企业级时序数据库选型指南:从传统架构向智能时序数据管理的转型之路
文章目录
- 时序数据库技术演进:从单点优化到全栈智能
- Apache IoTDB:重新定义时序数据管理标准
- 技术架构革新:分层解耦的系统设计
- 核心技术优势分析
- 存储效率:业界领先的压缩算法
- 查询性能:毫秒级响应的秘密
- 工业级特性:满足严苛生产环境
- 高可用架构设计
- 边缘-云端协同能力
- 安全与合规
- 行业应用实践:IoTDB的成功案例
- 选型实战:如何制定时序数据库选型策略
- 需求评估框架
- 选型决策矩阵
- POC验证要点
- 性能测试
- 功能验证
- 稳定性测试
- IoTDB部署与优化指南
- 硬件配置建议
- 生产环境推荐配置
- 存储规划策略
- 关键参数调优
- 内存配置
- 并发控制
- 监控与运维
- 关键监控指标
- 告警策略
- 数据备份与恢复
- 备份策略
- 恢复流程
- 结语
时序数据库技术演进:从单点优化到全栈智能
时序数据库技术的发展经历了三个重要阶段,每个阶段都针对当时面临的核心问题提出了解决方案。从最初单纯解决存储效率问题,到后来应对大规模数据挑战,再到现在的智能化全栈方案,技术演进的脉络清晰可见。
| 发展阶段 | 技术特征 | 代表产品 | 核心优势 | 主要局限 |
|---|---|---|---|---|
| 第一代:存储优化 | • 专用数据编码算法 • 简单时间分区策略 • 基础聚合查询能力 | 早期InfluxDB OpenTSDB | • 存储成本降低5-10倍 • 列式存储提升效率 • 基本压缩算法应用 | • 数据模型缺乏灵活性 • 扩展能力严重受限 • 运维复杂度居高不下 |
| 第二代:分布式升级 | • 分片和副本机制 • 集群自动扩展 • 多级存储优化 • 丰富查询语言 | InfluxDB企业版 TimescaleDB | • 解决单机性能瓶颈 • 支持水平扩展 • 提供高可用保障 | • 架构复杂性显著增加 • 跨节点查询性能损失 • 运维学习成本高昂 |
| 第三代:智能全栈 | • 自适应多层存储 • 内置ML算法 • 边缘-云端协同 • 工业级可靠性 | Apache IoTDB TimechoDB企业版 | • AI驱动的智能化特性 • 端到端解决方案 • 15-20倍压缩比 • 毫秒级查询响应 | • 技术相对较新 • 生态建设仍在完善 |
第三代时序数据库以Apache IoTDB为代表,真正实现了从存储到分析的全栈智能化。IoTDB不仅继承了前两代产品的技术优势,更重要的是通过深度学习时序数据特征,提供了自适应的存储策略和智能的查询优化。其创新的边缘-云端协同架构特别适合工业物联网场景,能够在保证实时性的同时实现数据的统一管理。

Apache IoTDB:重新定义时序数据管理标准
技术架构革新:分层解耦的系统设计
Apache IoTDB采用了创新的分层解耦架构,彻底改变了传统时序数据库的设计思路,这种设计使得IoTDB在存储效率上实现了质的飞跃,压缩比达到15-20倍,远超传统方案。
存储层(TsFile):
[元数据区] → [时间索引] → [值索引] → [数据区]↓ ↓ ↓ ↓设备信息 时间戳索引 数据类型 压缩数据块
计算层: IoTDB内置了专门为时序数据优化的计算引擎,支持流批一体的查询处理、时间窗口函数、趋势分析算法、 异常检测模型。
