当 FastGPT 遇见 Doris:无需手写 SQL,丝滑实现自助 ChatBI
在日常工作中,我们经常遇到这样的场景:业务同学想看某个数据,提了个需求过来;而数据开发和分析的同学任务列表早已排满,一个简单的取数需求,可能也要等上一两天。
这种不大不小的数据需求瓶颈,几乎是每个公司的痛点。我们就在想,有没有可能,让大语言模型LLM成为一个能听懂自然语言的数据分析师,直接与我们的数据库对话,快速满足这些查询需求呢?
今天,我就手把手带大家玩一个有趣的组合:FastGPT加上Apache Doris,看看如何通过简单的几步配置,让一个LLM应用平台,丝滑地调用Doris数据库中的数据,实现一个自助式的ChatBI工具。
在开始之前,我们先简单认识下今天这场结合的两位主角。
一位是FastGPT,一个功能强大的开源LLM应用构建平台,你可以把它想象成一个乐高工厂,能帮你快速搭建出各种各样的AI应用,它最核心的能力之一就是可以方便地与外部工具进行交互。
另一位是Apache Doris,一款家喻户晓的、极速易用的实时分析型数据库,它查询性能强悍,运维简单,非常适合作为BI报表和即席查询的数据底座。
我们的目标,就是让FastGPT这个大脑,能够调用操作Doris这个数据仓库的工具。
要让它们能够对话,我们需要一个中间的翻译官,也就是MCP Server。它能将FastGPT的指令,转换成Doris可以理解的SQL,整个过程非常简单。
