[1Prompt1Story] 滑动窗口机制 | 图像生成管线 | VAE变分自编码器 | UNet去噪神经网络
链接:https://github.com/byliutao/1Prompt1Story
这个项目是一个基于单个提示生成一致文本到图像的模型。它在ICLR 2025会议上获得了聚焦论文的地位。该项目提供了生成一致图像的代码、Gradio演示代码以及基准测试代码。
主要功能点:
- 使用单个提示生成一致的文本到图像
- 提供在线
Gradio演示 - 包含基准测试代码
技术栈:
- PyTorch
- Transformers
- Diffusers
- OpenCV
- Scipy
- Gradio
docs:1Prompt1Story
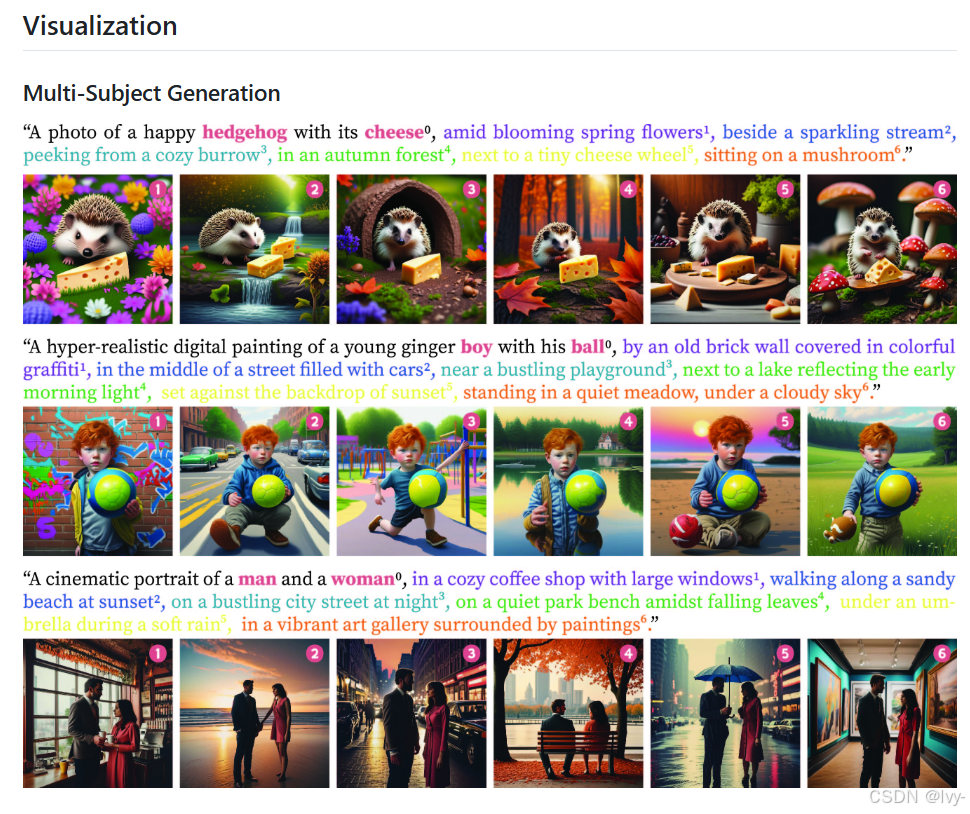
1Prompt1Story项目通过AI生成图像实现连贯叙事。
该项目采用滑动窗口方法创建图像序列,确保核心主体(ID提示词)在不同场景中保持视觉稳定性。
这种一致性通过动态影响图像生成过程的自定义控制实现,具体通过调节提示词权重和注意力机制达成。
可视化
章节目录
- 滑动窗口故事生成器
- 图像生成管线
- 生成行为控制器
- 语义向量重加权(SVR)
- 注意力机制增强(IPCA)
- 去噪神经网络(UNet)
第一章:滑动窗口故事生成器
欢迎来到1Prompt1Story的精彩世界🐻❄️
在本章中,我们将探索一种称为滑动窗口故事生成器的智能技术。
该工具通过AI生成动态故事画面,确保核心角色或对象在场景变换中保持视觉一致性。
一致性挑战
假设我们需要创建包含连续场景的图像故事,例如"红狐在雪地嬉戏→进食浆果→树下休憩"。
若将全部描述一次性输入AI图像生成器,可能导致画面混乱:红狐形象模糊或背景元素混杂。
核心问题在于:
- AI模型擅长处理
简洁明确的指令 - 过长或复杂的提示词会干扰模型对重点内容的理解
