低配硬件运行智谱GLM-4.5V视觉语言模型推理服务的方法
低配硬件运行智谱GLM-4.5V视觉语言模型推理服务的方法
flyfish
2025-08-14
2025-08-15
新建环境
首先查看当前已有的环境(可选,用于确认要克隆的环境名称):
conda env list
克隆环境的命令
conda create --name 新环境名称 --clone 被克隆的环境名称
配置
输入
python -c "import torch; print('PyTorch:', torch.__version__); print('CUDA:', torch.version.cuda)"
python --version
输出
PyTorch: 2.7.1+cu126
CUDA: 12.6
Python 3.12.9
flash_attn版本
flash_attn-2.8.1+cu12torch2.7cxx11abiFALSE-cp312-cp312-linux_x86_64.whl
transformers 版本
pip show transformers
Name: transformers
Version: 4.56.0.dev0
先把模型压缩
GLM-4.5V 原始模型 + AWQ 压缩技术处理 =GLM-4.5V-AWQ
模型压缩后可以占用很少的硬件资源
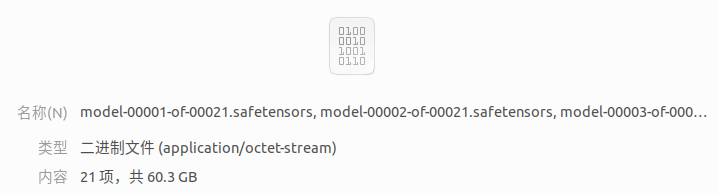
压缩后模型的大小
运行
vllm serve GLM-4.5V-AWQ --served-model-name GLM-4.5V-AWQ --tool-call-parser glm45 --reasoning-parser glm45 --enable-auto-tool-choice --enable-expert-parallel --max-num-seqs 512 --tensor-parallel-size 2
解释
vllm serve # 指定要部署的模型(经过AWQ量化的GLM-4.5V多模态模型)GLM-4.5V-AWQ # 设置服务对外暴露的模型名称(客户端调用时需使用此名称)--served-model-name GLM-4.5V-AWQ # 指定GLM-4.5系列模型的工具调用解析器(适配其特有的工具调用格式)--tool-call-parser glm45 # 指定GLM-4.5系列模型的推理逻辑解析器(确保推理过程正确解析)--reasoning-parser glm45 # 启用模型自动选择工具的功能(无需人工指定,模型自主判断是否调用外部工具)--enable-auto-tool-choice # 启用专家并行模式(针对MoE架构模型,将不同专家网络分配到不同设备并行计算)--enable-expert-parallel # 设置服务同时处理的最大序列数(并发请求上限为512)--max-num-seqs 512 # 指定张量并行的设备数量(使用2个GPU拆分模型层进行并行计算)--tensor-parallel-size 2
使用例子

Thinking
用户现在问“你是谁?”,需要明确回答。首先,我是由智谱AI研发的人工智能多模态模型,叫GLM-4.5V,要准确传达这个信息。需要简洁明了,让用户清楚身份。我是由智谱AI研发的人工智能多模态模型GLM-4.5V,能够理解和生成多种类型的信息,帮助用户解答问题、提供服务等
解释图像


启动之后的日志
INFO 08-13 21:45:37 [__init__.py:241] Automatically detected platform cuda.
(APIServer pid=4093961) INFO 08-13 21:45:40 [api_server.py:1805] vLLM API server version 0.10.1.dev620+gcf453f3f5
(APIServer pid=4093961) INFO 08-13 21:45:40 [utils.py:326] non-default args: {'model_tag': 'GLM-4.5V-AWQ', 'enable_auto_tool_choice': True, 'tool_call_parser': 'glm45', 'model': 'GLM-4.5V-AWQ', 'served_model_name': ['GLM-4.5V-AWQ'], 'reasoning_parser': 'glm45', 'tensor_parallel_size': 2, 'enable_expert_parallel': True, 'max_num_seqs': 512}
(APIServer pid=4093961) INFO 08-13 21:45:48 [__init__.py:702] Resolved architecture: Glm4vMoeForConditionalGeneration
(APIServer pid=4093961) INFO 08-13 21:45:48 [__init__.py:1740] Using max model len 65536
(APIServer pid=4093961) INFO 08-13 21:45:48 [scheduler.py:222] Chunked prefill is enabled with max_num_batched_tokens=2048.
