Kubernetes 集群镜像资源管理
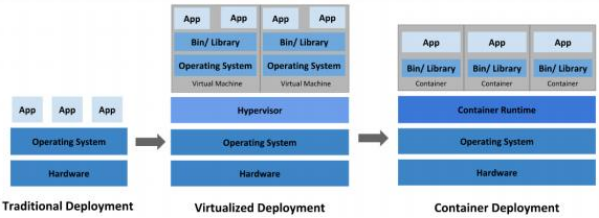
应用部署方式演变
在部署应用程序的方式上,主要经历了三个阶段:
传统部署:互联网早期,会直接将应用程序部署在物理机上
优点:简单,不需要其它技术的参与
缺点:不能为应用程序定义资源使用边界,很难合理地分配计算资源,而且程序之间容易产生影响
虚拟化部署:可以在一台物理机上运行多个虚拟机,每个虚拟机都是独立的一个环境
优点:程序环境不会相互产生影响,提供了一定程度的安全性
缺点:增加了操作系统,浪费了部分资源
容器化部署:与虚拟化类似,但是共享了操作系统
容器化部署方式给带来很多的便利,但是也会出现一些问题,比如说:
一个容器故障停机了,怎么样让另外一个容器立刻启动去替补停机的容器
当并发访问量变大的时候,怎么样做到横向扩展容器数量
容器编排应用
为了解决这些容器编排问题,就产生了一些容器编排的软件:
Swarm:Docker自己的容器编排工具
Mesos:Apache的一个资源统一管控的工具,需要和Marathon结合使用
Kubernetes:Google开源的的容器编排工具
kubernetes 简介
在Docker 作为高级容器引擎快速发展的同时,在Google内部容器技术已经应用很多年。
Borg系统运行管理着成千上万的容器应用。
Kubernetes项目来源于Borg,可以说是集结了Borg设计思想的精华,并且吸收了Borg系统中的经验和教训。
Kubernetes对计算资源进行了更高层次的抽象,通过将容器进行细致的组合,将最终的应用服务交给用户。
kubernetes的本质是一组服务器集群,它可以在集群的每个节点上运行特定的程序,来对节点中的容器
进行管理。目的是实现资源管理的自动化,主要提供了如下的主要功能:
自我修复:一旦某一个容器崩溃,能够在1秒中左右迅速启动新的容器
弹性伸缩:可以根据需要,自动对集群中正在运行的容器数量进行调整
服务发现:服务可以通过自动发现的形式找到它所依赖的服务
负载均衡:如果一个服务起动了多个容器,能够自动实现请求的负载均衡
版本回退:如果发现新发布的程序版本有问题,可以立即回退到原来的版本
存储编排:可以根据容器自身的需求自动创建存储卷

K8S的设计架构
K8S各个组件用途
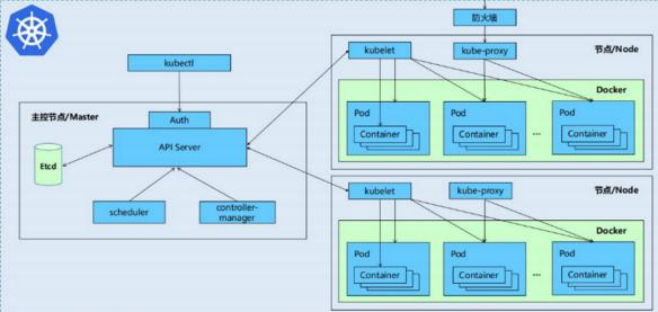
一个kubernetes集群主要是由控制节点(master)、工作节点(node)构成,每个节点上都会安装不同的组件
1 master:集群的控制平面,负责集群的决策
ApiServer : 资源操作的唯一入口,接收用户输入的命令,提供认证、授权、API注册和发现等机制
Scheduler : 负责集群资源调度,按照预定的调度策略将Pod调度到相应的node节点上
ControllerManager : 负责维护集群的状态,比如程序部署安排、故障检测、自动扩展、滚动更新等
Etcd :负责存储集群中各种资源对象的信息
2 node:集群的数据平面,负责为容器提供运行环境
kubelet:负责维护容器的生命周期,同时也负责Volume(CVI)和网络(CNI)的管理
Container runtime:负责镜像管理以及Pod和容器的真正运行(CRI)
kube-proxy:负责为Service提供cluster内部的服务发现和负载均衡
K8S 各组件之间的调用关系
当我们要运行一个web服务时
1. kubernetes环境启动之后,master和node都会将自身的信息存储到etcd数据库中
2. web服务的安装请求会首先被发送到master节点的apiServer组件
3. apiServer组件会调用scheduler组件来决定到底应该把这个服务安装到哪个node节点上在此时,它会从etcd中读取各个node节点的信息,然后按照一定的算法进行选择,并将结果告知apiServer
4. apiServer调用controller-manager去调度Node节点安装web服务
5. kubelet接收到指令后,会通知docker,然后由docker来启动一个web服务的pod
6. 如果需要访问web服务,就需要通过kube-proxy来对pod产生访问的代理
K8S 的 常用名词感念
Master:集群控制节点,每个集群需要至少一个master节点负责集群的管控
Node:工作负载节点,由master分配容器到这些node工作节点上
Pod: kubernetes的最小控制单元,容器都是运行在pod中的,一个pod中可以有1个或者多个容器
Controller:控制器,通过它来实现对pod的管理,比如启动pod、停止pod、伸缩pod的数量等等
Service: pod对外服务的统一入口,下面可以维护者同一类的多个pod
Label:标签,用于对pod进行分类,同一类pod会拥有相同的标签
NameSpace:命名空间,用来隔离pod的运行环境
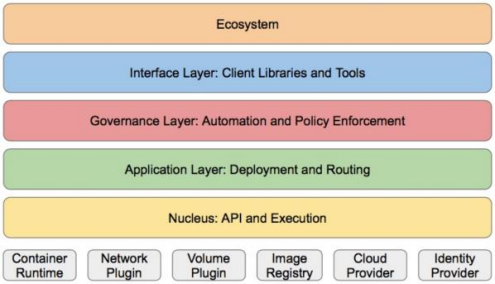
k8S的分层架构
核心层:Kubernetes最核心的功能,对外提供API构建高层的应用,对内提供插件式应用执行环境
应用层:部署(无状态应用、有状态应用、批处理任务、集群应用等)和路由(服务发现、DNS解析等)
管理层:系统度量(如基础设施、容器和网络的度量),自动化(如自动扩展、动态Provision等)以及策略管理(RBAC、Quota、PSP、NetworkPolicy等)
接口层:kubectl命令行工具、客户端SDK以及集群联邦
生态系统:在接口层之上的庞大容器集群管理调度的生态系统,可以划分为两个范畴
Kubernetes外部:日志、监控、配置管理、CI、CD、Workflow、FaaS、OTS应用、ChatOps。
Kubernetes内部:CRI、CNI、CVI、镜像仓库、Cloud Provider、集群自身的配置和管理等
K8S集群环境搭建
K8S 集群创建方式有3种:
centainerd
默认情况下,K8S在创建集群时使用的方式
docker
Docker使用的普记录最高,虽然K8S在1.24版本后已经费力了kubelet对docker的支持,但时可以借助
cri-docker方式来实现集群创建
cri-o
CRI-O的方式是Kubernetes创建容器最直接的一种方式,在创建集群的时候,需要借助于cri-o插件的方式来实现Kubernetes集群的创建
docker 和cri-o 这两种方式要对kubelet程序的启动参数进行设置
k8s中容器的管理方式
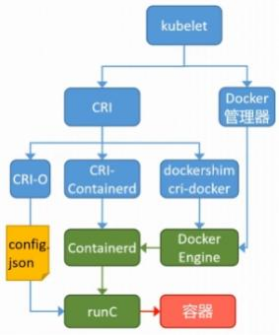
k8s 集群部署
k8s 环境部署说明
主机IP
主机名
角色
172.25.254.100
master.timinglee.org
master,k8s集群控制节点
172.25.254.10
work1.timinglee.org
k8s集群工作节点1
172.25.254.20
work2.timinglee.org
k8s集群工作节点2
172.25.254.200
reg.timinglee.org
harbor仓库
所有节点禁用selinux和防火墙
所有节点同步时间和解析
所有节点安装docker-ce
所有节点禁用swap,注意注释掉/etc/fstab文件中的定义
环境配置
docker配置软件仓库
docker ]# vim /etc/yum.repos.d/docker.repo
[docker]
name=docker-ce
baseurl=https://mirrors.aliyun.com/docker-ce/linux/rhel/9/x86_64/stable
gpgcheck=0
安装docker-ce并启动服务
# yum install -y docker-ce
# vim /usr/lib/systemd/system/docker.service
ExecStart=/usr/bin/dockerd -H fd:// --containerd=/run/containerd/containerd.sock --iptables=true
docker ]# for i in 10 20 100; do scp /usr/lib/systemd/system/docker.service root@172.25.254.$i:/usr/lib/systemd/system/docker.service; done
所有主机 ]# systemctl enable --now docker
# docker info
证书
docker ]# openssl req -newkey rsa:4096 -nodes -sha256 -keyout /root/data/certs/timinglee.org.key -addext "subjectAltName = DNS:reg.timinglee.org" -x509 -days 365 -out /root/data/certs/timinglee.org.crt
# cd harbor/
# cp harbor.yml.tmpl harbor.yml

