型支持远超最大训练分辨率768的分辨率——我们在4k以上分辨率观察到稳定的特征图(参见图4)。
5.2 模型蒸馏
A Family of Models for Multiple Use-Cases We perform knowledge distillation of the ViT-7B model into smaller Vision Transformer variants (ViT-S, ViT-B, and ViT-L), which are highly valued by the community for their improved manageability and efficiency. Our distillation approach uses the same training objective as in the first training phase, ensuring consistency in learning signals. However, instead of relying on an exponential moving average (EMA) of model weights, we use the 7B model directly as the teacher to guide the smaller student models. In this case, the teacher model is fixed. We do not observe patch-level consistency issues and therefore do not apply the Gram anchoring technique. This strategy enables the distilled models to inherit the rich representational power of the large teacher while being more practical for deployment and experimentation.
【翻译】多用例模型家族 我们对ViT-7B模型进行知识蒸馏,得到更小的Vision Transformer变体(ViT-S、ViT-B和ViT-L),这些模型因其改进的可管理性和效率而受到社区的高度重视。我们的蒸馏方法使用与第一个训练阶段相同的训练目标,确保学习信号的一致性。然而,我们不依赖模型权重的指数移动平均(EMA),而是直接使用7B模型作为教师来指导较小的学生模型。在这种情况下,教师模型是固定的。我们没有观察到patch级一致性问题,因此不应用Gram锚定技术。这种策略使蒸馏模型能够继承大型教师的丰富表示能力,同时在部署和实验方面更加实用。
【解析】在DINOv3的实现中,蒸馏策略有几个关键特点:首先,它保持了与主训练阶段相同的训练目标,这确保了学习过程的连贯性,避免了因目标函数改变而导致的性能损失。其次,与传统方法不同,这里不使用指数移动平均来平滑教师模型的参数,而是直接使用固定的7B模型作为教师。这种设计简化了蒸馏过程,因为固定的教师模型提供了稳定的指导信号,不会在训练过程中发生变化。更重要的是,由于教师模型是固定的且已经训练完成,patch级一致性问题不再是关注点,因此不需要应用Gram锚定技术。这种简化不仅降低了计算复杂度,还避免了额外的超参数调节。
Our ViT-7B model is distilled into a series of ViT models with sizes covering a broad range of compute budgets, and allowing proper comparison with concurrent models. They include the standard ViT-S (21M params), B (86M), L (0.3B), along with a custom ViT-S+ (29M) and a custom ViT-H+ (0.8B) model to close the performance gap with the self-distilled 7B teacher model. Indeed, we observe in DINOv2 that smaller student models can reach a performance on par with their teacher as the distillation. As a result, the distilled models deliver frontier-level performance for a fraction of the inference compute as we see in Tab. 14. We train the models for 1M iterations then perform 250k iterations of learning-rate cooldown following a cosine schedule before applying the high-resolution phase described in Sec. 5.1 above without Gram anchoring.
【翻译】我们的ViT-7B模型被蒸馏成一系列ViT模型,尺寸覆盖了广泛的计算预算范围,并允许与并行模型进行适当比较。它们包括标准的ViT-S(21M参数)、B(86M)、L(0.3B),以及定制的ViT-S+(29M)和定制的ViT-H+(0.8B)模型,以缩小与自蒸馏7B教师模型的性能差距。实际上,我们在DINOv2中观察到,较小的学生模型可以通过蒸馏达到与其教师相当的性能。因此,蒸馏模型以一小部分推理计算提供前沿级别的性能,如表14所示。我们训练模型1M次迭代,然后按照余弦调度执行250k次学习率冷却迭代,之后应用第5.1节中描述的高分辨率阶段,但不使用Gram锚定。
Figure 12: Multi-student distillation procedure. In this diagram, we distill 3 students in parallel: we first share teacher inference across all T nodes to save compute, and gather inputs and results on all GPUs. Then, smaller groups perform student training. We adjust the size of these groups such that the training step has the same duration across all students SiS iSi , minimizing idle time waiting at the synchronization barrier.
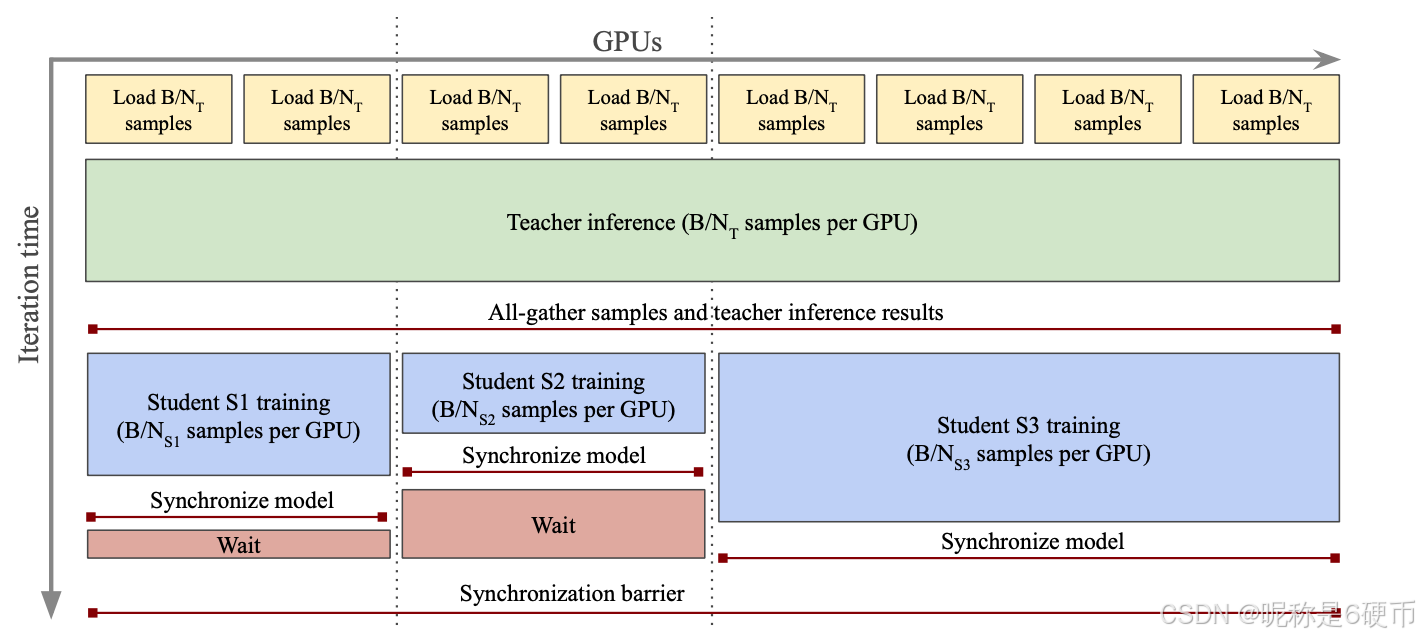
【翻译】图12:多学生蒸馏过程。在此图中,我们并行蒸馏3个学生:我们首先在所有T个节点间共享教师推理以节省计算,并在所有GPU上收集输入和结果。然后,较小的组执行学生训练。我们调整这些组的大小,使得训练步骤在所有学生SiS_iSi上具有相同的持续时间,最小化在同步屏障处等待的空闲时间。
Efficient Multi-Student Distillation As the inference cost for a large teacher can be orders of magnitude higher than for students (see Fig. 16a ), we design a parallel distillation pipeline that allows training multiple students at the same time and sharing the teacher inference across all nodes involved in the training (see Fig. 12 for a diagram). Let CT\mathit{C}_{T}CT and CSC_{S}CS be respectively the cost of running the teacher inference and the student training on a single sample, in single-teacher/single-student distillation with batch-size BBB where each of the NNN GPUs processes a B/NB/NB/N slice of the data, the teacher inference costs B/N×CTB/N\times C_{T}B/N×CT and the stu nt training costs B/N×CSB/N\times C_{S}B/N×CS per GPU. In multi-student distillation, we proceed as follows. Each student Si is assigned a set of NSiN_{S i}NSi GPUs for training, and all NT=∑NSiN_{T}=\sum N_{S i}NT=∑NSi GPUs are part al inference group. At each iteration, we first run the teacher inference on the global group for a B/NT×CTB/N_{T}\times C_{T}B/NT×CT × compute cost per GPU. We then run an all-gather collective operation to share the input data and inference result with all compute nodes. Finally, each student group separately performs student training for a B/NSi×CSiB/N_{S i}\times C_{S i}B/NSi×CSi cost.
【翻译】高效多学生蒸馏 由于大型教师的推理成本可能比学生高几个数量级(见图16a),我们设计了一个并行蒸馏管道,允许同时训练多个学生并在参与训练的所有节点间共享教师推理(见图12示意图)。设CT\mathit{C}_{T}CT和CSC_{S}CS分别为在单个样本上运行教师推理和学生训练的成本,在单教师/单学生蒸馏中,批大小为BBB,其中NNN个GPU中的每一个处理数据的B/NB/NB/N切片,教师推理每GPU成本为B/N×CTB/N\times C_{T}B/N×CT,学生训练每GPU成本为B/N×CSB/N\times C_{S}B/N×CS。在多学生蒸馏中,我们按如下方式进行。每个学生SiS_iSi被分配一组NSiN_{S_i}NSi个GPU用于训练,所有NT=∑NSiN_{T}=\sum N_{S_i}NT=∑NSi个GPU都是推理组的一部分。在每次迭代中,我们首先在全局组上运行教师推理,每GPU计算成本为B/NT×CTB/N_{T}\times C_{T}B/NT×CT。然后我们运行all-gather集体操作,与所有计算节点共享输入数据和推理结果。最后,每个学生组分别执行学生训练,成本为B/NSi×CSiB/N_{S_i}\times C_{S_i}B/NSi×CSi。
The above calculations shows that adding an additional student to the distillation pipeline will (1) reduce the per-GPU compute at each iteration, thus globally improving distillation speed, and (2) increase the overall compute only by the training cost of the new student, since the total teacher inference cost is now fixed. The implementation only requires setting up GPU process groups carefully, adapting data-loaders and teacher inference to ensure inputs and outputs are synchronized across groups using NCCL collectives. As the groups are synchronized at each iteration, in order to maximize speed, we adapt the number of GPUs for each student such that their iteration times are roughly the same. With this procedure, we seamlessly train multiple students, and produce a whole family of distilled models from our flagship 7B model.
【翻译】上述计算表明,向蒸馏管道添加额外的学生将:(1) 减少每次迭代的每GPU计算量,从而全局改善蒸馏速度,(2) 仅增加新学生的训练成本来增加总体计算量,因为总教师推理成本现在是固定的。实现只需要仔细设置GPU进程组,调整数据加载器和教师推理,以确保使用NCCL集体操作在组间同步输入和输出。由于组在每次迭代时同步,为了最大化速度,我们为每个学生调整GPU数量,使其迭代时间大致相同。通过这个过程,我们无缝地训练多个学生,并从我们的旗舰7B模型中产生整个蒸馏模型家族。
【解析】多学生蒸馏是DINOv3中一个重要的工程优化策略,解决了大模型蒸馏过程中的计算效率问题。传统的单教师单学生蒸馏存在明显的计算资源浪费:大型教师模型的推理成本远高于小型学生模型的训练成本,导致在等待教师推理完成时学生训练资源闲置。多学生蒸馏通过共享教师推理结果来解决这个问题,让多个学生模型同时从同一次教师推理中学习。关键创新在于将计算过程分为两个阶段:首先所有GPU协作完成教师推理,然后分组并行进行不同学生的训练。这种设计的数学优势很明显:增加新学生只会增加该学生的训练成本,而教师推理成本在所有学生间摊销,总体效率显著提升。实现上需要精心设计GPU进程组和数据同步机制,使用NCCL集体通信确保数据一致性。为了避免木桶效应,算法动态调整每个学生的GPU分配,确保所有学生的训练时间大致相等,最小化同步等待时间。这种方法不仅提高了计算效率,还简化了部署流程,能够从单个大型教师模型一次性产生完整的模型家族,满足不同应用场景的需求。
5.3 将DINOv3与文本对齐
Open-vocabulary image-text alignment has received significant interest and enthusiasm from the research community, thanks to its potential to enable flexible and scalable multimodal understanding. A large body of work has focused on improving the quality of CLIP ( Radford et al. , 2021 ), which originally learned only a global alignment between image and text representations. While CLIP has demonstrated impressive zero-shot capabilities, its focus on global features limits its ability to capture fine-grained, localized correspondences. More recent works ( Zhai et al. , 2022b ) have shown that effective image-text alignment can be achieved with pre-trained self-supervised visual backbones. This makes it possible to leverage these powerful models in multi-modal settings, facilitating richer and more precise text-to-image associations that extend beyond global semantics while also reducing computational costs, since the visual encoding is already learned.
【翻译】开放词汇的图像-文本对齐已经受到了研究社区的极大兴趣和热情,这归功于其实现灵活且可扩展的多模态理解的潜力。大量工作专注于改进CLIP(Radford等,2021)的质量,该方法最初仅学习图像和文本表示之间的全局对齐。虽然CLIP展示了令人印象深刻的零样本能力,但其对全局特征的关注限制了其捕获细粒度、局部对应关系的能力。更近期的工作(Zhai等,2022b)表明,可以通过预训练的自监督视觉骨干网络实现有效的图像-文本对齐。这使得在多模态设置中利用这些强大模型成为可能,促进了超越全局语义的更丰富、更精确的文本-图像关联,同时还降低了计算成本,因为视觉编码已经学习完成。
We align a text encoder with our DINOv3 model by adopting the training strategy previously proposed in Jose et al. ( 2025 ). This approach follows the LiT training paradigm ( Zhai et al. , 2022b ), training a text representation from scratch to match images to their captions with a contrastive objective, while keeping the vision encoder frozen. To allow for some flexibility on the vision side, two transformer layers are introduced on top of the frozen visual backbone. A key enhancement of this method is the concatenation of the meanpooled patch embeddings with the output CLS token before matching to the text embeddings. This enables aligning both global and local visual features to text, leading to improved performance on dense prediction tasks without requiring additional heuristics or tricks. Furthermore, we use to the same data curation protocol as established in Jose et al. ( 2025 ) to ensure consistency and comparability.
【翻译】我们通过采用Jose等(2025)先前提出的训练策略来将文本编码器与我们的DINOv3模型对齐。这种方法遵循LiT训练范式(Zhai等,2022b),从头开始训练文本表示,使用对比目标将图像与其标题匹配,同时保持视觉编码器冻结。为了在视觉端提供一些灵活性,在冻结的视觉骨干网络之上引入了两个transformer层。该方法的一个关键增强是在与文本嵌入匹配之前,将均值池化的补丁嵌入与输出CLS标记连接起来。这使得全局和局部视觉特征都能与文本对齐,从而在密集预测任务上获得改进的性能,而不需要额外的启发式方法或技巧。此外,我们使用与Jose等(2025)中建立的相同数据整理协议,以确保一致性和可比性。
6 Results
In this section, we evaluate our flagship DINOv3 7B model on a variety of computer vision tasks. Throughout our experiments, unless otherwise specified, we keep DINOv3 frozen and solely use its representations. We demonstrate that with DINOv3, finetuning is not necessary to obtain strong performance. This section is organized as follows. We first probe the quality of DINOv3’s dense ( Sec. 6.1 ) and global ( Sec. 6.2 ) image representations using lightweight evaluation protocols and compare it to the strongest available vision encoders. We show that DINOv3 learns exceptional dense features while offering robust and versatile global image representations. Then, we consider DINOv3 as a basis for developing more complex computer vision systems ( Sec. 6.3 ). We show with little effort on top of DINOv3, we are able to achieve results competitive with or exceeding the state of the art in tasks as diverse as object detection, semantic segmentation, 3D view estimation, or relative monocular depth estimation.
【翻译】在本节中,我们在各种计算机视觉任务上评估我们的旗舰DINOv3 7B模型。在我们的实验中,除非另有说明,我们保持DINOv3冻结并仅使用其表示。我们证明了使用DINOv3,微调不是获得强性能的必要条件。本节组织如下。我们首先使用轻量级评估协议探索DINOv3的密集(第6.1节)和全局(第6.2节)图像表示的质量,并将其与最强的可用视觉编码器进行比较。我们展示了DINOv3学习到了卓越的密集特征,同时提供了鲁棒且多功能的全局图像表示。然后,我们将DINOv3视为开发更复杂计算机视觉系统的基础(第6.3节)。我们展示了在DINOv3基础上付出很少努力,我们能够在目标检测、语义分割、3D视图估计或相对单目深度估计等多样化任务上实现与最先进技术竞争或超越的结果。
6.1 DINOv3提供卓越的密集特征
We first investigate the raw quality of DINOv3’s dense representations using a diverse set of lightweight evaluations. In all cases, we utilize the frozen patch features of the last layer, and evaluate them using (1) qualitative visualizations ( Sec. 6.1.1 ), (2) dense linear probing ( Sec. 6.1.2 : segmentation, depth estimation), (3) non-parametric approaches ( Sec. 6.1.3 : 3D correspondence estimation, Sec. 6.1.4 : object discovery, Sec. 6.1.5 : tracking), and (4) lightweight attentive probing ( Sec. 6.1.6 : video classification).
【翻译】我们首先使用一组多样的轻量级评估来调查DINOv3密集表示的原始质量。在所有情况下,我们利用最后一层的冻结patch特征,并使用以下方法评估它们:(1) 定性可视化(第6.1.1节),(2) 密集线性探测(第6.1.2节:分割、深度估计),(3) 非参数方法(第6.1.3节:3D对应估计,第6.1.4节:对象发现,第6.1.5节:跟踪),以及(4) 轻量级注意力探测(第6.1.6节:视频分类)。
Baselines We compare the dense features of DINOv3 with those of the strongest publicly available image encoders, both weakly- and self-supervised ones. We consider the weakly-supervised encoders Perception Encoder (PE) Core ( Bolya et al. , 2025 ) and SigLIP 2 ( Tschannen et al. , 2025 ), which use CLIP-style imagetext contrastive learning. We also compare to the strongest self-supervised methods: DINOv3’s predecessor DINOv2 ( Oquab et al. , 2024 ) with registers ( Darcet et al. , 2024 ), Web-DINO ( Fan et al. , 2025 ), a recent scaling effort of DINO, and Franca ( Venkataramanan et al. , 2025 ), the best open-data SSL model. Finally, we compare to the agglomerative models AM-RADIOv2.5 ( Heinrich et al. , 2025 ), distilled from DINOv2, CLIP ( Radford et al. , 2021 ), DFN ( Fang et al. , 2024a ), and Segment Anything (SAM) ( Kirillov et al. , 2023 ), and to PEspatial, distilling SAM 2 ( Ravi et al. , 2025 ) into PEcore. For each baseline, we report the performance of the strongest model available and specify the architecture in the tables.
【翻译】基线方法 我们将DINOv3的密集特征与最强的公开可用图像编码器的特征进行比较,包括弱监督和自监督方法。我们考虑弱监督编码器Perception Encoder (PE) Core (Bolya等,2025) 和SigLIP 2 (Tschannen等,2025),它们使用CLIP风格的图像-文本对比学习。我们还与最强的自监督方法进行比较:DINOv3的前身DINOv2 (Oquab等,2024) 带有寄存器 (Darcet等,2024),Web-DINO (Fan等,2025),DINO的最新扩展尝试,以及Franca (Venkataramanan等,2025),最佳的开放数据SSL模型。最后,我们与聚合模型AM-RADIOv2.5 (Heinrich等,2025) 进行比较,该模型从DINOv2、CLIP (Radford等,2021)、DFN (Fang等,2024a) 和Segment Anything (SAM) (Kirillov等,2023) 蒸馏而来,以及PEspatial,将SAM 2 (Ravi等,2025) 蒸馏到PEcore中。对于每个基线,我们报告可用的最强模型的性能,并在表格中指定架构。
6.1.1 定性分析
We start by analyzing DINOv3’s dense feature maps qualitatively. To this end, we project the dense feature space into 3 dimensions using principal component analysis (PCA), and map the resulting 3D space into RGB. Because of the sign ambiguity in PCA (eight variants) and the arbitrary mapping between principal components and colors (six variants), we explore all combinations and report the visually most compelling one. The resulting visualization is shown in Fig. 13 . Compared to other vision backbones, it can be seen that the features of DINOv3 are sharper, containing much less noise, and showing superior semantical coherence.
【翻译】我们首先定性分析DINOv3的密集特征图。为此,我们使用主成分分析(PCA)将密集特征空间投影到3维,并将得到的3D空间映射到RGB。由于PCA中的符号模糊性(八种变体)和主成分与颜色之间的任意映射(六种变体),我们探索了所有组合并报告了视觉上最引人注目的一种。结果可视化如图13所示。与其他视觉骨干网络相比,可以看出DINOv3的特征更加清晰,包含的噪声更少,并显示出卓越的语义一致性。
Figure 13: Comparison of dense features. We compare several vision backbones by projecting their dense outputs using PCA and mapping them to RGB. From left to right: SigLIP 2 ViT-g/16, PEspatial ViT-G/14, models using patch 16 and 1120 DINOv2 ViT-g/14 with registers, DINOv3 ViT-7B/16. Images are forwarded at resolution 1280×960 for models using patch 16 and 1120×840 for patch 14, i.e. all feature maps have size 80×60.

