Cache的基本原理和缓存一致性
接触过很多软件工程师,在他们认识里,好像Cache的“透明”的,是硬件工程师的事情,并不怎么关心Cache的行为。但实际上想要进一步提升软件性能、优化系统设计,写出高效的代码,对Cache的理解使用是必不可少。
当然我也是在多次使用并调试过Cache后,才有一点点认识,把之前整理的一些笔记简单分享下,希望能够给需要的人提供一点帮助,另外如果问题之处,还请批评指正。
1 基础知识
1.1 什么是cache
**高速缓存(Cache)**是位于CPU和主存之间的告诉存储单元,专门用于缓存最近使用的数据。
1.2 为什么需要缓存 (Cache)
计算机存储系统存在一个基本矛盾:上层越是靠近CPU的存储设备容量越小、速度越快、价格也越贵,而下层越是远离CPU的存储设备容量越大、速度越慢、价格也越便宜。
显然,高性能与大容量难以在单一存储层同时实现。
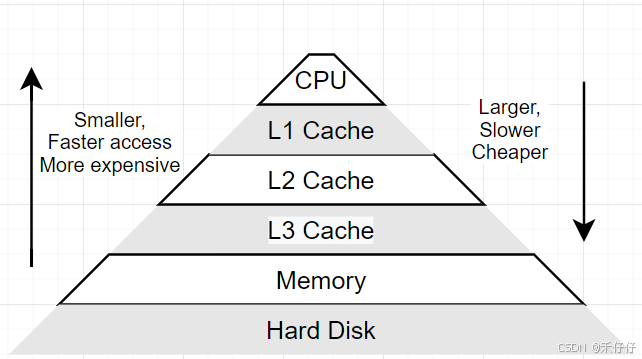
为了弥补 CPU 处理速度与主内存(RAM)访问速度之间的巨大差距,缓存 (Cache) 技术应运而生。CPU 缓存通常分为多级,最常见的是 L1(一级缓存)、L2(二级缓存) 和 L3(三级缓存)。下图是现在CPU架构中常见的大小核心设计,一般会设计三级Cache。
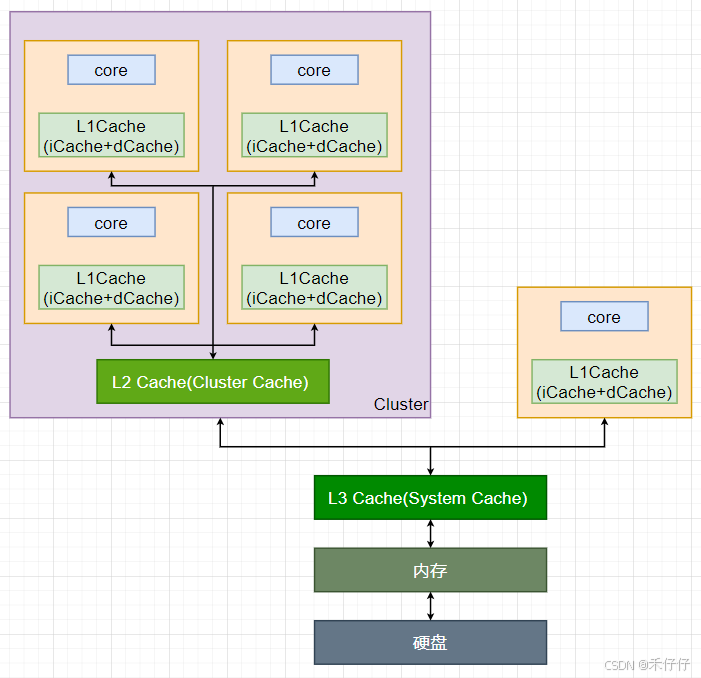
- L1 Cache:
- 最靠近 CPU 核心,速度最快(必须接近 CPU 的时钟频率),成本最高,容量最小(通常在几十 KB 级别)。
- 一般分为指令缓存 (I-Cache) 和数据缓存 (D-Cache)。两者原理类似,但 D-Cache 需要支持读写操作,而 I-Cache 通常只读,因此 D-Cache 的设计更为复杂。
- 使用高速的多端口 SRAM 实现。大容量 SRAM 的查找时间会更长,这限制了 L1 的容量。
- L2 Cache:
- 一般在一个cluster内部共享,用来加速协调SMP多核的访问
- 速度稍慢于 L1,成本和容量介于 L1 和 L3 之间(通常是几百 KB 到几 MB 级别)。
- 通常是指令和数据共享的设计。它作为 L1 Cache 和更低层级存储(L3 或内存)之间的缓冲,旨在保存更多近期可能被访问的数据。
- L3 Cache:
- 位于 L2 Cache 和主内存之间,也可以称为system cache,通常被设计为所有核心共享的资源,减少访问主内存的次数