镜像仓库
docker ]# vim harbor.yml 【配置安装文件格式】
# docker rm -f registry 【删除使用的仓库容器】
# docker logout reg.timinglee.org 【退出登录】
# mkdir -p /data/harbor 【创建安装目录】
# ./install.sh --with-chartmuseum 【安装】
# docker compose stop 【停止】
# docker compose up -d 【开启】
docker ]# for i in 10 20 100; do ssh -l root 172.25.254.$i mkdir -p /etc/docker/certs.d/reg.timinglee.org/ scp /root/data/certs/timinglee.org.crt root@172.25.254.$i:/etc/docker/certs.d/reg.timinglee.org/ca.crt;done
# vim /etc/docker/daemon.json
{
"registry-mirrors": ["http://reg.timinglee.org"],
"insecure-registries": ["reg.timinglee.org:5000", "172.25.254.200:5000"],
"log-opts": {
"max-size": "100m"
}
}
# for i in 10 20 100; do scp /etc/docker/daemon.json root@172.25.254.$i:/etc/docker/;done
# vim /etc/hosts
172.25.254.100 master.timinglee.org
172.25.254.10 work1.timinglee.org
172.25.254.20 work2.timinglee.org
172.25.254.200 reg.timinglee.org
# for i in 10 20 100; do scp /etc/hosts root@172.25.254.$i:/etc/hosts;done

配置挂载登录仓库
所有主机 ]# getenforce 【所有的确认是Disabled】
# vim /etc/fstab
# systemctl daemon-reload
# systemctl mask swap.target
# reboot
# swapon -s 【无输出】
# docker login reg.timinglee.org


下载软件
docker ]# dnf install cri-dockerd-0.3.14-3.el8.x86_64.rpm libcgroup-0.41-19.el8.x86_64.rpm -y
# for i in 10 20 100; do scp *.rpm k8s-1.30.tar.gz root@172.25.254.$i:/mnt;done
其他主机 ]# cd /mnt
# dnf install cri-dockerd-0.3.14-3.el8.x86_64.rpm libcgroup-0.41-19.el8.x86_64.rpm -y
docker ]# vim /lib/systemd/system/cri-docker.service 【指定网络插件名称及基础容器镜像】
# for i in 10 20 100; do scp /lib/systemd/system/cri-docker.service root@172.25.254.$i:/lib/systemd/system/cri-docker.service;done
所有主机 ]# systemctl enable --now cri-docker.service
# tar zxf k8s-1.30.tar.gz
# dnf install *.rpm -y
# dnf install bash-completion -y
# echo "source <(kubectl completion bash)" >> ~/.bashrc 【永久启用 kubectl 命令自动补全】
# source ~/.bashrc
# vim /etc/yum.repos.d/k8s.repo
[k8s]
name=k8s
baseurl=https://mirrors.aliyun.com/kubernetes-new/core/stable/v1.30/rpm
gpgcheck=0
# dnf install kubelet-1.30.0 kubeadm-1.30.0 kubectl-1.30.0 -y
集群搭建
docker ~]# docker load -i k8s_docker_images-1.30.tar
# docker login reg.timinglee.org -u admin -p lee
# docker images | awk '/reg/{system("docker push" $1":"$2)}' 【自动推送】
# docker tag registry.aliyuncs.com/google_containers/kube-apiserver:v1.30.0 reg.timinglee.org/k8s/kube-apiserver:v1.30.0
# docker push reg.timinglee.org/k8s/kube-apiserver:v1.30.0 【手动推送】
所有主机 ]# systemctl enable --now kubelet.service
master ~]# kubeadm init --pod-network-cidr=10.244.0.0/16 --image-repository --v=5 reg.timinglee.org/k8s --kubernetes-version v1.30.0 --cri-socket=unix:///var/run/cri-dockerd.sock
# echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile 【指定文件路径】
# source ~/.bash_profile
# kubectl get node 查看结果:
# docker load -i /root/flannel-0.25.5.tag.gz
# docker tag flannel/flannel:v0.25.5 reg.timinglee.org/flannel/flannel:v0.25.5
# docker push reg.timinglee.org/flannel/flannel:v0.25.5
# docker tag flannel/flannel-cni-plugin:v1.5.1-flannel1 reg.timinglee.org/flannel/flannel-cni-plugin:v1.5.1-flannel1
# docker push reg.timinglee.org/flannel/flannel-cni-plugin:v1.5.1-flannel1
# vim /root/kube-flannel.yml 【配置剧本文件】
# kubectl apply -f /root/kube-flannel.yml 【使用剧本开启集群】
# kubectl get nodes
# kubectl -n kube-flannel get pods 查看pod列表:
# kubeadm token create --print-join-command
其他主机 ]# kubeadm reset --cri-socket=unix:///var/run/cri-dockerd.sock 【重启方便运行】
# kubeadm join 172.25.254.100:6443 --token zsfao3.19qjnz40m80w5fqq --discovery-token-ca-cert-hash sha256:a884e31d150826ffa1f744ebb8b8a92c3b1dc52310b1d80482a699e4f76c6a5c --cri-socket=unix:///var/run/cri-dockerd.sock 【加入集群】
master ~]# kubectl get nodes 查看集群结果:
docker ~]# docker tag nginx:latest reg.timinglee.org/library/nginx:latest
# docker push reg.timinglee.org/library/nginx:latest
master ~]# kubectl create deployment web --image nginx --replicas 2 【2个主机运行镜像nginx】
# kubectl get pods -o wide 查看运行主机:
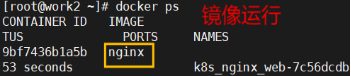
# docker ps 查看运行的镜像:
# kubectl get pods 查看结果:







kubernetes 中的资源
资源管理介绍
在kubernetes中,所有的内容都抽象为资源,用户需要通过操作资源来管理kubernetes。
kubernetes的本质上就是一个集群系统,用户可以在集群中部署各种服务
所谓的部署服务,其实就是在kubernetes集群中运行一个个的容器,并将指定的程序跑在容器中。
kubernetes的最小管理单元是pod而不是容器,只能将容器放在`Pod`中,
kubernetes一般也不会直接管理Pod,而是通过`Pod控制器`来管理Pod的。
Pod中服务的访问是由kubernetes提供的`Service`资源来实现。
Pod中程序的数据需要持久化是由kubernetes提供的各种存储系统来实现
# kubectl version 【查看版本】
# docker tag busyboxplus:latest reg.timinglee.org/library/busyboxplus:latest
# docker push reg.timinglee.org/library/busyboxplus:latest
# docker tag timinglee/myapp:v1 reg.timinglee.org/library/myapp:v1
# docker tag timinglee/myapp:v2 reg.timinglee.org/library/myapp:v2
# docker push reg.timinglee.org/library/myapp:v2
# docker push reg.timinglee.org/library/myapp:v1
运行方式
# kubectl run test --image myapp:v1 【可以直接运行】
# kubectl get pods 查看结果:
# kubectl run test --image myapp:v1 --dry-run=client -o yaml > /mnt/test.yml
# vim test.yml
apiVersion: v1
kind: Pod
metadata:
labels:
run: test
name: test
spec:
containers:
- image: myapp:v1
name: test1
command: ["/bin/sh","-c","sleep 3000"]
# kubectl create -f /mnt/test.yml
# kubectl get pod查看结果:
# kubectl describe pods test 【查看详细信息】
# kubectl delete -f test.yml 【删除pod】
# kubectl get pod查看结果:
# vim test.yml
apiVersion: v1
kind: Pod
metadata:
labels:
run: test
name: test
spec:
containers:
- image: myapp:v1
name: test1
command: ["/bin/sh","-c","sleep 3000"]
# kubectl delete pod test
# kubectl create -f /mnt/test.yml
# kubectl get pods 查看结果:
# kubectl get pods -o wide
# curl 10.244.2.5 访问结果:
# vim test.yml
# kubectl apply -f /mnt/test.yml
# curl 10.244.2.5 访问结果:
# kubectl explain pod 【查看配置信息】









