数据结构初阶(13)排序算法-选择排序(选择排序、堆排序)(动图演示)
2.2 选择排序
2.2.1基本思想
基本思想
- 每一次从待排序的数据元素中选出最小(或最大)的一个元素。
- 将最值存放在序列的起始位置(结束位置)。
- 循环执行,直到全部待排序的数据元素排完 。
比 + 选 (+ 放)
2.2.2 直接选择排序
直接选择排序是一种简单直观的原地比较排序算法,无论数据是否有序,其时间复杂度均为 O(n²)——暴力选择排序。
因此仅适用于小规模数据排序。它的主要优点是不占用额外内存空间(空间复杂度 O(1)),但由于其低效的时间复杂度,不适合大规模数据排序。
基本逻辑
基本逻辑
- 在元素集合 array[i] ~ array[n-1](a[0] ~ a[n-i])中选择关键码最大(小)的数据元素
- 若它不是这组元素中的最后一个(第一个)元素,则将它与这组元素中的最后一个(第一个)元素交换
- 在剩余的array[i] ~ array[n-2](array[i+1]--array[n-1])集合中,重复上述步骤,直到集合剩余1个元素
可以将每趟循环选出的当前最大(小)值,依次放在数组的起始位置(从左向右放)。
(直接选择排序)
可以将每趟循环选出的当前最大(小)值,依次放在数组的结束位置(从右向左放)。
(堆排序)
动图演示
算法步骤
- 初始状态:最开始待排序序列为 arr[0] ~ a[n-1] ,已排序序列为空。
- 查找最小值:在待排序序列中找出最小值。
- 交互位置:将最小值与待排序的第一个元素交换。
- 重复执行:重复二三步,直到整个序列有序 (共需要n-1轮)。
(这是一种暴力选择)
和直接插入排序一样,直接选择排序也可以类比打扑克牌:
直接插入排序:一次摸一张牌,加入手牌(已排好序)。
直接选择排序:一次摸完全部牌,再选出3放到最左边、4放到次左边、5……,依次码好牌。
优化方式
- 一次选一个最值 ——> 一次选两个最值。
代码实现
1. 先考虑单趟
- 选出未排序部分的最大值、最小值——不能只保存值,需要保存下标。
(是交换,不是是覆盖)- 分别放到数组的开头、结尾。
- 最小值可以直接放到begin,最大值要判别一下再放到end。
(判别:最大值占了begin、最小值占了end)2. 再考虑整体
- 调整未排序部分的区间:左、右向中间收缩一,直到begin、end相遇。
//直接选择排序
void SelectSort(int* a, int n)
{//一次遍历选出:最小放左,最大放右,左右向中收缩一,直到begin、end相遇int begin = 0, end = n - 1;while (begin < end){// 找出最小值和最大值的下标(初始都设为begin)int mini = begin, maxi = begin;for (size_t i = begin + 1; i <= end; i++){//如果有比最小更小——可以做到稳定——就需要选小时往后遍历相等不更新if (a[i] < a[mini]){//就更新最小值下标mini = i;}//如果有比最大更大——可以做到稳定——就需要选大时往后遍历相等要更新if (a[i] >= a[maxi]){//就更新最大值下标maxi = i;}}//交换最左和最小——这一步就直接导致选择排序无法做到稳定Swap(&a[begin], &a[mini]);//如果最大值下标==最左值下标,那么交换最左和最小后——最大值下标处就不是最大值了if (maxi == begin){//最大值占了begin,在mini的交换中被换到了mini这个位置,需要更新maxi的位置//反馈修正最大值下标maxi = mini;}//交换最右和最大Swap(&a[end], &a[maxi]);//向中收缩++begin;--end;//PrintArray(a, n);}
}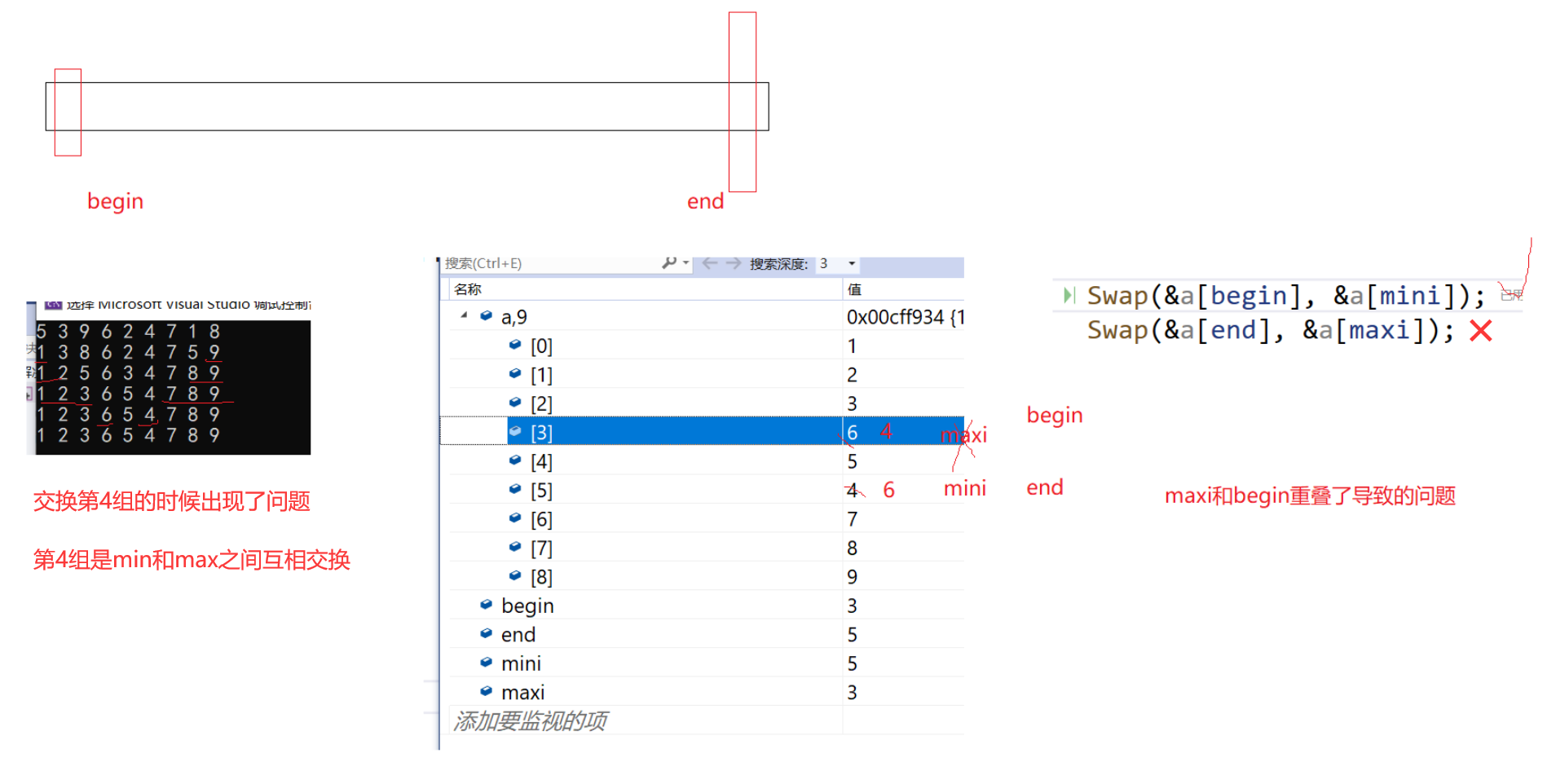
第一步换没问题,但是第一步换完,maxi不在原位了。
第二步换出现了问题。
性能分析
不论有序无序都要遍历未排序部分进行选择,时间复杂度与数据是否有序无关。
最好最坏都是O(N^2)。
时间复杂度:
- 无论数据是否有序,均需两层循环比较O(n²)
空间复杂度:
- 仅需常数级额外空间 O(1)
稳定性:
- 不稳定 (交换时可能改变相同元素的相对元素)
遍历一次选一个数据,则每次遍历需要执行:N次、N-1、……、2。O(N^2)(等差数列)
遍历一次选两个数据,则每次遍历需要执行:N次、N-2、……、2。O(N^2)(等差数列)
性能比较
x.1 选择排序 VS 冒泡排序
感觉上差不多,细节上有差异:
- 冒泡每次遍历内部也有部分交换,最终把最值交换到最后。
- 选择只在选完之后,交换一次,把最值放到最后。
- 故冒泡属于交换排序,选择属于选择排序。
x.2 O(N^2)的算法
void TestOP()
{srand(time(0));//要产生随机需要一个种子,否则随机是写死的伪随机const int N = 100000;int* a1 = (int*)malloc(sizeof(int) * N); //创建7个随机数组,每个数组10万元素int* a2 = (int*)malloc(sizeof(int) * N);int* a3 = (int*)malloc(sizeof(int) * N);int* a4 = (int*)malloc(sizeof(int) * N);int* a5 = (int*)malloc(sizeof(int) * N);int* a6 = (int*)malloc(sizeof(int) * N);int* a7 = (int*)malloc(sizeof(int) * N);for (int i = 0; i < N; ++i){a1[i] = rand();a2[i] = a1[i]; //随机生成10万个数据a3[i] = a1[i];a4[i] = a1[i];a5[i] = a1[i];a6[i] = a1[i];a7[i] = a1[i];}int begin1 = clock(); //系统启动到执行到此的毫秒数InsertSort(a1, N);int end1 = clock(); //系统启动到执行到此的毫秒数int begin7 = clock();BubbleSort(a7, N);int end7 = clock();int begin3 = clock();SelectSort(a3, N);int end3 = clock();int