- 需要
分帧叙述策略,在保持主角一致性的同时实现场景平滑过渡
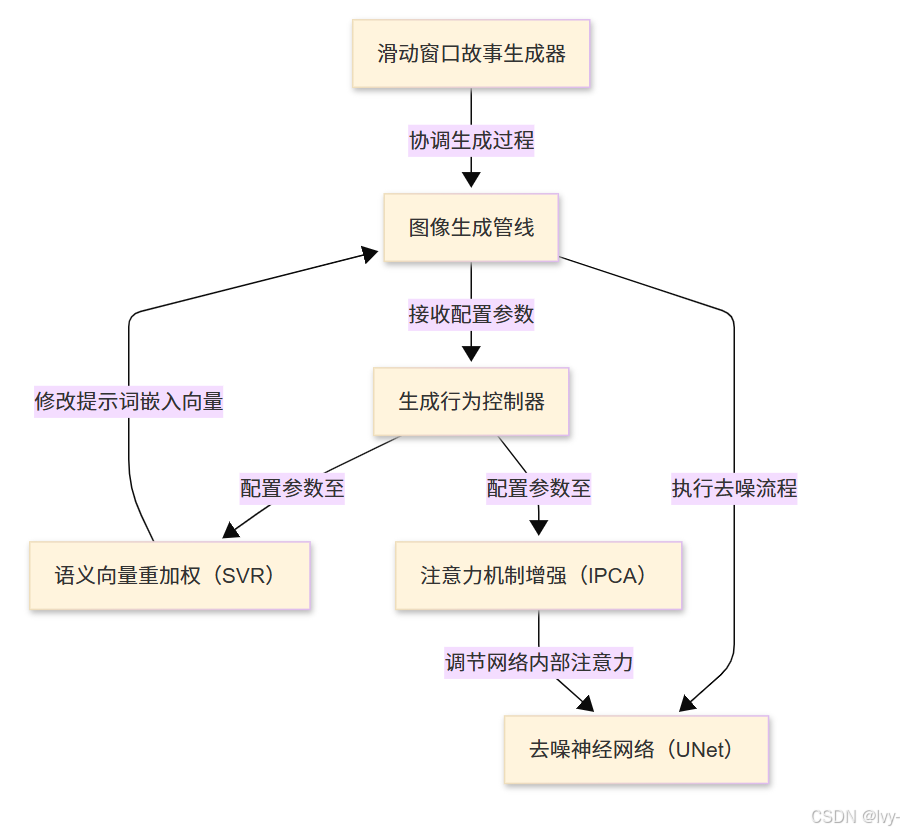
解决方案:滑动窗口机制
滑动窗口故事生成器犹如智能取景器,通过动态聚焦实现分步叙事:
- ID提示词(核心主体):贯穿所有画面的固定描述(如"红狐")
- 帧提示列表(场景演变):分步场景描述集合(如[“雪地嬉戏”, “进食浆果”, “树下休憩”])
- 滑动窗口机制:每次仅选取帧提示列表的子集生成单帧画面,窗口沿列表滑动推进
- 循环模式:窗口到达列表末端时自动回绕起始位置,形成
无缝循环叙事
该机制确保:
- 核心主体(ID提示词)在每帧画面中保持清晰一致
- 场景通过渐进式切换实现流畅演变
滑动窗口工作流程
假设帧提示列表为[A, B, C, D],窗口长度为2:
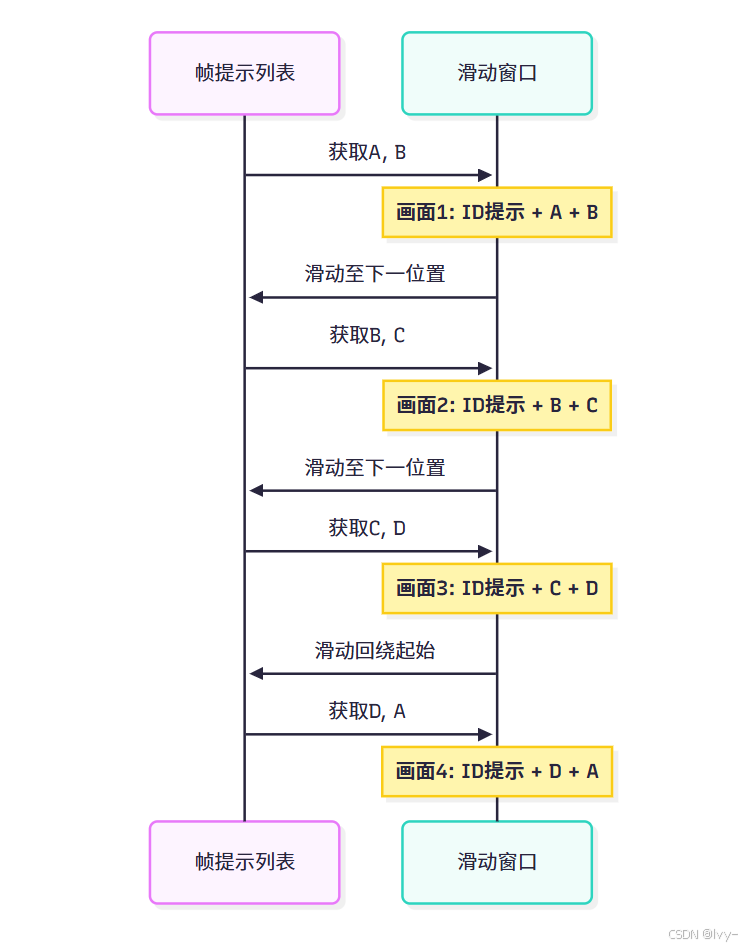
窗口滑动过程始终保持部分前一画面的提示词,通过重叠提示实现平滑过渡。
使用指南
通过main.py脚本启动生成器,示例命令如下:
python main.py \--id_prompt "红狐写真" \--frame_prompt_list "佩戴围巾于草地" "雪地嬉戏" "村庄边缘临溪" \--window_length 2 \--seed 42 \--save_padding "狐物语"
参数解析:
--id_prompt:核心主体描述(每帧画面固定出现)--frame_prompt_list:场景演变描述集合(空格分隔)--window_length:单次组合的帧提示词数量--seed:随机种子(确保结果可复现)--save_padding:输出文件前缀
执行后将生成序列图像及合成故事长图,红狐形象保持稳定而场景渐进变化。
技术实现解析
核心函数movement_gen_story_slide_windows位于unet/utils.py,工作流程如下:
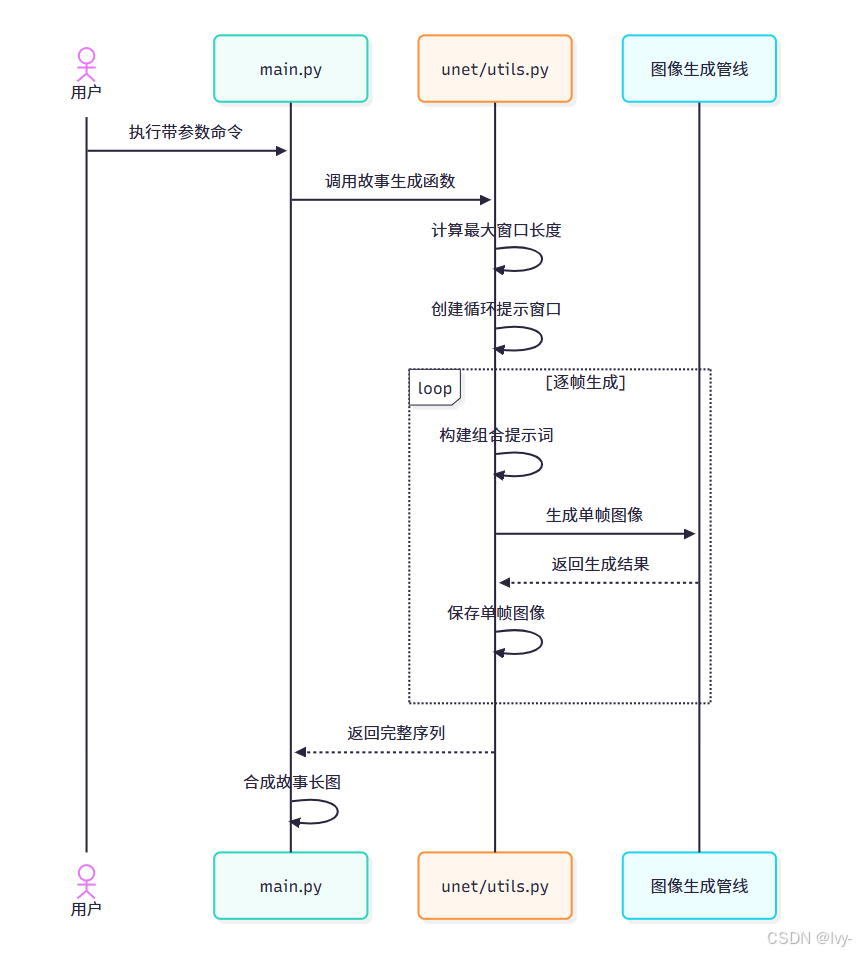
关键技术点:
最大窗口长度计算(防止提示词过长)
def get_max_window_length(unet_controller, id_prompt, frame_prompt_list):combined_prompt = id_promptmax_len = 0for prompt in frame_prompt_list:combined_prompt += ' ' + promptif len(combined_prompt.split()) >= 77: # 标准token限制breakmax_len += 1return max_len
循环窗口生成
def circular_sliding_windows(lst, w):n = len(lst)return [ [lst[(i+j)%n] for j in range(w)] for i in range(n) ]
核心生成逻辑
def movement_gen_story_slide_windows(id_prompt, frame_list, pipe, window_len, seed, controller, save_dir):# 计算可用窗口长度max_win = get_max_window_length(controller, id_prompt, frame_list)window_len = min(window_len, max_win)# 生成提示窗口prompt_windows = circular_sliding_windows(frame_list, window_len)story_images = []for idx, window in enumerate(prompt_windows):# 