资源管理方式
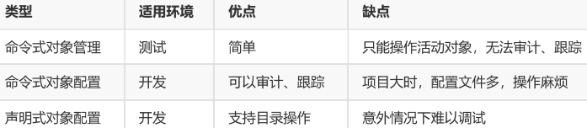
命令式对象管理:直接使用命令去操作kubernetes资源
kubectl run nginx-pod --image=nginx:latest --port=80`
命令式对象配置:通过命令配置和配置文件去操作kubernetes资源
kubectl create/patch -f nginx-pod.yaml`
声明式对象配置:通过apply命令和配置文件去操作kubernetes资源
kubectl apply -f nginx-pod.yaml`
命令式对象管理
kubectl是kubernetes集群的命令行工具,通过它能够对集群本身进行管理,并能够在集群上进行容器化应用的安装部署
kubectl命令的语法如下:
kubectl [command] [type] [name] [flags]
comand:指定要对资源执行的操作,例如create、get、delete
type:指定资源类型,比如deployment、pod、service
name:指定资源的名称,名称大小写敏感
flags:指定额外的可选参数
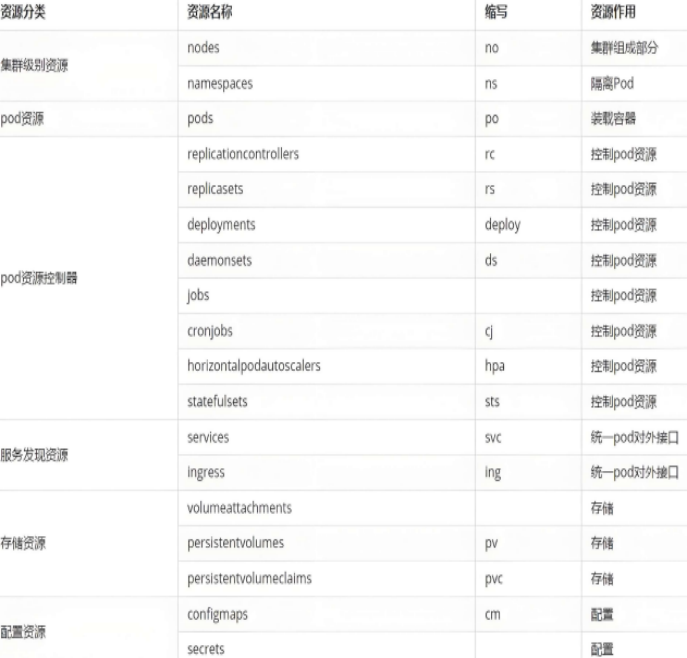
资源类型
kubernetes中所有的内容都抽象为资源
# kubectl api-resources 【查看资源】
常用资源类型
kubectl 常见命令操作
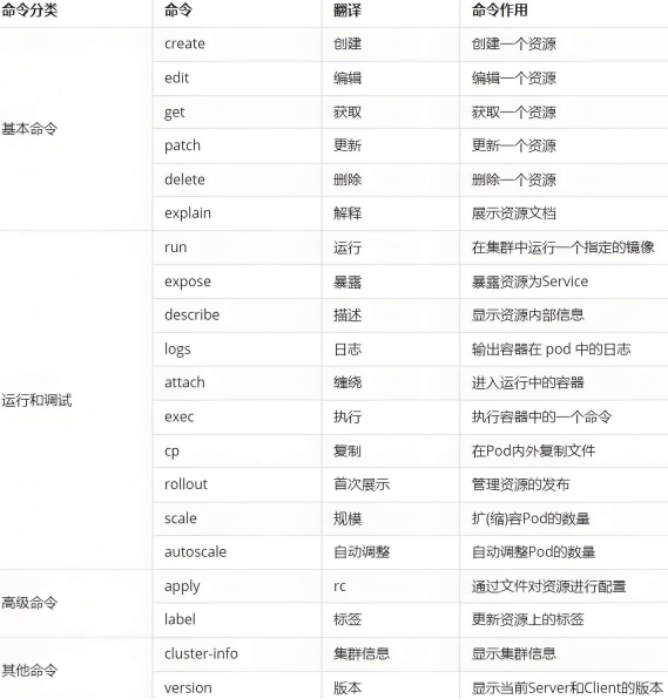
# kubectl create deployment webcluster --image myapp:v1 --replicas 4 【创建控制器,pod为4】
# kubectl get deployments.apps 查看结果:
# kubectl explain deployment 【查看资源帮助】
# kubectl explain deployment.spec 【查看控制器参数帮助】
# kubectl edit deployments.apps webcluster 【更改控制器数据】
# kubectl get deployments.apps 查看更改:
# kubectl patch deployments.apps web -p '{"spec":{"replicas":4}}'
# kubectl delete deployments.apps webcluster 【删除控制器】
# kubectl get deployments.apps 查看更改:





运行和调试命令示例
# kubectl run testpod --image nginx 【运行pod】
# kubectl get pods
# kubectl get services
# kubectl expose pod testpod --port 80 --target-port 80
# kubectl get services 查看结果:
# curl -v 10.104.62.28 测试访问:
# kubectl describe svc web-service 【查看ip访问信息】
# kubectl describe pods testpod 【查看资源详细信息】
# kubectl logs pods/testpod 【查看资源日志】
# kubectl run -it testpod --image busybox 【运行交互pod,ctrl + pq可以退出不停止】
# kubectl run nginx --image nginx 【运行非交互pod】
进入到已经运行的容器,且容器有交互环境
# kubectl attach pods/testpod -it
# kubectl run test --image myapp:v1
# kubectl exec pods/test -c test -- ls / 【查看没有yml文件】
# kubectl cp test.yml test:/ 【复制yml文件】
# kubectl exec pods/test -c test -- ls / | grep *.yml 查看结果:
# kubectl delete pod test





什么是pod
Pod是可以创建和管理Kubernetes计算的最小可部署单元
一个Pod代表着集群中运行的一个进程,每个pod都有一个唯一的ip。
一个pod类似一个豌豆荚,包含一个或多个容器(通常是docker)
多个容器间共享IPC、Network和UTC namespace。

创建自主式pod (生产不推荐)
优点:
灵活性高:
可以精确控制 Pod 的各种配置参数,包括容器的镜像、资源限制、环境变量、命令和参数等,满足特定的应用需求。
学习和调试方便:
对于学习 Kubernetes 的原理和机制非常有帮助,通过手动创建 Pod 可以深入了解 Pod 的结构和配置方式。在调试问题时,可以更直接地观察和调整 Pod 的设置。
适用于特殊场景:
在一些特殊情况下,如进行一次性任务、快速验证概念或在资源受限的环境中进行特定配置时,手动创建 Pod 可能是一种有效的方式。
缺点:
管理复杂:
如果需要管理大量的 Pod,手动创建和维护会变得非常繁琐和耗时。难以实现自动化的扩缩容、故障恢复等操作。
缺乏高级功能:
无法自动享受 Kubernetes 提供的高级功能,如自动部署、滚动更新、服务发现等。这可能导致应用的部署和管理效率低下。
可维护性差:
手动创建的 Pod 在更新应用版本或修改配置时需要手动干预,容易出现错误,并且难以保证一致性。相比之下,通过声明式配置或使用 Kubernetes 的部署工具可以更方便地进行应用的维护和更新。
利用控制器管理pod(推荐)
高可用性和可靠性:
自动故障恢复:如果一个 Pod 失败或被删除,控制器会自动创建新的 Pod 来维持期望的副本数量。确保应用可以始终处于可用状态,不会减少或者因为单个 Pod 的故障最终导致服务中断。
健康检查和自愈:可以配置控制器对 Pod 进行健康检查(如存活探针和就绪探针)。如果 Pod 不健康,控制器会采取适当的行动,如重启 Pod 或删除并重新创建它,以保证应用的正常运行。
可扩展性:
轻松扩缩容:可以通过简单的命令或配置更改来增加或减少 Pod 的数量,以满足不同的工作负载需求。例如,在高流量期间可以快速扩展以处理更多请求,在低流量期间可以缩容以节省资源。水平自动扩缩容(HPA):可以基于自定义指标(如 CPU 利用率、内存使用情况或应用特定的指标)自动调整 Pod 的数量,实现动态的资源分配和成本优化。
版本管理和更新:
滚动更新:对于 Deployment 等控制器,可以执行滚动更新来逐步替换旧版本的 Pod 为新版本,确保应用在更新过程中始终保持可用。可以控制更新的速率和策略,以减少对用户的影响。回滚:如果更新出现问题,可以轻松回滚到上一个稳定版本,保证应用的稳定性和可靠性。
声明式配置:
简洁的配置方式:使用 YAML 或 JSON 格式的声明式配置文件来定义应用的部署需求。这种方式使得配置易于理解、维护和版本控制,同时也方便团队协作。期望状态管理:只需要定义应用的期望状态(如副本数量、容器镜像等),控制器会自动调整实际状态与期望状态保持一致。无需手动管理每个 Pod 的创建和删除,提高了管理效率。
服务发现和负载均衡:
自动注册和发现:Kubernetes 中的服务(Service)可以自动发现由控制器管理的 Pod,并将流量路由到它们。这使得应用的服务发现和负载均衡变得简单和可靠,无需手动配置负载均衡器。流量分发:可以根据不同的策略(如轮询、随机等)将请求分发到不同的 Pod,提高应用的性能和可用性。
多环境一致性:
一致的部署方式:在不同的环境(如开发、测试、生产)中,可以使用相同的控制器和配置来部署应用,确保应用在不同环境中的行为一致。这有助于减少部署差异和错误,提高开发和运维效率。
【# watch -n 1 "kubectl get pods" 监控代码】
手动执行pod
# kubectl run timinglee --image nginx
# kubectl get pods -o wide timinglee
自动执行pod
# kubectl create deployment timinglee --image nginx 【建立控制器并自动运行pod】
# kubectl get pods
# kubectl scale deployment timinglee --replicas 3 【为timinglee扩容】
# kubectl get pods
# kubectl scale deployment timinglee --replicas 2 【缩容】
# kubectl get pods




运行多个容器pod
# vim web.yml
apiVersion: v1
kind: Pod
metadata:
labels:
run: web
name: web
spec:
containers:
- image: nginx:latest
name: web1
- image: nginx:latest
name: web2
# kubectl delete pod web
# kubectl apply -f web.yml
# kubectl get pods -o wide
# kubectl exec -it web -c web1 -- /bin/sh
# curl -I http://localhost 查看访问:
# kubectl exec -it web -c web2 -- curl -I http://localhost



pod间的网络整合
# vim web.yml
apiVersion: v1
kind: Pod
metadata:
labels:
run: web
name: web
spec:
containers:
- image: myapp:v1
name: myapp1
imagePullPolicy: IfNotPresent # 强制使用本地镜像
- image: busybox:latest
name: busybox
imagePullPolicy: IfNotPresent
command: ["/bin/sh","-c","sleep 1000000"]
# kubectl delete pod web
# kubectl apply -f web.yml
# kubectl get pods 查看结果:
# kubectl exec -it web -c busybox -- /bin/sh
/ # ifconfig
# kubectl get pods -o wide



应用版本的更新
# kubectl create deployment timinglee --image myapp:v1 --replicas 2
# kubectl expose deployment timinglee --port 80 --target-port 80 【暴露端口】
# kubectl get services
# curl -v 10.106.215.200
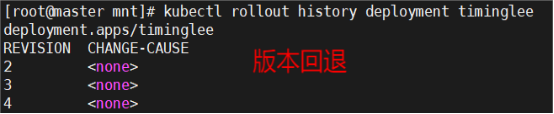
# kubectl rollout history deployment timinglee 【查看历史版本】
# kubectl set image deployments/timinglee myapp=myapp:v2 【更新版本】
# kubectl rollout undo deployment timinglee --to-revision 1 【版本回滚】