【翻译】图13:密集特征比较。我们通过使用PCA投影其密集输出并将其映射到RGB来比较几个视觉骨干网络。从左到右:SigLIP 2 ViT-g/16,PEspatial ViT-G/14,使用patch 16和1120的模型,带寄存器的DINOv2 ViT-g/14,DINOv3 ViT-7B/16。对于使用patch 16的模型,图像以1280×960分辨率前向传播,对于patch 14的模型为1120×840,即所有特征图的大小为80×60。
6.1.2 密集线性探测
We perform linear probing on top of the dense features for two tasks: semantic segmentation and monocular depth estimation. In both cases, we train a linear transform on top of the frozen patch outputs of DINOv3. For semantic segmentation, we evaluate on the ADE20k ( Zhou et al. , 2017 ), Cityscapes ( Cordts et al. , 2016 ), and PASCAL VOC 2012 ( Everingham et al. , 2012 ) datasets and report the mean intersection-over-union (mIoU) metric. For depth estimation, we use the NYUv2 ( Silberman et al. , 2012 ) and KITTI ( Geiger et al. , 2013 ) datasets and report the root mean squared error (RMSE).
【翻译】我们在密集特征之上对两个任务进行线性探测:语义分割和单目深度估计。在这两种情况下,我们在DINOv3的冻结patch输出之上训练线性变换。对于语义分割,我们在ADE20k (Zhou等,2017)、Cityscapes (Cordts等,2016) 和PASCAL VOC 2012 (Everingham等,2012) 数据集上进行评估,并报告平均交并比(mIoU)指标。对于深度估计,我们使用NYUv2 (Silberman等,2012) 和KITTI (Geiger等,2013) 数据集,并报告均方根误差(RMSE)。
Table 3: Dense linear probing results on semantic segmentation and monocular depth estimation with frozen backbones. We report the mean Intersection-over-Union (mIoU) metric for the segmentation benchmarks ADE20k, Cityscapes, and VOC. We report the Root Mean Squared Error (RMSE) metric for the depth estimation benchmarks NYUv2 and KITTI.
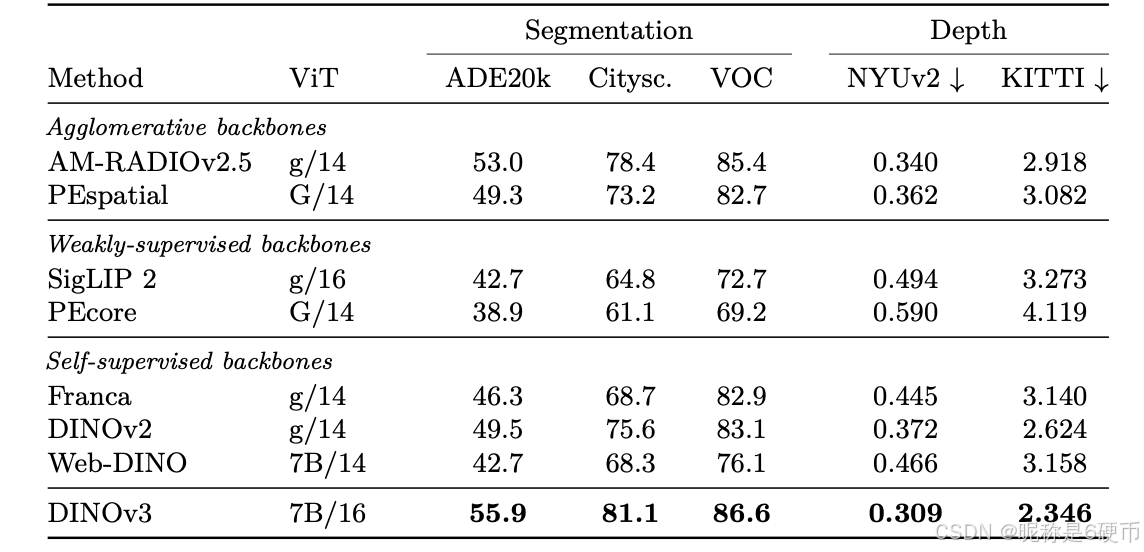
【翻译】表3:使用冻结骨干网络在语义分割和单目深度估计上的密集线性探测结果。我们报告分割基准ADE20k、Cityscapes和VOC的平均交并比(mIoU)指标。我们报告深度估计基准NYUv2和KITTI的均方根误差(RMSE)指标。
Results ( Tab. 3 ) The segmentation results demonstrate the superior quality of our dense features. On the general ADE20k dataset, DINOv3 outperforms the self-supervised baselines by more than 6 mIoU points, and the weakly supervised baselines by more than 13 points. Furthermore, DINOv3 surpasses PEspatial by more than 6 points, and AM-RADIOv2.5 by nearly 3 points. These results are remarkable as both are strong baselines, being distilled from the heavily supervised segmentation model SAM ( Kirillov et al. , 2023 ). Similar results are observed on the self-driving benchmark Cityscapes, with DINOv3 surpassing DINOv2 by more than 4 mIoU points and outperforming all other approaches. VOC has a particularly challenging evaluation protocol, as it uses the reduced-size validation set with only 1.4k images for training a linear classifier. Despite this constraint, DINOv3 still obtains the best result with 79.5 mIoU, closely followed by PEspatial (78.9) and AM-RADIOv2.5 (78.6).
【翻译】结果(表3)分割结果展示了我们密集特征的卓越质量。在通用ADE20k数据集上,DINOv3超越自监督基线超过6个mIoU点,超越弱监督基线超过13个点。此外,DINOv3超越PEspatial超过6个点,超越AM-RADIOv2.5近3个点。这些结果令人瞩目,因为两者都是强基线,都是从重度监督的分割模型SAM (Kirillov等,2023) 蒸馏而来。在自动驾驶基准Cityscapes上观察到类似结果,DINOv3超越DINOv2超过4个mIoU点,并优于所有其他方法。VOC具有特别具有挑战性的评估协议,因为它使用缩减大小的验证集,仅有1.4k图像用于训练线性分类器。尽管有这个限制,DINOv3仍然获得最佳结果79.5 mIoU,PEspatial (78.9) 和AM-RADIOv2.5 (78.6) 紧随其后。
On monocular depth estimation, DINOv3 again outperforms all other models by significant margins: the weakly-supervised models PEcore and SigLIP 2 are still lagging, with DINOv2 and the more advanced models derived from SAM are the closest competitors. Interestingly, while PEspatial and AM-RADIO show strong performance on NYU, their performance is lower than DINOv2’s on KITTI. Even there, DINOv3 outperforms its predecessor DINOv2 by 0.278 RMSE.
【翻译】在单目深度估计方面,DINOv3再次以显著优势超越所有其他模型:弱监督模型PEcore和SigLIP 2仍然落后,DINOv2和从SAM衍生的更先进模型是最接近的竞争对手。有趣的是,虽然PEspatial和AM-RADIO在NYU上表现强劲,但它们在KITTI上的性能低于DINOv2。即便如此,DINOv3仍以0.278 RMSE的优势超越其前身DINOv2。
Both sets of evaluations show the outstanding representation power of the dense features of DINOv3 and reflect the visual results from Fig. 13 . With only a linear predictor, DINOv3 allows robust prediction of object categories and masks, as well as physical measurements of the scene such as relative depth. These results show that the features are not only visually sharp and properly localized, they also represent many important properties of the underlying observations in a linearly separable way. Finally, the absolute performance obtained with a linear classifier on ADE20k (55.9 mIoU) is itself impressive, as it is not far from the absolute the state-of-the-art (63.0 mIoU) on this dataset.
【翻译】这两组评估都显示了DINOv3密集特征的卓越表示能力,并反映了图13中的视觉结果。仅使用线性预测器,DINOv3就能够鲁棒地预测对象类别和掩码,以及场景的物理测量如相对深度。这些结果表明,特征不仅在视觉上清晰且定位准确,还以线性可分的方式表示了底层观察的许多重要属性。最后,在ADE20k上使用线性分类器获得的绝对性能(55.9 mIoU)本身就令人印象深刻,因为它与该数据集上的绝对最先进技术(63.0 mIoU)相差不远。
6.1.3 3D对应估计
Understanding the 3D world has always been an important goal of computer vision Image foundation models have recently fueled research in 3D understanding by offering 3D\it{3D}3D -aware features . In this section, we evaluate the multi-view consistency of DINOv3—that is, whether patch features of the same keypoint in different views of an object are similar—following the protocol defined in Probe3D ( Banani et al. , 2024 ). We distinguish between geometric and semantic correspondence estimation. The former refers to matching keypoints for the same object instance while the latter refers to matching keypoints for different instances of the same object class . We evaluate geometric correspondence on the NAVI dataset ( Jampani et al. , 2023 ) and semantic correspondence on the SPair dataset ( Min et al. , 2019 ), and measure performance with correspondence recall in both cases. Please refer to App. D.3 for more experimental details.
【翻译】理解3D世界一直是计算机视觉的重要目标。图像基础模型最近通过提供具有3D感知的特征推动了3D理解研究。在本节中,我们评估DINOv3的多视图一致性——即同一对象在不同视图中相同关键点的patch特征是否相似——遵循Probe3D (Banani等,2024) 定义的协议。我们区分几何和语义对应估计。前者指匹配同一对象实例的关键点,而后者指匹配同一对象类别的不同实例的关键点。我们在NAVI数据集 (Jampani等,2023) 上评估几何对应,在SPair数据集 (Min等,2019) 上评估语义对应,并在两种情况下都用对应召回率来衡量性能。请参阅附录D.3了解更多实验细节。
Table 4: Evaluation of 3D consistency of dense representations. We estimate 3D keypoint correspondences across views following the evaluation protocol of Probe3D ( Banani et al. , 2024 ). To measure performance, we report the correspondence recall, i.e . the percentage of correspondences falling into a specified distance.
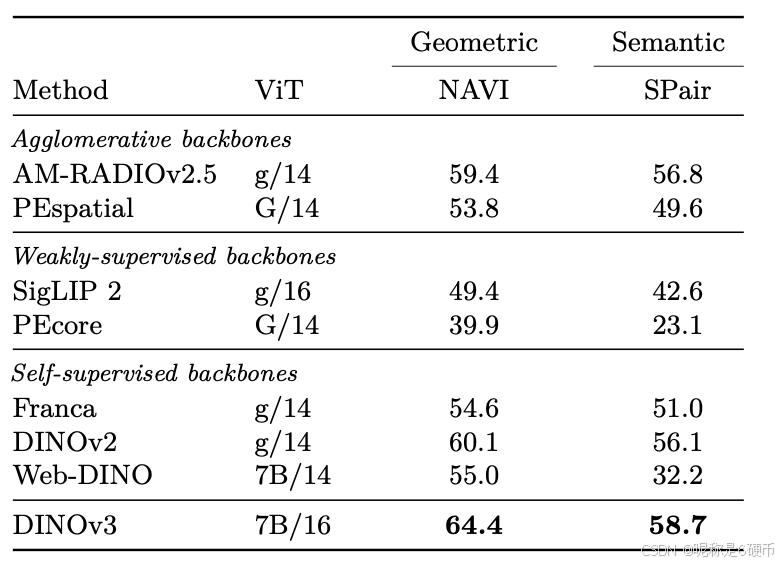
【翻译】表4:密集表示的3D一致性评估。我们遵循Probe3D (Banani等,2024) 的评估协议估计跨视图的3D关键点对应。为了衡量性能,我们报告对应召回率,即落入指定距离内的对应百分比。
Results ( Tab. 4 ) For geometric correspondences, DINOv3 outperforms all other models and improves over the second best model (DINOv2) by 4.3%4.3\%4.3% recall. Other SSL scaling endeavors (Franca and WebSSL) lag behind DINOv2, showing that it is still a strong baseline. Weakly-supervised models (PEcore and SigLIP 2) do not fare well on this task, indicating a lack of 3D awareness. For models with SAM distillation, AM-RADIO nearly reaches the performance of DINOv2, but PEspatial still lags behind it ( −11.6%-11.6\%−11.6% recall), and even falls behind Franca ( −0.8%-0.8\%−0.8% recall). This suggests that self-supervised learning is a key component for strong performance on this task. For semantic correspondences, the same conclusions apply. DINOv3 performs best, outperforming both its predecessor ( +2.6%+2.6\%+2.6% recall) and AM-RADIO (+1 . 9% recall). Overall, these impressive performance on keypoint matching are very promising signals for downstream use of DINOv3 in other 3D-heavy applications.
【翻译】结果(表4)对于几何对应,DINOv3超越所有其他模型,比第二好的模型(DINOv2)提高了4.3%的召回率。其他SSL扩展尝试(Franca和WebSSL)落后于DINOv2,表明它仍然是一个强基线。弱监督模型(PEcore和SigLIP 2)在此任务上表现不佳,表明缺乏3D感知能力。对于使用SAM蒸馏的模型,AM-RADIO几乎达到DINOv2的性能,但PEspatial仍然落后(-11.6%召回率),甚至落后于Franca(-0.8%召回率)。这表明自监督学习是此任务强性能的关键组成部分。对于语义对应,同样的结论适用。DINOv3表现最佳,超越其前身(+2.6%召回率)和AM-RADIO(+1.9%召回率)。总的来说,这些在关键点匹配上的令人印象深刻的性能是DINOv3在其他3D密集应用中下游使用的非常有希望的信号。
6.1.4 无监督对象发现
Powerful self-supervised features facilitate discovering object instances in images without requiring any annotations ( Vo et al. , 2021 ; Siméoni et al. , 2021 ; Seitzer et al. , 2023 ; Wang et al. , 2023c ; Siméoni et al. , 2025 ). We test this capability for different vision encoders via the task of unsupervised object discovery, which requires class-agnostic segmentation of objects in images ( Russell et al. , 2006 ; Tuytelaars et al. , 2010 ; Cho et al. , 2015 ; Vo et al. , 2019 ). In particular, we use the non-parametric graph-based TokenCut algorithm ( Wang et al. , 2023c ), which has shown strong performance on a variety of backbones. We run it on three widely used datasets: VOC 2007, VOC 2012 ( Everingham et al. , 2015 ), and COCO-20k ( Lin et al. , 2014 ; Vo et al. , 2020 ). We follow the evaluation protocol defined by Siméoni et al. ( 2021 ) and report the CorLoc metric. To properly compare backbones with different feature distributions, we perform a search over the main TokenCut hyperparameter, namely the cosine similarity threshold applied when constructing the patch graph used for partitioning. Originally, the best object discovery results were obtained with DINO ( Caron et al. , 2021 ) using the keys of the last attention layer. However, this hand-crafted choice does not consistently generalize to other backbones. For simplicity, we always employ the output features for all models.
【翻译】强大的自监督特征有助于在图像中发现对象实例而无需任何标注 (Vo等,2021;Siméoni等,2021;Seitzer等,2023;Wang等,2023c;Siméoni等,2025)。我们通过无监督对象发现任务测试不同视觉编码器的这种能力,该任务需要对图像中的对象进行类别无关的分割 (Russell等,2006;Tuytelaars等,2010;Cho等,2015;Vo等,2019)。特别地,我们使用非参数的基于图的TokenCut算法 (Wang等,2023c),该算法在各种骨干网络上表现出强劲性能。我们在三个广泛使用的数据集上运行:VOC 2007、VOC 2012 (Everingham等,2015) 和COCO-20k (Lin等,2014;Vo等,2020)。我们遵循Siméoni等 (2021) 定义的评估协议并报告CorLoc指标。为了适当比较具有不同特征分布的骨干网络,我们对TokenCut的主要超参数进行搜索,即在构建用于分割的patch图时应用的余弦相似度阈值。最初,使用DINO (Caron等,2021) 的最后注意力层的键获得了最佳的对象发现结果。然而,这种手工选择并不能一致地推广到其他骨干网络。为简单起见,我们始终对所有模型使用输出特征。
Results ( Fig. 14 ) The original DINO has set a very high bar for this task. Interestingly, while DINOv2 has shown very strong performance for pixel-wise dense tasks, it fails at object discovery. This can in part be attributed to the artifacts present in the dense features ( c.f . Fig. 13 ). DINOv3, with its clean and precise output feature maps outperforms both its predecessors, with a 5 . 9 CorLoc improvement on VOC 2007, and all other backbones, whether self-, weakly-supervised or agglomerative. This evaluation confirms that DINOv3’s dense features are both semantically strong and well localized. We believe that this will pave the way for more class-agnostic object detection approaches, especially in scenarios where annotations are costly or unavailable, and where the set of relevant classes is not confined to a predefined subset.
【翻译】结果(图14)原始DINO为此任务设定了很高的标准。有趣的是,虽然DINOv2在像素级密集任务上表现出非常强劲的性能,但它在对象发现方面失败了。这部分可归因于密集特征中存在的伪影(参见图13)。DINOv3凭借其清洁和精确的输出特征图超越了其前身,在VOC 2007上CorLoc提升了5.9,并超越了所有其他骨干网络,无论是自监督、弱监督还是聚合方法。这项评估证实了DINOv3的密集特征在语义上强大且定位良好。我们相信这将为更多类别无关的对象检测方法铺平道路,特别是在标注成本高昂或不可用的场景中,以及相关类别集合不局限于预定义子集的情况下。
Figure 14: Unsupervised object discovery. We apply TokenCut ( Wang et al. , 2022c ) on the output patch features of different backbones and report CorLoc metric. We also visualize predicted masks obtained with DINOv3 (red overlay on input images at res. 1024), obtained with no annotation and no post-processing .
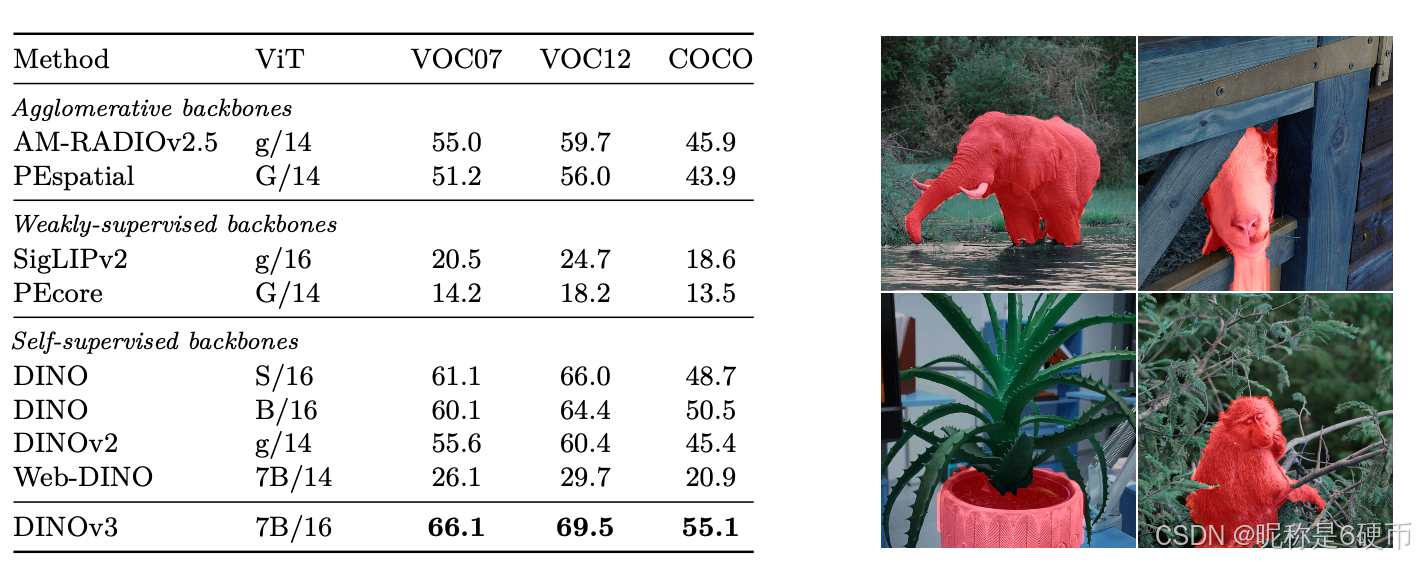
【翻译】图14:无监督对象发现。我们对不同骨干网络的输出patch特征应用TokenCut (Wang等,2022c) 并报告CorLoc指标。我们还可视化了使用DINOv3获得的预测掩码(在分辨率1024的输入图像上的红色覆盖),在没有标注和后处理的情况下获得。
6.1.5 视频分割跟踪
Beyond static images, an important property of visual representations is their temporal consistency , i.e . whether the features evolve in a stable manner through time. To test for this property, we evaluate DINOv3 on the task of video segmentation tracking: given ground-truth instance segmentation masks in the first frame of a video, the goal is to propagate these masks to subsequent frames. We use the DAVIS 2017 ( PontTuset et al. , 2017 ), YouTube-VOS ( Xu et al. , 2018 ), and MOSE ( Ding et al. , 2023 ) datasets. We evaluate performan using the standard I&F\mathcal{I}\&\mathcal{F}I&F -mean metric, which combines region similarity ( I\mathcal{I}I ) and contour accuracy ( algorithm that considers the similarity between patch features across frames. We evaluate at three input F ) ( Perazzi et al. , 2016 ). Following Jabri et al. ( 2020 ), we use a non-parametric label propagation resolutions, using a short side length of 420/480 (S), 840/960 (M), and 1260/1440 (L) pixels for models with patch size 14/16 (matching the number of patch tokens). The I&F\mathcal{I}\&\mathcal{F}I&F score is always computed at the native resolution of the videos. See App. D.5 for more detailed experimental settings.