INFO 08-13 21:45:55 [__init__.py:241] Automatically detected platform cuda.
(EngineCore_0 pid=4094678) INFO 08-13 21:45:58 [core.py:620] Waiting for init message from front-end.
(EngineCore_0 pid=4094678) INFO 08-13 21:45:58 [core.py:72] Initializing a V1 LLM engine (v0.10.1.dev620+gcf453f3f5) with config: model='GLM-4.5V-AWQ', speculative_config=None, tokenizer='GLM-4.5V-AWQ', skip_tokenizer_init=False, tokenizer_mode=auto, revision=None, override_neuron_config={}, tokenizer_revision=None, trust_remote_code=False, dtype=torch.float16, max_seq_len=65536, download_dir=None, load_format=auto, tensor_parallel_size=2, pipeline_parallel_size=1, disable_custom_all_reduce=False, quantization=awq_marlin, enforce_eager=False, kv_cache_dtype=auto, device_config=cuda, decoding_config=DecodingConfig(backend='auto', disable_fallback=False, disable_any_whitespace=False, disable_additional_properties=False, reasoning_backend='glm45'), observability_config=ObservabilityConfig(show_hidden_metrics_for_version=None, otlp_traces_endpoint=None, collect_detailed_traces=None), seed=0, served_model_name=GLM-4.5V-AWQ, enable_prefix_caching=True, chunked_prefill_enabled=True, use_async_output_proc=True, pooler_config=None, compilation_config={"level":3,"debug_dump_path":"","cache_dir":"","backend":"","custom_ops":[],"splitting_ops":["vllm.unified_attention","vllm.unified_attention_with_output","vllm.mamba_mixer2"],"use_inductor":true,"compile_sizes":[],"inductor_compile_config":{"enable_auto_functionalized_v2":false},"inductor_passes":{},"use_cudagraph":true,"cudagraph_num_of_warmups":1,"cudagraph_capture_sizes":[512,504,496,488,480,472,464,456,448,440,432,424,416,408,400,392,384,376,368,360,352,344,336,328,320,312,304,296,288,280,272,264,256,248,240,232,224,216,208,200,192,184,176,168,160,152,144,136,128,120,112,104,96,88,80,72,64,56,48,40,32,24,16,8,4,2,1],"cudagraph_copy_inputs":false,"full_cuda_graph":false,"pass_config":{},"max_capture_size":512,"local_cache_dir":null}
(EngineCore_0 pid=4094678) WARNING 08-13 21:45:58 [multiproc_worker_utils.py:273] Reducing Torch parallelism from 24 threads to 1 to avoid unnecessary CPU contention. Set OMP_NUM_THREADS in the external environment to tune this value as needed.
(EngineCore_0 pid=4094678) INFO 08-13 21:45:58 [shm_broadcast.py:289] vLLM message queue communication handle: Handle(local_reader_ranks=[0, 1], buffer_handle=(2, 16777216, 10, 'psm_43947ac5'), local_subscribe_addr='ipc:///tmp/036f62e6-84ca-4073-a75a-1a8752ef5460', remote_subscribe_addr=None, remote_addr_ipv6=False)
INFO 08-13 21:46:02 [__init__.py:241] Automatically detected platform cuda.
INFO 08-13 21:46:02 [__init__.py:241] Automatically detected platform cuda.