配置提示词权重controller.frame_prompt_express = window[0]controller.frame_prompt_suppress = window[1:]# 生成组合提示词full_prompt = f"{id_prompt} {' '.join(window)}"# 调用生成管线image = pipe(full_prompt, generator=torch.Generator().manual_seed(seed)).images[0]story_images.append(image)# 合成输出return combine_story(story_images)
code:https://github.com/lvy010/AI-exploration/tree/main/AI_image/1Prompt1Story
结语
本章揭示了滑动窗口故事生成器如何通过智能提示词管理实现连贯叙事。
在后续章节中,我们将深入解析图像生成管线的技术细节,揭示AI如何将结构化提示转化为视觉盛宴。
第二章:图像生成管线
在第一章中,我们学习了滑动窗口故事生成器如何巧妙编排文本提示序列,实现连贯的动画叙事。
但精心设计的文本提示如何转化为可见图像?这正是图像生成管线的核心使命。
图像工厂:从文本构思到视觉现实
想象一个高科技工厂的运作场景:滑动窗口机制交付生产订单(如"红狐雪地嬉戏"的文本提示),这些订单需经过专业设备处理才能转化为成品(图像)。
图像生成管线正是这个智能工厂的全自动化产线与中央控制系统,负责将文本构思转化为最终视觉呈现。
管线核心组件
我们的图像工厂包含四大核心设备:
-
文本编码器(语言翻译器)
将人类可读的提示(如"红狐")转化为AI可理解的数值化"思维向量" -
VAE(变分自编码器)
一种生成模型,通过压缩图像到潜在空间(低维表示)再重建,适合生成模糊但结构合理的图像。