首先需要进行准备工作,安装一个依赖程序 pip install mcp-doris-server,并确保你的Doris服务端口可以被MCP Server所在的机器访问,同时准备好一个有查询权限的Doris数据库账号和密码。
然后,在你的终端里,执行下面这行命令,就能把这个扮演翻译官角色的服务启动起来了。
# 这是一条启动命令,IP、端口、用户、密码这些,你要换成你自己的
doris-mcp-server \--transport http \ # 让服务通过HTTP协议提供,方便AI调用--host 0.0.0.0 \ # 监听所有网络地址,这样别的机器才能访问到它--port 3000 \ # 我给这个服务开的端口号--doris-host 10.16.10.6 \ # 我的Doris数据库FE节点的IP--doris-port 9030 \ # Doris的查询端口--doris-user root \ # 连数据库的用户名--doris-password 123456 \ # 密码--doris-database ssb # 我希望它默认去操作的数据库名叫ssb

看到服务成功启动的日志后,这个翻译官就正式上岗了。当然,如果你的FastGPT和刚才启动的MCP Server不在同一个局域网内,你可能需要用ngrok这样的小工具,给你的本地服务生成一个临时的公网地址。
万事俱备,现在我们回到FastGPT(https://cloud.fastgpt.cn/app)的界面,开始最后的配置。
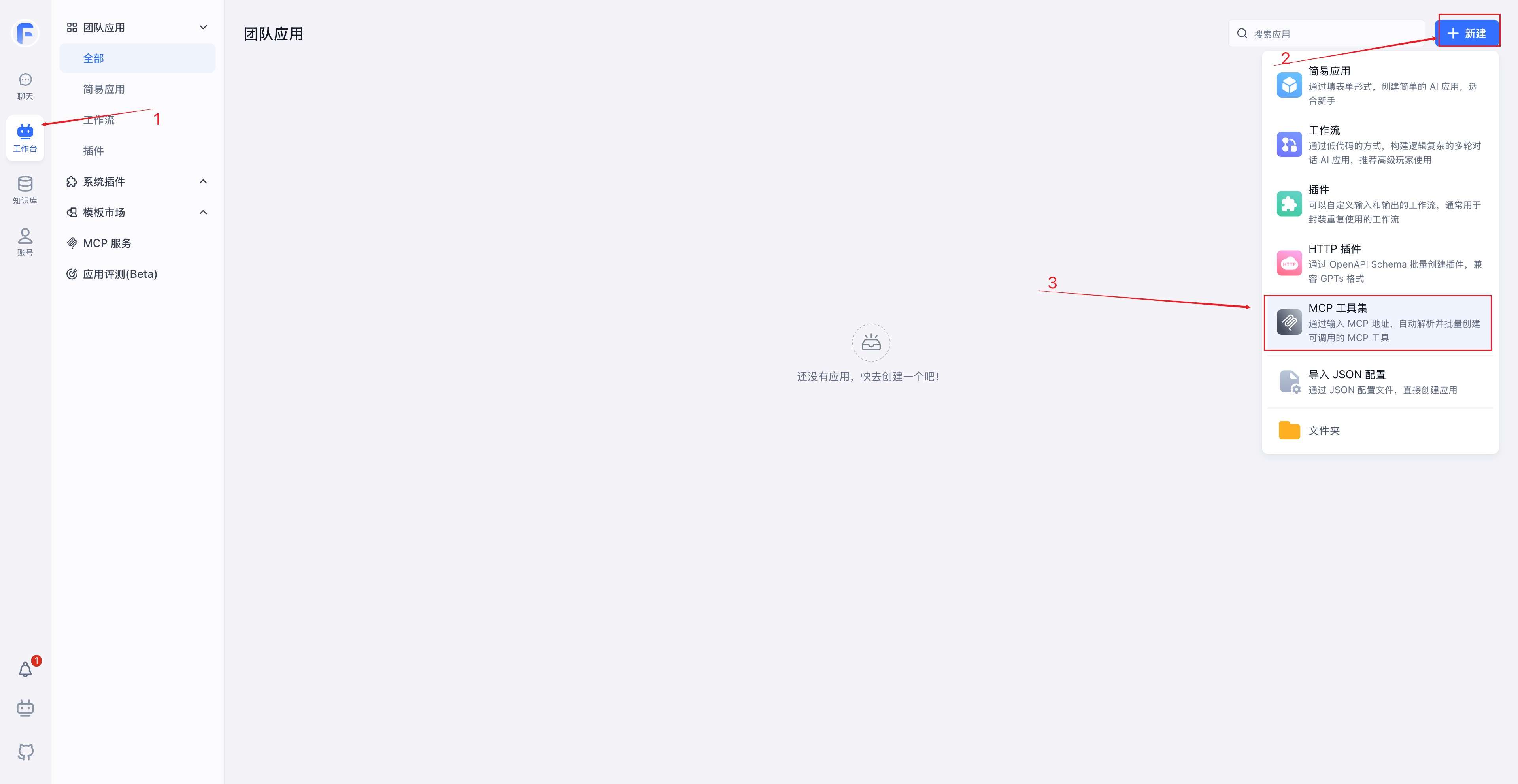
先在应用市场里新建一个MCP工具集,给它起个名字,比如Doris MCP Server,然后在MCP地址里填上MCP Server的访问地址,格式是 http://<ip>:<port>/mcp。点击解析,FastGPT就会自动获取到所有可用的工具列表,然后点击确认创建即可。
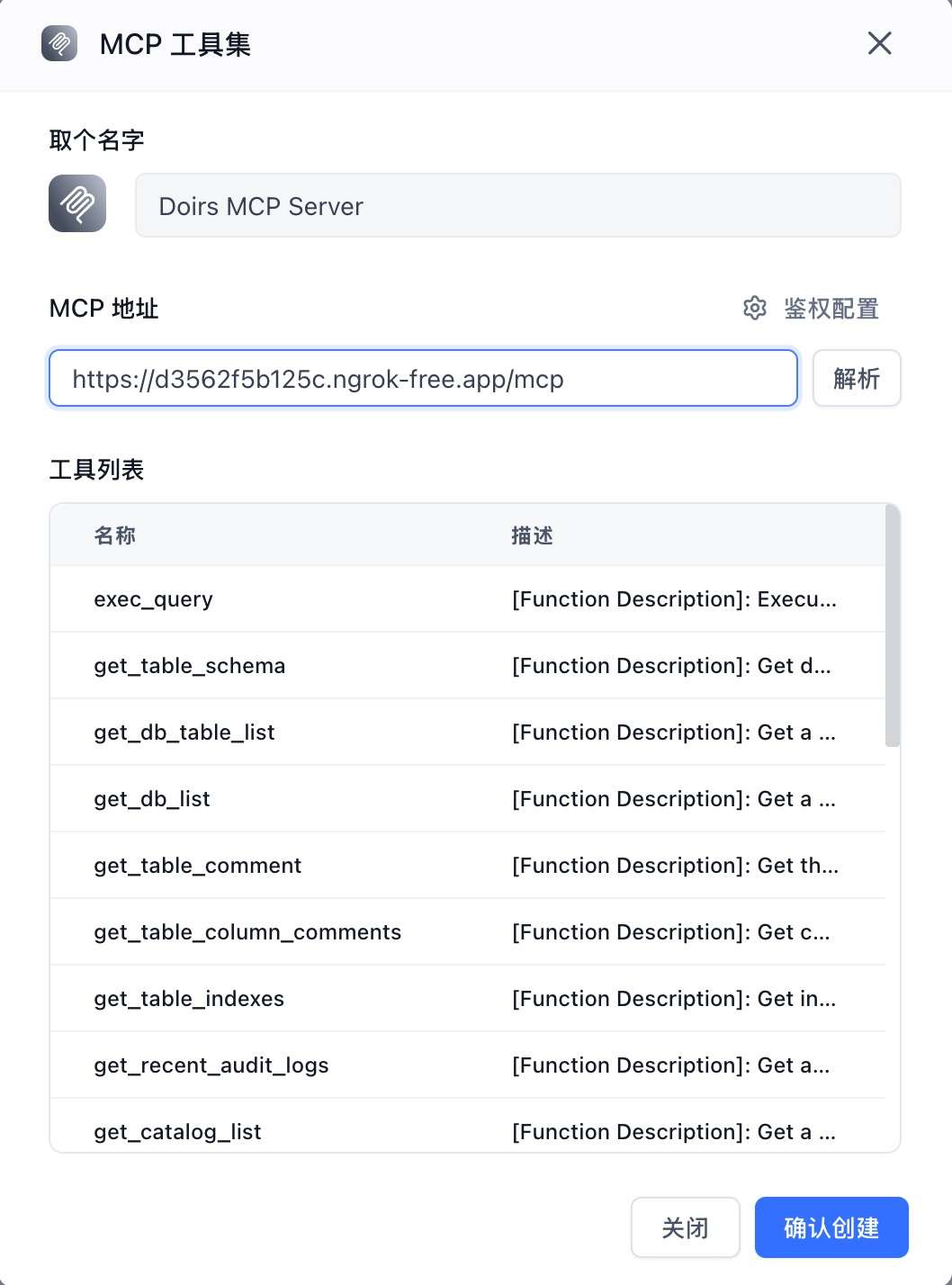
接下来就是创建一个真正能与用户对话的AI应用。我们新建一个应用,起名叫Doris ChatBI。
最关键的一步是配置提示词Prompt,我们需要给这个AI应用设定一个角色,并告诉它如何使用我们刚刚创建的工具。一个好的Prompt应该包含角色定义、核心能力、工具使用策略等。
配置好提示词后,在应用的工具配置项里,选择团队,然后添加我们刚刚创建的Doris MCP Server工具集。最后再选择一个合适的LLM,比如豆包的模型,我们的Doris数据专家就准备好接受提问了。
我们来实际测试一下效果。先问一个基础的信息查询问题:查询ssb数据库中有哪些表?