- 速度比 L2 Cache 更慢,但远快于主内存。
- 容量更大(通常是几 MB 到几十 MB 级别),单位容量成本相对 L2 更低。
当然上面的解释是显而易见的,下面是更加专业理论的解释为什么需要Cache,如下:
- 加速访问速度
由于CPU的访问速度远高于主内存,频繁的数据交换会导致瓶颈。Cache通过缓存经常访问的数据减少对内存的依赖,显著加快数据访问速度。 - 利用局部原理
基于时间和空间相关的特性,程序往往重复访问相同或者邻近的数据。Cache能够高效的捕捉这种模式,提高更快的数据响应
NOTE:
时间相关性:如果一个数据现在被访问了,那么在以后很有可能还会被访问
空间相关性:如果一个数据现在被访问了,那么它周围的数据在以后也很有可能被访问。
2 Cache的原理
当然网上有很多硬件大佬对Cache机制原理的分享,我这里算是分享下自己的学习,意在简单理解硬件行为的同时更好的提升软件质量。
Cache主要由两部分组成,Tag RAM和Data RAM。
2.1 高速缓存(Cache)的核心组成
高速缓存的物理结构主要由两部分构成:
- Tag RAM
作用:存储缓存行(Cache Line)对应的内存地址高位信息(Tag)。
工作机制:通过比较访问地址的 Tag 部分与存储的 Tag,判断目标数据是否命中缓存。
- Data RAM
作用:存储实际的内存数据块(Cache Data Block)。
设计依据:基于程序局部性原理(时间局部性 + 空间局部性),一次加载连续地址的数据。
另外一个Tag和它对应的所有数据组成的一行称为一个cacheline,是高速缓存操作的最小单位,一般设计在4-128bytes(我是用过的Cache line是32和64bytes的CPU,另外这里说的cacheline大小指的是data block的大小,不包含tag)。
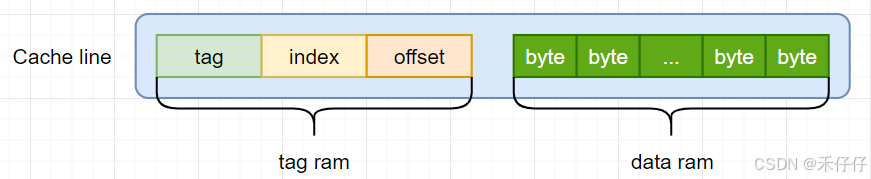
Cache匹配简单流程(以读内存为例)
- 1、地址拆分:访问地址 → [tag] + [index] + [offset]。
- 2、定位Cache line:用index找到对应的 Cache line。
- 3、定位Cache line filed: 用offset找到在Cache line对应的位置
- 4、tag匹配:比较所有Cache line 的Tag与地址的 Tag:
- 命中(hit):直接读取数据块,使用offset定位具体字节。