图像压缩:将真实图像编码为抽象潜在表征图像解压:将潜在空间数据解码为可视图像
-
UNet(去噪神经网络)
一种带跳跃连接的对称网络,能保留图像细节,常用于图像分割或扩散模型中逐步去噪生成高清图。作为核心画师,从随机噪声(类似电视雪花屏)起步,在文本引导下通过多步去噪逐步揭示隐藏图像
-
调度器(艺术指导)
精确控制UNet在各去噪步骤中的噪声消除量,确保图像生成过程平滑自然
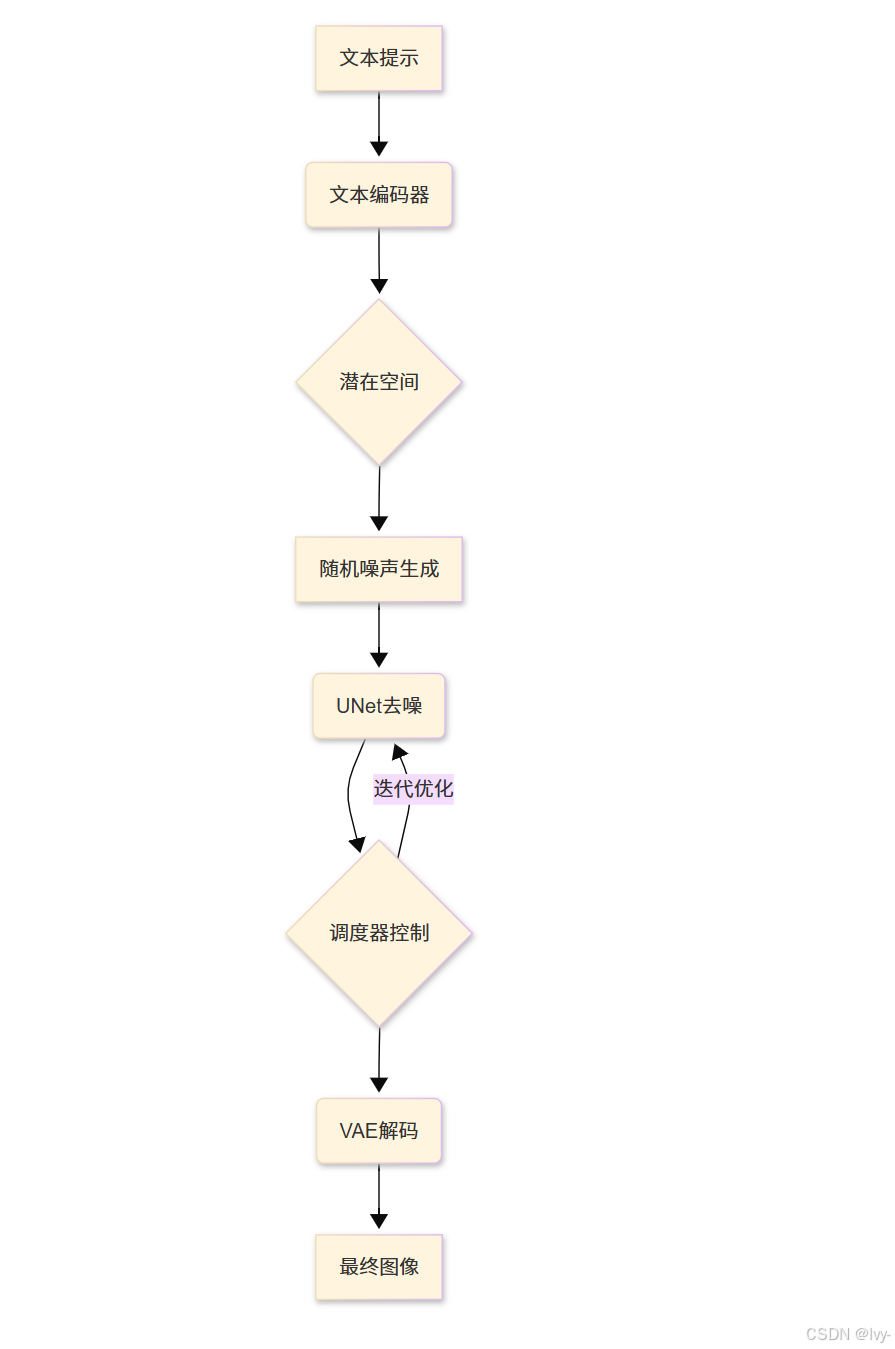
管线使用方法
通过StableDiffusionXLPipeline实例(来自Diffusers库的定制版本)实现核心交互:
# 摘自main.py(简化版)
from unet.pipeline_stable_diffusion_xl import StableDiffusionXLPipeline
import torch# 初始化管线(加载模型与分词器)
pipe = StableDiffusionXLPipeline.from_pretrained("stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16
).to("cuda") # 启用GPU加速# 接收滑动窗口生成的提示词
story_prompt = "红狐雪地嬉戏写真"# 配置可复现的随机种子
story_generator = torch.Generator().manual_seed(42)# 执行图像生成
# unet_controller参数用于高级控制(第三章详解)
generated_images = pipe(prompt=story_prompt,generator=story_generator,unet_controller=None # 基础模式设为None
).images# 保存首张生成图像
generated_images[0].save("fox_snow.jpg")
