【Trans2025】计算机视觉|UMFormer:即插即用!让遥感图像分割更精准!

论文地址:https://ieeexplore.ieee.org/document/10969832#page=1.00&gsr=0
代码地址:https://github.com/takeyoutime/UMFormer
关注UP CV缝合怪,分享最计算机视觉新即插即用模块,并提供配套的论文资料与代码。
https://space.bilibili.com/473764881
摘要
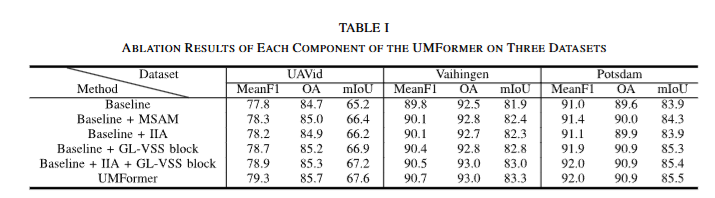
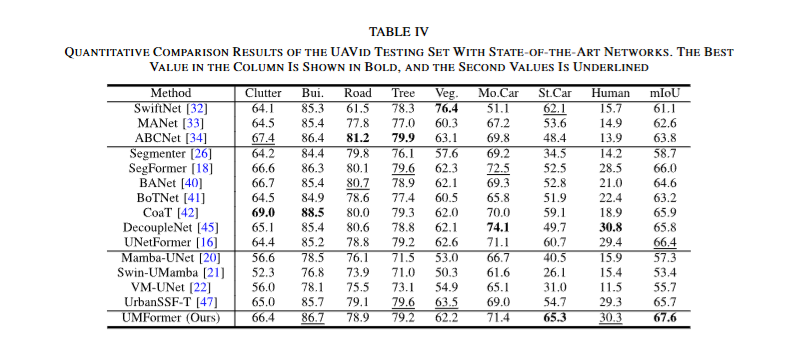
在本研究中,构建了一个名为UMFormer的编解码器风格网络,用于遥感图像的语义分割。具体来说,UMFormer采用ResNet18作为编码器,目的是执行初步的图像特征提取。随后,对自注意力机制进行优化,以便在多尺度条件下提取与不同大小对象相关的全局信息。为了融合编解码器特征图信息,构建了另一种注意力结构来重建空间信息并捕获相对位置关系。最后,设计了一个基于Mamba的解码器,以有效地对全局和局部信息进行建模。同时,设计了一种利用特征相似性的特征融合机制,目的是将局部信息嵌入到全局信息中。在无人机图像数据集(UAVid)、Vaihingen和Potsdam数据集上进行的大量实验表明,所提出的UMFormer在保持高效运行速度的同时,也提高了准确性。
引言
本研究关注遥感图像语义分割领域。遥感图像语义分割通过精确识别和标记遥感图像中的地面物体和地表特征,为地面物体识别、变化检测和土地覆盖分类提供基础支持,在多个领域发挥着重要作用。然而,这项任务仍然面临诸多挑战。
首先,遥感图像中城市场景的多样性和复杂性给图像的精确分割带来了巨大挑战。不同类别物体的大小和分布差异会导致分割边缘混淆,例如,道路、植被和建筑物等大型类别通常遍布整个图像,占据了很大一部分像素;而车辆和行人等小型类别像素数量相对较少,但空间分布不均匀,导致各种物体类型的边缘在分割结果中容易混淆。
其次,相同类别之间存在全局依赖关系,例如道路的相互连接,以及某些区域大面积的建筑物或植被;不同类别之间存在局部依赖关系,例如车辆与道路之间的关系。有效地捕获这些全局和局部依赖关系可以提高物体分割的准确性。
目前,大多数现有工作通过具有固定感受野的卷积运算来提取图像信息。然而,固定感受野的卷积运算在捕获大型目标的全局信息方面能力有限,导致目标信息的丢失或模糊。此外,小型目标的信息可能被稀疏提取,导致定位不准确。
Transformer 的出现解决了图像中上下文信息建模的问题。但Transformer 的自注意力机制在遥感图像语义分割中的效率因线性时间推理和缓慢的二次训练而降低。为解决上述问题,研究人员提出了 Mamba 状态空间模型。作为一种高效的长距离上下文捕获模块,Mamba 能够在保持较低计算资源消耗的同时捕获全局信息。