- 未命中(miss):从内存加载数据块,替换对应的Cache line(按替换策略)。
2.2 Cache的组成方式
2.2.1 直接映射缓存
Cache 被分成很多行(cacheline),一行可以存储主存的任意一个数据块,数据块大小等于cacheline;每个内存块只能放在Cache的一个固定位置。
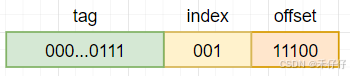
举例看下,直接映射缓存的,假如当前使用Cache size是256bytes,8个cacheline,每个cacheline size是32bytes。此时CPU(x32)要访问0x73c这个地址。
- tag ram分布
- offset:
cacheline size是32bytes,所以要访问全部byte需要5bit(2^5=32) - index
一共有8个cacheline,所以索引需要3bit(2^3=8) - tag
当前是的地址位宽(AW)是32bit,则tag为24bit(32-5-3=24)
举例:地址0x73c解析为
- 定位流程,如图
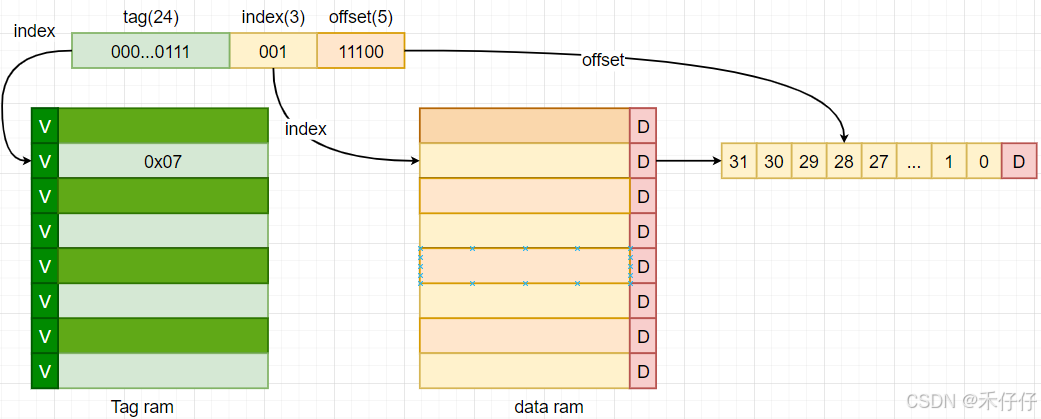
- 1、 取index定位到对应的cacheline
- 2、 取offset定位到对应的byte
- 3、 取tag ram里的tag和地址中的tag比较,如果相同表明该是cache命中(hit),否则miss(说明是其他地址的数据)
另外:
- 实际上每个cacheline的tag还有一个valid bit,这个bit用来表示cacheline中数据是否有效(1有效;0是无效)。实际在确认hit之前,会检查该位是否有效,有效tag才有意义,否则无效,直接判断失效。
- data ram最后会有一个dirty bit,用于标记数据是否被修改且未同步回主存,在写回策略发挥关键作用,后面在详细说明下。
直接映射缓存在硬件设计上会更加简单,成本上也会较低。根据直接映射缓存的工作方式,我们可以画出主存地址地址和Cache的对应的关系图,如下:
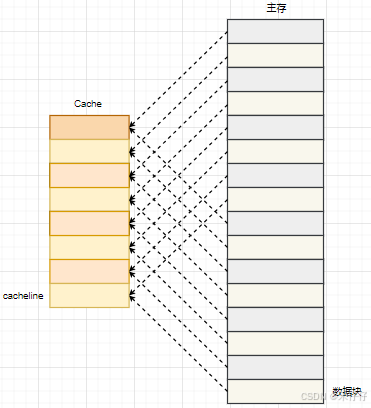
可以看到数据块0-7地址对应数据刚好对应整个Cache,数据块8-f的地址也是同样对应整个Cache。
但这种方式在使用时可能带来以下问题:
- 1.高冲突
比如数据块0、8都是对应cacheline0,恰好访问在数据0和8之前切换,则会造成Cache 未满,热点数据仍被频繁驱逐,命中率骤降。 - 2.资源利用率低
