Flink的状态管理
一、状态的概念
Flink的状态其实你就可以将其想象为中间结果就可以了。在Flink中,算子的任务可以分为无状态和有状态两种情况。
无状态算子任务在计算过程中是不依赖于其他数据的,只根据当前的输入数据就可以得到结果输出。比如之前讲到的Map、FlatMap、Filter算子等。
有状态算子任务,在计算的过程中需要依赖一些其他的数据,然后再结合当前的输入数据得到最终的执行结果。比如聚合算子、窗口算子都是有状态的算子。
有状态算子的一般处理流程是:
(1)、算子任务接收上游输入的数据;
(2)、获取当前的状态信息;
(3)、根据业务逻辑进行处理并更新状态信息;
二、状态的分类
Flink总体来说有两种分类状态:托管状态、原始状态。
托管状态就是由Flink来进行状态的统一管理。状态的存储访问、故障恢复和重组等一系列问题都由Flink来实现,开发者只用去调接口就可以了;原始状态是自定义的,相当于就是自己开辟一块内存,然后由开发者自己来管理状态信息,自己实现状态的序列化和故障恢复。
但是大部分情况下,我们都是使用的托管状态,就是由Flink来管理状态信息。
那在托管状态下其实又把状态分成了两类,分别是算子状态(Operator State)和按键分区状态(Keyed State)。
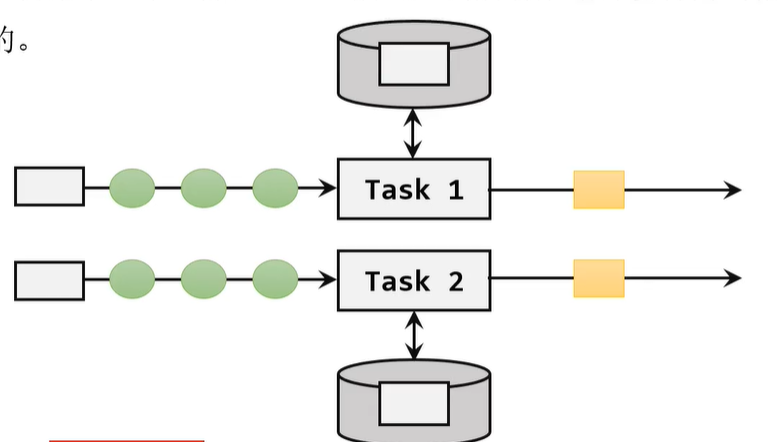
这两种状态的区别很简单,就是看状态的获取是否要按照Key来获取,不同的Key之间不能获取到同一个状态的。下面的这个就是算子状态的示意图。在这个图中,流入同一个子任务的数据共享同一个状态。
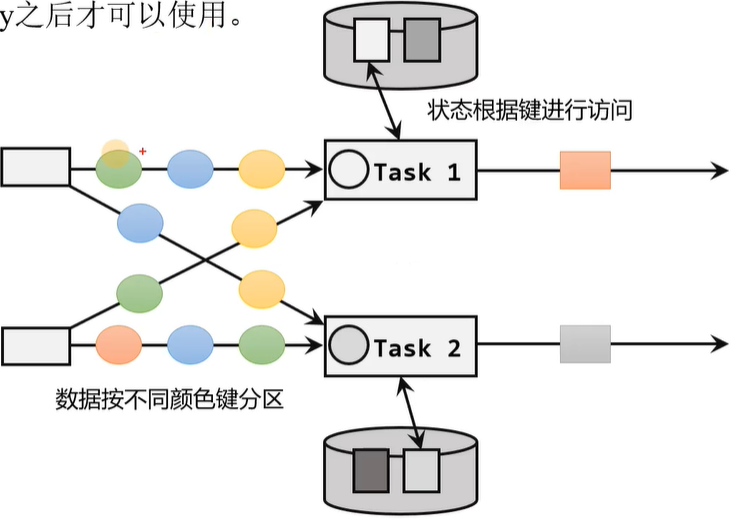
下面是按键分区状态的示意图,就能看到虽然数据会发往同一个子任务中,但是在这个子任务中依然会按照Key值来获取不同的状态信息。
三、状态的生存时间
在实际的应用中,状态会随着时间的推移而渐渐增多,如果不对其加以限制,状态就会把存储空间耗尽。开始的优化思路是直接在代码中调用.clear()方法去清除状态,但是有的时候我们的逻辑不希望将状态直接给清除掉,这时就需要配置一个状态的“生存时间”(time-to-live,TTL)。也就是说,超出这一时间之后状态才会被清除。那这里又出现了一个问题,就是我们需要怎么去监测这个状态信息的生存时间到了呢?如果用一个进程不停地扫描所有的状态看是否过期,这样会消耗大量的资源在做这种无用功。所有我们给状态加了一个属性,也就是状态的“失效时间”。状态创建时,设置失效时间=当前时间+TTL;之后如果有对状态的访问和修改,我们再对失效时间进行更新;当需要拿数据进行操作的时候或者每隔一段时间扫描检查状态是否失效的操作要执行时,就可以判断状态是否失效,从而确定是否需要将状态清除。