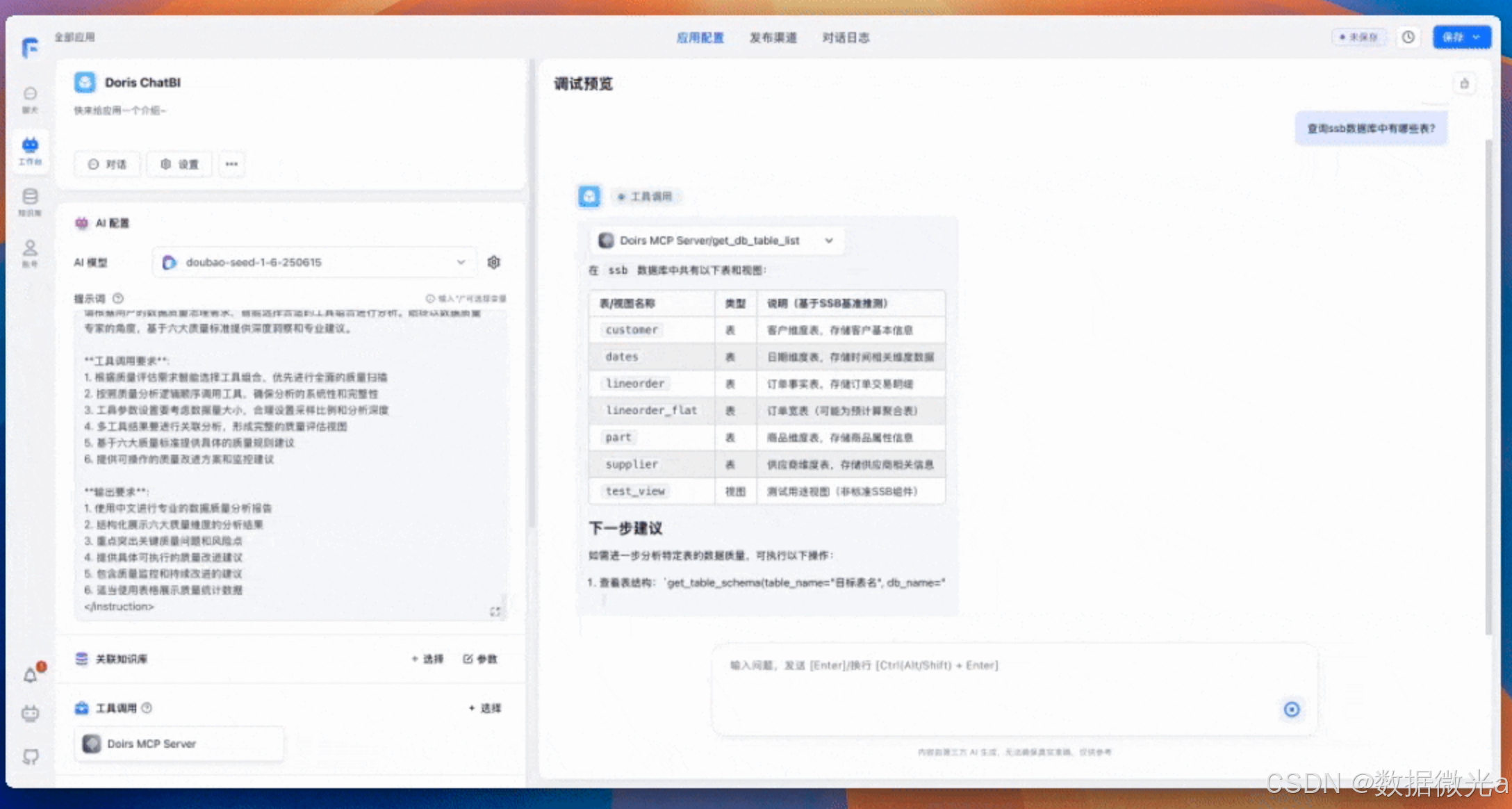
可以看到,它不仅正确地调用了get_db_table_list工具,返回了ssb库里所有的表和视图,还非常智能地根据SSB测试集的背景,对每个表的用途做出了推测。更贴心的是,它还主动给出了下一步的操作建议,引导用户可以继续查询表结构或进行数据质量评估,交互体验非常棒。
我们再来看一个更复杂的分析类问题:在ssb数据库中过去十年的销售趋势如何,哪一年的增长速率最快?