比如频繁访问数据块3,则cacheline3一直被占用,而其他cacheline一直限制 - 3.性能波动
比如部分程序内存地址分布问题,导致访问冲突率高,会导致性能下降。
以上使得现代处理器很少使用这种方式。
2.2.2 组相连映射缓存
当然组相连就是为了解决直接映射不足,在**组相联缓存(Set-Associative Cache)**中,一个数据可以存储在多个cacheline中,具体位置由组索引(Set Index)决定。如果一个数据可以映射到同一组内的n个不同的Cache Line,那么这个缓存就称为n路组相联(n-way set-associative)缓存。
例如:
2路组相联:每个组(Set)有2个Cache Line,数据可放在其中任意一个。
4路组相联:每个组有4个Cache Line,数据可存放在其中任意一个。
这种设计减少了冲突失效(Conflict Miss),提高了缓存命中率,相对增加些硬件复杂度(如并行比较多个Tag)。
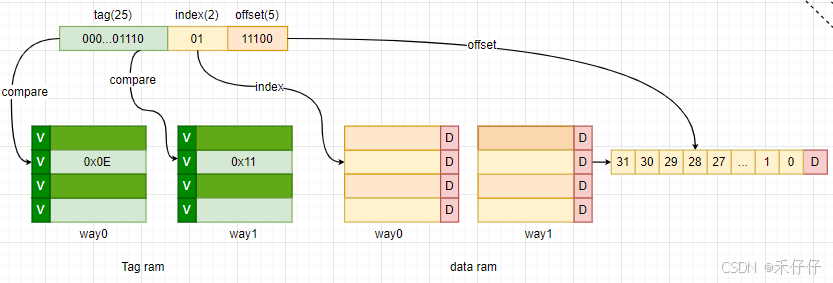
原理:
- 1.地址解析:当CPU请求数据时,首先将地址分解为三部分:标记(Tag)、组索引(Set Index)和偏移(offset)
- 2.组定位:利用组索引确定数据位域哪个组。每个组包含多个缓存行(cacheline)
- 3.标记比较:在确定的组内,CPU比较请求地址的标记和组内tag ram的标记(valid为高时),寻找匹配的缓存行
- 4.命中处理:如果找到匹配的标记,表示缓存命中(hit),则根据偏移直接从缓存中读取数据
- 5.未命中处理:若无匹配,则缓存未命中(miss),需要从主存加载数据到缓存中
根据组相连映射缓存的工作方式,我们可以画出主存地址地址和Cache的对应的关系图,如下:
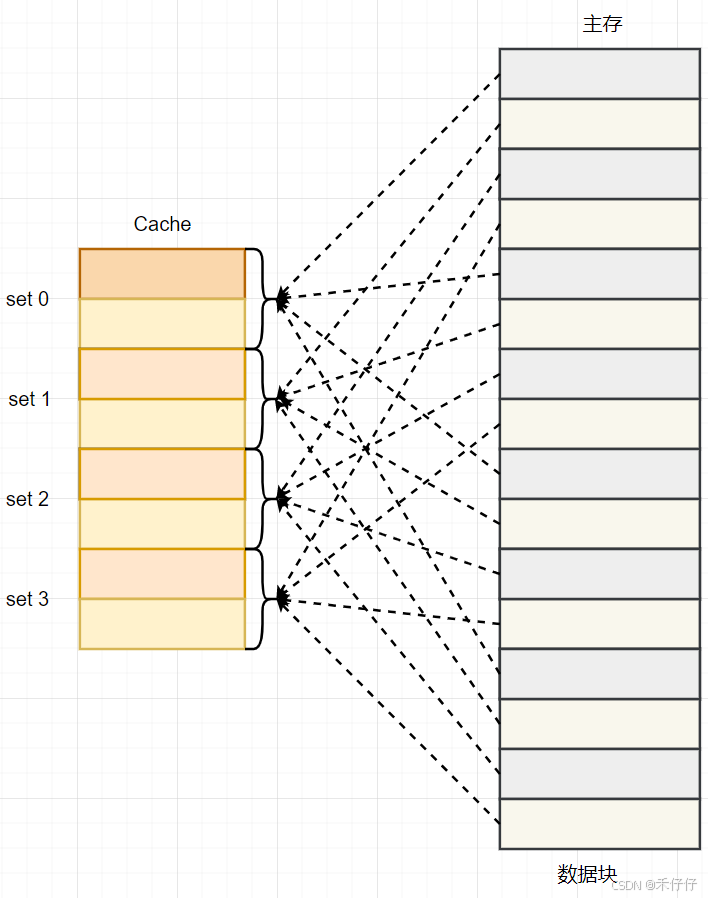
2.2.3 全相连映射缓存
在**全相连缓存(Fully Associative Cache)**中,存储器中的任意地址可以存放在任意一个Cache Line中,无需通过索引(Index)定位。此时,地址仅包含Tag和块内偏移(Block Offset),系统会并行比较所有Cache Line的Tag(通常使用CAM(内容寻址存储器)存储Tag,而Data部分仍用普通SRAM存储)。由于需要全局匹配,全相连缓存的灵活性最高(无冲突失效),但硬件开销大、延迟高,因此通常仅用于小容量高速缓存(如TLB)。