【翻译】除了静态图像,视觉表示的一个重要属性是它们的时间一致性,即特征是否以稳定的方式随时间演化。为了测试这一属性,我们在视频分割跟踪任务上评估DINOv3:给定视频第一帧中的真值实例分割掩码,目标是将这些掩码传播到后续帧。我们使用DAVIS 2017 (PontTuset等,2017)、YouTube-VOS (Xu等,2018) 和MOSE (Ding等,2023) 数据集。我们使用标准的I&F\mathcal{I}\&\mathcal{F}I&F-mean指标评估性能,该指标结合了区域相似性 (I\mathcal{I}I) 和轮廓准确性 (F) (Perazzi等,2016)。遵循Jabri等 (2020),我们使用非参数标签传播算法,该算法考虑跨帧patch特征之间的相似性。我们在三种输入分辨率下评估,对于patch大小为14/16的模型,使用短边长度为420/480 (S)、840/960 (M) 和1260/1440 (L) 像素(匹配patch token的数量)。I&F\mathcal{I}\&\mathcal{F}I&F分数始终在视频的原始分辨率下计算。详细的实验设置请参见附录D.5。
Results ( Tab. 5 ) Aligned with all previous results, weakly-supervised backbones do not deliver convincing performance. PEspatial, distilled from the video model SAMv2, provides satisfactory performance, surpassing DINOv2 on smaller resolutions, but falling short on larger ones. Across resolutions, DINOv3 outperforms all competitors, with a staggering 83.3 I&F\mathcal{I}\&\mathcal{F}I&F on DAVIS-L, 6.7 points above DINOv2. Furthermore, performance as a function of resolution follows a healthy trend, confirming that our model is able to make use of more input pixels to output precise, high-resolution feature maps ( c.f . Figs. 3 and 4 ). In contrast, performance at higher resolutions stays almost flat for SigLIP 2 and PEcore, and degrades for PEspatial. Interestingly, our image model, without any tuning on video, allows to properly track objects in time (see Fig. 15 ). This makes it a great candidate to embed videos, allowing to build strong video models on top.
【翻译】结果(表5)与所有先前结果一致,弱监督骨干网络未能提供令人信服的性能。从视频模型SAMv2蒸馏而来的PEspatial提供了令人满意的性能,在较小分辨率上超越DINOv2,但在较大分辨率上表现不足。在各种分辨率下,DINOv3都超越所有竞争对手,在DAVIS-L上达到惊人的83.3 I&F\mathcal{I}\&\mathcal{F}I&F,比DINOv2高6.7个点。此外,性能随分辨率的变化遵循健康趋势,证实我们的模型能够利用更多输入像素来输出精确的高分辨率特征图(参见图3和4)。相比之下,SigLIP 2和PEcore在更高分辨率下的性能几乎保持平稳,而PEspatial的性能则有所下降。有趣的是,我们的图像模型无需任何视频调优就能正确地在时间上跟踪对象(见图15)。这使其成为视频嵌入的绝佳候选,允许在其基础上构建强大的视频模型。
6.1.6 视频分类
The previous results have shown the low-level temporal consistency of DINOv3’s representations, allowing to accurately track objects in time. Going beyond, we evaluate in this section the suitability of its dense features for high-level video classification. Similar to the setup of V-JEPA 2 ( Assran et al. , 2025 ), we train an attentive probe —a shallow 4-layer transformer-based classifier—on top of patch features extracted from each frame. This enables reasoning over temporal and spatial dimensions as the features are extracted independently per frame. During evaluation, we either take a single clip per video, or use test-time augmentation (TTA) by averaging the predictions of 3 spatial and 2 temporal crops per video. See App. D.6 for experimental details. We run this evaluation on three datasets: UCF101 ( Soomro et al. , 2012 ), Something-Something V2 ( Goyal et al. , 2017 ), and Kinetics-400 ( Kay et al. , 2017 ), and report top-1 accuracy. As an additional baseline, we report the performance of V-JEPA v2, a state-of-the-art SSL model for video understanding.
【翻译】先前的结果已显示了DINOv3表示的低级时间一致性,能够准确地在时间上跟踪对象。更进一步,我们在本节中评估其密集特征对高级视频分类的适用性。类似于V-JEPA 2 (Assran等,2025) 的设置,我们在从每帧提取的patch特征基础上训练一个注意力探针——一个浅层4层transformer分类器。这使得能够在时间和空间维度上进行推理,因为特征是按帧独立提取的。在评估期间,我们要么对每个视频取单个片段,要么通过平均每个视频3个空间和2个时间裁剪的预测来使用测试时增强(TTA)。实验细节见附录D.6。我们在三个数据集上运行此评估:UCF101 (Soomro等,2012)、Something-Something V2 (Goyal等,2017) 和Kinetics-400 (Kay等,2017),并报告top-1准确率。作为额外基线,我们报告V-JEPA v2的性能,这是视频理解的最先进SSL模型。
Table 5: Video segmentation tracking evaluation. We report the I&F\mathcal{I}\&\mathcal{F}I&F -mean on DAVIS, YouTube-VOS, and MOSE at multiple resolutions. For models with patch size 14/16, the small, medium and large resolutions correspond to a video short side of 420/480, 840/960, 1260/1140 pixels.
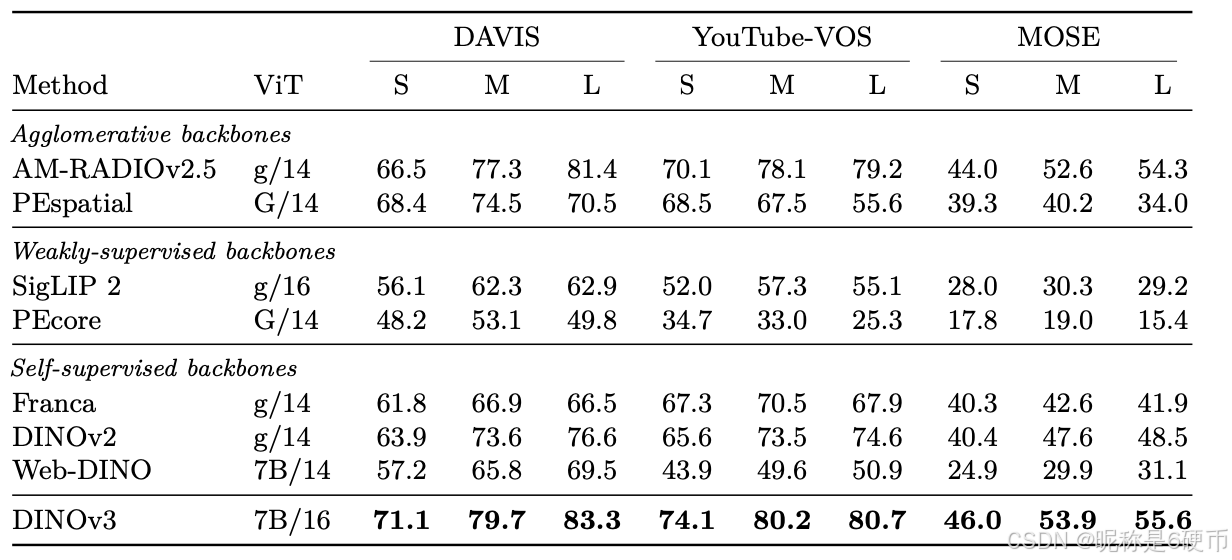
【翻译】表5:视频分割跟踪评估。我们报告在多种分辨率下DAVIS、YouTube-VOS和MOSE上的I&F\mathcal{I}\&\mathcal{F}I&F-mean。对于patch大小为14/16的模型,小、中、大分辨率分别对应视频短边420/480、840/960、1260/1140像素。
Figure 15: Segmentation tracking example. Given the ground-truth instance segmentation masks for the initial frame, we propagate the instance labels to subsequent frames according to patch similarity in the feature space of DINOv3. The input resolution is 2048 ×\times× 1536 pixels, resulting in 128 × 96 patches.
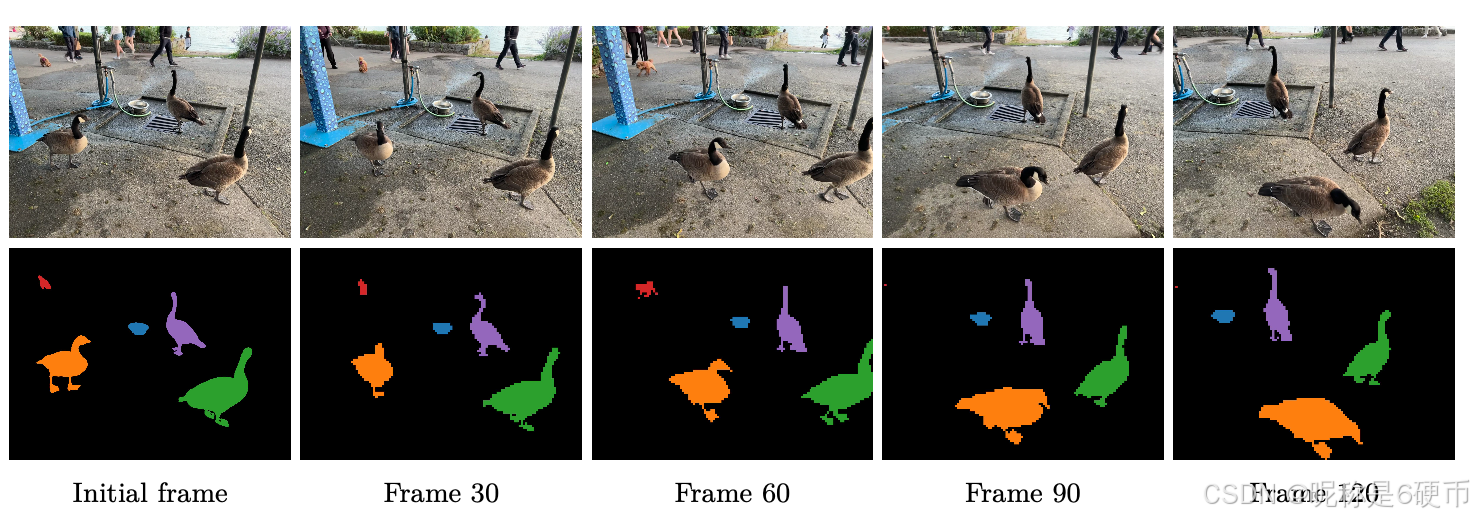
【翻译】图15:分割跟踪示例。给定初始帧的真值实例分割掩码,我们根据DINOv3特征空间中的patch相似性将实例标签传播到后续帧。输入分辨率为2048 × 1536像素,产生128 × 96个patches。
Results ( Tab. 6 ) In line with the conclusion of the previous experiment, we find that DINOv3 can be successfully used for extracting strong video features. As this evaluation involves training several layers of self-attention, the differences between models are less visible. However, DINOv3 lands in the same range as PEcore and SigLIP 2, and clearly outperforms other models (DINOv2, AM-RADIO) across datasets. UCF101 and K400 are appearance-focused, where strong category-level understanding of objects gives most of the performance. SSv2 on the other hand, requires better understanding of motion—the dedicated video model V-JEPA v2 shines on this dataset. Interestingly, the gap between DINOv3 and the weakly-supervised models is slightly bigger on this dataset. This again confirms the suitability of DINOv3 to video tasks.
【翻译】结果(表6)与先前实验的结论一致,我们发现DINOv3可以成功用于提取强大的视频特征。由于此评估涉及训练多层自注意力,模型之间的差异不太明显。然而,DINOv3与PEcore和SigLIP 2处于同一范围,并在各数据集上明显优于其他模型(DINOv2、AM-RADIO)。UCF101和K400侧重于外观,其中对对象的强大类别级理解提供了大部分性能。另一方面,SSv2需要更好地理解运动——专用视频模型V-JEPA v2在此数据集上表现出色。有趣的是,DINOv3与弱监督模型之间的差距在此数据集上略大。这再次证实了DINOv3对视频任务的适用性。
Table 6: Video classification evaluation using attentive probes. We report top-1 accuracy on UCF101, Something-Something V2 (SSv2), and Kinetics-400 (K400). For each model, we report performance for evaluating a single clip per video, or applying test-time augmentation (TTA) by averaging the predicted probabilities from multiple clips.
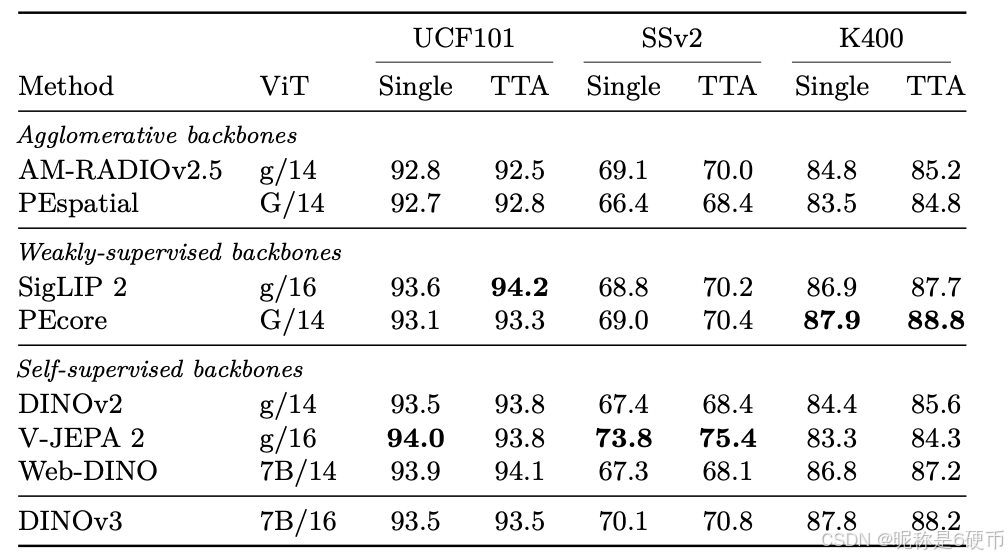
【翻译】表6:使用注意力探针的视频分类评估。我们报告UCF101、Something-Something V2 (SSv2) 和Kinetics-400 (K400) 上的top-1准确率。对于每个模型,我们报告评估每个视频单个片段的性能,或通过平均多个片段的预测概率应用测试时增强(TTA)的性能。
6.2 DINOv3具有鲁棒且多功能的全局图像描述符
In this section, we evaluate DINOv3’s ability to capture global image statistics. To this end, we consider classic classification benchmarks using linear probes ( Sec. 6.2.1 ) and instance retrieval benchmarks ( Sec. 6.2.2 ). Again, we compare to the strongest publicly available image encoders. In addition to the models from the previous section, we evaluate the two weakly supervised models AIMv2 ( Fini et al. , 2024 ), trained using joint auto-regressive pixel and text prediction, and the massive EVA-CLIP-18B ( Sun et al. , 2024 ).
【翻译】在本节中,我们评估DINOv3捕获全局图像统计信息的能力。为此,我们考虑使用线性探针的经典分类基准(第6.2.1节)和实例检索基准(第6.2.2节)。同样,我们与最强的公开可用图像编码器进行比较。除了前一节的模型之外,我们还评估两个弱监督模型AIMv2(Fini等,2024),该模型使用联合自回归像素和文本预测进行训练,以及大规模的EVA-CLIP-18B(Sun等,2024)。
6.2.1 使用线性探针的图像分类
We train a linear classifier on top of DINOv3’s output CLS token to evaluate the model on classification benchmarks. We consider the ImageNet1k ( Deng et al. , 2009 ) dataset and its variants to evaluate out-ofdistribution robustness, and a suite of datasets from different domains to understand DINOv3’s ability to distinguish fine-grained classes. See App. D.7 for evaluation details.
【翻译】我们在DINOv3输出的CLS token基础上训练线性分类器,以在分类基准上评估模型。我们考虑ImageNet1k (Deng等,2009) 数据集及其变体来评估分布外鲁棒性,以及来自不同领域的一系列数据集来理解DINOv3区分细粒度类别的能力。评估细节见附录D.7。
Domain Generalization from ImageNet ( Tab. 7 ) In this experiment, we train on ImageNettrain , use ImageNetval as a validation set to select hyperparameters, and transfer the best found classifier to different test datasets: ImageNetV2 ( Recht et al. , 2019 ) and ReaL ( Beyer et al. , 2020 ) are alternative sets of images and labels for ImageNet, used to test overfitting on the ImageNet validation set; R endition ( Hendrycks et al. , 2021a ) and S ketch ( Wang et al. , 2019 ) show stylized and artificial versions of the ImageNet classes; A dversarial ( Hendrycks et al. , 2021b ) and Obj ectNet ( Barbu et al. , 2019 ) contain deliberately-chosen difficult examples; C orruptions ( Hendrycks and Dietterich , 2019 ) measures robustness to common image corruptions. For reference, we also list linear probing results from Dehghani et al. ( 2023 ) for ViTs trained using supervised classification on the massive JFT dataset (3B–4B images). Note that these results follow a slightly different evaluation protocol and are not directly comparable to our results.
【翻译】来自ImageNet的域泛化(表7)在此实验中,我们在ImageNet训练集上训练,使用ImageNet验证集作为验证集来选择超参数,并将找到的最佳分类器转移到不同的测试数据集:ImageNetV2 (Recht等,2019) 和ReaL (Beyer等,2020) 是ImageNet的替代图像和标签集,用于测试在ImageNet验证集上的过拟合;Rendition (Hendrycks等,2021a) 和Sketch (Wang等,2019) 展示ImageNet类别的风格化和人工版本;Adversarial (Hendrycks等,2021b) 和ObjectNet (Barbu等,2019) 包含故意选择的困难样本;Corruptions (Hendrycks和Dietterich,2019) 衡量对常见图像损坏的鲁棒性。作为参考,我们还列出了Dehghani等 (2023) 对在大规模JFT数据集(30亿-40亿图像)上使用监督分类训练的ViT的线性探测结果。请注意,这些结果遵循略有不同的评估协议,与我们的结果不能直接比较。
DINOv3 significantly surpasses all previous self-supervised backbones, with gains of +10%+10\%+10% on ImageNet-R, +6%+6\%+6% on -Sketch, +13%+13\%+13% on ObjectNet over the previously strongest SSL model DINOv2. We note that the strongest weakly-supervised models, SigLIP 2 and PE, are now better than the strongest supervised ones (ViT-22B) on hard OOD tasks like ImageNet-A and ObjectNet. DINOv3 reaches comparable results on ImageNet-R and -Sketch, and, on the hard tasks ImageNet-A and ObjectNet, is closely behind PE, while exceeding SigLIPv2. On ImageNet, while validation scores are 0.7–0.9 points behind SigLIPv2 and PE, the performance on the “cleaner” test sets -V2 and -ReaL is virtually the same. Notably, DINOv3 achieves the best robustness to corruptions (ImageNet-C). All in all, this is the first time that a SSL model has reached comparable results to weakly- and supervised models on image classification —a domain which used to be the strong point of (weakly-)supervised training approaches. This is a remarkable result, given that models like ViT-22B, SigLIP 2, and PE are trained using massive human-annotated datasets. In contrast, DINOv3 learns purely from images, which makes it feasible to further scale/improve the approach in the future.
【翻译】DINOv3显著超越所有先前的自监督骨干网络,在ImageNet-R上获得+10%的提升,在Sketch上获得+6%的提升,在ObjectNet上比之前最强的SSL模型DINOv2获得+13%的提升。我们注意到最强的弱监督模型SigLIP 2和PE现在在ImageNet-A和ObjectNet等困难的OOD任务上比最强的监督模型(ViT-22B)表现更好。DINOv3在ImageNet-R和Sketch上达到了可比的结果,在困难任务ImageNet-A和ObjectNet上紧随PE,同时超越SigLIPv2。在ImageNet上,虽然验证分数比SigLIPv2和PE低0.7-0.9个点,但在"更干净"的测试集V2和ReaL上的性能几乎相同。值得注意的是,DINOv3在损坏鲁棒性(ImageNet-C)方面取得了最佳结果。总而言之,这是SSL模型首次在图像分类上达到与弱监督和监督模型可比的结果——这个领域曾经是(弱)监督训练方法的强项。考虑到ViT-22B、SigLIP 2和PE等模型使用大规模人工标注数据集进行训练,这是一个令人瞩目的结果。相比之下,DINOv3纯粹从图像中学习,这使得未来进一步扩展/改进该方法成为可能。
Table 7: Classification accuracy of linear probes trained on ImageNet1k with frozen backbones. Weaklyand self-supervised models are evaluated with image resolution adapted to 1024 patch tokens ( i.e . 448×448448\times448448×448 for patch size 14, 512×512512\times512512×512 for patch size 16). For reference, we also list results from Dehghani et al. ( 2023 ) using a different evaluation protocol (marked with ∗ ).