随后,研究人员尝试将 Mamba 应用于遥感图像语义分割任务中,以取代 Transformer 来捕获全局信息。然而,现有的基于 Mamba 的方法未能充分考虑局部信息在此任务中的重要性,导致无法在准确性和效率之间取得最佳平衡。尽管如此,Mamba 在遥感图像语义分割领域仍展现出巨大的应用潜力。
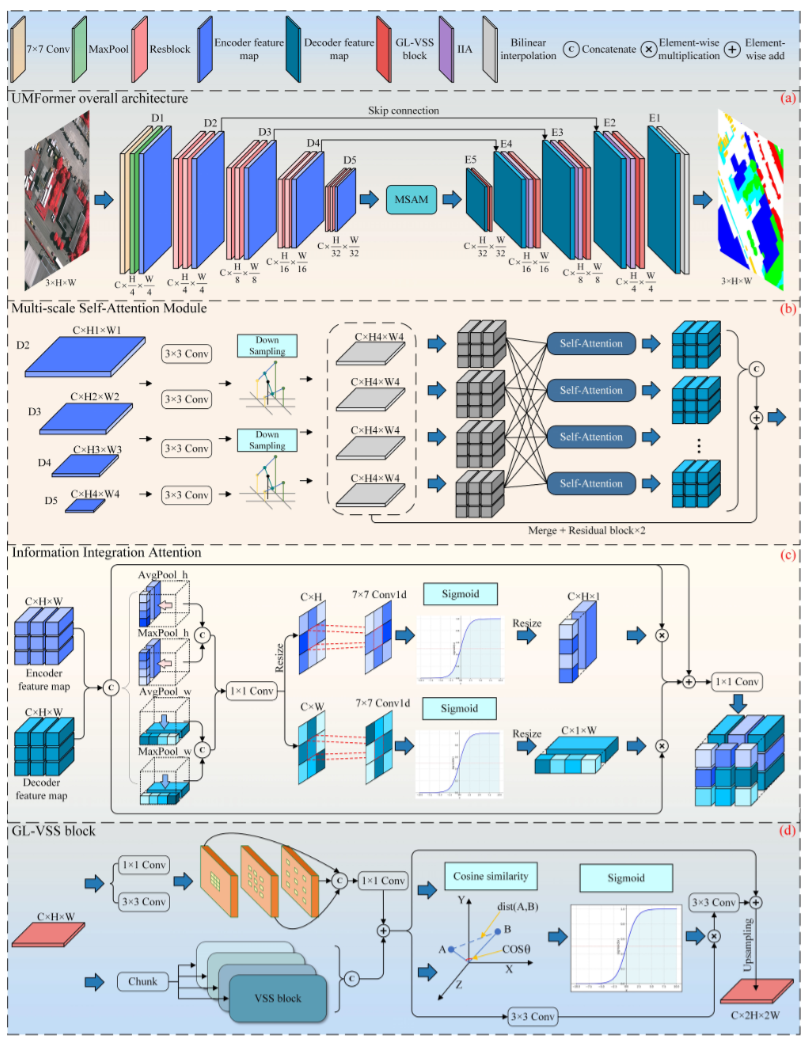
基于此,本研究旨在设计一个能够在准确性和效率之间达到最佳平衡的遥感图像语义分割网络。受自注意力机制和 Mamba 的启发,本研究提出了 UMFormer 以应对上述挑战。具体而言,UMFormer 有效地结合了卷积神经网络 (CNN)、自注意力机制和 Mamba 的各自优势,构建了一个混合网络。由于残差块强大的特征提取能力,本研究选择 ResNet18 作为 UMFormer 的编码器部分。
论文创新点
本研究提出了一个名为UMFormer的轻量级语义分割网络,旨在高效地分割遥感图像中的城市场景。本研究的创新点主要体现在以下几个方面:
-
🗺️ 多尺度自注意力模块(MSAM)的构建: 🗺️
- 该模块借鉴了Transformer中的自注意力机制,并针对遥感图像中不同大小目标的全局信息获取不足的问题,从多尺度条件下挖掘目标的长距离上下文语义信息。
- 与仅在单一尺度上提取全局信息的现有方法不同,MSAM 实现了跨不同尺度的相互自注意力,从而更全面地捕获目标的全局信息,显著提高了分割精度,尤其提升了对建筑物和低矮植被等类别的分割完整性。
-
🔍 信息整合注意力(IIA)机制的设计: 🔍
- 该机制被应用于编码器和解码器特征图融合的过程中。
- 通过利用图像特征的位置不变性,IIA 可以确定目标之间的相对位置关系,从而准确定位感兴趣区域,并减少噪声的影响。
- 这有效地解决了分割结果中类别之间混淆和噪声干扰等问题,提高了对相似目标的区分能力。
-
🌐 全局局部视觉状态空间 (GL-VSS) 模块的集成: 🌐
- 本研究将 Vision Mamba 集成到 UMFormer 的解码器中,并设计了GL-VSS 模块。
- 该模块包含局部信息分支、全局信息分支和特征嵌入头三个部分。全局信息分支利用 Vision Mamba 提取全局信息,而局部信息分支采用空洞卷积来增强局部信息的整合和提取。
- 在 GL-VSS 模块的末尾,两个分支通过一个简洁有效的结构相互嵌入,实现了以全局信息为主,局部信息为辅的融合方式,从而提高了分割边缘的精度和一致性。
- 与仅关注全局信息而忽略局部信息的现有基于 Mamba 的方法相比,GL-VSS 模块更有效地平衡了全局和局部信息的重要性,从而显著提高了分割精度。
-
🤝 基于特征相似度的特征融合机制的引入: 🤝
- 该机制通过计算全局和局部特征图之间的余弦相似度,并将其作为权重来加权融合后的特征,从而强化了相似度高的特征区域,进一步增强了全局和局部信息的融合效果。
- 这使得最终输出的特征图在表达性和泛化能力方面都得到了显著提升,从而提高了分割的准确性和鲁棒性。
通过这些创新,UMFormer 在城市场景分割任务中实现了效率和精度的最佳平衡,在多个公开数据集上取得了优于现有轻量级语义分割网络的性能。
论文实验