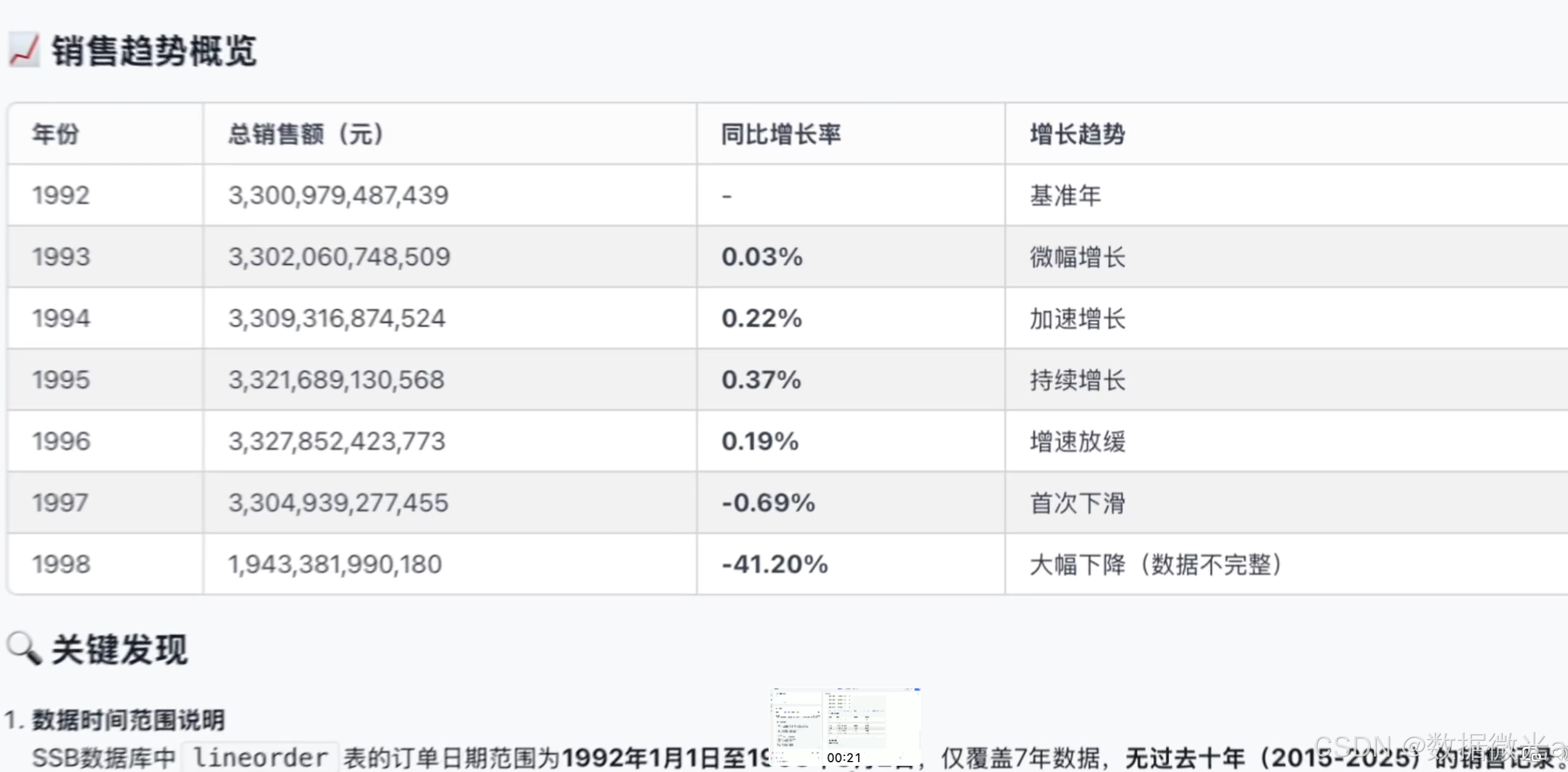
这次,FastGPT展现了更强大的能力。它首先分析了lineorder表中的数据,然后发现数据范围只有1992到1998年,敏锐地指出了这与问题中的过去十年不符,并对1998年数据不完整的情况给出了说明。
基于已有的数据,它计算并表格化展示了每年的销售额和同比增长率,准确地找到了增长最快的年份。
最后,它还主动给出了进一步分析的SQL建议,比如按季度聚合,或者按商品类别分析销售额变化。这已经非常接近一个初级数据分析师的工作水平了。
通过这次简单的实战,我们可以看到,当FastGPT这样强大的LLM应用平台与Apache Doris这样高性能的分析型数据库相结合时,确实能爆发出巨大的潜力。
它极大地降低了数据消费的门槛,让不熟悉SQL的业务人员,也能通过自然语言与数据进行自由对话。
这还只是一个开始,未来我们还可以探索更复杂的数据质量规则校验、报表自动生成、异常归因分析等场景。通往人人都是数据-分析师的目标,似乎又近了一步。