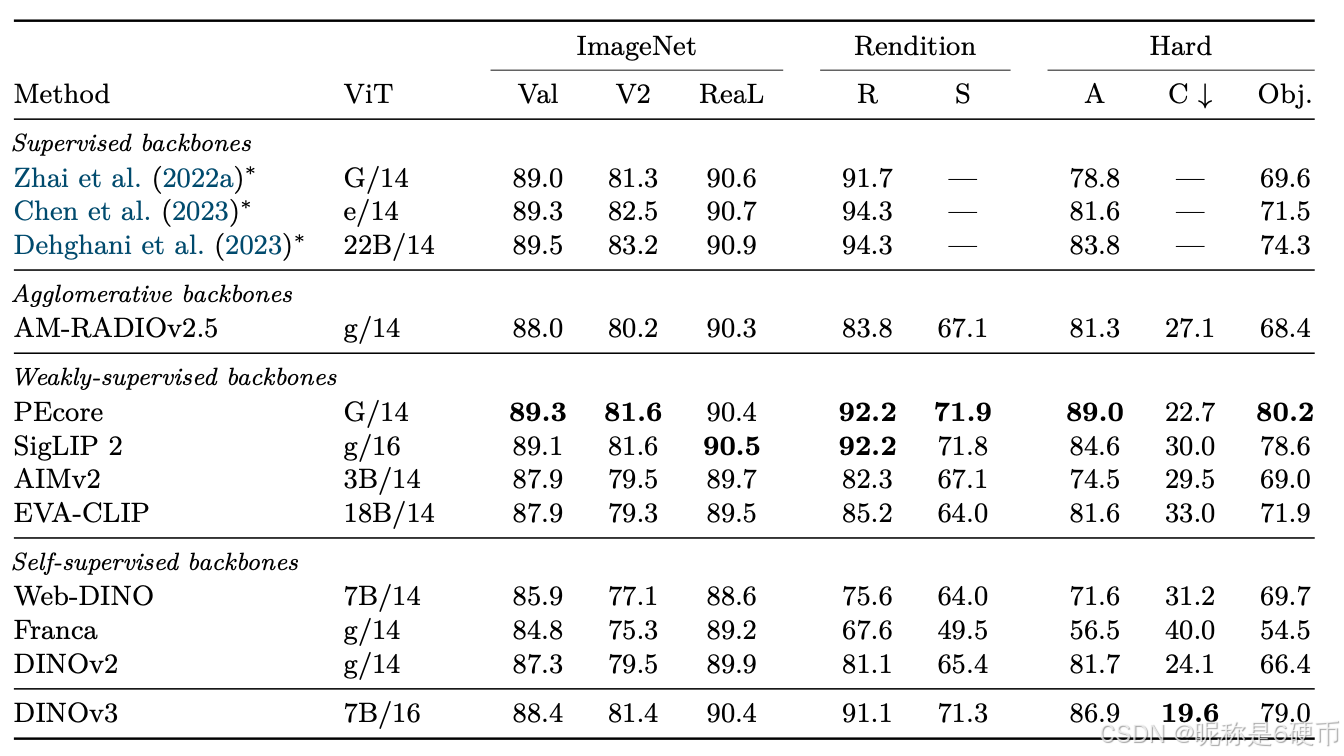
【翻译】表7:在ImageNet1k上使用冻结骨干网络训练的线性探针的分类准确率。弱监督和自监督模型使用适应1024个patch token的图像分辨率进行评估(即patch大小为14时为448×448448\times448448×448,patch大小为16时为512×512512\times512512×512)。作为参考,我们还列出了Dehghani等(2023)使用不同评估协议的结果(标记为∗)。
Table 8: Finegrained classification benchmarks. Fine-S averages over 12 datasets, see Tab. 22 for full results.
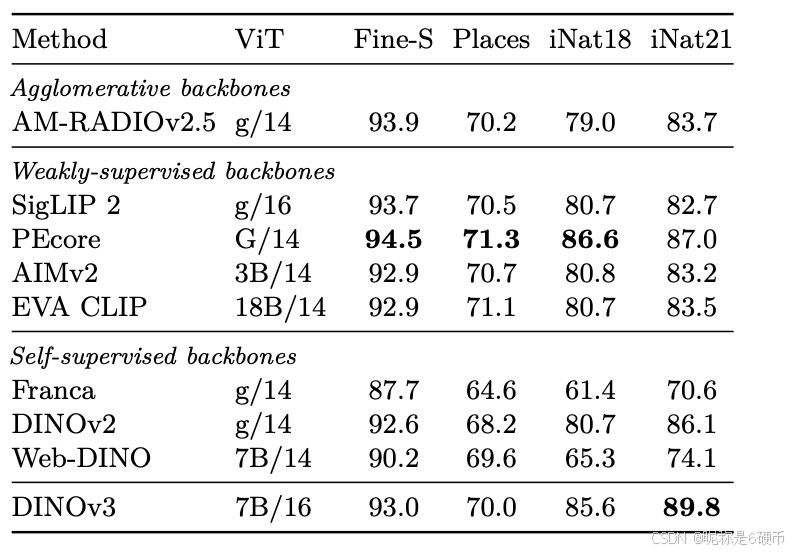
【翻译】表8:细粒度分类基准。Fine-S是12个数据集的平均值,完整结果见表22。
Table 9: Instance recognition benchmarks. See Tab. 23 for additional metrics.
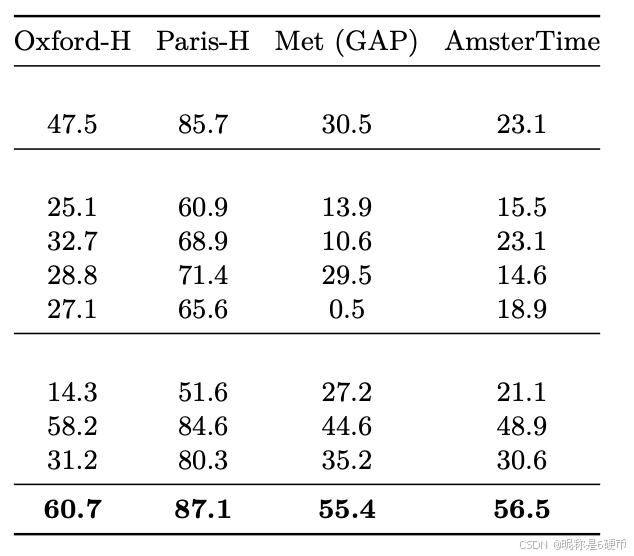
【翻译】表9:实例识别基准。更多指标见表23。
Finegrained Classification ( Tab. 8 ) We also measure DINOv3’s performance when training linear probes on several datasets for fine-grained classification. In particular, we report the accuracy on 3 large datasets, namely Places205 ( Zhou et al. , 2014 ) for scene recognition, and iNaturalist 2018 ( Van Horn et al. , 2018 ) and iNaturalist 2021 ( Van Horn et al. , 2021 )) for detailed plant and animal-species recognition, as well as the average over 12 smaller datasets covering scenes, objects, and textures (as in Oquab et al. ( 2024 ), here termed Fine-S). See also Tab. 22 for individual results on those datasets.
【翻译】细粒度分类(表8)我们还测量了DINOv3在多个细粒度分类数据集上训练线性探针时的性能。特别地,我们报告了3个大型数据集的准确率,即用于场景识别的Places205(Zhou等,2014),以及用于详细植物和动物物种识别的iNaturalist 2018(Van Horn等,2018)和iNaturalist 2021(Van Horn等,2021),以及涵盖场景、对象和纹理的12个较小数据集的平均值(如Oquab等(2024)所述,这里称为Fine-S)。这些数据集的单独结果也见表22。
We find that, again, DINOv3 surpasses all previous SSL methods. It also shows competitive results compared to the weakly-supervised methods, indicating its robustness and generalization capability across diverse finegrained classification tasks. Notably, DINOv3 attains the highest accuracy on the difficult iNaturalist21 dataset at 89.8%89.8\%89.8% , outperforming even the best weakly-supervised model PEcore with 87.0%87.0\%87.0% .
【翻译】我们发现,DINOv3再次超越了所有先前的SSL方法。与弱监督方法相比,它也显示出竞争性的结果,表明其在各种细粒度分类任务中的鲁棒性和泛化能力。值得注意的是,DINOv3在困难的iNaturalist21数据集上达到了最高准确率89.8%,甚至超越了最佳弱监督模型PEcore的87.0%。
6.2.2 实例识别
To evaluate the instance-level recognition capabilities of our model, we adopted a non-parametric retrieval approach. Here, database images are ranked by their cosine similarity to a given query image, using the output CLS token. We benchmark performance across several datasets: the Oxford and Paris datasets for landmark recognition ( Radenović et al. , 2018 ), the Met dataset featuring artworks from the Metropolitan Museum ( Ypsilantis et al. , 2021 ), and AmsterTime, which consists of modern street view images matched to historical archival images of Amsterdam ( Yildiz et al. , 2022 ). Retrieval effectiveness is quantified using mean average precision for Oxford, Paris, and AmsterTime, and global average precision for Met. See App. D.8 for more evaluation details.
【翻译】为了评估我们模型的实例级识别能力,我们采用了非参数检索方法。在这里,数据库图像根据与给定查询图像的余弦相似度进行排序,使用输出的CLS token。我们在多个数据集上进行性能基准测试:用于地标识别的Oxford和Paris数据集(Radenović等,2018),来自大都会博物馆的艺术品Met数据集(Ypsilantis等,2021),以及AmsterTime,它由与阿姆斯特丹历史档案图像匹配的现代街景图像组成(Yildiz等,2022)。检索效果使用Oxford、Paris和AmsterTime的平均精度均值以及Met的全局平均精度进行量化。更多评估细节见附录D.8。
Results ( Tabs. 9 and 23 ) Across all evaluated benchmarks, DINOv3 achieves the strongest performance by large margins, e.g . improving over the second best model DINOv2 by +10.8+10.8+10.8 points on Met and +7.6 points on AmsterTime. On this benchmark, weakly-supervised models are lagging far behind DINOv3, with the exception of AM-RADIO, which is distilled from DINOv2 features. These findings highlight the robustness and versatility of DINOv3 for instance-level retrieval tasks, spanning both traditional landmark datasets and more challenging domains such as art and historical image retrieval.
【翻译】结果(表9和23)在所有评估的基准测试中,DINOv3都以很大的优势取得了最强的性能,例如在Met上比第二好的模型DINOv2提高了+10.8个点,在AmsterTime上提高了+7.6个点。在这个基准测试中,弱监督模型远远落后于DINOv3,除了AM-RADIO,它是从DINOv2特征中蒸馏出来的。这些发现突出了DINOv3在实例级检索任务中的鲁棒性和多功能性,涵盖了传统地标数据集和更具挑战性的领域,如艺术和历史图像检索。
6.3 DINOv3是复杂计算机视觉系统的基础
The previous two sections already provided solid signal for the quality of DINOv3 in both dense and global tasks. However, these results were obtained under “model probing” experimental protocols, using lightweight linear adapters or even non-parametric algorithms to assess the quality of features. While such simple evaluations allowed to remove confounding factors from involved experimental protocols, they are not enough to evaluate the full potential of DINOv3 as a foundational component in a larger computer vision system. Thus, in this section, we depart from the lightweight protocols, and instead train more involved downstream decoders and consider stronger, task-specific baselines. In particular, we use DINOv3 as a basis for (1) object detection with Plain-DETR ( Sec. 6.3.1 ), (2) semantic segmentation with Mask2Former ( Sec. 6.3.2 ), (3) monocular depth estimation with Depth Anything ( Sec. 6.3.3 ), and (4) 3D understanding with the Visual Geometry Grounded Transformer ( Sec. 6.3.4 ). These tasks are only intended as explorations for what is possible with DINOv3. Still, we find that building on DINOv3 unlocks competitive or even state-of-the-art results with little effort.
【翻译】前面的两个章节已经为DINOv3在密集和全局任务中的质量提供了有力信号。然而,这些结果是在"模型探测"实验协议下获得的,使用轻量级线性适配器甚至非参数算法来评估特征质量。虽然这样的简单评估允许从复杂的实验协议中移除混淆因子,但它们不足以评估DINOv3作为更大计算机视觉系统中基础组件的全部潜力。因此,在本节中,我们偏离轻量级协议,转而训练更复杂的下游解码器,并考虑更强的任务特定基线。特别地,我们将DINOv3用作以下任务的基础:(1) 使用Plain-DETR的目标检测(第6.3.1节),(2) 使用Mask2Former的语义分割(第6.3.2节),(3) 使用Depth Anything的单目深度估计(第6.3.3节),以及(4) 使用Visual Geometry Grounded Transformer的3D理解(第6.3.4节)。这些任务仅旨在探索DINOv3的可能性。尽管如此,我们发现基于DINOv3构建能够以很少的努力解锁竞争性甚至最先进的结果。
6.3.1 目标检测
As a first task, we tackle the long-standing computer vision problem of object detection. Given an image, the goal is to provide bounding boxes for all instances of objects of pre-defined categories. This task requires both precise localization and good recognition, as boxes need to match the object boundaries and correspond to the correct category. While performance on standard benchmarks like COCO ( Lin et al. , 2014 ) is mostly saturated, we propose to tackle this task with a frozen backbone, only training a small decoder on top.
【翻译】作为第一个任务,我们解决目标检测这一长期存在的计算机视觉问题。给定一张图像,目标是为预定义类别的所有对象实例提供边界框。这个任务需要精确的定位和良好的识别,因为边界框需要匹配对象边界并对应正确的类别。虽然在COCO(Lin等,2014)等标准基准测试上的性能大多已经饱和,我们提出使用冻结的骨干网络来解决这个任务,只在顶部训练一个小型解码器。
Datasets and Metrics We evaluate DINOv3 on object detection capabilities with the COCO dataset ( Lin et al. , 2014 ), reporting results on the COCO-VAL2017 split. Additionally, we evaluate out-of-distribution performance on the COCO-O evaluation dataset ( Mao et al. , 2023 ). This dataset contains the same classes but provides input images under six distribution shift settings. For both datasets, we report mean Average Precision (mAP) with IoU thresholds in [0 . 5 : 0 . 05 : 0 . 95]. For COCO-O, we additionally report the effective robustness (ER). Since COCO is a small dataset, comprising only 118k training images, we leverage the larger Objects365 dataset ( Shao et al. , 2019 ) for pre-training the decoder, as is common practice.
【翻译】数据集和指标 我们使用COCO数据集(Lin等,2014)评估DINOv3的目标检测能力,报告COCO-VAL2017分割上的结果。此外,我们在COCO-O评估数据集(Mao等,2023)上评估分布外性能。该数据集包含相同的类别,但在六种分布偏移设置下提供输入图像。对于两个数据集,我们报告IoU阈值在[0.5 : 0.05 : 0.95]范围内的平均精度均值(mAP)。对于COCO-O,我们还报告有效鲁棒性(ER)。由于COCO是一个小数据集,只包含118k训练图像,我们利用更大的Objects365数据集(Shao等,2019)来预训练解码器,这是常见做法。
Table 10: Comparison with state-of-the-art systems on object detection. We train a detection adapter on top of a frozen DINOv3 backbone. We show results on the validation set of the COCO and COCO-O datasets, and report the mAP across IoU thresholds, as well as the effective robustness (ER). Our detection system based on DINOv3 sets a new state of the art. As the InternImage-G detection model has not been released, we were unable to reproduce their results or compute COCO-O scores.
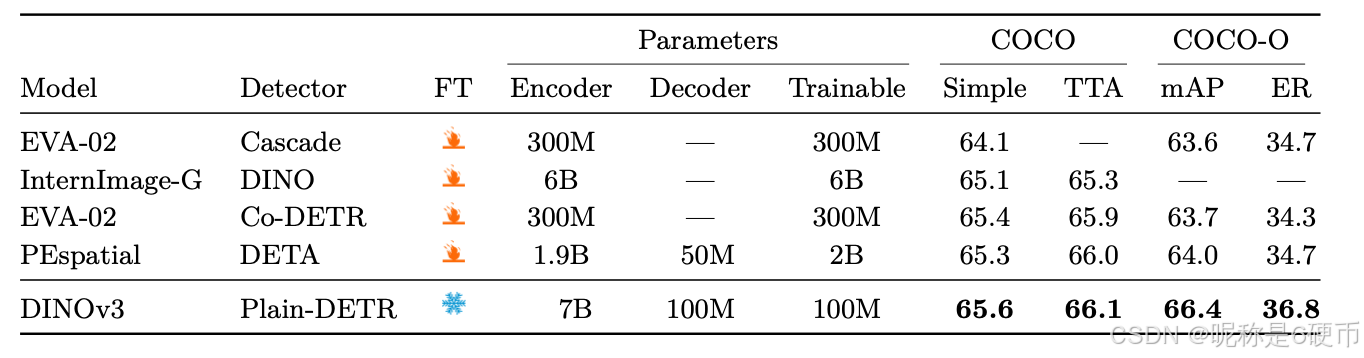
【翻译】表10:目标检测最先进系统的比较。我们在冻结的DINOv3骨干网络上训练检测适配器。我们展示了COCO和COCO-O数据集验证集上的结果,并报告跨IoU阈值的mAP以及有效鲁棒性(ER)。我们基于DINOv3的检测系统创造了新的最先进性能。由于InternImage-G检测模型尚未发布,我们无法重现其结果或计算COCO-O分数。
Implementation We build upon the Plain-DETR ( Lin et al. , 2023b ), but make the following modification: We do not fuse the transformer encoder into the backbone, but keep it as a separate module, similar to the original DETR ( Carion et al. , 2020 ), which allows us to keep the DINOv3 backbone completely frozen during training and inference. To the best of our knowledge, this makes it the first competitive detection model to use a frozen backbone . We train the Plain-DETR detector on Objects365 for 22 epochs at resolution 1536, then one epoch at resolution 2048, followed by 12 epochs on COCO at resolution 2048. At inference time, we run at resolution 2048. Optionally, we also apply test-time augmentation (TTA) by forwarding the image at multiple resolutions (from 1536 to 2880). See App. D.9 for full experimental details.
【翻译】实现 我们基于Plain-DETR(Lin等,2023b),但进行以下修改:我们不将transformer编码器融合到骨干网络中,而是将其保持为单独的模块,类似于原始DETR(Carion等,2020),这允许我们在训练和推理期间保持DINOv3骨干网络完全冻结。据我们所知,这使其成为第一个使用冻结骨干网络的竞争性检测模型。我们在Objects365上以1536分辨率训练Plain-DETR检测器22个epoch,然后以2048分辨率训练一个epoch,接着在COCO上以2048分辨率训练12个epoch。在推理时,我们以2048分辨率运行。可选地,我们还通过在多个分辨率(从1536到2880)上前向图像来应用测试时增强(TTA)。完整的实验细节见附录D.9。
Results ( Tab. 10 ) We compare our system with four models: EVA-02 with a Cascade detector ( Fang et al. , 2024b ), EVA-02 with Co-DETR ( Zong et al. , 2023 ), InternImage-G with DINO ( Wang et al. , 2023b ), and PEspatial with DETA ( Bolya et al. , 2025 ). We find that our lightweight detector (100M parameters) trained on top of a frozen DINOv3 backbone manages to reach state-of-the-art performance. For COCOO, the gap is pronounced, showing that the detection model can effectively leverage the robustness of the DINOv3. Interestingly, our model outperforms all previous models with much fewer trained parameters, with the smallest comparison point still using more than 300M trainable parameters. We argue that achieving such strong performance without specializing the backbone is an enabler for various practical applications: A single backbone forward can provide features that support multiple tasks, reducing compute requirements.
【翻译】结果(表10)我们将我们的系统与四个模型进行比较:使用Cascade检测器的EVA-02(Fang等,2024b),使用Co-DETR的EVA-02(Zong等,2023),使用DINO的InternImage-G(Wang等,2023b),以及使用DETA的PEspatial(Bolya等,2025)。我们发现,在冻结的DINOv3骨干网络上训练的轻量级检测器(100M参数)能够达到最先进的性能。对于COCO-O,差距很明显,表明检测模型可以有效利用DINOv3的鲁棒性。有趣的是,我们的模型用更少的训练参数超越了所有先前的模型,最小的比较点仍然使用超过300M的可训练参数。我们认为,在不专门化骨干网络的情况下实现如此强的性能是各种实际应用的推动因素:单个骨干网络前向传播可以提供支持多个任务的特征,减少计算需求。
6.3.2 语义分割
Following the previous experiment, we now evaluate on semantic segmentation, another long-standing computer vision problem. This task also requires strong, well localized representations, and expects a dense per-pixel prediction. However, opposed to object detection, the model does not need to differentiate instances of the same object. Similar to detection, we train a decoder on top of a frozen DINOv3 model.
