MARCONet++ 攻克中文文本图像超分难题
一. 前言
论文:https://arxiv.org/pdf/2508.07537v1
代码:https://github.com/csxmli2016/MARCONetPlusPlus
文本图像超分辨率(SR)旨在从低分辨率图像中恢复清晰的文字,但这项任务在处理结构复杂、样式多变的中文文本时尤其具有挑战性。现有方法大多为英文设计,或依赖于字符识别先验,在处理严重退化或不规则布局的中文文本时,常常导致笔画失真、结构错误。
在MARCONet的基础上提出了 MARCONet++,一个专为中文文本SR设计的全新框架。它创新地提出了一种 生成式结构先验(Generative Structure Prior),利用StyleGAN的强大生成能力,为恢复精确的汉字笔画结构提供了可靠指导。
二. 研究背景与动机
与字母文字不同,中文字符结构复杂,一个微小的笔画错误就可能改变整个字的含义(如“已”和“己”)。同时,字体、布局(如弯曲、透视)的多样性也为SR任务增加了巨大难度。
以往的方法大多依赖 识别先验,即利用识别网络来判断生成结果的“可读性”。然而,这种高层级的语义约束对于恢复底层的、精确的笔画结构往往力不从心。如下图所示,在处理不规则布局或复杂笔画时,基于识别先验的方法(TATT, LEMMA, DiffTSR)容易产生错误的结构。

