读From GPT-2 to gpt-oss: Analyzing the Architectural Advances
序
本篇由来,在COC上我当面感谢了组委会和姜宁老师,随即被姜宁老师催稿,本来当天晚上写了一个流水账,感觉甚为不妥。于是决定慢慢写,缓缓道来。要同时兼顾Show me the code,Show me the vide。希望能形成一个从不同侧面观测我自己Community Over Code 2025参会心的,收获的内容集合。
感觉这个系列正慢慢变成一场开发过程的图文慢直播,肯能有助于大家一步一步的从零开始构建自己的Agent。
我定了一个番茄钟,每天写稿大概1~2个钟,写到哪儿算哪儿。
今天也对内容进行了调整把前略改成附录了,颇有一种写论文的感觉。
BTW,知乎我一般隔一天发。插曲可以TL;DR。
词汇表
异人智能,我从KK和建忠老师的直播,个人笔记,了解到的词汇,我很喜欢。大家请自行替换为大模型,Agent就好了。
昨天我们前置了内容,今天我们在DeepSeek的辅助下读From GPT-2 to gpt-oss: Analyzing the Architectural Advances这篇稿子
原文
效果如图:
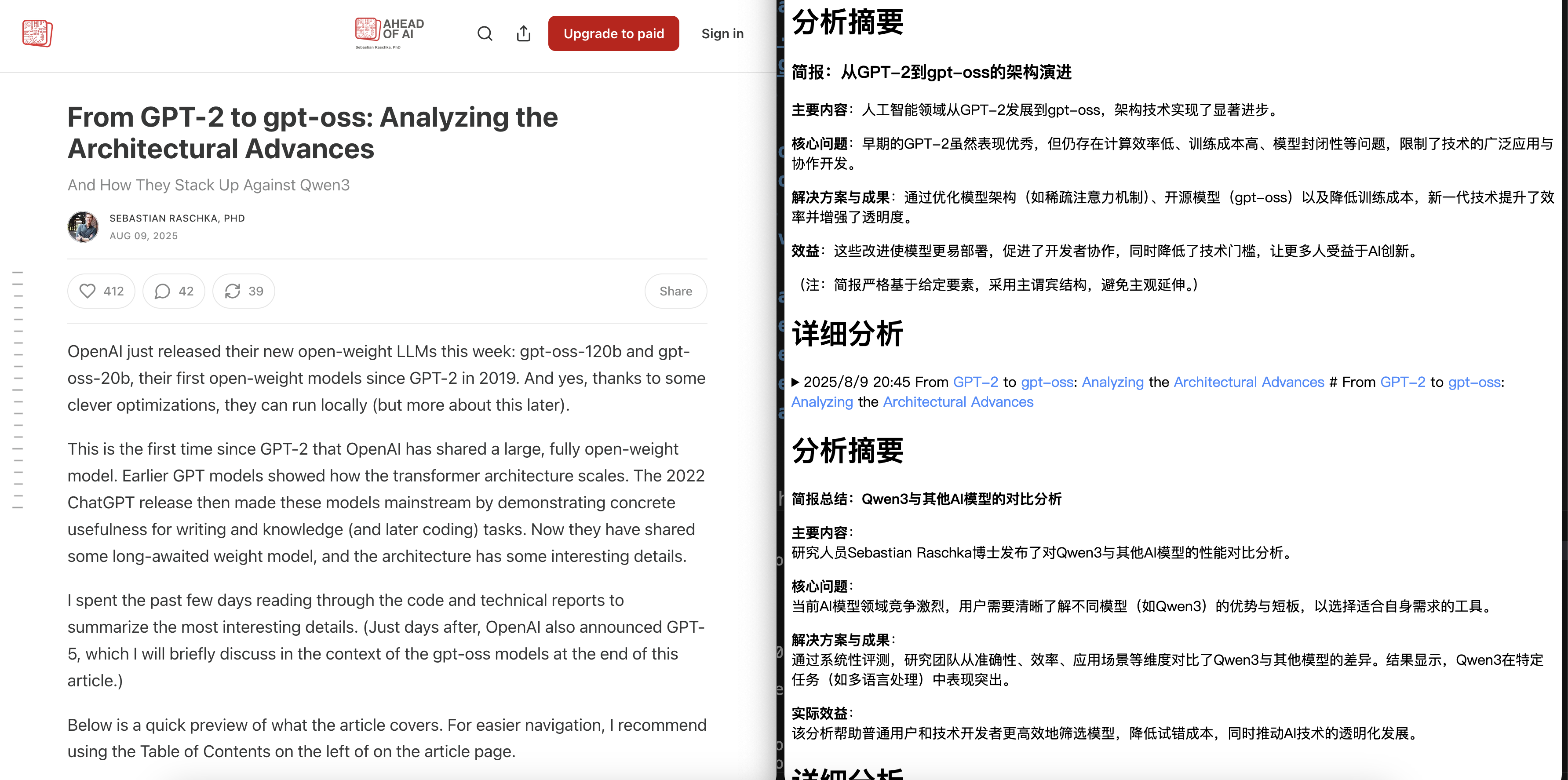
OpenAI本周发布了新的开源大语言模型(LLM)——gpt-oss-120b和gpt-oss-20b。这是自2019年GPT-2以来,OpenAI首次公开完全开源的权重模型。
OpenAI通过智能优化技术,使新模型能在本地设备上运行,降低了使用门槛。同时,新模型延续了Transformer架构的扩展性,并进一步提升了实用性。
- 模型规模与效率:GPT-OSS模型需要优化以适应单块GPU运行,而传统方法(如FP16)可能无法满足需求。MXFP4优化:采用4位混合精度浮点(MXFP4)压缩技术,显著降低模型显存占用,使其能在单块GPU上高效运行。
- 技术迭代:OpenAI快速推出GPT-5,使得社区开源模型(如GPT-OSS)需持续更新以保持竞争力。
架构对比:通过分析GPT-OSS与GPT-2的差异(如层数、注意力机制),帮助开发者理解性能提升的关键。
研究人员对比了两种AI模型(GPT-OSS与Qwen3),分析其在“宽度(参数量)与深度(层数)”设计上的差异,并测试了注意力机制中的偏差问题与“信息沉没”现象。此外,还提供了与GPT-5的性能基准比较结果。
核心问题
- 模型设计矛盾:增加宽度(并行计算能力)可能牺牲深度(复杂推理能力),反之亦然,影响模型效率与效果。
- 注意力偏差:某些模型在处理长序列时,注意力机制可能过度聚焦局部信息(偏差)或丢失关键数据(沉没),降低准确性。
解决方案与成果
主流LLM开发者普遍采用相同的底层架构(如Transformer),创新有限。目前尚未找到优于Transformer的替代方案,尽管存在状态空间模型和文本扩散模型等尝试。Transformer仍是主流,因其性能稳定且经过验证。
- 权衡优化:通过调整参数分配策略,部分模型(如Qwen3)在保持深度的同时扩展宽度,提升了多任务处理能力。
- 注意力改进:引入“信息沉没缓冲”技术,减少数据丢失,使长文本分析更稳定。
- 20B模型可运行于16GB显存的消费级GPU,120B模型支持单张H100(80GB显存),降低了使用门槛。
基于GTP-2
GPT-2作为早期模型,其性能和能力可能已无法满足当前需求,需要了解其局限性以推动技术迭代。
通过对比GPT-2与现代架构的差异,分析技术演进的关键改进。
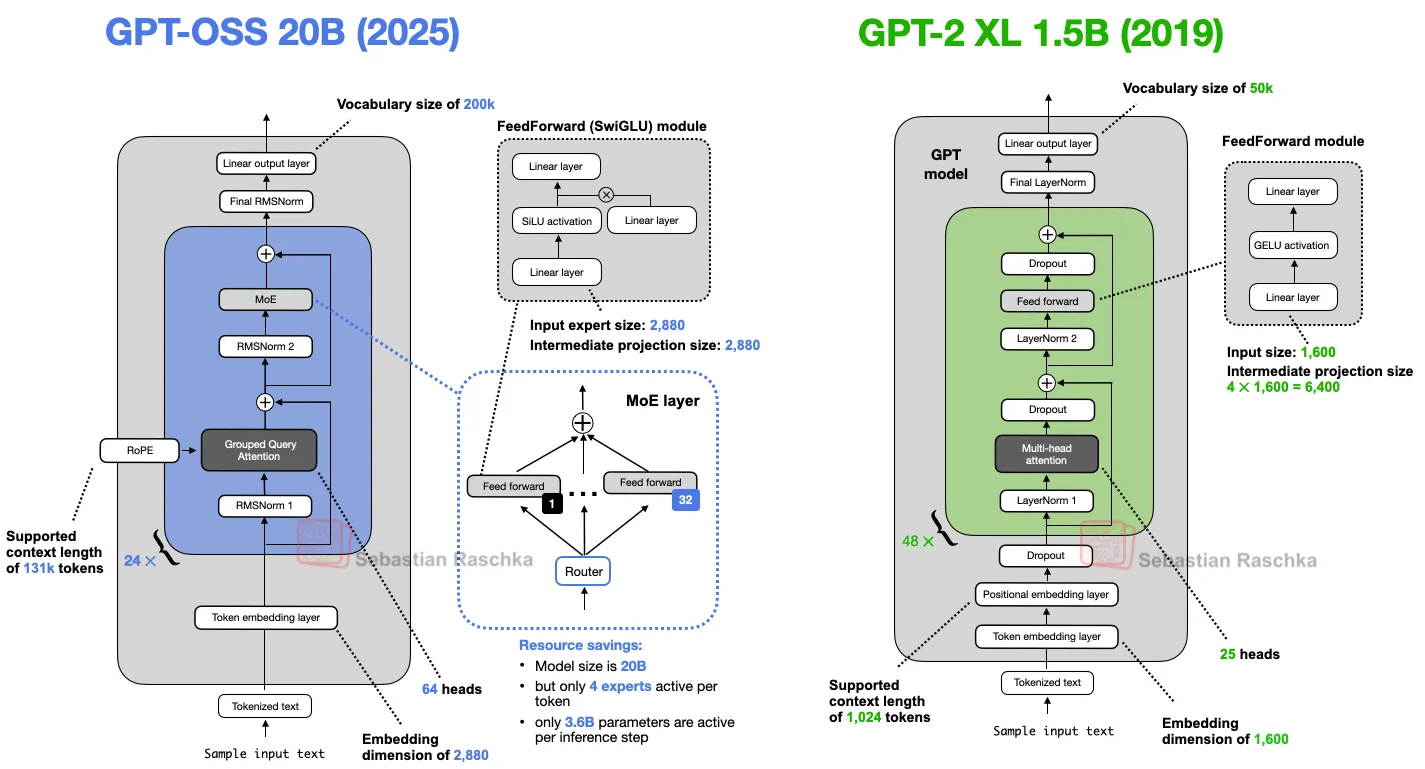
GPT-oss和GPT-2是基于2017年《Attention Is All You Need》论文提出的Transformer架构的解码器专用大语言模型(LLM)。多年来,这类模型的技术细节不断演进,但这些改进并非GPT-oss独有,也出现在其他LLM中。