begin2 = clock();//ShellSort(a2, N);int end2 = clock();int begin4 = clock();//HeapSort(a4, N);int end4 = clock();//int begin5 = clock();//QuickSortNonR(a5, 0, N - 1);//int end5 = clock();//int begin6 = clock();//MergeSortNonR(a6, N);//int end6 = clock();printf("InsertSort:%d\n", end1 - begin1);printf("BubbleSort:%d\n", end7 - begin7);//printf("ShellSort:%d\n", end2 - begin2);printf("SelectSort:%d\n", end3 - begin3);//printf("HeapSort:%d\n", end4 - begin4);//printf("QuickSort:%d\n", end5 - begin5);//printf("MergeSort:%d\n", end6 - begin6);free(a1);free(a2);free(a3);free(a4);free(a5);free(a6);free(a7);
}int main()
{//TestInsertSort();//TestBubbleSort();//TestShellSort();//TestSelectSort();//TestQuickSort();//TestMergeSort();//TestCountSort();TestOP();//MergeSortFile("sort.txt");return 0;
}测试结果
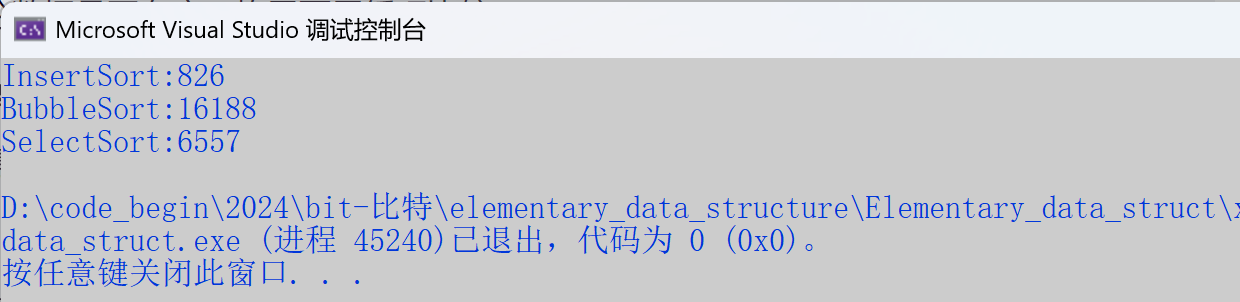
结论
常见的O(N²)排序算法包括:
冒泡排序(Bubble Sort)
选择排序(Selection Sort)
插入排序(Insertion Sort)
算法说明
1. 选择排序:
- 思想:每次从未排序部分选择最小(或最大)元素,放到已排序部分的末尾。
- 比较次数:固定为N(N-1)/2。
- 交换次数:最多N-1次(每次选择后交换一次),比冒泡排序少很多。
- 因此,选择排序的交换次数远少于冒泡排序,通常更高效。
2. 插入排序:
思想:将未排序部分的元素插入到已排序部分的适当位置。
比较次数:最好情况O(N)(已排序),最坏和平均O(N²)。
交换次数:最好情况0,最坏O(N²)。
对于部分有序的数组,插入排序非常高效;完全逆序时与冒泡排序类似。
效率比较——比较和交换次数:
冒泡排序:比较和交换次数都较高(尤其是交换)。
选择排序:比较次数相同,但交换次数少。
插入排序:比较和交换次数与初始顺序有关,部分有序时优于冒泡。
性能总结
- “分析+实验”表明,选择排序和插入排序通常比冒泡排序更快。
- 在O(N²)的排序算法中,冒泡排序确实是效率最低。
x.3 为什么要学这些算法
快速排序:效率高,实践意义最大,很多有关排序的地方的底层算法都是快排。
那为什么不直接学习最好的快速排序qsort???