利用yaml文件部署应用
用yaml文件部署应用有以下优点
声明式配置:
清晰表达期望状态:以声明式的方式描述应用的部署需求,包括副本数量、容器配置、网络设置等。这使得配置易于理解和维护,并且可以方便地查看应用的预期状态。可重复性和版本控制:配置文件可以被版本控制,确保在不同环境中的部署一致性。可以轻松回滚到以前的版本或在不同环境中重复使用相同的配置。团队协作:便于团队成员之间共享和协作,大家可以对配置文件进行审查和修改,提高部署的可靠性和稳定性。
灵活性和可扩展性:
丰富的配置选项:可以通过 YAML 文件详细地配置各种 Kubernetes 资源,如 Deployment、Service、ConfigMap、Secret 等。可以根据应用的特定需求进行高度定制化。组合和扩展:可以将多个资源的配置组合在一个或多个 YAML 文件中,实现复杂的应用部署架构。同时,可以轻松地添加新的资源或修改现有资源以满足不断变化的需求。
与工具集成:
与 CI/CD 流程集成:可以将 YAML 配置文件与持续集成和持续部署(CI/CD)工具集成,实现自动化的应用部署。例如,可以在代码提交后自动触发部署流程,使用配置文件来部署应用到不同的环境。命令行工具支持:Kubernetes 的命令行工具 `kubectl` 对 YAML 配置文件有很好的支持,可以方便地应用、更新和删除配置。同时,还可以使用其他工具来验证和分析 YAML 配置文件,确保其正确性和安全性。
资源清单参数
参数名 类型 说明
version String 这里是指的是K8S API的版本,目前基本上是v1,可以用kubectl api-versions命令查询
kind String 这里指的是yaml文件定义的资源类型和角色,比如:Pod
metadata Object 元数据对象,固定值就写metadata
metadata.name String 元数据对象的名字,这里由我们编写,比如命名Pod的名字
metadata.namespace String 元数据对象的命名空间,由我们自身定义
Spec Object 详细定义对象,固定值就写Spec
spec.containers[] list 这里是Spec对象的容器列表定义,是个列表
spec.containers[].name String 这里定义容器的名字
spec.containers[].image string 这里定义要用到的镜像名称
spec.containers[].imagePullPolicy String 定义镜像拉取策略,有三个值可选: (1) Always: 每次都尝试重新拉取镜像 (2) IfNotPresent:如果本地有镜像就使用本地镜像 (3) )Never:表示仅使用本地镜像
spec.containers[].command[] list 指定容器运行时启动的命令,若未指定则运行容器打包时指定的命令
spec.containers[].args[] list 指定容器运行参数,可以指定多个
spec.containers[].workingDir String 指定容器工作目录
spec.containers[].volumeMounts[] list 指定容器内部的存储卷配置
spec.containers[].volumeMounts[].name String 指定可被容器挂载的存储卷的名称
spec.containers[].volumeMounts[].mountPath String 指定可被容器挂载的存储卷路径
spec.containers[].volumeMounts[].readOnly String 设置存储卷路径的读写模式,ture或false,默认为读写模式
spec.containers[].ports[] list 指定容器需要用到的端口列表
spec.containers[].ports[].name String 指定端口名称
spec.containers[].ports[].containerPort String 指定容器需要监听的端口号
spec.containers[] ports[].hostPort String 指定容器所在主机需要监听的端口号,默认跟上面containerPort相同,注意设置了hostPort同一台主机无法启动该容器的相同副本(因为主机的端口号不能相同,这样会冲突)
spec.containers[].ports[].protocol String 指定端口协议,支持TCP和UDP,默认值为 TCP
spec.containers[].env[] list 指定容器运行前需设置的环境变量列表
spec.containers[].env[].name String 指定环境变量名称
spec.containers[].env[].value String 指定环境变量值
spec.containers[].resources Object 指定资源限制和资源请求的值(这里开始就是设置容器的资源上限)
spec.containers[].resources.limits Object 指定设置容器运行时资源的运行上限
spec.containers[].resources.limits.cpu String 指定CPU的限制,单位为核心数,1=1000m
spec.containers[].resources.limits.memory String 指定MEM内存的限制,单位为MIB、GiB
spec.containers[].resources.requests Object 指定容器启动和调度时的限制设置
spec.containers[].resources.requests.cpu String CPU请求,单位为core数,容器启动时初始化可用数量
spec.containers[].resources.requests.memory String 内存请求,单位为MIB、GIB,容器启动的初始化可用数量
spec.restartPolicy string 定义Pod的重启策略,默认值为Always. (1)Always: Pod-旦终止运行,无论容器是如何 终止的,kubelet服务都将重启它 (2)OnFailure: 只有Pod以非零退出码终止时,kubelet才会重启该容器。如果容器正常结束(退出码为0),则kubelet将不会重启它 (3) Never: Pod终止后,kubelet将退出码报告给Master,不会重启该
spec.nodeSelector Object 定义Node的Label过滤标签,以key:value格式指定
spec.imagePullSecrets Object 定义pull镜像时使用secret名称,以name:secretkey格式指定
spec.hostNetwork Boolean 定义是否使用主机网络模式,默认值为false。设置true表示使用宿主机网络,不使用docker网桥,同时设置了true将无法在同一台宿主机 上启动第二个副本
运行简单的单个容器pod
# mkdir /root/pod
# cd /root/pod/
# touch web.yml
# kubectl create -n lee deployment webcluster --image myapp:v1 --dry-run=client -o yaml > web.yml
# kubectl create namespace lee --dry-run=client -o yaml 【建立lee】
# kubectl create namespace lee 【启动命名】
# kubectl get namespace lee 查看结果:
# kubectl apply -f web.yml 【启动容器】

端口映射
# vim web.yml
apiVersion: v1
kind: Pod
metadata:
labels:
run: web
name: web
spec:
containers:
- image: myapp:v1
name: web
ports: #暴露端口,不暴露端口无法访问
- name: http
containerPort: 80
hostPort: 80
protocol: TCP
# kubectl delete pod web
# kubectl apply -f web.yml
# kubectl get pods -o wide
# curl -v work2.timinglee.org


设定环境变量
# vim web.yml
apiVersion: v1
kind: Pod
metadata:
labels:
run: timinglee
name: test
spec:
containers:
- image: busybox:latest
name: busybox
imagePullPolicy: IfNotPresent # 优先使用本地镜像
command: ["/bin/sh","-c","echo $NAME;sleep 3000000"]
env:
- name: NAME
value: timinglee
# kubectl delete pod web
# kubectl apply -f web.yml
# kubectl logs test -c busybox

资源限制
资源限制会影响pod的Qos Class资源优先级,资源优先级分为Guaranteed > Burstable > BestEffort
QoS(Quality of Service)即服务质量
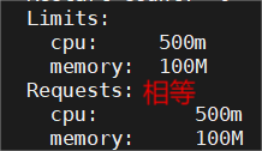
最高优先级
# vim web.yml
apiVersion: v1
kind: Pod
metadata:
labels:
run: timinglee
name: test
spec:
containers:
- image: myapp:v1
name: myapp
resources:
limits: #pod使用资源的最高限制
cpu: 500m
memory: 100M
requests: #pod期望使用资源量,不能大于limits
cpu: 500m
memory: 100M
# kubectl delete pod test --ignore-not-found
# kubectl apply -f web.yml
# kubectl describe pods test
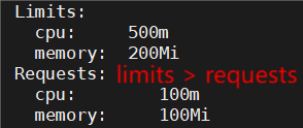
中等优先级
# vim web.yml
apiVersion: v1
kind: Pod
metadata:
name: test-burstable
spec:
containers:
- name: nginx
image: nginx
resources:
requests:
cpu: "100m"
memory: "100Mi"
limits:
cpu: "500m"
memory: "200Mi"
# kubectl describe pods test 查看结果:
最低优先级
# vim web.yml
apiVersion: v1
kind: Pod
metadata:
name: test-besteffort
spec:
containers:
- name: nginx
image: nginx
# 不设置 resources
# kubectl describe pods test 查看结果:
优先级设置

容器启动管理
# vim web.yml
apiVersion: v1
kind: Pod
metadata:
labels:
run: timinglee
name: test
spec:
restartPolicy: Always
containers:
- image: myapp:v1
name: myapp
# kubectl delete pod test --ignore-not-found
# kubectl apply -f web.yml
# kubectl get pods -o wide 【查看启动容器的节点】
# ssh -l root work2.timinglee.org docker ps -a | grep "k8s_myapp_test" 【查看启动的容器】


选择运行节点
# vim web.yml
apiVersion: v1
kind: Pod
metadata:
labels:
run: timinglee
name: test
spec:
nodeSelector:
kubernetes.io/hostname: work1.timinglee.org #选择节点
restartPolicy: Always
containers:
- image: myapp:v1
name: myapp
# kubectl delete pod test
# kubectl apply -f web.yml
# kubectl get pods -o wide