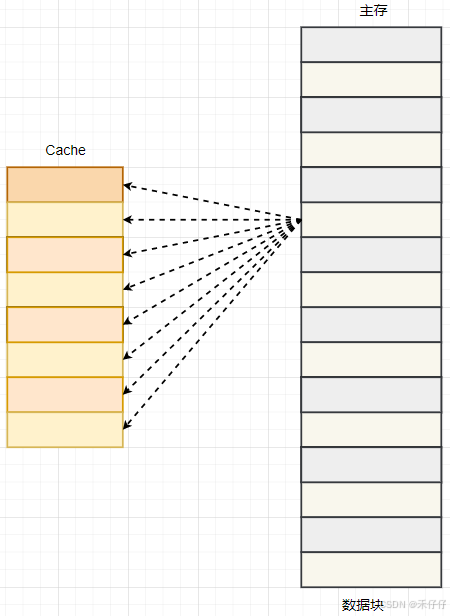
在实际硬件设计中,更常用的是组相连映射方式,缓存的分组策略(特别是组相联缓存的关联度选择)会紧密围绕 Cache 总容量、访问延迟要求及成本约束进行综合权衡:
分组(n值)与 Cache 容量的关系:
- 小容量 Cache(如 L1 Cache:32–64KB):→ 采用 4–8 路组相联(如 Intel L1: 8-way)。理由:容量有限时需较高关联度缓解冲突失效(避免频繁替换热点数据)。
- 大容量 Cache(如 L3 Cache:10–100MB):→ 采用 12–24 路组相联(如 AMD Zen4: 16-way,Apple M2: 24-way)。理由:容量本身降低冲突概率,但须控制延迟 → 中等关联度 + 分Bank设计。
L1、L2、L3 Cache常见的分组:
- L1 Cache(延迟敏感):8-way(Intel/ARM)或 4-way(部分嵌入式芯片)。
- L2 Cache(容量/延迟平衡):8–12 way(通用CPU)或 16-way(Apple M系列)。
- L3 Cache(容量优先):12–24 way(通过多组Bank并行降低高关联度延迟)。
实际现在很多设计都会把Cache做成可配的,比如把Cache配置为ram使用,或者一半配成ram另外一半配置为Cache
3 cache更新策略
cache更新策略是指当发生cache命中时,写操作应该如何更新数据。
-
cache写策略(Write Policy),缓存命中时的写入方式分成两种:写直通((Write-Through))和回写(Write-Back)。
-
写分配策略(Write Allocation Policy), 缓存未命中时的决策分为:写分配(Write-Allocate)和非写分配(Non-Write-Allocate)
-
读分配策略(Read-Allocation Policy),即缓存未命中时的读取方式分为:读分配(Read-Allocate)和非读分配(Non-Read-Allocate)
而读命中,一般没有名字,直接从Cache中读取。
下面时Read/Write在Hit/Miss情况下,不同策略的表现行为和优缺点:
| 行为 | Hit/Miss | 类型 | 解释 | 优缺点 |
|---|---|---|---|---|
| Read | Hit | - | CPU 直接从 Cache 获取数据。 | 优点:极快(纳秒级延迟)。 |
| Miss | Read Through | 数据直接从 Main Memory 读取到 CPU,不存入 Cache。 | 优点:避免 Cache 污染。 缺点:重复读取相同数据效率低。 | |
| Read Allocate | 数据从 Main Memory 加载到 Cache,再从 Cache 读取到 CPU。 | 优点:后续读取相同数据更快。 缺点:占用 Cache 空间。 | ||
| No-Read Allocate | 等同于 Read Through,数据不加载到 Cache。 | 同 Read Through。 | ||
| Write | Hit | Write Through | 数据同时写入 Cache 和 Main Memory。 | 优点:内存数据始终最新(强一致性)。 缺点:写入延迟高,带宽压力大。 |
| Write Back | 数据仅写入 Cache,Main Memory 延迟更新(如 Cache 替换时)。 | 优点:写入速度快,带宽占用低。 缺点:内存数据可能过期(需额外机制维护一致性)。 | ||
| Miss | Write Allocate | 数据先加载到 Cache,再按 Write Hit 策略处理(Write Through/Back)。 | 优点:适合后续可能重复写入的场景。 缺点:额外加载开销。 | |
| No-Write Allocate | 数据直接写入 Main Memory,不加载到 Cache。 | 优点:避免无效 Cache 占用。 缺点:后续写入无加速。 |
4 Cache使用问题
4.1 性能问题
const int row = 1024;
const int col = 1024;
int matrix[row][col];//按行遍历
int sum_row = 0;
for (int r = 0; r < row; r++) {for (int c = 0; c < col; c++) {sum_row += matrix[r][c];}
}//按列遍历
int sum_col = 0;
for (int c = 0; c < col; c++) {for (int r = 0; r < row; r++) {sum_col += matrix[r][c];}
}
上面是个老生常谈的代码,Cache最小操作单元是cacheline,根据局部性原理,访问主存时会把相邻的部分也加载到Cache里,按行访问的话,后续访问地址相邻的数据时,Cache的命中率就会很高,性能相应按列访问会有不小提升。
4.2 缓存一致性问题
-
写直达(Write Through)
我们在写内存时,如果是写直达(Write Through)方式,把数据同时写入内存和 Cache 中,那么内存和Cache就直接保持一致,就不会存在一致性问题。
但这样优点就是简单,但缺点是无论数据在不在 Cache 里面,每次写操作都会写回到内存,这样写操作将会花费大量的时间,无疑性能会受到很大的影响。 -
写回(Write Back)
在写回机制中,当发生写操作时,新的数据仅仅被写入 Cache Block 里,只有当修改过的 Cache Block「被替换」时才需要写到内存中,减少了数据写回内存的频率,这样便可以提高系统的性能。 -
缓存命中时(数据在 Cache 中)
- 直接更新 Cache 数据
- 标记 Cache Block 为脏(Dirty) → 代表与内存不一致
- 但不写入内存
2.缓存未命中时(数据不在 Cache 中)
- 若目标 Cache Block 是脏的:
- 先将该 Block 数据写回内存
- 再加载新数据到 Cache
- 标记为脏
- 若目标 Cache Block 是干净的: - 直接加载新数据到 Cache
- 标记为脏
会发现这种好处是,在大量操作命中Cache的时,大部分时间CPU都不需要读写内存,性能将可以提升很多。
场景1:
单核缓存一致性问题
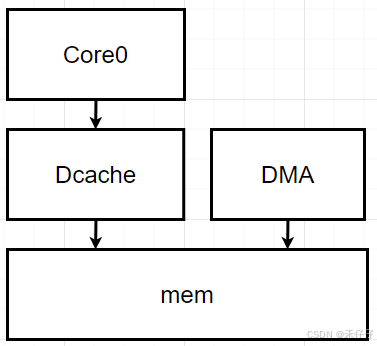
1、DMA将数据包写入内存mem,CPU(协议栈)需要读取该数据包,但Cache并感知不到内存更新,这是就会导致不一致的问题;
2、同理,CPU(协议栈)组包之后,写入mem,实际只写入了Dcache,并未写入到内存,此时DMA去读取,获取到的也是旧数据。
解决方法:
一般这种单核和外设之间的数据一致性问题,也比较简单,可以通过软件来操作保证缓存一致性:
1、CPU读时数据标记缓存无效,将会把数据先读取到Cache,再从Cache读走。
2、CPU写数据时,刷(flush)Cache操作,将数据从cache刷到mem中。
当然也可以把Cache关了,读写直通(虽然没了一致性问题,但就相当于没了Cache)
场景2:
多核一致性问题