(VllmWorker TP1 pid=4095007) INFO 08-13 21:46:06 [shm_broadcast.py:289] vLLM message queue communication handle: Handle(local_reader_ranks=[0], buffer_handle=(1, 10485760, 10, 'psm_1a960640'), local_subscribe_addr='ipc:///tmp/798ccd59-f8ad-4dfa-9e57-d187e31343ff', remote_subscribe_addr=None, remote_addr_ipv6=False)
(VllmWorker TP0 pid=4095006) INFO 08-13 21:46:06 [shm_broadcast.py:289] vLLM message queue communication handle: Handle(local_reader_ranks=[0], buffer_handle=(1, 10485760, 10, 'psm_4f18cd46'), local_subscribe_addr='ipc:///tmp/1d553c96-138f-47cf-ad92-fc7f19a5bd6f', remote_subscribe_addr=None, remote_addr_ipv6=False)
(VllmWorker TP1 pid=4095007) INFO 08-13 21:46:07 [__init__.py:1392] Found nccl from library libnccl.so.2
(VllmWorker TP1 pid=4095007) INFO 08-13 21:46:07 [pynccl.py:70] vLLM is using nccl==2.26.2
(VllmWorker TP0 pid=4095006) INFO 08-13 21:46:07 [__init__.py:1392] Found nccl from library libnccl.so.2
(VllmWorker TP0 pid=4095006) INFO 08-13 21:46:07 [pynccl.py:70] vLLM is using nccl==2.26.2
(VllmWorker TP1 pid=4095007) INFO 08-13 21:46:07 [custom_all_reduce.py:35] Skipping P2P check and trusting the driver's P2P report.
(VllmWorker TP0 pid=4095006) INFO 08-13 21:46:07 [custom_all_reduce.py:35] Skipping P2P check and trusting the driver's P2P report.
(VllmWorker TP0 pid=4095006) INFO 08-13 21:46:07 [shm_broadcast.py:289] vLLM message queue communication handle: Handle(local_reader_ranks=[1], buffer_handle=(1, 4194304, 6, 'psm_b939ca6f'), local_subscribe_addr='ipc:///tmp/4139e835-0ee1-4849-8f0e-2ac0ba56dbf5', remote_subscribe_addr=None, remote_addr_ipv6=False)
(VllmWorker TP1 pid=4095007) INFO 08-13 21:46:07 [parallel_state.py:1134] rank 1 in world size 2 is assigned as DP rank 0, PP rank 0, TP rank 1, EP rank 1
(VllmWorker TP0 pid=4095006) INFO 08-13 21:46:07 [parallel_state.py:1134] rank 0 in world size 2 is assigned as DP rank 0, PP rank 0, TP rank 0, EP rank 0
(VllmWorker TP1 pid=4095007) WARNING 08-13 21:46:08 [topk_topp_sampler.py:61] FlashInfer is not available. Falling back to the PyTorch-native implementation of top-p & top-k sampling. For the best performance, please install FlashInfer.
(VllmWorker TP0 pid=4095006) WARNING 08-13 21:46:08 [topk_topp_sampler.py:61] FlashInfer is not available. Falling back to the PyTorch-native implementation of top-p & top-k sampling. For the best performance, please install FlashInfer.
(VllmWorker TP1 pid=4095007) Using a slow image processor as `use_fast` is unset and a slow processor was saved with this model. `use_fast=True` will be the default behavior in v4.52, even if the model was saved with a slow processor. This will result in minor differences in outputs. You'll still be able to use a slow processor with `use_fast=False`.
(VllmWorker TP0 pid=4095006) Using a slow image processor as `use_fast` is unset and a slow processor was saved with this model. `use_fast=True` will be the default behavior in v4.52, even if the model was saved with a slow processor. This will result in minor differences in outputs. You'll still be able to use a slow processor with `use_fast=False`.
(VllmWorker TP0 pid=4095006) INFO 08-13 21:46:45 [gpu_model_runner.py:1942] Starting to load model GLM-4.5V-AWQ...
(VllmWorker TP0 pid=4095006) INFO 08-13 21:46:45 [gpu_model_runner.py:1974] Loading model from scratch...
(VllmWorker TP0 pid=4095006) INFO 08-13 21:46:45 [cuda.py:325] Using Flash Attention backend on V1 engine.