服务层: 提供多协议访问接口,包括SQL-like查询语言(类似传统SQL,降低学习成本)、REST API(便于Web应用集成)、工业协议适配(OPC-UA、Modbus等)。

核心技术优势分析
存储效率:业界领先的压缩算法
IoTDB通过多种创新技术实现了极致的存储优化:
-
自适应编码策略
- 浮点数据:采用Gorilla算法,利用时序数据的连续性特征
- 整型数据:使用TS_2DIFF编码,基于二阶差分的压缩
- 枚举数据:字典编码,将重复值映射为小整数
-
分层压缩机制
原始数据 → 特征编码 → 通用压缩(Snappy) → TsFile格式
查询性能:毫秒级响应的秘密
IoTDB的查询引擎采用了多项创新技术:
1. 智能索引策略
- 时间索引:B+树结构,支持快速时间范围查询
- 空间索引:针对多维度查询优化
- 统计索引:预计算常用统计值
2. 查询优化器
- 谓词下推:将过滤条件推送到存储层
- 并行处理:充分利用多核CPU性能
- 缓存机制:热点数据智能缓存
工业级特性:满足严苛生产环境
高可用架构设计
IoTDB采用了多重保障的高可用设计,确保了系统可用性,即使多个节点故障也能继续提供服务。
配置节点集群(ConfigNode) ← 元数据同步 → 数据节点集群(DataNode)↑ ↑3节点选主 N节点分片+副本↓ ↓保证元数据一致性 保证数据高可用
边缘-云端协同能力
IoTDB独创的边缘-云协同架构,特别适合工业物联网场景,既保证了现场控制的实时性,又实现了数据的统一管理。
[边缘设备] --实时采集--> [边缘IoTDB] --断点续传--> [云端IoTDB集群]↓ ↓ ↓本地控制 边缘预处理 中心分析
安全与合规
IoTDB提供企业级的安全保障:
- 多级权限控制(用户-角色-权限模型)
- 数据加密存储
- 审计日志完整记录
- 符合等保2.0要求
行业应用实践:IoTDB的成功案例
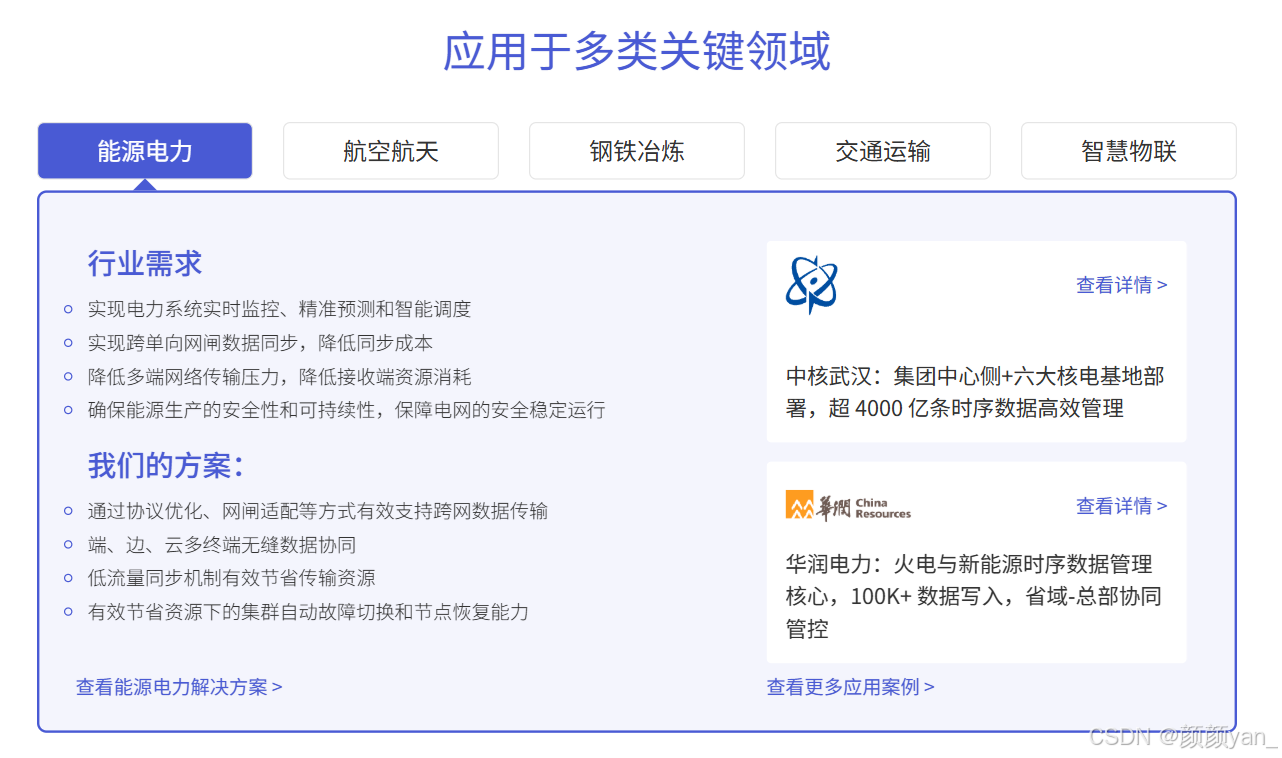
IoTDB在各个行业的成功实践证明了其技术价值和商业价值。通过深入分析几个典型案例,我们可以看到IoTDB如何在不同场景下发挥独特优势,为企业数字化转型提供强有力的支撑。无论是电力行业对高可靠性的要求,制造业对实时性的需求,还是新能源行业对环境适应性的挑战,IoTDB都能提供针对性的解决方案,为企业创造实实在在的业务价值。
| 应用领域 | 项目规模 | 核心挑战 | IoTDB解决方案 | 关键成果 |
|---|---|---|---|---|
| 能源电力 | • 15万变电设备 • 100万数据点/秒 • 覆盖全省电网 | • 传统数据库性能瓶颈 • 实时监控要求严格 • 故障定位效率低下 | • 20节点集群架构 • SSD热存储+对象冷存储 • 边缘站点轻量部署 | • 写入延迟:秒级→毫秒级 • 故障定位:小时级→分钟级 • 运维成本↓60% • 存储成本↓75% |
| 智能制造 | • 12个生产基地 • 60000台设备 • 预测性维护体系 | • 多基地数据统一管理 • 实时监控与预测分析 • 设备故障预警准确性 | • 边缘版本地实时分析 • 数据湖支撑AI训练 • 混合云弹性架构 | • 故障预警准确率92% • 非计划停机↓45% • 能源消耗优化15% • 质量缺陷率↓30% |