为了解决这一问题,作者团队提出,应当从 结构层面 直接为SR过程提供指导,即本文的核心思想——生成式结构先验。
三. 算法原理:基于结构先验的SR框架
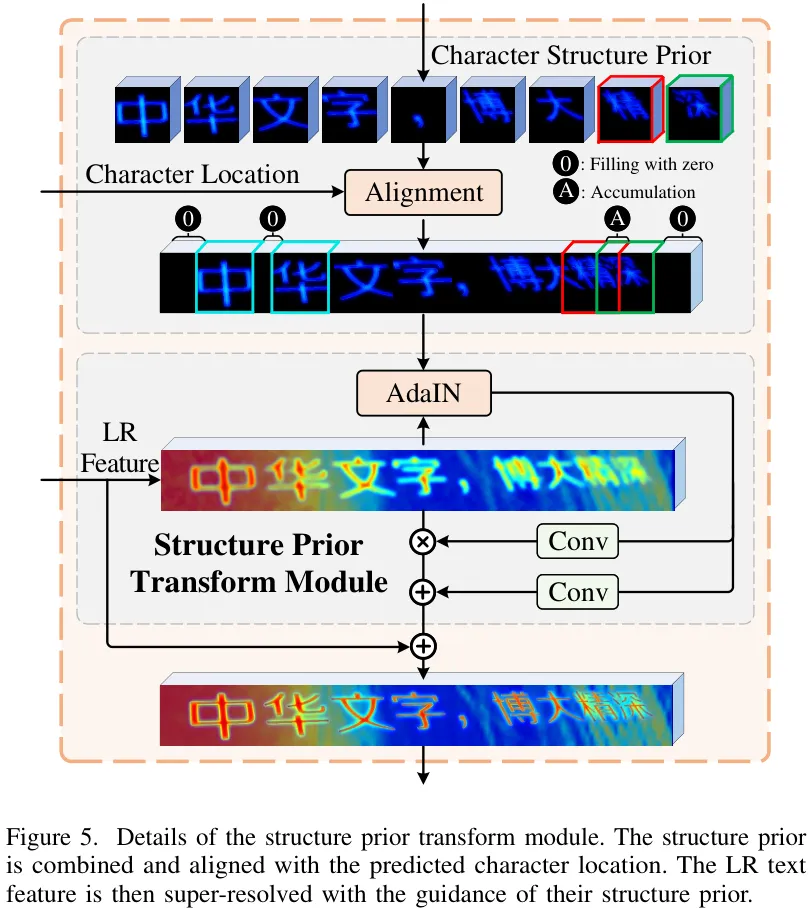
MARCONet++ 的核心思想是:将汉字的 结构(Structure) 和 风格(Style) 进行解耦。它利用一个预训练的StyleGAN来生成高分辨率的、仅包含标准笔画的“结构模板”,即结构先验。在SR过程中,再将这个“干净”的结构先验与从低分辨率图像中提取的“风格信息”(如字体、粗细、位置、方向等)相结合,从而恢复出高保真度的文本图像。
整个框架如下图所示,主要包含四个部分:
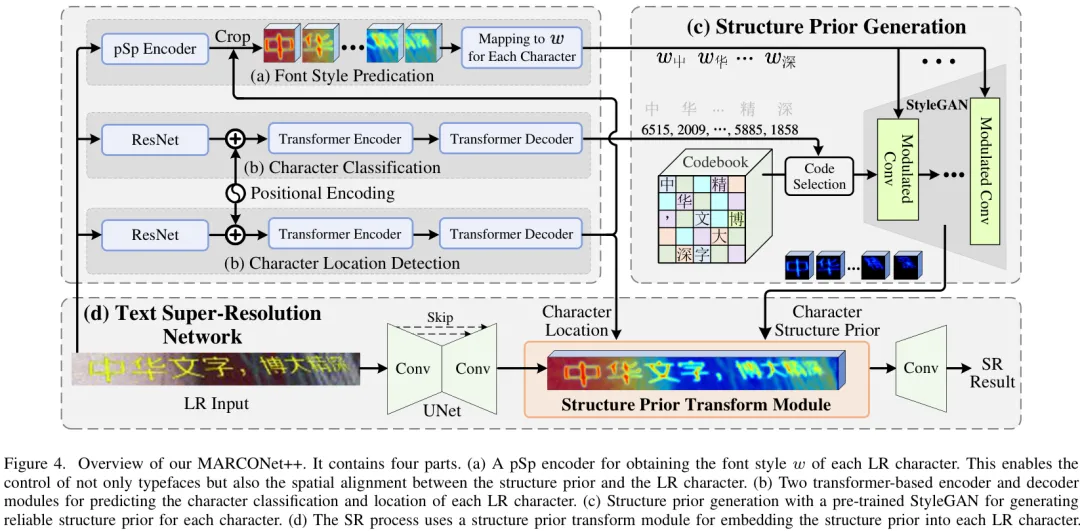 • 字体风格预测 (a) :使用pSp编码器从每个低分辨率字符块中提取其独特的风格向量w。这个w向量控制着生成字符的字体、大小、位置、方向甚至透视效果。
• 字体风格预测 (a) :使用pSp编码器从每个低分辨率字符块中提取其独特的风格向量w。这个w向量控制着生成字符的字体、大小、位置、方向甚至透视效果。
• 字符分类与定位 (b) :通过两个Transformer模块,分别对输入的每个字符进行识别(确定是哪个汉字)和定位(确定其在图像中的位置)。
• 结构先验生成 © :这是框架的创新核心。研究者对StyleGAN进行了改造,用一个 码本(Codebook) 来代替原有的单一输入。码本中的每一个“码(code)”唯一对应一个汉字的规范结构。在生成时,根据上一步的字符识别结果,从码本中取出对应的“结构码”,再结合第一步预测出的“风格向量w”,驱动StyleGAN生成一个与低分辨率输入在风格、位置上完全对齐的高分辨率结构先验。
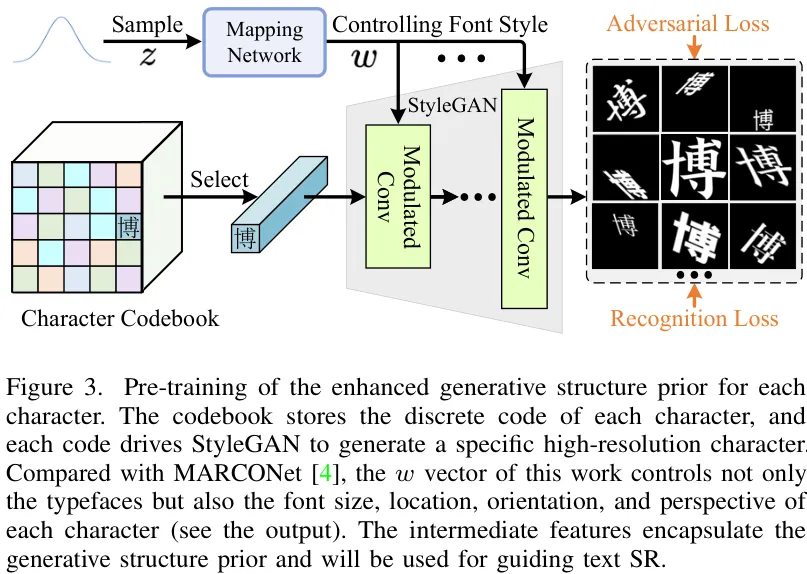
结构先验的预训练过程,码本(codebook)负责结构,w向量负责风格。
文本超分辨率 (d) :最后,通过一个“结构先验变换模块”,将生成的高清结构先验特征嵌入到低分辨率的文本特征中,指导U-Net网络完成最终的超分辨率重建。
四. 算法效果
MARCONet++在合成数据和真实世界的中文文本图像上均表现出卓越的性能,显著优于现有方法。
从视觉效果上看,MARCONet++恢复的字符笔画清晰、结构准确,边缘锐利,即使在布局弯曲、字体不规则的困难场景下,也能保持极高的保真度。


作者也用自己的图片进行了实际测试,效果还真不错。

五. 总结与思考
1. 总结
MARCONet++为解决复杂的中文文本图像超分辨率问题提供了一个非常优雅且有效的框架。其核心价值在于:
- 提出了生成式结构先验:跳出了传统识别先验的框架,从更底层的结构层面为SR任务提供了更可靠、更精细的指导,是该领域的一个重要思想创新。
- 巧妙的解耦设计:通过“码本+StyleGAN”的机制,成功地将字符的“不变的结构”与“可变的风格”分离开来,使得模型既能保证结构正确,又能灵活适应各种真实场景下的风格变化。
- 卓越的性能和泛化能力:无论是在合成数据还是真实世界的常规、非常规文本上,都取得了当前最佳的效果,并展示了向其他语言(如韩语、日语)泛化的潜力。
2. 思考
◦ 对竖排文本的超分会失效,后续可以优化;文档的方向需要是正方向,否则效果退化严重。
◦ 对长文本行的效果退化严重,在中文场景下效果优秀,在其他语言场景下效果一般,需要重新训练。
◦ 在文本和背景缝合处,仔细观察可看到回帖痕迹,可适当改进。
◦ 比较依赖OCR的识别结果,可通过优化OCR进一步提高识别算法效果。
欢迎技术交流 ! ! ! WeChat : guopeiAI