【翻译】继前面的实验之后,我们现在评估语义分割,这是另一个长期存在的计算机视觉问题。这个任务也需要强大的、良好定位的表示,并期望密集的逐像素预测。然而,与目标检测相反,模型不需要区分同一对象的实例。类似于检测,我们在冻结的DINOv3模型上训练解码器。
Datasets and Metrics We focus our evaluation on the ADE20k dataset ( Zhou et al. , 2017 ), which contains 150 semantic categories across 20k training images and 2k validation images. We measure performance using the mean Intersection over Union (mIoU). To train the segmentation model, we additionally use the COCOStuff ( Caesar et al. , 2018 ) and Hypersim ( Roberts et al. , 2021 ) datasets. Those contain 164k images with 171 semantic categories, and 77k images with 40 categories respectively.
【翻译】数据集和指标 我们将评估重点放在ADE20k数据集(Zhou等,2017)上,该数据集包含20k训练图像和2k验证图像中的150个语义类别。我们使用平均交并比(mIoU)来衡量性能。为了训练分割模型,我们另外使用COCOStuff(Caesar等,2018)和Hypersim(Roberts等,2021)数据集。这些数据集分别包含164k图像(171个语义类别)和77k图像(40个类别)。
Implementation To build a decoder that maps DINOv3 features to semantic categories, we combine ViTAdapter ( Chen et al. , 2022 ) and Mask2Former ( Cheng et al. , 2022 ), similar to prior work ( Wang et al. , 2022b ; 2023b ; a ). However, in our case, the DINOv3 backbone remains frozen during training. In order to avoid altering the backbone features, we further modify the original ViT-Adapter architecture by removing the injector component. Compared to baselines, we also increase the embedding dimensions from 1024 to 2048, to support processing the 4096-dimensional output of the DINOv3 backbone. We start by pre-training the segmentation decoder on COCO-Stuff for 80k iterations, followed by 10k iterations on Hypersim ( Roberts et al. , 2021 ). Finally, we train for 20k iterations on the training split of ADE20k and report results on the validation split. All training is done at an input resolution of 896. At inference time we consider two setups: single-scale, i.e . we forward images at training resolution, or multi-scale, i.e . we average predictions at multiple image ratios between × 0 . 9 and 1 . 1 the original training resolution. We refer to App. D.10 for more experimental details.
【翻译】实现 为了构建将DINOv3特征映射到语义类别的解码器,我们结合ViTAdapter(Chen等,2022)和Mask2Former(Cheng等,2022),类似于先前的工作(Wang等,2022b;2023b;a)。然而,在我们的情况下,DINOv3骨干网络在训练期间保持冻结。为了避免改变骨干特征,我们进一步修改原始ViT-Adapter架构,移除注入器组件。与基线相比,我们还将嵌入维度从1024增加到2048,以支持处理DINOv3骨干网络的4096维输出。我们首先在COCO-Stuff上预训练分割解码器80k次迭代,然后在Hypersim(Roberts等,2021)上进行10k次迭代。最后,我们在ADE20k的训练分割上训练20k次迭代,并在验证分割上报告结果。所有训练都在896的输入分辨率下进行。在推理时,我们考虑两种设置:单尺度,即我们在训练分辨率下前向图像,或多尺度,即我们在原始训练分辨率的×0.9和1.1之间的多个图像比例下平均预测。更多实验细节参见附录D.10。
Table 11: Comparison with state-of-the-art systems for semantic segmentation on ADE20k. We evaluate the model in a single- or multi-scale setup (respectively Simple and TTA). Following common practice, we run this evaluation at resolution 896 and report mIoU scores. BEIT3, ONE-PEACE and DINOv3 use a Mask2Former with ViT-Adapter architecture, and the decoder parameters take into account both. We report results on further datasets in Tab. 24
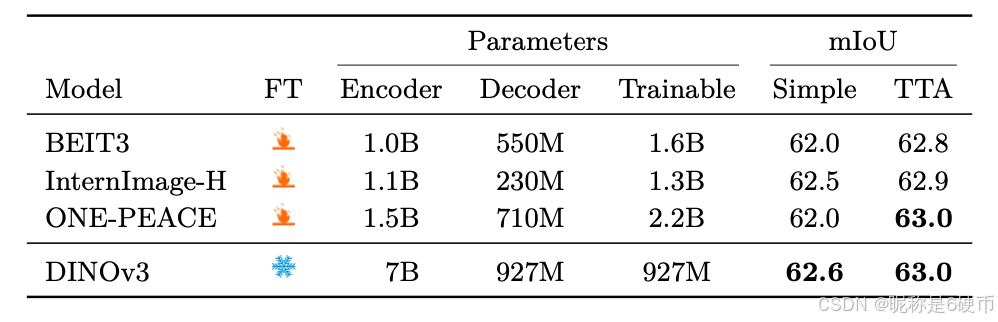
【翻译】表11:ADE20k语义分割最先进系统的比较。我们在单尺度或多尺度设置(分别为Simple和TTA)下评估模型。遵循常见做法,我们在896分辨率下运行此评估并报告mIoU分数。BEIT3、ONE-PEACE和DINOv3使用带有ViT-Adapter架构的Mask2Former,解码器参数考虑了两者。我们在表24中报告了更多数据集上的结果。
Results ( Tab. 11 ) We compare our model’s performance with several state-of-the-art baselines, including BEIT-3 ( Wang et al. , 2022b ), InternImage-H ( Wang et al. , 2023b ) and ONE-PEACE ( Wang et al. , 2023a ), and report results on additional datasets in Tab. 24 . Our segmentation model based on the frozen DINOv3 backbone reaches state-of-the-art performance, equaling that of ONE-PEACE (63 . 0 mIoU). It also improves over all prior models on the COCO-Stuff ( Caesar et al. , 2018 ) and VOC 2012 ( Everingham et al. , 2012 ) datasets. As semantic segmentation requires accurate per-pixel predictions, vision transformer backbones pose a fundamental problem. Indeed, the 16 pixel-wide input patches make the granularity of the prediction relatively coarse—encouraging solutions like ViT-Adapter. On the other hand, we have shown that we can obtain high-quality feature maps, even at very high resolutions up to 4096 ( c.fc.fc.f . Figs. 3 and 4 ); this corresponds to dense feature maps 512-tokens wide. We hope that future work will be able to leverage these high-resolution features to reach state-of-the-art performance without having to rely on heavy decoders like ViT-Adapter with Mask2Former.
【翻译】结果(表11)我们将模型性能与几个最先进的基线进行比较,包括BEIT-3(Wang等,2022b)、InternImage-H(Wang等,2023b)和ONE-PEACE(Wang等,2023a),并在表24中报告了额外数据集上的结果。我们基于冻结DINOv3骨干网络的分割模型达到了最先进的性能,与ONE-PEACE(63.0 mIoU)持平。它在COCO-Stuff(Caesar等,2018)和VOC 2012(Everingham等,2012)数据集上也超越了所有先前的模型。由于语义分割需要准确的逐像素预测,视觉transformer骨干网络构成了一个根本问题。确实,16像素宽的输入补丁使预测的粒度相对粗糙——鼓励像ViT-Adapter这样的解决方案。另一方面,我们已经表明,即使在高达4096的非常高分辨率下,我们也可以获得高质量的特征图(参见图3和4);这对应于512个token宽的密集特征图。我们希望未来的工作能够利用这些高分辨率特征来达到最先进的性能,而不必依赖像带有Mask2Former的ViT-Adapter这样的重型解码器。
6.3.3 单目深度估计
We now consider building a system for monocular depth estimation. To do so, we follow the setup of Depth Anything V2 (DAv2) ( Yang et al. , 2024b ), a recent state-of-the-art method. The key innovation of DAv2 is to use a large collection of synthetically generated images with ground truth depth annotations. Critically, this relies on DINOv2 as a feature extractor that is able to bridge the sim-to-real gap, a capability that other vision backbones like SAM ( Kirillov et al. , 2023 ) do not show ( Yang et al. , 2024b ). Thus, we swap DINOv2 with DINOv3 in the DAv2 pipeline to see if we can achieve similar results.
【翻译】我们现在考虑构建一个单目深度估计系统。为此,我们采用Depth Anything V2(DAv2)(Yang等,2024b)的设置,这是一种最新的最先进方法。DAv2的关键创新是使用大量具有真实深度标注的合成生成图像。关键的是,这依赖于DINOv2作为特征提取器,能够弥合仿真到真实的差距,这是像SAM(Kirillov等,2023)这样的其他视觉骨干网络所不具备的能力(Yang等,2024b)。因此,我们在DAv2管道中将DINOv2替换为DINOv3,看看是否能取得类似的结果。
Implementation Like DAv2, we use a Dense Prediction Transformer (DPT) ( Ranftl et al. , 2021 ) to predict a pixelwise depth field, using features from four equally spaced layers of DINOv3 as input. We train the model using the set of losses from DAv2 on DAv2’s synthetic dataset, increasing the training resolution to 1024×7681024\times7681024×768 to make use of DINOv3’s high resolution capabilities. In contrast to DAv2, we keep the backbone frozen instead of finetuning it, testing the out-of-the-box capabilities of DINOv3. We also found it beneficial to scale up the DPT head to obtain the full potential DINOv3 7B’s larger features. See App. D.11 for details.
【翻译】实现 像DAv2一样,我们使用密集预测Transformer(DPT)(Ranftl等,2021)来预测逐像素深度场,使用DINOv3四个等间距层的特征作为输入。我们使用DAv2的损失函数集在DAv2的合成数据集上训练模型,将训练分辨率提高到1024×7681024\times7681024×768以利用DINOv3的高分辨率能力。与DAv2相比,我们保持骨干网络冻结而不是微调它,测试DINOv3的开箱即用能力。我们还发现扩大DPT头部有助于获得DINOv3 7B更大特征的全部潜力。详见附录D.11。
Datasets and Metrics We evaluate our model on 5 real-world datasets (NYUv2 ( Silberman et al. , 2012 ), KITTI ( Geiger et al. , 2013 ), ETH3D ( Schöps et al. , 2017 ), ScanNet (from Ke et al. ( 2025 )) and DIODE ( Vasiljevic et al. , 2019 )) in the zero-shot scale-invariant depth setup, similar to Ranftl et al. ( 2020 ); Ke et al. ( 2025 ); Yang et al. ( 2024b ). We report the standard metrics absolute relative error (ARel) (lower is better) and δ1\delta_{1}δ1 (higher is better). We refer to Yang et al. ( 2024a ) for a description of those metrics.
【翻译】数据集和指标 我们在5个真实世界数据集(NYUv2(Silberman等,2012)、KITTI(Geiger等,2013)、ETH3D(Schöps等,2017)、ScanNet(来自Ke等(2025))和DIODE(Vasiljevic等,2019))上评估我们的模型,采用零样本尺度不变深度设置,类似于Ranftl等(2020);Ke等(2025);Yang等(2024b)。我们报告标准指标绝对相对误差(ARel)(越低越好)和δ1\delta_{1}δ1(越高越好)。我们参考Yang等(2024a)对这些指标的描述。
Table 12: Comparison with state-of-the-art systems for relative monocular depth estimation. By combining DINOv3 with Depth Anything V2 ( Yang et al. , 2024b ), we obtain a SotA model for relative depth estimation.
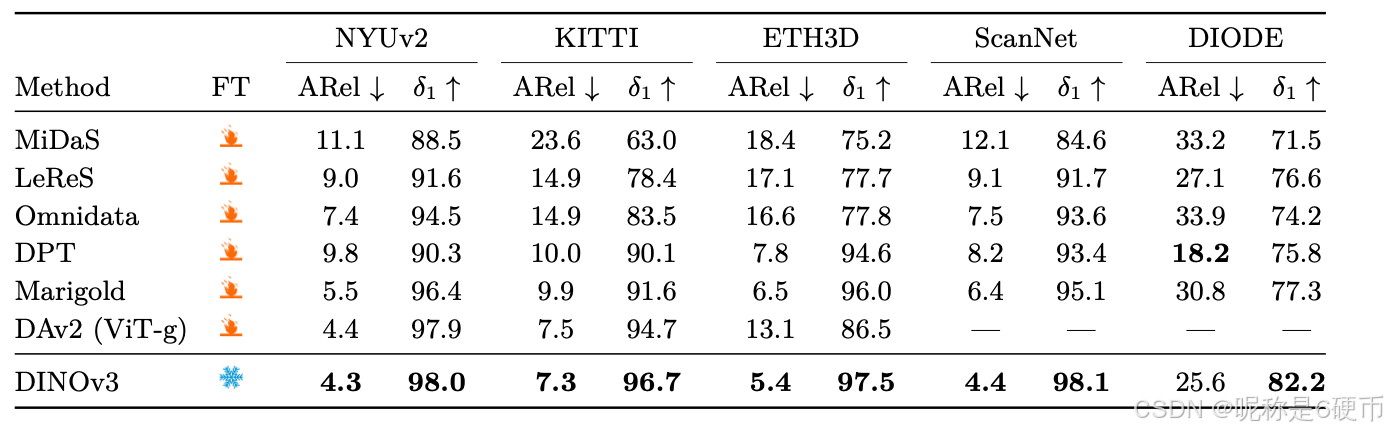
【翻译】表12:相对单目深度估计最先进系统的比较。通过将DINOv3与Depth Anything V2(Yang等,2024b)结合,我们获得了相对深度估计的最先进模型。
Results ( Tab. 12 ) We compare to the state of the art for relative depth estimation: MiDaS ( Ranftl et al. , 2020 ), LeReS ( Yin et al. , 2021 ), Omnidata ( Eftekhar et al. , 2021 ), DPT ( Ranftl et al. , 2021 ), Marigold in the ensemble version ( Ke et al. , 2025 ) and DAv2. Our depth estimation model reaches a new state-of-the-art on all datasets, only lacking behind in ARel on DIODE compared to DPT. Remarkably, this is possible using a frozen backbone , whereas all other baselines need to finetune the backbone for depth estimation. In addition, this validates that DINOv3 inherits DINOv2’s strong sim-to-real capabilities , a desirable property that opens up the possibility for downstream tasks to use synthetically generated training data.
【翻译】结果(表12)我们与相对深度估计的最先进方法进行比较:MiDaS(Ranftl等,2020)、LeReS(Yin等,2021)、Omnidata(Eftekhar等,2021)、DPT(Ranftl等,2021)、集成版本的Marigold(Ke等,2025)和DAv2。我们的深度估计模型在所有数据集上都达到了新的最先进水平,只有在DIODE上的ARel指标略逊于DPT。值得注意的是,这是使用冻结骨干网络实现的,而所有其他基线都需要为深度估计微调骨干网络。此外,这验证了DINOv3继承了DINOv2强大的仿真到真实能力,这是一个理想的特性,为下游任务使用合成生成的训练数据开辟了可能性。
6.3.4 基于DINOv3的视觉几何基础Transformer
Finally, we consider 3D understanding with the recent Visual Geometry Grounded Transformer (VGGT) ( Wang et al. , 2025 ). Trained on a large set of 3D-annotated data, VGGT learns to estimate all important 3D attributes of a scene, such as camera intrinsics and extrinsics, point maps, or depth maps, in a single forward pass. Using a simple, unified pipeline, it reaches state-of-the-art results on many 3D tasks while being more efficient than specialized methods—constituting a major advance in 3D understanding.
【翻译】最后,我们考虑使用最新的视觉几何基础Transformer(VGGT)(Wang等,2025)进行3D理解。VGGT在大量3D标注数据上训练,学习在单次前向传递中估计场景的所有重要3D属性,如相机内参和外参、点图或深度图。使用简单、统一的管道,它在许多3D任务上达到最先进的结果,同时比专门的方法更高效——构成了3D理解的重大进步。
Implementation VGGT uses a DINOv2-pretrained backbone to obtain representations for different views of a scene, before fusing them with a transformer. Here, we simply swap the DINOv2 backbone with DINOv3, using our ViT-L variant (see Sec. 7 ) to match DINOv2 ViT-L/14 in the original work. We run the same training pipeline as VGGT, including finetuning of the image backbone. We switch the image resolution from 518×518518\times518518×518 to 592×592592\times592592×592 to accommodate DINOv3’s patch size 16 and keep the the results comparable to VGGT. We additionally adopt a small number of hyperparameter changes detailed in App. D.12 .
【翻译】实现 VGGT使用DINOv2预训练的骨干网络来获得场景不同视图的表示,然后用transformer融合它们。在这里,我们简单地将DINOv2骨干网络替换为DINOv3,使用我们的ViT-L变体(见第7节)来匹配原始工作中的DINOv2 ViT-L/14。我们运行与VGGT相同的训练管道,包括对图像骨干网络的微调。我们将图像分辨率从518×518518\times518518×518切换到592×592592\times592592×592以适应DINOv3的补丁大小16,并保持结果与VGGT可比。我们还采用了少量超参数更改,详见附录D.12。
Datasets and Metrics Following Wang et al. ( 2025 ), we evaluate on camera pose estimation on the Re10K ( Zhou et al. , 2018 ) and CO3Dv2 ( Reizenstein et al. , 2021 ) datasets, dense multi-view estimation on DTU ( Jensen et al. , 2014 ), and two-view matching on ScanNet-1500 ( Dai et al. , 2017 ). For camera pose estimation and two-view matching, we report the standard area-under-curve (AUC) metric. For multiview estimation, we report the smallest L2-distance between prediction to ground truth as “Accuracy”, the smallest L2-distance from ground truth to prediction as “Completeness” and their average as 'Overall". We refer to Wang et al. ( 2025 ) for details about method and evaluation.
【翻译】数据集和指标 遵循Wang等(2025),我们在Re10K(Zhou等,2018)和CO3Dv2(Reizenstein等,2021)数据集上评估相机姿态估计,在DTU(Jensen等,2014)上评估密集多视图估计,在ScanNet-1500(Dai等,2017)上评估双视图匹配。对于相机姿态估计和双视图匹配,我们报告标准曲线下面积(AUC)指标。对于多视图估计,我们报告预测到真实值的最小L2距离作为"准确性",真实值到预测的最小L2距离作为"完整性",以及它们的平均值作为"整体"。我们参考Wang等(2025)了解方法和评估的详细信息。
Results ( Tab. 13 ) We find that VGGT equipped with DINOv3 further improves over the previous stateof-the-art set by VGGT on all three considered tasks—using DINOv3 leads to clear and consistent gains. This is encouraging, given that we only applied minimal tuning for DINOv3. These tasks span different levels of visual understanding: high-level abstraction of scene content (camera pose estimation), dense geometric prediction (multi-view depth estimation), and fine-grained pixel-level correspondence (view matching). To gether with the previous results on correspondence estimation ( Sec. 6.1.3 ) and depth estimation ( Sec. 6.3.3 ), we take this as further empirical evidence for the strong suitability of DINOv3 as a basis for 3D tasks. Additionally, we anticipate further improvements from using the larger DINOv3 7B model.
【翻译】结果(表13)我们发现,配备DINOv3的VGGT在所有三个考虑的任务上都进一步改进了VGGT设定的先前最先进水平——使用DINOv3带来了明显且一致的收益。这是令人鼓舞的,考虑到我们只对DINOv3进行了最小的调整。这些任务涵盖不同层次的视觉理解:场景内容的高级抽象(相机姿态估计)、密集几何预测(多视图深度估计)和细粒度像素级对应(视图匹配)。结合之前在对应估计(第6.1.3节)和深度估计(第6.3.3节)上的结果,我们将此作为DINOv3作为3D任务基础的强大适用性的进一步经验证据。此外,我们预期使用更大的DINOv3 7B模型会有进一步的改进。
Table 13: 3D understanding using Visual Geometry Grounded Transformer (VGGT) ( Wang et al. , 2025 ). Simply by swapping DINOv2 for DINOv3 ViT-L as the image feature extractor in the VGGT pipeline, we are able to obtain state-of-the-art results on various 3D geometry tasks. We reproduce baseline results from Wang et al. ( 2025 ). We also report methods using ground truth camera information, marked with ∗ . Camera pose estimation results are reported with AUC@30.