| 新能源 | • 3000台风机 • 20个风场 • 50Hz高频采集 | • 恶劣环境网络不稳定 • 海量高频数据处理 • 设备健康精准预测 | • 边缘-云协同架构 • 断网续传机制 • 本地缓存+智能同步 | • 风机可用率97.5% • 运维成本↓40% • 发电效率提升8% • 统一数据管理平台 |
选型实战:如何制定时序数据库选型策略
需求评估框架
在选型之前,企业需要从以下五个维度进行全面评估:
| 评估维度 | 评估指标 | 填写说明/选项 |
|---|---|---|
| 数据规模维度 | 设备数量 | ____ 台 |
| 每台设备测点数 | ____ 个 | |
| 采样频率 | ____ Hz | |
| 数据保存周期 | ____ 年 | |
| 预估总数据量 | ____ TB | |
| 性能要求维度 | 写入吞吐量 | ____ 万点/秒 |
| 查询响应时间 | ____ 毫秒 | |
| 并发用户数 | ____ 个 | |
| 可用性要求 | ____ % | |
| 功能需求维度 | 实时监控 | 是/否 |
| 历史查询 | 是/否 | |
| 趋势分析 | 是/否 | |
| 异常检测 | 是/否 | |
| 报表生成 | 是/否 | |
| 环境约束维度 | 部署方式 | 云端/边缘/混合 |
| 网络环境 | 稳定/不稳定 | |
| 硬件资源 | 充足/受限 | |
| 预算约束 | ____ 万元 | |
| 合规要求维度 | 数据本地化 | 是/否 |
| 等保合规 | 是/否 | |
| 行业认证 | 是/否 | |
| 国产化要求 | 是/否 |
选型决策矩阵
基于需求评估结果,可以使用以下决策矩阵进行产品筛选:
| 场景特征 | 推荐方案 | 理由说明 |
|---|---|---|
| 工业物联网 + 边缘计算 | IoTDB | 轻量化部署,断网续传 |
| 超大规模 + 高并发 | IoTDB集群版 | 线性扩展,性能最优 |
| 成本敏感 + 长期存储 | IoTDB | 压缩率高,TCO最低 |
| 国产化 + 等保要求 | IoTDB企业版 | 全面合规,技术支持 |
POC验证要点
选定候选方案后,建议进行为期2-4周的概念验证(POC),重点验证以下方面:
性能测试
# 写入性能测试
iotdb-benchmark -cf config.properties -r true -w true# 查询性能测试
iotdb-benchmark -cf config.properties -r true -q true
功能验证
- 数据模型适配度:是否符合业务层次结构
- 查询语言易用性:开发人员上手难度
- 监控运维便利性:系统指标获取和告警设置
稳定性测试
- 长时间运行稳定性
- 故障恢复能力
- 数据一致性保证
IoTDB部署与优化指南
硬件配置建议
生产环境推荐配置
| 节点类型 | CPU | 内存 | 存储 | 网络 |
|---|---|---|---|---|
| ConfigNode | 8核+ | 16GB+ | SSD 500GB+ | 万兆 |
| DataNode | 16核+ | 32GB+ | SSD 2TB+ + HDD 10TB+ | 万兆 |
| 边缘节点 | 4核+ | 8GB+ | SSD 500GB+ | 千兆 |