参数解析:
generator:确保相同种子生成确定性结果unet_controller:实现跨帧一致性的高级控制接口(第三章详解).images:返回PIL图像对象列表
管线工作原理
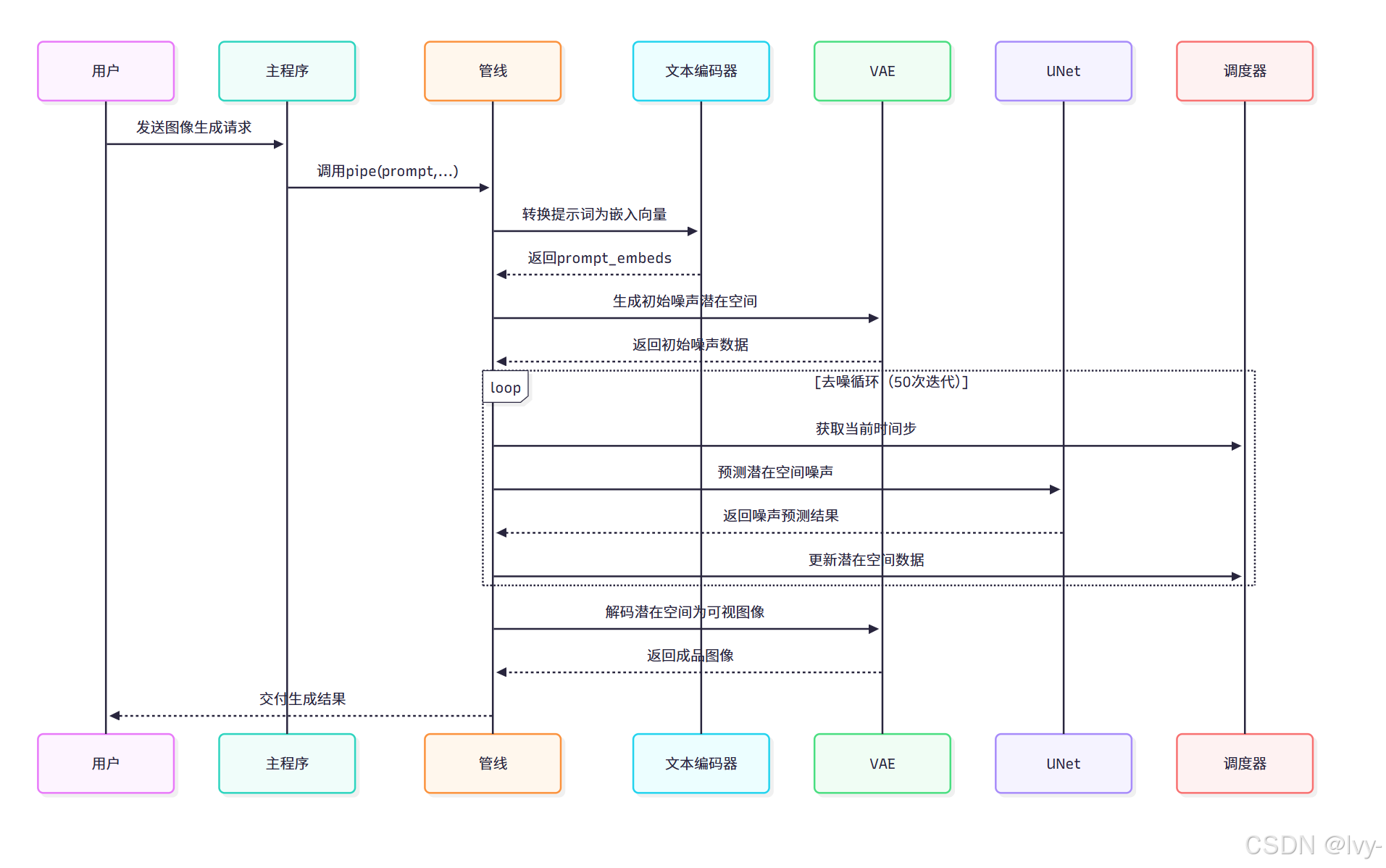
1. 提示词编码(encode_prompt)
def encode_prompt(self, prompt: str, ..., unet_controller=None):# 分词处理text_inputs = self.tokenizer(prompt, padding="max_length", truncation=True, return_tensors="pt")# 生成嵌入向量prompt_embeds = self.text_encoder(text_input_ids, output_hidden_states=True)# 提取UNet专用嵌入层input_prompt_embeds = prompt_embeds.hidden_states[-2] return input_prompt_embeds
该过程将文本转化为AI可理解的数值化表征,为后续生成提供语义指引
2. 潜在空间初始化(prepare_latents)
def prepare_latents(self, ..., same=False):# 生成随机噪声矩阵latent_shape = (batch_size, num_channels, height//8, width//8)latents = torch.randn(latent_shape, generator=generator)# 批量生成时保持噪声一致性if same: latents[1:] = latents[0] return latents * self.scheduler.init_noise_sigma