共享宿主机网络
# vim web.yml
apiVersion: v1
kind: Pod
metadata:
labels:
run: timinglee
name: test
spec:
hostNetwork: true
restartPolicy: Always
containers:
- image: busybox:latest
name: busybox
imagePullPolicy: IfNotPresent # 优先使用本地镜像
command: ["/bin/sh","-c","sleep 100000"]
# kubectl delete pod test
# kubectl apply -f web.yml
# kubectl get pods -o wide 查看共享:
# kubectl exec -it test -c busybox -- /bin/sh
/ # ifconfig 查看结果:

pod的生命周期
INIT 容器
Pod 可以包含多个容器,应用运行在这些容器里面,同时 Pod 也可以有一个或多个先于应用容器启动的 Init 容器。
Init 容器与普通的容器非常像,除了如下两点:
它们总是运行到完成
init 容器不支持 Readiness,因为它们必须在 Pod 就绪之前运行完成,每个 Init 容器必须运行成功,下一个才能够运行。
如果Pod的 Init 容器失败,Kubernetes 会不断地重启该 Pod,直到 Init 容器成功为止。但是,如果 Pod 对应的 restartPolicy 值为 Never,它不会重新启动。
INIT 容器的功能
Init 容器可以包含一些安装过程中应用容器中不存在的实用工具或个性化代码。
Init 容器可以安全地运行这些工具,避免这些工具导致应用镜像的安全性降低。
应用镜像的创建者和部署者可各自独立工作,而没有必要联合构建一个单独的应用镜像。
Init 容器能以不同于Pod内应用容器的文件系统视图运行。因此,Init容器可具有访问 Secrets 的权限,而应用容器不能够访问。
由于 Init 容器必须在应用容器启动之前运行完成,因此 Init 容器提供了一种机制来阻塞或延迟应用容器的启动,直到满足了一组先决条件。一旦前置条件满足,Pod内的所有的应用容器会并行启动。
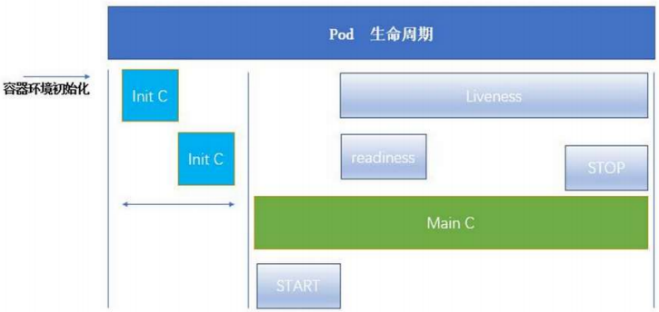
INIT 容器示例
【# watch -n 1 "kubectl get pods -o wide" 监控代码】
# vim web.yml
apiVersion: v1
kind: Pod
metadata:
labels:
name: initpod
name: initpod
spec:
containers:
- name: myapp
image: myapp:v1
initContainers:
- name: init-my
image: busybox:latest
imagePullPolicy: IfNotPresent
command: ["sh", "-c", "until test -e /testfile; do echo waiting for myservice; sleep 2; done"]
# kubectl delete pod web
# kubectl apply -f web.yml
# kubectl get pods
# kubectl logs pods/initpod init-my 【查看检测】
# kubectl exec -it initpod -c init-my -- /bin/sh -c "touch /testfile" 【测试创建文件】



探针
探针是由 kubelet 对容器执行的定期诊断:
ExecAction:在容器内执行指定命令。如果命令退出时返回码为 0 则认为诊断成功。
TCPSocketAction:对指定端口上的容器的 IP 地址进行 TCP 检查。如果端口打开,则诊断被认为是成功的。
HTTPGetAction:对指定的端口和路径上的容器的 IP 地址执行 HTTP Get 请求。如果响应的状态码大于等于200 且小于 400,则诊断被认为是成功的。
每次探测都将获得以下三种结果之一:
成功:容器通过了诊断。
失败:容器未通过诊断。
未知:诊断失败,因此不会采取任何行动。
Kubelet 可以选择是否执行在容器上运行的三种探针执行和做出反应:
livenessProbe:指示容器是否正在运行。如果存活探测失败,则 kubelet 会杀死容器,并且容器将受到其重启策略的影响。如果容器不提供存活探针,则默认状态为 Success。
readinessProbe:指示容器是否准备好服务请求。如果就绪探测失败,端点控制器将从与 Pod 匹配的所有 Service 的端点中删除该 Pod 的 IP 地址。初始延迟之前的就绪状态默认为 Failure。如果容器不提供就绪探针,则默认状态为 Success。
startupProbe: 指示容器中的应用是否已经启动。如果提供了启动探测(startup probe),则禁用所有其他探测,直到它成功为止。如果启动探测失败,kubelet 将杀死容器,容器服从其重启策略进行重启。如果容器没有提供启动探测,则默认状态为成功Success。
ReadinessProbe 与 LivenessProbe 的区别
ReadinessProbe 当检测失败后,将 Pod 的 IP:Port 从对应的 EndPoint 列表中删除。
LivenessProbe 检测失败后,将杀死容器并根据 Pod 的重启策略来决定作出对应的措施
StartupProbe 与 ReadinessProbe、LivenessProbe 的区别
如果三个探针同时存在,先执行 StartupProbe 探针,其他两个探针将会被暂时禁用,直到 pod 满足 StartupProbe 探针配置的条件,其他 2 个探针启动,如果不满足按照规则重启容器。
另外两种探针在容器启动后,会按照配置,直到容器消亡才停止探测,而 StartupProbe 探针只是在容器启动后按照配置满足一次后,不在进行后续的探测。
存活探针示例:
# vim web.yml
apiVersion: v1
kind: Pod
metadata:
labels:
name: liveness
name: liveness
spec:
containers:
- name: myapp # 注意:这里需要短横线(列表项)
image: myapp:v1
livenessProbe:
tcpSocket: #检测端口存在性
port: 8080 # 检测 8080 端口
initialDelaySeconds: 3 #容器启动后要等待多少秒后就探针开始工作,默认是 0
periodSeconds: 1 #执行探测的时间间隔,默认为 10s
timeoutSeconds: 1 #探针执行检测请求后,等待响应的超时时间,默认为 1s
# kubectl delete pod initpod
# kubectl apply -f web.yml
# kubectl exec -it liveness -- /bin/sh
/ # nginx -s stop
# kubectl describe pods

就绪探针示例:
# vim web.yml
apiVersion: v1
kind: Pod
metadata:
labels:
name: readiness
name: readiness
spec:
containers:
- name: myapp # 必须用短横线开头(列表项)
image: myapp:v1
ports:
- containerPort: 80 # 显式声明端口(可选但推荐)
readinessProbe:
httpGet:
path: /test.html # 确保该路径存在于应用中
port: 80
initialDelaySeconds: 5 # 建议延长初始延迟
periodSeconds: 3
timeoutSeconds: 1
# kubectl delete pod liveness
# kubectl apply -f web.yml
# kubectl get pods 查看运行:
# kubectl describe pods readiness
# kubectl describe services readiness
# kubectl exec pods/readiness -c myapp -- /bin/sh -c "echo test > /usr/share/nginx/html/test.html" 【配置文件】
# kubectl describe services readiness 查看结果:




什么是控制器
控制器也是管理pod的一种手段
自主式pod:pod退出或意外关闭后不会被重新创建
控制器管理的 Pod:在控制器的生命周期里,始终要维持 Pod 的副本数目
Pod控制器是管理pod的中间层,使用Pod控制器之后,只需要告诉Pod控制器,想要多少个什么样的Pod就可以了,它会创建出满足条件的Pod并确保每一个Pod资源处于用户期望的目标状态。如果Pod资源在运行中出现故障,它会基于指定策略重新编排Pod
当建立控制器后,会把期望值写入etcd,k8s中的apiserver检索etcd中我们保存的期望状态,并对比pod的当前状态,如果出现差异代码自驱动立即恢复
控制器常用类型
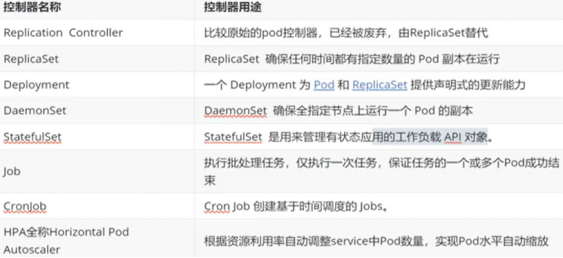
replicaset控制器
replicaset功能
ReplicaSet 是下一代的 Replication Controller,官方推荐使用ReplicaSet
ReplicaSet和Replication Controller的唯一区别是选择器的支持,ReplicaSet支持新的基于集合的选择器需求
ReplicaSet 确保任何时间都有指定数量的 Pod 副本在运行
虽然 ReplicaSets 可以独立使用,但今天它主要被Deployments 用作协调 Pod 创建、删除和更新的机制
replicaset参数说明
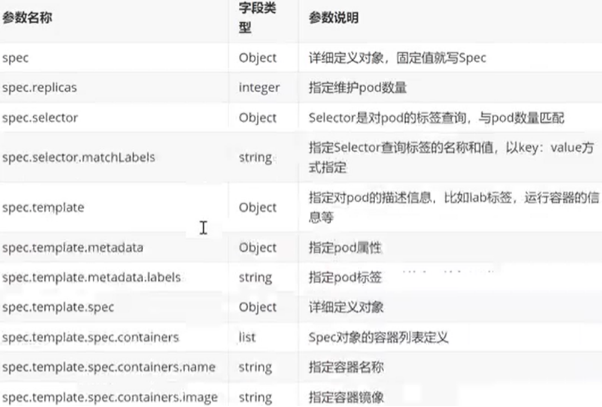
replicaset 示例
# mkdir controller
# cd controller/
# kubectl create deployment replicaset --image myapp:v1 --dry-run=client -o yaml > /root/controller/replicaset.yml
# vim replicaset.yml
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: replicaset #指定pod名称,一定小写,如果出现大写报错
spec:
replicas: 2 #指定维护pod数量为2
selector: #指定检测匹配方式
matchLabels: #指定匹配方式为匹配标签
app: myapp #指定匹配的标签为app=myapp
template: #模板,当副本数量不足时,会根据下面的模板创建pod副本
metadata:
labels:
app: myapp #注意这里的app要和上面的app一样,也可以同样是name
spec:
containers:
- image: myapp:v1
name: myapp
# kubectl delete pod readiness
# kubectl apply -f replicaset.yml
# kubectl get pods --show-labels 查看结果:
replicaset是通过标签匹配pod
# kubectl label pod replicaset-l4xnr app=timinglee --overwrite 【建立新的pod】
# kubectl label pod rep… app- 【删除新的pod】
# kubectl delete pods replicaset-24s2w 【删除,replicaset自动控制副本数量,pod可以自愈】
# kubectl delete -f replicaset.yml 【删除运行的资源】
# kubectl label pod replicaset-l4xnr app=myapp --overwrite 【创建新的会自动删除】
自动确保pod数为维护的数


deployment 控制器
deployment控制器的功能
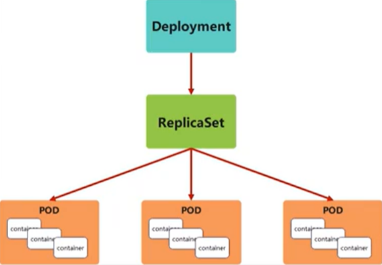
为更好的解决服务编排问题,kubernetes在V1.2版本开始,引入了Deployment控制器。
Deployment控制器并不直接管理pod,而是通过管理ReplicaSet来间接管理Pod
Deployment管理ReplicaSet,ReplicaSet管理Pod
Deployment 为 Pod 和 ReplicaSet 提供了一个申明式的定义方法
在Deployment中ReplicaSet相当于一个版本
典型的应用场景:
用来创建Pod和ReplicaSet
滚动更新和回滚
扩容和缩容
暂停与恢复
deployment控制器示例
# vim deployment.yml
apiVersion: apps/v1
kind: Deployment
metadata:
name: deployment
spec:
replicas: 4
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
containers:
- image: myapp:v1
name: myapp
# kubectl apply -f deployment.yml
# kubectl describe deployments.apps deployment