存储规划策略
# 热数据(近7天):SSD存储,支持高频查询
hot_data:storage: SSDretention: 7dcompression: medium# 温数据(7天-1年):SATA存储,中等访问频率
warm_data:storage: SATAretention: 1ycompression: high# 冷数据(1年以上):对象存储,归档备份
cold_data:storage: object_storeretention: 10ycompression: max
关键参数调优
内存配置
# JVM堆内存设置(建议为物理内存的50%-70%)
-Xms16g -Xmx16g# 写入内存缓冲区(影响写入性能)
memtable_size_threshold=1073741824 # 1GB# 查询内存限制(防止OOM)
query_memory_budget=8589934592 # 8GB
并发控制
# 写入线程池大小
wal_writer_buffer_size=16777216# 查询并发度
max_concurrent_client_num=65535
query_thread_count=16
监控与运维
关键监控指标
- 写入QPS和延迟
- 查询QPS和响应时间
- 内存和磁盘使用率
- 节点健康状态
- 数据同步延迟
告警策略
alerts:- name: 写入延迟过高condition: write_latency > 1000msaction: 邮件+短信通知- name: 磁盘空间不足 condition: disk_usage > 85%action: 自动扩容+通知- name: 节点下线condition: node_status == downaction: 立即通知运维
数据备份与恢复
备份策略
# 增量备份(每小时执行)
iotdb-backup.sh --type incremental --target s3://backup-bucket/hourly/# 全量备份(每日执行)
iotdb-backup.sh --type full --target s3://backup-bucket/daily/# 长期归档(每月执行)
iotdb-backup.sh --type archive --target glacier://archive-vault/monthly/
恢复流程
# 查看可用备份
iotdb-restore.sh --list-backups# 恢复到指定时间点
iotdb-restore.sh --timestamp 2024-03-15T10:30:00 --source s3://backup-bucket/
结语
时序数据库的选型不仅仅是技术决策,更是企业数字化转型战略的重要组成部分。从我们的深入分析可以看出,Apache IoTDB凭借其卓越的技术架构、丰富的工业实践和完善的生态支持,已经成为时序数据管理领域的佼佼者。
- 开源版下载:https://iotdb.apache.org/zh/Download/
- 企业版试用:https://timecho.com
在数字化转型的关键节点,选择一个合适的时序数据库平台,将为您的企业在智能化竞争中赢得先机。IoTDB不仅能解决当前的数据挑战,更能为您未来的AI驱动业务奠定坚实的数据基础。