现在的CPU很多都是多核,每个Core都会拥有各自的L1 Cache,每个Cluster也有有自己的L2 Cache,所有的Core也会有L3 Cache,那么就会带来多核的缓存一致性的问题,如果不能保证缓存一致性的问题,就可能给软件带来很多意想不到的错误。
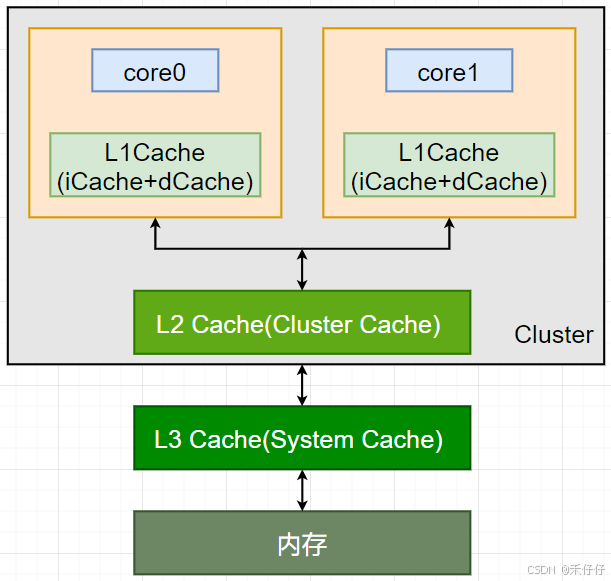
当前的Cluster里共两个core,当core0修改全局地址变量 i = 10;然后缓存到了Cache(并未修改mem),此时core1读取i,获取到的仍然时未修改前的变量。(这里只有L1 是各自core独有的,L2和L3 Cache是俩个core共有)
为了解决这个问题,就要一种机制来同步俩个core 缓存中的数据,这个机制就要做到以下两点:
1、写传播(Wreite Propagation),即:某个core的Cache数据更新时,必须要传播到其他core的Cache
2、事务的串形化(Transaction Serialization),即:某个core里对数据的操作顺序,必须在其他核心看起来顺序是一样的(这里实现需要“锁”机制)
总线嗅探(Snooping)
原理:所有缓存通过共享总线监听内存操作(如读写请求),嗅到相关地址时触发本地动作。
MESI协议
最经典的协议是MESI
MESI 协议其实是 4 个状态单词的开头字母缩写,分别是:
- Modified,已修改
- Exclusive,独占
- Shared,共享
- Invalidated,已失效
这四个状态来标记cacheline四个不同的状态,即cacheline的状态机。
| 状态 | 含义 | 监听动作触发 |
|---|---|---|
| M (Modified) | 数据已修改(仅本核心有效) | 收到读请求 → 写回内存并转S |
| E (Exclusive) | 独占(未修改,仅本核有) | 收到写请求 → 转 M |
| S (Shared) | 共享(多核只读副本) | 收到写请求 → 无效化本副本 |
| I (Invalid) | 无效(数据不可用) | 可加载新数据 |
简单流程:
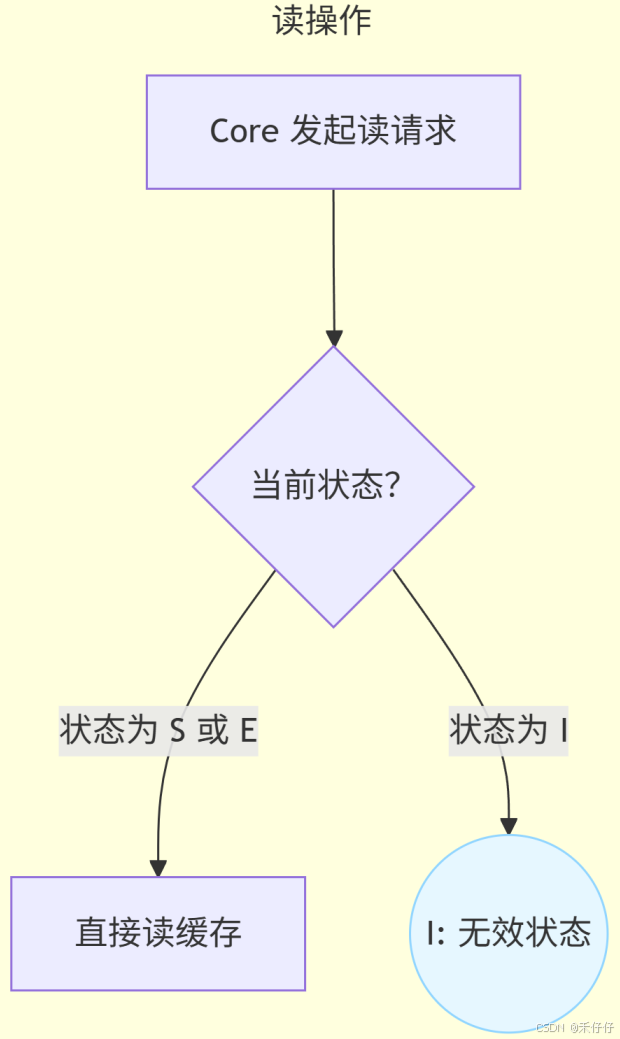
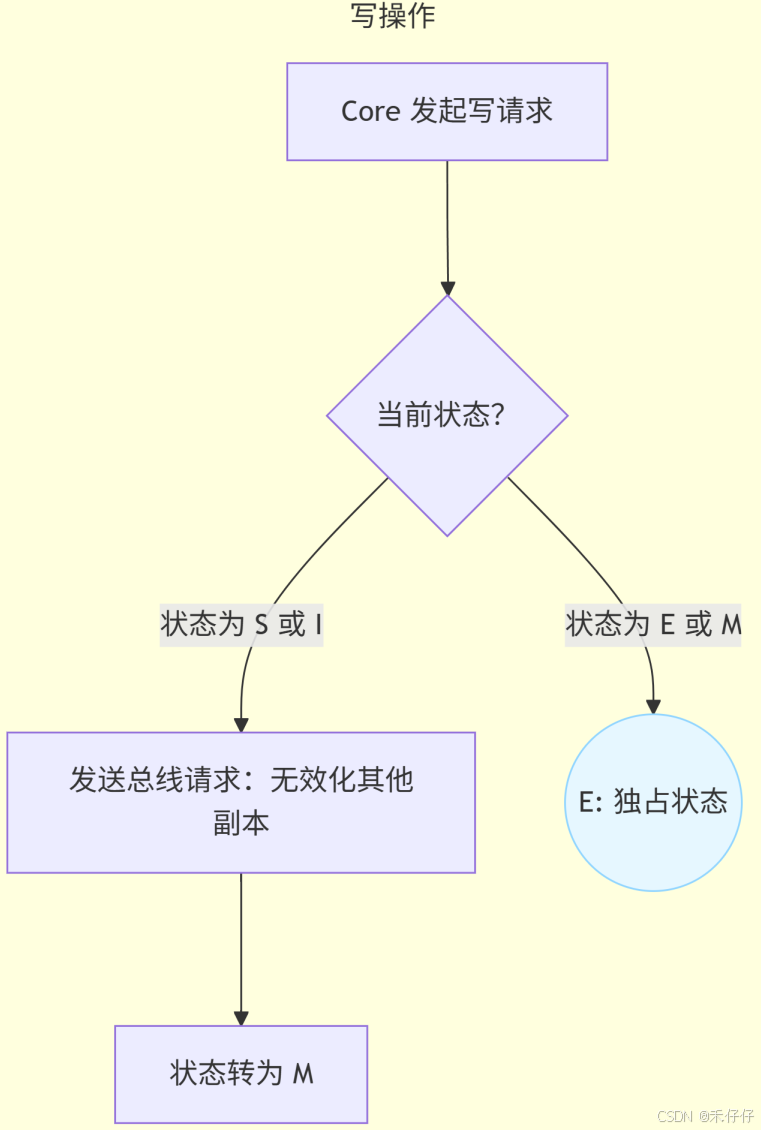
当然我这里只是简单介绍了下保证缓存一致性的机制,感兴趣,可以自行搜索深度学习下,作为软件开发,想要提升软件性能,发挥硬件的最大能力,还是要理解这些硬件机制的。
参考:
Cache 学习笔记
浅析CPU高速缓存(cache)
一文看懂CPU cache的基本原理