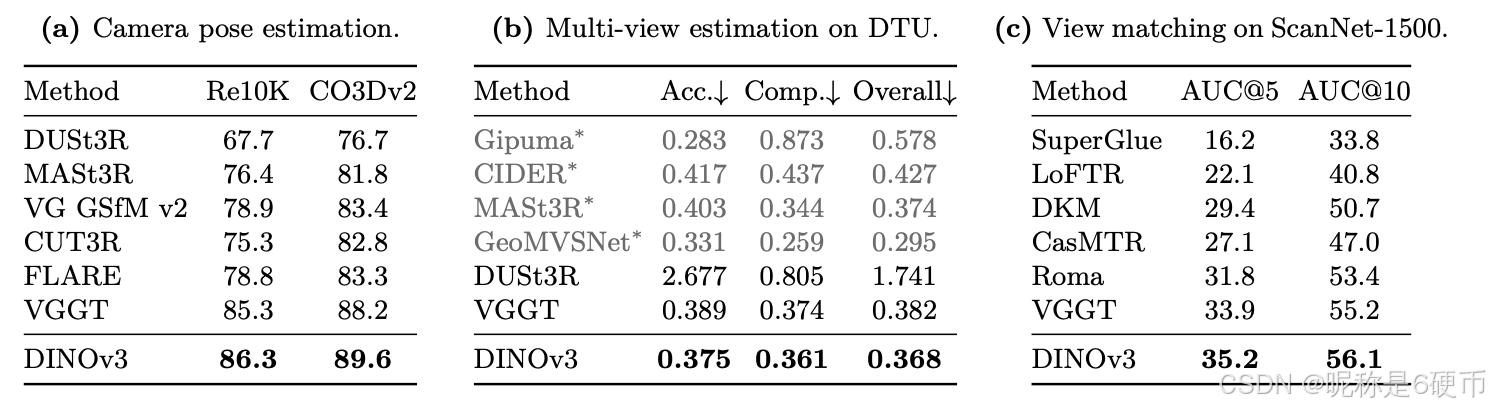
【翻译】表13:使用视觉几何基础Transformer(VGGT)(Wang等,2025)进行3D理解。仅通过在VGGT管道中将DINOv2替换为DINOv3 ViT-L作为图像特征提取器,我们就能够在各种3D几何任务上获得最先进的结果。我们重现了Wang等(2025)的基线结果。我们还报告了使用真实相机信息的方法,用∗标记。相机姿态估计结果用AUC@30报告。
7 评估DINOv3模型的完整家族
In this section, we provide quantitative evaluations on the family of models distilled from our 7B-parameters model (See Sec. 5.2 ). This family includes variants based on the Vision Transformer (ViT) and the ConvNeXt (CNX) architectures. We provide the detailed parameter counts and inference FLOPs for all models in Fig. 16a . These models cover a wide range of computational budgets to accommodate a broad spectrum of users and deployment scenarios. We conduct a thorough evaluation of all ViT ( Sec. 7.1 ) and ConvNeXt variants to assess their performance across tasks.
【翻译】在本节中,我们对从我们的70亿参数模型蒸馏出的模型家族进行定量评估(见第5.2节)。这个家族包括基于Vision Transformer(ViT)和ConvNeXt(CNX)架构的变体。我们在图16a中提供了所有模型的详细参数计数和推理FLOPs。这些模型涵盖了广泛的计算预算,以适应广泛的用户和部署场景。我们对所有ViT(第7.1节)和ConvNeXt变体进行了全面评估,以评估它们在各项任务中的性能。
Figure 2 provides an overview comparison of the DINOv3 family versus other model collections. The DINOv3 family significantly outperforms all others on dense prediction tasks. This includes specialized models distilled from supervised backbones like AM-RADIO and PEspatial. At the same time, our models achieve similar results on classification tasks, making them the optimal choice across compute budgets.
【翻译】图2提供了DINOv3家族与其他模型集合的总体比较。DINOv3家族在密集预测任务上显著优于所有其他模型。这包括从监督骨干网络(如AM-RADIO和PEspatial)蒸馏出的专门模型。同时,我们的模型在分类任务上取得了相似的结果,使它们成为各种计算预算下的最佳选择。
In Sec. 7.1 detail our ViT models and compare them to other open-source alternatives. Then, in Sec. 7.2 , we discuss the ConvNeXt models. Finally, following Sec. 5.3 , we trained a text encoder aligned with the output of our ViT-L model. We present multi-modal alignment results for this model in Sec. 7.3 .
【翻译】在第7.1节中,我们详细介绍了我们的ViT模型并将它们与其他开源替代方案进行比较。然后,在第7.2节中,我们讨论ConvNeXt模型。最后,遵循第5.3节,我们训练了一个与我们ViT-L模型输出对齐的文本编码器。我们在第7.3节中展示了该模型的多模态对齐结果。
7.1 适用于每个用例的Vision Transformer
Our ViT family spans architectures from the compact ViT-S to the larger 840 million parameter ViT H+^{\mathrm{H+}}H+ models. The former is designed to run efficiently on resource-constrained devices such as laptops, the latter delivers state-of-the-art performance for more demanding applications. We compare our ViT models to the best open-source image encoders of corresponding size, namely DINOv2 ( Oquab et al. , 2024 ), SigLIP 2 ( Tschannen et al. , 2025 ) and Perception Encoder ( Bolya et al. , 2025 ). For a fair comparison, we ensure that the input sequence length is equivalent across models. Specifically, for model with a patch size of 16 we input images of size 512×512512\times512512×512 versus 448×448448\times448448×448 when models are using patch size 14.
【翻译】我们的ViT家族涵盖了从紧凑的ViT-S到更大的8.4亿参数ViTH+^{\mathrm{H+}}H+模型的架构。前者旨在在资源受限的设备(如笔记本电脑)上高效运行,后者为更苛刻的应用提供最先进的性能。我们将我们的ViT模型与相应大小的最佳开源图像编码器进行比较,即DINOv2(Oquab等,2024)、SigLIP 2(Tschannen等,2025)和Perception Encoder(Bolya等,2025)。为了公平比较,我们确保模型间的输入序列长度相等。具体来说,对于补丁大小为16的模型,我们输入512×512512\times512512×512大小的图像,而当模型使用补丁大小14时则使用448×448448\times448448×448。
Our empirical study clearly demonstrates that DINOv3 models consistently outperform their counterparts on dense prediction tasks. Most notably, on the ADE20k benchmark, the DINOv3 ViT-L model achieves an improvement of over 6 mIoU points compared to the best competitor DINOv2. The ViT-B variant shows a gain of approximately 3 mIoU points against the next best competitor. These substantial improvements highlight the effectiveness of DINOv3’s local features in capturing fine-grained spatial details. Furthermore, evaluations on depth estimation tasks also reveal consistent performance gains over competing approaches.
【翻译】我们的经验研究清楚地表明,DINOv3模型在密集预测任务上始终优于其对应模型。最值得注意的是,在ADE20k基准测试中,DINOv3 ViT-L模型与最佳竞争对手DINOv2相比,改进了超过6个mIoU点。ViT-B变体与次佳竞争对手相比显示了大约3个mIoU点的收益。这些显著的改进突出了DINOv3局部特征在捕获细粒度空间细节方面的有效性。此外,在深度估计任务上的评估也显示出相对于竞争方法的一致性能提升。
Figure 16: (a) Presentation of the distilled models’ characteristics. CNX stands for ConvNeXT. We present per model the number of parameters and the GFLOPs estimated on images of size 256×256256\times256256×256 and 512×512512\times512512×512 . (b) We compare DINOv3 ViT-H+ to its 7B-sized teacher; despite having almost 10 ×\times× less parameters, the ViT-H+ is close to DINOv3 7B in performance.
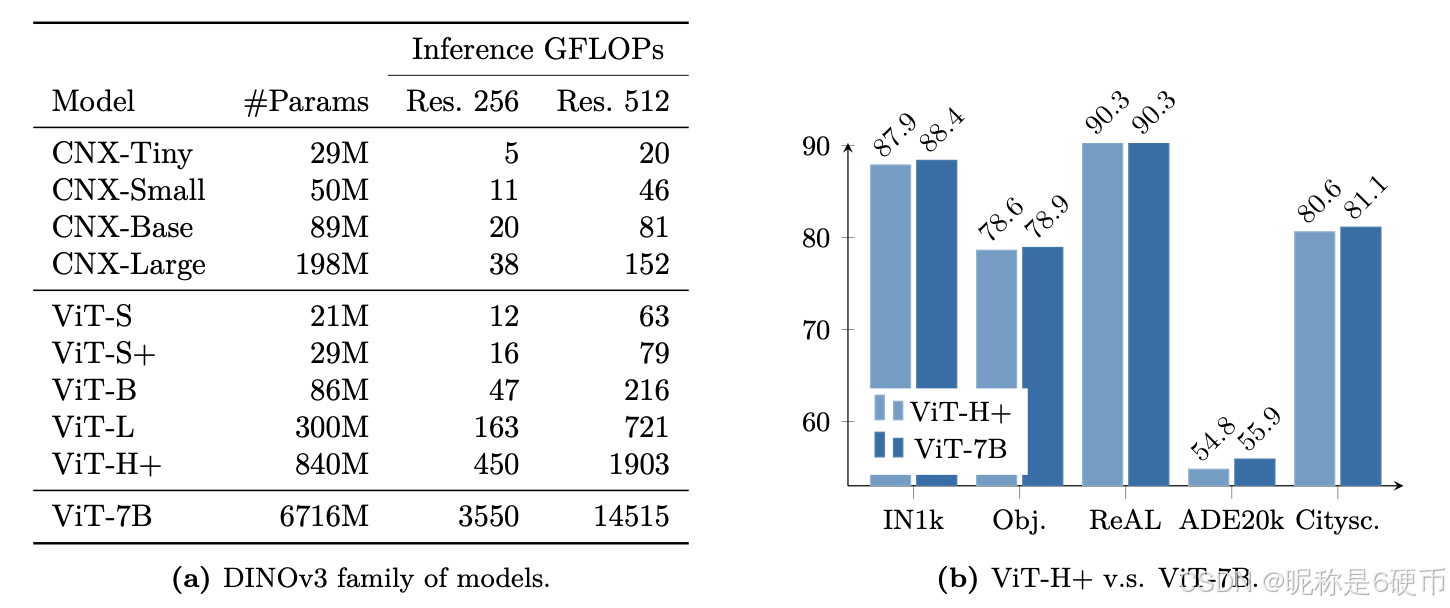
【翻译】图16:(a)蒸馏模型特性的展示。CNX代表ConvNeXT。我们为每个模型展示参数数量和在256×256256\times256256×256和512×512512\times512512×512大小图像上估计的GFLOPs。(b)我们将DINOv3 ViT-H+与其70亿大小的教师模型进行比较;尽管参数少了近10倍,ViT-H+在性能上接近DINOv3 7B。
Table 14: Comparison of our family of models against open-source alternatives of comparable size. We showcase our ViT-{S, S+, B, L, H+} models on a representative set of global and dense benchmarks: classification (IN-ReAL, IN-R, ObjectNet), retrieval (Oxford-H), segmentation (ADE20k), depth (NYU), tracking (DAVIS at 960px), and keypoint matching (NAVI, SPair). We match the number of patch tokens for a fair comparison across models of different patch size.
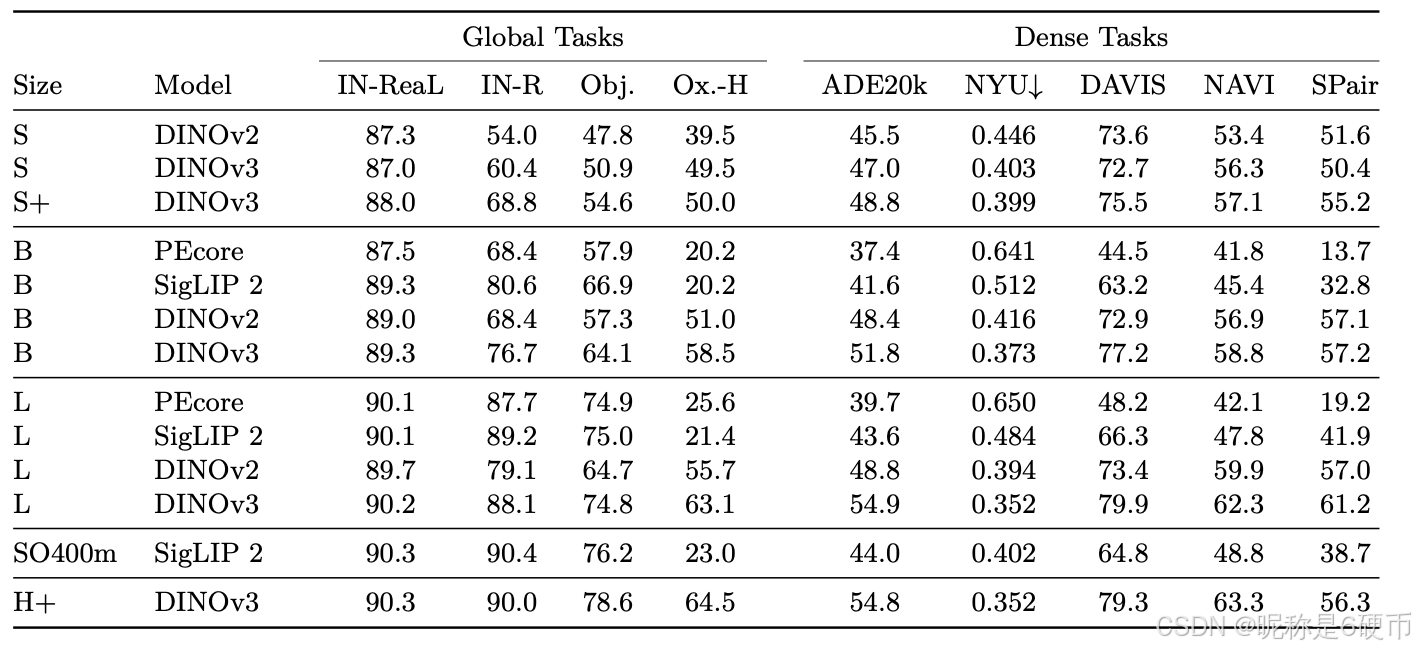
【翻译】表14:我们的模型家族与可比大小的开源替代方案的比较。我们在一组代表性的全局和密集基准测试上展示我们的ViT-{S, S+, B, L, H+}模型:分类(IN-ReAL, IN-R, ObjectNet)、检索(Oxford-H)、分割(ADE20k)、深度(NYU)、跟踪(960px的DAVIS)和关键点匹配(NAVI, SPair)。我们匹配补丁标记的数量以在不同补丁大小的模型间进行公平比较。
This underscores the versatility of the DINOv3 family across different dense vision problems. Importantly, our models achieve competitive results on global recognition benchmarks such as ObjectNet and ImageNet1k. This indicates that the enhanced dense task performance does not come at the expense of global task accuracy. This balance confirms that DINOv3 models provide a robust and well-rounded solution, excelling across both dense and global vision tasks without compromise.
【翻译】这突出了DINOv3家族在不同密集视觉问题上的多功能性。重要的是,我们的模型在全局识别基准测试(如ObjectNet和ImageNet1k)上取得了竞争性结果。这表明增强的密集任务性能并不以牺牲全局任务准确性为代价。这种平衡证实了DINOv3模型提供了一个强大且全面的解决方案,在密集和全局视觉任务上都表现出色,没有妥协。
On another note, we want to also validate if the largest models that we distill capture all the information from the teacher. To this end, we run a comparison of our largest ViT-H+ with the 7B teacher. As shown in Fig. 16b , the largest student achieves performance that is on par with the 8 times larger ViT-7B model.
【翻译】另外,我们还想验证我们蒸馏的最大模型是否捕获了教师模型的所有信息。为此,我们对我们最大的ViT-H+与70亿教师模型进行了比较。如图16b所示,最大的学生模型达到了与8倍大的ViT-7B模型相当的性能。
Figure 17: Stability of the features at multiple resolutions for the DINOv3 ViT family of models. Topto-bottom: ViT-S, S+\mathrm{S+}S+ , B, L, H+. We run inference on an image at multiple resolutions, then perform principal component analysis on the features computed on a 1792×10241792\times10241792×1024 image ( 112×64112\times64112×64 image tokens). We then project features at all resolutions onto the principal components 5–7 that we map to the RGB space for visualization. While the models are functional at all resolutions, we observe that the features remain consistent across a large range of resolutions before drifting: for example, ViT-S+ features are stable between 896×512896\times512896×512 and 3584×20483584\times20483584×2048 inputs, while ViT-L barely starts drifting on the largest resolution 7168×40967168\times40967168×4096 . ViT-H+ remains stable throughout the whole tested range.
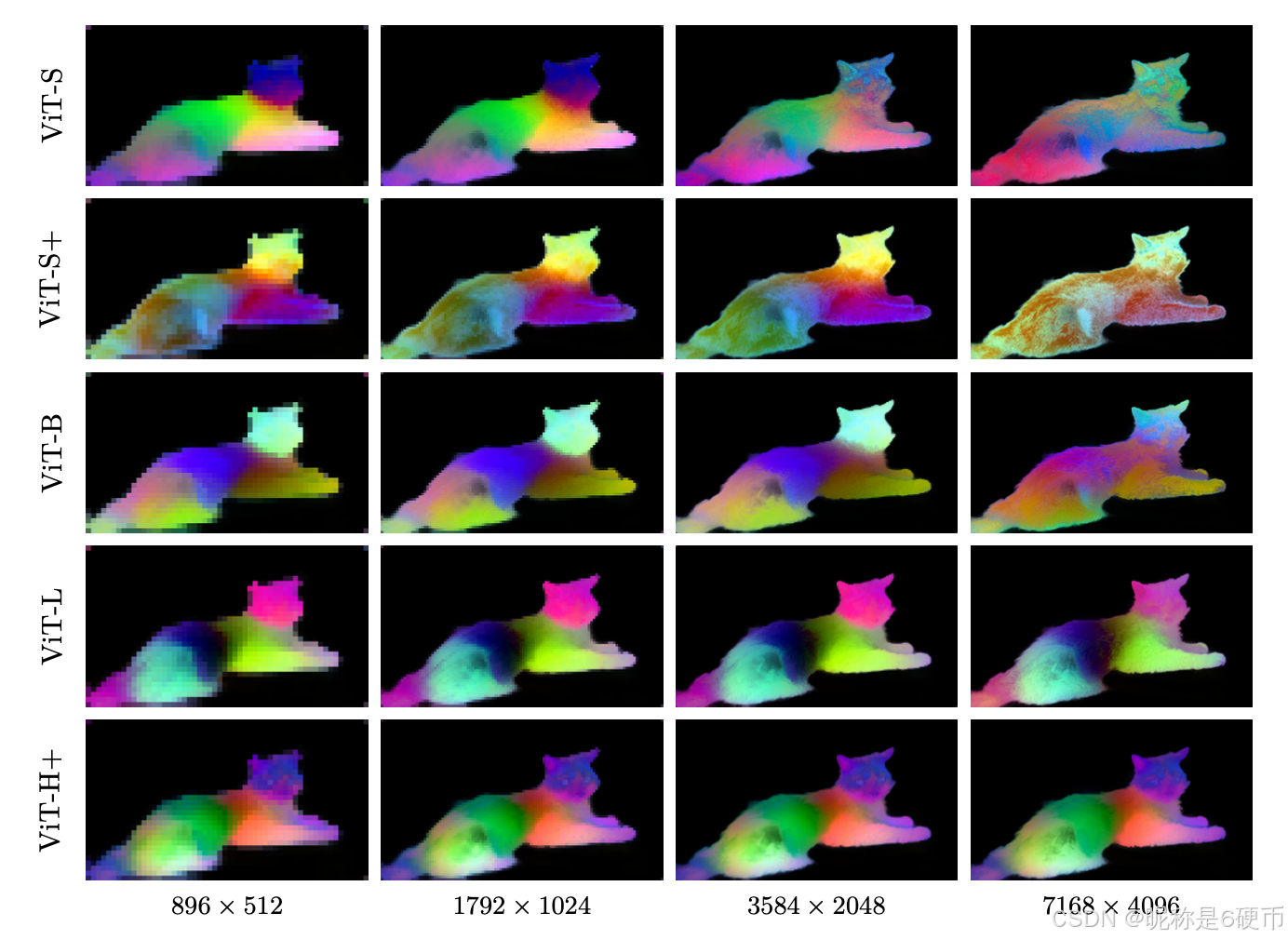
【翻译】图17:DINOv3 ViT模型家族在多个分辨率下特征的稳定性。从上到下:ViT-S, S+\mathrm{S+}S+, B, L, H+。我们在多个分辨率下对图像进行推理,然后对在1792×10241792\times10241792×1024图像(112×64112\times64112×64图像标记)上计算的特征执行主成分分析。然后我们将所有分辨率的特征投影到主成分5-7上,将其映射到RGB空间进行可视化。虽然模型在所有分辨率下都能正常工作,但我们观察到特征在大范围分辨率内保持一致,然后才开始偏移:例如,ViT-S+特征在896×512896\times512896×512和3584×20483584\times20483584×2048输入之间保持稳定,而ViT-L在最大分辨率7168×40967168\times40967168×4096上才开始偏移。ViT-H+在整个测试范围内都保持稳定。
This result not only validates the effectiveness of our distillation process but also demonstrates that, when guided by a high-quality teacher, smaller models can learn to deliver comparable levels of performance. This finding reinforces our belief that training very large models benefits the broader community . The strength of larger models can be successfully distilled into more efficient, smaller models with little or no loss of quality.