学习各种排序都有自己的价值——每种算法都有自己的应用场景
插入排序:对于接近有序的数据能达到线性时间复杂度,比堆排序更实用(处理随机数据当然堆排序好用)
冒泡排序、简单选择排序:在实践当中,严格来说,都只有教学意义——价值在于好理解,便于教学初学者,能让初学者迅速掌握一种简单有效的排序算法,并应用于日常。
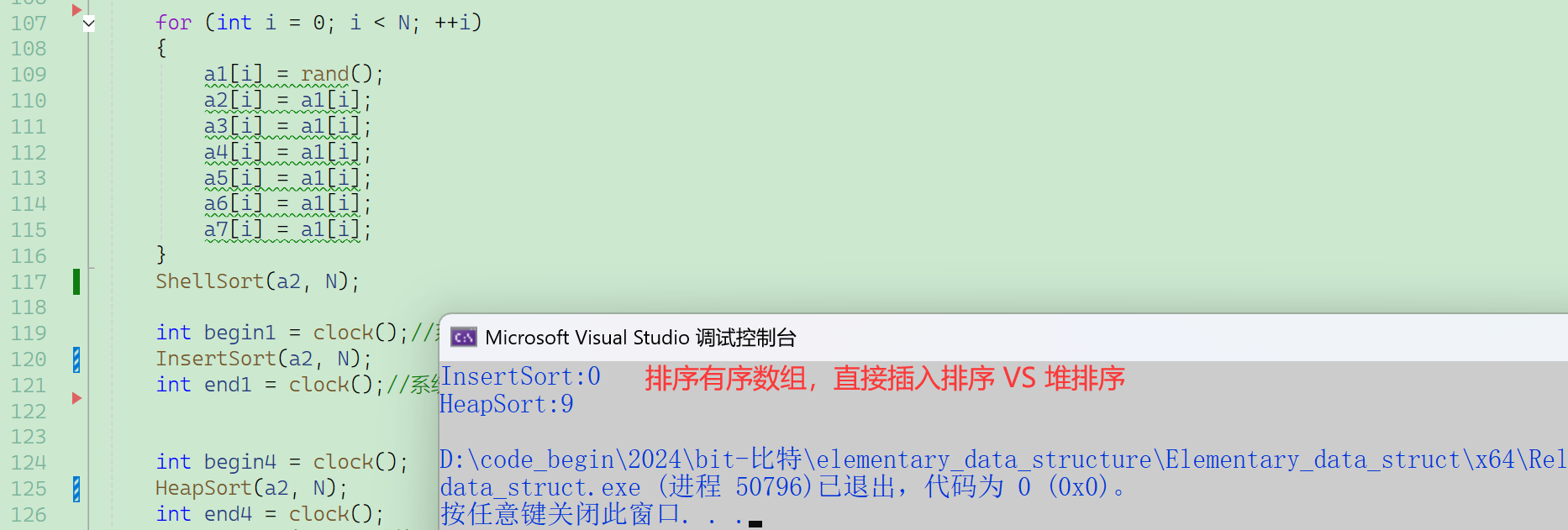
特性总结
直接选择排序的特性总结:
1. 直接选择排序思考非常好理解,但是效率不是很好。实际中很少使用
2. 时间复杂度:O(N^2)
3. 空间复杂度:O(1)
4. 稳定性:不稳定
2.2.3 堆排序
堆排序(Heapsort)是指利用堆积树(堆)这种数据结构所设计的一种排序算法.