创建初始噪声空间时,same参数可实现跨帧噪声一致性,为动画连贯性奠定基础
噪声空间
是图像生成过程中模型随机添加的干扰信号,通过逐步调整这些噪声最终生成清晰的图像。类似于“从模糊的电视雪花屏逐渐修复成完整画面”。
3. 去噪循环(call)
for i, t in enumerate(self.timesteps):# UNet预测噪声分布noise_pred = self.unet(latent_model_input,t,encoder_hidden_states=prompt_embeds,unet_controller=unet_controller # 接受高级控制)# 调度器更新潜在空间latents = self.scheduler.step(noise_pred, t, latents)[0]
每次迭代逐步清除噪声,unet_controller在此注入定制化生成逻辑
4. 图像解码(vae.decode)
image = self.vae.decode(latents, return_dict=False)[0]
将优化后的潜在空间数据解码为768x768像素的RGB图像
技术价值
1Prompt1Story是ICLR 2025聚焦论文项目,通过AI实现单提示词驱动的连贯图像叙事。
核心创新在于滑动窗口机制,将ID提示词(如"红狐")与帧提示列表(场景描述)动态组合,在保持主体一致性的同时实现场景平滑过渡。
技术实现结合PyTorch框架与Diffusers库,通过文本编码器、VAE、UNet等组件构建图像生成管线,支持Gradio在线演示。
项目提供完整的代码实现与基准测试方案,解决了传统文本到图像生成中主体漂移的难题。
该管线架构实现三大创新:
- 分层控制:通过UNet控制器实现提示词权重
动态调整 - 潜在空间复用:批量生成时共享噪声基底确保
跨帧一致性 - 自适应调度:根据硬件资源动态调整去噪步长