更新容器运行版本
# vim deployment.yml
apiVersion: apps/v1
kind: Deployment
metadata:
name: deployment
spec:
minReadySeconds: 5 #最小就绪时间5秒
replicas: 4
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
containers:
- image: myapp:v2 #更新为版本2
name: myapp
# kubectl apply -f deployment.yml
# curl 10.244.1.33 测试访问:
更新的过程是重新建立一个版本的RS,新版本的RS会把pod 重建,然后把老版本RS回收

版本回滚
# vim deployment.yml
apiVersion: apps/v1
kind: Deployment
metadata:
name: deployment
spec:
replicas: 4
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
containers:
- image: myapp:v1 #回滚到之前版本
name: myapp
# kubectl apply -f deployment.yml
# curl 10.244.2.58 测试访问:

滚动更新策略
# vim deployment.yml
apiVersion: apps/v1
kind: Deployment
metadata:
name: deployment
spec:
minReadySeconds: 5 #最小就绪时间,指定pod每隔多久更新一次
replicas: 4
strategy: #指定更新策略
rollingUpdate:
maxSurge: 1 #比定义pod数量多几个
maxUnavailable: 0 #比定义pod个数少几个
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
containers:
- image: myapp:v1
name: myapp
# kubectl apply -f deployment.yml
# kubectl get pods -l app=myapp
# kubectl rollout status deployment/deployment
# kubectl get all



暂停及恢复
在实际生产环境中做的变更可能不止一处,当修改了一处后,如果执行变更就直接触发了
我们期望的触发时当我们把所有修改都搞定后一次触发
暂停,避免触发不必要的线上更新
# kubectl rollout pause deployment deployment-example
# vim deployment-example.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: deployment-example
spec:
minReadySeconds: 5
strategy:
rollingUpdate:
maxSurge: 1
maxUnavailable: 0
replicas: 6
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
containers:
- name: myapp
image: nginx
resources:
limits:
cpu: 0.5
memory: 200Mi
requests:
cpu: 0.5
memory: 200Mi
# kubectl apply -f deployment-example.yaml
调整副本数,不受影响
# kubectl get deployment deployment-example -o wide
但是更新镜像和修改资源并没有触发更新
# kubectl rollout status deployment deployment-example

daemonset控制器
daemonset功能
DaemonSet 确保全部(或者某些)节点上运行一个 Pod 的副本。当有节点加入集群时, 也会为他们新增一个 Pod ,当有节点从集群移除时,这些 Pod 也会被回收。删除 DaemonSet 将会删除它创建的所有 Pod
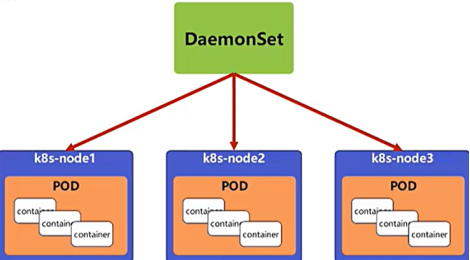
DaemonSet 的典型用法:
在每个节点上运行集群存储 DaemonSet,例如 glusterd、ceph。
在每个节点上运行日志收集 DaemonSet,例如 fluentd、logstash。
在每个节点上运行监控 DaemonSet,例如 Prometheus Node Exporter、zabbix agent等
一个简单的用法是在所有的节点上都启动一个 DaemonSet,将被作为每种类型的 daemon 使用
一个稍微复杂的用法是单独对每种 daemon 类型使用多个 DaemonSet,但具有不同的标志, 并且对不同硬件类型具有不同的内存、CPU 要求
daemonset 示例
# vim daemonset-example.yml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: daemonset-example
spec:
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
tolerations: #对于污点节点的容忍
- effect: NoSchedule
operator: Exists
containers:
- name: nginx
image: nginx
# kubectl delete -f *.yml
# kubectl apply -f daemonset-example.yml
# kubectl get pods -o wide
# kubectl get daemonset daemonset-example 【检查 DaemonSet 状态】
# kubectl taint nodes work1.timinglee.org key=value:NoExecute 【添加强力的污点】
# kubectl describe nodes | grep Taints 【查看污点】



job 控制器
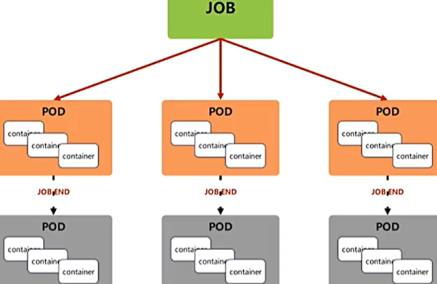
job控制器功能
Job,主要用于负责批量处理(一次要处理指定数量任务)短暂的一次性(每个任务仅运行一次就结束)任务
Job特点如下:
当Job创建的pod执行成功结束时,Job将记录成功结束的pod数量
当成功结束的pod达到指定的数量时,Job将完成执行
job 控制器示例:
# kubectl create job job-example --image myapp:v1 --dry-run=client -o yaml > job.yml
# vim job.yml
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
completions: 6 #一共完成任务数为6
parallelism: 2 #每次并行完成2个
template:
spec:
containers:
- name: pi
image: perl:5.34.0
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"] # 计算Π的后2000位
restartPolicy: Never #关闭后不自动重启
backoffLimit: 4 #运行失败后尝试4重新运行
# docker load -i /root/perl-5.34.tar.gz
# docker tag perl:5.34.0 reg.timinglee.org/library/perl:5.34.0
# docker push reg.timinglee.org/library/perl:5.34.0 【推送】
# kubectl delete -f *.yml
# kubectl apply -f job.yml
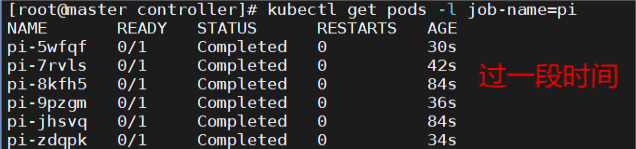
# kubectl get pods -l job-name=pi
# kubectl get job pi 查看结果:
# kubectl logs pi-5wfqf 【查看perl计算Π后2000数】


关于重启策略设置的说明:
如果指定为OnFailure,则job会在pod出现故障时重启容器
而不是创建pod,failed次数不变
如果指定为Never,则job会在pod出现故障时创建新的pod
并且故障pod不会消失,也不会重启,failed次数加1
如果指定为Always的话,就意味着一直重启,意味着job任务会重复去执行了
cronjob 控制器
cronjob 控制器功能
Cron Job 创建基于时间调度的 Jobs。
CronJob控制器以Job控制器资源为其管控对象,并借助它管理pod资源对象
CronJob可以以类似于Linux操作系统的周期性任务作业计划的方式控制其运行时间点及重复运行的方式。
CronJob可以在特定的时间点(反复的)去运行job任务。
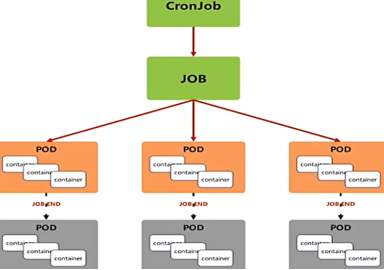
cronjob 控制器 示例
# vim cronjob.yml
apiVersion: batch/v1
kind: CronJob
metadata:
name: hello
spec:
schedule: "* * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox
imagePullPolicy: IfNotPresent
command: ["/bin/sh", "-c", "date; echo Hello from the Kubernetes cluster"]
restartPolicy: OnFailure
# kubectl delete -f *.yml
# kubectl apply -f cronjob.yml
# kubectl get cronjob hello
# kubectl get jobs --watch 查看运行:




什么是微服务
# kubectl apply -f /root/kube-flannel.yml
用控制器来完成集群的工作负载,那么应用如何暴漏出去?需要通过微服务暴漏出去后才能被访问
Service是一组提供相同服务的Pod对外开放的接口。
借助Service,应用可以实现服务发现和负载均衡。
service默认只支持4层负载均衡能力,没有7层功能。(可以通过Ingress实现)
# vim web.yml
apiVersion: apps/v1
kind: Deployment
metadata:
name: deployment
spec:
minReadySeconds: 5 #最小就绪时间,指定pod每隔多久更新一次
replicas: 4
strategy: #指定更新策略
rollingUpdate:
maxSurge: 1 #比定义pod数量多几个
maxUnavailable: 0 #比定义pod个数少几个
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
containers:
- image: myapp:v1
name: myapp
# kubectl apply -f web.yml
# kubectl expose deployment deployment --port 80 --target-port 80 --external-ip 172.25.254.100
# kubectl describe services deployment
# curl 172.25.254.100/hostname.html 检测访问:
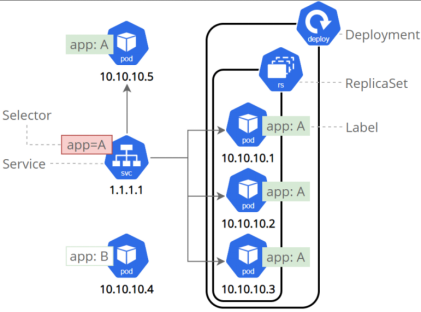