【翻译】这个结果不仅验证了我们蒸馏过程的有效性,还证明了在高质量教师模型的指导下,较小的模型可以学会提供相当水平的性能。这一发现强化了我们的信念,即训练非常大的模型有益于更广泛的社区。较大模型的优势可以成功地蒸馏到更高效、更小的模型中,几乎不会损失质量。
7.2 资源受限环境下的高效ConvNeXts
In this section, we evaluate the quality of our ConvNeXt (CNX) models distilled from the 7B teacher. ConvNeXt models are highly efficient in terms of FLOPs and are well-suited for deployment on devices optimized for convolutional computations. Furthermore, transformer models often do not lend themselves well to quantization ( Bondarenko et al. , 2021 ), whereas quantization of convolutional nets is a well explored subject. We distill CNX architectures of size T, S, B, and L (see Fig. 16a ) and compare them to the original ConvNeXt models ( Liu et al. , 2022 ). These baselines achieve high performance on ImageNet-1k as they were trained in a supervised fashion using ImageNet-22k labels, and thus represent a strong competitor. For this experiment, we provide results for global tasks at input resolutions 256 and 512, for ADE20k at resolution 512, and for NYU at resolution 640.
【翻译】在本节中,我们评估从70亿教师模型蒸馏出的ConvNeXt(CNX)模型的质量。ConvNeXt模型在FLOPs方面非常高效,非常适合部署在为卷积计算优化的设备上。此外,Transformer模型通常不适合量化(Bondarenko等,2021),而卷积网络的量化是一个被充分探索的主题。我们蒸馏了大小为T、S、B和L的CNX架构(见图16a),并将它们与原始ConvNeXt模型(Liu等,2022)进行比较。这些基线在ImageNet-1k上取得了高性能,因为它们使用ImageNet-22k标签以监督方式训练,因此代表了强有力的竞争对手。在此实验中,我们为输入分辨率256和512的全局任务、分辨率512的ADE20k和分辨率640的NYU提供结果。
Table 15: Evaluation of our distilled DINOv3 ConvNeXt models. We compare our models to off-the-shelf ConvNeXts trained supervised on ImageNet-22k ( Liu et al. , 2022 ). For global tasks, we give results at input resolutions 256 and 512, as we found the supervised models to significantly degrade at resolution 512.
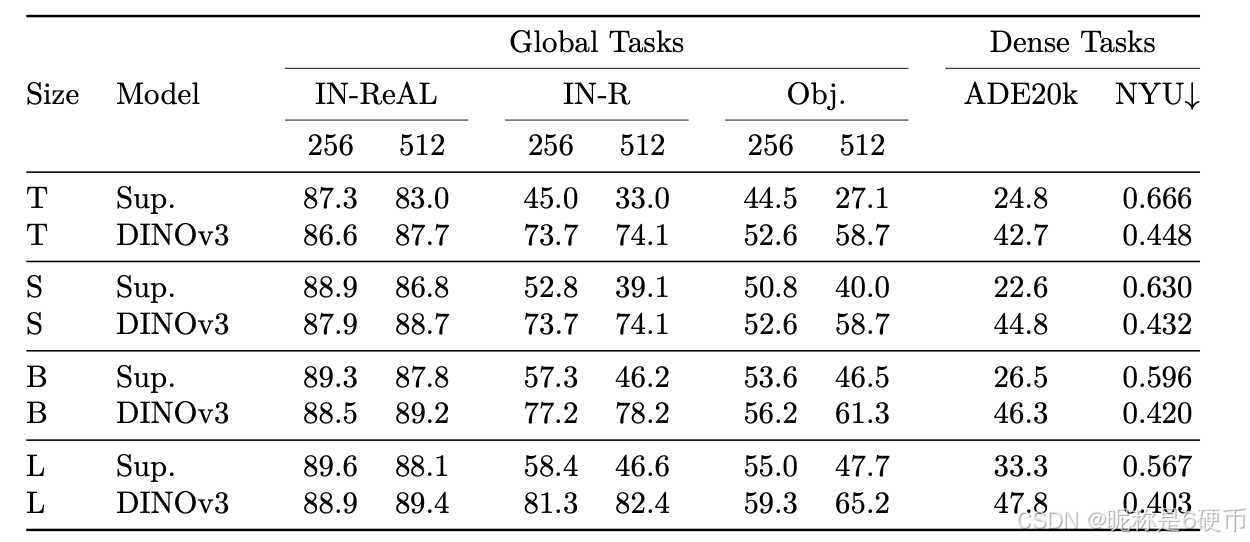
【翻译】表15:我们蒸馏的DINOv3 ConvNeXt模型的评估。我们将我们的模型与在ImageNet-22k上监督训练的现成ConvNeXts(Liu等,2022)进行比较。对于全局任务,我们给出输入分辨率256和512的结果,因为我们发现监督模型在分辨率512时显著退化。
Results ( Tab. 15 ) We find that on in-distribution image classification, our models slightly lag behind the supervised ones at resolution 256 ( e.g . − 0 . 7 IN-ReAL for CNX-T). However, the trend is reversed at resolution 512, with the supervised ConvNeXts significantly degrading, whereas our models scale with increased input resolution. For out-of-distribution classification (IN-R, ObjectNet), there are significant gaps between the two model families for all sizes—a testament to the robustness of the DINOv3 CNX models. Furthermore, the DINOv3 models offer very large improvement on dense tasks. Indeed, for CNX-T, our model yields a +17.9+17.9+17.9 mIoU (42.7 versus 24.8) improvement, and for CNX-L, our model gets +14.5+14.5+14.5 mIoU (47.8 versus 33.3). The combination of high performance and computational efficiency makes the distilled ConvNeXt models especially promising for real-world applications where resource constraints are critical. Aside from that, the distillation of the ViT-7B model into smaller ConvNeXt models is particularly exciting, as it bridges two fundamentally different architectures. While ViT-7B is based on transformer blocks with a CLS token, ConvNeXt relies on convolutional operations without a CLS token, making this transfer of knowledge non-trivial. This achievement highlights the versatility and effectiveness of our distillation process.
【翻译】结果(表15)我们发现在分布内图像分类中,我们的模型在分辨率256时略微落后于监督模型(例如CNX-T的IN-ReAL为-0.7)。然而,在分辨率512时趋势发生逆转,监督ConvNeXts显著退化,而我们的模型随着输入分辨率的增加而扩展。对于分布外分类(IN-R、ObjectNet),两个模型家族在所有大小上都存在显著差距——这证明了DINOv3 CNX模型的鲁棒性。此外,DINOv3模型在密集任务上提供了非常大的改进。确实,对于CNX-T,我们的模型产生了+17.9 mIoU(42.7对24.8)的改进,对于CNX-L,我们的模型获得了+14.5 mIoU(47.8对33.3)。高性能和计算效率的结合使得蒸馏的ConvNeXt模型在资源约束至关重要的实际应用中特别有前景。除此之外,将ViT-7B模型蒸馏到较小的ConvNeXt模型中特别令人兴奋,因为它连接了两种根本不同的架构。虽然ViT-7B基于带有CLS标记的Transformer块,ConvNeXt依赖于没有CLS标记的卷积操作,这使得知识的转移非常重要。这一成就突出了我们蒸馏过程的多功能性和有效性。
7.3 基于DINOv3的dino.txt的零样本推理
As detailed in Sec. 5.3 , we train a text encoder to align both the CLS token and the output patches of the distilled DINOv3 ViT-L model to text, following the recipe of dino.txt Jose et al. ( 2025 ). We evaluate the quality of the alignment both at the global- and patch-level on standard benchmarks. We report the zeroshot classification accuracy using the CLIP protocol ( Radford et al. , 2021 ) on the ImageNet-1k, ImageNetAdversarial, ImageNet-Rendition and ObjectNet benchmarks. For image-text retrieval, we evaluate on the COCO2017 dataset ( Tsung-Yi et al. , 2017 ) and report Recall@1 on both image-to-text ( I→T\mathrm{I}\rightarrow\mathrm{T}I→T ) and textto-image (T open-vocabulary segmentation task using the common benchmarks ADE20k and Cityscapes, for which we → I) tasks. To probe the quality of patch-level alignment, we evaluate our model on the report the mIoU metric.
【翻译】如第5.3节详述,我们训练一个文本编码器,遵循dino.txt Jose等(2025)的方法,将蒸馏DINOv3 ViT-L模型的CLS标记和输出补丁都与文本对齐。我们在标准基准测试上评估全局和补丁级别对齐的质量。我们使用CLIP协议(Radford等,2021)报告在ImageNet-1k、ImageNetAdversarial、ImageNet-Rendition和ObjectNet基准测试上的零样本分类准确率。对于图像-文本检索,我们在COCO2017数据集(Tsung-Yi等,2017)上进行评估,并报告图像到文本(I→T\mathrm{I}\rightarrow\mathrm{T}I→T)和文本到图像(T → I)任务的Recall@1。使用常见基准测试ADE20k和Cityscapes进行开放词汇分割任务。为了探测补丁级别对齐的质量,我们在我们的模型上评估并报告mIoU指标。
Results ( Tab. 16 ) We compare our text-aligned DINOv3 ViT-L with competitors in the same size class. Compared to Jose et al. ( 2025 ), which aligns DINOv2 to text, DINOv3 leads to significantly better performance on all benchmarks. On global alignment tasks, we compare favorably to the original CLIP ( Radford et al. , 2021 ) and strong baselines such as EVA-02-CLIP ( Sun et al. , 2023 ) but slightly behind SigLIP2 ( Tschannen et al. , 2025 ) and Perception Encoder ( Bolya et al. , 2025 ). On dense alignment tasks, our text-aligned model shows excellent performance on two challenging benchmarks ADE20K and Cityscapes thanks to clean feature maps of DINOv3.
【翻译】结果(表16)我们将我们的文本对齐DINOv3 ViT-L与同等大小类别的竞争对手进行比较。与将DINOv2与文本对齐的Jose等(2025)相比,DINOv3在所有基准测试上都表现出明显更好的性能。在全局对齐任务上,我们与原始CLIP(Radford等,2021)和强基线如EVA-02-CLIP(Sun等,2023)相比表现良好,但略落后于SigLIP2(Tschannen等,2025)和Perception Encoder(Bolya等,2025)。在密集对齐任务上,由于DINOv3的干净特征图,我们的文本对齐模型在两个具有挑战性的基准测试ADE20K和Cityscapes上表现出色。
Table 16: Comparing our text-aligned DINOv3 ViT-L to the state-of-the-art. Our model achieves excellent dense alignment performance while staying competitive in global alignment tasks. All compared models are of ViT-L size and operate on the same sequence length of 576.
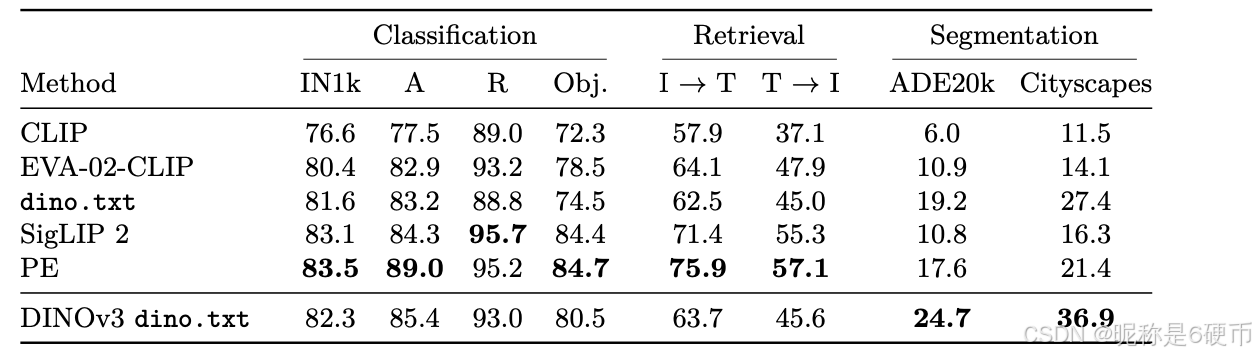
【翻译】表16:将我们的文本对齐DINOv3 ViT-L与最先进技术进行比较。我们的模型在保持全局对齐任务竞争力的同时,取得了出色的密集对齐性能。所有比较的模型都是ViT-L大小,并在相同的序列长度576上运行。
8 DINOv3在地理空间数据上的应用
Our self-supervised learning recipe is generic and can be applied to any image domain. In this section, we showcase this universality by building a DINOv3 7B model for satellite images, which have very different characteristics ( e.g . object texture, sensor noise, and focal views) than the web images on which DINOv3 was initially developed.
【翻译】我们的自监督学习方法是通用的,可以应用于任何图像领域。在本节中,我们通过为卫星图像构建DINOv3 70亿模型来展示这种通用性,卫星图像具有与DINOv3最初开发时使用的网络图像非常不同的特征(例如物体纹理、传感器噪声和焦点视图)。
8.1 预训练数据和基准测试
Our satellite DINOv3 7B model is pre-trained on SAT-493M, a dataset of 493 millions of 512×512512\times512512×512 images sampled randomly from Maxar RGB ortho-rectified imagery at 0.6 meter resolution. We use the exact same set of hyper-parameters that are used for the web DINOv3 7B model, except for the RGB mean and std normalization that are adapted for satellite images, and the training length. Similar to the web model, our training pipeline for the satellite model consists of 100k iterations of initial pre-training with global crops (256 $ \times $ 256 ), followed by 10k iterations using Gram regularization, and finalized with 8k steps of high resolution fine-tuning at resolution 512. Also similar to the web model, we distill our 7B satellite model into a more manageable ViT-Large model to facilitate its use in low-budget regime.
【翻译】我们的卫星DINOv3 70亿模型在SAT-493M上进行预训练,这是一个包含4.93亿张512×512512\times512512×512图像的数据集,从Maxar RGB正射校正影像中以0.6米分辨率随机采样。我们使用与网络DINOv3 70亿模型完全相同的超参数集,除了适用于卫星图像的RGB均值和标准差归一化,以及训练长度。与网络模型类似,我们的卫星模型训练管道包括使用全局裁剪(256×256)进行10万次迭代的初始预训练,然后使用Gram正则化进行1万次迭代,最后在分辨率512上进行8千步高分辨率微调。同样与网络模型类似,我们将70亿卫星模型蒸馏为更易管理的ViT-Large模型,以便在低预算环境中使用。
We evaluate DINOv3 satellite and web models on multiple earth observation tasks. For the task of global canopy height mapping, we use the Satlidar dataset described in App. D.13 , which consists of one million 512×512512\times512512×512 images with LiDAR ground truths split into train/val/test splits with ratios 8/1/18/1/18/1/1 . The splits include the Neon and São Paulo dataset used by Tolan et al. ( 2024 ). For national-scale canopy height mapping, we evaluate on Open-Canopy ( Fogel et al. , 2025 ), which combines SPOT 6-7 satellite imagery and aerial LiDAR data over 87,000 km 2 across France. Since images in this dataset have 4 channels including the additional infra-red (IR) channel, we adapt our backbone by taking the average of the three channels in the weights of the patch embed module and adding it to the weights as the fourth channel. We trained a DPT decoder on 512×512512\times512512×512 crops of images resized to 1667 to match the Maxar ground sample resolution.
【翻译】我们在多个地球观测任务上评估DINOv3卫星和网络模型。对于全球冠层高度制图任务,我们使用附录D.13中描述的Satlidar数据集,该数据集包含一百万张512×512512\times512512×512图像和LiDAR真实值,按8/1/18/1/18/1/1的比例分为训练/验证/测试集。这些分割包括Tolan等(2024)使用的Neon和圣保罗数据集。对于国家尺度的冠层高度制图,我们在Open-Canopy(Fogel等,2025)上进行评估,该数据集结合了SPOT 6-7卫星影像和法国87,000平方公里范围内的航空LiDAR数据。由于该数据集中的图像有4个通道,包括额外的红外(IR)通道,我们通过取补丁嵌入模块权重中三个通道的平均值并将其作为第四个通道添加到权重中来适应我们的主干网络。我们在调整为1667大小的图像的512×512512\times512512×512裁剪上训练了一个DPT解码器,以匹配Maxar地面采样分辨率。
Semantic geospatial tasks are assessed with GEO-Bench ( Lacoste et al. , 2023 ), which comprises six classification and six segmentation tasks spanning various spatial resolutions and optical bands. The GEO-Bench tasks are diverse, including the detection of rooftop-mounted photovoltaic systems, classifying local climate zones, measuring drivers of deforestation, and detecting tree crowns. For high-resolution semantic tasks, we consider the land cover segmentation dataset LoveDA ( Wang et al. , 2022a ), the object segmentation dataset iSAID ( Zamir et al. , 2019 ), and the horizontal detection dataset DIOR ( Li et al. , 2020 ).
【翻译】语义地理空间任务通过GEO-Bench(Lacoste等,2023)进行评估,该基准包括跨越各种空间分辨率和光学波段的六个分类和六个分割任务。GEO-Bench任务多样化,包括屋顶安装光伏系统的检测、本地气候区分类、森林砍伐驱动因素测量和树冠检测。对于高分辨率语义任务,我们考虑土地覆盖分割数据集LoveDA(Wang等,2022a)、对象分割数据集iSAID(Zamir等,2019)和水平检测数据集DIOR(Li等,2020)。
8.2 冠层高度估计
Estimating canopy height from satellite imagery is a challenging metric task, requiring accurate recovery of continuous spatial structure despite random variations in slope, viewing geometry, sun angle, atmospheric scattering, and quantization artifacts. This task is critical for global carbon monitoring and for forest and agriculture management ( Harris et al. , 2021 ). Following Tolan et al. ( 2024 ), the first work to leverage a SSL backbone trained on satellite images for this task, we train a DPT head on top of frozen DINOv3 on the SatLidar1M training set, then evaluate it on i.i.d. samples on SatLidar1M validation set as well as out-ofdistribution test sets including SatLidar1M test, Neon and Sao Paulo. We additionally train and evaluate on the Open-Canopy dataset.
【翻译】从卫星图像估计冠层高度是一项具有挑战性的度量任务,需要在坡度、观察几何、太阳角度、大气散射和量化伪影的随机变化下准确恢复连续的空间结构。这项任务对于全球碳监测以及森林和农业管理至关重要(Harris等,2021)。遵循Tolan等(2024)——第一个利用在卫星图像上训练的SSL主干网络进行此任务的工作,我们在SatLidar1M训练集上在冻结的DINOv3顶部训练DPT头,然后在SatLidar1M验证集的独立同分布样本以及包括SatLidar1M测试、Neon和圣保罗在内的分布外测试集上进行评估。我们还在Open-Canopy数据集上进行训练和评估。
Table 17: Evaluation of different backbones for high-resolution canopy height prediction. All models are trained with a DPT decoder. Results are presented either for experiments with the decoder trained on SatLidar and evaluated on IID samples (SatLidar Val) and OOD test sets (SatLidar Test, Neon and São Paulo), or for experiments with the decoder trained and evaluated on the Open-Canopy dataset. We list mean absolute error (MAE) and the block R2R^{2}R2 metric from Tolan et al. ( 2024 ). For completeness, we additionally evaluate the original decoder of Tolan et al. ( 2024 ) that was trained on Neon dataset (denoted by ∗^*∗ ).
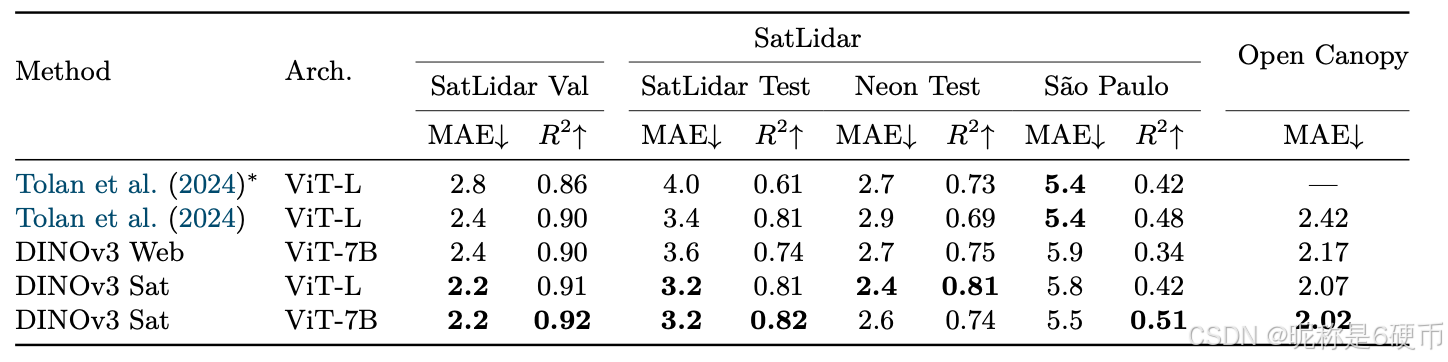
【翻译】表17:不同主干网络在高分辨率冠层高度预测中的评估。所有模型都使用DPT解码器进行训练。结果要么是在SatLidar上训练解码器并在独立同分布样本(SatLidar Val)和分布外测试集(SatLidar Test、Neon和圣保罗)上评估的实验,要么是在Open-Canopy数据集上训练和评估解码器的实验。我们列出了Tolan等(2024)的平均绝对误差(MAE)和块R2R^{2}R2指标。为了完整性,我们还评估了Tolan等(2024)在Neon数据集上训练的原始解码器(用∗^*∗表示)。
Results ( Tab. 17 ) We compare different SSL backbones, denoting with “DINOv3 Sat” the model trained the SAT-493M dataset, and with “DINOv3 Web” the model trained on LVD-1689M (see Sec. 3.1 ). It can be seen that DINOv3 satellite models yield state-of-the-art performance on most benchmarks. Our 7B satellite model sets the new state of the art on SatLidar1M val, SatLidar1M test and Open-Canopy, reducing MAE from 2 . 4 to 2 . 2, from 3 . 4 to 3 . 2 and from 2 . 42 to 2 . 02 respectively. These results show that DINOv3 training recipe is generic and can be effectively applied out-of-the-box to other domains. Interestingly, our distilled ViT-L satellite model performs comparably to its 7B counterpart, achieving comparable results on SatLidar1M and Open-Canopy while faring surprisingly better on Neon test set, reaching the lowest MAE of 2 . 4 compared to 2 . 6 of the 7B model and 2 . 9 of Tolan et al. ( 2024 ). Our DINOv3 7B web model reaches decent performance on the benchmarks, outperforming Tolan et al. ( 2024 ) on SatLidar1M val, Neon and Open-Canopy but stays behind the satellite model. This highlights the strength of domain-specific pretraining for physically grounded tasks like canopy height estimation, where sensor-specific priors and radiometric consistency are important.