通过借鉴Transformer的通用优化路径(如注意力机制、模型结构调整),GPT-oss与其他LLM共享技术红利。这种协同演进提升了模型效率、训练速度和生成能力。
Dropout技术演变
早期的人工智能模型(如GPT-2之前)普遍使用Dropout技术,通过在训练中随机屏蔽部分神经元或注意力分数来防止过拟合(图3)。但近年来,大多数大型语言模型(如GPT-2之后的版本)已移除了这一技术。
Dropout虽能减少过拟合,但可能降低模型效率。现代大语言模型参数量庞大、训练数据充足,过拟合风险较低,而Dropout的随机性反而可能干扰模型学习稳定性和表现。
研究者通过实验发现,直接移除Dropout后,模型在以下方面表现更优:
- 结果:训练过程更稳定,收敛速度更快;
- 优势:节省计算资源,提升生成内容的连贯性。
Dropout的淘汰反映了AI技术的迭代——当模型和数据足够强大时,简化设计反而能提升性能。这一调整帮助现代大语言模型更高效地学习和输出高质量结果。
Dropout被用于注意力分数矩阵,以提升模型的泛化能力。在训练大型语言模型时,注意力机制可能过度依赖某些特定的注意力模式,导致模型过拟合或泛化能力下降。通过在注意力分数矩阵中引入Dropout,随机屏蔽部分注意力权重,强制模型学习更鲁棒的特征表示。这一方法减少了模型对特定注意力模式的依赖,提升了泛化性能。
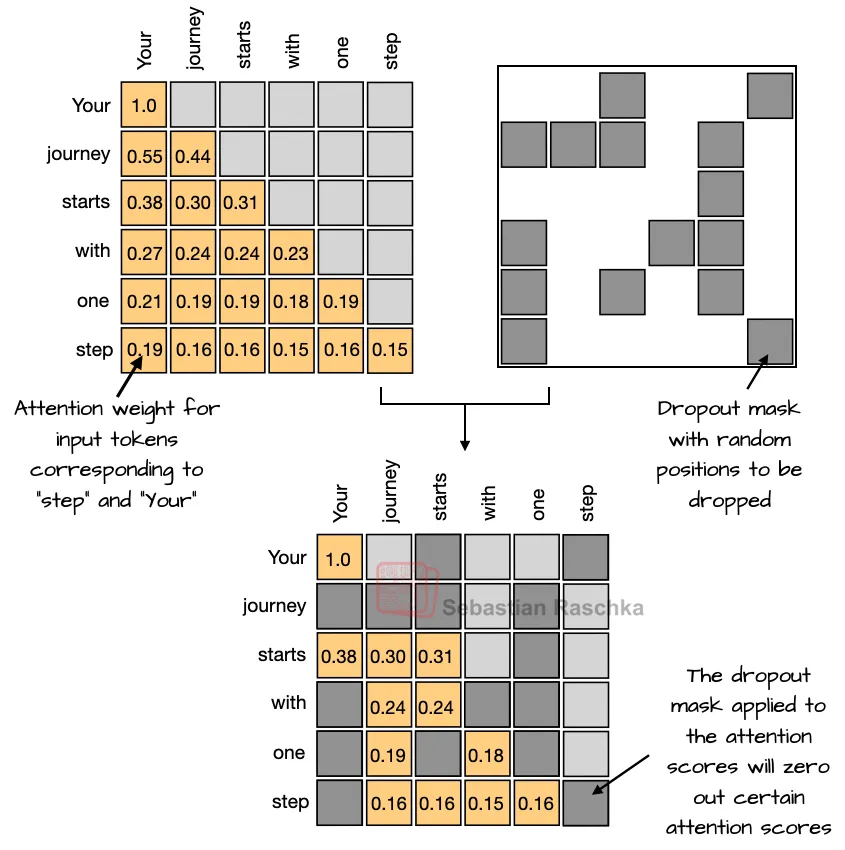
Dropout的益处
降低过拟合风险:模型不再过度依赖训练数据中的局部模式。
增强鲁棒性:模型能更好地适应未见过的数据。
提高训练稳定性:Dropout的随机性有助于避免训练过程中的局部最优问题。
Dropout因与LLM训练机制不匹配而失效,去除后反而提升了效率与性能。这一发现推动了LLM架构设计的优化。
研究发现,Dropout技术(一种防止过拟合的正则化方法)在GPT-2等大型语言模型(LLM)中效果有限。它最初继承自传统Transformer架构,但在LLM训练中并未显著提升性能。
Dropout最初是为多轮次(数百次)训练的小规模数据集设计的,而LLM通常在超大规模数据上仅训练一个周期(单轮)。由于每个数据点只学习一次,过拟合风险极低,Dropout的防过拟合作用变得冗余。2025年一项针对Pythia 1.4模型的小规模实验也证实,单周期训练下,Dropout反而会降低模型表现。
研究人员逐步放弃在LLM中使用Dropout。实验表明,移除Dropout后:
- 结果:模型下游任务性能更优;
- 益处:简化了训练流程,节省计算资源,同时保持模型泛化能力。
位置编码技术取代绝对位置嵌入
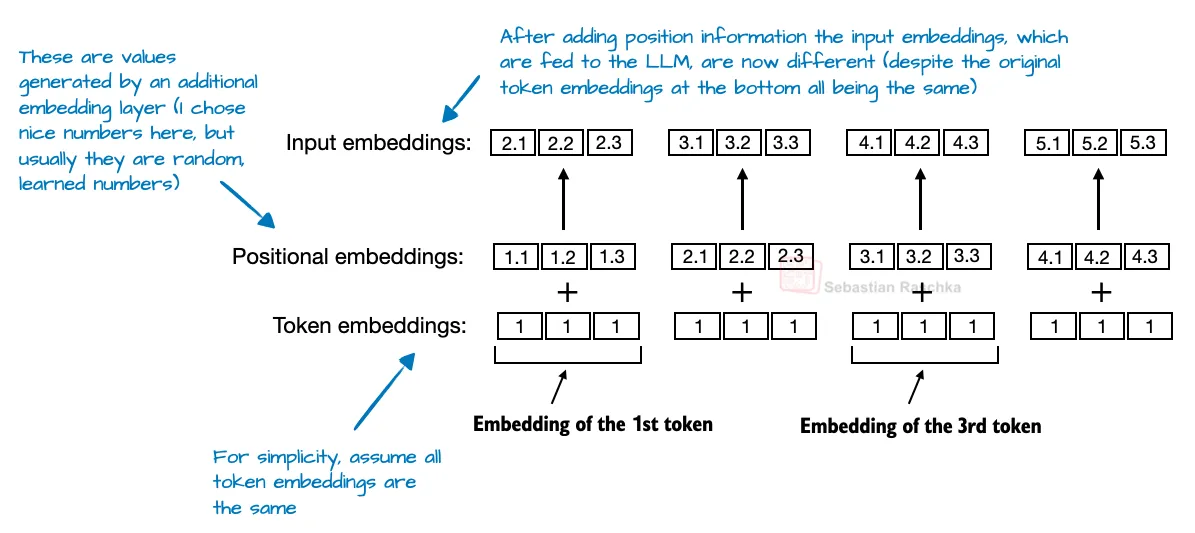
在基于Transformer架构的大语言模型(如GPT)中,注意力机制默认无法识别输入标记的顺序,因此需要引入位置编码技术。最初的GPT模型采用绝对位置嵌入(Absolute Positional Embeddings),通过为序列中的每个位置添加一个可学习的嵌入向量来解决这一问题(如图4所示)。绝对位置嵌入存在局限性,例如可能无法灵活处理变长序列或难以捕捉相对位置关系。RoPE(Rotary Position Embedding)取代了绝对位置嵌入。RoPE通过旋转机制动态编码位置信息,不仅能更高效地建模相对位置关系,还提升了模型对长序列的适应性。
2021年提出的旋转位置嵌入(RoPE)改用旋转操作调整查询和键向量的方向,旋转角度与词语位置相关。这一方法被2023年发布的Llama模型采用,并成为现代大语言模型的标准技术。
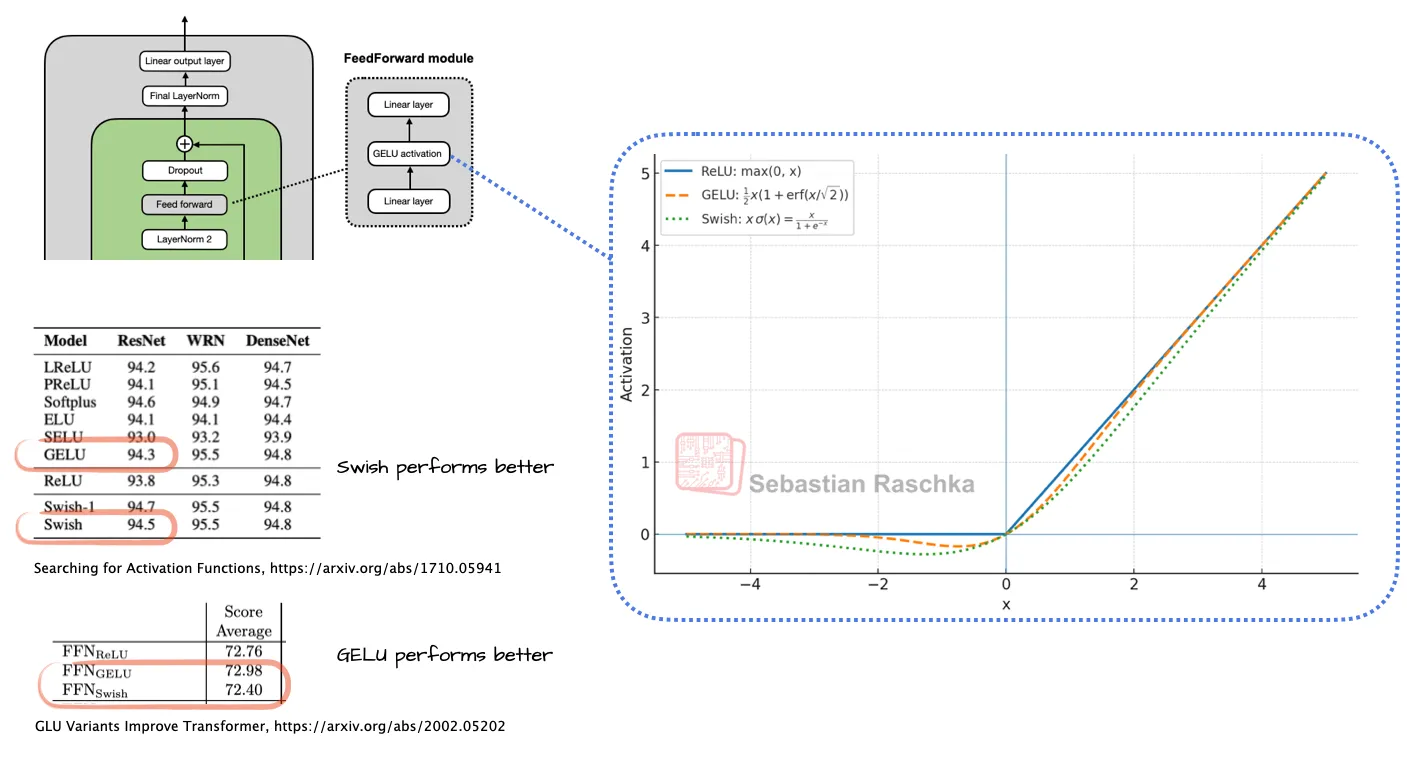
Swish/SwiGLU 替代 GELU 的原因与优势
研究表明,Swish 的计算成本略低于 GELU,这可能是替换的主要原因。Swish 在保持性能的同时,提高了计算效率,使模型运行更高效。过去,深度学习领域对激活函数的选择存在争议,但十多年前ReLU成为主流。近年来,研究者提出了更平滑的变体,如GELU和Swish(见图5),并逐渐被广泛采用。早期的激活函数(如ReLU)虽有效,但存在局限性,例如不够平滑或梯度消失问题,可能影响模型性能。这些改进的激活函数(如GELU和Swish)提供了更稳定的训练过程,可能在某些任务中略微提升模型表现,同时减少了梯度相关问题,使深度学习模型更可靠。
Swish和GELU通过平滑曲线替代ReLU的硬截断:
- Swish:结合Sigmoid的平滑性与ReLU的稀疏激活特性,提升梯度传播效率。
- GELU:基于高斯分布调整输入权重,更自然地处理负值信息。
GELU的计算成本较高,因为它依赖误差函数(erf),需要通过多项式近似计算高斯积分,而Swish(即x * sigmoid(x))的计算更简单。Swish降低了计算成本,同时保持了与GELU相近的模型性能,提升了训练和推理的效率。
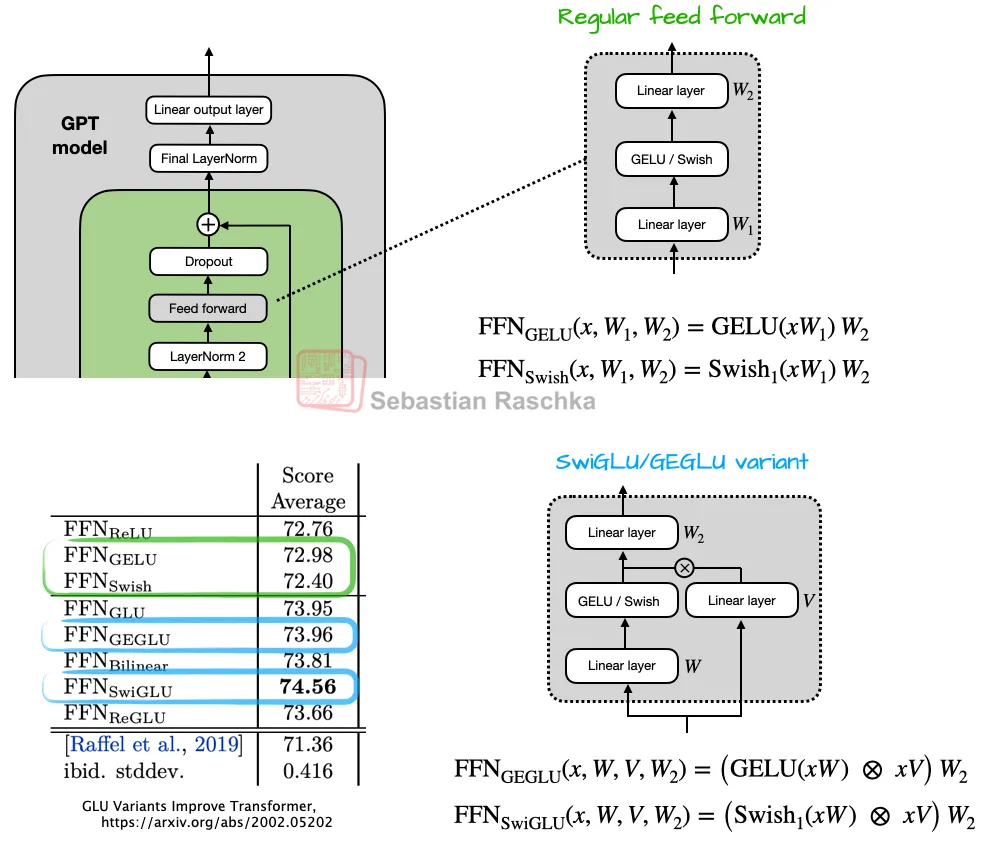
神经网络激活函数与模块的优化进展
Swish、GELU及其门控变体SwiGLU与GEGLU的性能对比
近年来,神经网络中的激活函数和模块设计不断改进。Swish激活函数成为当前主流架构的首选,但GELU(如Google的Gemma模型)仍未被完全淘汰。更显著的变化是,传统的前馈模块(小型多层感知机)被新型的“门控线性单元(GLU)”替代。传统前馈模块的计算效率和表现力可能存在局限,而激活函数的选择(如Swish与GELU)对模型性能的影响存在争议,例如性能提升可能受误差范围或超参数调优的干扰。研究者提出用GLU结构替代传统前馈模块,具体方案是将原有的2个全连接层扩展为3个,通过门控机制增强信息流动(如图6所示)。这种设计能提升模型的表达能力和训练效率。GLU模块的引入为模型性能提供了更稳定的优化路径,而Swish和GELU的并存说明不同场景下需灵活选择激活函数。这些改进共同推动了神经网络在速度和精度上的进步。
理解GLU变体的权重设计差异
文章讨论SwiGLU/GEGLU与传统前馈层(如W_1层)的权重设计差异。表面看,GLU变体的参数量更多(W、V两层),但实际应用中,它们的权重层通常被设计为传统层的一半大小。这种差异容易造成误解,因为直接比较参数数量会忽略实际设计中的调整(如W和V的尺寸减半),导致对模型效率的错误判断。通过具体代码实现对比传统GLU变体,明确展示权重分配的优化逻辑。结果表明:尽管GLU变体结构更复杂,但通过调整层尺寸,最终参数量与传统层相当甚至更优。这种设计既保留了GLU变体的性能优势(如更强的非线性表达能力),又避免了参数冗余,提升了计算效率。
前馈模块与SwiGLU变体的对比
图7展示了两种神经网络模块的对比:标准前馈模块(上方)和SwiGLU变体(下方)。标准前馈模块在复杂任务中可能存在效率或性能限制,需要更优化的结构来提升模型表现。SwiGLU变体通过改进激活函数设计(如结合Swish和GLU),增强了模块的非线性表达能力。实验结果表明,这种结构能提升模型训练效率和任务性能。SwiGLU在保持计算效率的同时,提供了更强的特征提取能力,适用于大规模语言模型等场景。
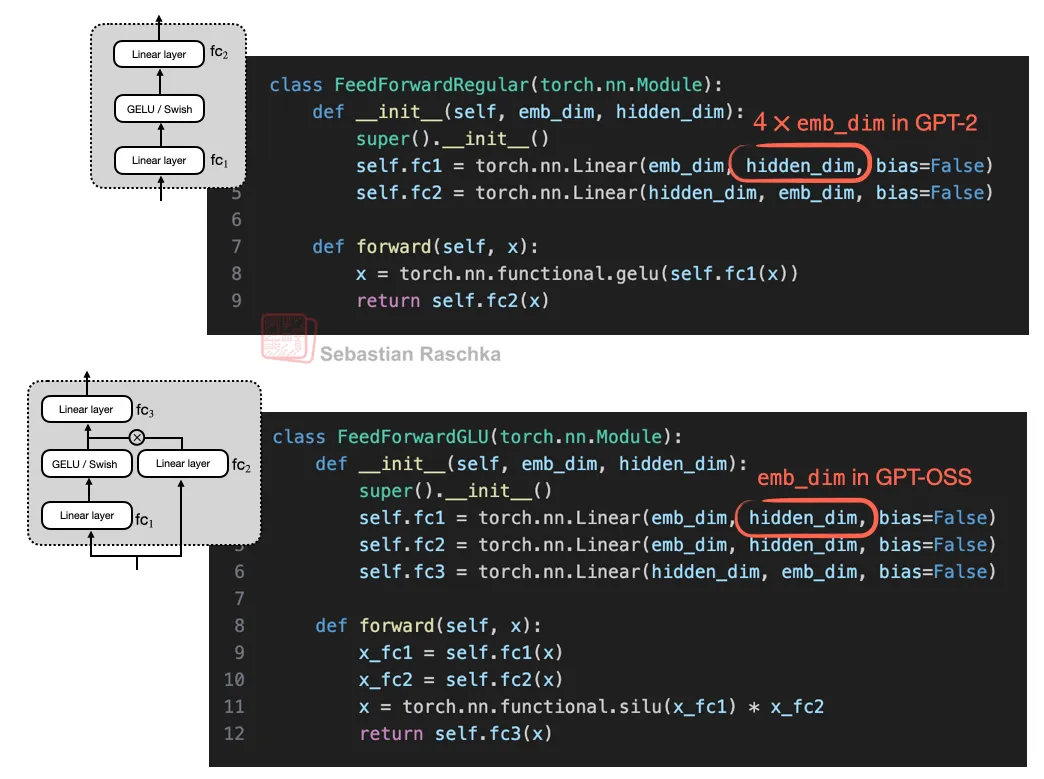
在神经网络中,当嵌入维度为1024时,传统的全连接前馈网络(feed forward)需要大量参数。具体来说,两个全连接层(fc1和fc2)各自需要约419万参数,总参数数达到约838万。如此庞大的参数量会导致模型计算成本高、训练速度慢,并可能增加过拟合风险,影响模型的效率和泛化能力。通过优化网络结构或采用参数共享、低秩分解等技术,可以减少参数数量。例如,使用更高效的架构(如Transformer中的前馈层设计)或压缩方法,能在保持模型性能的同时降低计算资源消耗。减少参数可以提升训练和推理速度,降低硬件需求,并可能提高模型的泛化能力,使其更适合实际应用部署。传统全连接层(如fc1、fc2、fc3)参数量大(总计约629万),可能影响模型性能和训练效率。采用GLU变体后,参数量减少,同时通过引入“乘法交互”增强了模型的表达能力。这种设计类似“深而窄”的网络结构,比“浅而宽”的网络表现更好。
- 参数更少:降低了计算资源需求。
- 性能更强:乘法交互提升了模型的学习能力。
- 效率更高:在训练和推理中表现更优。
简言之,GLU变体以更少的参数实现了更好的效果,是神经网络设计的创新突破。
GPT-OSS采用混合专家(MoE)技术优化模型性能
GPT-OSS在原有单一路径前馈模块(FeedForward)的基础上,引入了混合专家(Mixture-of-Experts, MoE)技术。该技术通过动态选择多个子模块处理不同输入,而非固定使用单一模块(如图8所示)。传统单一前馈模块存在计算资源利用率不足的问题。所有输入均通过同一模块处理,导致部分参数冗余或未被充分利用,影响模型效率和适应性。
- 技术升级:
- 结合SwiGLU(前文提到的激活函数改进)与MoE架构,用多专家系统替代单一模块。
- 每个生成步骤仅激活部分专家(子模块),降低计算负载。
- 结果与优势:
- 提升效率:动态路由机制减少冗余计算,加快推理速度。
- 增强灵活性:不同专家可专注处理特定任务,提高模型适应性。
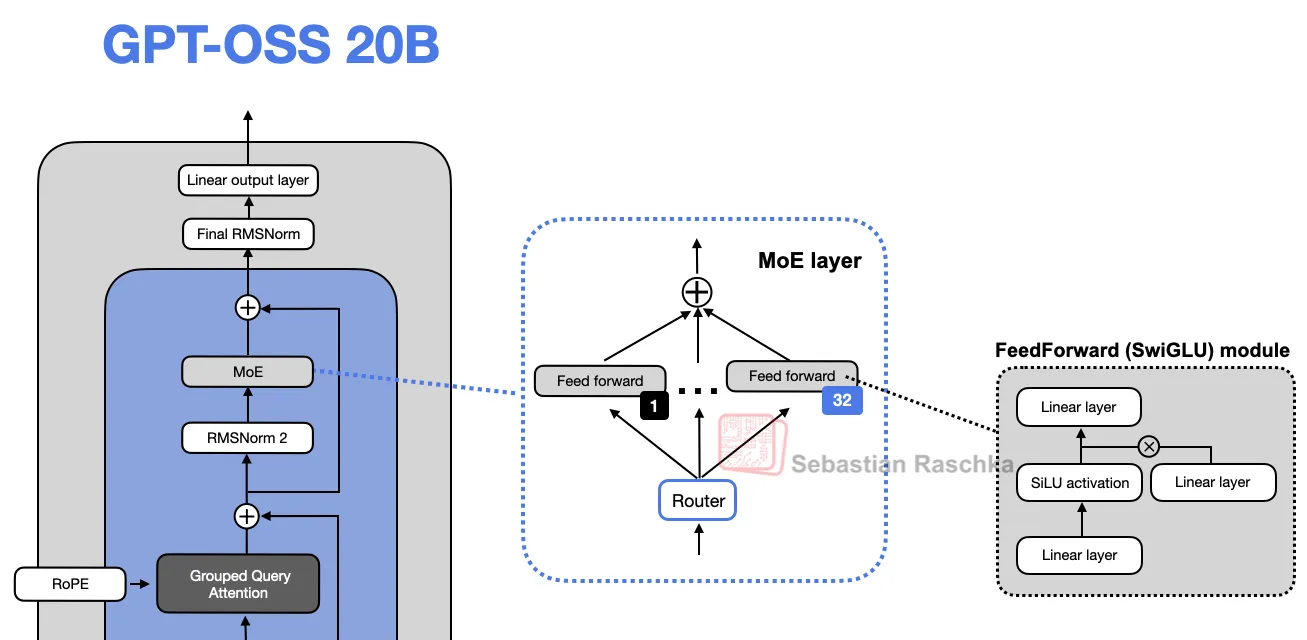
研究人员通过用多个前馈模块(专家)替换单一前馈模块,构建了混合专家模型(MoE)。这种设计大幅增加了模型的总参数量,但通过稀疏激活机制(每次仅调用少数专家)保持了计算效率。传统大语言模型若直接增加参数规模,会导致计算成本过高,影响训练和推理效率。MoE模型引入路由器机制,动态选择每轮计算所需的专家。虽然总参数量庞大(专家权重占比超90%),但实际激活的参数量极少。
分组查询注意力(GQA)取代多头注意力(MHA)
研究人员提出了一种名为分组查询注意力(GQA)的新技术,用于替代传统的多头注意力(MHA)机制。MHA虽然效果优秀,但计算和内存开销较大,因为每个注意力头都需要独立的键(Key)和值(Value)计算。这导致模型效率降低,尤其在处理大规模数据时。
GQA通过分组共享键值投影优化了这一过程。例如,4个注意力头可以分成2组,每组共享同一套键值计算(如图9所示)。这种方式减少了重复计算,从而降低内存占用并提升运算效率。
实验表明,GQA在几乎不影响模型性能的前提下,显著减少了计算资源消耗,使模型运行更高效、更节省内存。这一改进特别适合需要处理海量数据的AI应用场景。
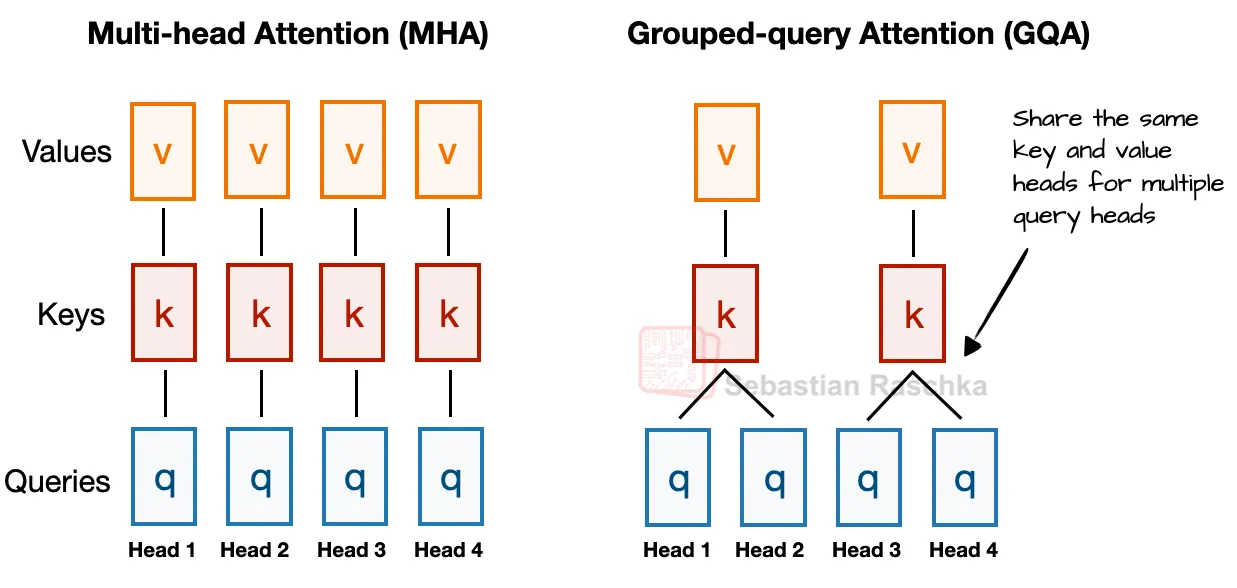
传统MHA需为每个查询生成独立的键值对,导致计算量和内存占用较高,可能影响大语言模型的效率与扩展性。GQA通过分组共享键值对(如示例中的2:1比例),减少了重复计算。这一改进降低了资源消耗,同时保持了模型性能,使模型更轻量且易于扩展。GQA在提升计算效率的同时,为开发更高效的大规模语言模型提供了可行路径,有助于平衡性能与资源成本。
滑动窗口注意力机制
滑动窗口注意力(Sliding-window attention)最早由LongForme论文(2020年)提出,后因Mistral模型推广而普及。gpt-oss模型在每一层中应用了这一技术。传统注意力机制(如多头注意力)需要计算全局上下文,导致内存和计算成本高昂,影响模型效率。
滑动窗口注意力通过将注意力范围限制在局部窗口内,减少计算量。其特点包括:
- 降低资源消耗:缩小上下文窗口,节省内存和算力。
- 兼容分组查询注意力(GQA):可与其他高效注意力变体结合使用。
优势
提升模型运行效率,适合长文本处理。
在保持性能的同时减少硬件需求。
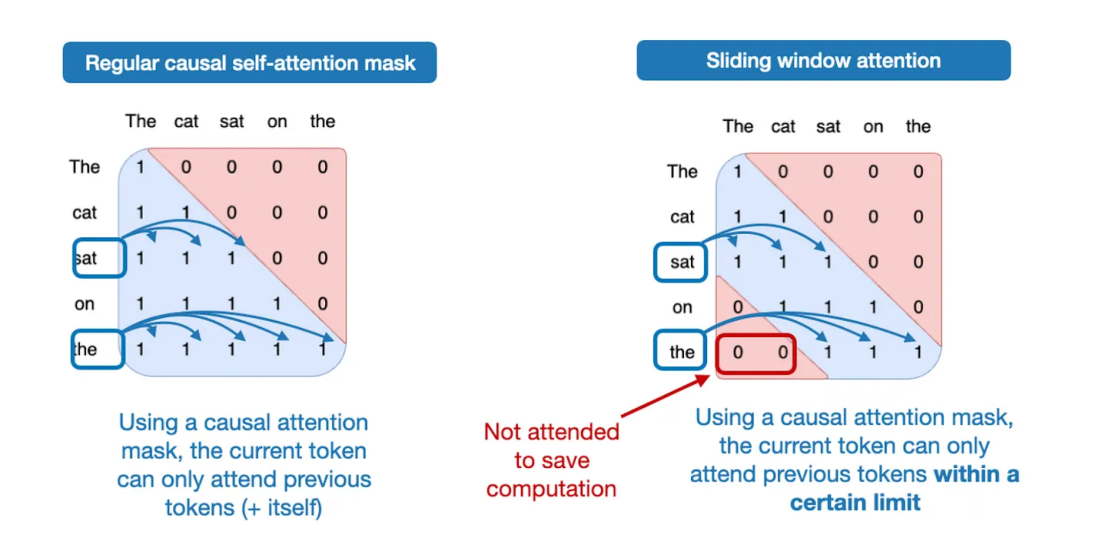
GPT-OSS与滑动窗口注意力技术的优化
GPT-OSS模型采用交替使用的全局注意力(GQA)和滑动窗口注意力(128词限制)层。类似技术曾被Gemma 2(2024)以1:1比例应用,而Gemma 3(2024)进一步调整为5:1比例(即每5层局部注意力配1层全局注意力)。研究显示,滑动窗口对模型性能影响极小。
解决方案与效果
- 技术方案:
- GPT-OSS混合全局与滑动窗口注意力(比例未公开),窗口缩小至128词。
- Gemma 3证明5:1高局部比例可行,窗口减至1024词。
实验结果:
Gemma研究表明,滑动窗口对性能影响可忽略(如图表所示)。
GPT-3曾暗中使用类似稀疏注意力,验证技术可靠性。
用户受益
- 效率提升:局部注意力降低计算开销,适合长文本处理。
- 成本优化:小窗口设计减少资源占用,维持模型性能。
- 技术延续性:GPT-3到Gemma系列的技术迭代证明方案成熟。
总结
通过混合注意力机制与极简窗口设计,GPT-OSS在效率与性能间取得平衡,延续了行业技术趋势。
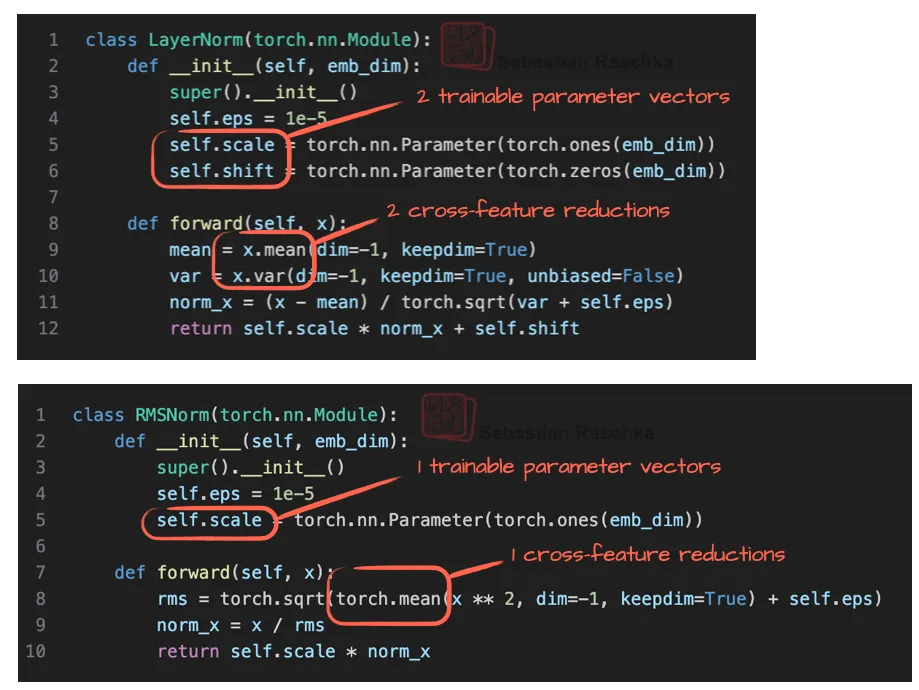
RMSNorm替代LayerNorm的优化改进
近年来,人工智能领域的一项小改进是用RMSNorm(2019年提出)替代了传统的LayerNorm(2016年提出)。这一变化类似于之前用Swish和SwiGLU替换GELU激活函数,属于模型效率的优化趋势之一。LayerNorm虽然被广泛用于归一化神经网络层的激活值,但随着模型规模的扩大和并行计算需求的提升,其计算效率逐渐成为瓶颈。此外,早前流行的BatchNorm也因依赖批次统计量(均值和方差)而难以高效并行化,且在小批量数据上表现不佳。RMSNorm通过简化归一化计算(仅使用均方根标准化,无需均值调整)提升了计算效率,同时保持了与LayerNorm相似的性能。这一改进使模型训练更高效,尤其适合大规模并行计算场景。
优势:
- 计算效率更高:减少计算量,加速训练和推理。
- 更适合并行化:避免BatchNorm的批次依赖问题。
- 小批量适应性:在小批量数据上表现更稳定。
这一优化延续了深度学习领域“小而美”的技术迭代趋势,为模型性能提升提供了实用解决方案。
RMSNorm作为一种替代方案,通过简化计算步骤(例如省略均值中心化),在保持性能的同时降低了计算开销。实验结果表明,RMSNorm在小规模线性层中与LayerNorm效果相近,但计算更高效。
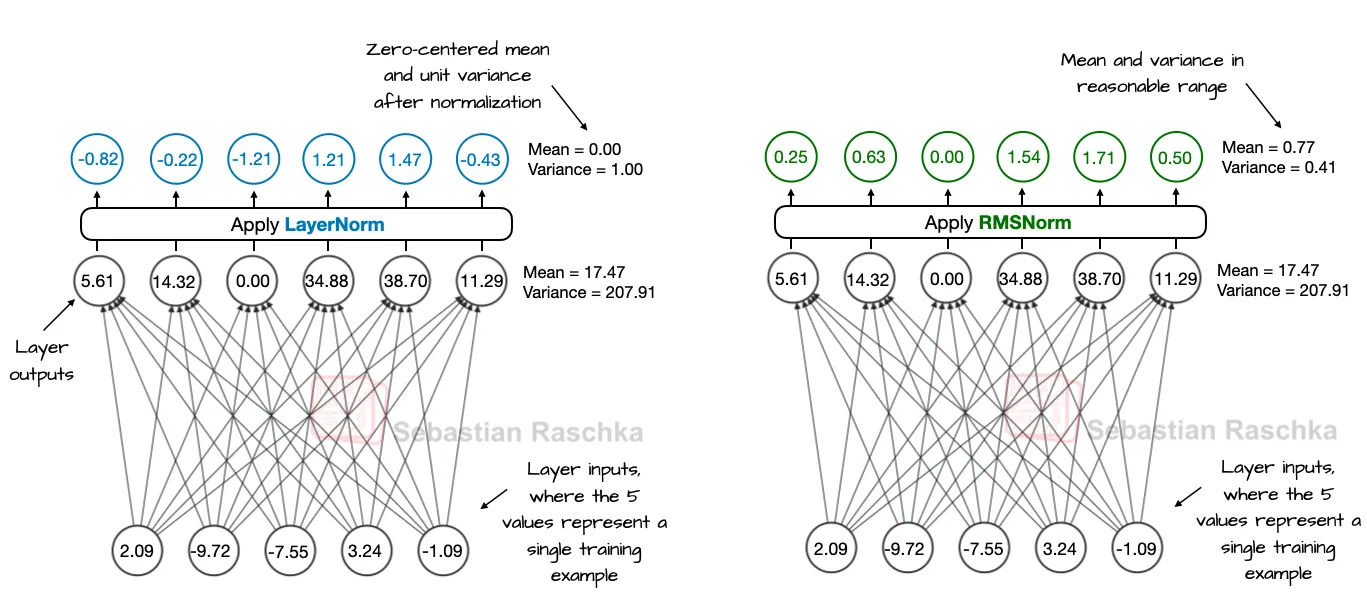
- LayerNorm通过减去均值并除以标准差,使输出均值为0、方差为1,强制数据标准化。
- RMSNorm则通过除以均方根值,虽不强制零均值和单位方差,但仍将输出控制在合理范围(如-1到1)。
采用RMSNorm替代LayerNorm。RMSNorm省去了偏差(平移)项,仅通过单次均方根计算归一化,减少跨特征操作次数。如图12的代码所示,这一改进降低了计算复杂度。
RMSNorm通过移除均值计算(仅保留方差缩放),简化了运算流程。
- 结果:代码对比显示,RMSNorm减少了计算步骤,更轻量。
- 优势:提升计算效率,适合资源受限的场景(如移动端或大规模模型部署),同时保持模型性能。
GPT-2的遗产
GPT-2作为大型语言模型的早期架构,因其结构简洁清晰,至今仍被推荐为学习语言模型(LLM)的入门选择。初学者在接触复杂的语言模型时,容易因过多的优化技巧和层级结构而陷入困惑,难以掌握核心原理。学习者能更快理解语言模型的核心机制,为后续进阶学习(如GPT-3等更复杂模型)打下坚实基础。这种“由简入繁”的路径,提升了学习效率和信心。
GPT OSS与Qwen3架构的对比分析
文章对比了开源模型GPT OSS与近期发布的Qwen3架构,重点分析了两者在规模与性能上的异同。Qwen3作为2025年5月发布的先进开源模型,因其参数规模与GPT OSS相近(约200亿参数),成为直接比较的对象。为何需要对比这两者?一方面,GPT OSS代表了GPT-2以来的技术演进成果,而Qwen3是当前开源领域的标杆之一。通过对比,可评估不同技术路线的优劣,帮助开发者和研究者选择更适合的模型架构。通过参数规模对齐(如选择Qwen3中与GPT OSS相当的MoE模型),直接比较两者的性能差异。这种对比揭示了Qwen3在效率或任务表现上的潜在优势,同时凸显GPT OSS的特定设计价值。
此类分析为开源社区提供了清晰的参考:
- 技术选型:帮助团队根据需求(如计算资源、任务类型)选择模型;
- 优化方向:通过差异分析,指导后续模型改进;
- 开源生态:促进不同架构间的经验共享,推动整体技术进步。
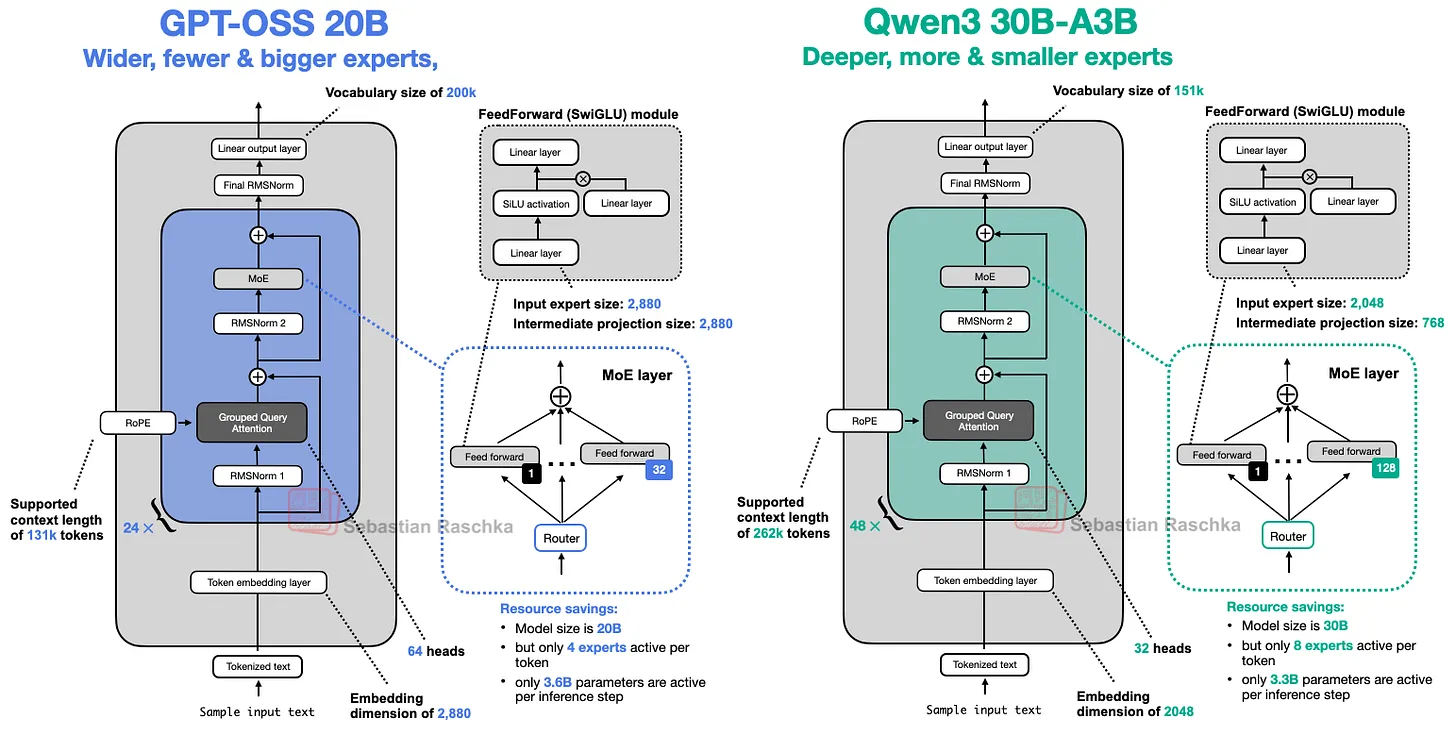
主要内容:GPT-OSS 20B和Qwen3 30B-A3B两款模型的架构组件高度相似,但存在关键差异。
核心问题:两者的主要区别在于模型规模(如参数量的不同)以及GPT-OSS采用了滑动窗口注意力机制(如第1.6节所述),而Qwen3未使用该技术。
解决方案与结果:通过逐一对比架构细节(如维度设计、注意力机制),明确技术差异。分析表明,滑动窗口注意力可能提升GPT-OSS的局部上下文处理效率,而Qwen3的更大参数量可能增强整体表现。
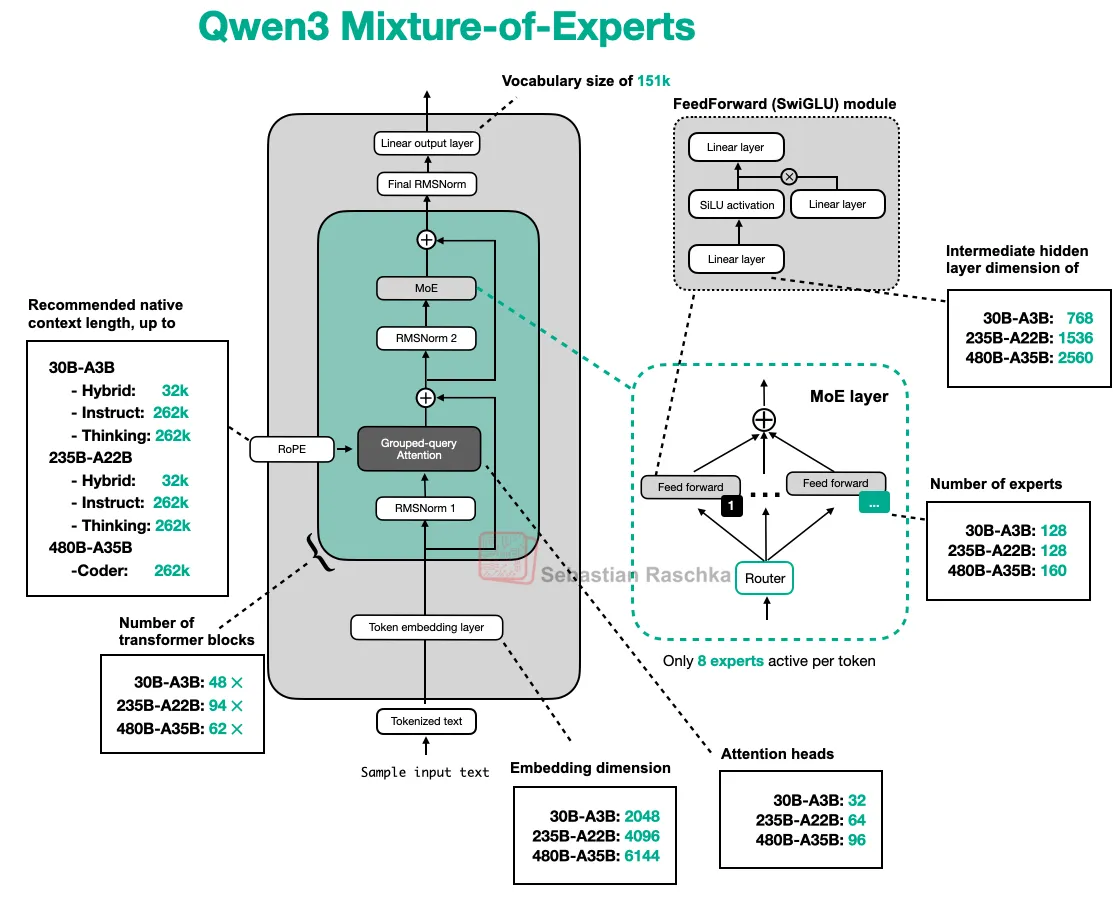
Qwen3模型的深度架构优势
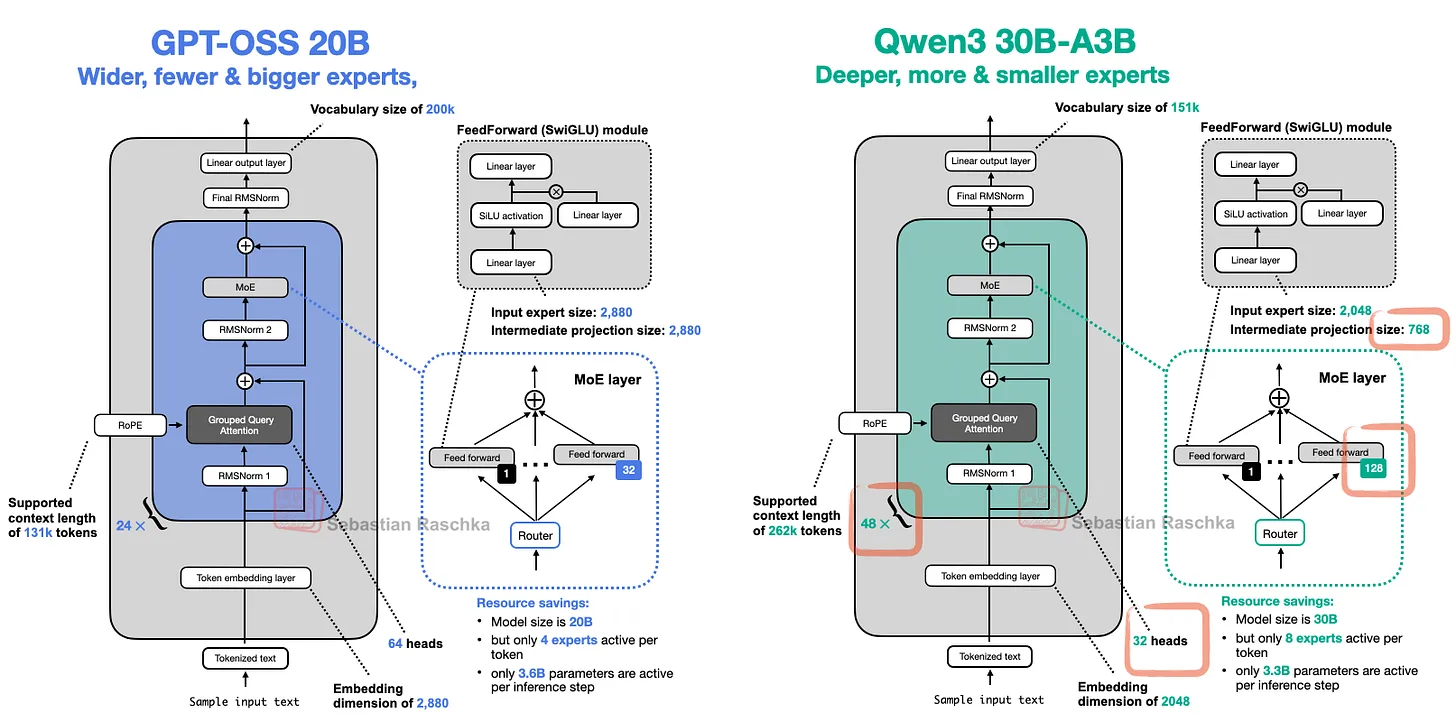
主要内容:Qwen3模型的架构比对比模型更深,拥有48层Transformer模块,而对比模型仅有24层。
核心问题:更深的架构设计(48层)可能带来更高的计算复杂度或训练成本,但为何仍被采用?
解决方案与结果:通过增加Transformer层数(深度),Qwen3提升了模型的特征提取和表达能力。实验表明,深度架构能更有效地捕捉数据中的复杂模式。
实际效益:这种设计使Qwen3在任务处理中表现更优,尤其适用于需要高精度理解的场景(如自然语言处理),最终为用户提供更准确的输出结果。
通过增加Transformer块数量(如Qwen3的设计),模型能捕捉更复杂的语言特征。结果显示,深层架构提升了性能,但需权衡计算资源消耗。
GPT-OSS与标准GPT架构的对比分析
GPT-OSS是一种比标准GPT(如GPT-3)更宽的神经网络架构,主要差异包括:嵌入维度(2880 vs. 2048)、中间专家层维度(5760 vs. 768)以及更多的注意力头数。
核心问题
在参数总量固定的前提下,如何选择架构设计(更深或更宽)以平衡模型性能与训练效率?更深模型可能面临梯度不稳定(如梯度爆炸/消失)的问题,而更宽架构虽能提升推理速度,却会增加内存开销。
解决方案与结果
- 解决方案:
- 更宽架构(如GPT-OSS)通过并行化加速推理,吞吐量更高(单位时间生成更多token)。
- 更深架构依赖RMSNorm和残差连接等技术缓解训练不稳定性。
- 对比结果:
- Gemma 2论文的消融实验(表9)显示,在参数量和数据集相同时,不同架构的性能差异需进一步验证。
优势总结
- 更宽架构:适合高吞吐需求场景,推理更快,但内存占用更大。
- 更深架构:灵活性更强,但需额外技术保障训练稳定性。
- 实际选择:需根据任务需求(如速度优先或资源限制)权衡设计。
更宽的模型架构在9B参数规模下表现略优
主要内容:
一项研究发现,在9B(90亿)参数的模型架构中,采用更宽(宽度优先)的设计比更深(深度优先)的设计表现更好。
主要问题:
在构建大规模AI模型时,设计者需权衡模型的宽度(每层神经元数量)和深度(层数)。哪种设计更优一直是一个关键问题。
解决方案与结果:
研究人员对比了两种9B参数架构:
- 更宽的模型:在4项基准测试中平均得分为52.0。
- 更深的模型:平均得分为50.8。
实际效益:
更宽的设计略微领先(52.0 vs. 50.8),为AI开发者提供了明确的优化方向。这一发现可帮助团队更高效地设计高性能模型,节省调参成本。
GPT-OSS 采用了较少的专家数量(32 个)和较大的专家规模,而 Qwen3 则使用更多但更小的专家(128 个)。这一设计与当前趋势(如 DeepSeekMoE 论文所示)形成对比,后者倾向于更多但更小的专家模型。
主要问题:在总参数量相同的情况下,如何平衡专家数量和专家规模,以优化模型性能?
解决方案与结果:GPT-OSS 选择减少专家数量(32 个),但增大每个专家的规模,同时仅激活 4 个专家(而非 8 个)。这种设计可能提高计算效率,并减少专家切换的开销。
优势:较大的专家可能提高单专家的学习能力,而较少的激活专家可降低计算成本。这一调整可能带来更高效的推理性能,同时保持模型的总参数量不变。
少数大专家对许多小专家
DeepSeekMoE提出了一种新型的“专家混合”(Mixture-of-Experts, MoE)语言模型架构,旨在通过更精细的专家分工提升模型性能。研究团队设计了细粒度专家专业化策略,通过动态路由机制,确保每个输入仅激活最相关的专家子集。实验表明,该模型在相同计算成本下,性能显著优于传统密集模型和标准MoE架构。
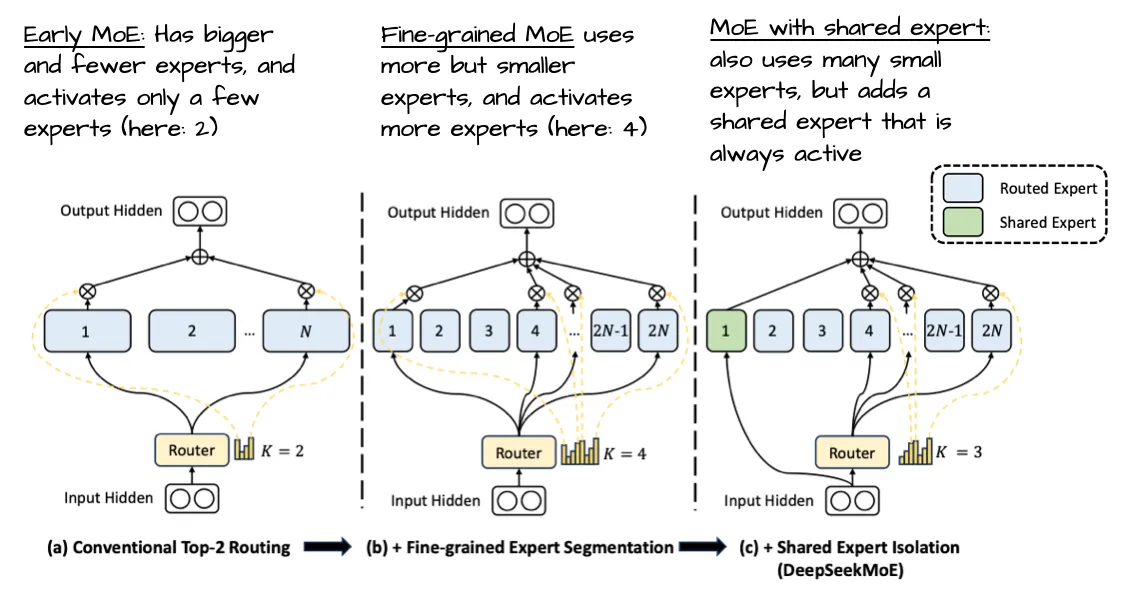
通过对比发现,gpt-oss和Qwen3利用“共享专家”优化模型效率,而DeepSeek选择其他技术路径。这种差异可能导致模型性能、训练成本或应用场景的不同。
主要内容:
研究发现,GPT模型在较小规模(如200亿参数)时,专家数量较少,这可能与模型容量限制有关。
主要问题:
专家数量不足可能是由于模型规模较小(200亿参数),导致计算资源分配受限,无法支持更多专家模块。
解决方案与结果:
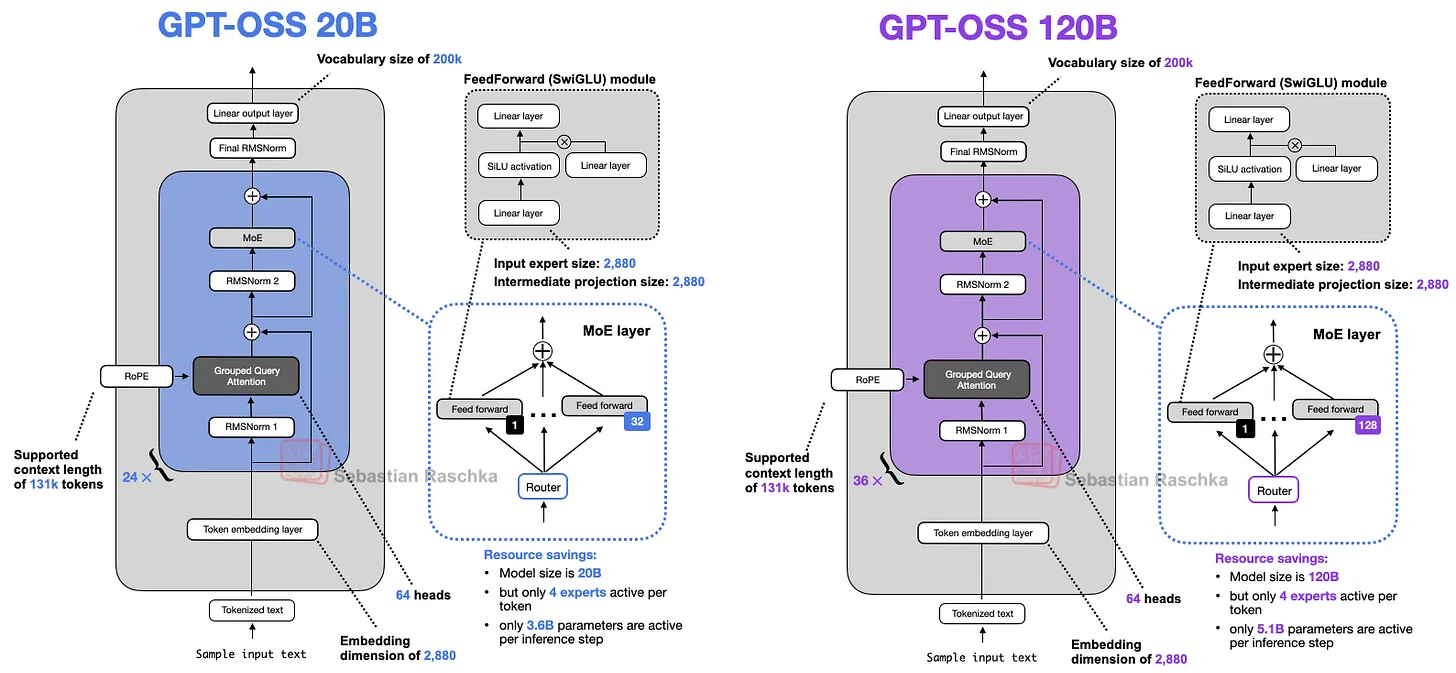
在更大规模(1200亿参数)的模型中,研究人员增加了专家数量和Transformer层数,同时保持其他参数不变(如图1所示)。
效益:
扩大模型规模后,专家数量的提升可能优化了模型性能,使其能够处理更复杂的任务,同时保持计算效率的平衡。
采用“仅扩展核心组件”(Transformer块和专家数量)的简化设计。
结果与效益:
- 效率提升:减少非必要参数调整,降低计算资源需求;
- 可扩展性:通过模块化设计更易实现大规模模型升级;
- 成本优化:聚焦关键组件扩展,避免冗余结构带来的训练负担。
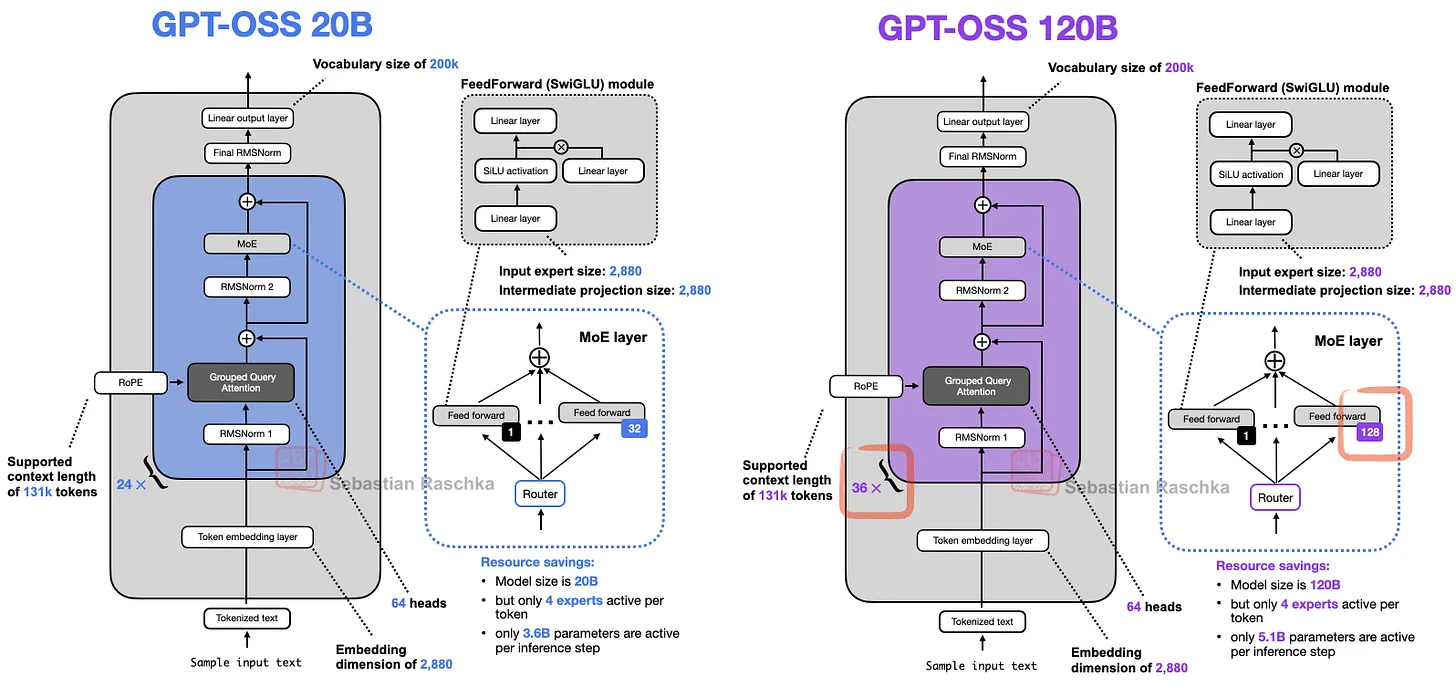
主要内容:
研究人员发现,120B模型和20B模型的结构非常相似。120B模型是主要开发目标,而20B模型是通过减少部分Transformer模块和专家数量(MoE架构中的关键参数)来缩小的版本。
主要问题:
这种设计方式不太常见,因为通常模型的不同规模会通过调整更多参数(如层数、宽度等)来实现,而非仅缩减模块和专家数量。因此,有人猜测20B模型可能并非从头训练,而是从120B模型裁剪而来。
解决方案与结果:
若假设成立,研究人员可能采用“剪枝+继续训练”的方法(即基于120B模型削减部分结构并微调),而非从零开始训练20B模型。这种方式能节省计算资源,并更快得到小模型。
潜在优势:
- 效率提升:避免重复训练,缩短开发周期。
- 成本优化:减少算力消耗,降低实验成本。
- 性能延续:小模型可能保留大模型的部分能力。
对比案例:
其他团队(如Qwen3的MoE模型)会均衡调整更多参数(如图17所示),而非仅聚焦于模块和专家数量,说明当前方法的特殊性。
Qwen3的MoE模型
注意力偏差和注意力下沉
GPT-OSS和Qwen3均采用了分组查询注意力(GQA)机制,但GPT-OSS在部分层中通过滑动窗口注意力限制上下文长度。此外,GPT-OSS在注意力权重中使用了偏置单元(bias units),以优化模型性能。
核心问题:
- 注意力机制差异:GPT-OSS和Qwen3虽均使用GQA,但GPT-OSS通过滑动窗口限制上下文,可能影响长序列建模能力。
- 偏置单元的作用:GPT-OSS引入的注意力偏置单元的具体效果尚需验证,可能影响模型的稳定性和泛化性。
解决方案与效果:
- 滑动窗口注意力:GPT-OSS在部分层采用滑动窗口,减少计算开销,提升推理效率,但可能牺牲部分长距离依赖捕捉能力。
- 注意力偏置单元:通过引入偏置调整注意力权重,可能增强模型对关键信息的聚焦能力,提升生成质量。
优势:
- 计算高效:滑动窗口降低内存和计算需求,适合长文本处理。
- 精准注意力:偏置单元可能帮助模型更稳定地分配注意力,减少无关信息干扰。
GPT-oss模型在注意力层中引入了偏置单元(bias units),这一改进旨在优化模型的注意力机制。GPT-oss通过添加偏置单元,增强了注意力层的灵活性和适应性。这一调整使模型能够更精准地分配注意力权重,从而提升生成文本的连贯性和逻辑性。
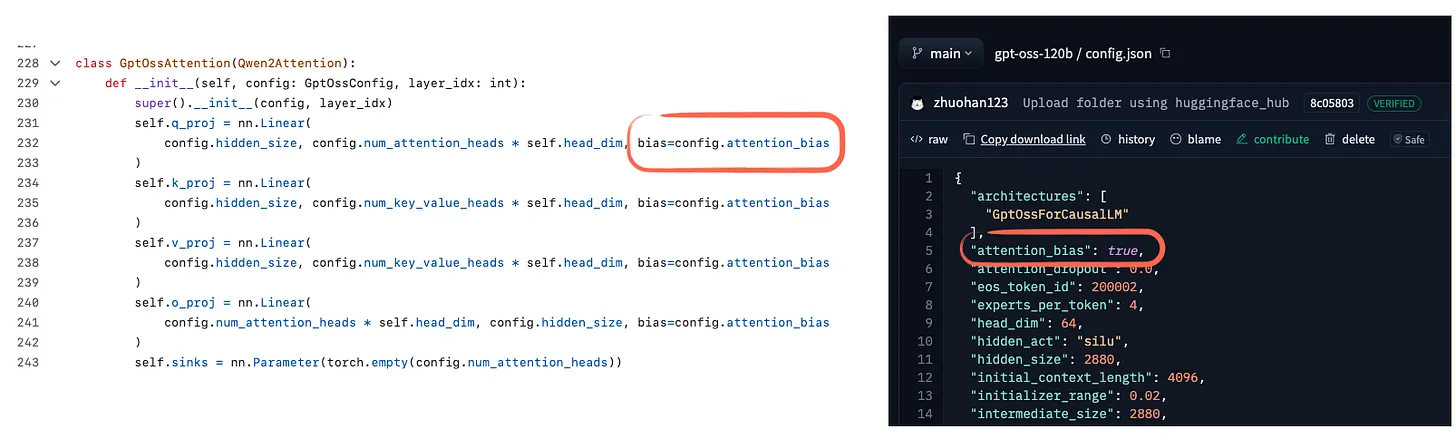
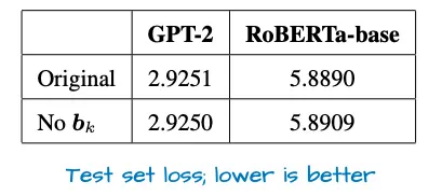
神经网络中的偏置单元是否必要?
近年来,像GPT-2这样的早期神经网络模型中常使用偏置单元(bias units),但如今已较少见。研究表明,这类偏置单元可能并非必要,尤其是在关键变换(如k_proj)中。偏置单元曾被广泛使用,但后来被认为冗余。数学分析证明,至少在关键变换中,偏置单元的作用有限。
注意力汇聚机制(Attention Sinks)的作用与实现
在长上下文语言模型中,研究者引入了一种称为“注意力汇聚”(Attention Sinks)的机制。该机制通过一个特殊的“始终被关注”的虚拟标记(或偏置项)来稳定模型的注意力分配,尤其在处理超长文本时表现关键。
核心问题:
传统注意力机制在长序列任务中可能失效,因模型难以持续关注重要信息。随着上下文长度增加,部分关键内容可能被忽略,导致性能下降。
解决方案与效果:
- 方法:在模型起始位置添加虚拟的“注意力汇聚”标记(或通过可学习的偏置项实现),强制模型始终保留一部分注意力资源。
- 结果:该设计确保模型在长文本中仍能稳定分配注意力,避免信息丢失。
- 优势:提升长上下文任务的性能(如流式语言模型),同时减少计算资源浪费。
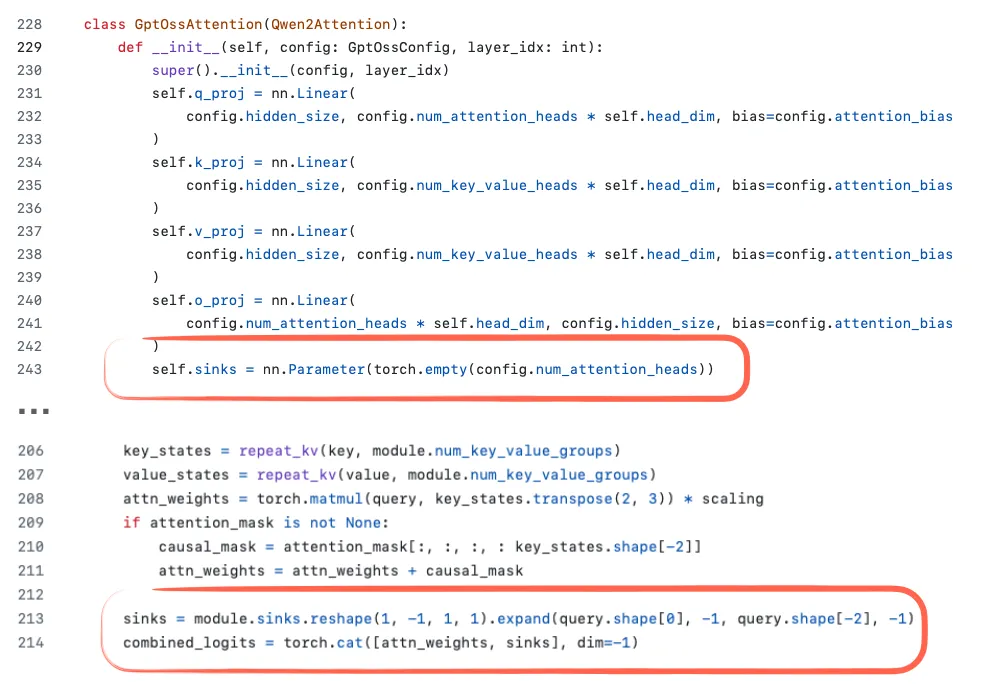
主要内容:研究人员提出了一种改进注意力机制的方法,旨在更公平地分配模型对不同文本片段的关注度(如图20所示)。
核心问题:传统的注意力机制可能对某些输入片段过度关注,导致模型在处理信息时出现偏差,影响结果的公平性和准确性。
解决方案与效果:新方法通过调整注意力评分(而非直接修改输入数据)来平衡模型对各部分的关注。这一调整避免了人为干预输入数据,保持了模型的自然处理流程。
优势:改进后的机制能更均衡地分配注意力,提升模型输出的客观性,同时减少对输入数据的依赖,使模型更高效、更稳定。
总结:通过优化注意力评分,新方法在无需改动输入的前提下,有效解决了注意力偏差问题,增强了模型的公平性和可靠性。
未完待续。。。
附录
思考
Agent是作者个人或者团体的一些强烈的哲学表达
最近看到的提示词相关内容汇总
基于数据驱动来写提示词(一)
Strands Agent实战
Strands Agent 前文
Community Over Code 2025获得的花絮(Strands Agent踩坑记录,被AWS的speaker催更
)
基于Strands Agent开发辅助阅读Agent
Agent从零开发
没用langchain什么的脚手架,从DeepSeek官网的首次调用 API 开始,一步一步,面向DeepSeek开始对话的开发实战记录。
没有Vibe Coding IDE, 学生可以从这个过程看底层一步一步怎么做的,为什么这么做。
如果想学习古法编程的朋友,可以一步一步从零自学。
理解原理,如果后续langchain全面收费的话,大家可以知道什么部分为什么这么设计,方便迁移。
是Conference还是Hackathon?Community Over Code 2025上践行自己的哲学感悟(一)
是Conference还是Hackathon?Community Over Code 2025上践行自己的哲学感悟(二)
是Conference还是Hackathon?Community Over Code 2025上践行自己的哲学感悟(三)
是Conference还是Hackathon?Community Over Code 2025上践行自己的哲学感悟(插曲篇)
是Conference还是Hackathon?Community Over Code 2025上践行自己的哲学感悟(五)
是Conference还是Hackathon?Community Over Code 2025上践行自己的哲学感悟(六)
是Conference还是Hackathon?Community Over Code 2025上践行自己的哲学感悟(七)