微服务的类型
生成控制器文件并建立控制器
# kubectl create deployment timinglee --image myapp:v1 --replicas 2 --dry-run=client -o yaml > timinglee.yaml
生成微服务yaml追加到已有yaml中
# kubectl expose deployment timinglee --port 80 --target-port 80 --dry-run=client -o yaml >> timinglee.yaml
# vim timinglee.yml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: timinglee
name: timinglee
spec:
replicas: 2
selector:
matchLabels:
app: timinglee
template:
metadata:
creationTimestamp: null
labels:
app: timinglee
spec:
containers:
- image: myapp:v1
name: myapp
--- #不同资源间用---隔开
apiVersion: v1
kind: Service
metadata:
labels:
app: timinglee
name: timinglee
spec:
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
app: timinglee

ipvs模式
Service 是由 kube-proxy 组件,加上 iptables 来共同实现的kube-proxy 通过 iptables 处理 Service 的过程,需要在宿主机上设置相当多的 iptables 规则,如果宿主机有大量的Pod,不断刷新iptables规则,会消耗大量的CPU资源IPVS模式的service,可以使K8s集群支持更多量级的Pod
ipvs模式配置方式
在所有节点中安装ipvsadm
# for i in 10 20 200; do ssh -l root 172.25.254.$i yum install ipvsadm -y;done
修改master节点的代理配置
# kubectl -n kube-system edit cm kube-proxy
重启pod,在pod运行时配置文件中采用默认配置,当改变配置文件后已经运行的pod状态不会变化,所以要重启pod
# kubectl -n kube-system get pods | awk '/kube-proxy/{system("kubectl -n kube-system delete pods "$1)}'
# ipvsadm -Ln
# kubectl delete pods 【重启恢复】
切换ipvs后kube-proxy会在宿主机上添加一个虚拟网卡:kube-ipvs0并分配所有service IP
# ip a | tail
# kubectl apply -f timinglee.yml
# ipvsadm -Ln
# kubectl get pods -o wide查看结果:

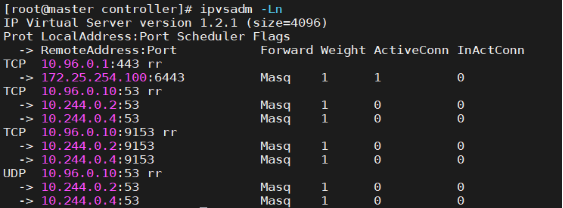



微服务类型详解
clusterip
特点:clusterip模式只能在集群内访问,并对集群内的pod提供健康检测和自动发现功能
# vim myapp.yml
apiVersion: v1
kind: Service
metadata:
labels:
app: timinglee
name: timinglee
spec:
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
app: timinglee
type: ClusterIP
# kubectl delete -f *.yml
# kubectl apply -f myapp.yml
# dig timinglee.default.svc.cluster.local @10.96.0.10
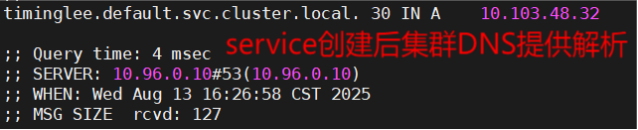
设置对外访问列表
--- #不同资源间用---隔开
apiVersion: v1
kind: Service
metadata:
labels:
app: myappv1
name: myappv1
spec:
externalIPs:
- 172.25.254.111 # 注意这里的破折号和缩进
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
app: myappv1
# kubectl apply -f timinglee.yml
# kubectl get service myappv1


ClusterIP中的特殊模式headless
headless(无头服务)
对于无头 `Services` 并不会分配 Cluster IP,kube-proxy不会处理它们, 而且平台也不会为它们进行负载均衡和路由,集群访问通过dns解析直接指向到业务pod上的IP,所有的调度有dns单独完成
# kubectl get svc
# dig timinglee.default.svc.cluster.local. @10.96.0.10
# vim timinglee.yaml
---
apiVersion: v1
kind: Service
metadata:
labels:
app: timinglee
name: timinglee
spec:
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
app: timinglee
type: ClusterIP
clusterIP: None #不用ip
# kubectl delete -f timinglee.yaml
# kubectl apply -f timinglee.yaml
# kubectl get services timinglee
# dig timinglee.default.svc.cluster.local. @10.96.0.10 查看结果:



nodeport
通过ipvs暴漏端口从而使外部主机通过master节点的对外ip:<port>来访问pod业务
其访问过程为:
# kubectl get svc timinglee 【暴漏端口一个】
# vim timinglee.yaml
---
apiVersion: v1
kind: Service
metadata:
labels:
app: timinglee-service
name: timinglee-service
spec:
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
app: timinglee
type: NodePort
# kubectl apply -f timinglee.yaml
# kubectl get services timinglee-service
# ipvsadm -Ln
# curl 172.25.254.100:30854
注意:nodeport默认端口是30000-32767,超出会报错



端口限制优化
# vim timinglee.yaml
apiVersion: v1
kind: Service
metadata:
labels:
app: timinglee-service
name: timinglee-service
spec:
ports:
- port: 80
protocol: TCP
targetPort: 80
nodePort: 33333
selector:
app: timinglee
type: NodePort
# kubectl apply -f timinglee.yaml
如果需要使用这个范围以外的端口就需要特殊设定
# vim /etc/kubernetes/manifests/kube-apiserver.yaml
# kubectl get svc


loadbalancer
云平台会为我们分配vip并实现访问,如果是裸金属主机那么需要metallb来实现ip的分配
apiVersion: v1
kind: Service
metadata:
labels:
app: timinglee-service
name: timinglee-service
spec:
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
app: timinglee
type: LoadBalancer
# kubectl apply -f timinglee.yml
# kubectl get svc 【默认无法分配外部访问IP】
LoadBalancer模式适用云平台,环境需要安装metallb提供支持
metalLB
metalLB功能
为LoadBalancer分配vip
部署方式
# kubectl edit cm -n kube-system kube-proxy
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
mode: "ipvs"
# docker load -i /root/service/metalLB.tag.gz
# docker tag quay.io/metallb/speaker:v0.14.8 reg.timinglee.org/metallb/speaker:v0.14.8
# docker push reg.timinglee.org/metallb/speaker:v0.14.8 【推送】
# docker tag quay.io/metallb/controller:v0.14.8 reg.timinglee.org/metallb/controller:v0.14.8
# docker push reg.timinglee.org/metallb/controller:v0.14.8
配置分配地址段
# kubectl apply -f /root/service/metallb-native.yaml
# vim configmap.yml
apiVersion: metallb.io/v1beta1
kind: IPAddressPool
metadata:
name: first-pool
namespace: metallb-system
spec:
addresses:
- 172.25.254.50-172.25.254.99
---
apiVersion: metallb.io/v1beta1
kind: L2Advertisement
metadata:
name: example
namespace: metallb-system
spec:
ipAddressPools:
- first-pool
# kubectl apply -f configmap.yml
# kubectl get svc
# curl 172.25.254.50 检测访问:

externalname
开启services后,不会被分配IP,而是用dns解析CNAME固定域名来解决ip变化问题一般应用于外部业务和pod沟通或外部业务迁移到pod内时在应用向集群迁移过程中,externalname在过度阶段就可以起作用了。集群外的资源迁移到集群时,在迁移的过程中ip可能会变化,但是域名+dns解析能完美解决此问题
# vim timinglee.yaml
---
apiVersion: v1
kind: Service
metadata:
labels:
app: timinglee-service
name: timinglee-service
spec:
selector:
app: timinglee
type: ExternalName
externalName: www.timinglee.org
# kubectl apply -f timinglee.yaml
# kubectl get services timinglee-service
# ipvsadm -Ln 检测查看:


Ingress-nginx
ingress-nginx功能
一种全局的、为了代理不同后端 Service 而设置的负载均衡服务,支持7层
Ingress由两部分组成:Ingress controller和Ingress服务
Ingress Controller 会根据你定义的 Ingress 对象,提供对应的代理能力。
业界常用的各种反向代理项目,比如 Nginx、HAProxy、Envoy、Traefik 等,都已经为Kubernetes 专门维护了对应的 Ingress Controller。
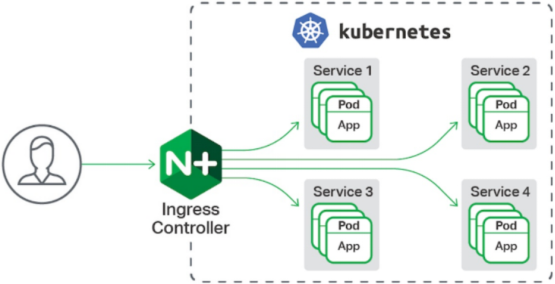
部署ingress
# mkdir /root/service/ingress
# cd /root/service/ingress/
# unzip ingress-1.13.1.zip
安装ingress
# vim deploy.yaml
# docker load -i ingress-nginx-1.13.1.tar
# docker tag registry.k8s.io/ingress-nginx/kube-webhook-certgen:v1.6.1 reg.timinglee.org/ingress-nginx/kube-webhook-certgen:v1.6.1
# docker push reg.timinglee.org/ingress-nginx/kube-webhook-certgen:v1.6.1
# docker tag registry.k8s.io/ingress-nginx/controller:v1.13.1 reg.timinglee.org/ingress-nginx/controller:v1.13.1
# docker push reg.timinglee.org/ingress-nginx/controller:v1.13.1
# kubectl apply -f deploy.yaml
# kubectl -n ingress-nginx get svc
# kubectl -n ingress-nginx get pods
# kubectl -n ingress-nginx edit svc ingress-nginx-controller 【修改微服务为loadbalancer】
# kubectl -n ingress-nginx get svc
在ingress-nginx-controller中看到的对外IP就是ingress最终对外开放的ip