【翻译】结果(表17)我们比较了不同的SSL主干网络,用"DINOv3 Sat"表示在SAT-493M数据集上训练的模型,用"DINOv3 Web"表示在LVD-1689M上训练的模型(见第3.1节)。可以看出,DINOv3卫星模型在大多数基准测试上产生了最先进的性能。我们的70亿卫星模型在SatLidar1M val、SatLidar1M test和Open-Canopy上设置了新的最先进水平,分别将MAE从2.4降至2.2、从3.4降至3.2、从2.42降至2.02。这些结果表明DINOv3训练方法是通用的,可以有效地开箱即用地应用于其他领域。有趣的是,我们蒸馏的ViT-L卫星模型的性能与其70亿对应模型相当,在SatLidar1M和Open-Canopy上取得了可比的结果,同时在Neon测试集上表现出人意料地更好,达到最低MAE 2.4,而70亿模型为2.6,Tolan等(2024)为2.9。我们的DINOv3 70亿网络模型在基准测试上达到了不错的性能,在SatLidar1M val、Neon和Open-Canopy上优于Tolan等(2024),但仍落后于卫星模型。这突出了领域特定预训练在冠层高度估计等物理基础任务中的优势,在这些任务中传感器特定先验和辐射一致性很重要。
8.3 与地球观测最新技术的比较
We compare the performance of different methods for Earth observation tasks in Tab. 18 and Tab. 19 . The frozen DINOv3 satellite and web models set new state-of-the-art results on 12 out of 15 classification, segmentation, and horizontal object detection tasks. Our Geo-Bench results surpass prior models, including Prithvi-v2 ( Szwarcman et al. , 2024 ) and DOFA ( Xiong et al. , 2024 ), which use 6+^{6+}6+ bands for Sentinel-2 and Landsat tasks, as well as task-specific fine-tuning ( Tab. 18 ). Despite using a frozen backbone with RGB-only input, the DINOv3 satellite model outperforms previous methods on the three unsaturated classification tasks and on five of six segmentation tasks. Interestingly, the DINOv3 7B web model is very competitve on these benchmarks. It achieves comparable or stronger performance on many GEO-Bench tasks as well as on large-scale, high-resolution remote sensing benchmarks for segmentation and detection. As shown in Tab. 18 and Tab. 19 , the frozen DINOv3 web model establishes new leading results Geo-Bench tasks as well as for segmentation and detection tasks on the LoveDA and DIOR datasets.
【翻译】我们在表18和表19中比较了不同方法在地球观测任务上的性能。冻结的DINOv3卫星和网络模型在15个分类、分割和水平目标检测任务中的12个任务上设置了新的最先进结果。我们的Geo-Bench结果超越了之前的模型,包括Prithvi-v2(Szwarcman等,2024)和DOFA(Xiong等,2024),这些模型在Sentinel-2和Landsat任务中使用6+^{6+}6+波段,以及任务特定的微调(表18)。尽管使用仅RGB输入的冻结主干网络,DINOv3卫星模型在三个未饱和分类任务和六个分割任务中的五个任务上超越了之前的方法。有趣的是,DINOv3 70亿网络模型在这些基准测试上非常有竞争力。它在许多GEO-Bench任务以及大规模高分辨率遥感分割和检测基准测试上取得了可比或更强的性能。如表18和表19所示,冻结的DINOv3网络模型在Geo-Bench任务以及LoveDA和DIOR数据集的分割和检测任务上建立了新的领先结果。
These findings have broader implications for the design of geospatial foundation models. Those have recently emphasized heuristic techniques such as multitemporal aggregation, multisensor fusion, or incorporating satellite-specific metadata ( Brown et al. , 2025 ; Feng et al. , 2025 ). Our results show that general-purpose SSL can match or exceed satellite-specific approaches for tasks that depend on precise object boundaries (segmentation or object detection). This supports emerging evidence finding that domain-agnostic pretraining can offer strong generalization even in specialized downstream domains ( Lahrichi et al. , 2025 ).
【翻译】这些发现对地理空间基础模型的设计具有更广泛的意义。这些模型最近强调启发式技术,如多时相聚合、多传感器融合或纳入卫星特定元数据(Brown等,2025;Feng等,2025)。我们的结果表明,通用SSL在依赖精确对象边界的任务(分割或目标检测)上可以匹配或超越卫星特定方法。这支持了新兴证据,即领域无关的预训练即使在专业下游领域也能提供强大的泛化能力(Lahrichi等,2025)。
Table 18: Comparison of our DINOv3 models against strong baselines DOFA ( Xiong et al. , 2024 ), Prithviv2 ( Szwarcman et al. , 2024 ), and Tolan et al. ( 2024 ) in Geo-Bench tasks. While Privthi-v2 and DOFA leverage all available optical bands, our models achieve significantly better performance with only RGB inputs.
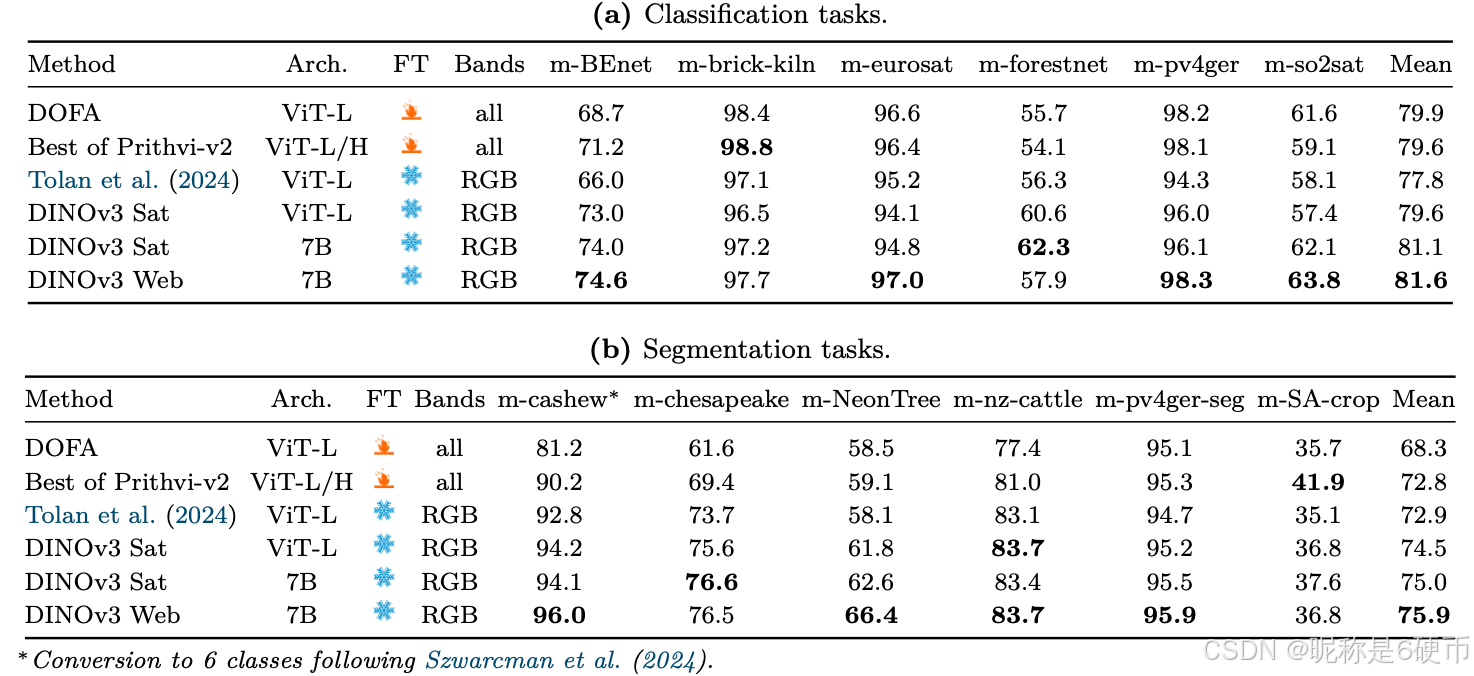
【翻译】表18:我们的DINOv3模型与强基线DOFA(Xiong等,2024)、Prithviv2(Szwarcman等,2024)和Tolan等(2024)在Geo-Bench任务上的比较。虽然Privthi-v2和DOFA利用所有可用的光学波段,但我们的模型仅使用RGB输入就取得了显著更好的性能。
Figure 18: Illustration of versatile applications in remote sensing made possible by a single DINOv3 model. The PCA on DINOv3 features shows finer details than DINOv2. The segmentation map was computed using only GEO-Bench chesapeake labels. The canopy height model decoder was trained on the Open-Canopy dataset using 4 channels (RGB + InfraRed), while inference was performed on RGB channels only.
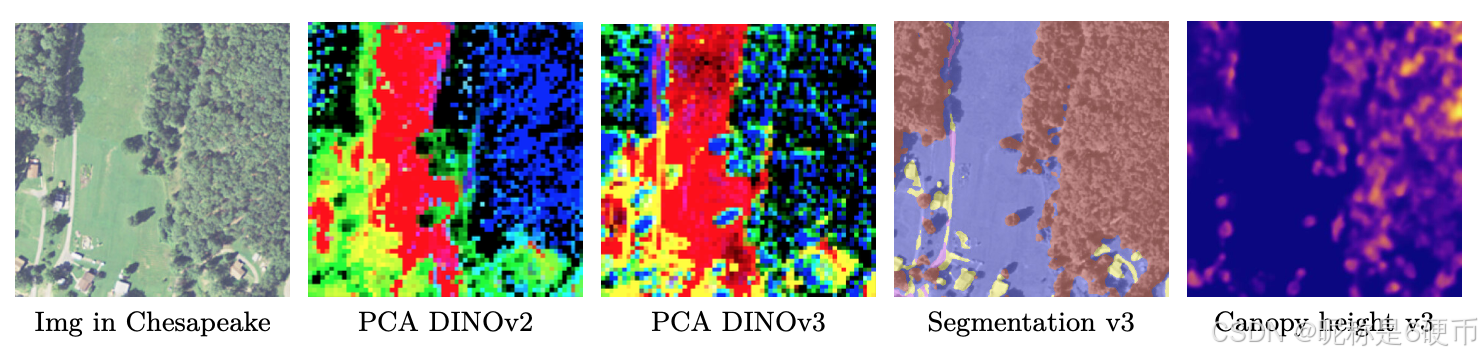
【翻译】图18:单个DINOv3模型在遥感中多样化应用的说明。DINOv3特征的PCA显示了比DINOv2更精细的细节。分割图仅使用GEO-Bench chesapeake标签计算。冠层高度模型解码器在Open-Canopy数据集上使用4个通道(RGB + 红外)进行训练,而推理仅在RGB通道上执行。
Collectively, our results suggest task-dependent benefits of domain-specific pretraining. The DINOv3 satellite model excels in metric tasks like depth estimation, leveraging satellite-specific priors. In contrast, the DINOv3 web model achieves state-of-the-art results on semantic geospatial tasks through diverse, universal representations. The complementary strengths of both models illustrate the broad applicability and effectiveness of the DINOv3 SSL paradigm.
【翻译】总的来说,我们的结果表明领域特定预训练具有任务依赖的好处。DINOv3卫星模型在深度估计等度量任务中表现出色,利用了卫星特定的先验知识。相比之下,DINOv3网络模型通过多样化的通用表示在语义地理空间任务上取得了最先进的结果。两个模型的互补优势说明了DINOv3 SSL范式的广泛适用性和有效性。
9 环境影响
To estimate the carbon emission of our pre-training, we follow the methodology used in previous work in natural language processing ( Strubell et al. , 2019 ; Touvron et al. , 2023 ) and SSL ( Oquab et al. , 2024 ). We fix the value of all exogenous variables, i.e . the Power Usage Effectiveness (PUE) and carbon intensity factor of a power grid to the same value as used by Touvron et al. ( 2023 ), i.e . we assume a PUE of 1.1 and a carbon intensity factor of the US average of 0.385 kg CO 2_22 eq/KWh. For the power consumption of GPUs, we take their thermal design power: 400W for A100 GPUs and 700W for H100 GPUs. We report the details of the computation for the pre-training of our ViT-7B in Tab. 20 . For reference, we provide the analogous data for DINOv2 and MetaCLIP. As another point of comparison, the energy required to train one DINOv3 model (47 MWh) is roughly equivalent to that required for 240,000 km of driving with an average electric vehicle.
【翻译】为了估计我们预训练的碳排放,我们遵循自然语言处理(Strubell等,2019;Touvron等,2023)和SSL(Oquab等,2024)之前工作中使用的方法。我们将所有外生变量的值固定为与Touvron等(2023)使用的相同值,即我们假设PUE为1.1,电网碳强度因子为美国平均值0.385 kg CO 2_22 eq/KWh。对于GPU的功耗,我们采用其热设计功率:A100 GPU为400W,H100 GPU为700W。我们在表20中报告了ViT-7B预训练计算的详细信息。作为参考,我们提供了DINOv2和MetaCLIP的类似数据。作为另一个比较点,训练一个DINOv3模型所需的能量(47 MWh)大致相当于普通电动汽车行驶240,000公里所需的能量。
Table 19: We compare the performance of DINOv3 to state-of-the-art models Privthi-v2 ( Szwarcman et al. , 2024 ), BillionFM ( Cha et al. , 2024 ) and SkySense V2 ( Zhang et al. , 2025 ) for high resolution semantic geospatial tasks. We report mIoU for the segmentation datasets LoveDA (1024 ×\times× ) and iSAID (896 ×\times× ), and mAP for the detection dataset DIOR (800×(800\times(800× ).
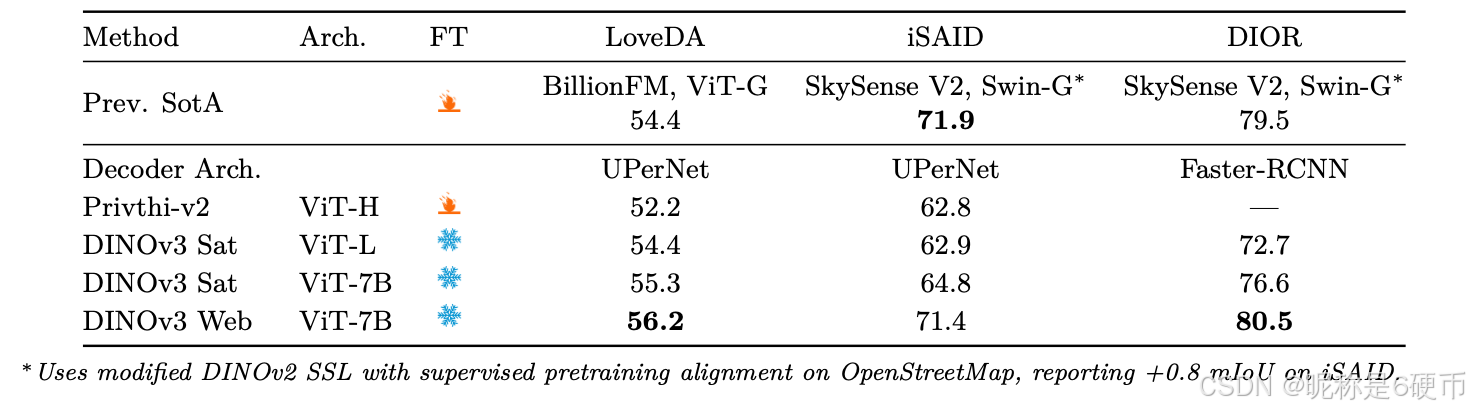
【翻译】表19:我们将DINOv3与最先进模型Privthi-v2(Szwarcman等,2024)、BillionFM(Cha等,2024)和SkySense V2(Zhang等,2025)在高分辨率语义地理空间任务上的性能进行比较。我们报告分割数据集LoveDA(1024×)和iSAID(896×)的mIoU,以及检测数据集DIOR(800×)的mAP。
Figure 19: A qualitative comparison of the DINOv3 7B satellite model to Tolan et al. ( 2024 ) on the Open Canopy dataset. For both models, the decoder is trained on 448 ×\times× 448 input images. It can be seen that DINOv3 produces more accurate maps, for example the accurate height for the trees on the field.

【翻译】图19:DINOv3 70亿卫星模型与Tolan等(2024)在Open Canopy数据集上的定性比较。对于两个模型,解码器都在448×448输入图像上进行训练。可以看出DINOv3产生了更准确的地图,例如田地上树木的准确高度。
Carbon Footprint of the Whole Project In order to compute the carbon footprint of the whole project, we use a rough estimate of a total 9M GPU hours. Using the same grid parameters as presented above, we estimate the total footprint to be roughly 2600 t CO 2_22 eq. For comparison, a full Boeing 777 return flight between Paris and New York corresponds to approximately 560 t CO 2_22 eq. Supposing 12 such flights per day, the environmental impact of our project represents half of all flights between these two cities for one day. This estimate only considers the electricity for powering the GPUs and ignores other emissions, such as cooling, manufacturing, and disposal.
【翻译】整个项目的碳足迹 为了计算整个项目的碳足迹,我们使用总计900万GPU小时的粗略估计。使用上述相同的网格参数,我们估计总足迹约为2600吨CO 2_22 当量。作为比较,波音777在巴黎和纽约之间的往返飞行约对应560吨CO 2_22 当量。假设每天有12次这样的航班,我们项目的环境影响相当于这两个城市之间一天所有航班的一半。此估计仅考虑为GPU供电的电力,忽略了其他排放,如制冷、制造和处置。
Table 20: Carbon footprint of model training. We report the potential carbon emission of reproducing a full model pre-training, computed using a PUE of 1.1 and carbon intensity factor of 0.385kg0.385\mathrm{kg}0.385kg CO 2_22 eq/KWh.

【翻译】表20:模型训练的碳足迹。我们报告了重现完整模型预训练的潜在碳排放,使用PUE为1.1和碳强度因子为0.385 kg CO2_22 eq/KWh计算。
10 Conclusion
DINOv3 represents a significant advancement in the field of self-supervised learning, demonstrating the potential to revolutionize the way visual representations are learned across various domains. By scaling dataset and model size through meticulous data preparation, design, and optimization, DINOv3 showcases the power of self-supervised learning to eliminate the dependency on manual annotations. The introduction of the Gram anchoring method effectively mitigates the degradation of dense feature maps over extended training periods, ensuring robust and reliable performance.
【翻译】DINOv3代表了自监督学习领域的重大进展,展示了在各个领域彻底改变视觉表示学习方式的潜力。通过精心的数据准备、设计和优化来扩展数据集和模型规模,DINOv3展示了自监督学习消除对手动标注依赖的强大能力。Gram锚定方法的引入有效缓解了密集特征图在长期训练过程中的退化,确保了稳健可靠的性能。
Together with the implementation of post-hoc polishing strategies, such as high-resolution post-training and distillation, we achieve state-of-the-art performance across a wide range of visual tasks with no fine-tuning of the image encoder. The DINOv3 suite of vision models not only sets new benchmarks but also offers a versatile solution across various resource constraints, deployment scenarios, and application use cases. The progress made with DINOv3 is a testament to the promise of self-supervised learning in advancing the state of the art in computer vision and beyond.
【翻译】结合事后打磨策略的实施,如高分辨率后训练和蒸馏,我们在广泛的视觉任务中取得了最先进的性能,而无需对图像编码器进行微调。DINOv3视觉模型套件不仅设立了新的基准,还为各种资源约束、部署场景和应用用例提供了多功能解决方案。DINOv3取得的进展证明了自监督学习在推进计算机视觉及其他领域最先进技术方面的前景。