它是选择排序的一种。
堆排序是一种基于二叉堆(Binary Heap)数据结构的比较排序算法,属于选择排序的优化版本。
它通过构建最大堆(或最小堆)实现升序(或降序)排序,具有 O(n * logn) 的时间复杂度。
且是原地排序(空间复杂度 O(1))。
基本逻辑
基本逻辑
它是通过堆(二叉树)的性质,来进行选择数据。
(简单选择排序是暴力选择)
需要注意的是:排升序-建大堆,排降序-建小堆。
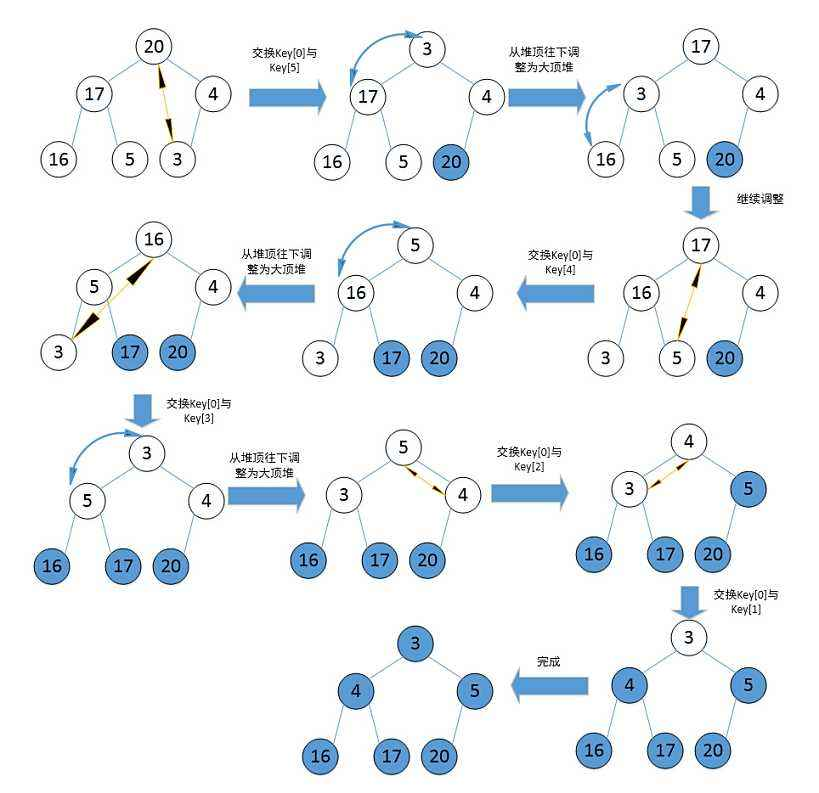
动图演示

图中建堆使用的是:每次插入一个数据,使用向上调整建堆。——O(N*logN)
实践中使用的方式:一次性插入所有数据,使用向下调整建堆。——O(N)
算法步骤
首先我们给定一个无序的序列。
- 构建一个堆
- 把堆首(最大/小值)和堆尾互换
- 删除堆首(把堆的尺寸缩小1),并重新构建堆——>只是在调整新堆首到正确的位置,堆的其他位置的数据的位置都相对比较正确。
- 重复步骤2、3,知道堆的尺寸为1。
代码实现
void AdjustDown(int* a, int n, int parent)
{int child = parent * 2 + 1;while (child < n){// 假设法,选出左右孩子中小的那个孩子if (child + 1 < n && a[child + 1] < a[child]){++child;}if (a[child] < a[parent]){Swap(&a[child], &a[parent]);parent = child;child = parent * 2 + 1;}else{break;}}
}// 堆排序
void HeapSort(int* a, int n)
{// a数组直接建堆——O(N)for (int i = (n - 1 - 1) / 2; i >= 0; --i){AdjustDown(a, n, i);}// O(N*logN)int end = n - 1;while (end > 0) //O(N){Swap(&a[0], &a[end]);AdjustDown(a, end, 0); //O(logN)--end;}
}性能分析
时间复杂度:
- 建堆O(n)+每次调整堆O(log n) 共O(n log n)
空间复杂度:
- 原地排序,无需额外空间 O(1)
稳定性:
- 不稳定
特性总结
堆排序的特性总结:
1. 堆排序使用堆来选数,效率就高了很多。
2. 时间复杂度:O(N*logN)
3. 空间复杂度:O(1)
4. 稳定性:不稳定