Loading safetensors checkpoint shards: 0% Completed | 0/21 [00:00<?, ?it/s]
(VllmWorker TP1 pid=4095007) INFO 08-13 21:46:46 [gpu_model_runner.py:1942] Starting to load model GLM-4.5V-AWQ...
(VllmWorker TP1 pid=4095007) INFO 08-13 21:46:46 [gpu_model_runner.py:1974] Loading model from scratch...
(VllmWorker TP1 pid=4095007) INFO 08-13 21:46:46 [cuda.py:325] Using Flash Attention backend on V1 engine.
Loading safetensors checkpoint shards: 5% Completed | 1/21 [00:00<00:11, 1.73it/s]
Loading safetensors checkpoint shards: 10% Completed | 2/21 [00:01<00:11, 1.71it/s]
Loading safetensors checkpoint shards: 14% Completed | 3/21 [00:01<00:10, 1.77it/s]
Loading safetensors checkpoint shards: 19% Completed | 4/21 [00:02<00:09, 1.83it/s]
Loading safetensors checkpoint shards: 24% Completed | 5/21 [00:02<00:08, 1.85it/s]
Loading safetensors checkpoint shards: 29% Completed | 6/21 [00:03<00:07, 1.90it/s]
Loading safetensors checkpoint shards: 33% Completed | 7/21 [00:03<00:07, 1.91it/s]
Loading safetensors checkpoint shards: 38% Completed | 8/21 [00:04<00:06, 1.91it/s]
Loading safetensors checkpoint shards: 43% Completed | 9/21 [00:04<00:06, 1.81it/s]
Loading safetensors checkpoint shards: 48% Completed | 10/21 [00:05<00:06, 1.76it/s]
Loading safetensors checkpoint shards: 52% Completed | 11/21 [00:06<00:05, 1.76it/s]
Loading safetensors checkpoint shards: 57% Completed | 12/21 [00:06<00:05, 1.80it/s]
Loading safetensors checkpoint shards: 62% Completed | 13/21 [00:06<00:03, 2.37it/s]
Loading safetensors checkpoint shards: 67% Completed | 14/21 [00:07<00:03, 2.15it/s]
Loading safetensors checkpoint shards: 71% Completed | 15/21 [00:07<00:02, 2.02it/s]
Loading safetensors checkpoint shards: 76% Completed | 16/21 [00:08<00:02, 2.36it/s]
Loading safetensors checkpoint shards: 81% Completed | 17/21 [00:08<00:01, 2.14it/s]
Loading safetensors checkpoint shards: 86% Completed | 18/21 [00:09<00:01, 1.97it/s]
Loading safetensors checkpoint shards: 90% Completed | 19/21 [00:09<00:01, 1.94it/s]
Loading safetensors checkpoint shards: 95% Completed | 20/21 [00:10<00:00, 1.91it/s]
Loading safetensors checkpoint shards: 100% Completed | 21/21 [00:10<00:00, 1.88it/s]
Loading safetensors checkpoint shards: 100% Completed | 21/21 [00:10<00:00, 1.93it/s]
(VllmWorker TP0 pid=4095006)
(VllmWorker TP0 pid=4095006) INFO 08-13 21:46:56 [default_loader.py:262] Loading weights took 10.95 seconds
(VllmWorker TP1 pid=4095007) INFO 08-13 21:46:57 [default_loader.py:262] Loading weights took 10.61 seconds
(VllmWorker TP0 pid=4095006) INFO 08-13 21:47:01 [gpu_model_runner.py:1996] Model loading took 28.2929 GiB and 15.586587 seconds
(VllmWorker TP1 pid=4095007) INFO 08-13 21:47:01 [gpu_model_runner.py:1996] Model loading took 28.2929 GiB and 14.970966 seconds
(VllmWorker TP1 pid=4095007) INFO 08-13 21:47:02 [gpu_model_runner.py:2499] Encoder cache will be initialized with a budget of 30970 tokens, and profiled with 1 video items of the maximum feature size.
(VllmWorker TP0 pid=4095006) INFO 08-13 21:47:02 [gpu_model_runner.py:2499] Encoder cache will be initialized with a budget of 30970 tokens, and profiled with 1 video items of the maximum feature size.
(VllmWorker TP1 pid=4095007) INFO 08-13 21:47:11 [backends.py:530] Using cache directory: /home/user/.cache/vllm/torch_compile_cache/b290c7cb24/rank_1_0/backbone for vLLM's torch.compile
(VllmWorker TP1 pid=4095007) INFO 08-13 21:47:11 [backends.py:541] Dynamo bytecode transform time: 7.69 s
(VllmWorker TP0 pid=4095006) INFO 08-13 21:47:12 [backends.py:530] Using cache directory: /home/user/.cache/vllm/torch_compile_cache/b290c7cb24/rank_0_0/backbone for vLLM's torch.compile
(VllmWorker TP0 pid=4095006) INFO 08-13 21:47:12 [backends.py:541] Dynamo bytecode transform time: 8.62 s
(VllmWorker TP1 pid=4095007) INFO 08-13 21:47:16 [backends.py:194] Cache the graph for dynamic shape for later use
(VllmWorker TP0 pid=4095006) INFO 08-13 21:47:17 [backends.py:194] Cache the graph for dynamic shape for later use
(VllmWorker TP1 pid=4095007) /home/user/anaconda3/envs/glm/lib/python3.12/site-packages/torch/_inductor/compile_fx.py:236: UserWarning: TensorFloat32 tensor cores for float32 matrix multiplication available but not enabled. Consider setting `torch.set_float32_matmul_precision('high')` for better performance.
(VllmWorker TP1 pid=4095007) warnings.warn(
(VllmWorker TP0 pid=4095006) /home/user/anaconda3/envs/glm/lib/python3.12/site-packages/torch/_inductor/compile_fx.py:236: UserWarning: TensorFloat32 tensor cores for float32 matrix multiplication available but not enabled. Consider setting `torch.set_float32_matmul_precision('high')` for better performance.
(VllmWorker TP0 pid=4095006) warnings.warn(
(VllmWorker TP1 pid=4095007) INFO 08-13 21:48:09 [backends.py:215] Compiling a graph for dynamic shape takes 57.55 s
(VllmWorker TP0 pid=4095006) INFO 08-13 21:48:11 [backends.py:215] Compiling a graph for dynamic shape takes 58.54 s
(VllmWorker TP1 pid=4095007) WARNING 08-13 21:48:17 [fused_moe.py:727] Using default MoE config. Performance might be sub-optimal! Config file not found at ['/home/user/anaconda3/envs/glm/lib/python3.12/site-packages/vllm/model_executor/layers/fused_moe/configs/E=64,N=8192,device_name=NVIDIA_RTX_A6000.json']
(VllmWorker TP0 pid=4095006) WARNING 08-13 21:48:17 [fused_moe.py:727] Using default MoE config. Performance might be sub-optimal! Config file not found at ['/home/user/anaconda3/envs/glm/lib/python3.12/site-packages/vllm/model_executor/layers/fused_moe/configs/E=64,N=8192,device_name=NVIDIA_RTX_A6000.json']
(VllmWorker TP0 pid=4095006) INFO 08-13 21:48:23 [monitor.py:34] torch.compile takes 67.17 s in total
(VllmWorker TP1 pid=4095007) INFO 08-13 21:48:23 [monitor.py:34] torch.compile takes 65.25 s in total
(VllmWorker TP0 pid=4095006) INFO 08-13 21:48:25 [gpu_worker.py:276] Available KV cache memory: 11.36 GiB
(VllmWorker TP1 pid=4095007) INFO 08-13 21:48:25 [gpu_worker.py:276] Available KV cache memory: 11.39 GiB
(EngineCore_0 pid=4094678) INFO 08-13 21:48:25 [kv_cache_utils.py:829] GPU KV cache size: 129,456 tokens
(EngineCore_0 pid=4094678) INFO 08-13 21:48:25 [kv_cache_utils.py:833] Maximum concurrency for 65,536 tokens per request: 1.98x
(EngineCore_0 pid=4094678) INFO 08-13 21:48:25 [kv_cache_utils.py:829] GPU KV cache size: 129,792 tokens
(EngineCore_0 pid=4094678) INFO 08-13 21:48:25 [kv_cache_utils.py:833] Maximum concurrency for 65,536 tokens per request: 1.98x
Capturing CUDA graph shapes: 99%| | 66/67 [00:09<00:00, 8.48it/s](VllmWorker TP1 pid=4095007) INFO 08-13 21:48:36 [custom_all_reduce.py:196] Registering 6164 cuda graph addresses
Capturing CUDA graph shapes: 100%|67/67 [00:10<00:00, 6.26it/s]
(VllmWorker TP0 pid=4095006) INFO 08-13 21:48:37 [custom_all_reduce.py:196] Registering 6164 cuda graph addresses
(VllmWorker TP1 pid=4095007) INFO 08-13 21:48:37 [gpu_model_runner.py:2598] Graph capturing finished in 11 secs, took 1.45 GiB
(VllmWorker TP0 pid=4095006) INFO 08-13 21:48:37 [gpu_model_runner.py:2598] Graph capturing finished in 11 secs, took 1.45 GiB
(EngineCore_0 pid=4094678) INFO 08-13 21:48:37 [core.py:199] init engine (profile, create kv cache, warmup model) took 95.53 seconds
(EngineCore_0 pid=4094678) Using a slow image processor as `use_fast` is unset and a slow processor was saved with this model. `use_fast=True` will be the default behavior in v4.52, even if the model was saved with a slow processor. This will result in minor differences in outputs. You'll still be able to use a slow processor with `use_fast=False`.
(APIServer pid=4093961) INFO 08-13 21:49:05 [loggers.py:142] Engine 000: vllm cache_config_info with initialization after num_gpu_blocks is: 8091
(APIServer pid=4093961) INFO 08-13 21:49:05 [api_server.py:1611] Supported_tasks: ['generate']
(APIServer pid=4093961) WARNING 08-13 21:49:05 [__init__.py:1615] Default sampling parameters have been overridden by the model's Hugging Face generation config recommended from the model creator. If this is not intended, please relaunch vLLM instance with `--generation-config vllm`.
(APIServer pid=4093961) INFO 08-13 21:49:05 [serving_responses.py:120] Using default chat sampling params from model: {'top_k': 1, 'top_p': 0.0001}
(APIServer pid=4093961) INFO 08-13 21:49:05 [serving_responses.py:149] "auto" tool choice has been enabled please note that while the parallel_tool_calls client option is preset for compatibility reasons, it will be ignored.
(APIServer pid=4093961) INFO 08-13 21:49:05 [serving_chat.py:93] "auto" tool choice has been enabled please note that while the parallel_tool_calls client option is preset for compatibility reasons, it will be ignored.
(APIServer pid=4093961) INFO 08-13 21:49:05 [serving_chat.py:133] Using default chat sampling params from model: {'top_k': 1, 'top_p': 0.0001}
(APIServer pid=4093961) INFO 08-13 21:49:05 [serving_completion.py:77] Using default completion sampling params from model: {'top_k': 1, 'top_p': 0.0001}
(APIServer pid=4093961) INFO 08-13 21:49:05 [api_server.py:1880] Starting vLLM API server 0 on http://0.0.0.0:8000
(APIServer pid=4093961) INFO 08-13 21:49:05 [launcher.py:29] Available routes are:
(APIServer pid=4093961) INFO 08-13 21:49:05 [launcher.py:37] Route: /openapi.json, Methods: HEAD, GET
(APIServer pid=4093961) INFO 08-13 21:49:05 [launcher.py:37] Route: /docs, Methods: HEAD, GET
(APIServer pid=4093961) INFO 08-13 21:49:05 [launcher.py:37] Route: /docs/oauth2-redirect, Methods: HEAD, GET
(APIServer pid=4093961) INFO 08-13 21:49:05 [launcher.py:37] Route: /redoc, Methods: HEAD, GET
(APIServer pid=4093961) INFO 08-13 21:49:05 [launcher.py:37] Route: /health, Methods: GET
(APIServer pid=4093961) INFO 08-13 21:49:05 [launcher.py:37] Route: /load, Methods: GET
(APIServer pid=4093961) INFO 08-13 21:49:05 [launcher.py:37] Route: /ping, Methods: POST
(APIServer pid=4093961) INFO 08-13 21:49:05 [launcher.py:37] Route: /ping, Methods: GET
(APIServer pid=4093961) INFO 08-13 21:49:05 [launcher.py:37] Route: /tokenize, Methods: POST
(APIServer pid=4093961) INFO 08-13 21:49:05 [launcher.py:37] Route: /detokenize, Methods: POST
(APIServer pid=4093961) INFO 08-13 21:49:05 [launcher.py:37] Route: /v1/models, Methods: GET
(APIServer pid=4093961) INFO 08-13 21:49:05 [launcher.py:37] Route: /version, Methods: GET
(APIServer pid=4093961) INFO 08-13 21:49:05 [launcher.py:37] Route: /v1/responses, Methods: POST
(APIServer pid=4093961) INFO 08-13 21:49:05 [launcher.py:37] Route: /v1/responses/{response_id}, Methods: GET
(APIServer pid=4093961) INFO 08-13 21:49:05 [launcher.py:37] Route: /v1/responses/{response_id}/cancel, Methods: POST
(APIServer pid=4093961) INFO 08-13 21:49:05 [launcher.py:37] Route: /v1/chat/completions, Methods: POST
(APIServer pid=4093961) INFO 08-13 21:49:05 [launcher.py:37] Route: /v1/completions, Methods: POST
(APIServer pid=4093961) INFO 08-13 21:49:05 [launcher.py:37] Route: /v1/embeddings, Methods: POST
(APIServer pid=4093961) INFO 08-13 21:49:05 [launcher.py:37] Route: /pooling, Methods: POST
(APIServer pid=4093961) INFO 08-13 21:49:05 [launcher.py:37] Route: /classify, Methods: POST
(APIServer pid=4093961) INFO 08-13 21:49:05 [launcher.py:37] Route: /score, Methods: POST
(APIServer pid=4093961) INFO 08-13 21:49:05 [launcher.py:37] Route: /v1/score, Methods: POST
(APIServer pid=4093961) INFO 08-13 21:49:05 [launcher.py:37] Route: /v1/audio/transcriptions, Methods: POST
(APIServer pid=4093961) INFO 08-13 21:49:05 [launcher.py:37] Route: /v1/audio/translations, Methods: POST
(APIServer pid=4093961) INFO 08-13 21:49:05 [launcher.py:37] Route: /rerank, Methods: POST
(APIServer pid=4093961) INFO 08-13 21:49:05 [launcher.py:37] Route: /v1/rerank, Methods: POST
(APIServer pid=4093961) INFO 08-13 21:49:05 [launcher.py:37] Route: /v2/rerank, Methods: POST
(APIServer pid=4093961) INFO 08-13 21:49:05 [launcher.py:37] Route: /scale_elastic_ep, Methods: POST
(APIServer pid=4093961) INFO 08-13 21:49:05 [launcher.py:37] Route: /is_scaling_elastic_ep, Methods: POST
(APIServer pid=4093961) INFO 08-13 21:49:05 [launcher.py:37] Route: /invocations, Methods: POST
(APIServer pid=4093961) INFO 08-13 21:49:05 [launcher.py:37] Route: /metrics, Methods: GET
(APIServer pid=4093961) INFO: Started server process [4093961]
(APIServer pid=4093961) INFO: Waiting for application startup.
(APIServer pid=4093961) INFO: Application startup complete.