密钥配置启动ip分配
# KEY=$(openssl rand -base64 32) 【生成密钥】
# kubectl -n metallb-system create secret generic memberlist --from-literal=secretkey="$KEY"
# kubectl -n metallb-system delete pods --all 【重启】
测试ingress
# kubectl create ingress webcluster --rule '*/=timinglee-svc:80' --dry-run=client -o yaml > timinglee-ingress.yml
# vim timinglee-ingress.yml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: test-ingress
spec:
ingressClassName: nginx
rules:
- http:
paths:
- backend:
service:
name: timinglee-svc
port:
number: 80
path: /
pathType: Prefix
#Exact(精确匹配),ImplementationSpecific(特定实现),Prefix(前缀匹配),Regular expression(正则表达式匹配)
# kubectl apply -f timinglee-ingress.yml
# kubectl get ingress
# for n in {1..5}; do curl 172.25.254.50/hostname.html; done


ingress 的高级用法
基于路径的访问
建立用于测试的控制器myapp
# vim myapp-v1.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ingress-test
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
spec:
ingressClassName: nginx
rules:
- http:
paths:
- backend:
service:
name: myappv1
port:
number: 80
path: /v1
pathType: Prefix
- backend:
service:
name: myappv2
port:
number: 80
path: /v2
pathType: Prefix
# kubectl apply -f myapp-v1.yaml
# kubectl get services
# kubectl get ingress ingress-test
# kubectl -n ingress-nginx get svc
# curl 172.25.254.50 访问结果:
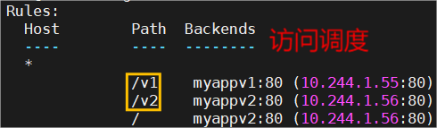

基于域名的访问
# vim /etc/hosts 【在测试主机中设定解析】
172.25.254.50 myappv1.timinglee.org myappv2.timinglee.org
# vim ingressmy.yml 【建立基于域名的yml文件】
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
name: ingressmy
spec:
ingressClassName: nginx
rules:
- host: myappv1.timinglee.org
http:
paths:
- backend:
service:
name: myapp-v1
port:
number: 80
path: /
pathType: Prefix
- host: myappv2.timinglee.org
http:
paths:
- backend:
service:
name: myapp-v2
port:
number: 80
path: /
pathType: Prefix
# kubectl apply -f ingressmy.yml
# kubectl describe ingress ingressmy
# curl myappv2.timinglee.org

建立tls加密
建立证书
# openssl req -newkey rsa:2048 -nodes -keyout tls.key -x509 -days 365 -subj "/CN=nginxsvc/O=nginxsvc" -out tls.crt
# ls tls* 查看结果:
# kubectl create secret tls web-tls-secret --key tls.key --cert tls.crt 【把证书加到集群内成为资源】
# kubectl get secrets
# kubectl describe secrets web-tls-secret
secret通常在kubernetes中存放敏感数据,他并不是一种加密方式


建立基于tls认证的yml文件
# vim my.yml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
name: ingress3
spec:
tls:
- hosts:
- myappv1.timinglee.org
secretName: web-tls-secret
ingressClassName: nginx
rules:
- host: myappv1.timinglee.org
http:
paths:
- backend:
service:
name: myapp-v1
port:
number: 80
path: /
pathType: Prefix
# kubectl apply -f my.yml
# kubectl describe ingress 查看结果:
# curl -k https://myappv1.timinglee.org
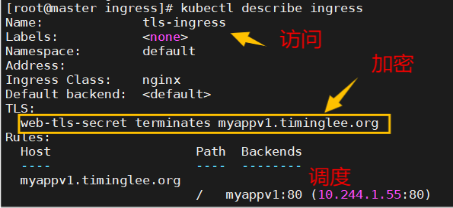
建立auth认证
建立认证文件
# dnf install httpd-tools -y
# htpasswd -cm htpasswd admin 【建立认证】
# cat htpasswd 查看结果:
建立认证类型资源
# kubectl create secret generic auth-web --from-file htpasswd 【提取为资源】
# kubectl describe secrets auth-web
建立基于用户认证的yaml文件
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: host-ingress
annotations:
nginx.ingress.kubernetes.io/auth-type: basic
nginx.ingress.kubernetes.io/auth-secret: auth-web
nginx.ingress.kubernetes.io/auth-realm: "Please input username and password"
nginx.ingress.kubernetes.io/rewrite-target: /
spec:
ingressClassName: nginx
rules:
- host: myappv1.timinglee.org
http:
paths:
- backend:
service:
name: myappv1
port:
number: 80
path: /
pathType: Prefix
建立yhingress
# kubectl describe ingress host-ingress
# curl myappv1.timinglee.org 【无法访问】
# curl myappv1.timinglee.org -uadmin:lee 【证书访问】


rewrite重定向
访问文件重定向
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: rew-ingress
annotations:
nginx.ingress.kubernetes.io/app-root: /hostname.html #默认访问文件hostname.html
spec:
ingressClassName: nginx
rules:
- http:
paths:
- backend:
service:
name: myappv1
port:
number: 80
path: /
pathType: Prefix
# kubectl describe ingress rew-ingress 查看结果:
# curl -L 172.25.254.50


正则表达式重定向
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: rew-ingress
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /$2 # 修正:捕获第二个分组
nginx.ingress.kubernetes.io/use-regex: "true"
spec:
ingressClassName: nginx
rules:
- http:
paths:
- backend:
service:
name: myappv1
port:
number: 80
path: /haha(/|$)(.*) # haha后的元素是 $2
pathType: ImplementationSpecific # 匹配正则表达式
# kubectl describe ingress rew-ingress 查看结果:
# curl 172.25.254.50/haha/
# curl 172.25.254.50/haha/hostname.html
/(.*)/(.*) # curl 172.25.254.50/第一个变量/第二个变量


什么是金丝雀发布
金丝雀发布(Canary Release)也称为灰度发布,是一种软件发布策略。
主要目的是在将新版本的软件全面推广到生产环境之前,先在一小部分用户或服务器上进行测试和验证,以降低因新版本引入重大问题而对整个系统造成的影响。
是一种Pod的发布方式。金丝雀发布采取先添加、再删除的方式,保证Pod的总量不低于期望值。并且在更新部分Pod后,暂停更新,当确认新Pod版本运行正常后再进行其他版本的Pod的更新。
Canary发布方式
其中header和weiht中的最多
基于header(http包头)灰度
通过Annotaion扩展
创建灰度ingress,配置灰度头部key以及value
灰度流量验证完毕后,切换正式ingress到新版本
之前我们在做升级时可以通过控制器做滚动更新,默认25%利用header可以使升级更为平滑,通过key 和vule 测试新的业务体系是否有问题。
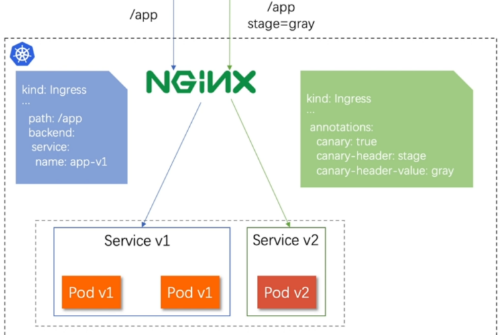
# vim cuingress.sh
#!/bin/bash
v1=0
v2=0
for (( i=0; i<10; i++))
do
response=`curl -s 172.25.254.51 |grep -c v1`
v1=`expr $v1 + $response`
v2=`expr $v2 + 1 - $response`
done
echo "v1:$v1, v2:$v2"
# chmod +x cuingress.sh
# sh cuingress.sh
建立老版本
# vim ingressold.yml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: old-ingress
spec:
ingressClassName: nginx
rules:
- http:
paths:
- backend:
service:
name: myappv1
port:
number: 80
path: /
pathType: Prefix
# curl 172.25.254.50 测试访问:
建立新版本
# vim ingressnew.yml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: new-ingress
annotations:
nginx.ingress.kubernetes.io/canary: "true"
nginx.ingress.kubernetes.io/canary-by-header: "timinglee"
nginx.ingress.kubernetes.io/canary-by-header-value: "2"
spec:
ingressClassName: nginx
rules:
- http:
paths:
- backend:
service:
name: myappv2
port:
number: 80
path: /
pathType: Prefix
# kubectl describe ingress new-ingress
# kubectl describe ingress old-ingress
# curl -H "timinglee:2" 172.25.254.50 【更改包头访问】

权重配置
# vim ingressnew.yml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: new-ingress
annotations:
nginx.ingress.kubernetes.io/canary: "true"
nginx.ingress.kubernetes.io/canary-weight: "10" #更改权重值
nginx.ingress.kubernetes.io/canary-weight-total: "100" #访问100次
spec:
ingressClassName: nginx
rules:
- http:
paths:
- backend:
service:
name: myappv2
port:
number: 80
path: /
pathType: Prefix
# kubectl apply -f ingressnew.yml
# sh cuingress.sh 查看测试:
#更改完毕权重后继续测试可观察变化
# vim ingressnew.yml
nginx.ingress.kubernetes.io/canary-weight: "10" #更改权重值
# sh cuingress.sh 查看测试:

