Kaggle赛题分析1:Elo用户忠诚度评分预测(2)-特征工程与模型训练
文章目录
- 一、特征工程
- 1.通用组合特征创建
- 1.1 通用组合特征的创建方法
- 1.2 基于transaction数据集创建通用组合特征
- 2.业务统计特征创建
- 3.数据合并
- 二、随机森林模型预测
- 1. 特征选择,皮尔逊相关系数
- 2. 借助网格搜索进行参数调优
- 三、后续优化策略
参考文章:写的比较碎,相对来讲参考文章总结的更好,更容易理解。
kaggle比赛案例:Elo Merchant Category Recommendation(1)
kaggle比赛案例:Elo Merchant Category Recommendation(2)
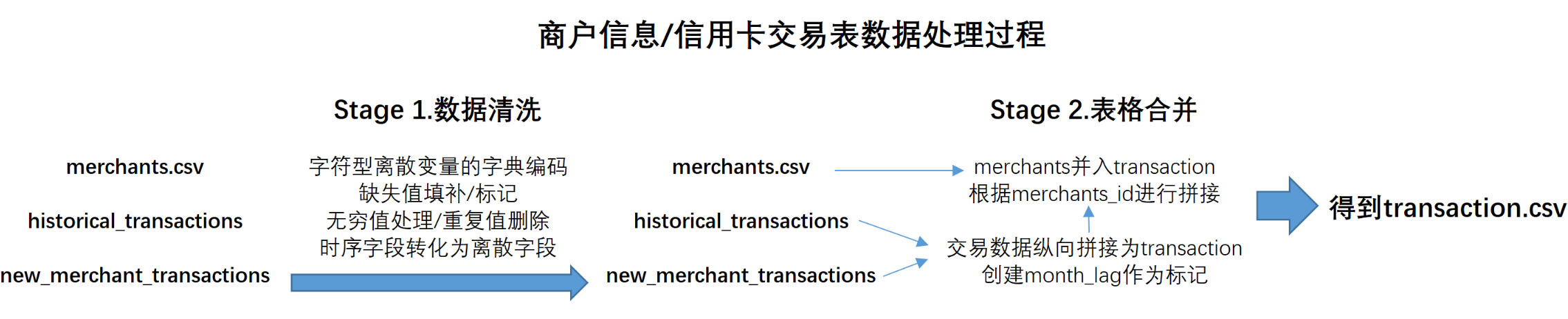
经历前面的数据解读、探索与清洗之后,将进入到特征工程与算法建模的环节,并在本小节的结尾,得出最终的预测结果。在此前的内容中,最终得到了train.csv、test.csv和transaction.csv三张表。首先,目前得到的训练集和测试集都是由原始训练集/测试集将时间字段处理后得到的,而transaction数据集则相对复杂,该数据集是由一张商户数据merchants.csv和两张交易数据表处理后合并得到,接下来,我们就依据这三张表进行后续操作。
一、特征工程
首先需要对得到的数据进一步进行特征工程处理。一般来说,对于已经清洗完的数据,特征工程部分核心需要考虑的问题就是特征创建(衍生)与特征筛选,也就是先尽可能创建/增加可能对模型结果有正面影响的特征,然后再对这些进行挑选,以保证模型运行稳定性及运行效率。当然,无论是特征衍生还是特征筛选,其实都有非常多的方法。此处为了保证思路和方法具有通用性,此处列举两种特征衍生的方法,即创建通用组合特征与业务统计特征;并在特征创建完毕后,介绍一种基础而通用的特征筛选的方法:基于皮尔逊相关系数的Filter方法进行特征筛选。这些方法都是非常通用且有效的方法,不仅能够帮助本次建模取得较好的成果,并且也能广泛适用到其他各场景中。
1.通用组合特征创建
1.1 通用组合特征的创建方法
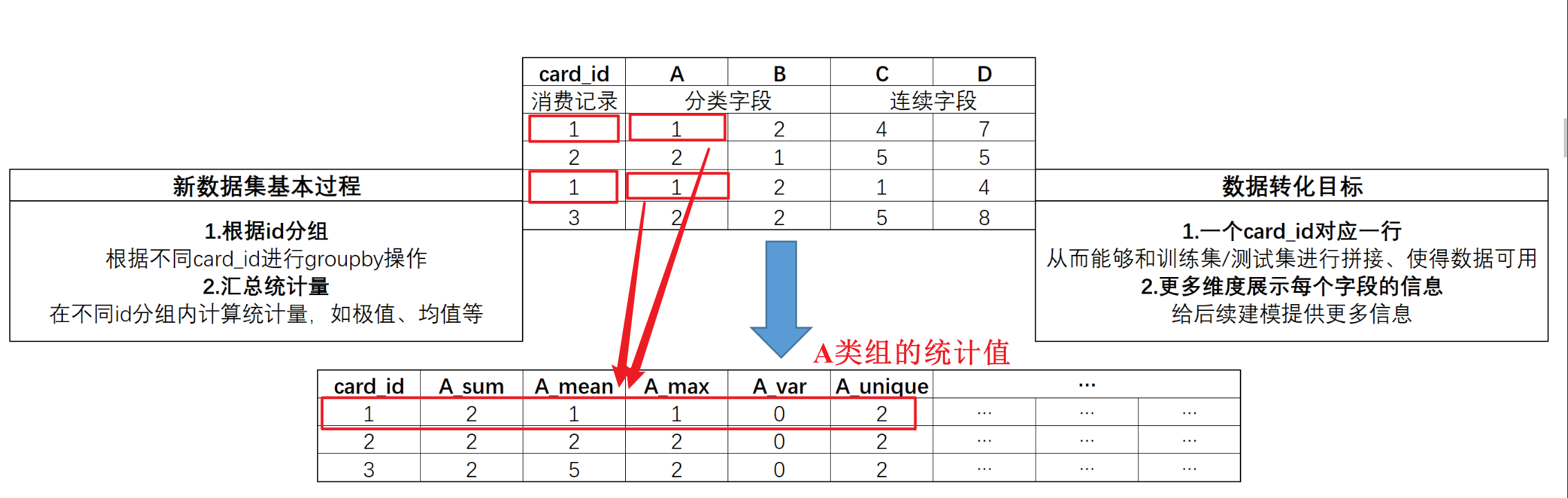
通用组合特征,指的是通过统计不同离散特征(A、B、C)在不同取值水平下(1、2、3)、不同连续特征取值之和创建的特征,并根据card_id进行分组求和。例如下图,通过该方法创建的数据集,不仅能够尽可能从更多维度表示每个card_id的消费情况,同时也能够顺利和训练集/测试集完成拼接,从而带入模型进行建模。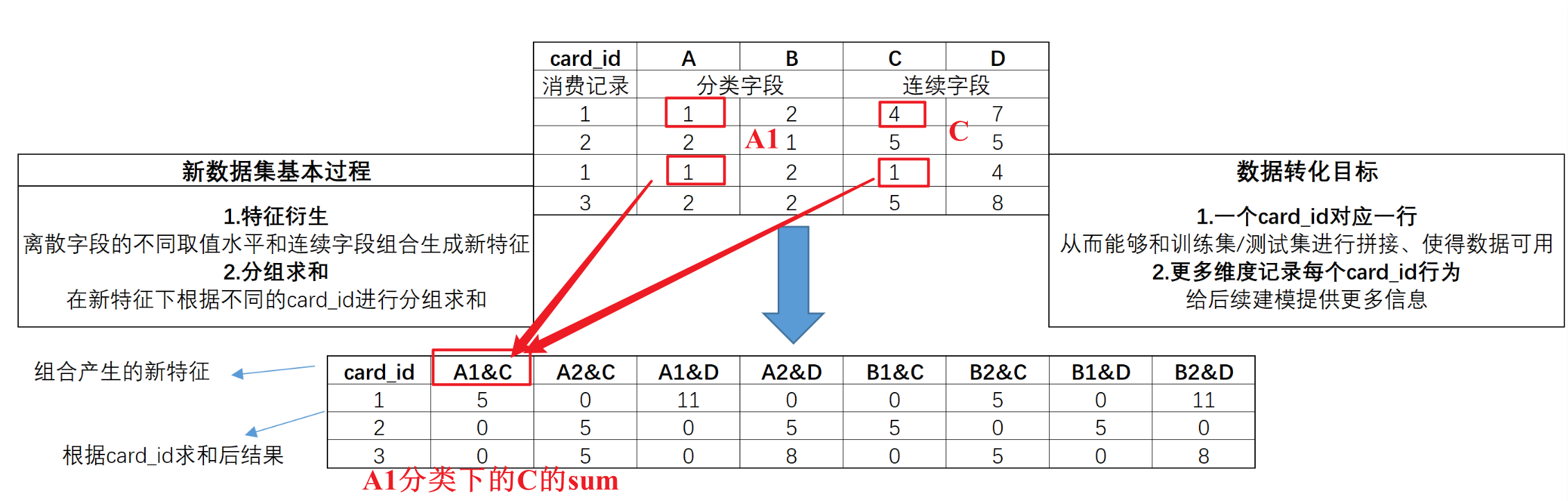
# 借助字典创建DataFrame
t1 = {'card_id':[1, 2, 1, 3], 'A':[1, 2, 1, 2], 'B':[2, 1, 2, 2], 'C':[4, 5, 1, 5], 'D':[7, 5, 4, 8],}t1 = pd.DataFrame(t1)
print(t1)# 标注特征类别
category_cols = ['A', 'B']
numeric_cols = ['C', 'D']# 创建一个以id为key、空字典为value的字典
features = {}
card_all = t1['card_id'].values.tolist()
for card in card_all:features[card] = {}
features# 所有字段名称组成的list
columns = t1.columns.tolist()
columns# 其中card_id在list当中的索引值
idx = columns.index('card_id')
idx# 离散型字段的索引值
category_cols_index = [columns.index(col) for col in category_cols]
category_cols_index
# 连续型字段的索引值
numeric_cols_index = [columns.index(col) for col in numeric_cols]
numeric_cols_index# 对离散型字段的不同取值和连续型字段两两组合
# 同时完成分组求和
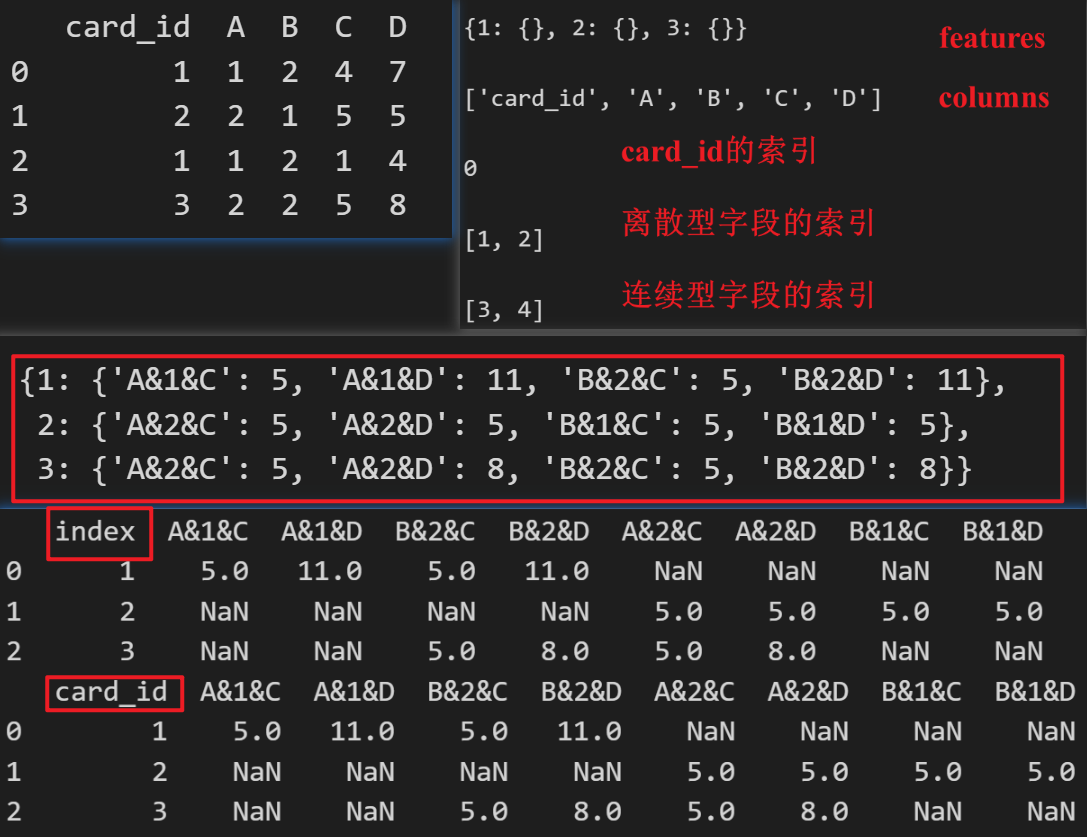
for i in range(t1.shape[0]):va = t1.loc[i].valuescard = va[idx]for cate_ind in category_cols_index:for num_ind in numeric_cols_index:col_name = '&'.join([columns[cate_ind], str(va[cate_ind]), columns[num_ind]])features[card][col_name] = features[card].get(col_name, 0) + va[num_ind]# 查看features最终结果
features
# 转化成df
df = pd.DataFrame(features).T.reset_index()
print(df)
# 将index列重命名为card_id
df = df.rename(columns={'index': 'card_id'})
print(df)
至此我们就完成了在极简数据集上进行通用组合特征的创建工作。这种特征创建的方式能够非常高效的表示更多数据集中的隐藏信息,不过该方法容易产生较多空值,在后续建模过程中需要考虑特征矩阵过于稀疏从而带来的问题。
1.2 基于transaction数据集创建通用组合特征
接下来,在transaction数据集上来完成通用组合特征的创建工作。此处需要注意的是,由于transaction数据集本身较大,尽管特征创建工作的求和部分会一定程度减少最终带入建模的数据体量,但操作transaction数据集本身就需要耗费大量的内容及一定的时间,如果要手动执行下述代码,建议至少配置32G及以上内存。
# 读取数据
train = pd.read_csv('./preprocess/train_pre.csv')
test = pd.read_csv('./preprocess/test_pre.csv')
transaction = pd.read_csv('./preprocess/transaction_d_pre.csv')# 标注离散字段or连续型字段
numeric_cols = ['purchase_amount', 'installments']category_cols = ['authorized_flag', 'city_id', 'category_1','category_3', 'merchant_category_id','month_lag','most_recent_sales_range','most_recent_purchases_range', 'category_4','purchase_month', 'purchase_hour_section', 'purchase_day']id_cols = ['card_id', 'merchant_id']
# 创建字典用于保存数据
features = {}
card_all = train['card_id'].append(test['card_id']).values.tolist()
for card in card_all:features[card] = {}# 标记不同类型字段的索引
columns = transaction.columns.tolist()
idx = columns.index('card_id')
category_cols_index = [columns.index(col) for col in category_cols]
numeric_cols_index = [columns.index(col) for col in numeric_cols]# 记录运行时间
s = time.time()
num = 0# 执行循环,并在此过程中记录时间
for i in range(transaction.shape[0]):va = transaction.loc[i].valuescard = va[idx]for cate_ind in category_cols_index:for num_ind in numeric_cols_index:col_name = '&'.join([columns[cate_ind], va[cate_ind], columns[num_ind]])features[card][col_name] = features[card].get(col_name, 0) + va[num_ind]num += 1if num%1000000==0:print(time.time()-s, "s")
del transaction
gc.collect()
在提取完特征后,接下来将带有交易数据特征的合并入训练集和测试集了:
# 字典转dataframe
df = pd.DataFrame(features).T.reset_index()
del features
cols = df.columns.tolist()
df.columns = ['card_id'] + cols[1:]# 生成训练集与测试集
train = pd.merge(train, df, how='left', on='card_id')
test = pd.merge(test, df, how='left', on='card_id')
del df
train.to_csv("preprocess/train_dict.csv", index=False)
test.to_csv("preprocess/test_dict.csv", index=False)gc.collect()
至此,我们就完成了从transaction中提取通用特征的过程。简单查看数据集基本情况:
2.业务统计特征创建
当然,除了通用组合特征外,我们还可以根据card_id来进行分组,然后统计不同字段在各组内的相关统计量,再将其作为特征,带入进行建模。其基本构造特征思路如下:
transaction = pd.read_csv('./preprocess/transaction_g_pre.csv')
# 标注离散字段or连续型字段
numeric_cols = ['authorized_flag', 'category_1', 'installments','category_3', 'month_lag','purchase_month','purchase_day','purchase_day_diff', 'purchase_month_diff','purchase_amount', 'category_2', 'purchase_month', 'purchase_hour_section', 'purchase_day','most_recent_sales_range', 'most_recent_purchases_range', 'category_4']
categorical_cols = ['city_id', 'merchant_category_id', 'merchant_id', 'state_id', 'subsector_id']
# 创建空字典
aggs = {}# 连续/离散字段统计量提取范围
for col in numeric_cols:aggs[col] = ['nunique', 'mean', 'min', 'max','var','skew', 'sum']
for col in categorical_cols:aggs[col] = ['nunique']
aggs['card_id'] = ['size', 'count']
cols = ['card_id']# 借助groupby实现统计量计算
for key in aggs.keys():cols.extend([key+'_'+stat for stat in aggs[key]])df = transaction[transaction['month_lag']<0].groupby('card_id').agg(aggs).reset_index()
df.columns = cols[:1] + [co+'_hist' for co in cols[1:]]df2 = transaction[transaction['month_lag']>=0].groupby('card_id').agg(aggs).reset_index()
df2.columns = cols[:1] + [co+'_new' for co in cols[1:]]
df = pd.merge(df, df2, how='left',on='card_id')df2 = transaction.groupby('card_id').agg(aggs).reset_index()
df2.columns = cols
df = pd.merge(df, df2, how='left',on='card_id')
del transaction
gc.collect()# 生成训练集与测试集
train = pd.merge(train, df, how='left', on='card_id')
test = pd.merge(test, df, how='left', on='card_id')
del df
train.to_csv("preprocess/train_groupby.csv", index=False)
test.to_csv("preprocess/test_groupby.csv", index=False)gc.collect()
执行完毕后,我们也可以简单查看数据集基本情况:
3.数据合并
至此,我们即完成了从两个不同角度提取特征的相关工作。不过截至目前上述两套方案的特征仍然保存在不同数据文件中,我们需要对其进行合并,才能进一步带入进行建模,合并过程较为简单,只需要将train_dict(test_dict)与train_group(test_group)根据card_id进行横向拼接、然后剔除重复列即可,实现过程如下所示:
# 1、数据读取
train_dict = pd.read_csv("preprocess/train_dict.csv")
test_dict = pd.read_csv("preprocess/test_dict.csv")
train_groupby = pd.read_csv("preprocess/train_groupby.csv")
test_groupby = pd.read_csv("preprocess/test_groupby.csv")# 2、剔除重复列
for co in train_dict.columns:if co in train_groupby.columns and co!='card_id':del train_groupby[co]
for co in test_dict.columns:if co in test_groupby.columns and co!='card_id':del test_groupby[co]
# 3、拼接特征
train = pd.merge(train_dict, train_groupby, how='left', on='card_id').fillna(0)
test = pd.merge(test_dict, test_groupby, how='left', on='card_id').fillna(0)# 4、数据保存与内存管理
train.to_csv("preprocess/train_all.csv", index=False)
test.to_csv("preprocess/test_all.csv", index=False)del train_dict, test_dict, train_groupby, test_groupby
gc.collect()
上述操作对缺失值进行了0的填补,此处缺失值并非真正的缺失值,该缺失值只是在特征创建过程没有统计结果的值,这些值从逻辑上来讲其实也都是0。因此此处缺失值填补相当于是数据补全。
二、随机森林模型预测
在准备好了基础特征之后,终于迎来了算法建模环节。此处重点介绍关于集成算法中的随机森林模型的建模及优化流程,并最终展示建模结果。
train = pd.read_csv("preprocess/train_all.csv")
test = pd.read_csv("preprocess/test_all.csv")
1. 特征选择,皮尔逊相关系数
由于此前创建了数千条特征,若带入全部特征进行建模,势必极大程度延长模型建模时间,并且带入太多无关特征对模型结果提升有限,因此此处我们借助皮尔逊相关系数,挑选和标签最相关的300个特征进行建模。当然此处300也可以自行调整。
# 提取特征名称
features = train.columns.tolist()
features.remove("card_id")
features.remove("target")
featureSelect = features[:]# 计算相关系数
corr = []
for fea in featureSelect:corr.append(abs(train[[fea, 'target']].fillna(0).corr().values[0][1]))# 取top300的特征进行建模,具体数量可选
se = pd.Series(corr, index=featureSelect).sort_values(ascending=False)
feature_select = ['card_id'] + se[:300].index.tolist()# 输出结果
train = train[feature_select + ['target']]
test = test[feature_select]
注意,此处可以通过皮尔逊相关系数进行特征提取的主要原因也是在于我们在特征创建的过程中,将所有特征都默认为连续性变量
2. 借助网格搜索进行参数调优
接下来,我们将借助sklearn中基础调参工具—网格搜索(Gridsearch)进行参数搜索与调优。
# 导包,均方误差计算函数、随机森林评估器和网格搜索评估器:
from sklearn.metrics import mean_squared_error
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import GridSearchCV
然后根据网格搜索的要求,我们需要根据随机森林的参数情况,有针对性的创造一个参数空间,随机森林基本参数基本情况如下:

其中我们挑选"n_estimators"、“min_samples_leaf”、 “min_samples_split”、 “max_depth” 和 “max_features” 进行参数搜索:
然后是关于网格搜索工具的选择。随着sklearn不断完善,有越来越多的网格搜索工具可供选择,但整体来看其实就是在效率和精度之间做权衡,有些网格搜索工具由于是全域枚举(如GridSearchCV),所以执行效率较慢、但结果精度有保障,而如果愿意牺牲精度换执行效率,则也有很多工具可以选择,如RandomizedSearchCV。当然,在最新的sklearn版本中,还出现了一种更高效的搜索策略——HalvingGridSearchCV,该方法先两两比对、然后逐层筛选的方法来进行参数筛选,并且同时支持HalvingGridSearchCV和HalvingRandomSearchCV。注意,这是sklearn最新版、也就是0.24版才支持的功能,该功能的出现也是0.24版最大的改动之一,而该功能的加入,也将进一步减少网格搜索所需计算资源、加快网格搜索的速度。
围绕本次竞赛的数据,在实际执行网格搜索的过程中,建议先使用RandomizedSearchCV确定大概范围,然后再使用GridSearchCV高精度搜索具体参数取值。当然,如果是使用最新版的sklearn,也可以考虑使用Halving方法进行搜索此处我们在大致确定最优参数范围的前提下设置在一个相对较小的参数空间内来进行搜索:
features = train.columns.tolist()
features.remove("card_id")
features.remove("target")# 构建参数空间
parameter_space = {"n_estimators": [79, 80, 81], "min_samples_leaf": [29, 30, 31],"min_samples_split": [2, 3],"max_depth": [9, 10],"max_features": ["auto", 80]
}# 构建随机森林评估器,并输入其他超参数取值
clf = RandomForestRegressor(criterion="mse",n_jobs=15,random_state=22)# 开始进行网格搜索
grid = GridSearchCV(clf, parameter_space, cv=2, scoring="neg_mean_squared_error")
grid.fit(train[features].values, train['target'].values)# 查看训练结果
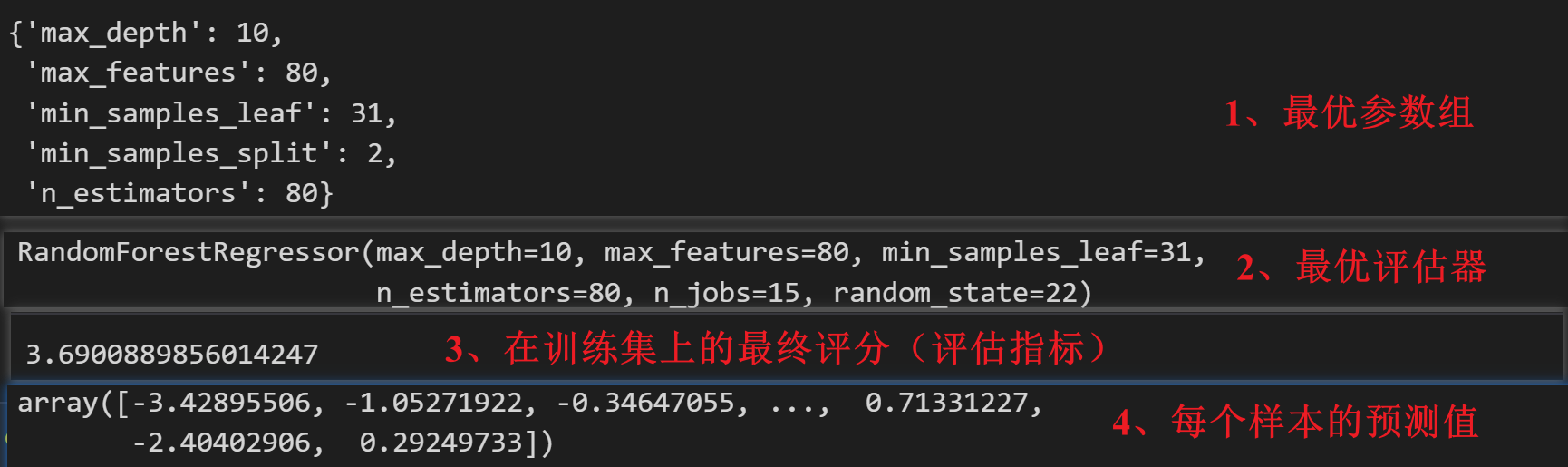
# 最优参数组
grid.best_params_
# 最优评估器
grid.best_estimator_# 在训练集上的最终评分
np.sqrt(-grid.best_score_)# 对每个样本的预测值
grid.best_estimator_.predict(test[features])# 提交结果
test['target'] = grid.best_estimator_.predict(test[features])
test[['card_id', 'target']].to_csv("result/submission_randomforest.csv", index=False)
三、后续优化策略
当然,围绕上述结果还有许多可以优化的地方,在公开课的最后,我们也将提供一些后续优化建议:
- 文本特征挖掘
在特征处理的过程中,可以尝试使用NLP领域的TF-IDF进行词频统计,增加离散变量特征; - 更多衍生特征
除了对离散变量进行词频统计外,我们还可以考虑构建更多特征,如全局card_id特征、最近两个月 card_id特征、二阶特征和补充特征等,来更深程度挖掘数据集信息; - 更多集成算法
除了随机森林外,还有许多功能非常强大的集成模型,包括LightGBM、XGBoost等,都是可以尝试使用的算法; - 模型融合方法
既然使用了多集成模型来进行建模,那么模型融合也势在必行。模型融合能够很好的综合各集成模型的输出结果,来做出最后更加综合的判断。当然模型融合可以考虑简单加权融合或者stacking融合方法; - 更加细致的数据处理
除了技术手段外,我们可也可以围绕此前得出的业务分析结论,对数据集进行更加细致的处理,如此前标签中出现的异常值的处理、13家商户没有过去一段时间营销信息等,通过更加细致的处理,能够让模型达到更好的效果。